tldr transformers
1.0.0
The "tl;dr" on a few notable papers on Transformers and modern NLP.
This is a living repo to keep tabs on different research threads.
Last Updated: September 20th, 2021.
Models: GPT- *, * BERT *, Adapter- *, * T5, Megatron, DALL-E, Codex, etc.
Topics: Transformer architectures + training; adversarial attacks; scaling laws; alignment; memorization; few labels; causality.
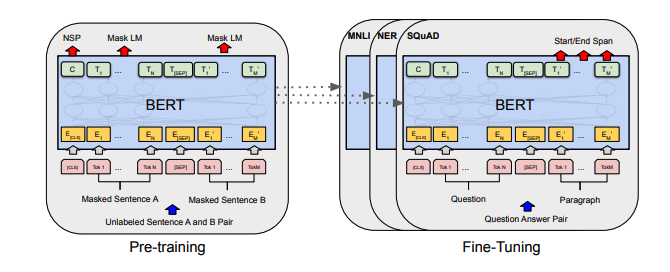
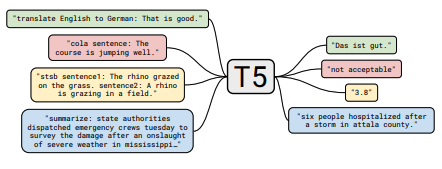
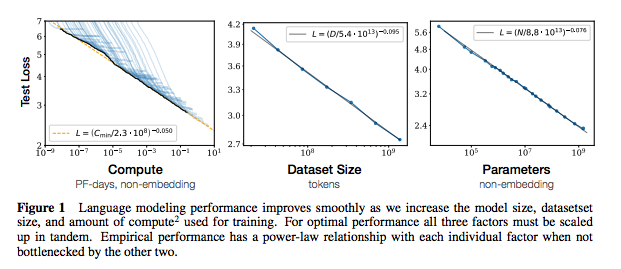
Each set of notes includes links to the paper, the original code implementation (if available) and the Huggingface ? implementation.
Here are some examples ---> t5, byt5, deduping transformer training sets.
This repo also includes a table quantifying the differences across transformer papers all in one table.
The transformers papers are presented somewhat chronologically below. Go to the ":point_right: Notes :point_left:" column below to find the notes for each paper.
This is not an intro to deep learning in NLP. If you are looking for that, I recommend one of the following: Fast AI's course, one of the Coursera courses, or maybe this old thing. Come here after that.
With the explosion in papers on all things Transformers the past few years, it seems useful to catalog the salient features/results/insights of each paper in a digestible format. Hence this repo.
| Model | Year | Institute | Paper | Notes ? | Original Code | Huggingface ? | Other Repo |
|---|---|---|---|---|---|---|---|
| Transformer | 2017 | Attention is All You Need | Skipped, too many good write-ups:
|
? | |||
| GPT-3 | 2018 | OpenAI | Language Models are Unsupervised Multitask Learners | To-Do | X | X | |
| GPT-J-6B | 2021 | EleutherAI | GPT-J-6B: 6B Jax-Based Transformer (public GPT-3) | X | here | x | x |
| BERT | 2018 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | BERT notes | here | here | ||
| DistilBERT | 2019 | Huggingface | DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter | DistilBERT notes | here | ||
| ALBERT | 2019 | Google/Toyota | ALBERT: A Lite BERT for Self-supervised Learning of Language Representations | ALBERT notes | here | here | |
| RoBERTa | 2019 | RoBERTa: A Robustly Optimized BERT Pretraining Approach | RoBERTa notes | here | here | ||
| BART | 2019 | BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension | BART notes | here | here | ||
| T5 | 2019 | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer | T5 notes | here | here | ||
| Adapter-BERT | 2019 | Parameter-Efficient Transfer Learning for NLP | Adapter-BERT notes | here | - | here | |
| Megatron-LM | 2019 | NVIDIA | Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism | Megatron notes | here | - | here |
| Reformer | 2020 | Reformer: The Efficient Transformer | Reformer notes | here | |||
| byT5 | 2021 | ByT5: Towards a token-free future with pre-trained byte-to-byte models | ByT5 notes | here | here | ||
| CLIP | 2021 | OpenAI | Learning Transferable Visual Models From Natural Language Supervision | CLIP notes | here | here | |
| DALL-E | 2021 | OpenAI | Zero-Shot Text-to-Image Generation | DALL-E notes | here | - | |
| Codex | 2021 | OpenAI | Evaluating Large Language Models Trained on Code | Codex notes | X | - |
All of the table summaries found ^ collapsed into one really big table here.
| Paper | Year | Institute | Notes ? | Codes |
|---|---|---|---|---|
| Gradient-based Adversarial Attacks against Text Transformers | 2021 | Gradient-based attack notes | None |
| Paper | Year | Institute | Notes ? | Codes |
|---|---|---|---|---|
| Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning | 2021 | SCL notes | None |
| Paper | Year | Institute | Notes ? | Codes |
|---|---|---|---|---|
| Fine-Tuning Language Models from Human Preferences | 2019 | OpenAI | Human pref notes | None |
| Paper | Year | Institute | Notes ? | Codes |
|---|---|---|---|---|
| Scaling Laws for Neural Language Models | 2020 | OpenAI | Scaling laws notes | None |
| Paper | Year | Institute | Notes ? | Codes |
|---|---|---|---|---|
| Extracting Training Data from Large Language Models | 2021 | Google et al. | To-Do | None |
| Deduplicating Training Data Makes Language Models Better | 2021 | Google et al. | Dedup notes | None |
| Paper | Year | Institute | Notes ? | Codes |
|---|---|---|---|---|
| An Empirical Survey of Data Augmentation for Limited Data Learning in NLP | 2021 | GIT/UNC | To-Do | None |
| Learning with fewer labeled examples | 2021 | Kevin Murphy & Colin Raffel (Preprint: "Probabilistic Machine Learning", Chapter 19) | Worth a read, won't summarize here. | None |
If you are interested in contributing to this repo, feel free to do the following:
Undoubtedly there is information that is incorrect here. Please open an Issue and point it out.
@misc{cliff-notes-transformers,
author = {Thompson, Will},
url = {https://github.com/will-thompson-k/cliff-notes-transformers},
year = {2021}
}For the notes above, I've linked the original papers.
MIT


