tldr transformers
1.0.0
"tl; dr" บนเอกสารที่โดดเด่นสองสามฉบับเกี่ยวกับหม้อแปลงและ NLP ที่ทันสมัย
นี่คือ การดำรงชีวิต repo เพื่อเก็บแท็บในหัวข้อการวิจัยที่แตกต่างกัน
อัปเดตล่าสุด : 20 กันยายน 2021
แบบจำลอง : gpt- *, *bert *, adapter- *, *t5, megatron, dall-e, codex ฯลฯ
หัวข้อ : สถาปัตยกรรมหม้อแปลง + การฝึกอบรม; การโจมตีของฝ่ายตรงข้าม กฎหมายการปรับขนาด; การจัดตำแหน่ง; การท่องจำ; ฉลากเพียงไม่กี่ป้าย เวรกรรม
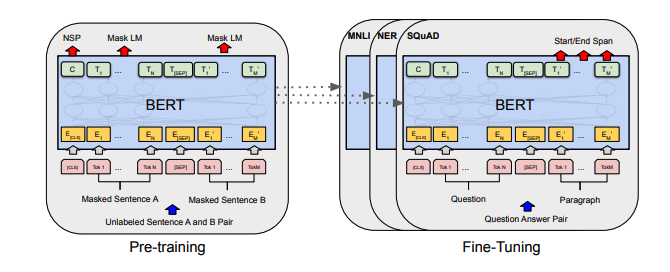
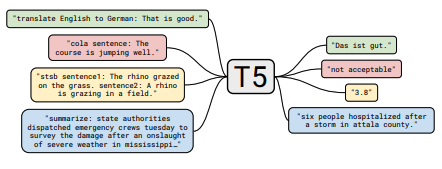
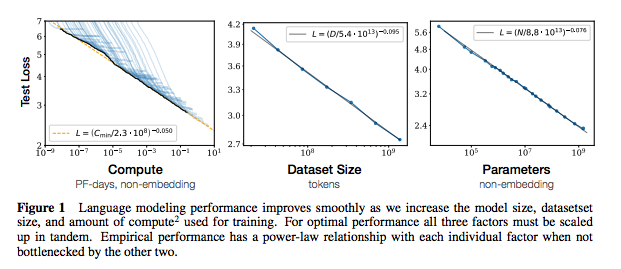
แต่ละชุดของโน้ตรวมลิงก์ไปยังกระดาษการใช้งานรหัสต้นฉบับ (ถ้ามี) และ HuggingFace? การดำเนินการ
นี่คือตัวอย่างบางส่วน ---> T5, BYT5, ชุดฝึกอบรมหม้อแปลง
repo นี้ยังรวมถึงตารางที่วัดความแตกต่างระหว่างเอกสารหม้อแปลง ทั้งหมดในตารางเดียว -
เอกสาร Transformers จะถูกนำเสนอค่อนข้างตามลำดับเวลาด้านล่าง ไปที่คอลัมน์ ": Point_right: หมายเหตุ: Point_left:" คอลัมน์ด้านล่างเพื่อค้นหาบันทึกย่อสำหรับแต่ละกระดาษ
นี่ ไม่ใช่ บทนำในการเรียนรู้อย่างลึกซึ้งใน NLP หากคุณกำลังมองหาสิ่งนั้นฉันขอแนะนำหนึ่งในสิ่งต่อไปนี้: หลักสูตรของ AI Fast AI หนึ่งในหลักสูตร Coursera หรืออาจเป็นเรื่องเก่า มาที่นี่หลังจากนั้น
ด้วยการระเบิดในเอกสารเกี่ยวกับทุกสิ่งที่ทำให้เกิดการแปลงสภาพในช่วงไม่กี่ปีที่ผ่านมาดูเหมือนว่าจะมีประโยชน์ในการจัดทำแคตตาล็อกคุณสมบัติ/ผลลัพธ์/ข้อมูลเชิงลึกของกระดาษแต่ละชิ้นในรูปแบบที่ย่อยได้ ดังนั้น repo นี้
| แบบอย่าง | ปี | สถาบัน | กระดาษ | หมายเหตุ? | รหัสต้นฉบับ | Huggingface? | repo อื่น ๆ |
|---|---|---|---|---|---|---|---|
| หม้อแปลงไฟฟ้า | 2017 | ความสนใจคือสิ่งที่คุณต้องการ | ข้ามการเขียนที่ดีมากเกินไป:
| - | |||
| GPT-3 | 2018 | Openai | แบบจำลองภาษาเป็นผู้เรียนมัลติทาสก์ที่ไม่ได้รับการดูแล | สิ่งที่ต้องทำ | x | x | |
| GPT-J-6B | 2021 | เอเลเฮอร์ | GPT-J-6B: Transformer ที่ใช้ JAX 6B ( Public GPT-3 ) | x | ที่นี่ | x | x |
| เบิร์ต | 2018 | เบิร์ต: การฝึกอบรมหม้อแปลงสองทิศทางลึกเพื่อความเข้าใจภาษา | Bert Notes | ที่นี่ | ที่นี่ | ||
| กลั่นกรอง | 2019 | กอด | Distilbert, Bert รุ่นกลั่น: เล็ก, เร็วขึ้น, ราคาถูกและเบาลง | Distilbert Notes | ที่นี่ | ||
| อัลเบิร์ต | 2019 | Google/Toyota | อัลเบิร์ต: Lite Bert สำหรับการเรียนรู้ด้วยตนเองของการเป็นตัวแทนภาษา | Albert Notes | ที่นี่ | ที่นี่ | |
| โรเบอร์ต้า | 2019 | Roberta: วิธีการฝึกอบรมเบิร์ตที่ได้รับการปรับปรุงให้ดีที่สุด | Roberta Notes | ที่นี่ | ที่นี่ | ||
| บาร์ต | 2019 | Bart: denoising sequence to-sequence pre-training สำหรับการสร้างภาษาธรรมชาติการแปลและความเข้าใจ | บาร์ตโน้ต | ที่นี่ | ที่นี่ | ||
| T5 | 2019 | การสำรวจขีด จำกัด ของการเรียนรู้การถ่ายโอนด้วยหม้อแปลงข้อความเป็นแบบรวมเป็นข้อความ | T5 Notes | ที่นี่ | ที่นี่ | ||
