OpenDiscoverPlatformCaseStudy
1.0.0
Consulte Open Discover® SDK para .NET Ejemplos Repositorio de GitHub
Una sola instancia de API de plataforma Open Discover generalmente es capaz de procesar conjuntos de documentos a 40-70 GB/hora de hora* (* Las tarifas dependerán del hardware del usuario y los tipos de archivos en el conjunto de datos). Es muy rápido en el procesamiento de documentos al tiempo que se extrae más contenido que la mayoría de los software de eDiscovery (por ejemplo, detección de elementos/entidades confidenciales y deshidrates durante el procesamiento). Se utilizó una aplicación de demostración de API de plataforma Open Discover, PlatformApidemo.exe, para procesar el conjunto de datos PST de Enron Outlook. La aplicación de demostración de PlatformApidemo.exe envuelve una instancia de la clase de procesamiento de documentos API de plataforma. Las capturas de pantalla del ejemplo de la salida de procesamiento de PlatformApidemo.exe se muestran en la siguiente sección a continuación.
PlatformApidemo.exe se distribuye con la evaluación de plataforma Open Discover junto con:
En una prueba de rendimiento reciente, el SDK Open Discover procesó el conjunto de datos PST de 53 GB Microsoft Outlook PST y la masa insertaron la salida de la API de la plataforma (texto/metadatos/elementos sensibles (PXI)/etc.) en RAVENDB en poco más de 30 minutos usando una sola PC de escritorio de Windows de 4 núcleos.
** Esta tasa de procesamiento de estudio de caso fue para la versión .NET 4.62 de SDK, la nueva versión de .NET 6 es> 100% más rápida en promedio, todas las tareas de procesamiento de PST en la versión .NET 6 de OpenDesscosverplatform se procesaron sus tareas de conjunto de datos PST entre 90-100+GB/HR (basado en el tamaño de entrada de entrada) con el elemento sensible detectado por detección (tasas de procesamiento de procesamiento es un hardware en estos números en estos números en estos números Utilizamos un auxil de escritorio con un auxilio de input en el tamaño de la entrada. CPU y 16 GB de RAM).
La captura de pantalla a continuación muestra un elemento de correo electrónico (y sus archivos adjuntos) que fue extraído de su contenedor PST Outlook y procesado por la aplicación PlatformApidemo.exe. El correo electrónico es de uno de los PST de Enron Microsoft Outlook. El control de la vista del árbol en el lado izquierdo de la imagen muestra la jerarquía de padres/niños de todos los documentos/contenedores