tldr transformers
1.0.0
트랜스포머 및 현대 NLP에 대한 몇 가지 주목할만한 논문에 "TL; DR".
이것은 a입니다 생활 다른 연구 스레드에 탭을 유지하기위한 리포지토리.
마지막 업데이트 : 2021 년 9 월 20 일.
모델 : gpt- *, *bert *, 어댑터- *, *t5, megatron, dall-e, codex 등
주제 : 변압기 아키텍처 + 훈련; 대적 공격; 스케일링 법률; 조정; 암기; 몇 가지 라벨; 인과 관계.
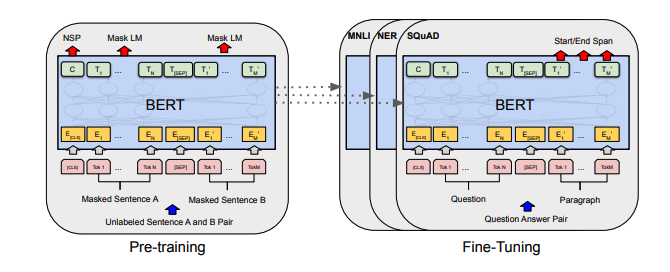
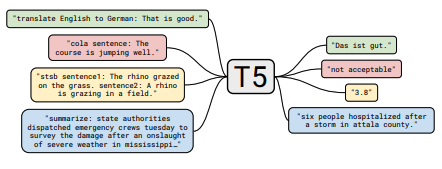
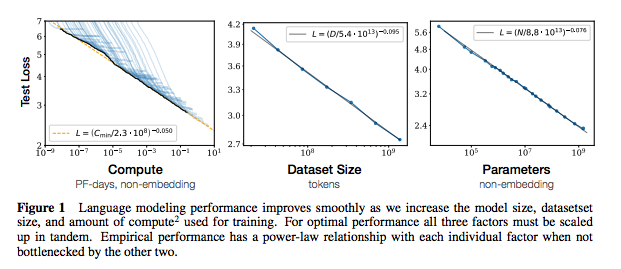
각 메모 세트에는 용지에 대한 링크, 원래 코드 구현 (사용 가능한 경우) 및 HuggingFace가 포함되어 있습니까? 구현.
다음은 몇 가지 예입니다 ---> T5, BYT5, 변압기 훈련 세트.
이 repo에는 변압기 종이의 차이점을 정량화하는 테이블도 포함됩니다. 모두 한 테이블에 .
Transformers Papers는 아래에서 약간 연대순으로 제시됩니다. ": point_right : notes : point_left :"아래 열로 이동하여 각 논문의 메모를 찾으십시오.
이것은 NLP의 딥 러닝에 대한 소개가 아닙니다 . 당신이 그것을 찾고 있다면, 나는 다음 중 하나를 추천합니다 : Fast AI의 코스, Coursera 코스 중 하나 또는 아마도이 오래된 것. 그 후 여기로 오세요.
지난 몇 년 동안 모든 트랜스포머에 대한 종이가 폭발적으로 이루어지면서 각 논문의 두드러진 기능/결과/통찰력을 소화 가능한 형식으로 카탈로그하는 것이 유용합니다. 따라서이 repo.
