OpenDiscoverPlatformCaseStudy
1.0.0
有關.NET示例GITHUB存儲庫,請參見OpenDiscover®SDK
打開的Discover Platform API的一個實例通常能夠以40-70 GB/小時的速率處理文檔集*(*速率將取決於數據集中的用戶硬件和文件類型)。與大多數Ediscovery軟件(例如,處理過程中的敏感項目/實體檢測以及處理過程中)相比,它在處理文檔方面非常快,同時提取更多內容。開放的Discover Platform API演示應用程序PlatformApideMo.exe用於處理Anron Outlook PST數據集。 PlatformApideMo.exe演示應用程序包含平台API文檔處理類的一個實例。示例PlatformApidemo.exe處理輸出的屏幕截圖顯示在下一節中。
PlatformApideMo.exe與Open Discover平台評估一起分發:
在最近的性能測試中,開放Discover SDK將53 GB Enron Microsoft Outlook PST PST數據集處理,並且大量插入了平台API輸出(Text/Metadata/sensistive(PXI)項目/等),使用一台4核Windows Desktop PC,將平台API輸出(text/metadata/stemitive(pxi)項目/等)插入了RAVENDB。
** This case study processing rate was for the .NET 4.62 version of SDK, the new .NET 6 version is > 100% faster on average, all the PST processing tasks on the .NET 6 version of OpenDiscoverPlatform processed their PST dataset tasks between 90-100+GB/hr rates (based on input size) WITH sensitive item detection enabled (processing rates are hardware dependent - in these numbers we used a single帶有Intel i7 CPU和16GB RAM的台式PC。
下面的屏幕截圖顯示了從其Outlook PST容器中提取的電子郵件項目(及其附件),並由Platformapidemo.exe應用程序處理。