tldr transformers
1.0.0
"TL ؛ DR" على بعض الأوراق البارزة على المحولات و NLP الحديثة.
هذا هو معيشة repo للحفاظ على علامات التبويب على مؤشرات ترابط البحث المختلفة.
آخر تحديث : 20 سبتمبر ، 2021.
النماذج : gpt- *، *bert *، adapter- *، *t5 ، megatron ، dall-e ، codex ، etc.
موضوعات : هيكل المحولات + التدريب ؛ هجمات الخصومة. قوانين التحجيم ؛ تنسيق؛ الحفظ بعض الملصقات السببية.
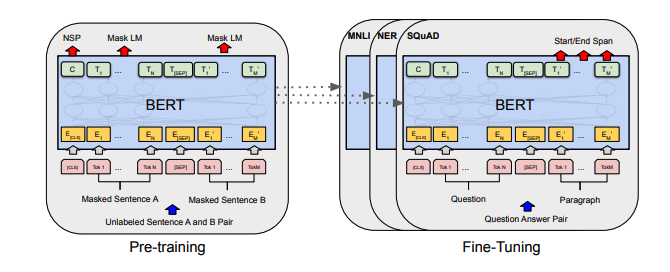
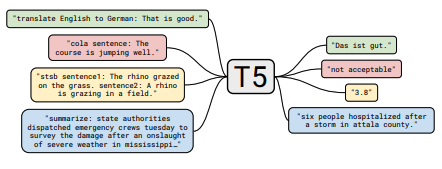
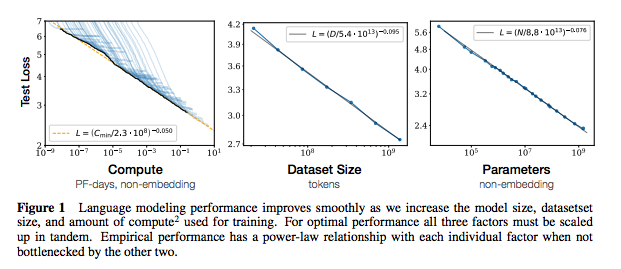
تتضمن كل مجموعة من الملاحظات روابط إلى الورقة ، وتطبيق الكود الأصلي (إن كان متاحًا) و uggingface؟ تطبيق.
فيما يلي بعض الأمثلة ---> T5 ، BYT5 ، مجموعات تدريب محولات DEDUPING.
يتضمن هذا الريبو أيضًا جدولًا يحدد الاختلافات عبر أوراق المحولات الكل في طاولة واحدة .
يتم تقديم أوراق Transformers إلى حد ما إلى حد ما أدناه. انتقل إلى ": point_right: ملاحظات: point_left:" العمود أدناه للعثور على الملاحظات لكل ورقة.
هذا ليس مقدمة للتعلم العميق في NLP. إذا كنت تبحث عن ذلك ، فإنني أوصي بواحدة مما يلي: دورة Fast AI ، أو إحدى دورات Coursera ، أو ربما هذا الشيء القديم. تعال إلى هنا بعد ذلك.
مع الانفجار في الأوراق على جميع الأشياء المحولات في السنوات القليلة الماضية ، يبدو من المفيد تصنيف الميزات/النتائج/الأفكار البارزة لكل ورقة بتنسيق قابل للهضم. وبالتالي هذا الريبو.