| 모델 | 년도 | 학회 | 종이 | 참고? | 원본 코드 | 포옹? | 다른 repo |
|---|---|---|---|---|---|---|---|
| 변신 로봇 | 2017 | 주의를 기울이기 만하면됩니다 | 건너 뛰기, 너무 많은 좋은 글쓰기 :
| ? | |||
| GPT-3 | 2018 | Openai | 언어 모델은 감독되지 않은 멀티 태스킹 학습자입니다 | 할 일 | 엑스 | 엑스 | |
| GPT-J-6B | 2021 | Eleutherai | GPT-J-6B : 6B JAX 기반 변압기 ( 공개 GPT-3 ) | 엑스 | 여기 | 엑스 | 엑스 |
| 버트 | 2018 | BERT : 언어 이해를위한 깊은 양방향 변압기의 사전 훈련 | 버트 노트 | 여기 | 여기 | ||
| Distilbert | 2019 | 포옹 페이스 | Distilbert, Bert의 증류 된 버전 : 작고, 빠르며, 저렴하며 가벼운 | Distilbert 노트 | 여기 | ||
| 앨버트 | 2019 | Google/Toyota | Albert : 언어 표현에 대한 자기 감독 학습을위한 라이트 버트 | 앨버트 노트 | 여기 | 여기 | |
| 로베르타 | 2019 | 페이스 북 | Roberta : 강력하게 최적화 된 Bert Pretraining 접근법 | 로베르타 노트 | 여기 | 여기 | |
| 바트 | 2019 | 페이스 북 | BART : 자연 언어 생성, 번역 및 이해를위한 시퀀스-시퀀스 사전 훈련 미용사 | 바트 노트 | 여기 | 여기 | |
| T5 | 2019 | 통합 된 텍스트-텍스트 변압기로 전송 학습의 한계 탐색 | T5 참고 | 여기 | 여기 | ||
| 어댑터 베트 | 2019 | NLP에 대한 매개 변수 효율적인 전송 학습 | 어댑터-베르트 노트 | 여기 | - | 여기 | |
| 메가 트론 LM | 2019 | nvidia | Megatron-LM : 모델 병렬 처리를 사용하여 수십억 개의 매개 변수 언어 모델을 교육합니다 | 메가 트론 노트 | 여기 | - | 여기 |
| 개혁가 | 2020 | 개혁자 : 효율적인 변압기 | 개혁자 노트 | 여기 | |||
| BYT5 | 2021 | BYT5 : 미리 훈련 된 바이트-바이트 모델을 갖춘 토큰이없는 미래를 향해 | byt5 참고 | 여기 | 여기 | ||
| 클립 | 2021 | Openai | 자연어 감독에서 전송 가능한 시각적 모델 학습 | 클립 노트 | 여기 | 여기 | |
| Dall-e | 2021 | Openai | 제로 샷 텍스트-이미지 생성 | 달 -E 노트 | 여기 | - | |
| 사본 | 2021 | Openai | 코드에서 훈련 된 대형 언어 모델 평가 | 코덱스 노트 | 엑스 | - |
모든 테이블 요약은 여기에서 정말 큰 테이블로 무너졌습니다.
| 종이 | 년도 | 학회 | 참고? | 코드 |
|---|---|---|---|---|
| 텍스트 변압기에 대한 그라디언트 기반 적대 공격 | 2021 | 페이스 북 | 그라디언트 기반 공격 노트 | 없음 |
| 종이 | 년도 | 학회 | 참고? | 코드 |
|---|---|---|---|---|
| 미리 훈련 된 언어 모델 미세 조정에 대한 대조 학습을 감독합니다 | 2021 | 페이스 북 | SCL 노트 | 없음 |
| 종이 | 년도 | 학회 | 참고? | 코드 |
|---|---|---|---|---|
| 인간의 선호에서 미세 조정 언어 모델 | 2019 | Openai | 인간의 pref 노트 | 없음 |
| 종이 | 년도 | 학회 | 참고? | 코드 |
|---|---|---|---|---|
| 신경 언어 모델의 스케일링 법률 | 2020 | Openai | 법률 노트 | 없음 |
| 종이 | 년도 | 학회 | 참고? | 코드 |
|---|---|---|---|---|
| 대형 언어 모델에서 교육 데이터 추출 | 2021 | Google et al. | 할 일 | 없음 |
| 중복 제거 교육 데이터는 언어 모델을 더 좋게 만듭니다 | 2021 | Google et al. | Dedup Notes | 없음 |
| 종이 | 년도 | 학회 | 참고? | 코드 |
|---|---|---|---|---|
| NLP의 제한된 데이터 학습을위한 데이터 확대에 대한 경험적 조사 | 2021 | git/unc | 할 일 | 없음 |
| 더 적은 레이블이 붙은 예제로 학습 | 2021 | Kevin Murphy & Colin Raffel (Preprint : "확률 론적 기계 학습", 19 장) | 읽을 가치가 있습니다. 여기서 요약하지 마십시오. | 없음 |
이 저장소에 기여하는 데 관심이 있으시면 다음을 수행하십시오.
의심 할 여지없이 여기에는 잘못된 정보가 있습니다. 문제를 열고 지적하십시오.
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}위의 메모의 경우 원래 논문을 연결했습니다.
MIT


