catELMo
1.0.0
Catelmo是一種雙向氨基酸嵌入模型,它學習上下文化的氨基酸表示,將氨基酸視為單詞和序列作為句子。它通過預測每個氨基酸令牌的圖案來學習氨基酸序列的模式,鑑於其先前的令牌。它已經接受了4,173,895 TCR的培訓
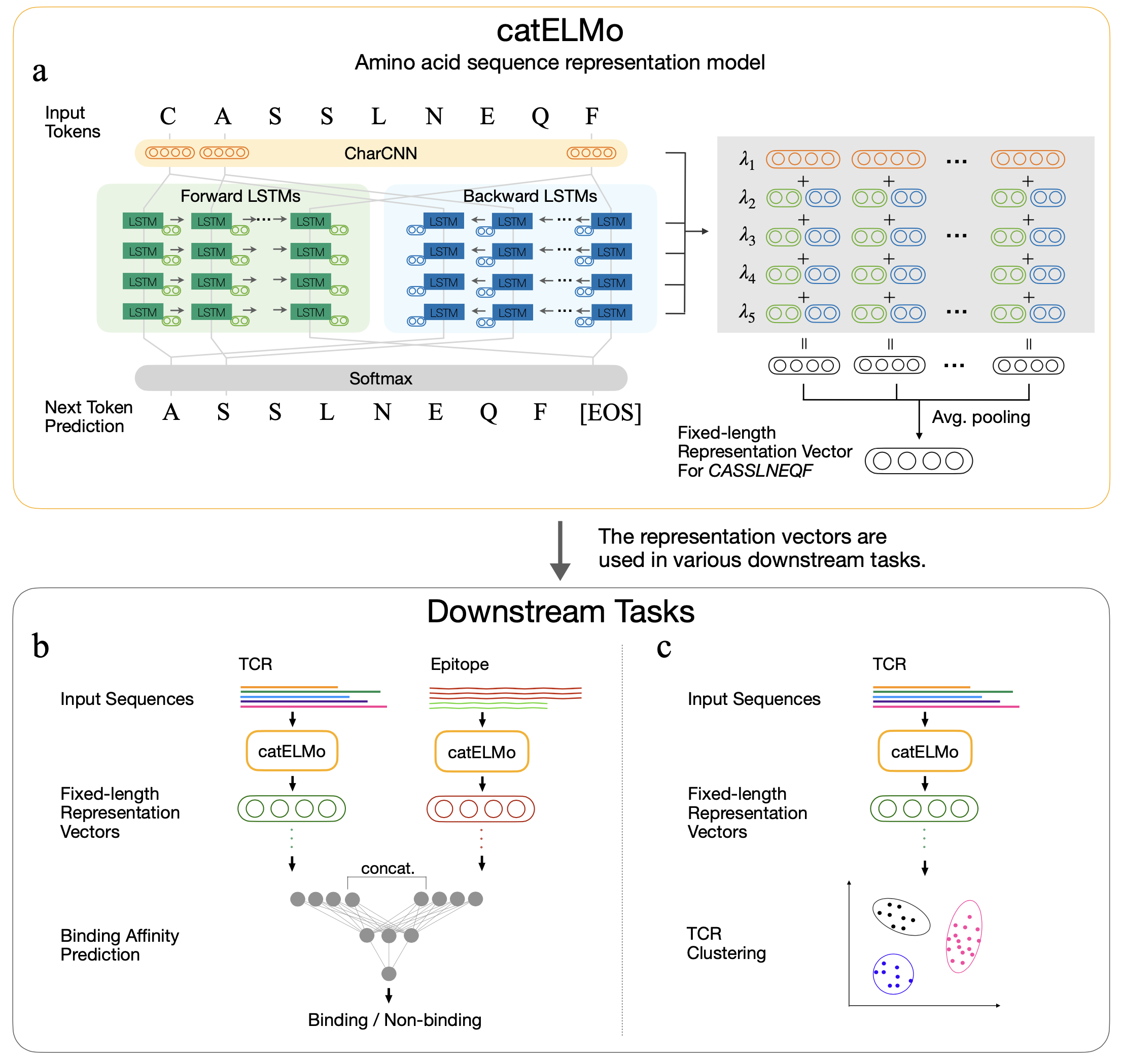
上下文感知的氨基酸嵌入進展分析TCR-質相互作用
Pengfei Zhang 1,2 ,Michael Cai 1,2 ,Seojin Bang 2 ,Heewook Lee 1,2
1亞利桑那州立大學的計算與增強情報學院,亞利桑那州立大學生物設計學院2
發表於: Elife,2023年。
紙|代碼|海報|幻燈片|演示文稿(YouTube)
git clone https://github.com/Lee-CBG/catELMo
cd catELMo/
conda create --name bap python=3.6.13
pip install pandas==1.1.5 tensorflow==2.6.0 keras==2.6.0 scikit-learn==0.24.2 tqdm
source activate bapdatasets集文件夾下載培訓和測試數據。embedders文件夾的說明,獲取TCR和表位的嵌入。表位分裂的一個例子
python -W ignore bap.py
--embedding catELMo_4_layers_1024
--split epitope
--gpu 0
--fraction 1
--seed 42如果您使用此代碼或使用我們的Catelmo進行研究,請引用我們的論文:
@article {catelmobiorxiv,
author = {Pengfei Zhang and Seojin Bang and Michael Cai and Heewook Lee},
title = {Context-Aware Amino Acid Embedding Advances Analysis of TCR-Epitope Interactions},
elocation-id = {2023.04.12.536635},
year = {2023},
doi = {10.1101/2023.04.12.536635},
publisher = {Cold Spring Harbor Laboratory},
journal = {bioRxiv}
}
這項工作是在創意共享歸因非商業 - 諾迪毒素4.0國際許可下獲得許可的。