該電子郵件來自Enron Microsoft Outlook PST之一。圖像左側的樹視圖控件顯示了所有處理過的文檔/容器的父/子層次結構,然後單擊樹控件中的項目將顯示其提取的內容。對於樹視圖中選定的Outlook電子郵件項,我們可以看到它具有6個MS Office Word文檔作為從電子郵件中提取的附件。每個附件/嵌入式項目都提取了其內容(無論多麼複雜,處理都會完全展開任何父母的層次結構)。注意文件格式標識結果,計算出“ sortdate”,各種文檔哈希,提取的元數據和圖像右上方的其他選項卡項目,其中包含其他提取內容:
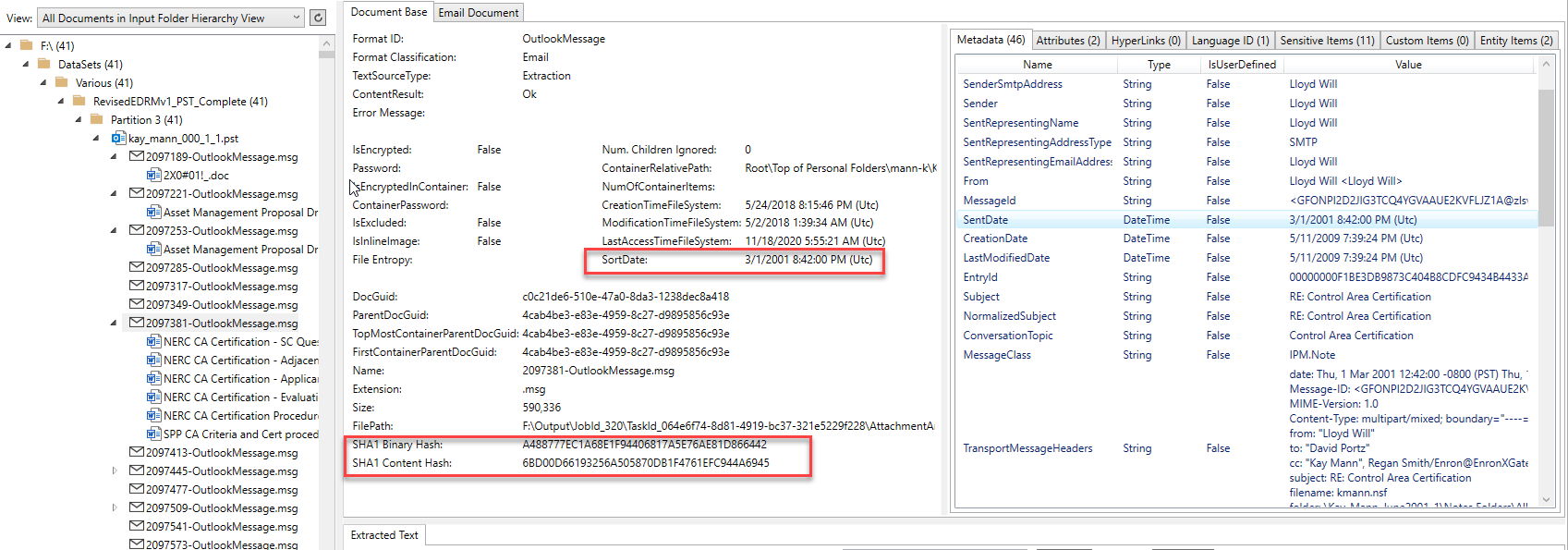
通過電子郵件發送特定內容,例如所有收件人和額外的哈希:
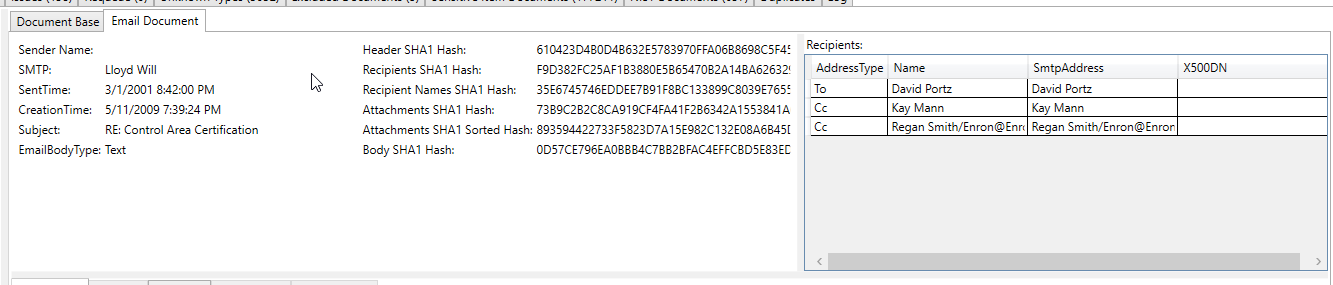
此處理後的電子郵件屏幕截圖顯示了一個在電子郵件提取的文本中提取/識別為“敏感項目”的銀行帳號(所有提取的文本和所有元數據都被掃描以備敏感項目):
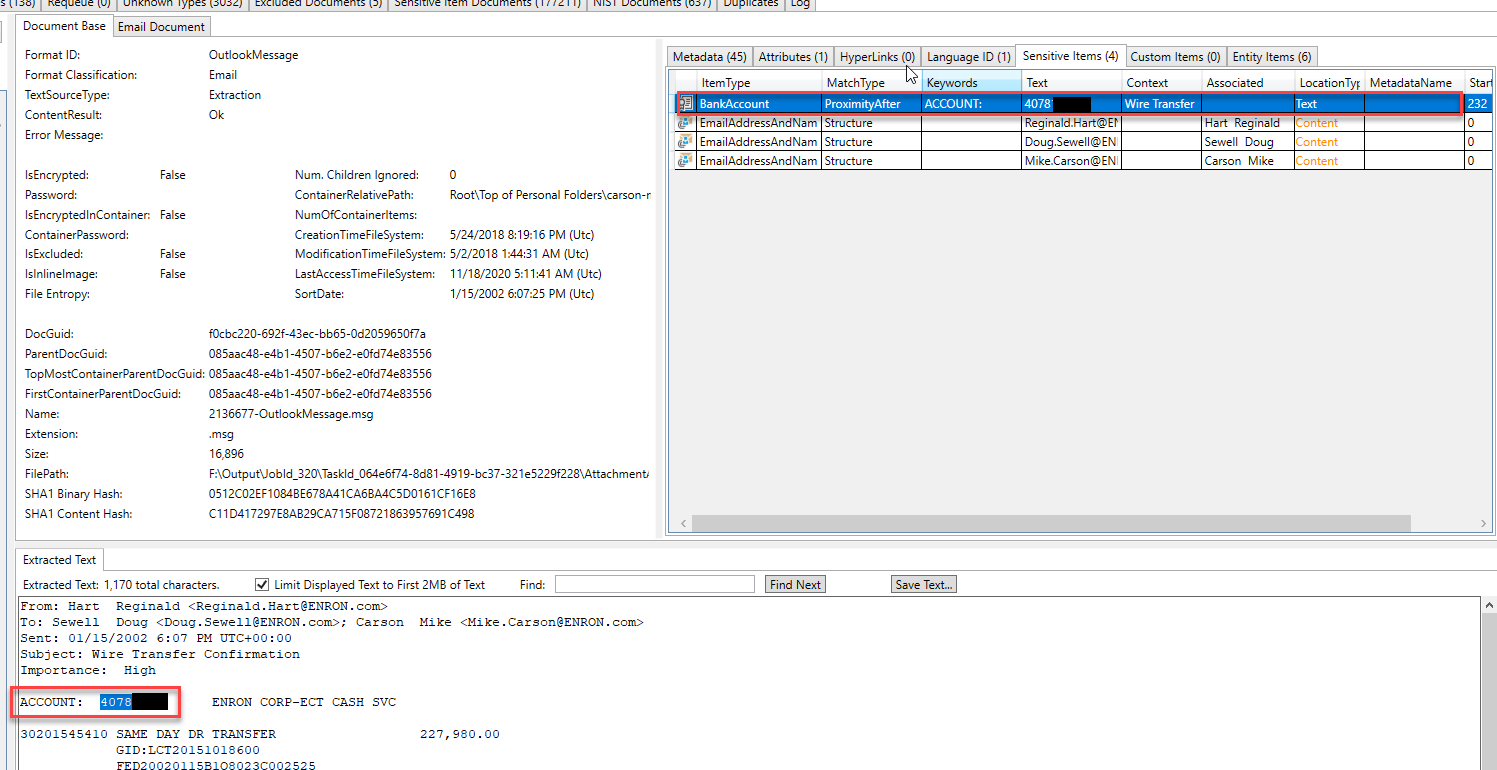
一些“實體”在另一封電子郵件中識別和提取。通過檢查此電子郵件中發現的實體類型,我們可以推測該電子郵件正在討論法律問題:
下面的屏幕截圖顯示了Ravendb Studio中的Anron數據庫,該數據庫填充了平台API處理的輸出。 Ravendb中存儲的一些數據庫文檔字段只能適合屏幕截圖,還有更多的字段。帶有紅色邊框註釋的列名是對象的集合:
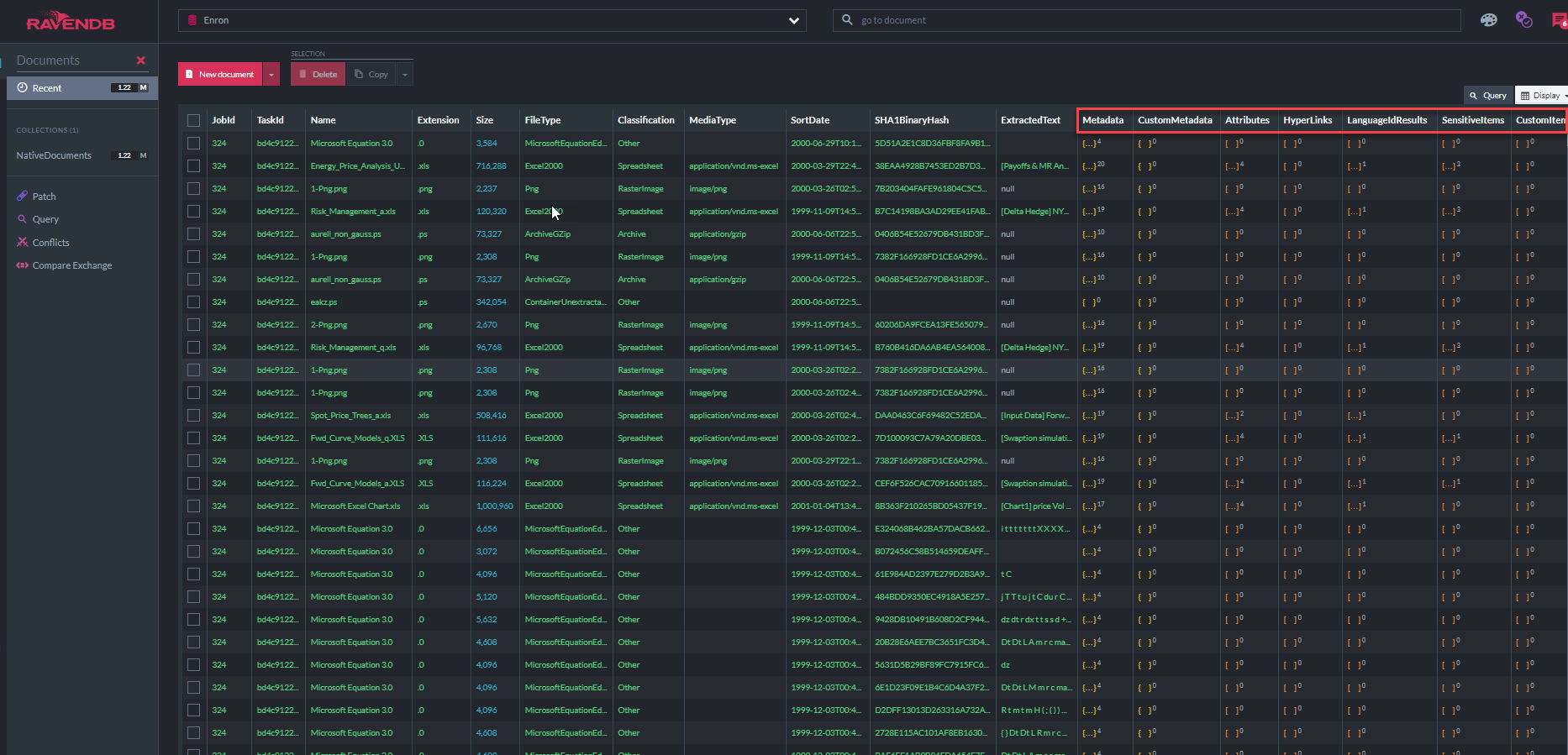
下面的屏幕截圖顯示了31個Ravendb索引中的一些“ ECA演示應用程序”用於查詢文檔存儲的索引(請注意,“ Metadatatapropertyindex”表明該數據庫中存儲了3770萬個元數據屬性,大多數是電子郵件元數據,此外還有所有提取的文本。
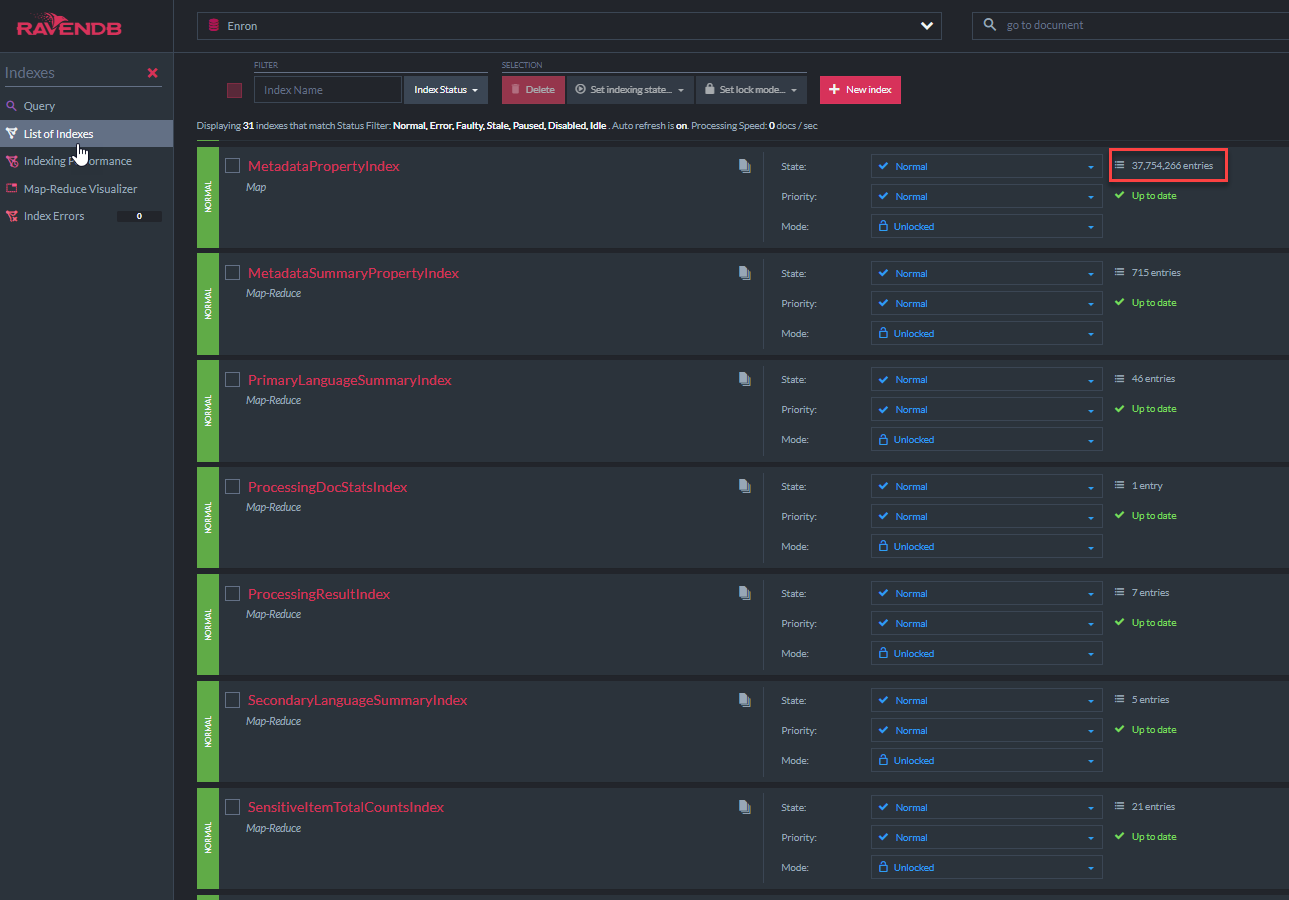
下面顯示了“元數據帕特基inindex” C#類代碼。該索引類來自Ravendb的AbstractIndexCreationTask(此演示中的所有其他索引)。該索引將允許所有元數據字段上的Lucene'Like'查詢。存在類似的nativedocument.custommetadata:
所有C#定義的RavendB索引都通過簡單的RavendB API呼叫從“ ECA Demo App”中的RavendB Enron數據庫中創建。
