tldr transformers
1.0.0
"TL; DR" pada beberapa makalah penting tentang Transformers dan NLP modern.
Ini adalah hidup Repo untuk mengawasi berbagai utas penelitian.
Terakhir Diperbarui : 20 September 2021.
Model : Gpt- *, *Bert *, adaptor- *, *t5, megatron, dall-e, codex, dll.
Topik : Transformer Architectures + Training; serangan musuh; hukum penskalaan; penyelarasan; menghafal; beberapa label; hubungan sebab dan akibat.
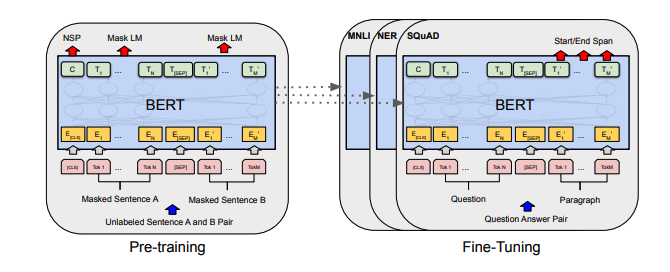
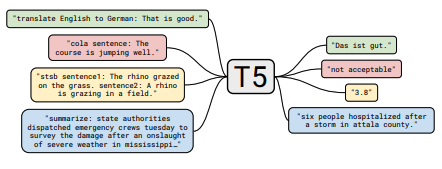
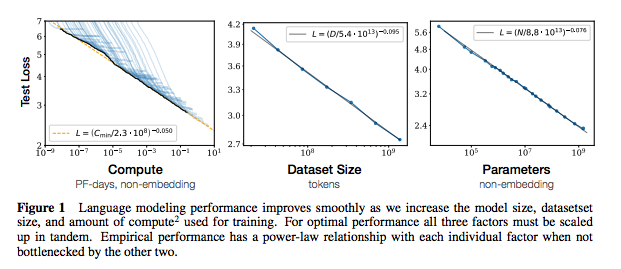
Setiap set catatan termasuk tautan ke kertas, implementasi kode asli (jika tersedia) dan huggingface? pelaksanaan.
Berikut adalah beberapa contoh ---> T5, byt5, set pelatihan transformator deduping.
Repo ini juga mencakup tabel yang mengukur perbedaan di seluruh kertas transformator Semua dalam satu meja .
Makalah Transformers disajikan secara kronologis di bawah ini. Buka kolom ": point_right: Catatan: point_left:" di bawah ini untuk menemukan catatan untuk setiap kertas.
Ini bukan intro untuk pembelajaran yang mendalam di NLP. Jika Anda mencari itu, saya merekomendasikan salah satu dari yang berikut: Kursus AI FAST, salah satu kursus Coursera, atau mungkin hal tua ini. Kemarilah setelah itu.
Dengan ledakan dalam makalah pada semua hal transformator beberapa tahun terakhir, tampaknya berguna untuk membuat katalog fitur/hasil/wawasan yang menonjol dari setiap kertas dalam format yang dapat dicerna. Karenanya repo ini.
