tldr transformers
1.0.0
El "TL; Dr" en algunos documentos notables en Transformers y NLP moderno.
Este es un viviendo Repo para vigilar diferentes hilos de investigación.
Última actualización : 20 de septiembre de 2021.
Modelos : Gpt- *, *bert *, adaptador- *, *t5, megatron, dall-e, Codex, etc.
Temas : Arquitecturas de transformadores + entrenamiento; ataques adversos; leyes de escala; alineación; memorización; Pocas etiquetas; causalidad.
¿Cada conjunto de notas incluye enlaces al documento, la implementación del código original (si está disponible) y la cara de Hugging? implementación.
Aquí hay algunos ejemplos ---> T5, BYT5, dedicando conjuntos de entrenamiento de transformadores.
Este repositorio también incluye una tabla que cuantifica las diferencias entre los documentos del transformador. Todo en una mesa .
Los documentos Transformers se presentan algo cronológicamente a continuación. Vaya a la columna ": Point_Right: Notes: Point_Left:" A continuación para encontrar las notas para cada documento.
Esta no es una introducción al aprendizaje profundo en la PNL. Si está buscando eso, recomiendo uno de los siguientes: el curso de AI Fast AI, uno de los cursos de Coursera, o tal vez esta vieja cosa. Ven aquí después de eso.
Con la explosión en los documentos de todas las cosas transformadores en los últimos años, parece útil catalogar las características/resultados/ideas destacados de cada documento en un formato digerible. De ahí este repositorio.
| Modelo | Año | Instituto | Papel | Notas? | Código original | ¿Huggingface? | Otro repositorio |
|---|---|---|---|---|---|---|---|
| Transformador | 2017 | La atención es todo lo que necesitas | Omitió, demasiados buenos escritos:
| ? | |||
| GPT-3 | 2018 | Opadai | Los modelos de idiomas son alumnos multitarea no supervisados | Hacer | incógnita | incógnita | |
| GPT-J-6B | 2021 | Eleutherai | GPT-J-6B: 6B Transformer basado en Jax ( público GPT-3 ) | incógnita | aquí | incógnita | incógnita |
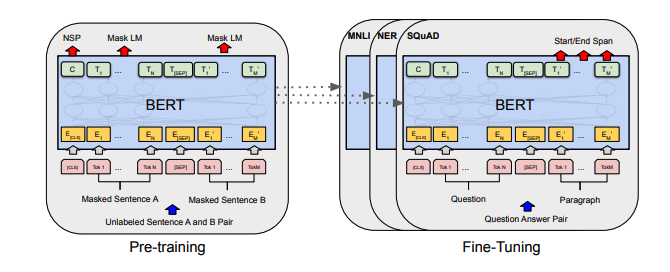
| Bert | 2018 | BERT: pretruamiento de transformadores bidireccionales profundos para la comprensión del lenguaje | Bert Notas | aquí | aquí | ||
| Distilbert | 2019 | Cara de abrazo | Distilbert, una versión destilada de Bert: más pequeño, más rápido, más barato y más ligero | Notas de Distilbert | aquí | ||
| Albert | 2019 | Google/Toyota | Albert: A Lite Bert para el aprendizaje auto-supervisado de representaciones lingüísticas | Notas de Albert | aquí | aquí | |
| Roberta | 2019 | Roberta: un enfoque de prepertinamiento de Bert con sólidamente optimizado | Notas de Roberta | aquí | aquí | ||
| Barbar | 2019 | BART: Precrendimiento de secuencia a secuencia de denominación para la generación de lenguaje natural, traducción y comprensión | Bart Notes | aquí | aquí | ||
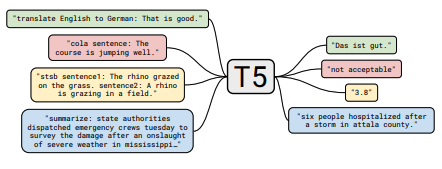
