OpenDiscoverPlatformCaseStudy
1.0.0
有关.NET示例GITHUB存储库,请参见OpenDiscover®SDK
打开的Discover Platform API的一个实例通常能够以40-70 GB/小时的速率处理文档集*(*速率将取决于数据集中的用户硬件和文件类型)。与大多数Ediscovery软件(例如,处理过程中的敏感项目/实体检测以及处理过程中)相比,它在处理文档方面非常快,同时提取更多内容。开放的Discover Platform API演示应用程序PlatformApideMo.exe用于处理Anron Outlook PST数据集。 PlatformApideMo.exe演示应用程序包含平台API文档处理类的一个实例。示例PlatformApidemo.exe处理输出的屏幕截图显示在下一节中。
PlatformApideMo.exe与Open Discover平台评估一起分发:
在最近的性能测试中,开放Discover SDK将53 GB Enron Microsoft Outlook PST PST数据集处理,并且大量插入了平台API输出(Text/Metadata/sensistive(PXI)项目/等),使用一台4核Windows Desktop PC,将平台API输出(text/metadata/stemitive(pxi)项目/等)插入了RAVENDB。
** This case study processing rate was for the .NET 4.62 version of SDK, the new .NET 6 version is > 100% faster on average, all the PST processing tasks on the .NET 6 version of OpenDiscoverPlatform processed their PST dataset tasks between 90-100+GB/hr rates (based on input size) WITH sensitive item detection enabled (processing rates are hardware dependent - in these numbers we used a single带有Intel i7 CPU和16GB RAM的台式PC。
下面的屏幕截图显示了从其Outlook PST容器中提取的电子邮件项目(及其附件),并由Platformapidemo.exe应用程序处理。