tldr transformers
1.0.0
トランスとモダンなNLPに関するいくつかの注目すべき論文に関する「TL; DR」。
これはですリビングさまざまな研究スレッドのタブを保持するためのレポ。
最終更新:2021年9月20日。
モデル:gpt- *、 *bert *、adapter- *、 *t5、megatron、dall-e、codexなど。
トピック:トランスアーキテクチャ +トレーニング。敵対的な攻撃;スケーリング法;アライメント;暗記;いくつかのラベル。因果関係。
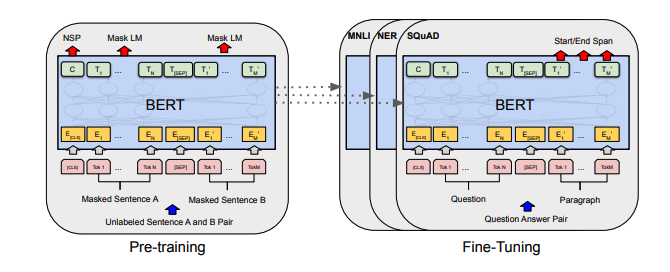
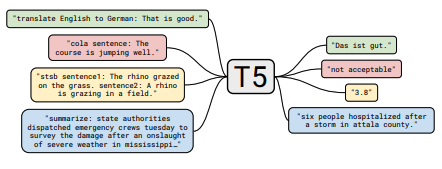
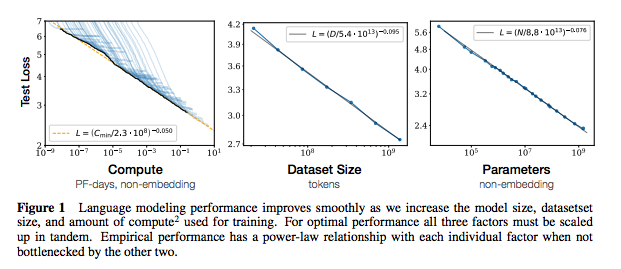
メモの各セットには、ペーパーへのリンク、元のコード実装(利用可能な場合)、およびハギングフェイスが含まれていますか?実装。
ここにいくつかの例があります---> t5、byt5、deduping Transformer Trainingセット。
このレポは、変圧器の論文間の違いを定量化するテーブルも含まれていますすべて1つのテーブルに。
変圧器の論文は、以下でやや時系列に示されています。 「:point_right:notes:point_left: "以下の列に移動して、各論文のメモを見つけます。
これは、NLPの深い学習の紹介ではありません。あなたがそれを探しているなら、私は次のいずれかをお勧めします:高速AIのコース、Courseraコースの1つ、またはこの古いもの。その後ここに来てください。
過去数年間、すべてのものに関するすべてのものに関する論文の爆発により、各論文の顕著な特徴/結果/洞察を消化可能な形式でカタログ化することが有用であると思われます。したがって、このリポジトリ。
| モデル | 年 | 研究所 | 紙 | メモ? | 元のコード | ハギングフェイス? | その他のレポ |
|---|---|---|---|---|---|---|---|
| トランス | 2017年 | グーグル | 注意が必要です | スキップされた、あまりにも多くの良い記事:
| ? | ||
| GPT-3 | 2018年 | Openai | 言語モデルは、教師のないマルチタスク学習者です | やる | x | x | |
| GPT-J-6B | 2021 | エレウターライ | GPT-J-6B:6B JAXベースのトランス( Public GPT-3 ) | x | ここ | x | x |
| バート | 2018年 | グーグル | BERT:言語理解のための深い双方向変圧器の事前訓練 | バートノート | ここ | ここ | |
| Distilbert | 2019年 | ハギングフェイス | Distilbert、Bertの蒸留バージョン:より小さく、より速く、安く、軽い | Distilbertノート | ここ | ||
| アルバート | 2019年 | グーグル/トヨタ | アルバート:言語表現の自己監督の学習のためのライトバート | アルバートノート | ここ | ここ | |
| ロベルタ | 2019年 | Roberta:堅牢に最適化されたBert Pretrainingアプローチ | ロベルタはメモ | ここ | ここ | ||
| バート | 2019年 | BART:自然言語の生成、翻訳、および理解のためのシーケンスからシーケンス前訓練 | バートノート | ここ | ここ | ||
| T5 | 2019年 | グーグル | 統一されたテキストツーテキスト変圧器で転送学習の限界を探る | T5ノート | ここ | ここ | |
| アダプターバート | 2019年 | グーグル | NLPのパラメーター効率の高い転送学習 | Adapter-Bertノート | ここ | - | ここ |
| Megatron-LM | 2019年 | nvidia | Megatron-LM:モデル並列性を使用した数十億パラメーター言語モデルのトレーニング | メガトロンのメモ | ここ | - | ここ |
| 改革者 | 2020 | グーグル | 改革者:効率的な変圧器 | 改革者ノート | ここ | ||
| BYT5 | 2021 | グーグル | BYT5:事前に訓練されたバイトからバイトモデルを備えたトークンフリーの未来に向けて | BYT5ノート | ここ | ここ | |
| クリップ | 2021 | Openai | 自然言語監督からの移転可能な視覚モデルの学習 | クリップノート | ここ | ここ | |
| Dall-E | 2021 | Openai | ゼロショットテキストから画像の生成 | Dall-Eノート | ここ | - | |
| コーデックス | 2021 | Openai | コードでトレーニングされた大きな言語モデルの評価 | コーデックスノート | x | - |
見つかったテーブルの要約はすべて、ここで1つの本当に大きなテーブルに崩壊しました。
| 紙 | 年 | 研究所 | メモ? | コード |
|---|---|---|---|---|
| テキスト変圧器に対するグラデーションベースの敵対攻撃 | 2021 | グラデーションベースの攻撃ノート | なし |
| 紙 | 年 | 研究所 | メモ? | コード |
|---|---|---|---|---|
| 事前に訓練された言語モデルの微調整のための監視されたコントラスト学習 | 2021 | SCLノート | なし |
| 紙 | 年 | 研究所 | メモ? | コード |
|---|---|---|---|---|
| 人間の好みからの微調整言語モデル | 2019年 | Openai | 人間のプリフェートノート | なし |
| 紙 | 年 | 研究所 | メモ? | コード |
|---|---|---|---|---|
| 神経言語モデルのスケーリング法則 | 2020 | Openai | スケーリング法ノート | なし |
| 紙 | 年 | 研究所 | メモ? | コード |
|---|---|---|---|---|
| 大規模な言語モデルからトレーニングデータを抽出します | 2021 | Google et al。 | やる | なし |
| トレーニングデータを強化すると、言語モデルが改善されます | 2021 | Google et al。 | Dedupノート | なし |
| 紙 | 年 | 研究所 | メモ? | コード |
|---|---|---|---|---|
| NLPでの限られたデータ学習のためのデータ増強の経験的調査 | 2021 | git/unc | やる | なし |
| ラベルの付いた例が少ない学習 | 2021 | Kevin Murphy&Colin Raffel(Preprint:「確率的機械学習」、第19章) | 読む価値は、ここで要約しません。 | なし |
このリポジトリに貢献することに興味がある場合は、次のことをお気軽にお問い合わせください。
間違いなく、ここで間違っている情報があります。問題を開いて、それを指摘してください。
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}上記のメモについては、元の論文をリンクしました。
mit


