OpenDiscoverPlatformCaseStudy
1.0.0
Consulte Open Discover® SDK para .NET Exemplos Github Repository
Uma única instância da API da plataforma Open Discover é tipicamente capaz de processamento de conjuntos de documentos a 40-70 GB/taxa de hora* (* as taxas dependerão de hardware do usuário e tipos de arquivos no conjunto de dados). É muito rápido no processamento de documentos, ao mesmo tempo em que extrai mais conteúdo do que a maioria do software de descoberta (por exemplo, detecção de item/entidade sensível e denist-ing durante o processamento). Um aplicativo de demonstração de API da Plataforma Discover Open, PlatformApidemo.exe, foi usado para processar o conjunto de dados do ENRON Outlook PST. O aplicativo PlatformApidemo.exe de demonstração envolve uma instância da classe de processamento de documentos da API da plataforma. Tapas de tela do exemplo de plataformapidemo.exe Saída de processamento é mostrada na próxima seção abaixo.
O plataformApidemo.exe é distribuído com a avaliação da plataforma Open Discover, juntamente com:
Em um teste de desempenho recente, o Open Discover SDK processou o conjunto de dados PST do Microsoft Outlook de 53 GB do Microsoft Outlook e a em massa inseriu a saída da API da plataforma (TEXT/METADATA/Sensive (PXI) itens/etc) no RavendB em pouco mais de 30 minutos usando um PC Windows Desktop 4-Core.
** This case study processing rate was for the .NET 4.62 version of SDK, the new .NET 6 version is > 100% faster on average, all the PST processing tasks on the .NET 6 version of OpenDiscoverPlatform processed their PST dataset tasks between 90-100+GB/hr rates (based on input size) WITH sensitive item detection enabled (processing rates are hardware dependent - in these numbers we used a single PC para desktop com Intel i7 CPU e 16 GB de RAM).