procesados, y hacer clic en un elemento en el control del árbol mostrará su contenido extraído. Para el elemento de correo electrónico de Outlook seleccionado en la vista de árbol, podemos ver que tiene documentos de Word de Office de 6 ms como archivos adjuntos que se extrajeron del correo electrónico. Todos y cada uno de los elementos adjuntos/integrados también se extrajeron su contenido (procesando completamente la jerarquía infantil principal, sin importar cuán complejo). Tenga en cuenta los resultados de identificación del formato de archivo, "sortdate" calculado, varios hash de documentos, los metadatos extraídos y otros elementos de pestaña en el lado superior derecho de la imagen que contiene otro contenido extraído:
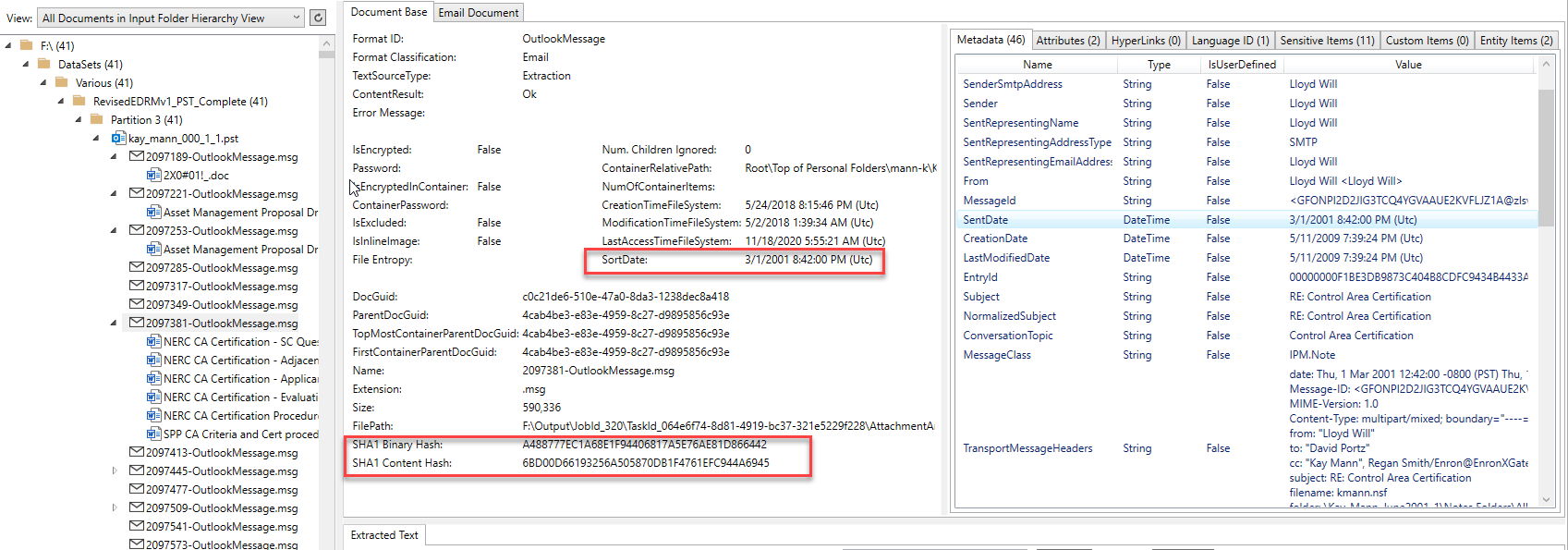
Envíe un correo electrónico a contenido específico como todos los destinatarios y hashes adicionales:
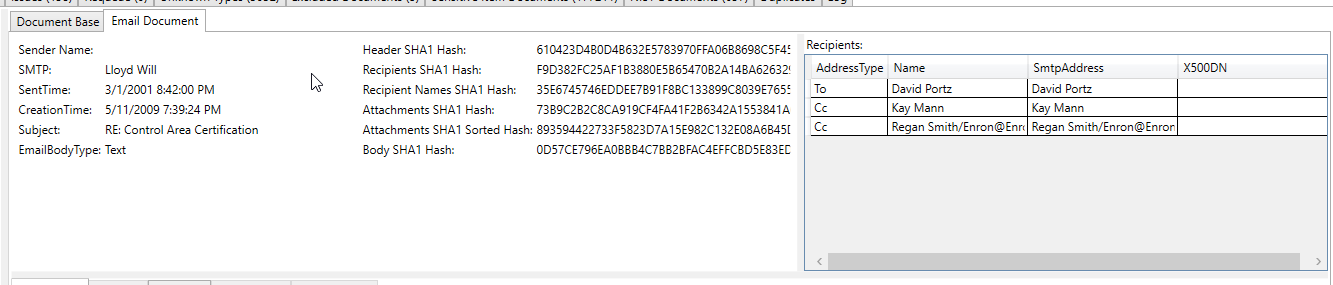
Esta captura de pantalla de correo electrónico procesada muestra un número de cuenta bancaria que se extrajo/identificó como un "elemento sensible" en el texto extraído del correo electrónico (todos los texto extraído y todos los metadatos están escaneados para elementos sensibles):
