tldr transformers
1.0.0
«TL; DR» на нескольких известных документах о трансформаторах и современном НЛП.
Это жизнь Репо, чтобы сохранить вкладки в различных исследовательских темах.
Последнее обновление : 20 сентября 2021 года.
Модели : Gpt- *, *Bert *, Adapter- *, *T5, Megatron, Dall-e, Codex и т. Д.
Темы : Трансформерные архитектуры + обучение; состязательные атаки; Масштабирование законов; выравнивание; запоминание; Несколько ярлыков; причинность.
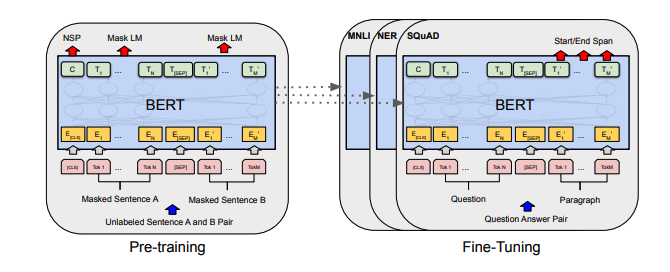
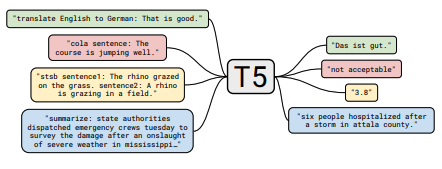
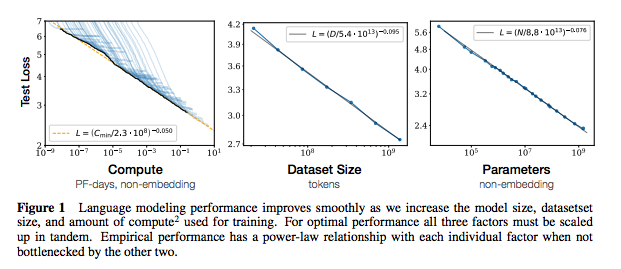
Каждый набор заметок включает в себя ссылки на статью, оригинальную реализацию кода (если доступно) и Huggingface? выполнение.
Вот несколько примеров ---> T5, Byt5, Depuping Transformer Trainer Set.
Этот репо также включает в себя таблицу, определяющую различия между документами трансформаторов Все в одной таблице Полем
Документы трансформаторов представлены несколько хронологически ниже. Перейдите в «: point_right: Примечания: point_left:» в столбце ниже, чтобы найти примечания для каждой статьи.
Это не вступление в глубокое обучение в НЛП. Если вы ищете это, я рекомендую один из следующих: быстрый курс AI, один из курсов Coursera, или, может быть, эта старая вещь. Приходите сюда после этого.
В результате взрыва в документах о трансформаторах всех вещей в последние несколько лет, кажется, полезно каталогизировать различные особенности/результаты/идеи каждой статьи в усвояемом формате. Отсюда этот репо.
| Модель | Год | Институт | Бумага | Примечания ? | Исходный код | Объятие? | Другое репо |
|---|---|---|---|---|---|---|---|
| Трансформатор | 2017 | Внимание - это все, что вам нужно | Пропущен, слишком много хороших рецензий:
| ? | |||
| GPT-3 | 2018 | Openai | Языковые модели - это неконтролируемые многозадачные ученики | Дел | Х | Х | |
| GPT-J-6B | 2021 | Eleutherai | GPT-J-6B: 6B Transformer на основе JAX ( Public GPT-3 ) | Х | здесь | х | х |
| БЕРТ | 2018 | Берт: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка | Берт Примечания | здесь | здесь | ||
| Дистильберт | 2019 | Объятие | Дистилберт, дистиллированная версия Bert: меньше, быстрее, дешевле и легче | Примечания Дистильберта | здесь | ||
| Альберт | 2019 | Google/Toyota | Альберт: Lite Bert для самоотверженного изучения языковых представлений | Альберт отмечает | здесь | здесь | |
| Роберта | 2019 | Роберта: надежно оптимизированный берт -подход | Роберта отмечает | здесь | здесь | ||
| БАРТ | 2019 | BART: дженочная последовательность к последовательности предварительной тренировки для генерации, перевода и понимания естественного языка | БАРТ ПРИМЕЧАНИЯ | здесь | здесь | ||
| T5 | 2019 | Изучение пределов обучения передачи с помощью унифицированного трансформатора текста в текст | T5 Примечания | здесь | здесь | ||
| Адаптер-Берт | 2019 | Параметр эффективного переноса обучения для NLP | Адаптер-Берт Примечания | здесь | - | здесь | |
| Мегатрон-лм | 2019 | Нвидия | Megatron-LM: обучение многомиллиардных моделей языков параметров с использованием модели параллелизма | Мегатрон отмечает | здесь | - | здесь |
| Реформатор | 2020 | Реформатор: эффективный трансформатор | Реформаторные примечания | здесь | |||
| байт5 | 2021 | BYT5: к будущему без токенов с предварительно обученными байтовыми моделями | BYT5 Примечания | здесь | здесь | ||
| Клип | 2021 | Openai | Передаваемые визуальные модели обучения от надзора естественного языка | Записывание | здесь | здесь | |
| Далл-э | 2021 | Openai | Ноль выстрела текста до изображения | Dall-e Примечания | здесь | - | |
| Кодекс | 2021 | Openai | Оценка крупных языковых моделей, обученных коду | Кодекс Примечания | Х | - |
Все резюме таблицы, найденные, сложены здесь на один действительно большой стол.
| Бумага | Год | Институт | Примечания ? | Коды |
|---|---|---|---|---|
| Атаки на основе градиента против текстовых трансформаторов | 2021 | Градиентные примечания атаки | Никто |
| Бумага | Год | Институт | Примечания ? | Коды |
|---|---|---|---|---|
| Контрольное контрастное обучение для предварительно обученной языковой модели тонкая настройка | 2021 | SCL Примечания | Никто |
| Бумага | Год | Институт | Примечания ? | Коды |
|---|---|---|---|---|
| Чико настраивающие языковые модели от человеческих предпочтений | 2019 | Openai | Человеческие примечания | Никто |
| Бумага | Год | Институт | Примечания ? | Коды |
|---|---|---|---|---|
| Масштабирование законов для моделей нейронного языка | 2020 | Openai | Законы масштабирования примечания | Никто |
| Бумага | Год | Институт | Примечания ? | Коды |
|---|---|---|---|---|
| Извлечение данных обучения из моделей крупных языков | 2021 | Google et al. | Дел | Никто |
| Дедупликация обучающих данных делает языковые модели лучше | 2021 | Google et al. | Примечания | Никто |
| Бумага | Год | Институт | Примечания ? | Коды |
|---|---|---|---|---|
| Эмпирическое обследование увеличения данных для ограниченного обучения данных в НЛП | 2021 | Git/unc | Дел | Никто |
| Обучение с меньшим количеством маркированных примеров | 2021 | Кевин Мерфи и Колин Раффел (Препринт: «Вероятностное машинное обучение», глава 19) | Стоит прочитать, не суммируйте здесь. | Никто |
Если вы заинтересованы в участии в этом репо, не стесняйтесь делать следующее:
Несомненно, здесь есть информация, которая неверна. Пожалуйста, откройте проблему и укажите ее.
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}Для примечаний выше я связал оригинальные бумаги.
Грань


