tldr transformers
1.0.0
O "tl; dr" em alguns papéis notáveis sobre transformadores e PN moderna.
Este é um vivendo repo para acompanhar os diferentes tópicos de pesquisa.
Última atualização : 20 de setembro de 2021.
Modelos : Gpt- *, *bert *, adaptador- *, *t5, megatron, dall-e, codex, etc.
Tópicos : Arquiteturas de Transformer + Treinamento; ataques adversários; leis de escala; alinhamento; memorização; poucos rótulos; causalidade.
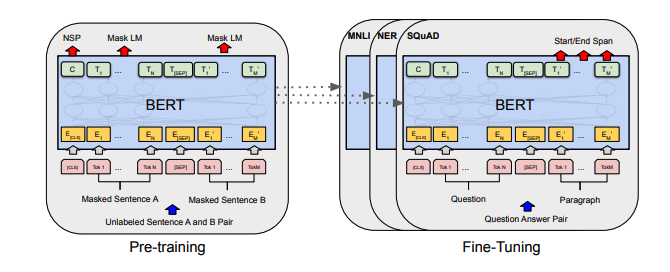
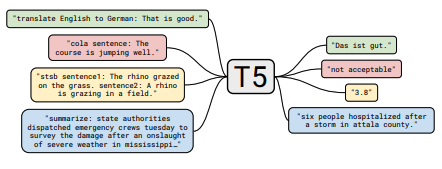
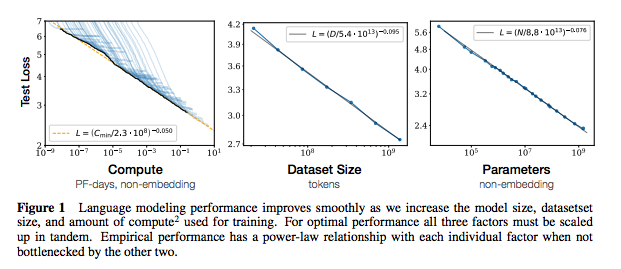
Cada conjunto de notas inclui links para o artigo, a implementação de código original (se disponível) e o HuggingFace? implementação.
Aqui estão alguns exemplos ---> t5, byt5, deduzindo conjuntos de treinamento de transformadores.
Este repo também inclui uma tabela quantificando as diferenças entre os papéis do transformador tudo em uma mesa .
Os documentos dos transformadores são apresentados um tanto cronologicamente abaixo. Vá para o ": Point_right: Notes: Point_Left:" Coluna abaixo para encontrar as notas para cada artigo.
Esta não é uma introdução ao aprendizado profundo na PNL. Se você está procurando por isso, recomendo um dos seguintes: Curso de Fast IA, um dos cursos da Coursera, ou talvez essa coisa antiga. Venha aqui depois disso.
Com a explosão nos artigos sobre todas as coisas dos transformadores nos últimos anos, parece útil catalogar os recursos/resultados/insights salientes de cada artigo em um formato digerível. Daí este repo.
| Modelo | Ano | Instituto | Papel | Notas? | Código original | Huggingface? | Outro repo |
|---|---|---|---|---|---|---|---|
| Transformador | 2017 | Atenção é tudo que você precisa | Saltado, muitos bons artigo:
| ? | |||
| GPT-3 | 2018 | Openai | Modelos de idiomas são aprendizes multitarefa sem supervisão | Pendência | X | X | |
| GPT-J-6B | 2021 | Eleutherai | GPT-J-6B: Transformador baseado em Jax 6B ( Public GPT-3 ) | X | aqui | x | x |
| Bert | 2018 | Bert: pré-treinamento de transformadores bidirecionais profundos para compreensão de idiomas | Notas de Bert | aqui | aqui | ||
| Distilbert | 2019 | Huggingface | Distilbert, uma versão destilada de Bert: menor, mais rápido, mais barato e mais leve | Notas Distilbert | aqui | ||
| Albert | 2019 | Google/Toyota | Albert: Um Lite Bert para o aprendizado auto-supervisionado de representações de idiomas | Notas de Albert | aqui | aqui | |
| Roberta | 2019 | Roberta: Uma abordagem de pré -treinamento de Bert robustamente otimizada | Roberta Notas | aqui | aqui | ||
| Bart | 2019 | BART: DenOising Sequence-Sensence Pré-treinamento para geração de linguagem natural, tradução e compreensão | Notas de Bart | aqui | aqui | ||
| T5 | 2019 | Explorando os limites do aprendizado de transferência com um transformador de texto em texto unificado | Notas T5 | aqui | aqui | ||
| Adaptador-Bert | 2019 | Learning de transferência com eficiência de parâmetro para PNL | Notas do adaptador-Bert | aqui | - | aqui | |
| Megatron-lm | 2019 | Nvidia | Megatron-LM: Treinando modelos de linguagem de parâmetros de bilhões de bilhões usando o paralelismo do modelo | Notas de Megatron | aqui | - | aqui |
| Reformador | 2020 | Reformer: o transformador eficiente | Notas do reformador | aqui | |||
| byt5 | 2021 | BYT5: em direção a um futuro sem token com modelos de byte a byte pré-treinados | Byt5 Notas | aqui | aqui | ||
| GRAMPO | 2021 | Openai | Aprendendo modelos visuais transferíveis da supervisão da linguagem natural | Notas de clipe | aqui | aqui | |
| Dall-e | 2021 | Openai | Geração de texto para imagem zero | Notas Dall-E | aqui | - | |
| Códice | 2021 | Openai | Avaliando grandes modelos de linguagem treinados no código | Notas Codex | X | - |
Todos os resumos da tabela encontrados em uma mesa realmente grande aqui.
| Papel | Ano | Instituto | Notas? | Códigos |
|---|---|---|---|---|
| Ataques adversários baseados em gradiente contra transformadores de texto | 2021 | Notas de ataque baseadas em gradiente | Nenhum |
| Papel | Ano | Instituto | Notas? | Códigos |
|---|---|---|---|---|
| Aprendizagem contrastiva supervisionada para modelo de linguagem pré-treinado | 2021 | Notas SCL | Nenhum |
| Papel | Ano | Instituto | Notas? | Códigos |
|---|---|---|---|---|
| Modelos de linguagem de ajuste fino de preferências humanas | 2019 | Openai | Notas pref humanas | Nenhum |
| Papel | Ano | Instituto | Notas? | Códigos |
|---|---|---|---|---|
| Escala de leis para modelos de idiomas neurais | 2020 | Openai | Notas das leis de escala | Nenhum |
| Papel | Ano | Instituto | Notas? | Códigos |
|---|---|---|---|---|
| Extraindo dados de treinamento de grandes modelos de linguagem | 2021 | Google et al. | Pendência | Nenhum |
| Dados de treinamento para desduplicar melhoram os modelos de idiomas | 2021 | Google et al. | Notas Dedup | Nenhum |
| Papel | Ano | Instituto | Notas? | Códigos |
|---|---|---|---|---|
| Uma pesquisa empírica de aumento de dados para aprendizado de dados limitados na PNL | 2021 | Git/UNC | Pendência | Nenhum |
| Aprendendo com menos exemplos rotulados | 2021 | Kevin Murphy e Colin Raffel (pré -impressão: "Aprendizado probabilístico de máquina", capítulo 19) | Vale a pena ler, não resumirá aqui. | Nenhum |
Se você estiver interessado em contribuir para este repositório, fique à vontade para fazer o seguinte:
Sem dúvida, há informações incorretas aqui. Por favor, abra um problema e aponte.
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}Para as notas acima, vinculei os papéis originais.
Mit


