tldr transformers
1.0.0
关于变压器和现代NLP的一些著名论文的“ TL; Dr”。
这是一个活的回购以保留不同的研究线程的标签。
最后更新:2021年9月20日。
型号:gpt- *, *bert *,apapter- *, *t5,Megatron,dall-e,codex,等。
主题:变压器体系结构 +培训;对抗攻击;缩放法律;结盟;记忆;很少的标签;因果关系。
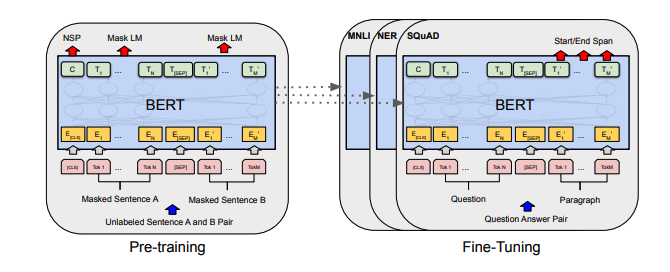
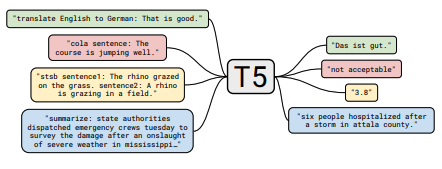
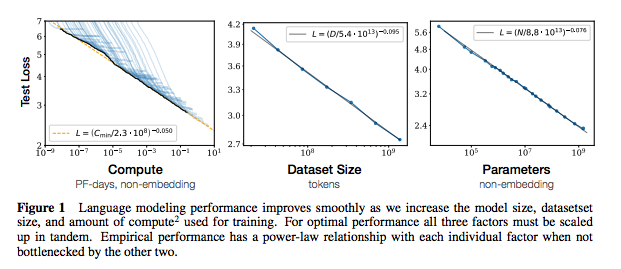
每组注释都包括指向纸张的链接,原始代码实现(如果有)和拥抱面?执行。
这里有一些例子---> t5,byt5,缩短变压器训练集。
此存储库还包括一个量化变压器论文差异的表一张桌子。
在下面按时间顺序介绍了变形金刚的论文。转到“:point_right:笔记:point_left:”下面的列以找到每篇论文的注释。
这不是NLP深度学习的介绍。如果您要寻找的话,我建议您使用以下一项:快速AI的课程,Coursera课程之一,或者这是古老的事情。在那之后来这里。
随着过去几年对变形金刚的所有内容的爆炸式爆炸,以易消化格式对每篇论文的显着特征/结果/见解进行分类似乎很有用。因此,这个仓库。
| 模型 | 年 | 研究所 | 纸 | 注意? | 原始代码 | 拥抱面? | 其他仓库 |
|---|---|---|---|---|---|---|---|
| 变压器 | 2017 | 谷歌 | 注意就是您所需要的 | 跳过,太多的文章:
| ? | ||
| GPT-3 | 2018 | Openai | 语言模型是无监督的多任务学习者 | 待办事项 | x | x | |
| GPT-J-6B | 2021 | Eleutherai | GPT-J-6B:基于JAX的6B变压器(公共GPT-3 ) | x | 这里 | x | x |
| 伯特 | 2018 | 谷歌 | BERT:深层双向变压器的预训练以了解语言理解 | 伯特注意 | 这里 | 这里 | |
| Distilbert | 2019 | 拥抱面 | Distilbert,Bert的蒸馏版:较小,更快,更便宜,更轻 | Distilbert笔记 | 这里 | ||
| 阿尔伯特 | 2019 | Google/Toyota | 阿尔伯特:一个用于自我监督语言表征学习的精简版 | 阿尔伯特笔记 | 这里 | 这里 | |
| 罗伯塔 | 2019 | 罗伯塔:一种强大优化的BERT预训练方法 | 罗伯塔笔记 | 这里 | 这里 | ||
| 巴特 | 2019 | 巴特:自然语言生成,翻译和理解的序列前训练序列前训练 | 巴特笔记 | 这里 | 这里 | ||
| T5 | 2019 | 谷歌 | 使用统一的文本到文本变压器探索转移学习的限制 | T5笔记 | 这里 | 这里 | |
| 适配器 - 伯特 | 2019 | 谷歌 | NLP的参数有效传输学习 | 适配器 - 伯特笔记 | 这里 | - | 这里 |
| Megatron-LM | 2019 | Nvidia | Megatron-LM:使用模型并联培训数十亿个参数语言模型 | 威震天注意 | 这里 | - | 这里 |
| 改革家 | 2020 | 谷歌 | 改革者:高效的变压器 | 改革家指出 | 这里 | ||
| byt5 | 2021 | 谷歌 | BYT5:迈向具有预训练字节模型的无令牌未来 | BYT5注释 | 这里 | 这里 | |
| 夹子 | 2021 | Openai | 从自然语言监督中学习可转移的视觉模型 | 剪辑笔记 | 这里 | 这里 | |
| dall-e | 2021 | Openai | 零击文本对图像生成 | dall-e注意 | 这里 | - | |
| 法典 | 2021 | Openai | 评估经过代码培训的大型语言模型 | 法典注释 | x | - |
所有的桌子摘要都发现 ^倒在一个非常大的桌子中。
| 纸 | 年 | 研究所 | 注意? | 代码 |
|---|---|---|---|---|
| 基于梯度的对抗攻击文本变压器 | 2021 | 基于梯度的攻击说明 | 没有任何 |
| 纸 | 年 | 研究所 | 注意? | 代码 |
|---|---|---|---|---|
| 预先训练的语言模型微调的对比度学习 | 2021 | SCL注意 | 没有任何 |
| 纸 | 年 | 研究所 | 注意? | 代码 |
|---|---|---|---|---|
| 来自人类偏好的微调语言模型 | 2019 | Openai | 人类的预注 | 没有任何 |
| 纸 | 年 | 研究所 | 注意? | 代码 |
|---|---|---|---|---|
| 神经语言模型的缩放法律 | 2020 | Openai | 缩放法律注释 | 没有任何 |
| 纸 | 年 | 研究所 | 注意? | 代码 |
|---|---|---|---|---|
| 从大语言模型中提取培训数据 | 2021 | Google等。 | 待办事项 | 没有任何 |
| 重复培训数据使语言模型更好 | 2021 | Google等。 | DEDUP笔记 | 没有任何 |
| 纸 | 年 | 研究所 | 注意? | 代码 |
|---|---|---|---|---|
| NLP中有限数据学习的数据增强的经验调查 | 2021 | git/unc | 待办事项 | 没有任何 |
| 以更少的示例学习学习 | 2021 | 凯文·墨菲(Kevin Murphy)和科林·拉弗尔(Colin Raffel)(预印本:“概率机器学习”,第19章) | 值得一读,不会在这里总结。 | 没有任何 |
如果您有兴趣为此仓库做出贡献,请随时执行以下操作:
毫无疑问,这里有不正确的信息。请打开一个问题并指出。
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}对于上面的注释,我已经链接了原始论文。
麻省理工学院


