tldr transformers
1.0.0
Das "tl; dr" auf ein paar bemerkenswerten Papieren über Transformers und moderne NLP.
Dies ist a Leben Repo, um verschiedene Forschungsfäden im Auge zu behalten.
Zuletzt aktualisiert : 20. September 2021.
Modelle : Gpt- *, *bert *, adapter- *, *t5, megatron, dall-e, codex usw.
Themen : Transformator Architekturen + Training; Gegentliche Angriffe; Skalierungsgesetze; Ausrichtung; Auswendiglernen; wenige Etiketten; Kausalität.
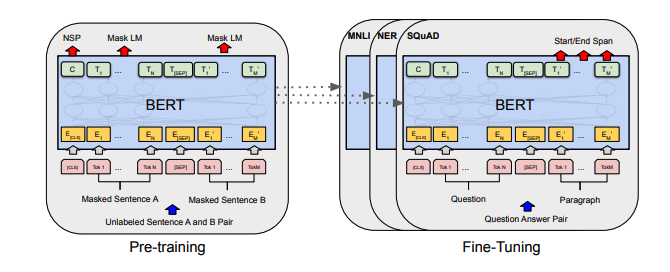
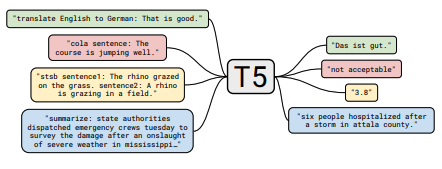
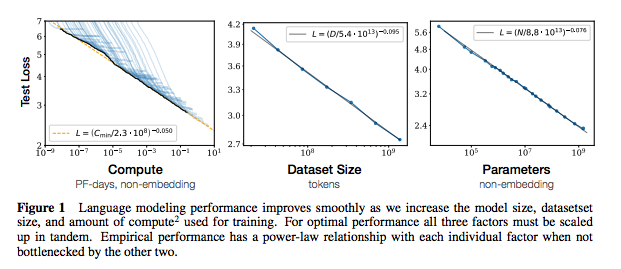
Jede Reihe von Notizen enthält Links zum Papier, die ursprüngliche Code -Implementierung (falls verfügbar) und das Umarmungsface? Durchführung.
Hier sind einige Beispiele ---> T5, Byt5, Deduping Transformator Training Sets.
Dieses Repo enthält auch eine Tabelle, die die Unterschiede zwischen Transformatorpapieren quantifiziert Alles in einem Tisch .
Die Transformatorenpapiere werden unten etwas chronologisch dargestellt. Gehen Sie zum ": point_right: Notizen: point_left:" Spalte unten, um die Notizen für jedes Papier zu finden.
Dies ist kein Intro in das Deep -Lernen in NLP. Wenn Sie danach suchen, empfehle ich einen der folgenden: Schnell -Ki -Kurs, einen der Coursera -Kurse oder vielleicht dieses alte Ding. Komm hierher.
Angesichts der Explosion in Papieren zu allen Dingen Transformatoren in den letzten Jahren erscheint es nützlich, die wichtigsten Merkmale/Ergebnisse/Erkenntnisse jedes Papiers in einem verdaulichen Format zu katalogisieren. Daher dieses Repo.