| อะแดปเตอร์เบิร์ต | 2019 | การเรียนรู้การถ่ายโอนพารามิเตอร์สำหรับ NLP | Adapter-Bert Notes | ที่นี่ | - | ที่นี่ | |
| megatron-lm | 2019 | Nvidia | Megatron-LM: การฝึกอบรมแบบจำลองภาษาพารามิเตอร์หลายพันล้านแบบใช้แบบจำลองแบบขนานโมเดล | บันทึก Megatron | ที่นี่ | - | ที่นี่ |
| ผู้ปฏิรูป | 2020 | นักปฏิรูป: หม้อแปลงที่มีประสิทธิภาพ | หมายเหตุนักปฏิรูป | ที่นี่ | |||
| BYT5 | 2021 | BYT5: ไปสู่อนาคตที่ปราศจากโทเค็นด้วยรุ่นไบต์ไปยังไบต์ที่ผ่านการฝึกอบรมมาก่อน | Byt5 Notes | ที่นี่ | ที่นี่ | ||
| คลิป | 2021 | Openai | การเรียนรู้แบบจำลองภาพที่ถ่ายโอนได้จากการกำกับดูแลภาษาธรรมชาติ | คลิปโน้ต | ที่นี่ | ที่นี่ | |
| Dall-e | 2021 | Openai | การสร้างข้อความเป็นแบบไม่ถ่ายภาพเป็นภาพ | Dall-e Notes | ที่นี่ | - | |
| codex | 2021 | Openai | การประเมินแบบจำลองภาษาขนาดใหญ่ที่ผ่านการฝึกอบรมเกี่ยวกับรหัส | Codex Notes | x | - |
บทสรุปทั้งหมดของตารางพบว่า ^ ทรุดตัวลงเป็นตารางที่ใหญ่จริงๆที่นี่
| กระดาษ | ปี | สถาบัน | หมายเหตุ? | รหัส |
|---|---|---|---|---|
| การโจมตีที่เป็นปฏิปักษ์ต่อการไล่ระดับสี | 2021 | บันทึกการโจมตีแบบไล่ระดับสี | ไม่มี |
| กระดาษ | ปี | สถาบัน | หมายเหตุ? | รหัส |
|---|---|---|---|---|
| การเรียนรู้แบบตัดกันภายใต้การดูแลสำหรับการปรับแต่งรูปแบบภาษาที่ผ่านการฝึกอบรมมาก่อน | 2021 | SCL Notes | ไม่มี |
| กระดาษ | ปี | สถาบัน | หมายเหตุ? | รหัส |
|---|---|---|---|---|
| แบบจำลองภาษาที่ปรับแต่งจากการตั้งค่าของมนุษย์ | 2019 | Openai | บันทึกย่อของมนุษย์ | ไม่มี |
| กระดาษ | ปี | สถาบัน | หมายเหตุ? | รหัส |
|---|---|---|---|---|
| การปรับขนาดกฎหมายสำหรับแบบจำลองภาษาประสาท | 2020 | Openai | หมายเหตุกฎหมายการปรับขนาด | ไม่มี |
| กระดาษ | ปี | สถาบัน | หมายเหตุ? | รหัส |
|---|---|---|---|---|
| การแยกข้อมูลการฝึกอบรมจากแบบจำลองภาษาขนาดใหญ่ | 2021 | Google และคณะ | สิ่งที่ต้องทำ | ไม่มี |
| ข้อมูลการฝึกอบรมซ้ำ ๆ ทำให้แบบจำลองภาษาดีขึ้น | 2021 | Google และคณะ | บันทึกย่อ | ไม่มี |
| กระดาษ | ปี | สถาบัน | หมายเหตุ? | รหัส |
|---|---|---|---|---|
| การสำรวจเชิงประจักษ์ของการเพิ่มข้อมูลสำหรับการเรียนรู้ข้อมูลที่ จำกัด ใน NLP | 2021 | git/unc | สิ่งที่ต้องทำ | ไม่มี |
| การเรียนรู้ด้วยตัวอย่างที่มีป้ายกำกับน้อยลง | 2021 | Kevin Murphy & Colin Raffel (preprint: "การเรียนรู้ของเครื่องน่าจะเป็น", บทที่ 19) | คุ้มค่ากับการอ่านจะไม่สรุปที่นี่ | ไม่มี |
หากคุณสนใจที่จะสนับสนุน repo นี้อย่าลังเลที่จะทำสิ่งต่อไปนี้:
ไม่ต้องสงสัยเลยว่ามีข้อมูลที่ไม่ถูกต้องที่นี่ กรุณาเปิดปัญหาและชี้ให้เห็น
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}สำหรับบันทึกด้านบนฉันได้เชื่อมโยงเอกสารต้นฉบับ
มิกซ์


