tldr transformers
1.0.0
關於變壓器和現代NLP的一些著名論文的“ TL; Dr”。
這是一個活的回購以保留不同的研究線程的標籤。
最後更新:2021年9月20日。
型號:gpt- *, *bert *,apapter- *, *t5,Megatron,dall-e,codex,等。
主題:變壓器體系結構 +培訓;對抗攻擊;縮放法律;結盟;記憶;很少的標籤;因果關係。
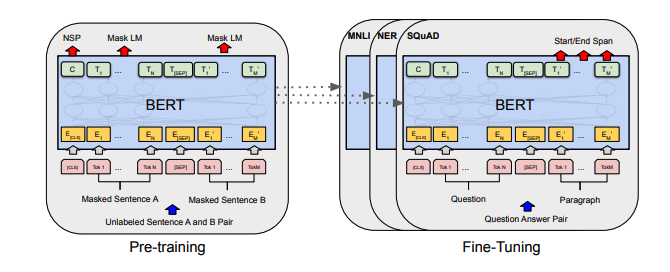
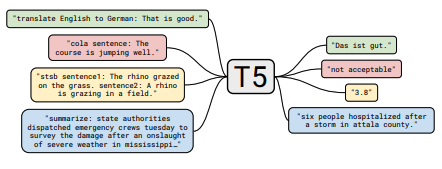
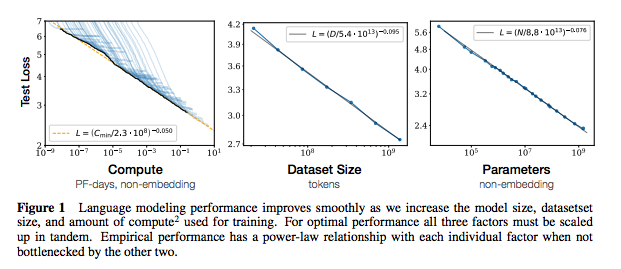
每組註釋都包括指向紙張的鏈接,原始代碼實現(如果有)和擁抱面?執行。
這裡有一些例子---> t5,byt5,縮短變壓器訓練集。
此存儲庫還包括一個量化變壓器論文差異的表一張桌子。
在下面按時間順序介紹了變形金剛的論文。轉到“:point_right:筆記:point_left:”下面的列以找到每篇論文的註釋。
這不是NLP深度學習的介紹。如果您要尋找的話,我建議您使用以下一項:快速AI的課程,Coursera課程之一,或者這是古老的事情。在那之後來這裡。
隨著過去幾年對變形金剛的所有內容的爆炸式爆炸,以易消化格式對每篇論文的顯著特徵/結果/見解進行分類似乎很有用。因此,這個倉庫。
| 模型 | 年 | 研究所 | 紙 | 注意? | 原始代碼 | 擁抱面? | 其他倉庫 |
|---|---|---|---|---|---|---|---|
| 變壓器 | 2017 | 注意就是您所需要的 | 跳過,太多的文章:
| ? | |||
| GPT-3 | 2018 | Openai | 語言模型是無監督的多任務學習者 | 待辦事項 | x | x | |
| GPT-J-6B | 2021 | Eleutherai | GPT-J-6B:基於JAX的6B變壓器(公共GPT-3 ) | x | 這裡 | x | x |
| 伯特 | 2018 | BERT:深層雙向變壓器的預訓練以了解語言理解 | 伯特注意 | 這裡 | 這裡 | ||
| Distilbert | 2019 | 擁抱面 | Distilbert,Bert的蒸餾版:較小,更快,更便宜,更輕 | Distilbert筆記 | 這裡 | ||
| 阿爾伯特 | 2019 | Google/Toyota | 阿爾伯特:一個用於自我監督語言表徵學習的精簡版 | 阿爾伯特筆記 | 這裡 | 這裡 | |
| 羅伯塔 | 2019 | 羅伯塔:一種強大優化的BERT預訓練方法 | 羅伯塔筆記 | 這裡 | 這裡 | ||
| 巴特 | 2019 | 巴特:自然語言生成,翻譯和理解的序列前訓練序列前訓練 | 巴特筆記 | 這裡 | 這裡 | ||
| T5 | 2019 | 使用統一的文本到文本變壓器探索轉移學習的限制 | T5筆記 | 這裡 | 這裡 | ||
| 適配器 - 伯特 | 2019 | NLP的參數有效傳輸學習 | 適配器 - 伯特筆記 | 這裡 | - | 這裡 | |
| Megatron-LM | 2019 | Nvidia | Megatron-LM:使用模型並聯培訓數十億個參數語言模型 | 威震天注意 | 這裡 | - | 這裡 |
| 改革家 | 2020 | 改革者:高效的變壓器 | 改革家指出 | 這裡 | |||
| byt5 | 2021 | BYT5:邁向具有預訓練字節模型的無令牌未來 | BYT5註釋 | 這裡 | 這裡 | ||
| 夾子 | 2021 | Openai | 從自然語言監督中學習可轉移的視覺模型 | 剪輯筆記 | 這裡 | 這裡 | |
| dall-e | 2021 | Openai | 零擊文本對圖像生成 | dall-e注意 | 這裡 | - | |
| 法典 | 2021 | Openai | 評估經過代碼培訓的大型語言模型 | 法典註釋 | x | - |
所有的桌子摘要都發現 ^倒在一個非常大的桌子中。
| 紙 | 年 | 研究所 | 注意? | 代碼 |
|---|---|---|---|---|
| 基於梯度的對抗攻擊文本變壓器 | 2021 | 基於梯度的攻擊說明 | 沒有任何 |
| 紙 | 年 | 研究所 | 注意? | 代碼 |
|---|---|---|---|---|
| 預先訓練的語言模型微調的對比度學習 | 2021 | SCL注意 | 沒有任何 |
| 紙 | 年 | 研究所 | 注意? | 代碼 |
|---|---|---|---|---|
| 來自人類偏好的微調語言模型 | 2019 | Openai | 人類的預注 | 沒有任何 |
| 紙 | 年 | 研究所 | 注意? | 代碼 |
|---|---|---|---|---|
| 神經語言模型的縮放法律 | 2020 | Openai | 縮放法律註釋 | 沒有任何 |
| 紙 | 年 | 研究所 | 注意? | 代碼 |
|---|---|---|---|---|
| 從大語言模型中提取培訓數據 | 2021 | Google等。 | 待辦事項 | 沒有任何 |
| 重複培訓數據使語言模型更好 | 2021 | Google等。 | DEDUP筆記 | 沒有任何 |
| 紙 | 年 | 研究所 | 注意? | 代碼 |
|---|---|---|---|---|
| NLP中有限數據學習的數據增強的經驗調查 | 2021 | git/unc | 待辦事項 | 沒有任何 |
| 以更少的示例學習學習 | 2021 | 凱文·墨菲(Kevin Murphy)和科林·拉弗爾(Colin Raffel)(預印本:“概率機器學習”,第19章) | 值得一讀,不會在這裡總結。 | 沒有任何 |
如果您有興趣為此倉庫做出貢獻,請隨時執行以下操作:
毫無疑問,這裡有不正確的信息。請打開一個問題並指出。
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}對於上面的註釋,我已經鏈接了原始論文。
麻省理工學院