| Model | Tahun | Lembaga | Kertas | Catatan? | Kode asli | Huggingface? | Repo lainnya |
|---|---|---|---|---|---|---|---|
| Transformator | 2017 | Perhatian adalah semua yang Anda butuhkan | Dilewati, terlalu banyak tulisan yang bagus:
| ? | |||
| GPT-3 | 2018 | Openai | Model bahasa adalah pelajar multitask tanpa pengawasan | Harus melakukan | X | X | |
| GPT-J-6B | 2021 | Eleutherai | GPT-J-6B: Transformator Berbasis Jax 6B ( GPT-3 Publik ) | X | Di Sini | X | X |
| Bert | 2018 | Bert: Pra-pelatihan transformator dua arah yang dalam untuk pemahaman bahasa | BERT BERT | Di Sini | Di Sini | ||
| Distilbert | 2019 | Huggingface | Distilbert, versi suling Bert: lebih kecil, lebih cepat, lebih murah dan lebih ringan | Catatan Distilbert | Di Sini | ||
| Albert | 2019 | Google/Toyota | Albert: Lite Bert untuk pembelajaran representasi bahasa sendiri | Catatan Albert | Di Sini | Di Sini | |
| Roberta | 2019 | Roberta: pendekatan pretraining Bert yang dioptimalkan dengan kuat | Roberta Notes | Di Sini | Di Sini | ||
| Bart | 2019 | Bart: Denoising Sequence-to-Sequence Pra-Pelatihan untuk Generasi Bahasa Alami, Terjemahan, dan Pemahaman | Catatan bart | Di Sini | Di Sini | ||
| T5 | 2019 | Menjelajahi Batas Pembelajaran Transfer dengan Transformator Teks ke Teks Terpadu | Catatan T5 | Di Sini | Di Sini | ||
| Adaptor-Bert | 2019 | Pembelajaran transfer yang efisien parameter untuk NLP | Catatan Adaptor-Bert | Di Sini | - | Di Sini | |
| Megatron-LM | 2019 | Nvidia | Megatron-LM: Pelatihan Model Bahasa Multi-Miliar Parameter Menggunakan Model Parallelism | Catatan Megatron | Di Sini | - | Di Sini |
| Pembaru | 2020 | Reformator: Transformator yang efisien | Catatan Reformer | Di Sini | |||
| byt5 | 2021 | BYT5: Menuju masa depan bebas token dengan model byte-to-byte pra-terlatih | Catatan BYT5 | Di Sini | Di Sini | ||
| KLIP | 2021 | Openai | Belajar model visual yang dapat ditransfer dari pengawasan bahasa alami | Catatan Klip | Di Sini | Di Sini | |
| Dall-E | 2021 | Openai | Generasi Teks-ke-Gambar Zero-Shot | Catatan Dall-E | Di Sini | - | |
| Naskah kuno | 2021 | Openai | Mengevaluasi model bahasa besar yang dilatih pada kode | Catatan kodeks | X | - |
Semua ringkasan tabel ditemukan ^ runtuh menjadi satu meja yang sangat besar di sini.
| Kertas | Tahun | Lembaga | Catatan? | Kode |
|---|---|---|---|---|
| Serangan permusuhan berbasis gradien terhadap transformator teks | 2021 | Catatan Serangan Berbasis Gradien | Tidak ada |
| Kertas | Tahun | Lembaga | Catatan? | Kode |
|---|---|---|---|---|
| Pembelajaran kontras yang diawasi untuk fine-tuning model bahasa pra-terlatih | 2021 | Catatan SCL | Tidak ada |
| Kertas | Tahun | Lembaga | Catatan? | Kode |
|---|---|---|---|---|
| Model bahasa yang menyempurnakan dari preferensi manusia | 2019 | Openai | Catatan Pref Manusia | Tidak ada |
| Kertas | Tahun | Lembaga | Catatan? | Kode |
|---|---|---|---|---|
| SKALING HUKUM UNTUK MODEL BAHASA SINIAL | 2020 | Openai | SKALING HUKUM CATATAN | Tidak ada |
| Kertas | Tahun | Lembaga | Catatan? | Kode |
|---|---|---|---|---|
| Mengekstraksi data pelatihan dari model bahasa besar | 2021 | Google et al. | Harus melakukan | Tidak ada |
| Deduplicating Data Pelatihan Membuat Model Bahasa Lebih Baik | 2021 | Google et al. | Catatan Dedup | Tidak ada |
| Kertas | Tahun | Lembaga | Catatan? | Kode |
|---|---|---|---|---|
| Survei empiris augmentasi data untuk pembelajaran data terbatas di NLP | 2021 | Git/unc | Harus melakukan | Tidak ada |
| Belajar dengan lebih sedikit contoh berlabel | 2021 | Kevin Murphy & Colin Raffel (pracetak: "Pembelajaran Mesin Probabilistik", Bab 19) | Layak dibaca, tidak akan meringkas di sini. | Tidak ada |
Jika Anda tertarik untuk berkontribusi pada repo ini, jangan ragu untuk melakukan hal berikut:
Tidak diragukan lagi ada informasi yang salah di sini. Harap buka masalah dan tunjukkan.
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}Untuk catatan di atas, saya telah menautkan kertas asli.
Mit


