catELMo
1.0.0
catELMo is a bi-directional amino acid embedding model that learns contextualized amino acid representations, treating an amino acid as a word and a sequence as a sentence. It learns patterns of amino acid sequences with its self-supervision signal, by predicting each the next amino acid token given its previous tokens. It has been trained on 4,173,895 TCR
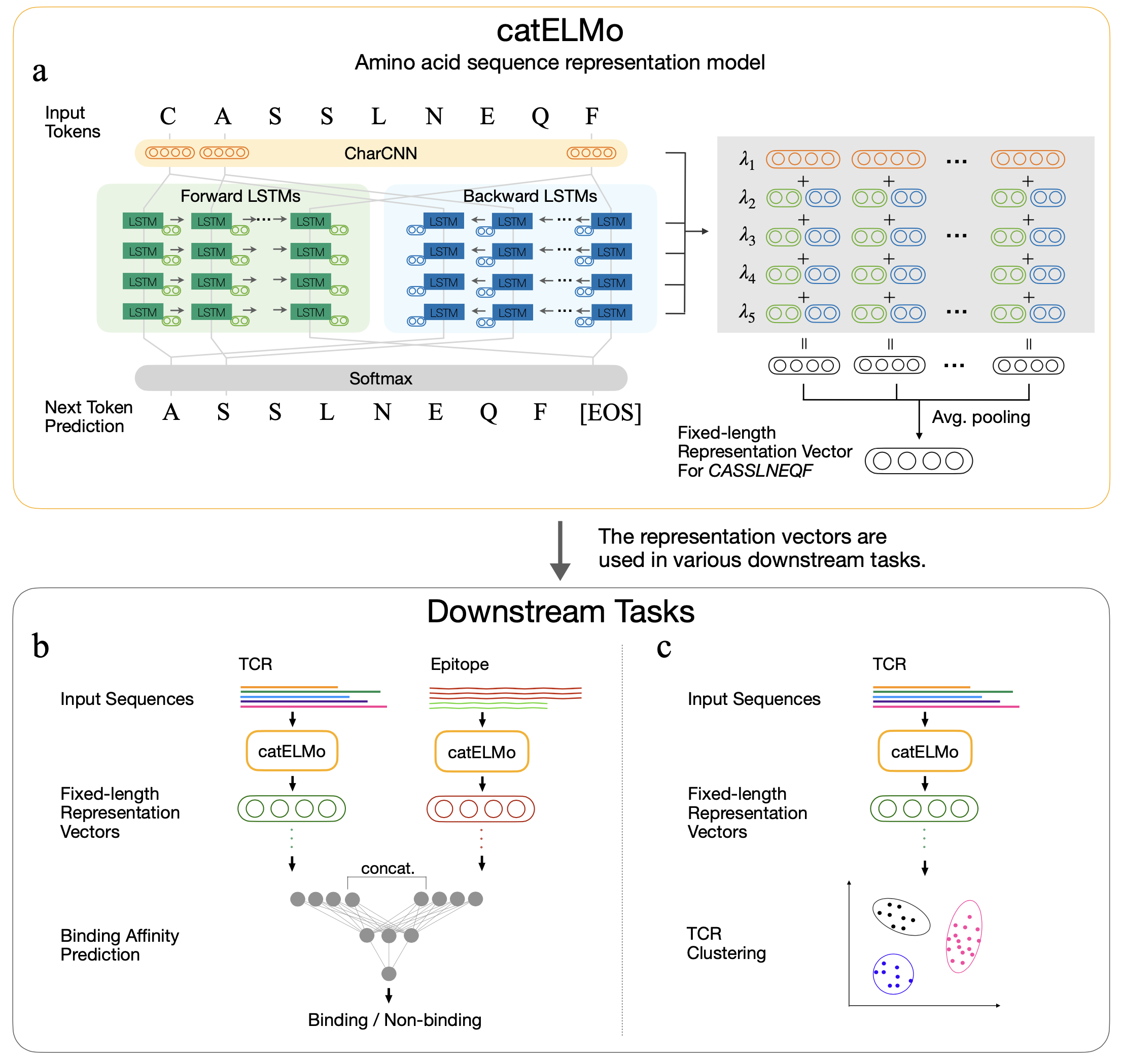
Context-Aware Amino Acid Embedding Advances Analysis of TCR-Epitope Interactions
Pengfei Zhang1,2, Michael Cai1,2, Seojin Bang2, Heewook Lee1,2
1 School of Computing and Augmented Intelligence, Arizona State University, 2 Biodesign Institute, Arizona State University
Published in: eLife, 2023.
Paper | Code | Poster | Slides | Presentation (YouTube)
git clone https://github.com/Lee-CBG/catELMo
cd catELMo/
conda create --name bap python=3.6.13
pip install pandas==1.1.5 tensorflow==2.6.0 keras==2.6.0 scikit-learn==0.24.2 tqdm
source activate bapdatasets folder.embedders folder.An example for epitope split
python -W ignore bap.py
--embedding catELMo_4_layers_1024
--split epitope
--gpu 0
--fraction 1
--seed 42If you use this code or use our catELMo for your research, please cite our paper:
@article {catelmobiorxiv,
author = {Pengfei Zhang and Seojin Bang and Michael Cai and Heewook Lee},
title = {Context-Aware Amino Acid Embedding Advances Analysis of TCR-Epitope Interactions},
elocation-id = {2023.04.12.536635},
year = {2023},
doi = {10.1101/2023.04.12.536635},
publisher = {Cold Spring Harbor Laboratory},
journal = {bioRxiv}
}
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.