A foto abaixo mostra um item de email (e seus anexos) que foi extraído de seu contêiner PST do Outlook e processado pelo aplicativo PlatformApidemo.exe. O email é de um dos PSTs da Enron Microsoft Outlook. O controle de visualização da árvore no lado esquerdo da imagem mostra a hierarquia pai/filho de todos os documentos/contêineres processados e clicar em um item no controle da árvore mostrará seu conteúdo extraído. Para o item de e -mail do Outlook selecionado na visualização da árvore, podemos ver que ele possui 6 documentos do MS Office Word como anexos que foram extraídos do email. Todo e qualquer item de anexo/incorporado também teve seu conteúdo extraído (o processamento de desenrolar totalmente qualquer hierarquia de filhos -filho, por mais complexa). Observe os resultados de identificação do formato do arquivo, calculado "SortDate", vários hashes de documentos, os metadados extraídos e outros itens de guia no lado superior direito da imagem que contêm outros conteúdos extraídos:
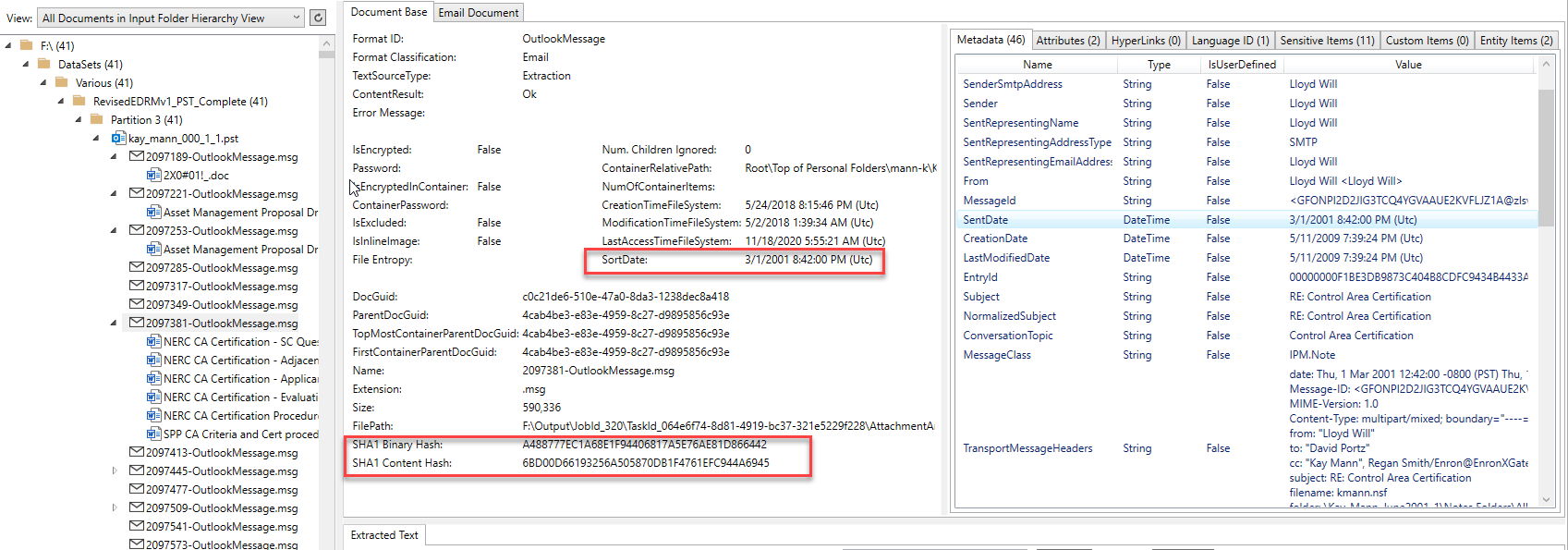
Email Conteúdo específico, como todos os destinatários e hashes extras:
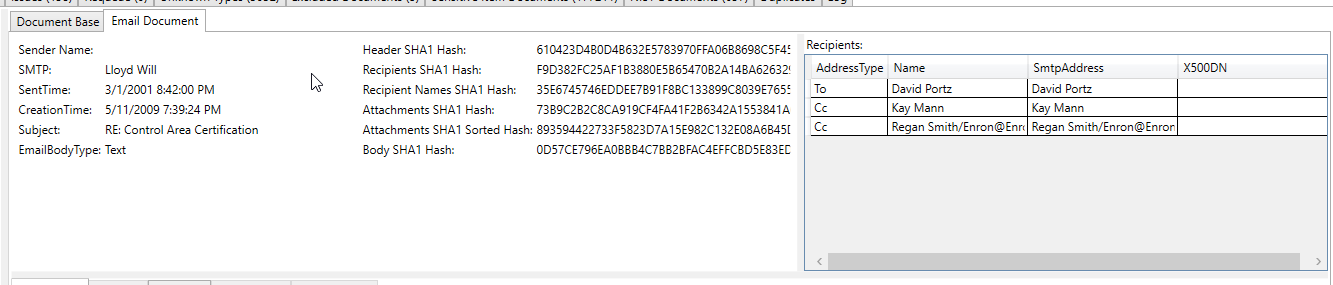
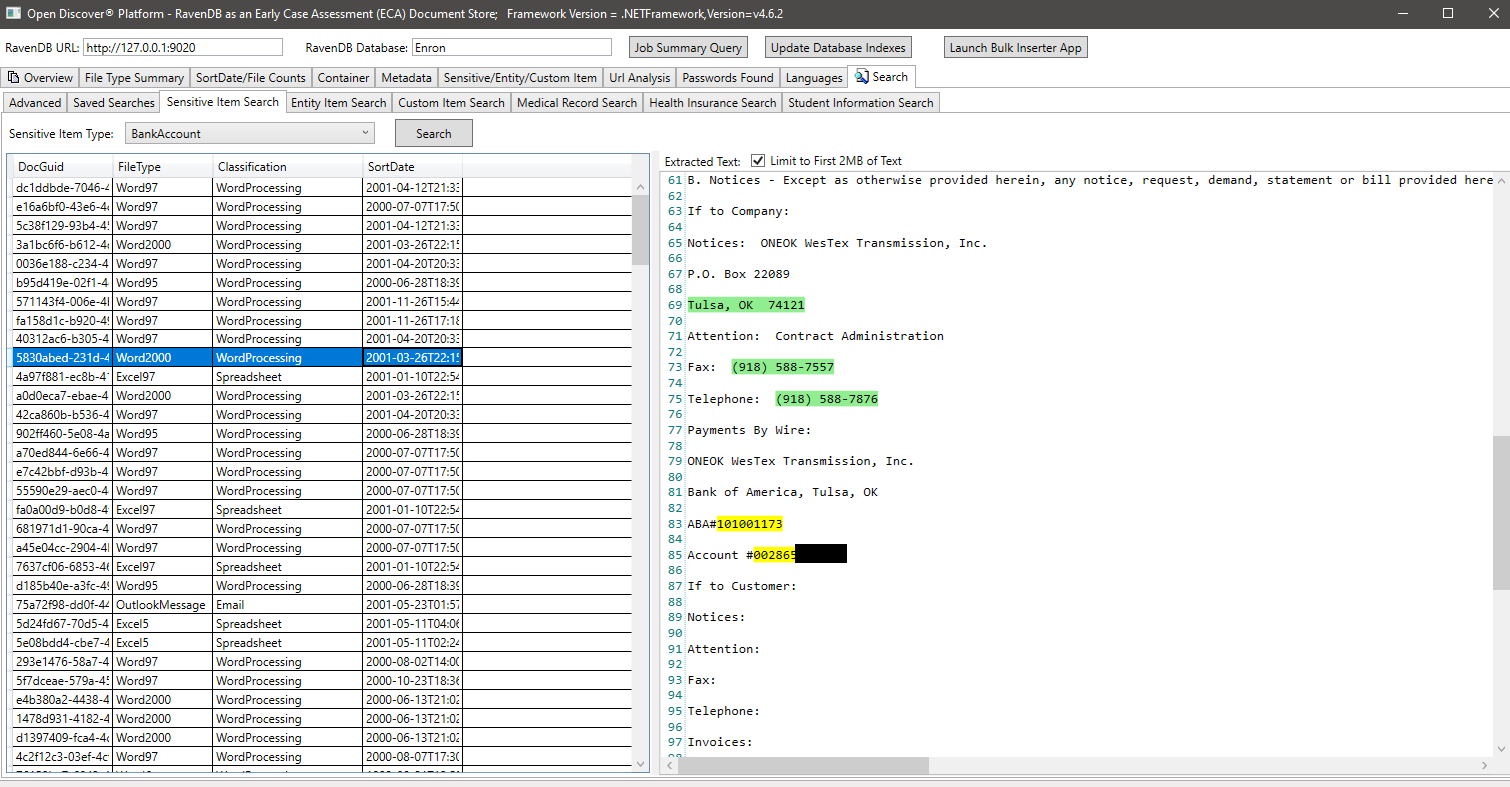
Esta captura de tela de email processada mostra um número de conta bancária que foi extraído/identificado como um "item sensível" no texto extraído do email (todo o texto extraído e todos os metadados são digitalizados para itens sensíveis):
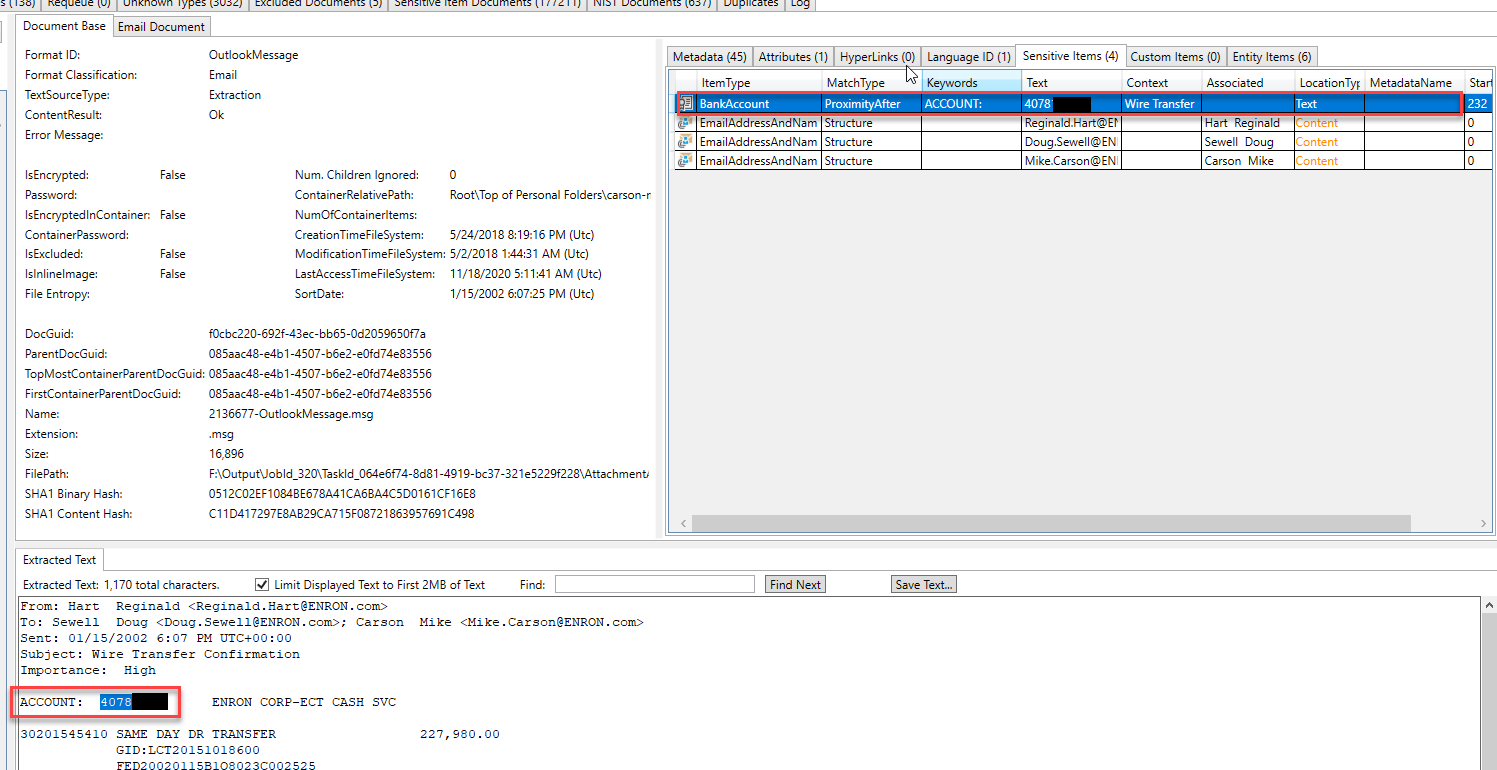
Algumas "entidades" identificadas e extraídas em um email diferente. Ao inspecionar os tipos de entidades encontradas neste e -mail, podemos supor que o email está discutindo um assunto legal:
A foto abaixo mostra o banco de dados da ENRON no estúdio Ravendb preenchido com a saída da API da plataforma. Somente alguns dos campos de documentos do banco de dados armazenados no Ravendb podem caber na foto da tela, há muito mais campos. Os nomes das colunas com uma anotação de borda vermelha são coleções de objetos:
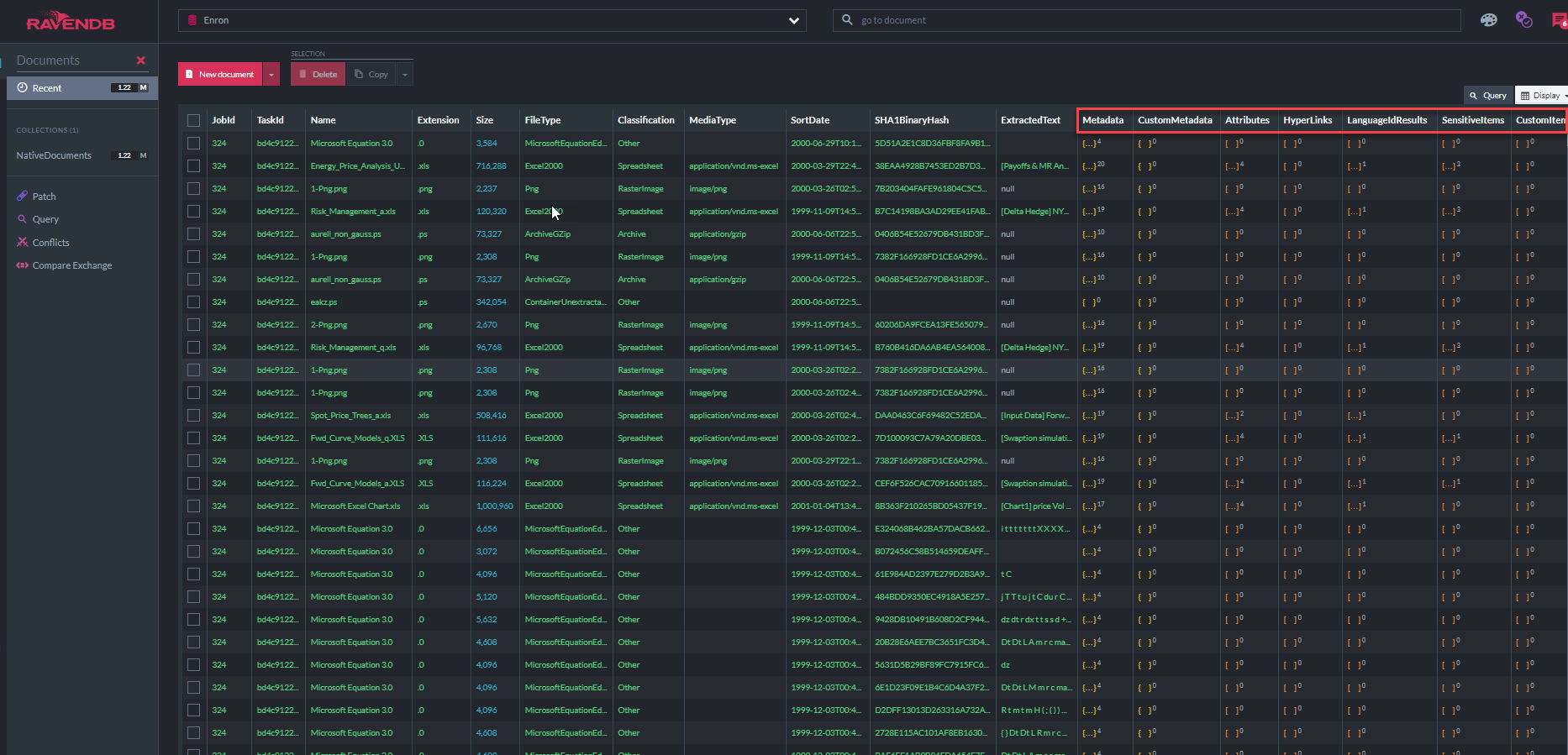