下面的屏幕截圖顯示了189 Microsoft Outlook PST Enron數據集的處理摘要統計信息(總共處理的1,221,542封電子郵件和附件)。該數據集中的大多數電子郵件和附件都是重複的文檔,因為事實是,在法律發現階段收集數據的員工正在來回發送電子郵件 - 下圖中所示的重複數據刪除統計數據基於二進制/內容哈希,將來會更新此案例研究(我們將與RavendB Indexes一起更新該案例研究(包括ravendb Indexes),以包括“家庭” preditiation of Family preditiation'''''''''''''''''''''''''請注意文件格式分類餅圖,特定文件格式餅圖的摘要以及處理結果的摘要(具有OK的值/錯誤Passeword/dataError/等的枚舉類型)餅圖。
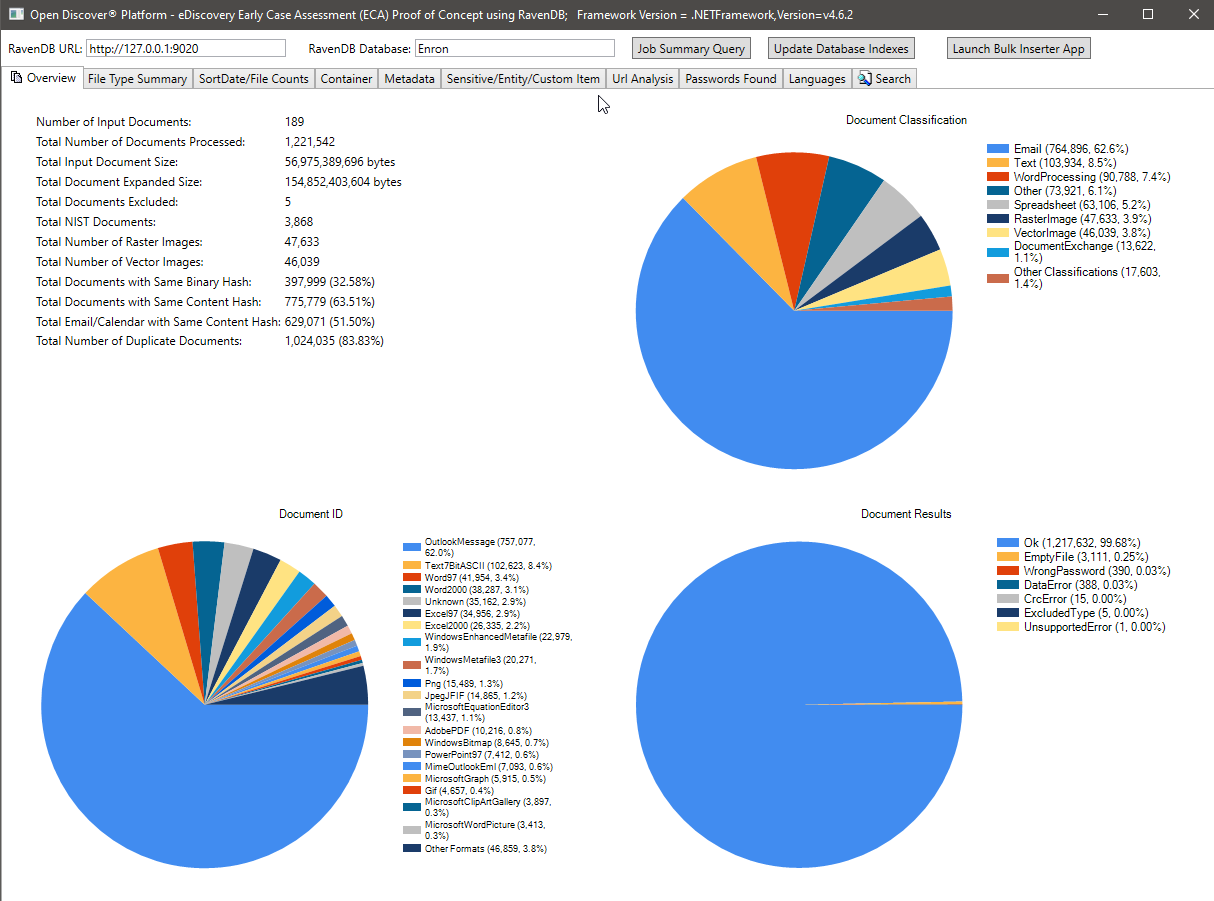
文件計數按順序摘要圖表:
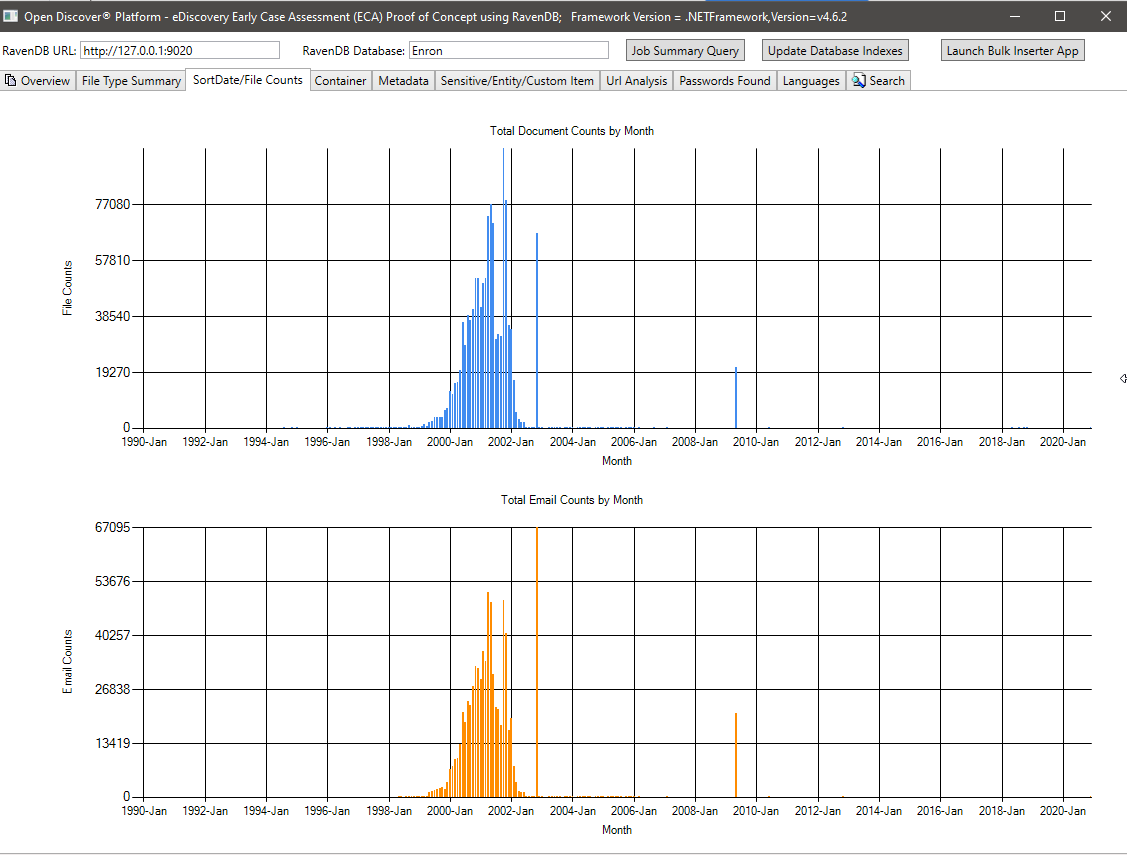
元數據摘要(元數據字段名稱/文檔總數)-715所有文檔中已知的唯一元數據字段名稱和636個自定義(用戶定義)元數據字段。該查詢可以幫助法律案件經理知道該集合中有哪些元數據字段可在:
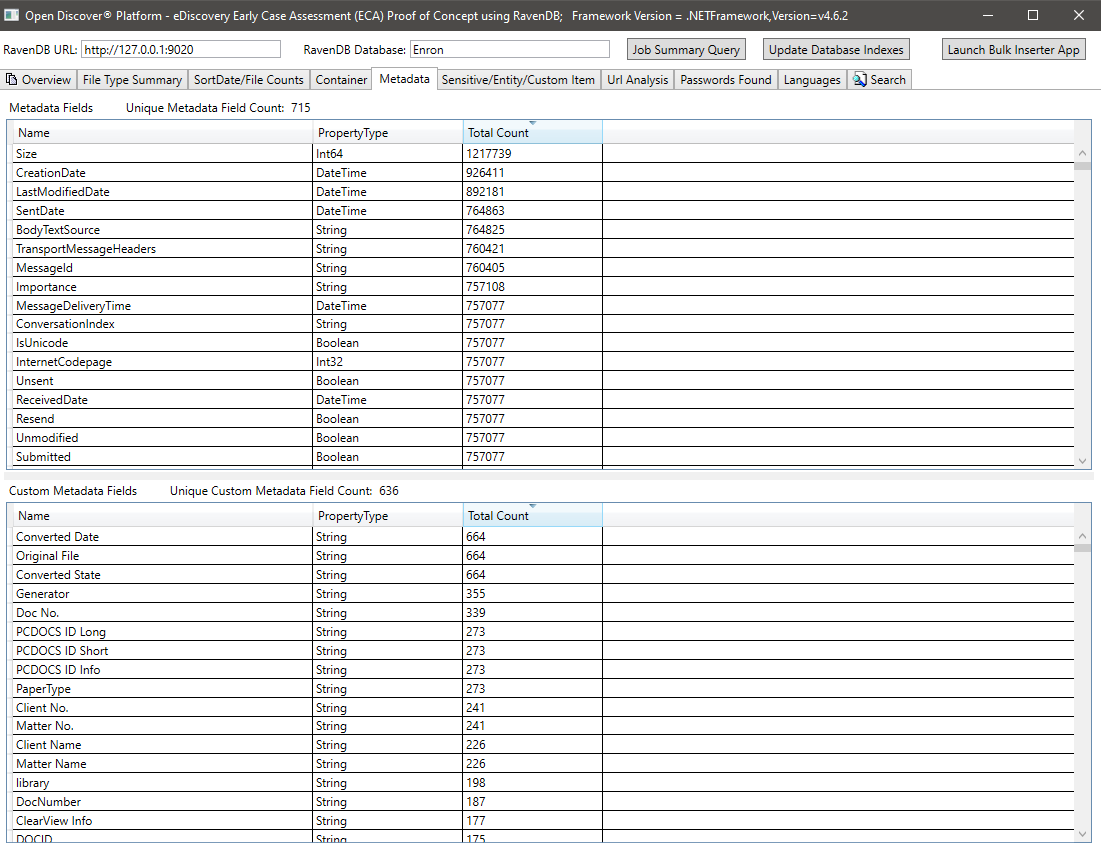
所有文檔的敏感項目/實體項目摘要:
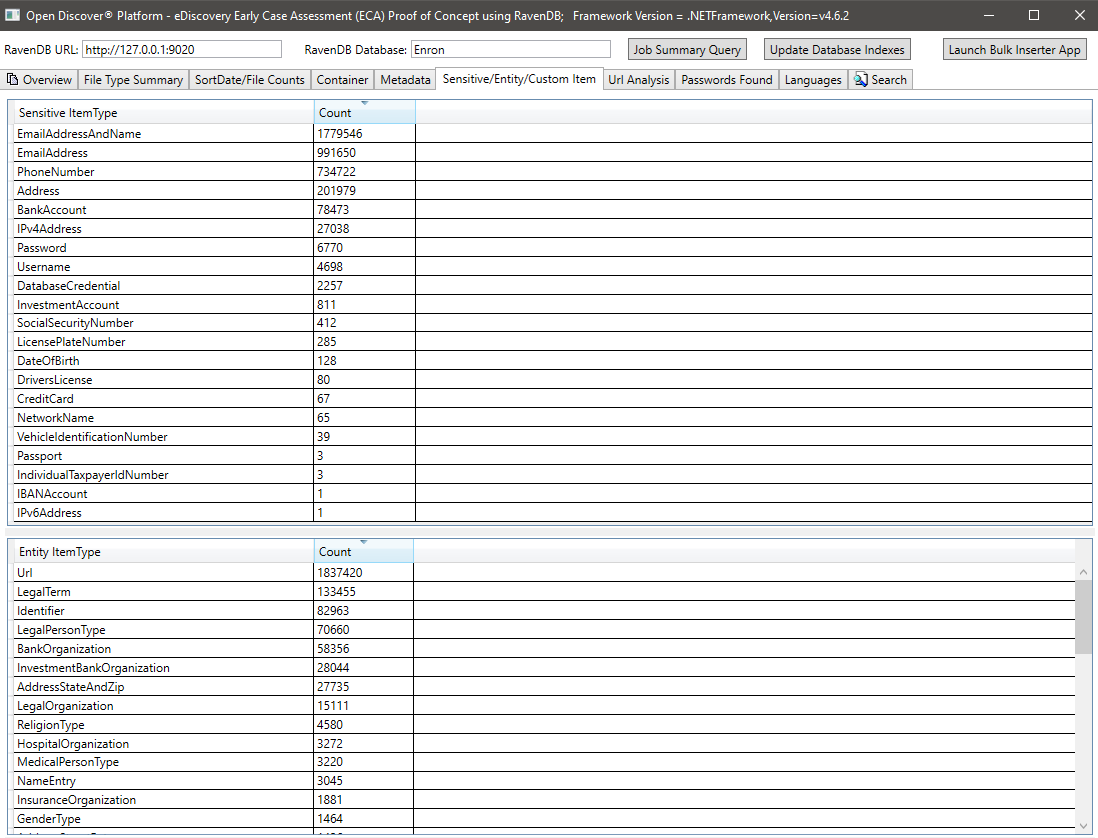
在所有文檔中發現的所有唯一URL的摘要(每個文檔的URL都可能有用,例如,如果公司想跟踪潛在的惡意URL入口點)。 Open Discover SDK檢測文檔超鏈接和文檔文本(即非Hyperlink)的所有URL:
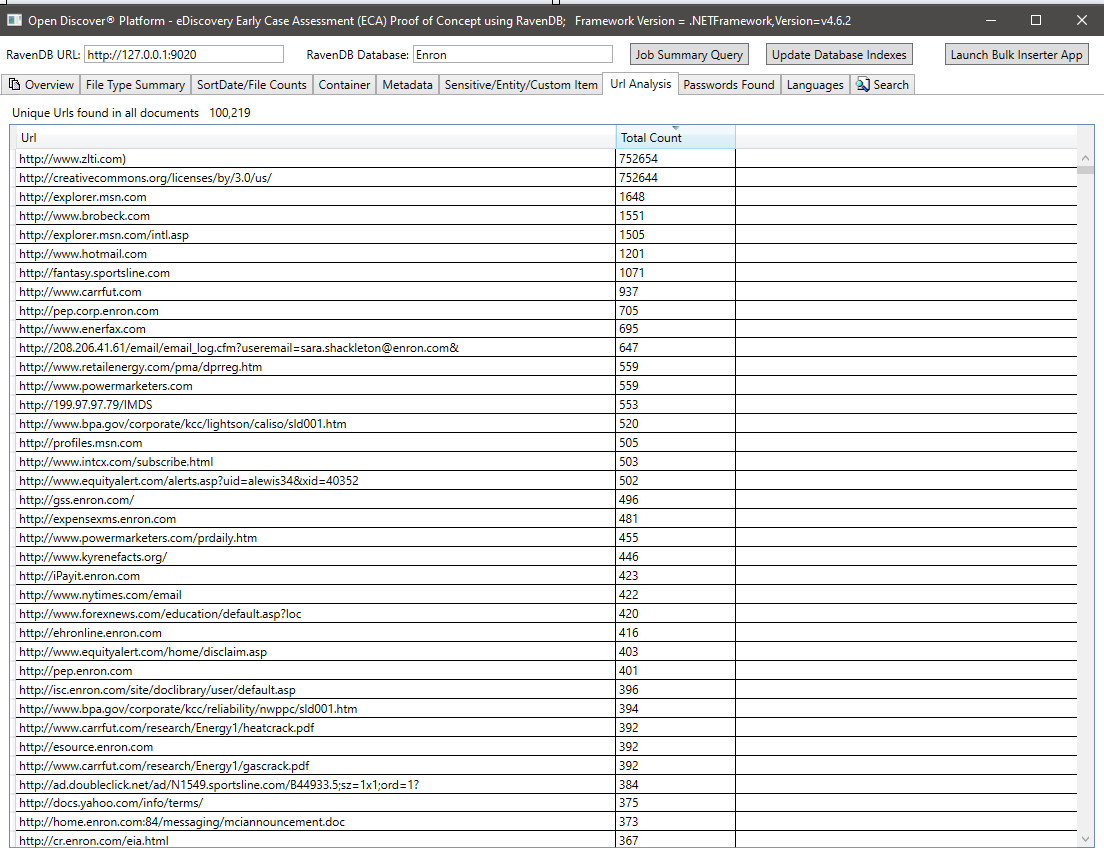
所有文檔中所有密碼的摘要。密碼和用戶名僅為25種內置的“敏感項目”類型中的2個,由Open Discover SDK/Platform支持。文檔中的密碼/用戶名憑據可能是安全風險,它們也可以用於重新處理任何具有“錯誤通信”的處理結果的文檔(由於同一家公司的員工經常將互相電子郵件發送給對方密碼以共享加密的辦公室文檔):
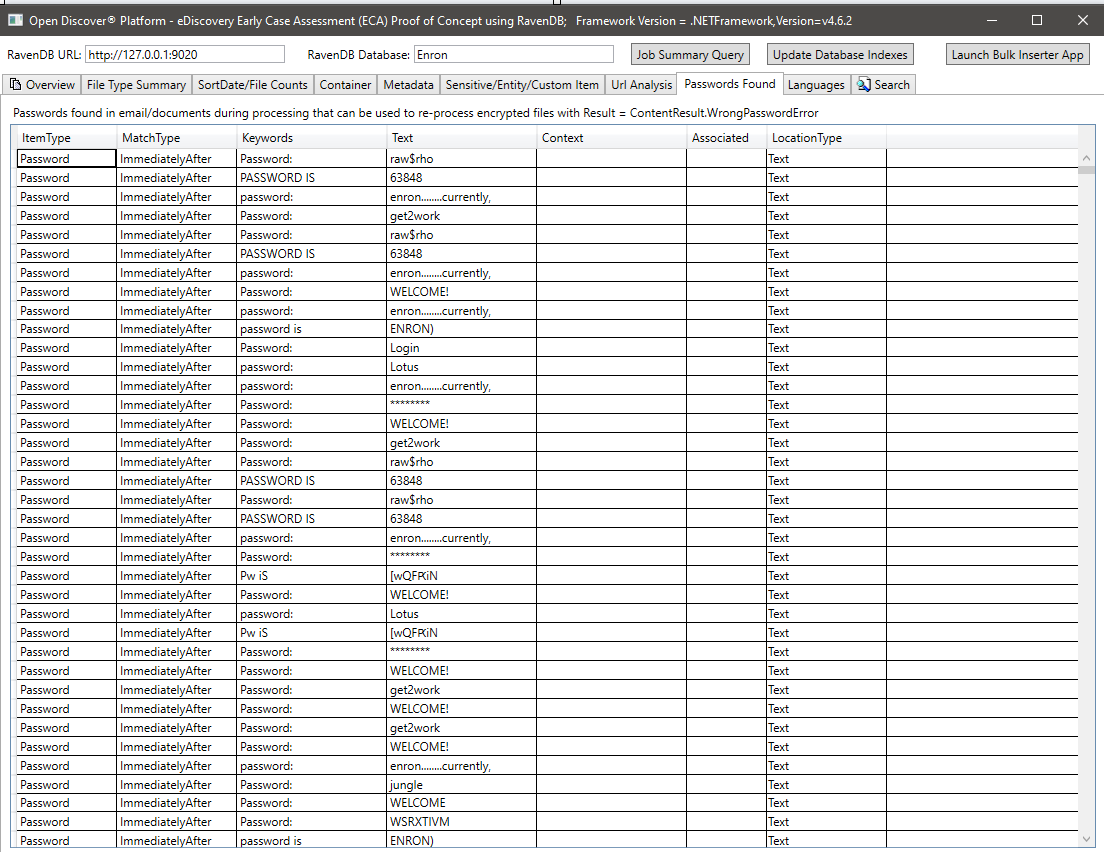
在處理後的文檔提取文本中檢測到的語言摘要:
示例全文搜索查詢(注意:Ravendb支持Lucene查詢):
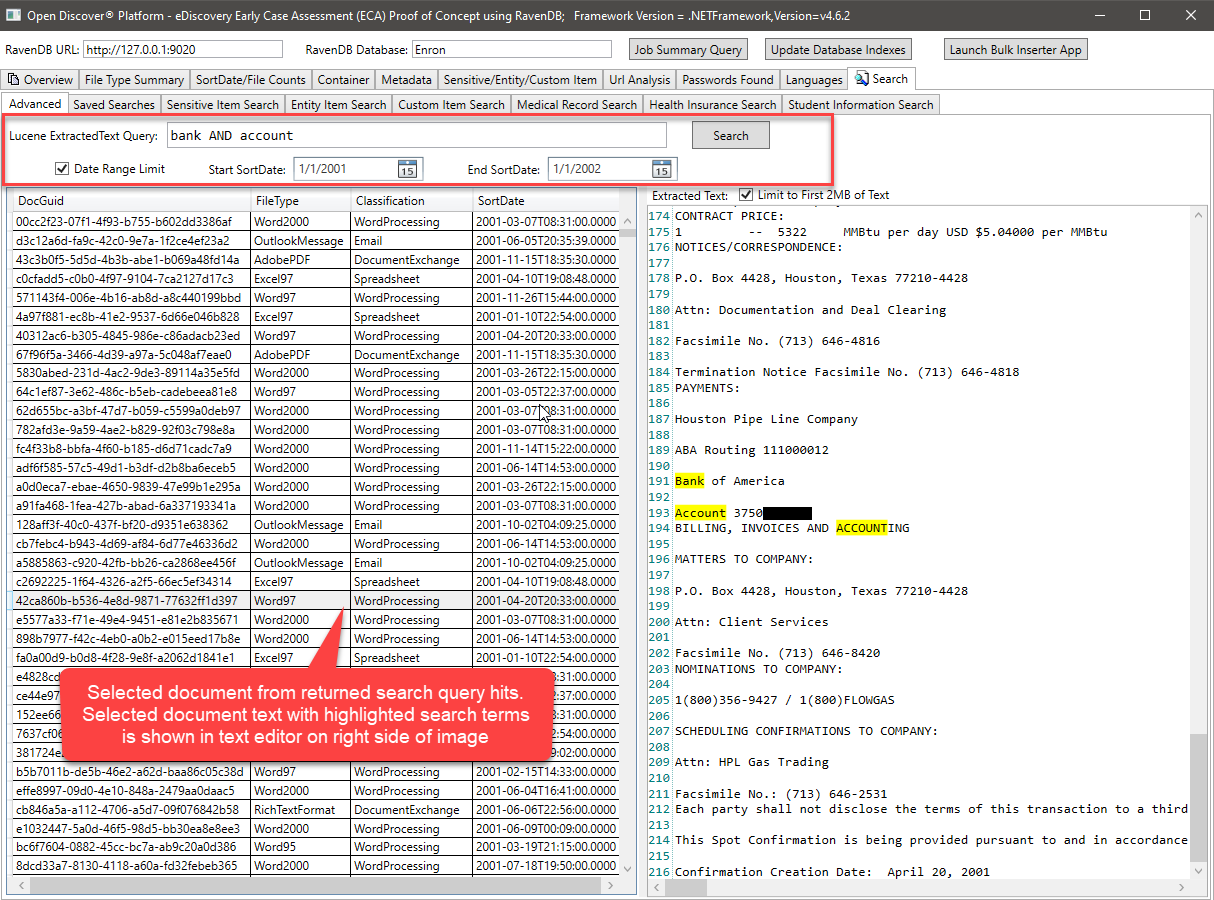