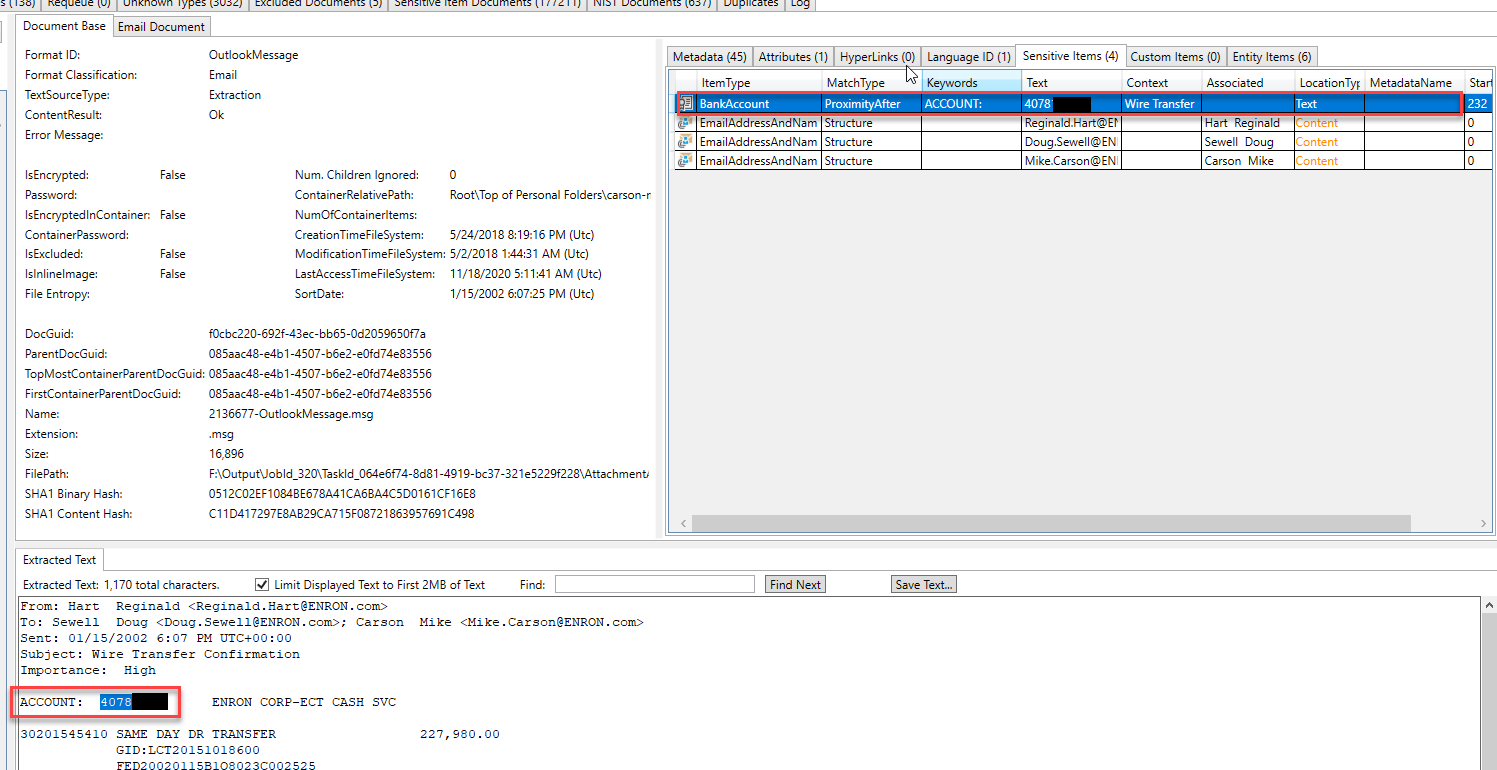
Algunas "entidades" identificadas y extraídas en un correo electrónico diferente. Al inspeccionar los tipos de entidades que se encuentran en este correo electrónico, podemos suponer que el correo electrónico está discutiendo un asunto legal:
La captura de pantalla a continuación muestra la base de datos Enron en Ravendb Studio poblada con la salida procesada de la API de la plataforma. Solo algunos de los campos de documentos de la base de datos almacenados en Ravendb podrían caber en la captura de pantalla, hay muchos más campos. Los nombres de la columna con una anotación de borde rojo son colecciones de objetos:
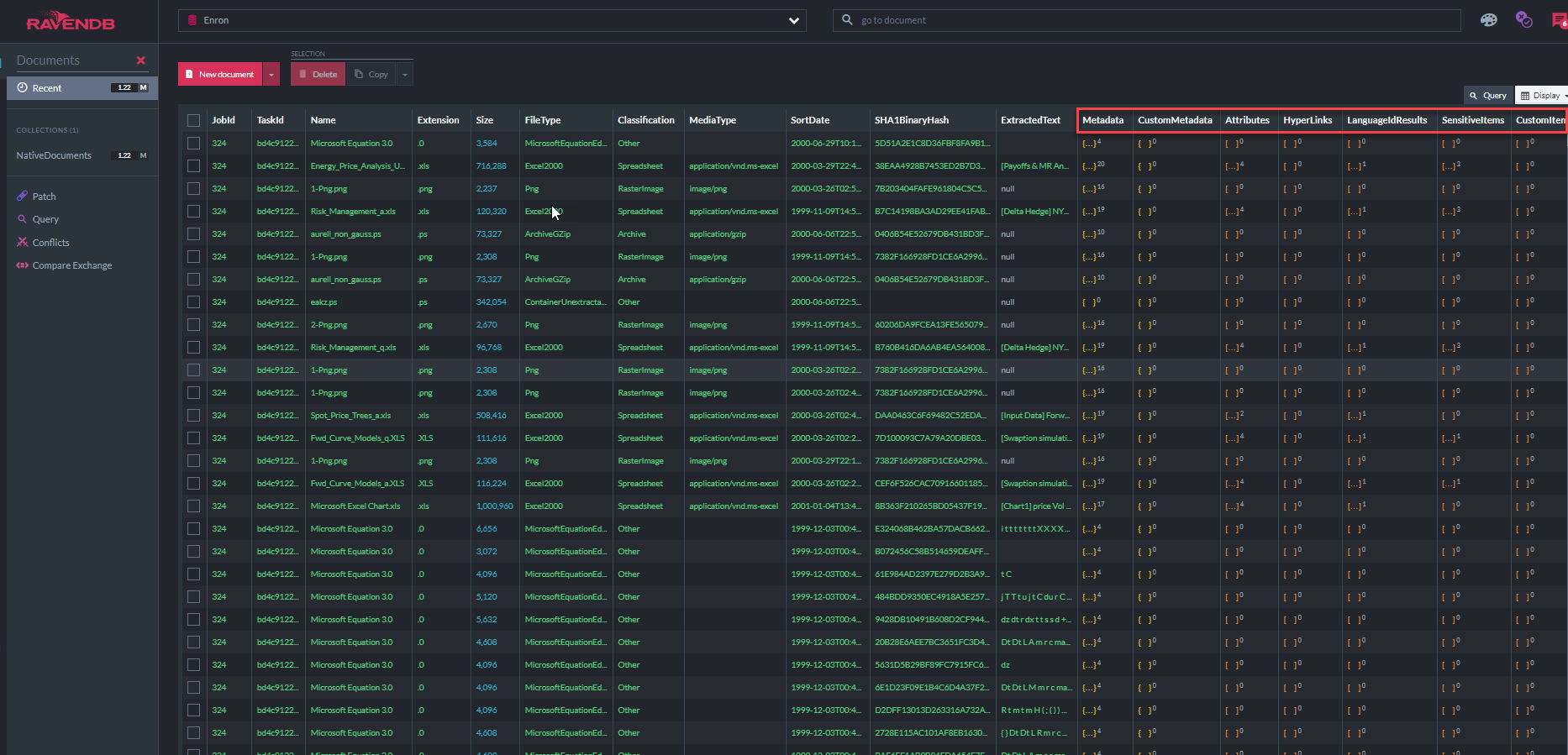
La captura de pantalla a continuación muestra algunos de los 31 índices RavendB que la "aplicación de demostración de ECA" utiliza para consultar el almacén de documentos (tenga en cuenta que el "metadatapropertyindex" muestra que hay 37.7 millones de propiedades de metadatos almacenadas en esta base de datos, principalmente metadatos de correo electrónico, además de todo el texto extraído):
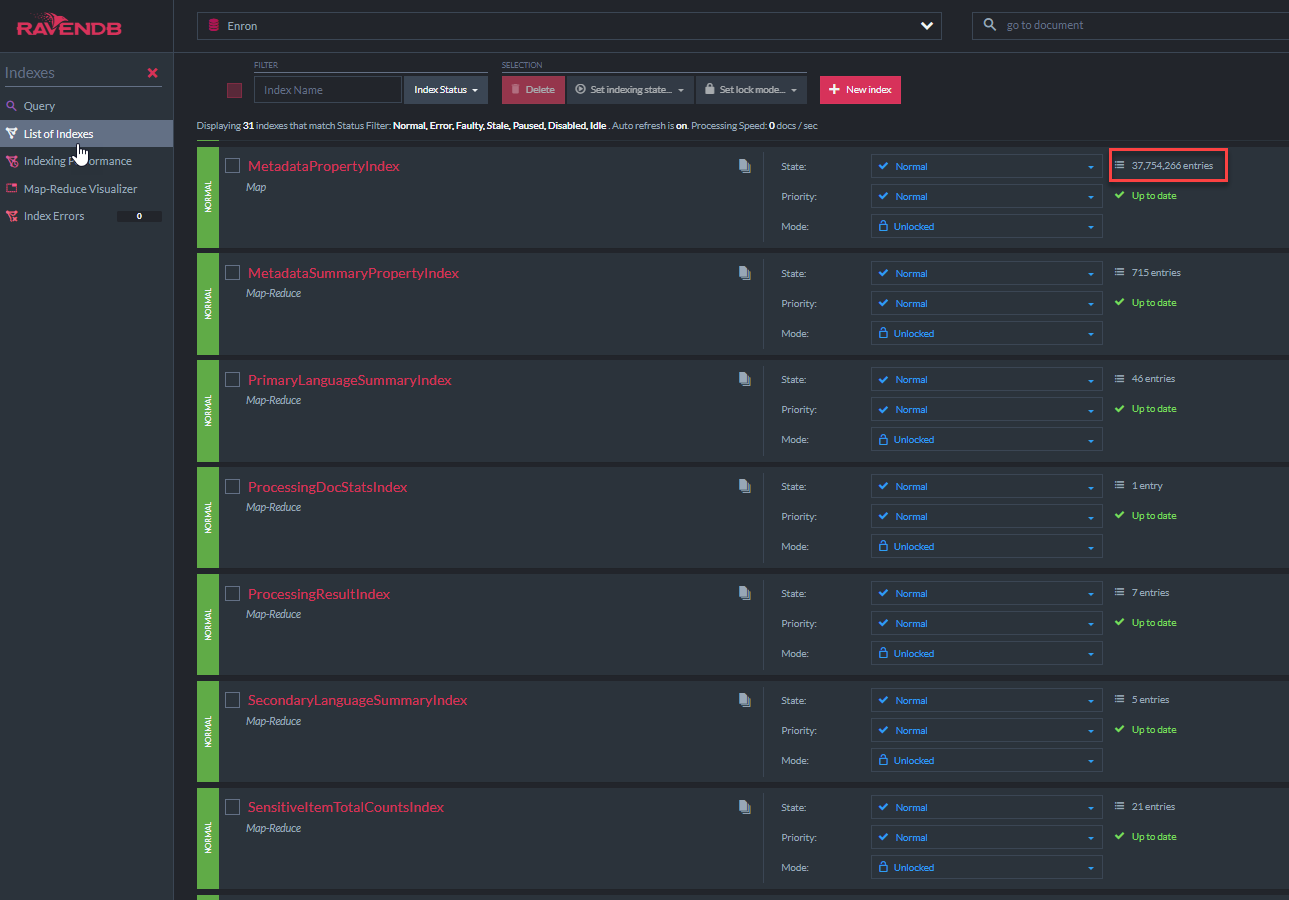