A captura de tela abaixo mostra alguns dos 31 índices de Ravendb que o "aplicativo de demonstração do ECA" usa para consultar o armazenamento de documentos (observe que o "MetadataPropertyIndex" mostra que existem 37,7 milhões de propriedades de metadados armazenadas nesse banco de dados, principalmente metadados por email, além de todo o texto extraído):
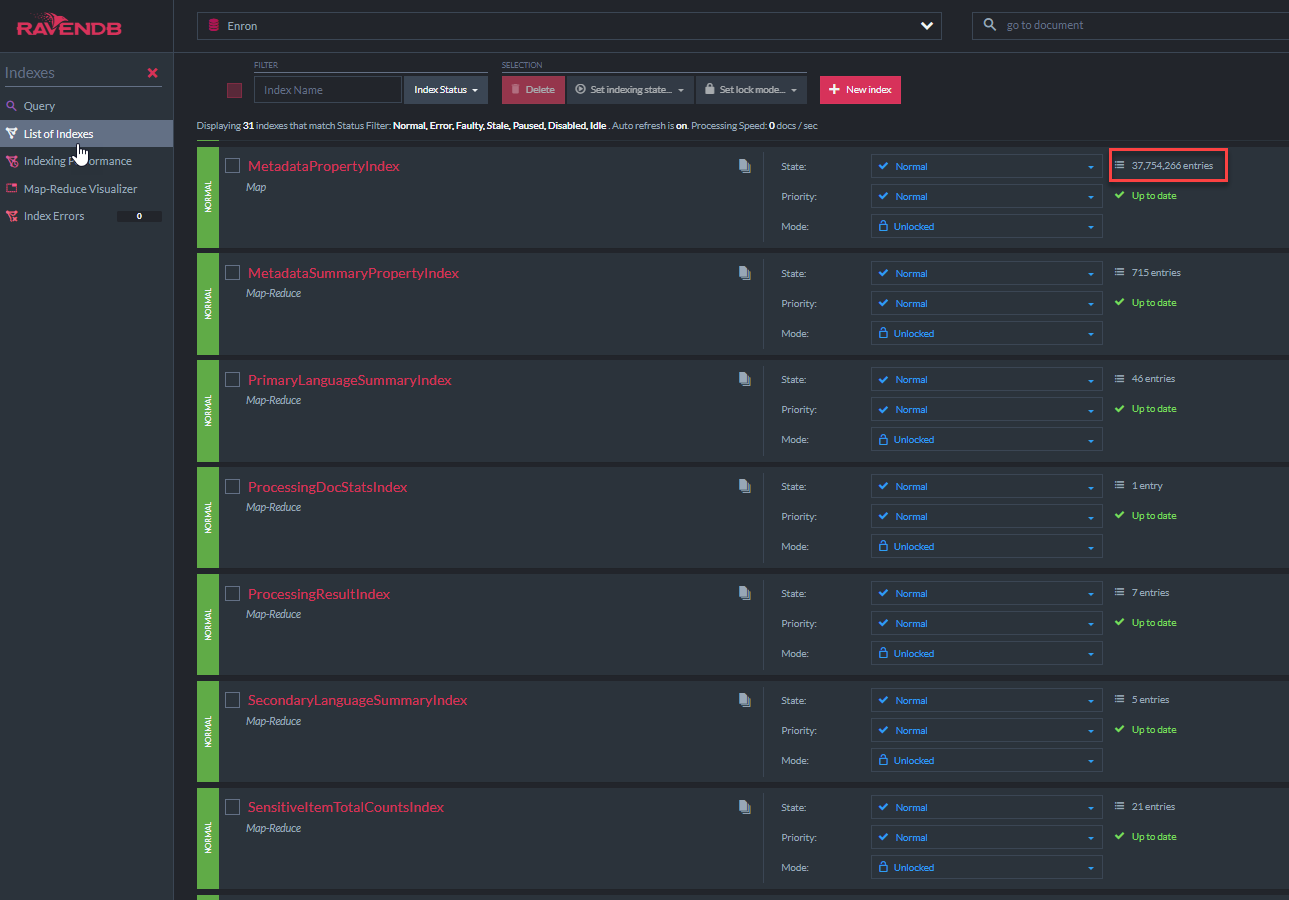
O código de classe "MetadataPropertyIndex" C# é exibido abaixo. Esta classe de índice deriva do AbstracIndexCreationTask de Ravendb (assim como todos os outros índices nesta demonstração). Esse índice permitirá consultas Lucene 'como' em todos os campos de metadados. Existe um índice semelhante para Nativedocument.custommetadata:
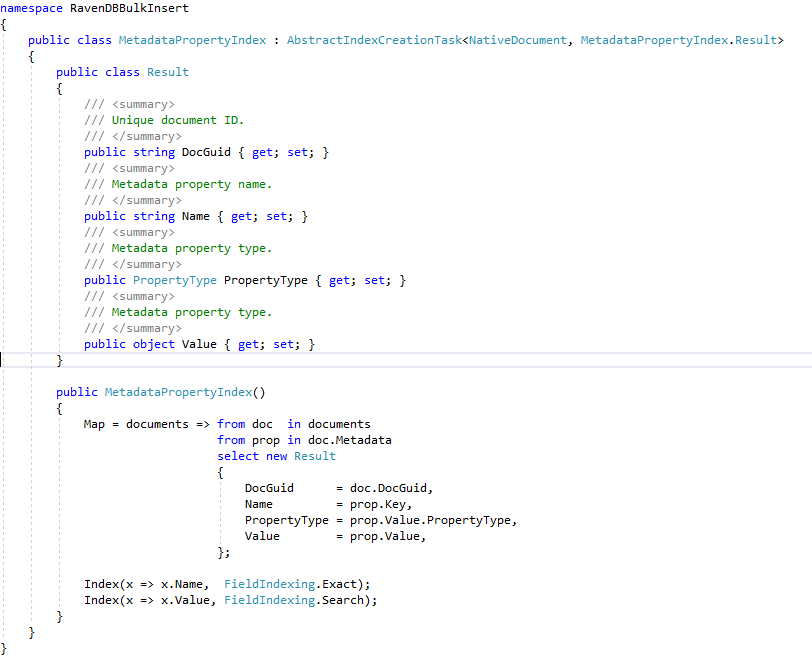
Todos os índices RAVENDB definidos C# são criados no banco de dados RAVENDB ENRON do "App de demonstração do ECA" por meio de uma chamada simples da API RAVENDB:
A foto abaixo mostra as estatísticas de resumo do processamento do conjunto de dados do 189 Microsoft Outlook PST Enron (1.221.542 e -mails e anexos processados no total). A maioria dos e -mails e anexos neste conjunto de dados são documentos duplicados devido ao fato de os funcionários da Enron cujos dados foram coletados durante a fase de descoberta legal estavam por e -mail um ao outro - as estatísticas de deduplicação mostradas na imagem abaixo foram baseadas no hash binário/conteúdo, no futuro, atualizaremos este estudo de caso (juntamente com o Ravendb Indexes) para incluir o setor legal, "a indústria do futuro, atualizamos este estudo de caso", juntamente com o Ravendb Indexes) para incluir a indústria jurídica "Disturi", a indústria do futuro ", e a indústria de conteúdo", atualizamos este estudo de caso (juntamente com o Ravendb. Observe o gráfico de pizza de classificação de formato de arquivo, resumo do gráfico específico de pizza de formato de arquivo e resumo dos resultados do processamento (tipo de enumeração com valores de OK/WhryPassword/DataError/etc) gráfico de pizza.