| نموذج | سنة | معهد | ورق | ملحوظات ؟ | الكود الأصلي | Luggingface؟ | ريبو آخر |
|---|---|---|---|---|---|---|---|
| محول | 2017 | جوجل | الانتباه هو كل ما تحتاجه | تخطي ، الكثير من عمليات الكتابة الجيدة:
| ؟ | ||
| GPT-3 | 2018 | Openai | نماذج اللغة متعلمين متعددة المهام غير خاضعة للإشراف | المهام | x | x | |
| GPT-J-6B | 2021 | إليوتراي | GPT-J-6B: 6B المستند إلى JAX Transformer ( GPT-3 ) | x | هنا | x | x |
| بيرت | 2018 | جوجل | بيرت: ما قبل التدريب من محولات ثنائية الاتجاه العميقة لفهم اللغة | ملاحظات بيرت | هنا | هنا | |
| Distilbert | 2019 | luggingface | Distilbert ، نسخة مقطرة من Bert: أصغر وأسرع وأرخص وأخف وزنا | ملاحظات Distilbert | هنا | ||
| ألبرت | 2019 | جوجل/تويوتا | ألبرت: لايت بيرت للتعلم الخاضع للرقابة لتمثيل اللغة | ألبرت ملاحظات | هنا | هنا | |
| روبرتا | 2019 | فيسبوك | روبرتا: نهج بيرت المحسن ببراعة | ملاحظات روبرتا | هنا | هنا | |
| بارت | 2019 | فيسبوك | بارت: تقليل التسلسل إلى التسلسل قبل التدريب لتوليد اللغة الطبيعية وترجمة والفهم | ملاحظات بارت | هنا | هنا | |
| T5 | 2019 | جوجل | استكشاف حدود التعلم النقل مع محول نص إلى نص موحد | ملاحظات T5 | هنا | هنا | |
| محول بيرت | 2019 | جوجل | التعلم النقل الفعال للمعلمة لـ NLP | ملاحظات المحول ببرت | هنا | - | هنا |
| Megatron-LM | 2019 | نفيديا | Megatron-LM: تدريب نماذج لغة المعلمة بمليارات المليارات باستخدام موازاة النموذج | ملاحظات ميجاترون | هنا | - | هنا |
| مصلح | 2020 | جوجل | المصلح: المحول الفعال | ملاحظات المصلح | هنا | ||
| BYT5 | 2021 | جوجل | BYT5: نحو مستقبل خالٍ من الرمز المميز مع نماذج بايت إلى بايت مدربة مسبقًا | ملاحظات BYT5 | هنا | هنا | |
| مقطع | 2021 | Openai | تعلم النماذج المرئية القابلة للتحويل من الإشراف على اللغة الطبيعية | مقطع ملاحظات | هنا | هنا | |
| دال | 2021 | Openai | صفر طلقة نص إلى صورة إلى صورة | يلاحظ دال | هنا | - | |
| المخطوطة | 2021 | Openai | تقييم نماذج اللغة الكبيرة المدربة على الكود | ملاحظات المخطوطة | x | - |
جميع ملخصات الجدول وجدت ^ انهارت في جدول واحد كبير حقا هنا.
| ورق | سنة | معهد | ملحوظات ؟ | الرموز |
|---|---|---|---|---|
| هجمات الخصومة القائمة على التدرج ضد محولات النص | 2021 | فيسبوك | ملاحظات الهجوم القائمة على التدرج | لا أحد |
| ورق | سنة | معهد | ملحوظات ؟ | الرموز |
|---|---|---|---|---|
| التعلم المتناقض الخاضع للإشراف لنموذج اللغة المسبق مسبقًا | 2021 | فيسبوك | ملاحظات SCL | لا أحد |
| ورق | سنة | معهد | ملحوظات ؟ | الرموز |
|---|---|---|---|---|
| نماذج لغة صقلها من التفضيلات البشرية | 2019 | Openai | الملاحظات الجاهزة البشرية | لا أحد |
| ورق | سنة | معهد | ملحوظات ؟ | الرموز |
|---|---|---|---|---|
| تحجيم قوانين نماذج اللغة العصبية | 2020 | Openai | ملاحظات قوانين التحجيم | لا أحد |
| ورق | سنة | معهد | ملحوظات ؟ | الرموز |
|---|---|---|---|---|
| استخراج بيانات التدريب من نماذج اللغة الكبيرة | 2021 | جوجل وآخرون. | المهام | لا أحد |
| بيانات التدريب المكررة تجعل نماذج اللغة أفضل | 2021 | جوجل وآخرون. | ملاحظات dedup | لا أحد |
| ورق | سنة | معهد | ملحوظات ؟ | الرموز |
|---|---|---|---|---|
| مسح تجريبي لزيادة البيانات لتعلم البيانات المحدود في NLP | 2021 | git/unc | المهام | لا أحد |
| التعلم مع عدد أقل من الأمثلة المسمى | 2021 | كيفن مورفي وكولين رافيل (preprint: "التعلم الآلي الاحتمالي" ، الفصل 19) | تستحق القراءة ، لن تلخص هنا. | لا أحد |
إذا كنت مهتمًا بالمساهمة في هذا الريبو ، فلا تتردد في القيام بما يلي:
مما لا شك فيه أن هناك معلومات غير صحيحة هنا. يرجى فتح مشكلة وإشرافها.
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}للملاحظات أعلاه ، قمت بربط الأوراق الأصلية.
معهد ماساتشوستس للتكنولوجيا