该电子邮件来自Enron Microsoft Outlook PST之一。图像左侧的树视图控件显示了所有处理过的文档/容器的父/子层次结构,然后单击树控件中的项目将显示其提取的内容。对于树视图中选定的Outlook电子邮件项,我们可以看到它具有6个MS Office Word文档作为从电子邮件中提取的附件。每个附件/嵌入式项目都提取了其内容(无论多么复杂,处理都会完全展开任何父母的层次结构)。注意文件格式标识结果,计算出“ sortdate”,各种文档哈希,提取的元数据和图像右上方的其他选项卡项目,其中包含其他提取内容:
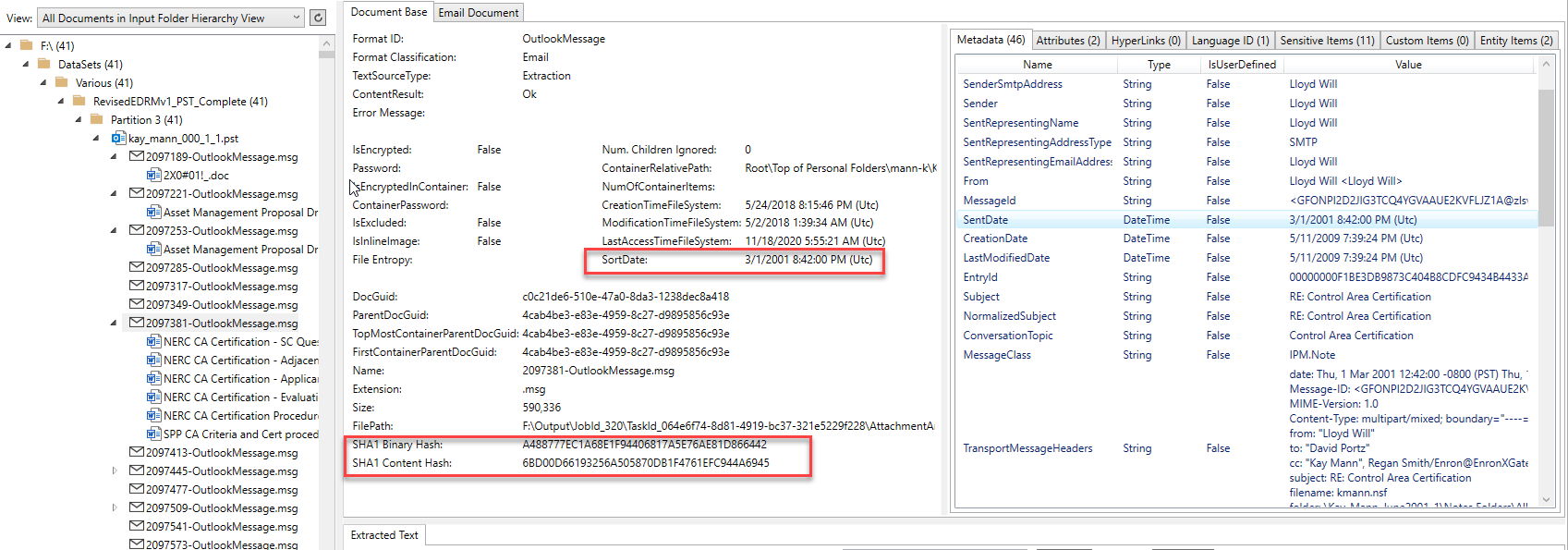
通过电子邮件发送特定内容,例如所有收件人和额外的哈希:
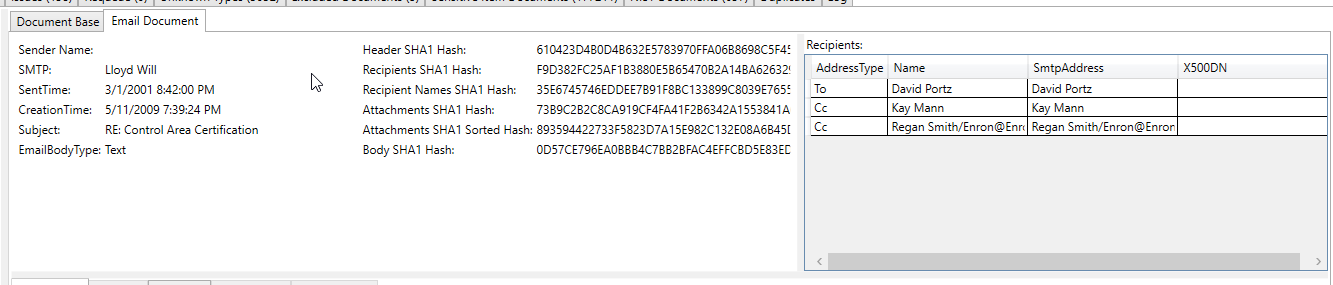
此处理后的电子邮件屏幕截图显示了一个在电子邮件提取的文本中提取/识别为“敏感项目”的银行帐号(所有提取的文本和所有元数据都被扫描以备敏感项目):
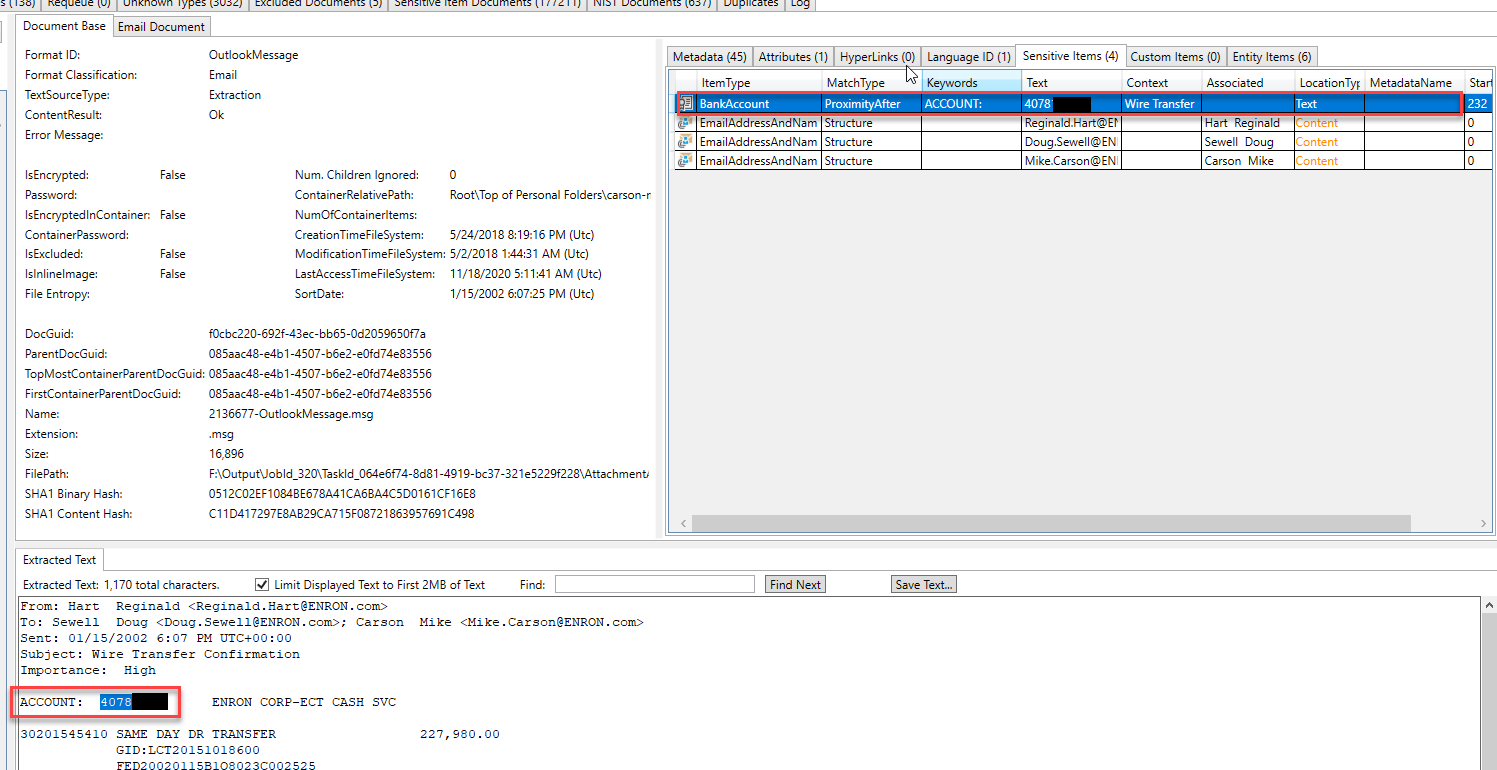
一些“实体”在另一封电子邮件中识别和提取。通过检查此电子邮件中发现的实体类型,我们可以推测该电子邮件正在讨论法律问题:
下面的屏幕截图显示了Ravendb Studio中的Anron数据库,该数据库填充了平台API处理的输出。 Ravendb中存储的一些数据库文档字段只能适合屏幕截图,还有更多的字段。带有红色边框注释的列名是对象的集合:
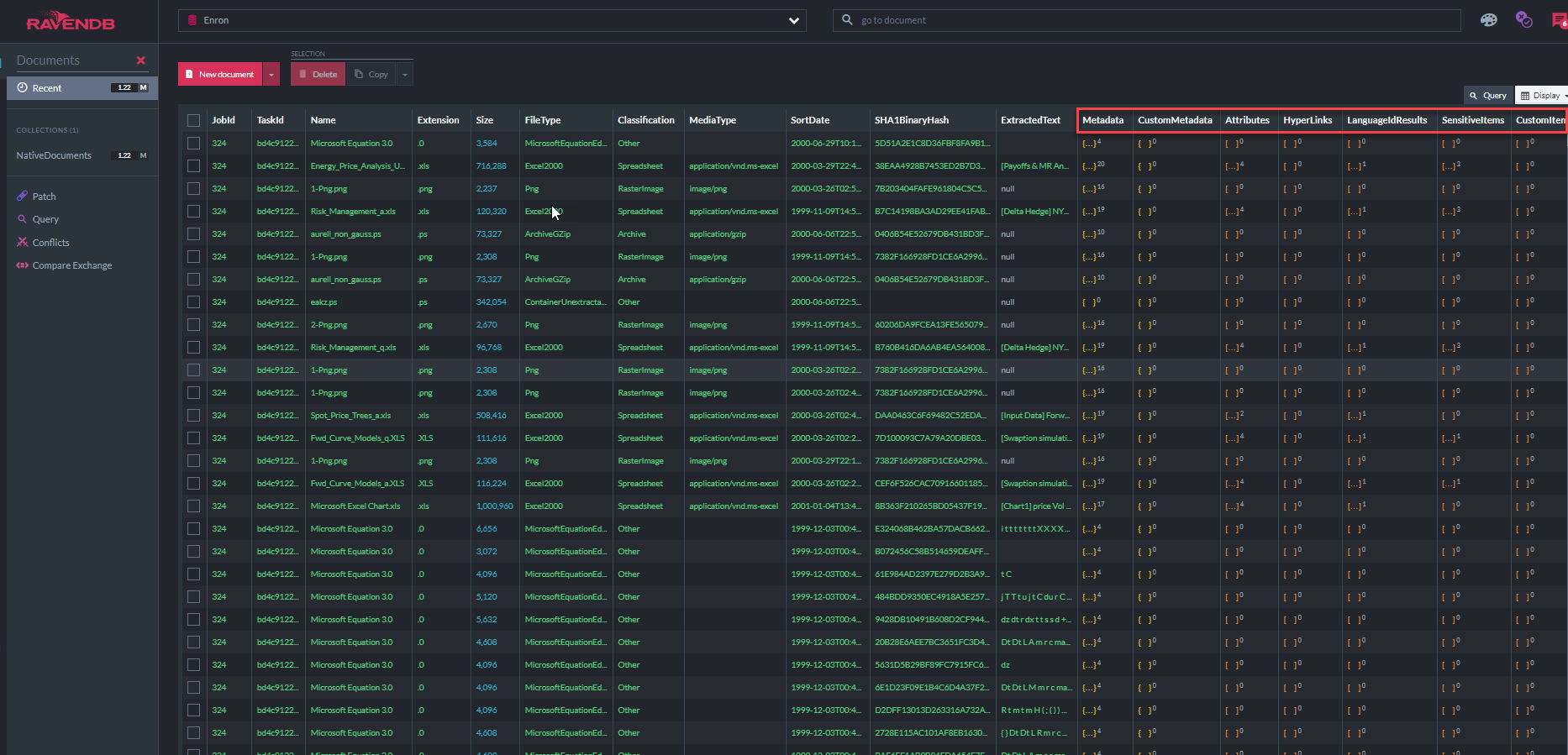
下面的屏幕截图显示了31个Ravendb索引中的一些“ ECA演示应用程序”用于查询文档存储的索引(请注意,“ Metadatatapropertyindex”表明该数据库中存储了3770万个元数据属性,大多数是电子邮件元数据,此外还有所有提取的文本。
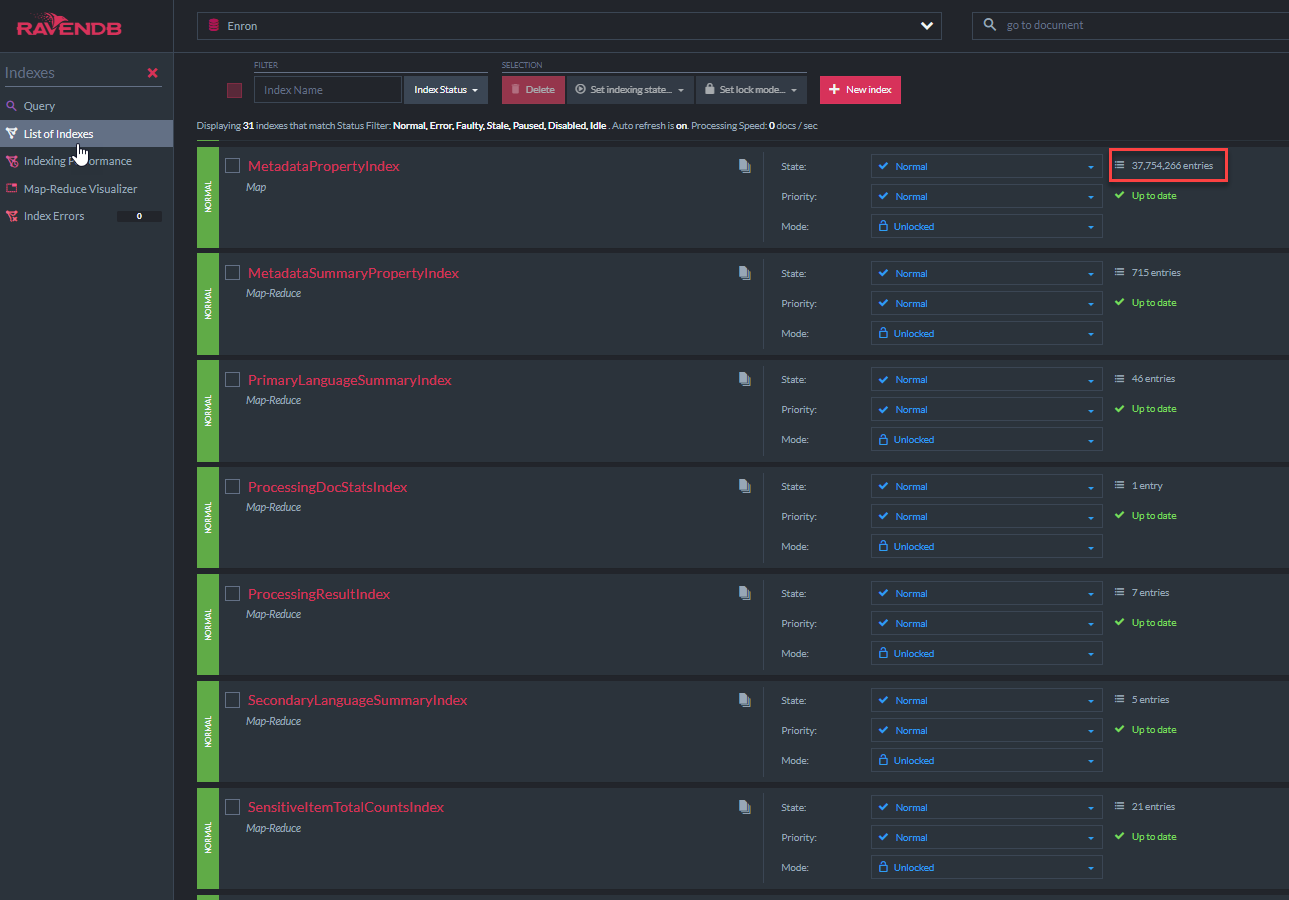
下面显示了“元数据帕特基inindex” C#类代码。该索引类来自Ravendb的AbstractIndexCreationTask(此演示中的所有其他索引)。该索引将允许所有元数据字段上的Lucene'Like'查询。存在类似的nativedocument.custommetadata:
所有C#定义的RavendB索引都通过简单的RavendB API呼叫从“ ECA Demo App”中的RavendB Enron数据库中创建。