El código de clase C# "metadatapropertyindex" se muestra a continuación. Esta clase de índice se deriva de la Task de CreationAdExCreation de Ravendb (al igual que todos los demás índices en esta demostración). Este índice permitirá consultas de Lucene 'Like' en todos los campos de metadatos. Un índice similar para NativedOcument.CustomMetadata existe:
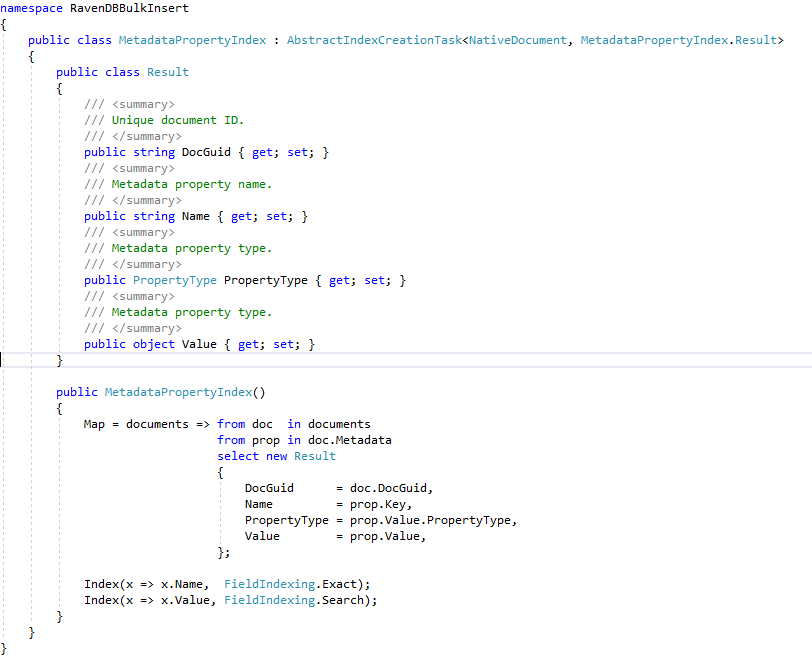
Todos los índices de RavendB definidos de C# se crean en la base de datos de Ravendb Enron a partir de la "aplicación de demostración de ECA" a través de una simple llamada de API de Ravendb:
La captura de pantalla a continuación muestra las estadísticas de resumen de procesamiento del conjunto de datos de Microsoft Outlook PST Enron (1,221,542 correos electrónicos y archivos adjuntos procesados en total). La mayoría de los correos electrónicos y archivos adjuntos en este conjunto de datos son documentos duplicados debido al hecho de que los empleados de Enron cuyos datos fueron recopilados durante la fase de descubrimiento legal se estaban enviando un correo electrónico entre sí, las estadísticas de deduplicación que se muestran en la imagen a continuación se basaron en el hash binario/contenido, en el futuro, actualizaremos este estudio de caso (junto con los índices de los Ravendb) para incluir la industria