上述Lucene查詢,查詢Extractext字段並使用(選項)最小/最大文檔sortdate來過濾返回的搜索結果。也很容易通過文檔FileType或文檔格式分類(WordPrococessing/dreversheet/email/etc)添加結果過濾。執行Lucene查詢的C#代碼看起來像這樣:
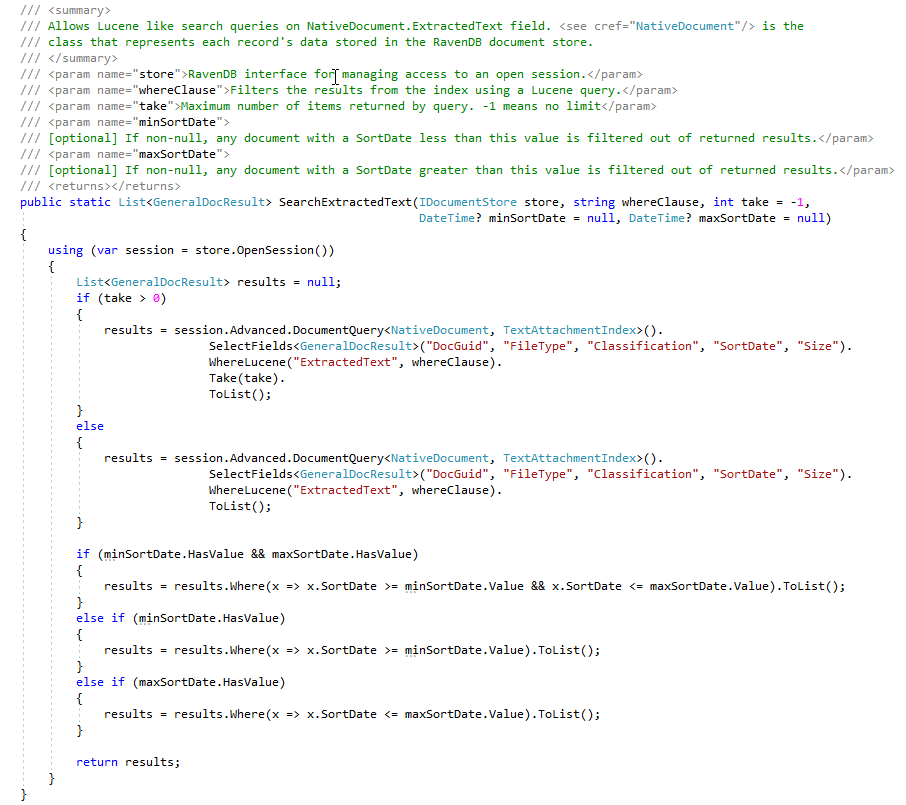
在ECA階段,法律審查律師喜歡創建許多不同的搜索查詢來查找響應文件。下面的屏幕截圖顯示了一些保存的Lucene查詢和結果(文檔命中次數和文檔總數)。請注意,這些用戶創建的搜索中的文檔計數包含重複的文檔計數,儘管我們的ravendb索引計算了重複文檔的數量,但對於此概念證明,我們尚未在文檔存儲中“標記”文檔,其中flag a flag表示flag tagration/doplate(用戶是一個'todo')
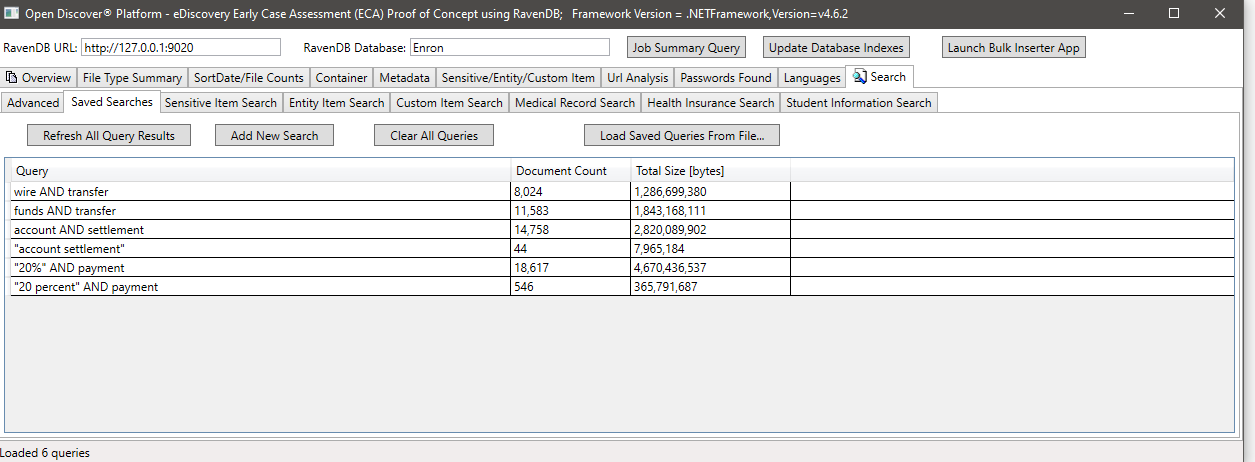
示例通過sensiviteMtype(識別敏感項目類型的檢測到的敏感對象的屬性)搜索,在此示例中,我們搜索所有具有類型sensisiveItemType.bankaccount的敏感項目的文檔:
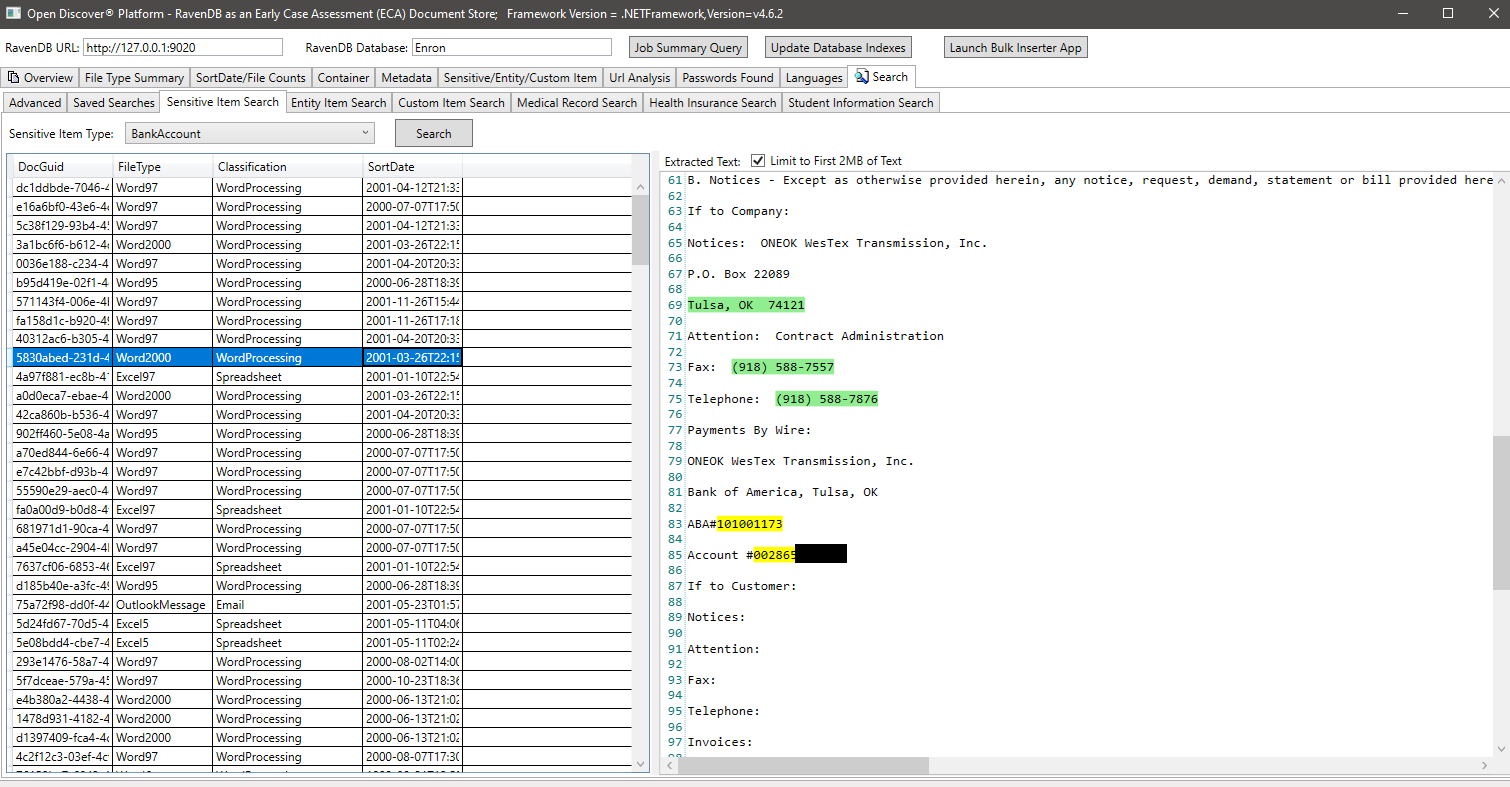