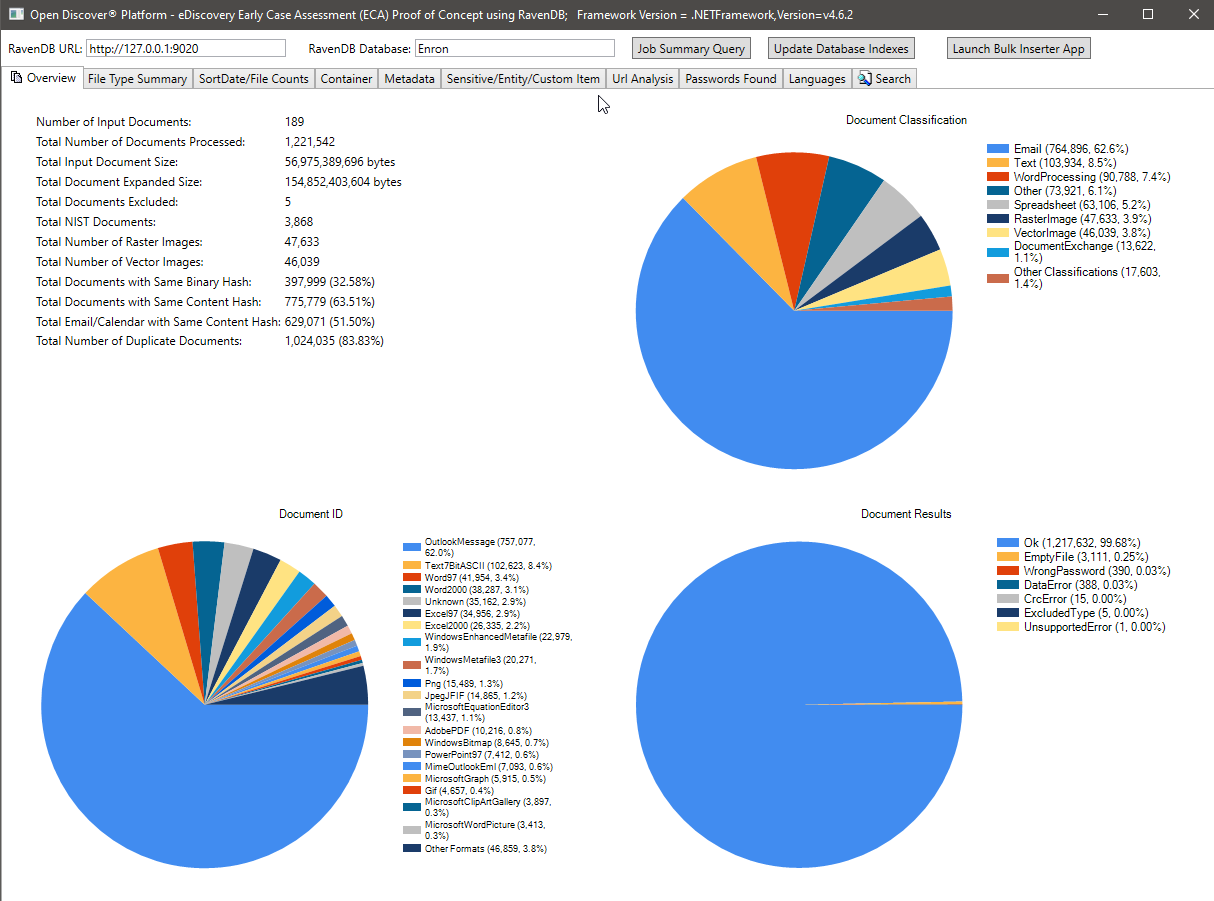
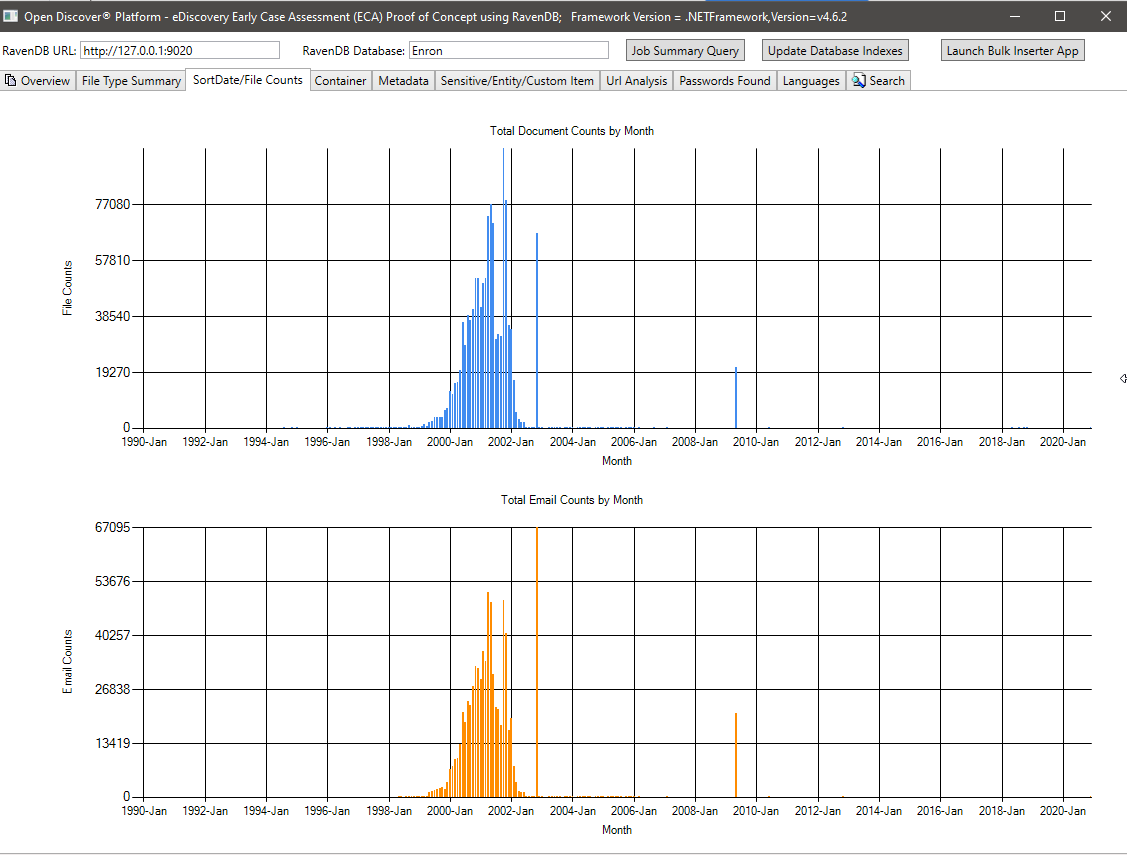
Contagem de arquivos por gráficos de resumo do SortDate:
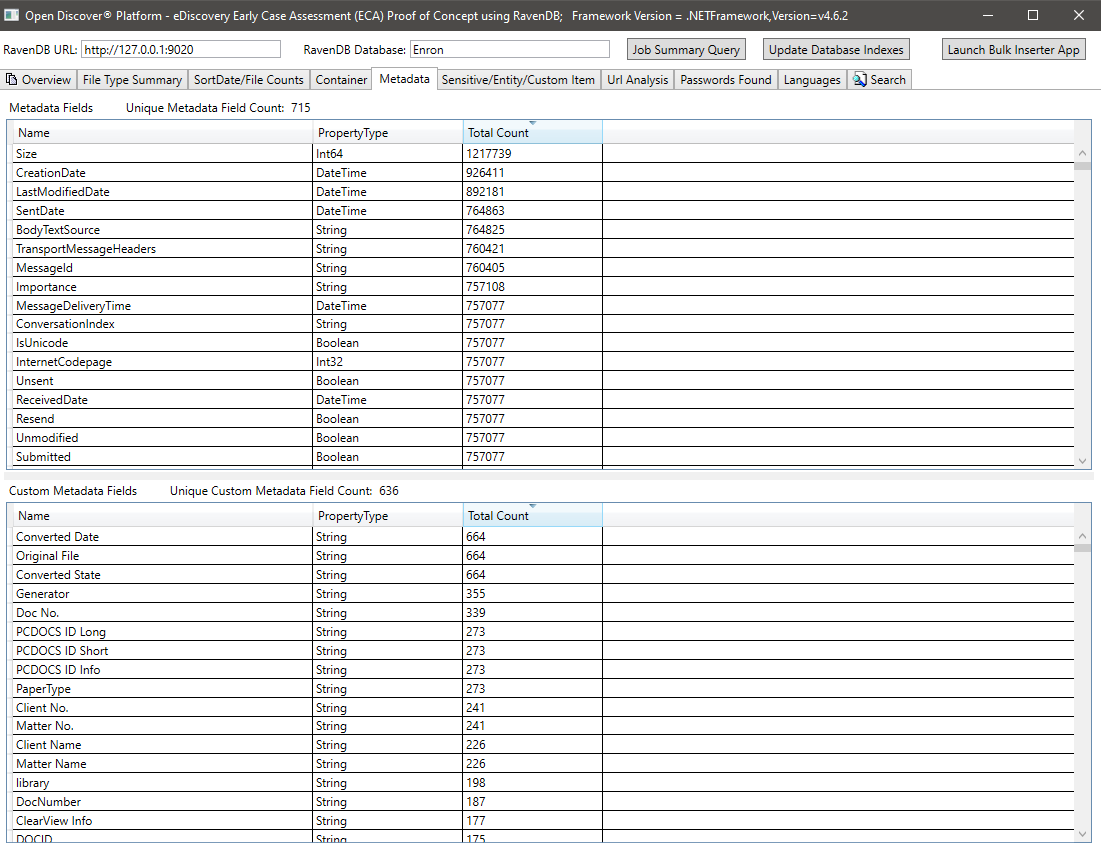
Resumo dos metadados (nome do campo de metadados/número total de documentos) - 715 Nomes de campo de metadados exclusivos conhecidos em todos os documentos e 636 campos de metadados personalizados (definidos pelo usuário). Esta consulta pode ajudar os gerentes de casos jurídicos a saber o que os campos de metadados estão disponíveis na coleção para pesquisar:
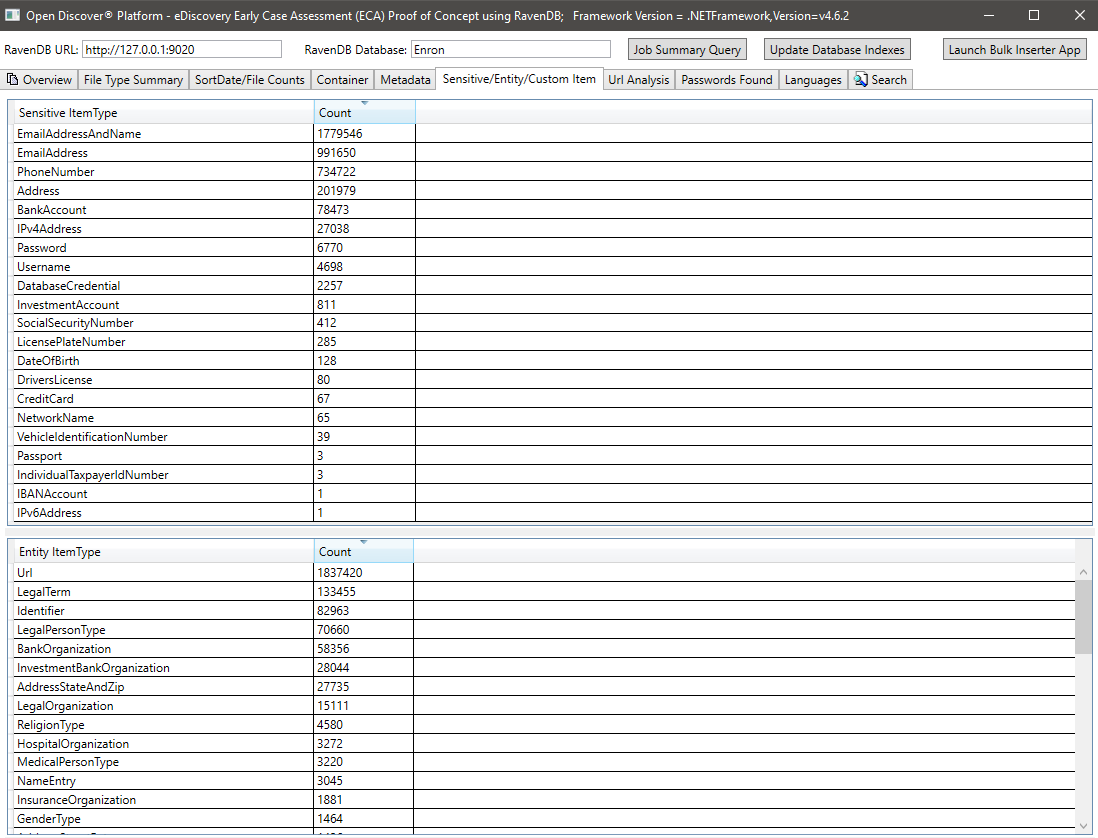
Resumo do item de item/entidade sensível para todos os documentos:
Resumo de todos os URLs exclusivos encontrados em todos os documentos (os URLs de todos os documentos podem ser úteis, por exemplo, se uma empresa quiser rastrear possíveis pontos de entrada de URL maliciosos). O Open Discover SDK detecta todos os URLs dos hiperlinks de documentos e no texto do documento (ou seja, não-hiperlink):
