tldr transformers
1.0.0
Le "TL; DR" sur quelques articles notables sur les transformateurs et la NLP moderne.
C'est un vie Repo pour garder un œil sur différents fils de recherche.
Dernière mise à jour : 20 septembre 2021.
Modèles : Gpt- *, * bert *, adaptateur- *, * t5, megatron, dall-e, codex, etc.
Sujets : Architectures de transformateur + formation; attaques contradictoires; lois sur l'échelle; alignement; mémorisation; quelques étiquettes; causalité.
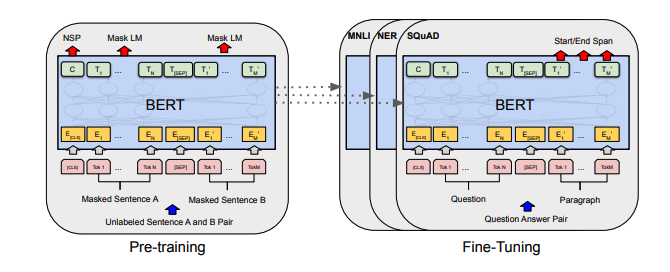
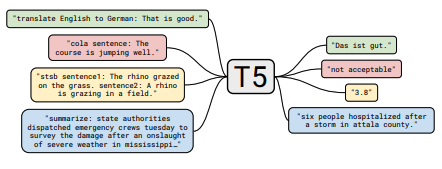
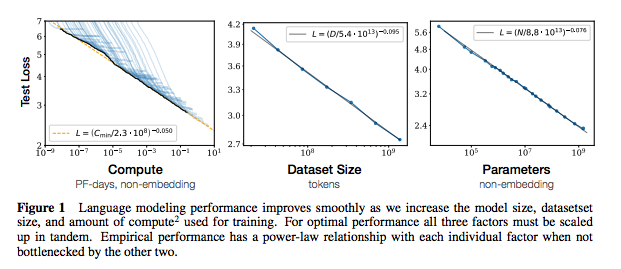
Chaque ensemble de notes comprend des liens vers le document, l'implémentation du code d'origine (si disponible) et le HuggingFace? mise en œuvre.
Voici quelques exemples ---> t5, byt5, déduptage des ensembles de formation des transformateurs.
Ce repo comprend également un tableau quantifiant les différences entre les articles du transformateur Tout dans une seule table .
Les articles Transformers sont présentés un peu chronologiquement ci-dessous. Accédez à la colonne ": Point_Right: Notes: Point_left:" Colonne ci-dessous pour trouver les notes pour chaque article.
Ce n'est pas une introduction à l'apprentissage en profondeur dans la PNL. Si vous cherchez cela, je recommande l'un des éléments suivants: le cours de Fast AI, l'un des cours de Coursera, ou peut-être cette vieille chose. Venez ici après ça.
Avec l'explosion des articles sur toutes les choses transformateurs au cours des dernières années, il semble utile de cataloguer les caractéristiques / résultats / résultats saillants de chaque article dans un format digestible. D'où ce repo.