下面的屏幕截图显示了189 Microsoft Outlook PST Enron数据集的处理摘要统计信息(总共处理的1,221,542封电子邮件和附件)。该数据集中的大多数电子邮件和附件都是重复的文档,因为事实是,在法律发现阶段收集数据的员工正在来回发送电子邮件 - 下图中所示的重复数据删除统计数据基于二进制/内容哈希,将来会更新此案例研究(我们将与RavendB Indexes一起更新该案例研究(包括ravendb Indexes),以包括“家庭” preditiation of Family preditiation'''''''''''''''''''''''''请注意文件格式分类饼图,特定文件格式饼图的摘要以及处理结果的摘要(具有OK的值/错误Passeword/dataError/等的枚举类型)饼图。
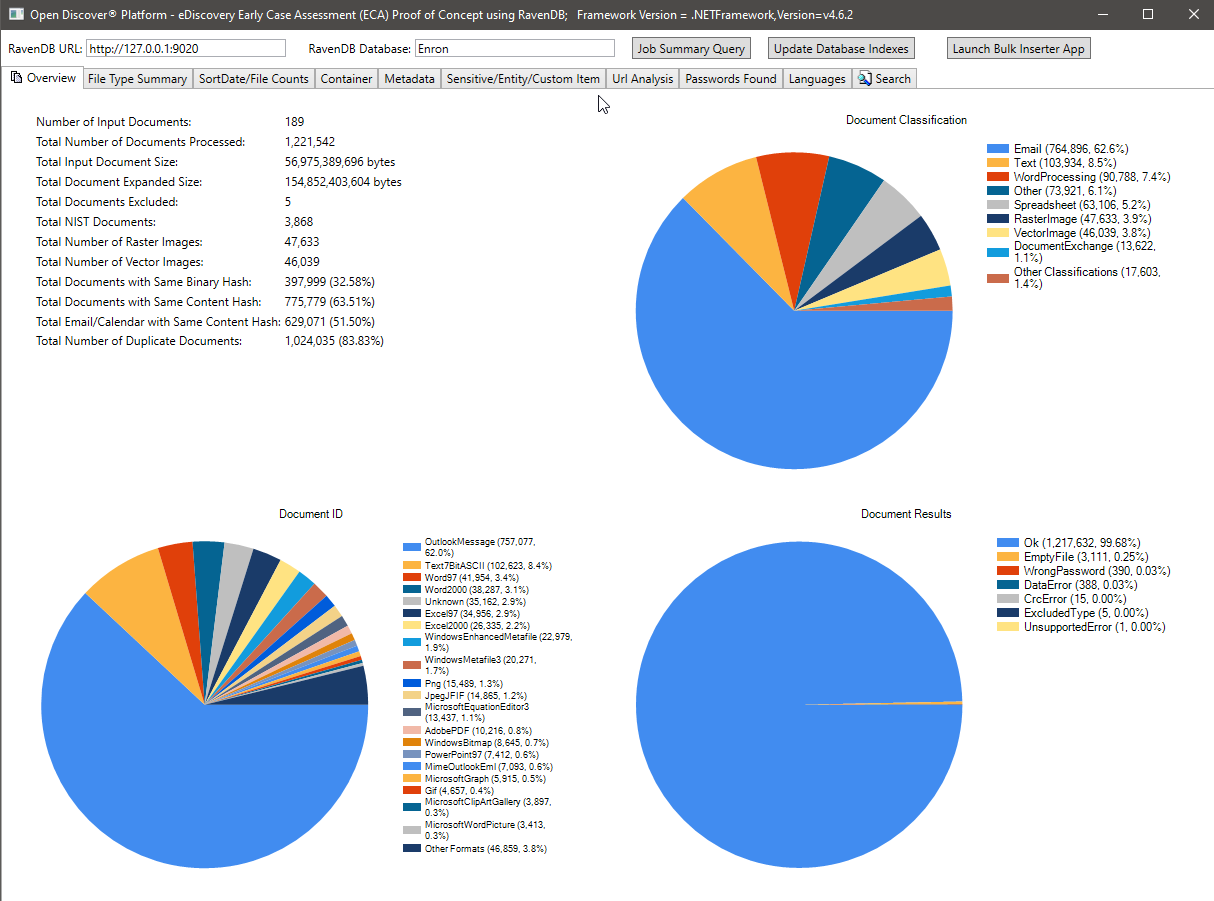
文件计数按顺序摘要图表:
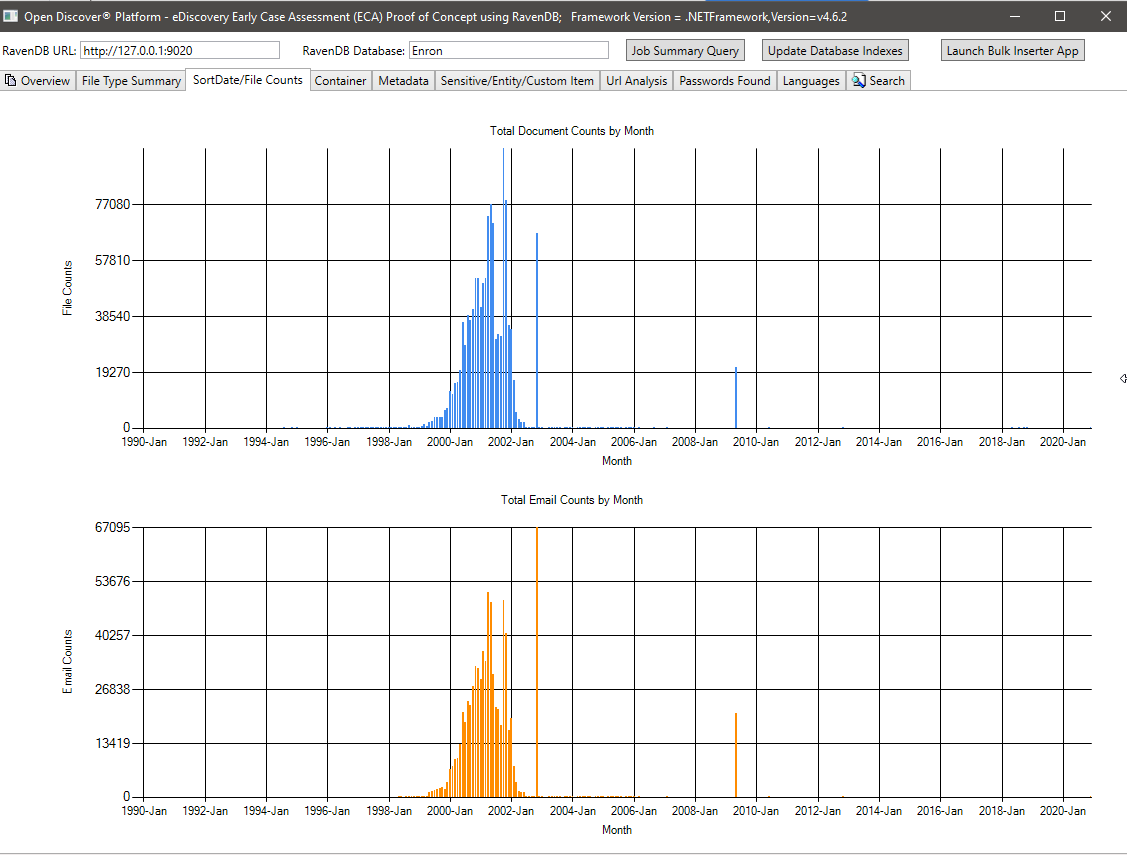
元数据摘要(元数据字段名称/文档总数)-715所有文档中已知的唯一元数据字段名称和636个自定义(用户定义)元数据字段。该查询可以帮助法律案件经理知道该集合中有哪些元数据字段可在:
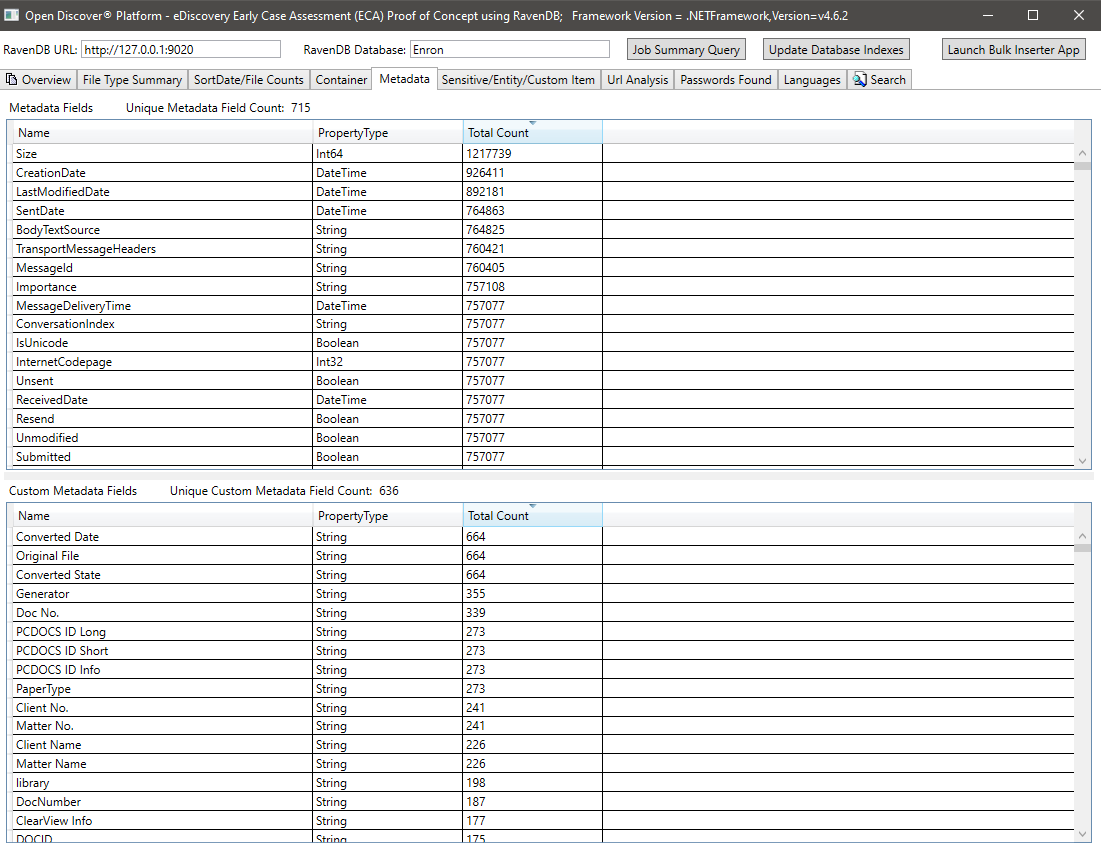
所有文档的敏感项目/实体项目摘要:
在所有文档中发现的所有唯一URL的摘要(每个文档的URL都可能有用,例如,如果公司想跟踪潜在的恶意URL入口点)。 Open Discover SDK检测文档超链接和文档文本(即非Hyperlink)的所有URL:
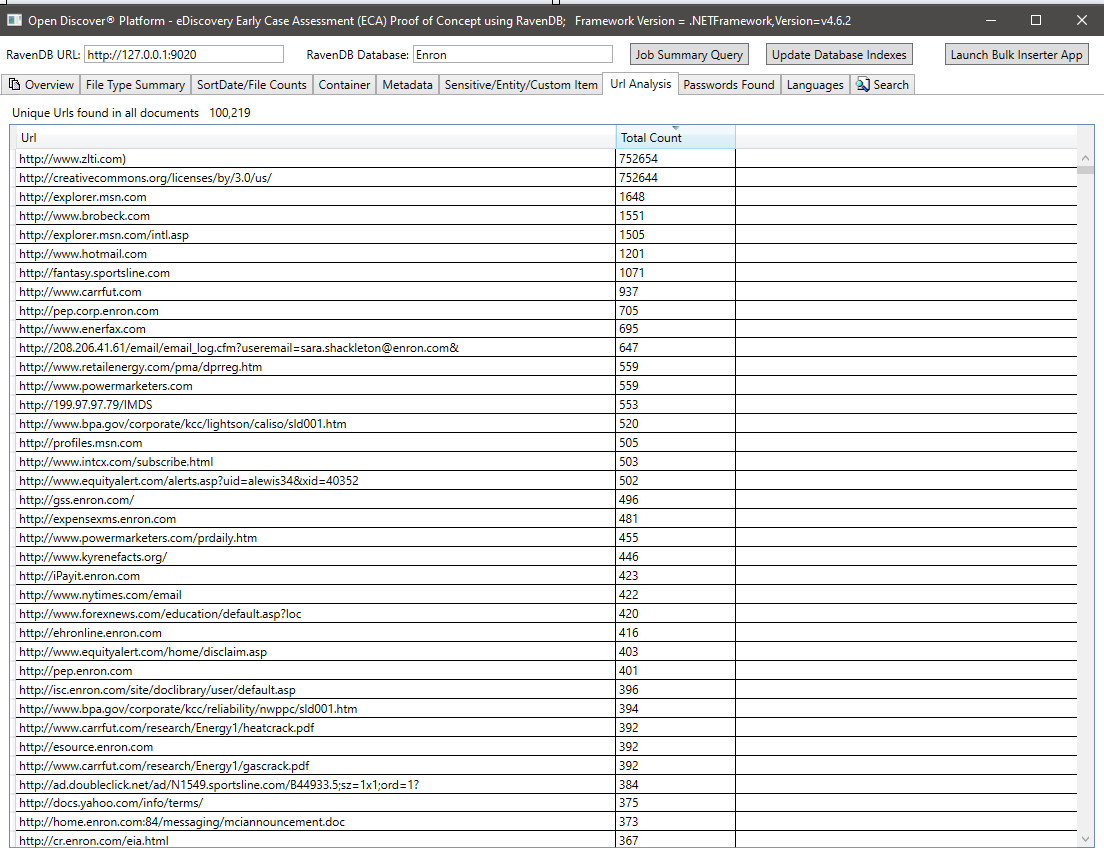
所有文档中所有密码的摘要。密码和用户名仅为25种内置的“敏感项目”类型中的2个,由Open Discover SDK/Platform支持。文档中的密码/用户名凭据可能是安全风险,它们也可以用于重新处理任何具有“错误通信”的处理结果的文档(由于同一家公司的员工经常将互相电子邮件发送给对方密码以共享加密的办公室文档):
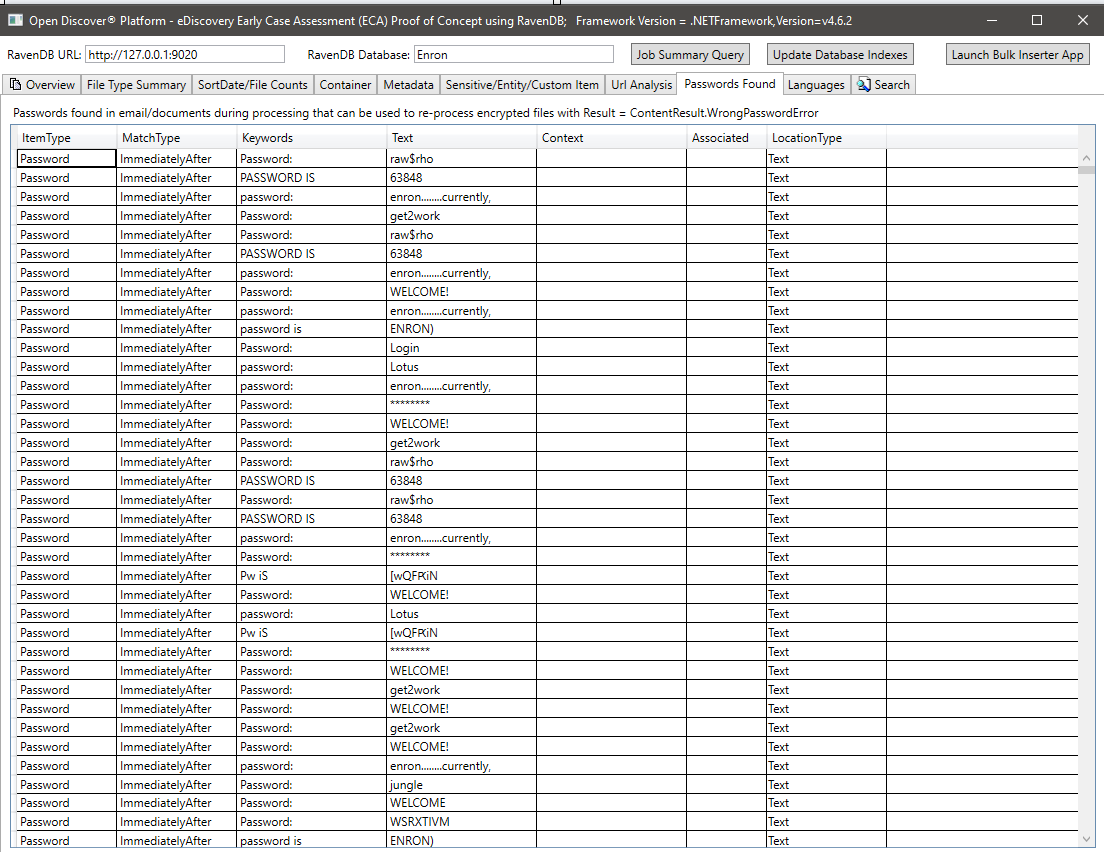
在处理后的文档提取文本中检测到的语言摘要:
示例全文搜索查询(注意:Ravendb支持Lucene查询):
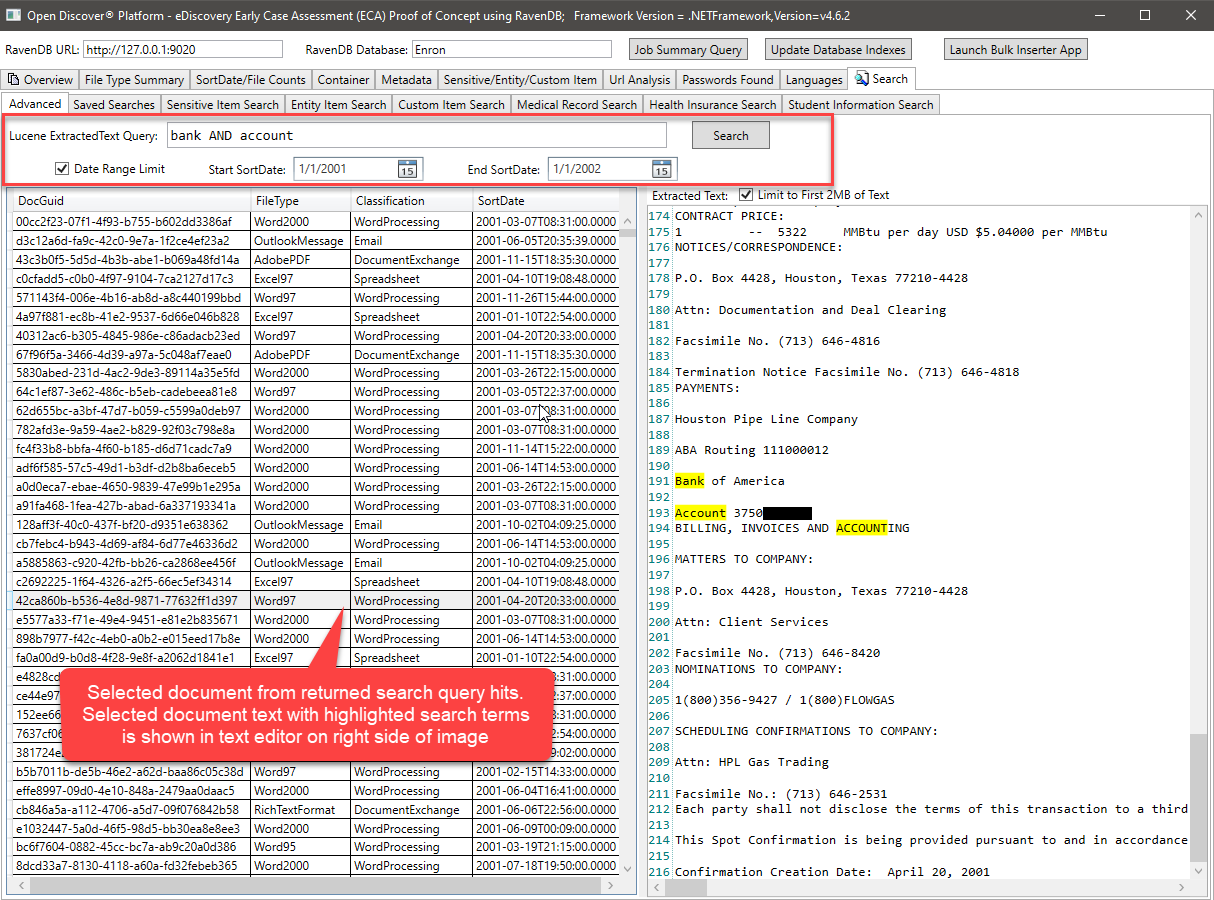