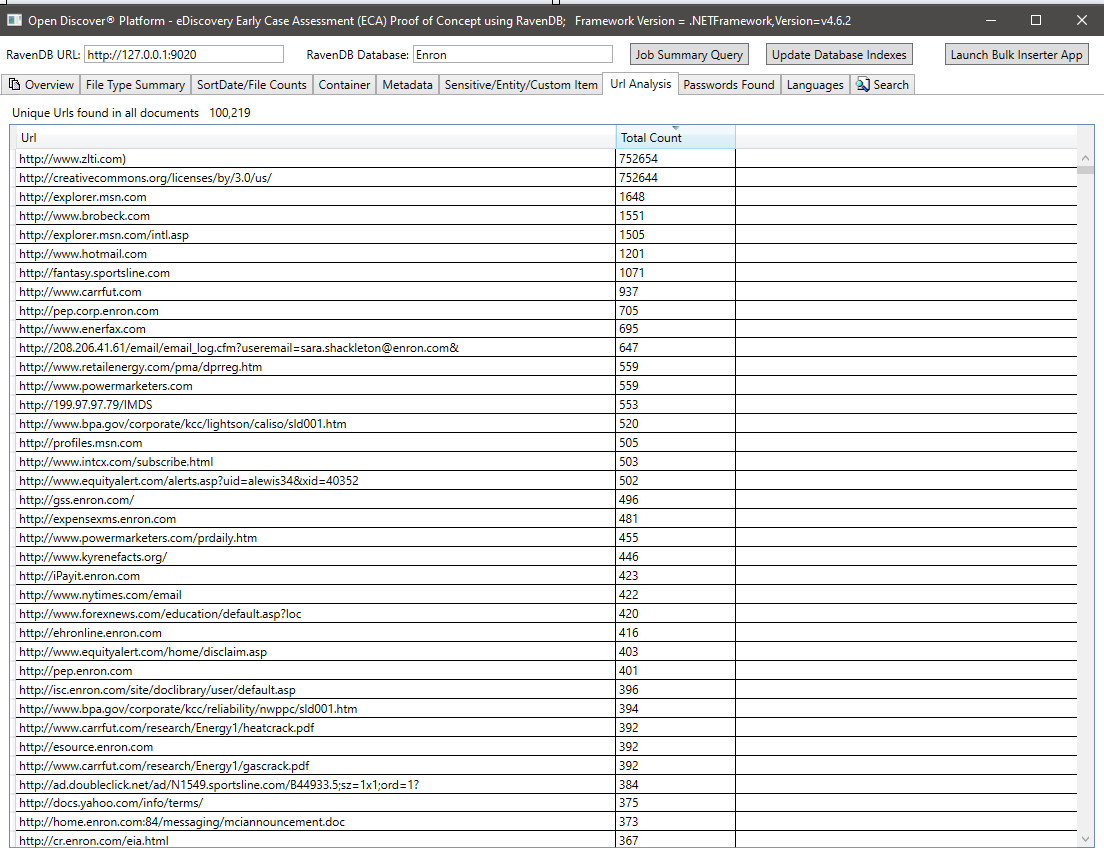
Resumo de todas as senhas encontradas em todos os documentos. Senhas e nomes de usuário são apenas 2 dos 25 tipos de 'item sensível' integrados suportados pelo Open Discover SDK/Plataforma. Credenciais de senha/nome de usuário em documentos podem ser um risco de segurança, eles também podem ser usados para reprocinar qualquer documento que tenha um resultado de processamento de 'WhryPassword' (como funcionários da mesma empresa geralmente enviam por e-mail para os documentos do escritório criptografado compartilhado):
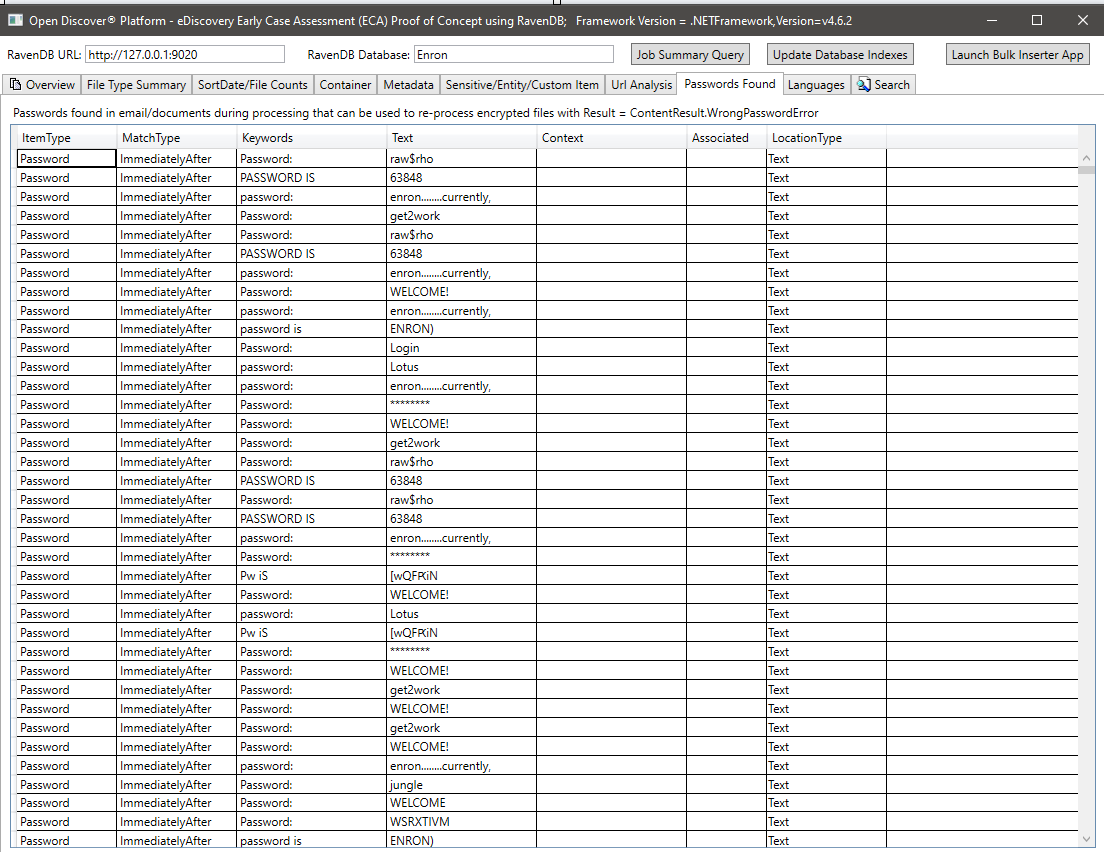
Resumo dos idiomas detectados no texto extraído dos documentos processados:
Exemplo de consulta de pesquisa de texto completo (Nota: Ravendb suporta consultas do Lucene):
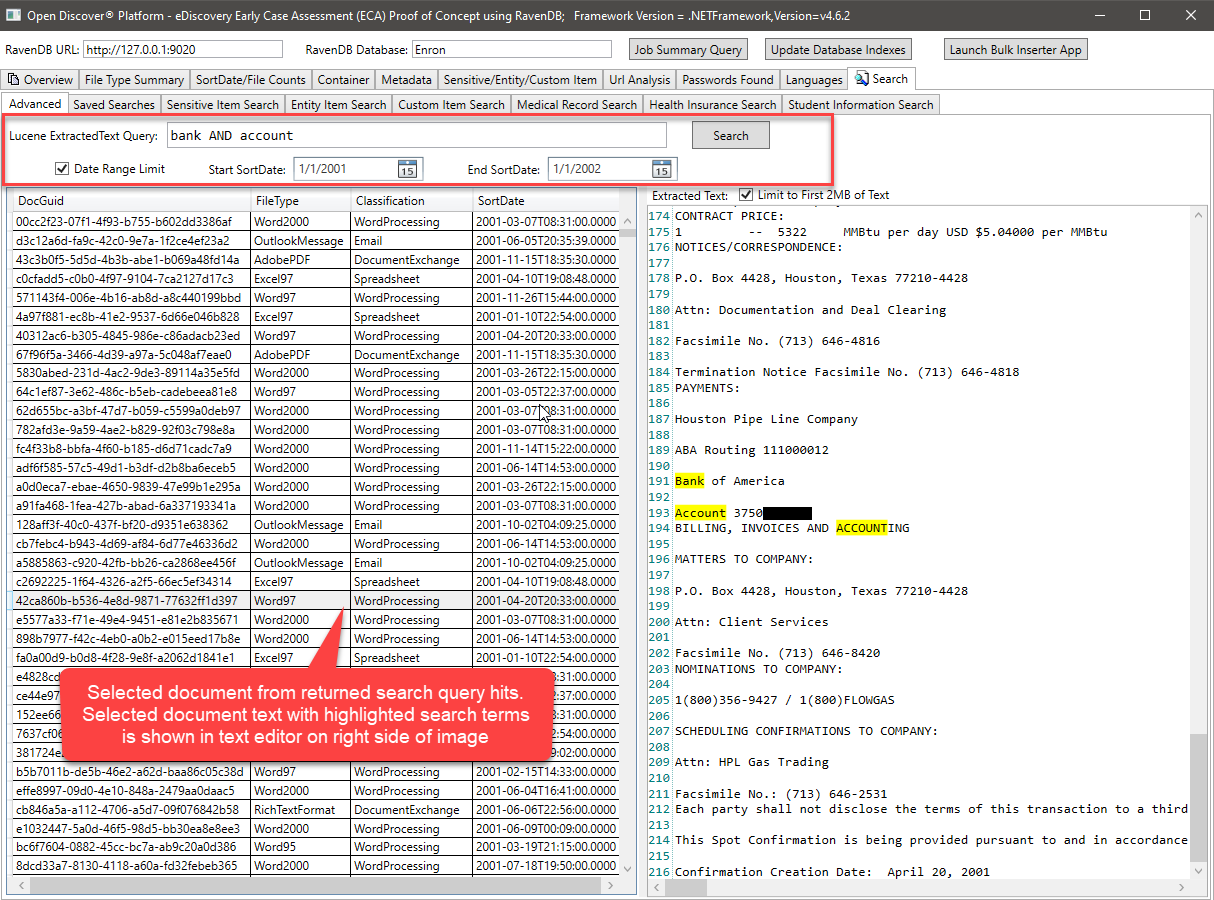