通過EntityItemType(檢測到的EntityItem對像上標識實體類型的屬性的屬性)的示例搜索,在此示例中,我們搜索所有具有類型EntityItemtype.patientnameentry的實體項目:PatientNameEntry:
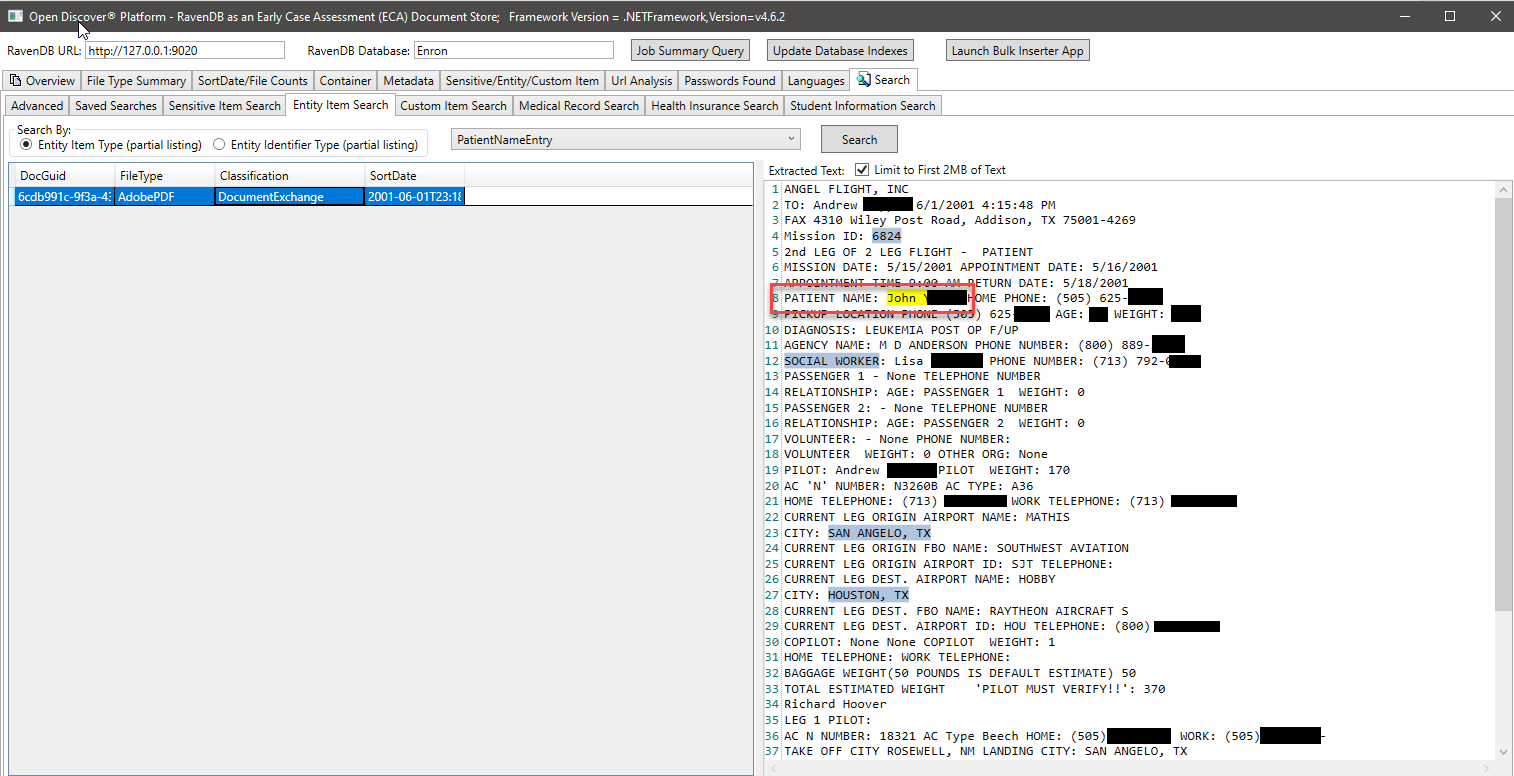
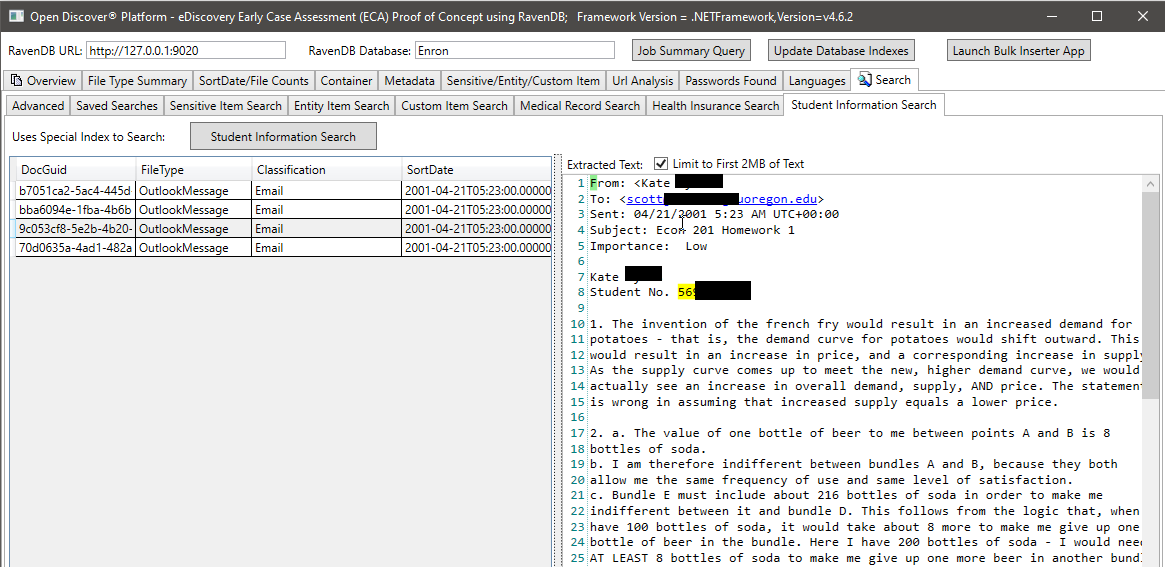
在下面的屏幕截圖中,我們使用了一個專門創建的RavendB索引,該索引索引了與學生信息有關的特定開放式SDK提取的實體類型,以查找可能具有學生信息的文檔(在屏幕截圖,學生的名字和學生ID中,學生ID被塗黑了,學生ID似乎是2000年以前常見的社會保障編號)。同樣,我們還有其他特殊索引來搜索病歷和患者信息:
OpenDiscover®平台輸出存儲在文檔數據庫(例如Ravendb)中的輸出可能會導致非常強大且迅速開發的法律早期案例評估(ECA)應用。此外,諸如以下應用程序也可以快速開發:
如果此案例研究使用了關係數據庫,而不是像Ravendb這樣的文檔數據庫,則該數據庫架構設計和商店程序開發將花費數月的時間,而不是作者花費了2週的時間來製定早期案例評估(ECA)的概念證明。