上述Lucene查询,查询Extractext字段并使用(选项)最小/最大文档sortdate来过滤返回的搜索结果。也很容易通过文档FileType或文档格式分类(WordPrococessing/dreversheet/email/etc)添加结果过滤。执行Lucene查询的C#代码看起来像这样:
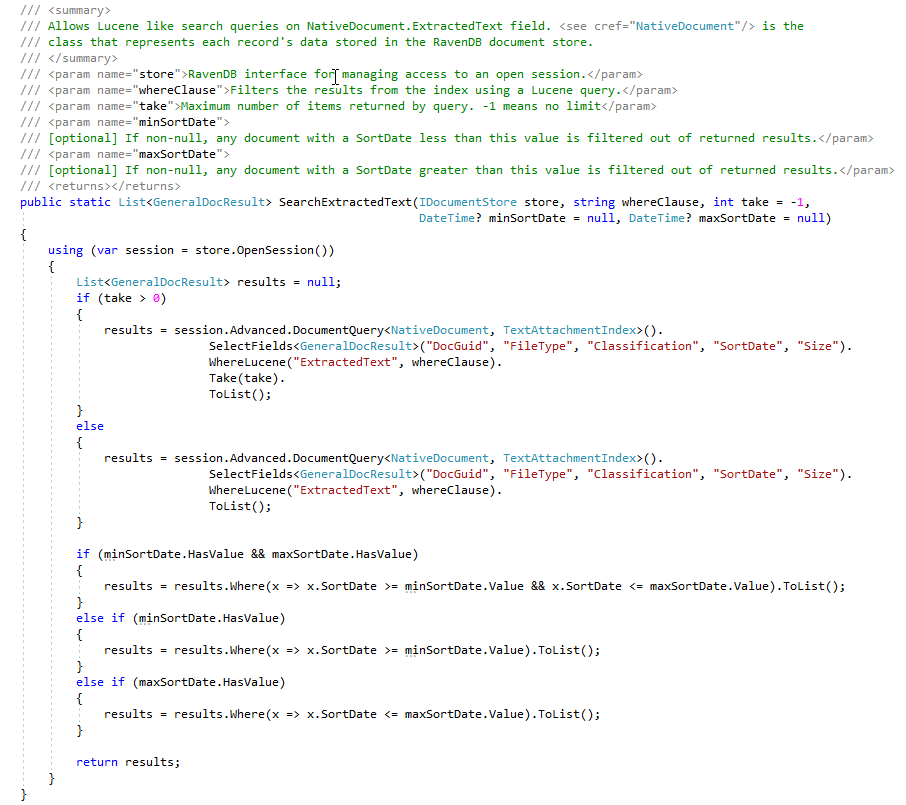
在ECA阶段,法律审查律师喜欢创建许多不同的搜索查询来查找响应文件。下面的屏幕截图显示了一些保存的Lucene查询和结果(文档命中次数和文档总数)。请注意,这些用户创建的搜索中的文档计数包含重复的文档计数,尽管我们的ravendb索引计算了重复文档的数量,但对于此概念证明,我们尚未在文档存储中“标记”文档,其中flag a flag表示flag tagration/doplate(用户是一个'todo')
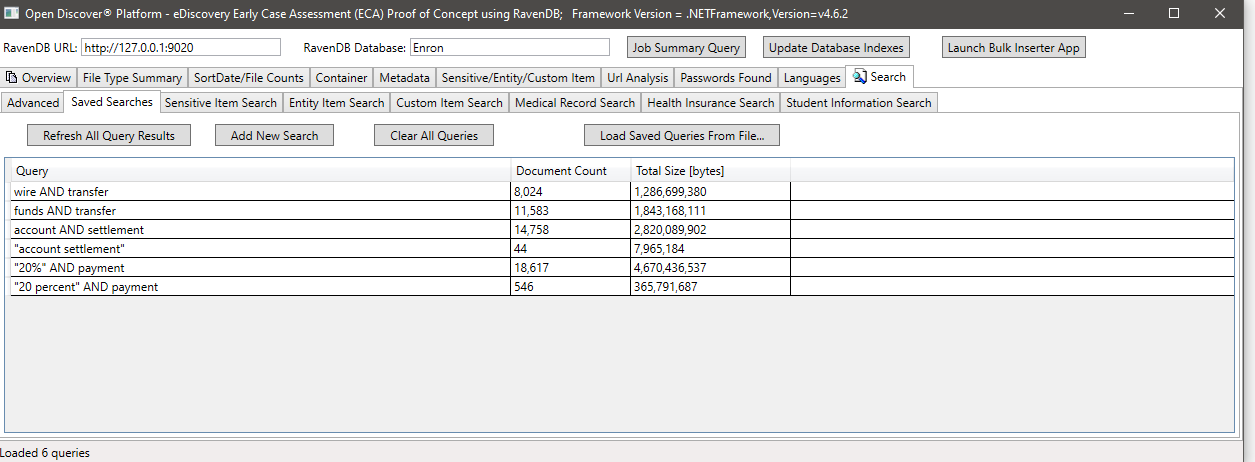
示例搜索sensiviteMtype(识别敏感项目类型的检测到的敏感对象的属性),在此示例中,我们搜索所有具有类型sensisitiveItemType.bankaccount的敏感项目的文档:
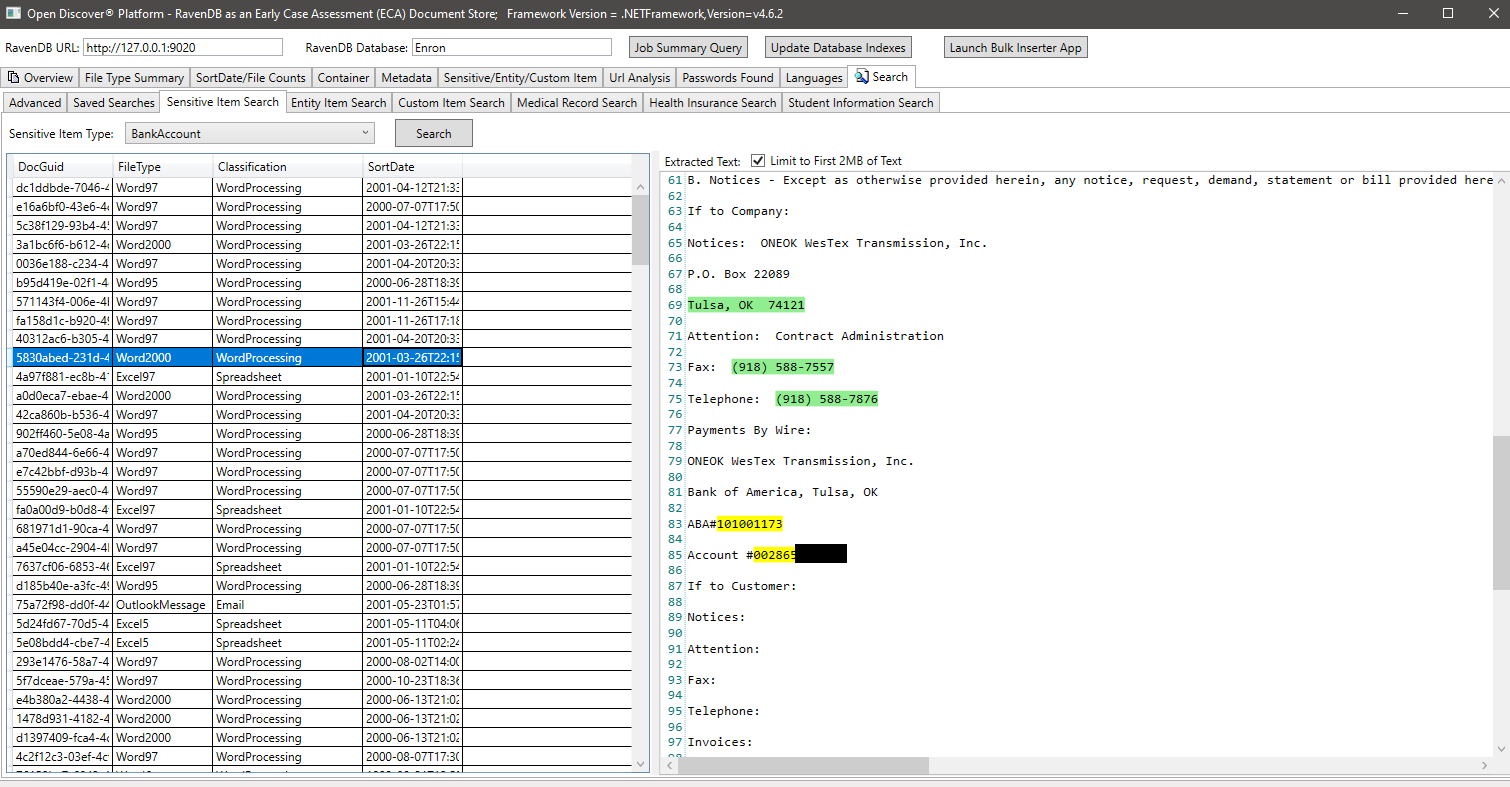