A consulta acima do Lucene, consulta o campo ExtrairDText e usa (opcionalmente) min/max documentdate para filtrar os resultados de pesquisa retornados. Seria muito fácil adicionar também a filtragem de resultados por documento FileType ou Classificação de formato de documento (WordProcessing/Spreadsheet/email/etc). O código C# que executa a consulta Lucene se parece com o seguinte:
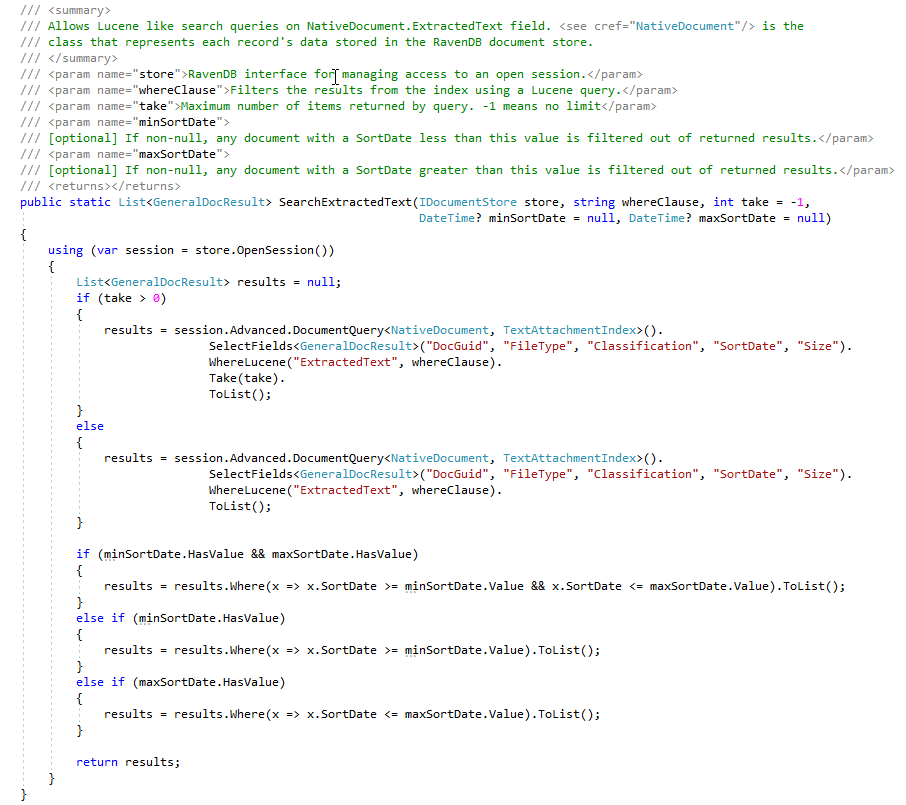
Durante a fase da ECA, os advogados de revisão legal gostam de criar muitas consultas de pesquisa diferentes para encontrar documentos de resposta. A foto abaixo mostra algumas consultas salvas do Lucene e os resultados (número de acertos de documentos e tamanho total dos documentos). Observe que as contagens de documentos nessas pesquisas criadas pelo usuário contêm contagens duplicadas de documentos, embora tenhamos índices RaVendB que contam o número de documentos duplicados, para essa prova de conceito, ainda não temos documentos "marcados" na loja de documentos com um sinalizador indicando mestre/duplicado (este é um 'TODO' pelo usuário):