| Modèle | Année | Institut | Papier | Notes? | Code d'origine | Houggingface? | Autre repo |
|---|---|---|---|---|---|---|---|
| Transformateur | 2017 | L'attention est tout ce dont vous avez besoin | Sauté, trop de bons écrits:
| ? | |||
| GPT-3 | 2018 | Openai | Les modèles de langage sont des apprenants multitâches non sortis | Faire | X | X | |
| GPT-J-6B | 2021 | Eleutherai | GPT-J-6B: Transformateur basé sur Jax 6B ( public GPT-3 ) | X | ici | x | x |
| Bert | 2018 | Bert: pré-formation des transformateurs bidirectionnels profonds pour la compréhension du langage | Bert Notes | ici | ici | ||
| Distilbert | 2019 | Étreinte | Distilbert, une version distillée de Bert: plus petit, plus rapide, moins cher et plus léger | NOTES DE DISTILBERT | ici | ||
| Albert | 2019 | Google / Toyota | Albert: A Lite Bert pour l'apprentissage auto-supervisé des représentations linguistiques | Notes Albert | ici | ici | |
| Roberta | 2019 | Roberta: une approche de pré-formation Bert optimisée à optimisation | Roberta Notes | ici | ici | ||
| Barbe | 2019 | BART: Pré-formation de séquence à séquence à la séquence pour la génération, la traduction et la compréhension du langage naturel | Bart | ici | ici | ||
| T5 | 2019 | Exploration des limites de l'apprentissage du transfert avec un transformateur de texte à texte unifié | NOTES T5 | ici | ici | ||
| Adaptateur | 2019 | Apprentissage de transfert économe en paramètres pour PNL | Notes d'adaptateur-BERT | ici | - | ici | |
| Mégatron-lm | 2019 | Nvidia | Megatron-LM: Formation de plusieurs milliards de modèles de langage de paramètres utilisant le parallélisme du modèle | Mégatron | ici | - | ici |
| Réformateur | 2020 | Réformateur: le transformateur efficace | Notes de réformateurs | ici | |||
| byt5 | 2021 | BYT5: Vers un avenir sans jeton avec des modèles d'octets pré-formés | NOTES BYT5 | ici | ici | ||
| AGRAFE | 2021 | Openai | Apprentissage des modèles visuels transférables à partir de la supervision du langage naturel | Clip Notes | ici | ici | |
| Dall-E | 2021 | Openai | Génération de texte à l'image zéro | Notes de Dall-e | ici | - | |
| Manuscrit | 2021 | Openai | Évaluation de modèles de grandes langues formés sur le code | Notes du codex | X | - |
Tous les résumés de la table ont trouvés ^ se sont effondrés dans une très grande table ici.
| Papier | Année | Institut | Notes? | Codes |
|---|---|---|---|---|
| Attaques contradictoires basées sur le gradient contre les transformateurs de texte | 2021 | Notes d'attaque basées sur le dégradé | Aucun |
| Papier | Année | Institut | Notes? | Codes |
|---|---|---|---|---|
| Apprentissage contrasté supervisé pour le modèle de réglage de la langue pré-formée | 2021 | Notes SCL | Aucun |
| Papier | Année | Institut | Notes? | Codes |
|---|---|---|---|---|
| Modèles de langage affinés des préférences humaines | 2019 | Openai | Notes de préf | Aucun |
| Papier | Année | Institut | Notes? | Codes |
|---|---|---|---|---|
| Échelle des lois pour les modèles de langage neuronal | 2020 | Openai | Notes de lois sur l'échelle | Aucun |
| Papier | Année | Institut | Notes? | Codes |
|---|---|---|---|---|
| Extraction des données de formation à partir de modèles de gros langues | 2021 | Google et al. | Faire | Aucun |
| La déduplication des données de formation rend les modèles de langage meilleurs | 2021 | Google et al. | Notes de déducteur | Aucun |
| Papier | Année | Institut | Notes? | Codes |
|---|---|---|---|---|
| Une étude empirique de l'augmentation des données pour l'apprentissage limité des données dans la PNL | 2021 | Git / unc | Faire | Aucun |
| Apprendre avec moins d'exemples étiquetés | 2021 | Kevin Murphy & Colin Raffel (Preprint: "Probabilistic Machine Learning", chapitre 19) | Vaut une lecture, ne résumera pas ici. | Aucun |
Si vous êtes intéressé à contribuer à ce dépôt, n'hésitez pas à faire ce qui suit:
Il y a sans aucun doute des informations incorrectes ici. Veuillez ouvrir un problème et le signaler.
@ misc { cliff - notes - transformers ,
author = { Thompson , Will },
url = { https : // github . com / will - thompson - k / cliff - notes - transformers },
year = { 2021 }
}Pour les notes ci-dessus, j'ai lié les papiers originaux.
Mit