legal preferida "basada en el hash". Tenga en cuenta el gráfico PIDA de clasificación de formato de archivo, el resumen del gráfico de formato de archivo específico y el resumen de los resultados del procesamiento (tipo de enumeración con valores de Ok/WrongPassword/DataSror/etc) Gráfico PIE.
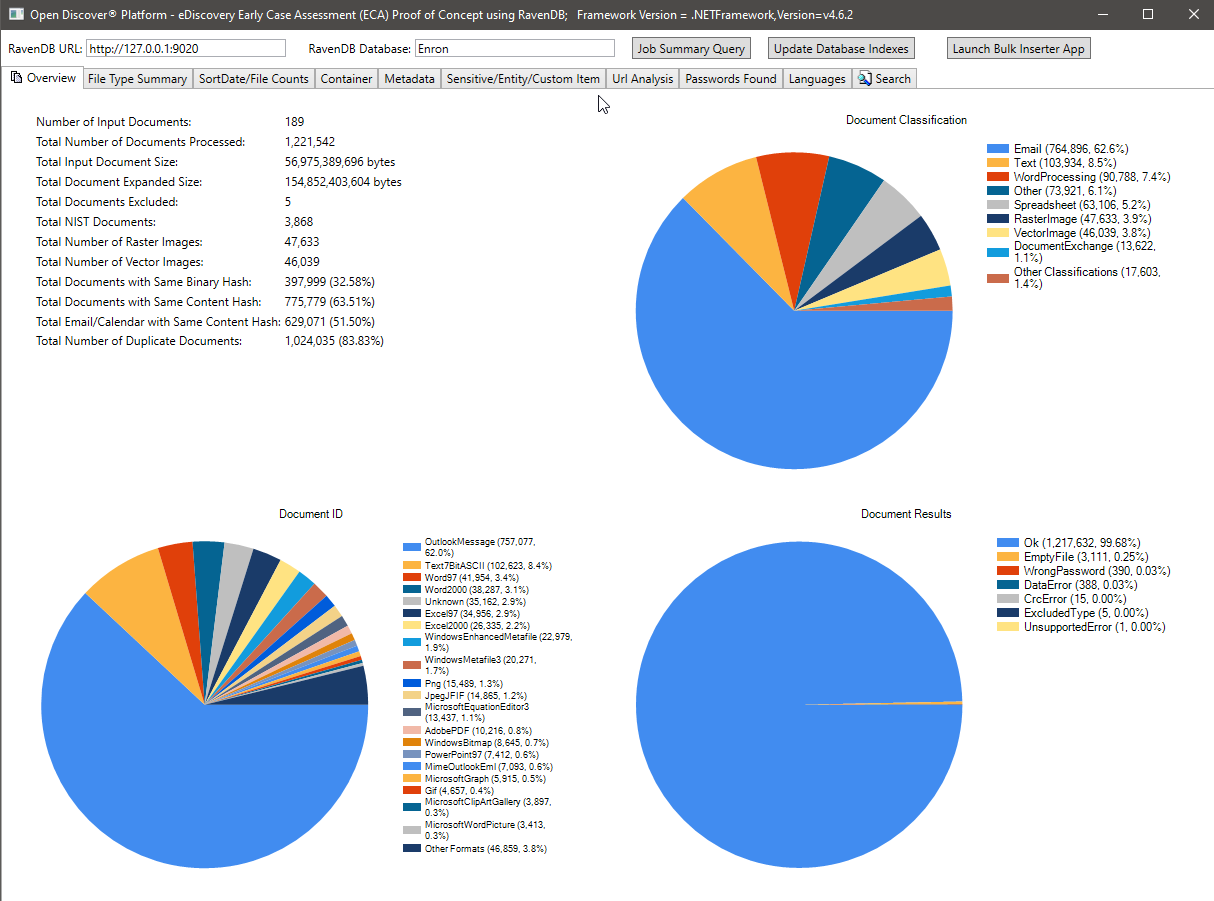
Cuenta de archivos mediante gráficos de resumen SortDate:
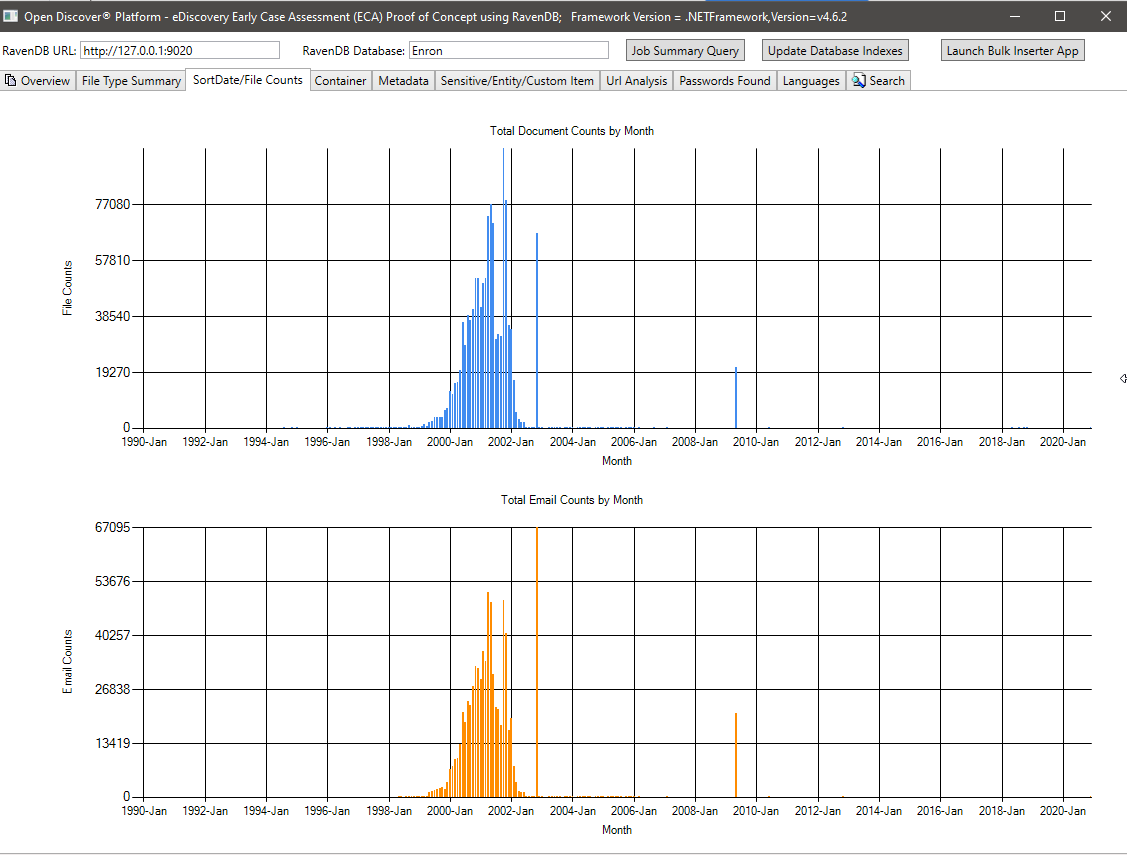
Resumen de metadatos (nombre de campo de metadatos/número total de documentos) - 715 nombres de campo de metadatos únicos conocidos en todos los documentos y 636 campos de metadatos personalizados (definidos por el usuario). Esta consulta puede ayudar a los administradores de casos legales a saber qué campos de metadatos están disponibles en la colección para buscar:
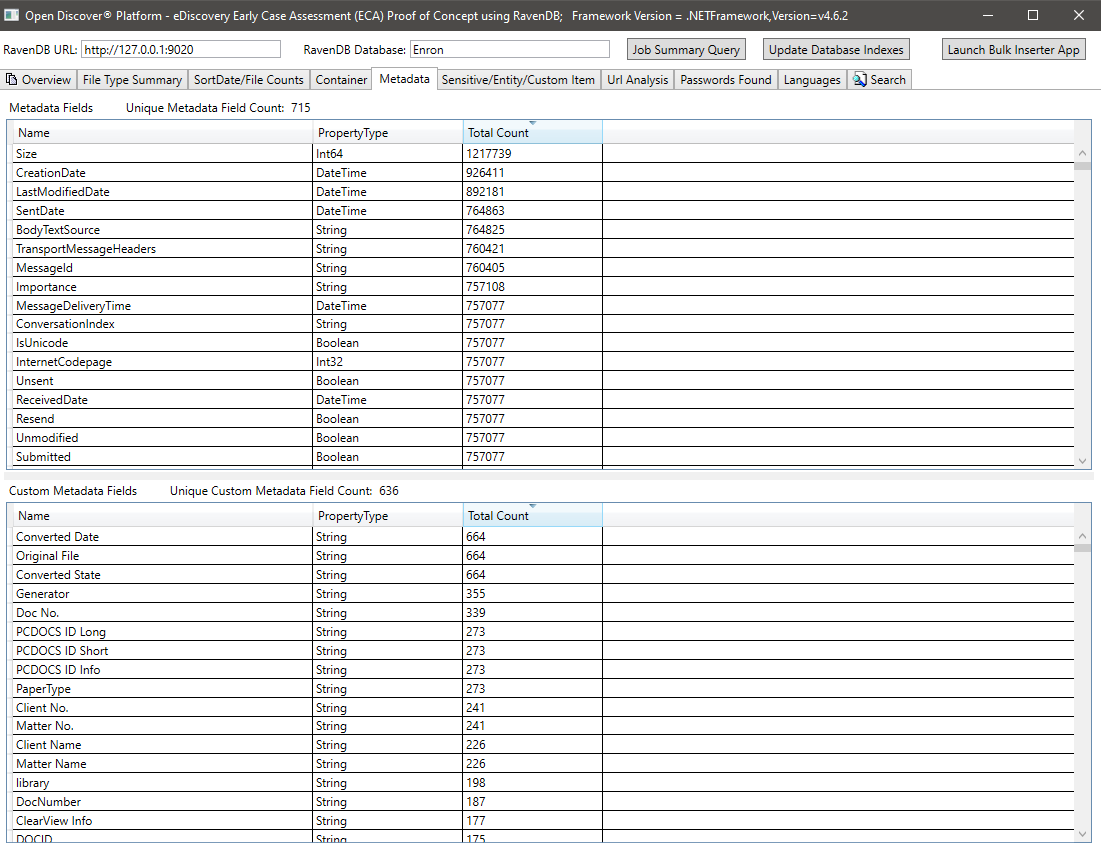
Resumen de elementos de elemento/entidad confidenciales para todos los documentos:
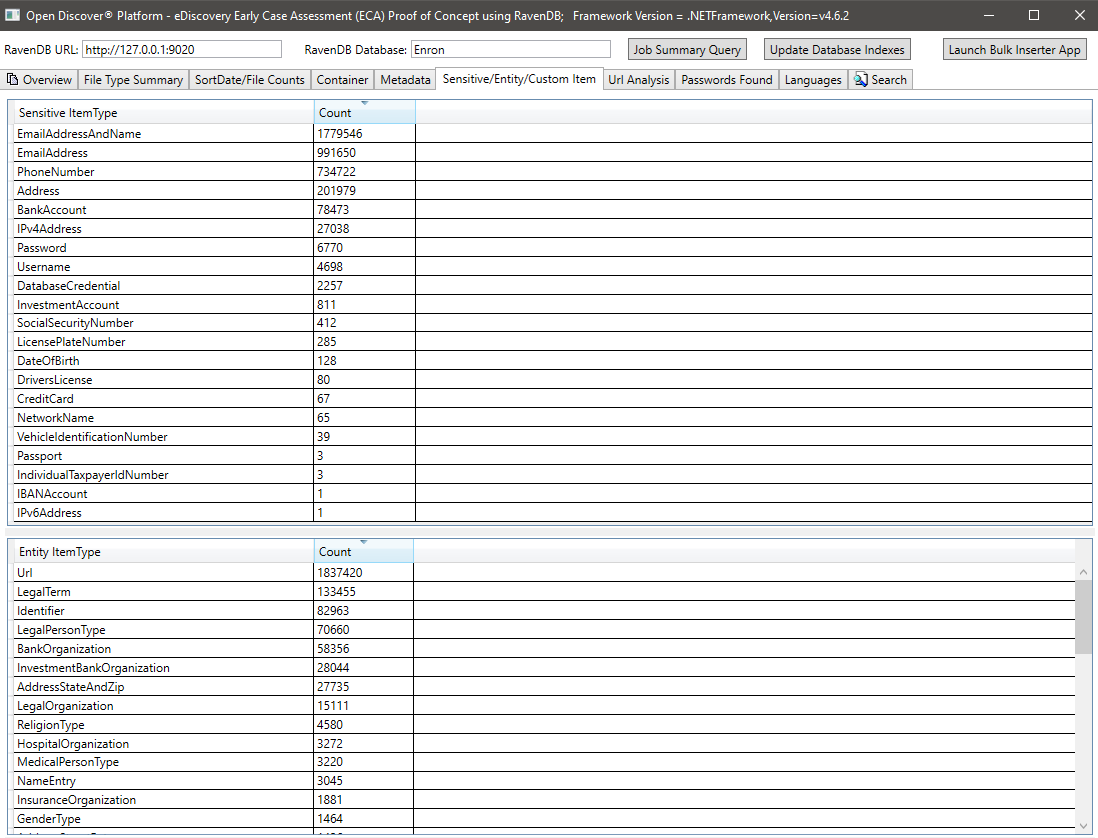
Resumen de todas las URL únicas que se encuentran en todos los documentos (las URL de cada documento pueden ser útiles, por ejemplo, si una empresa desea rastrear posibles puntos de entrada de URL maliciosas). Abrir Discover SDK detecta todas las URL de los hipervínculos de documentos y en el texto del documento (es decir, no hyperlink):