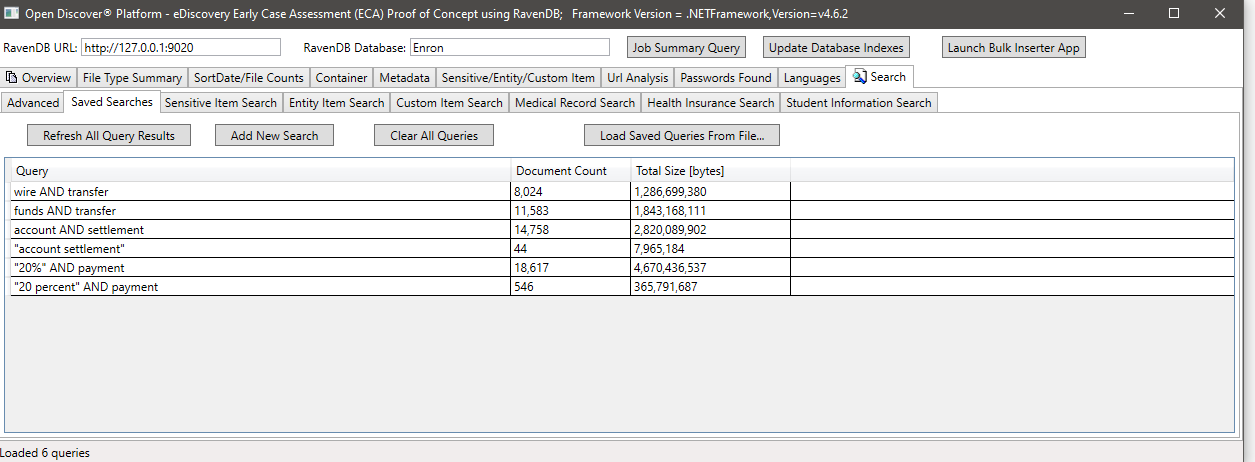
Exemplo de pesquisa por sensívelItemType (uma propriedade em objetos sensíveis detectados que identifica o tipo de item sensível), neste exemplo, pesquisamos todos os documentos que possuem um item sensível do tipo sensívelItemType.BankAccount:
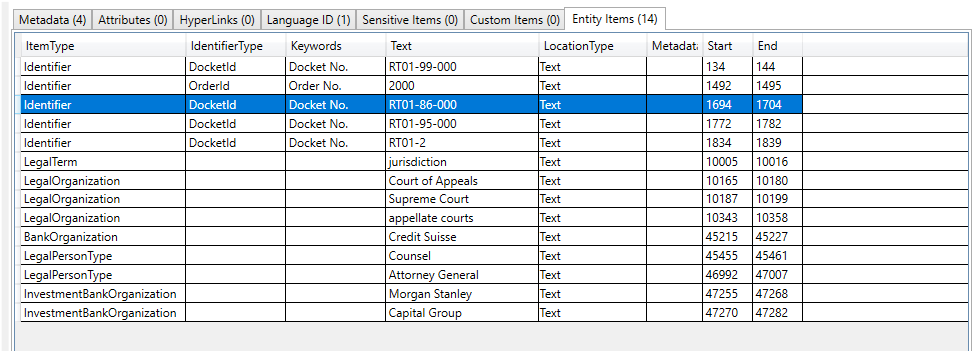
Exemplo de pesquisa por entityItemType (uma propriedade em objetos detectados entityiTem que identifica o tipo de item de entidade), neste exemplo pesquisamos todos os documentos que têm um item de entidade do tipo entityItemType.patientNameEntry:
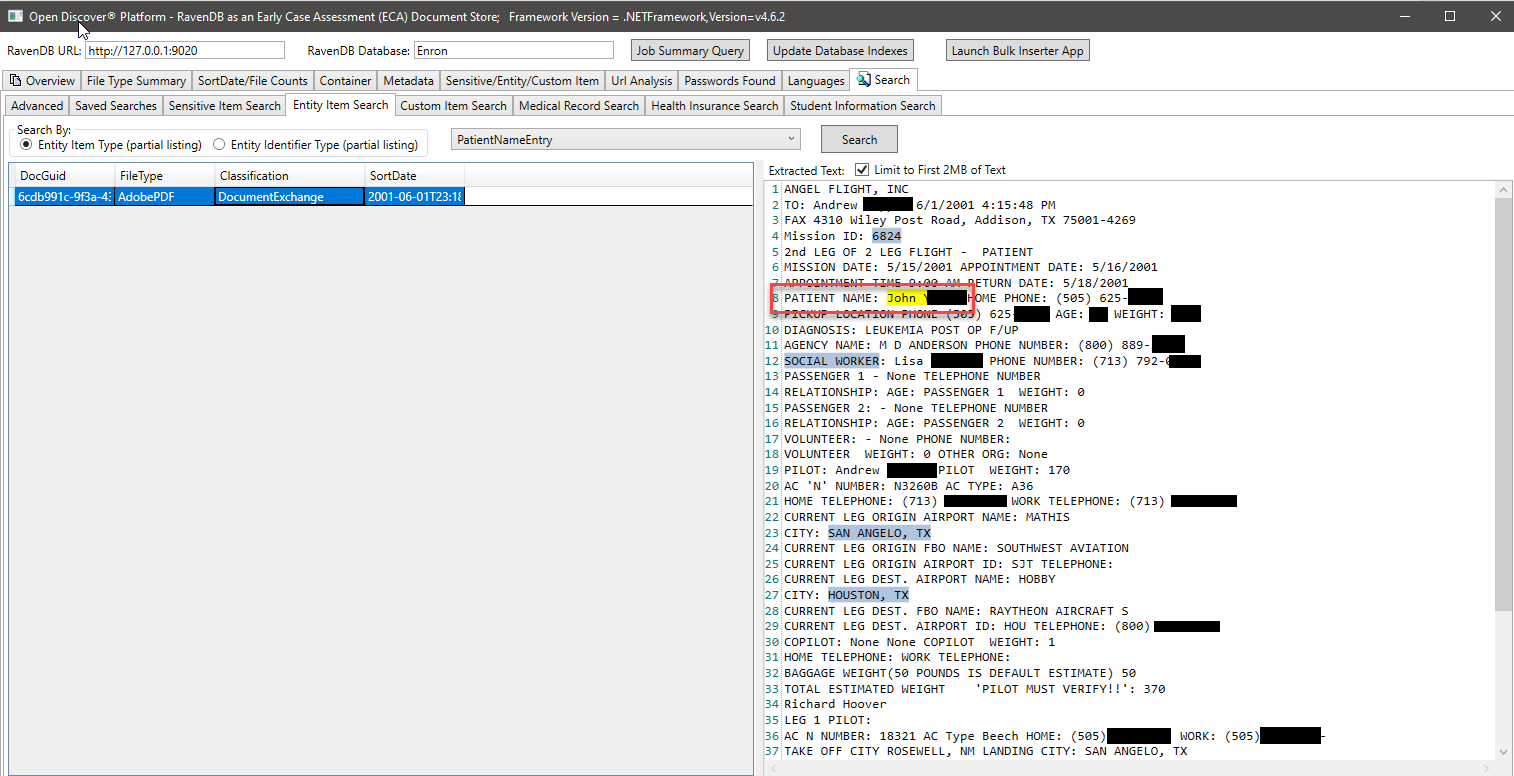
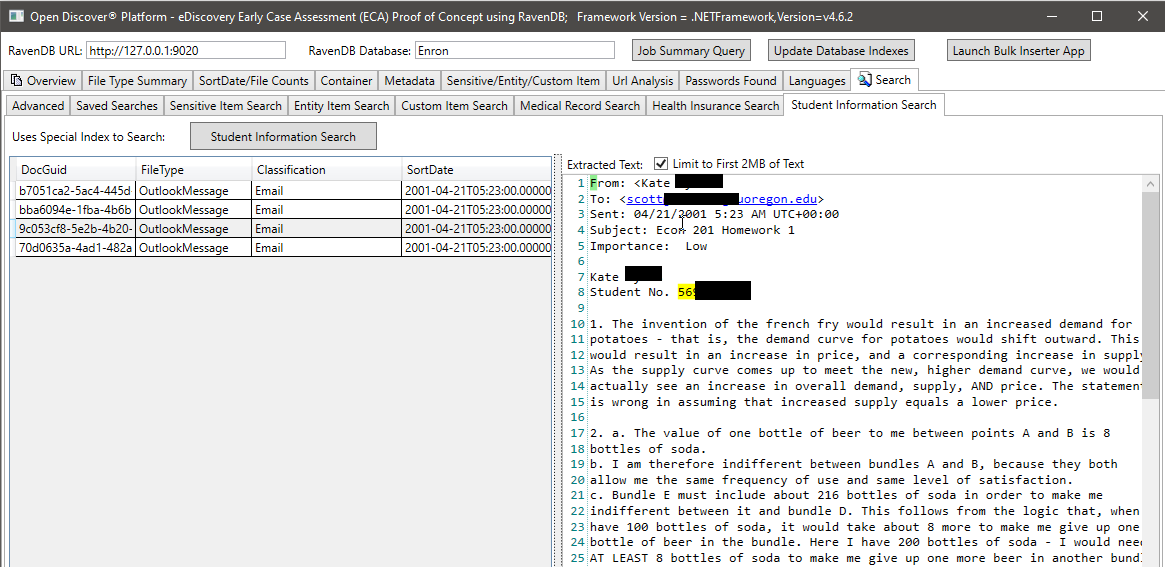
Na captura de tela abaixo, usamos um índice RAVENDB especialmente criado que indexa os tipos específicos de entidades extraídas do Discover Discover Discover SDK relacionadas às informações do aluno para encontrar documentos que possam ter informações sobre o aluno (no tiro na tela, o nome do aluno e o ID do aluno estão apagados, o ID do aluno parece ser um número de Seguro Social que era comum antes do 2000). Da mesma forma, temos outros índices especiais para procurar registros médicos e informações do paciente:
A saída da plataforma Open Discover® armazenada em um banco de dados de documentos como RaVendB pode levar a aplicativos de avaliação de casos legais (ECA) muito poderosos e rapidamente desenvolvidos. Além disso, aplicativos como os seguintes também podem ser desenvolvidos rapidamente:
Se este estudo de caso tivesse usado um banco de dados relacional em vez de um banco de dados de documentos como RavendB, levaria meses de design de esquemas de banco de dados e desenvolvimento de procedimentos de armazenamento e não as duas semanas em tempo que o autor levou para desenvolver essa prova de avaliação de casos (ECA).