通过EntityItemType(检测到的EntityItem对象上标识实体类型的属性的属性)的示例搜索,在此示例中,我们搜索所有具有类型EntityItemtype.patientnameentry的实体项目:PatientNameEntry:
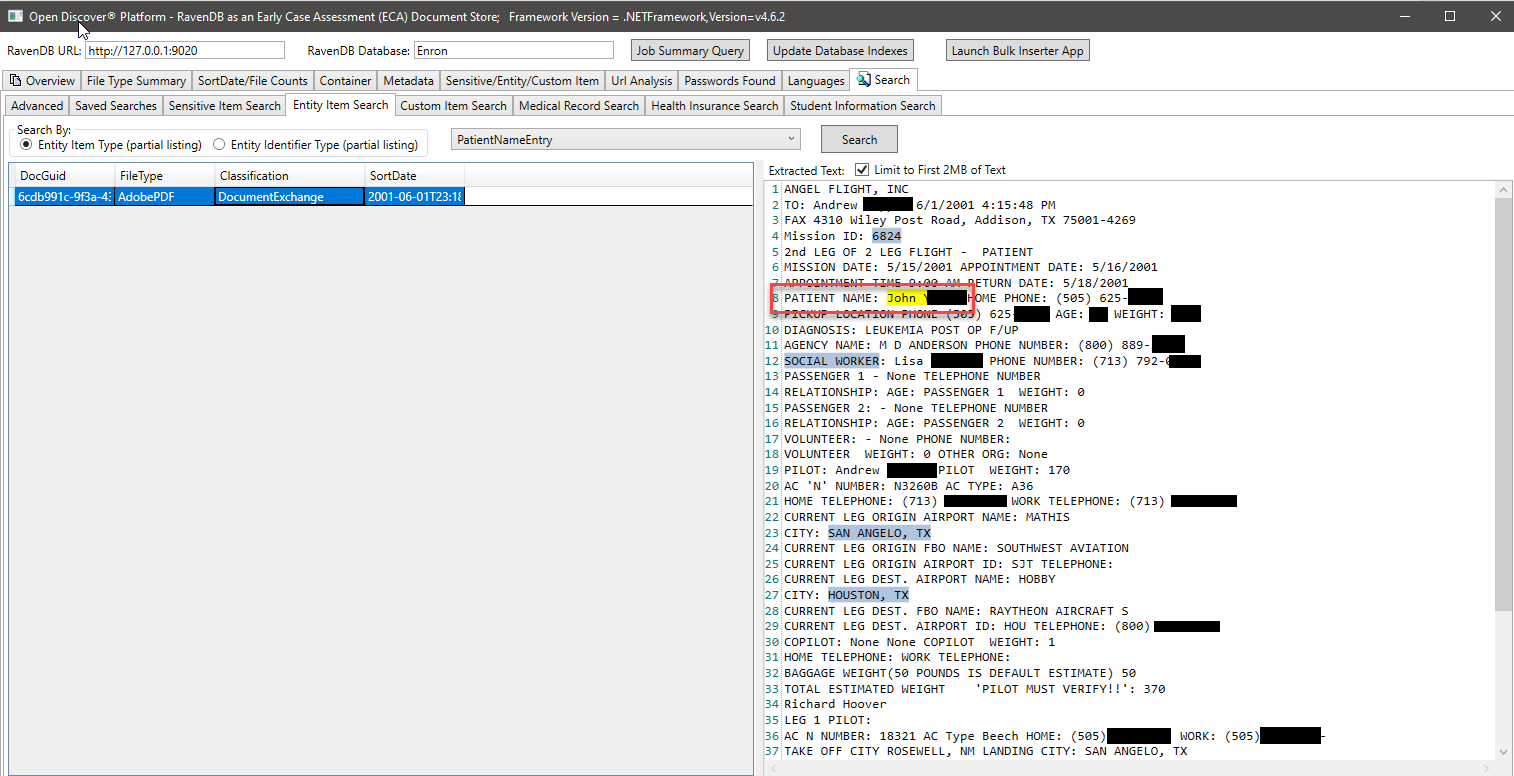
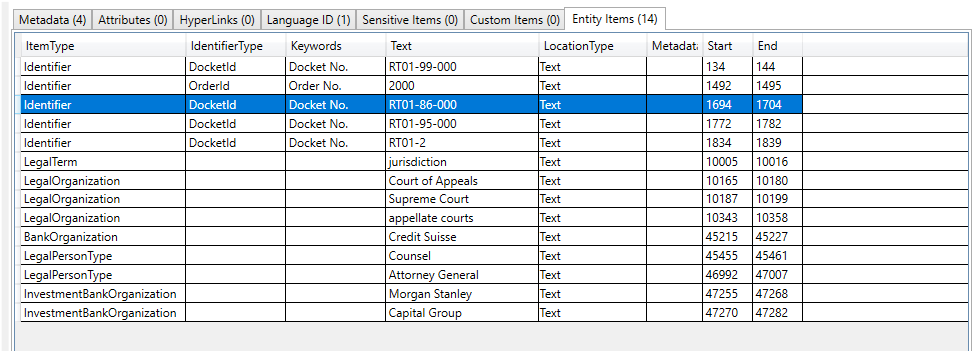
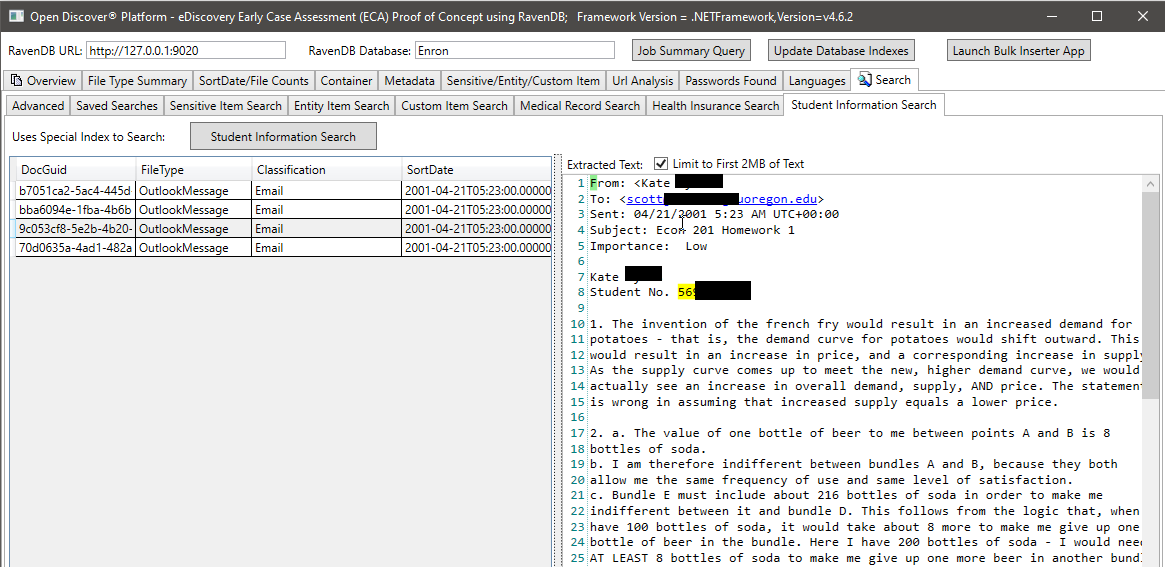
在下面的屏幕截图中,我们使用了一个专门创建的RavendB索引,该索引索引了与学生信息有关的特定开放式SDK提取的实体类型,以查找可能具有学生信息的文档(在屏幕截图,学生的名字和学生ID中,学生ID被涂黑了,学生ID似乎是2000年以前常见的社会保障编号)。同样,我们还有其他特殊索引来搜索病历和患者信息:
OpenDiscover®平台输出存储在文档数据库(例如Ravendb)中的输出可能会导致非常强大且迅速开发的法律早期案例评估(ECA)应用。此外,诸如以下应用程序也可以快速开发:
如果此案例研究使用了关系数据库,而不是像Ravendb这样的文档数据库,则该数据库架构设计和商店程序开发将花费数月的时间,而不是作者花费了2周的时间来制定早期案例评估(ECA)的概念证明。