| Modell | Jahr | Institut | Papier | Notizen? | Ursprünglicher Code | Umarmung? | Andere Repo |
|---|---|---|---|---|---|---|---|
| Transformator | 2017 | Aufmerksamkeit ist alles was Sie brauchen | Übersprungen, zu viele gute Artikel:
| ? | |||
| GPT-3 | 2018 | Openai | Sprachmodelle sind unbeaufsichtigte Multitasking -Lernende | Aufgabe | X | X | |
| GPT-J-6B | 2021 | Eleutherai | GPT-J-6B: 6B JAX-basierter Transformator ( Public GPT-3 ) | X | Hier | X | X |
| Bert | 2018 | Bert: Vorausbildung von tiefen bidirektionalen Transformatoren für das Sprachverständnis | Bert Notizen | Hier | Hier | ||
| Distilbert | 2019 | Umarmung | Distilbert, eine destillierte Version von Bert: kleiner, schneller, billiger und leichter | Distilbert Notizen | Hier | ||
| Albert | 2019 | Google/Toyota | Albert: Ein Lite Bert für das selbstbewertete Lernen von Sprachdarstellungen | Albert bemerkt | Hier | Hier | |
| Roberta | 2019 | Roberta: Ein robust optimierter Bert -Vorab -Ansatz | Roberta bemerkt | Hier | Hier | ||
| Bart | 2019 | BART: Denoising Sequenz-zu-Sequenz-Vorausbildung für die Erzeugung, Übersetzung und das Verständnis der natürlichen Sprache | Bart Notizen | Hier | Hier | ||
| T5 | 2019 | Erforschen der Grenzen des Transferlernens mit einem einheitlichen Text-zu-Text-Transformator | T5 Notizen | Hier | Hier | ||
| Adapter-Bert | 2019 | Parameter-effizientes Transferlernen für NLP | Adapter-Bert-Notizen | Hier | - - | Hier | |
| Megatron-lm | 2019 | Nvidia | Megatron-LM: Training von Multi-Milliarden-Parametersprachenmodellen unter Verwendung der Modellparallelität | Megatron Notizen | Hier | - - | Hier |
| Reformer | 2020 | Reformer: Der effiziente Transformator | Reformer Notizen | Hier | |||
| Byt5 | 2021 | Byt5: Auf dem Weg zu einer tokenfreien Zukunft mit vorgebildeten Byte-zu-Byte-Modellen | Byt5 Notizen | Hier | Hier | ||
| Clip | 2021 | Openai | Lernen übertragbarer visueller Modelle aus natürlicher Sprache Überwachung | Clip Notes | Hier | Hier | |
| Dall-e | 2021 | Openai | Null-Shot-Text-zu-Image-Erzeugung | Dall-e Notizen | Hier | - - | |
| Kodex | 2021 | Openai | Bewertung von großsprachigen Modellen, die auf Code trainiert wurden | Codex Notizen | X | - - |
Alle Tabellenzusammenfassungen wurden hier in einen wirklich großen Tisch zusammengebrochen.
| Papier | Jahr | Institut | Notizen? | Codes |
|---|---|---|---|---|
| Gegentliche Gegnerangriffe gegen Texttransformatoren | 2021 | Gradientenbasierte Angriffsnotizen | Keiner |
| Papier | Jahr | Institut | Notizen? | Codes |
|---|---|---|---|---|
| Übersichtliches kontrastives Lernen für vorgebliebenes Sprachmodell Feinabstimmung | 2021 | SCL Notes | Keiner |
| Papier | Jahr | Institut | Notizen? | Codes |
|---|---|---|---|---|
| Feinabstimmungssprachmodelle aus menschlichen Vorlieben | 2019 | Openai | Menschliche Vornotizen | Keiner |
| Papier | Jahr | Institut | Notizen? | Codes |
|---|---|---|---|---|
| Skalierungsgesetze für Modelle neuronaler Sprache | 2020 | Openai | Skalierungsgesetze Notizen | Keiner |
| Papier | Jahr | Institut | Notizen? | Codes |
|---|---|---|---|---|
| Extrahieren von Trainingsdaten aus Großsprachenmodellen | 2021 | Google et al. | Aufgabe | Keiner |
| Durch das Dingen von Trainingsdaten werden Sprachmodelle besser | 2021 | Google et al. | Dedup Notizen | Keiner |
| Papier | Jahr | Institut | Notizen? | Codes |
|---|---|---|---|---|
| Eine empirische Untersuchung der Datenerweiterung für begrenzte Datenlernen in NLP | 2021 | Git/UNC | Aufgabe | Keiner |
| Lernen mit weniger beschrifteten Beispielen | 2021 | Kevin Murphy & Colin Raffel (Präprint: "Probabilistisches maschinelles Lernen", Kapitel 19) | Eine Lektüre wert, wird hier nicht zusammenfassen. | Keiner |
Wenn Sie daran interessiert sind, zu diesem Repo beizutragen, können Sie Folgendes tun:
Zweifellos gibt es hier Informationen, die hier falsch sind. Bitte öffnen Sie ein Problem und weisen Sie darauf hin.
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}Für die obigen Notizen habe ich die Originalpapiere verknüpft.
MIT