| T5 | 2019 | Explorando los límites del aprendizaje de transferencia con un transformador de texto a texto unificado | Notas T5 | aquí | aquí | ||
| Adaptador-bert | 2019 | Aprendizaje de transferencia de parámetros-eficiente para PNL | Notas de adaptador-bert | aquí | - | aquí | |
| Megatron-lm | 2019 | Nvidia | Megatron-LM: capacitación de modelos de lenguaje de parámetros multimillonarios utilizando paralelismo del modelo | Notas megatronas | aquí | - | aquí |
| Reformador | 2020 | Reformador: el transformador eficiente | Notas de reformador | aquí | |||
| byt5 | 2021 | BYT5: Hacia un futuro sin token con modelos de byte-byte previamente entrenados | Byt5 Notas | aquí | aquí | ||
| ACORTAR | 2021 | Opadai | Aprender modelos visuales transferibles a partir de supervisión del lenguaje natural | Notas | aquí | aquí | |
| Dall-E | 2021 | Opadai | Generación de texto a imagen | Notas de Dall-E | aquí | - | |
| Códice | 2021 | Opadai | Evaluación de modelos de idiomas grandes capacitados en código | Notas de Codex | incógnita | - |
Todos los resúmenes de la mesa se encontraron colapsados en una mesa realmente grande aquí.
| Papel | Año | Instituto | Notas? | Codos |
|---|---|---|---|---|
| Ataques adversos basados en gradientes contra transformadores de texto | 2021 | Notas de ataque basadas en gradiente | Ninguno |
| Papel | Año | Instituto | Notas? | Codos |
|---|---|---|---|---|
| Aprendizaje contrastante supervisado para el modelo de lenguaje previamente capacitado ajustado | 2021 | Notas de SCL | Ninguno |
| Papel | Año | Instituto | Notas? | Codos |
|---|---|---|---|---|
| Modelos lingüísticos de ajuste de las preferencias humanas | 2019 | Opadai | Notas prefas humanas | Ninguno |
| Papel | Año | Instituto | Notas? | Codos |
|---|---|---|---|---|
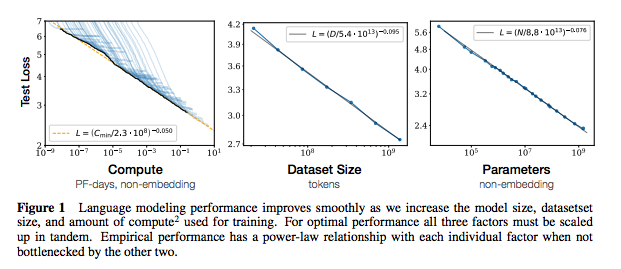
| Leyes de escala para modelos de lenguaje neuronal | 2020 | Opadai | Notas de las leyes de escala | Ninguno |
| Papel | Año | Instituto | Notas? | Codos |
|---|---|---|---|---|
| Extracción de datos de capacitación de modelos de idiomas grandes | 2021 | Google et al. | Hacer | Ninguno |
| Deduplicar datos de capacitación mejora los modelos de idiomas | 2021 | Google et al. | Notas de desgaste | Ninguno |
| Papel | Año | Instituto | Notas? | Codos |
|---|---|---|---|---|
| Una encuesta empírica del aumento de datos para el aprendizaje de datos limitado en la PNL | 2021 | Git/unc | Hacer | Ninguno |
| Aprender con menos ejemplos etiquetados | 2021 | Kevin Murphy y Colin Raffel (preimpresión: "Aprendizaje automático probabilístico", Capítulo 19) | Vale la pena leer, no resumirá aquí. | Ninguno |
Si está interesado en contribuir a este repositorio, no dude en hacer lo siguiente:
Indudablemente, hay información que es incorrecta aquí. Abra un problema y lo señale.
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}Para las notas anteriores, he vinculado los documentos originales.
MIT