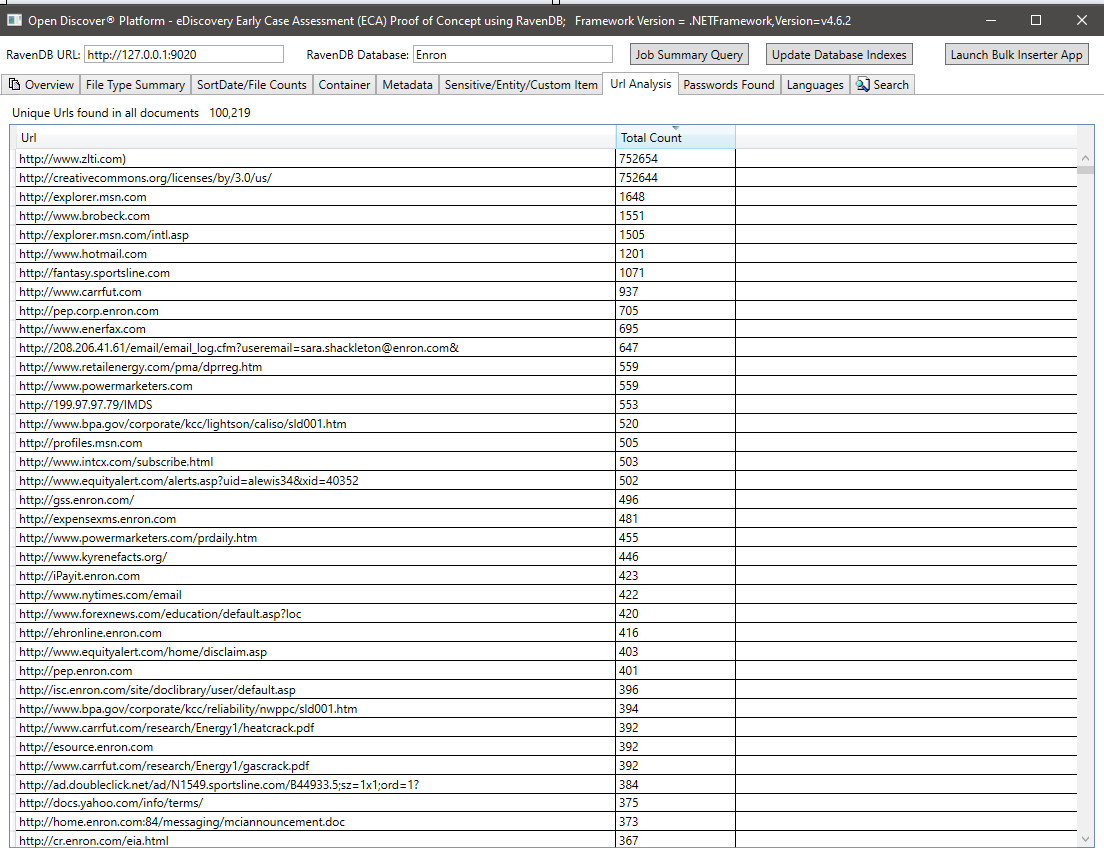
Resumen de todas las contraseñas encontradas en todos los documentos. Las contraseñas y los nombres de usuario son solo 2 de los 25 tipos de 'elemento sensible' incorporado admitidos por la plataforma/plataforma Open Discover. Las credenciales de contraseña/nombre de usuario en los documentos pueden ser un riesgo de seguridad, también se pueden usar para volver a procesar cualquier documento que tenga un resultado de procesamiento de 'WrightPassword' (ya que los empleados de la misma compañía a menudo se envían por correo electrónico contraseñas a documentos de oficina cifrados compartidos):
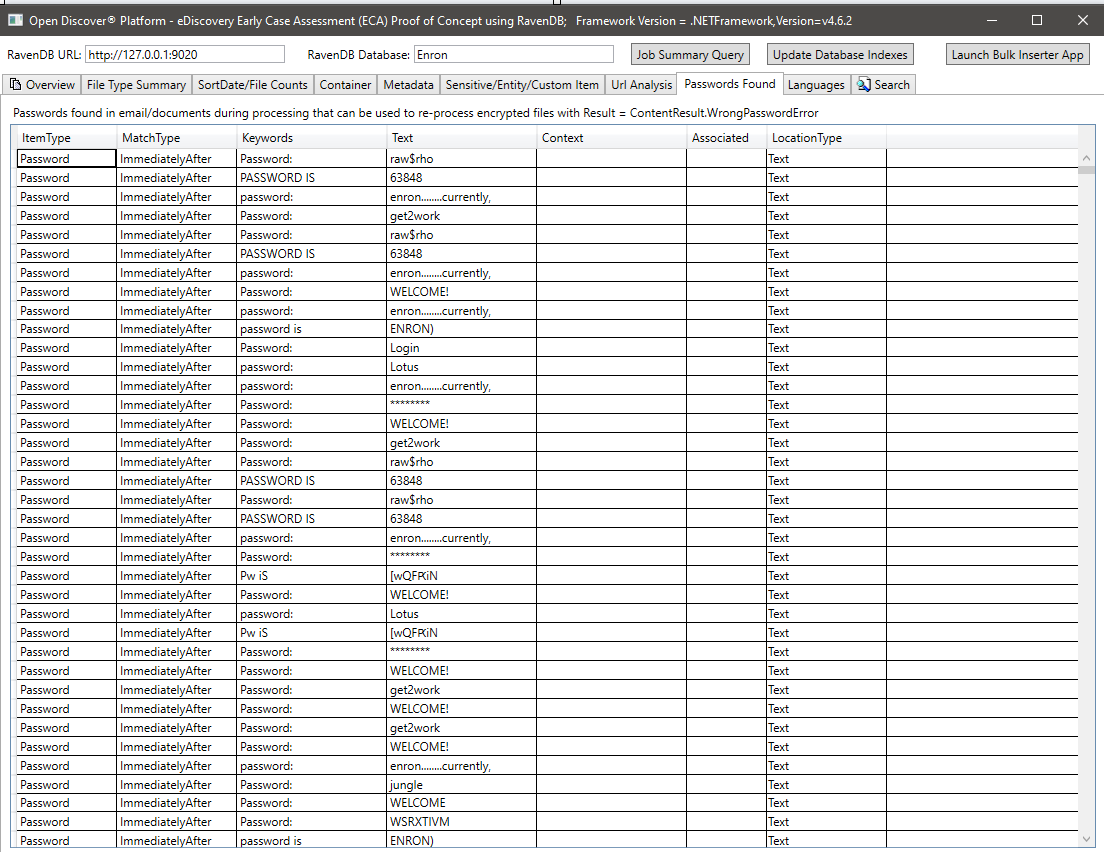
Resumen de idiomas detectados en el texto extraído de los documentos procesados:
Ejemplo de consulta de búsqueda de texto completo (Nota: Ravendb admite consultas de Lucene):
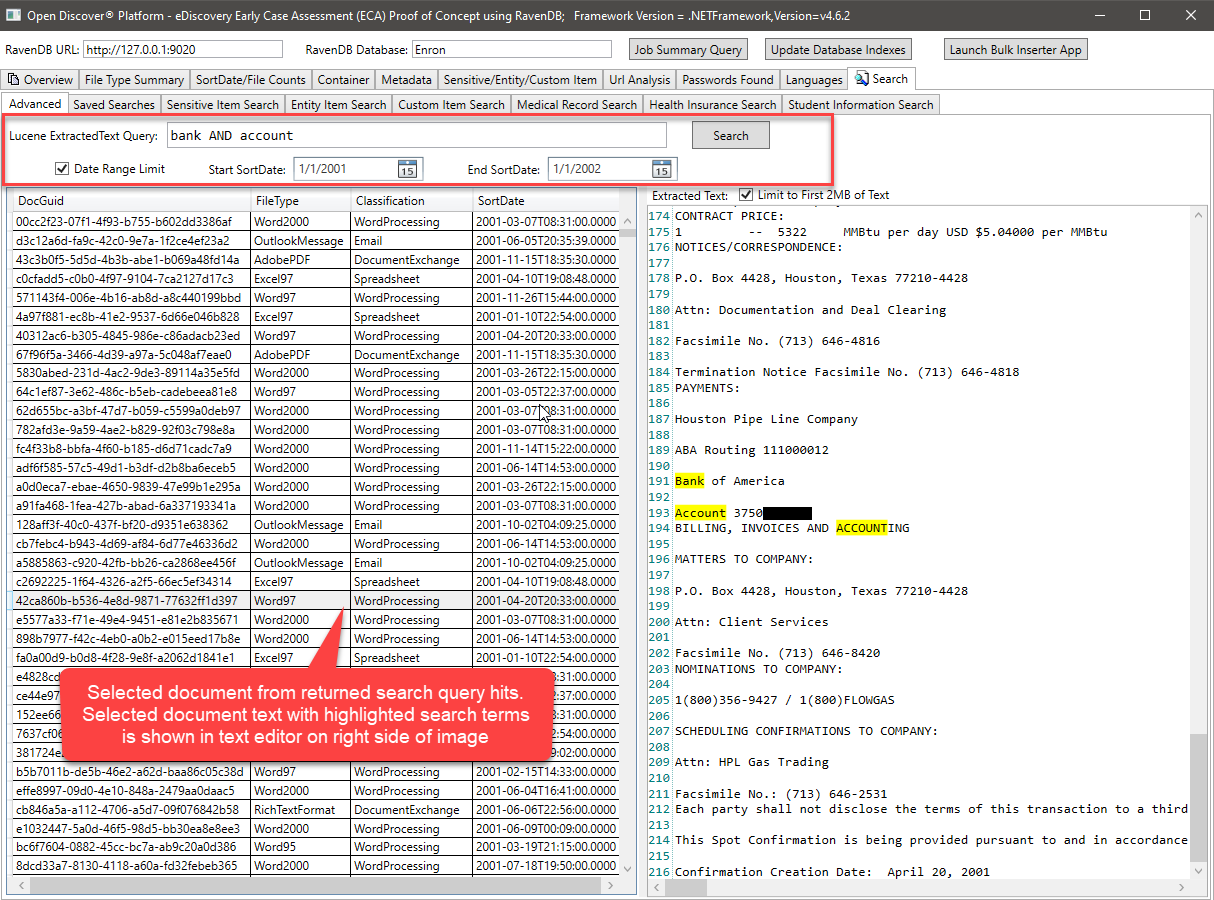
La consulta de Lucene anterior, consulta el campo ExtractedText y usa (opcionalmente) Min/Max Document SortDate para filtrar los resultados de búsqueda devueltos. Sería muy fácil agregar también el filtrado de resultados mediante el tipo de archivo de documento o clasificación de formato de documento (procesamiento de palabras/hoja de cálculo/correo electrónico/etc.). El código C# que realiza la consulta de Lucene se ve así:
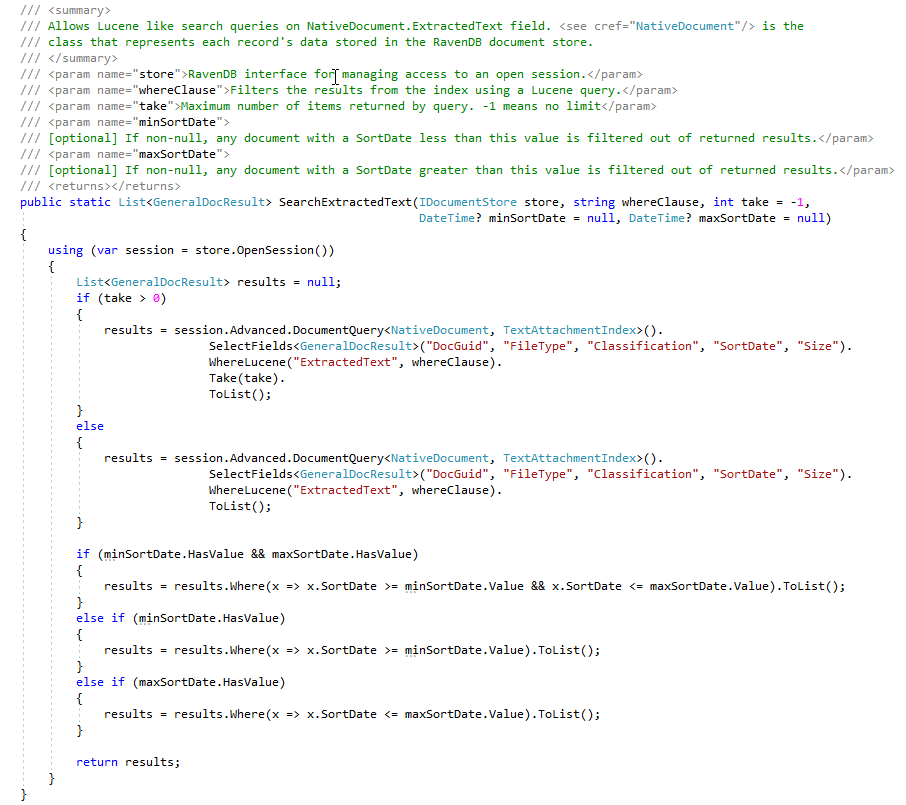
Durante la fase ECA, a los abogados de revisión legal les gusta crear muchas consultas de búsqueda diferentes para encontrar documentos de respuesta. La captura de pantalla a continuación muestra algunas consultas de Lucene guardadas y los resultados (número de golpes de documentos y tamaño total de los documentos). Tenga en cuenta que los recuentos de documentos en estas búsquedas creadas por el usuario contienen recuentos de documentos duplicados, aunque tenemos índices RavendB que cuentan el número de documentos duplicados, para esta prueba de concepto, aún no hemos "marcado" documentos en la tienda de documentos con un indicador que indique maestro/duplicado (esto es un 'TODO' por usuario):
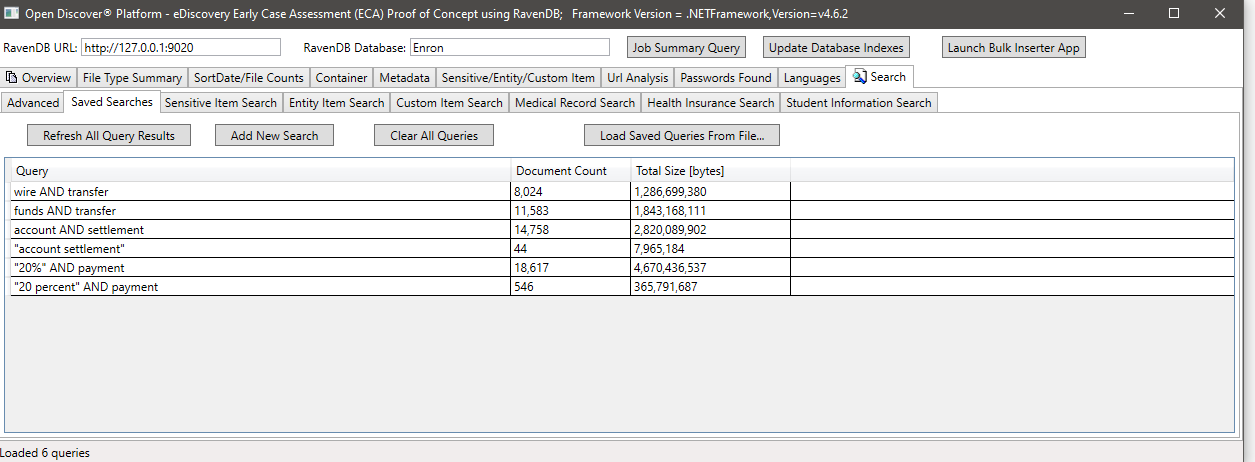
Ejemplo de búsqueda por SensitiveItemType (una propiedad en objetos SensitiveItem detectados que identifica el tipo de elemento sensible), en este ejemplo buscamos todos los documentos que tienen un elemento sensible de tipo SensitiveItemType.BankAccount:
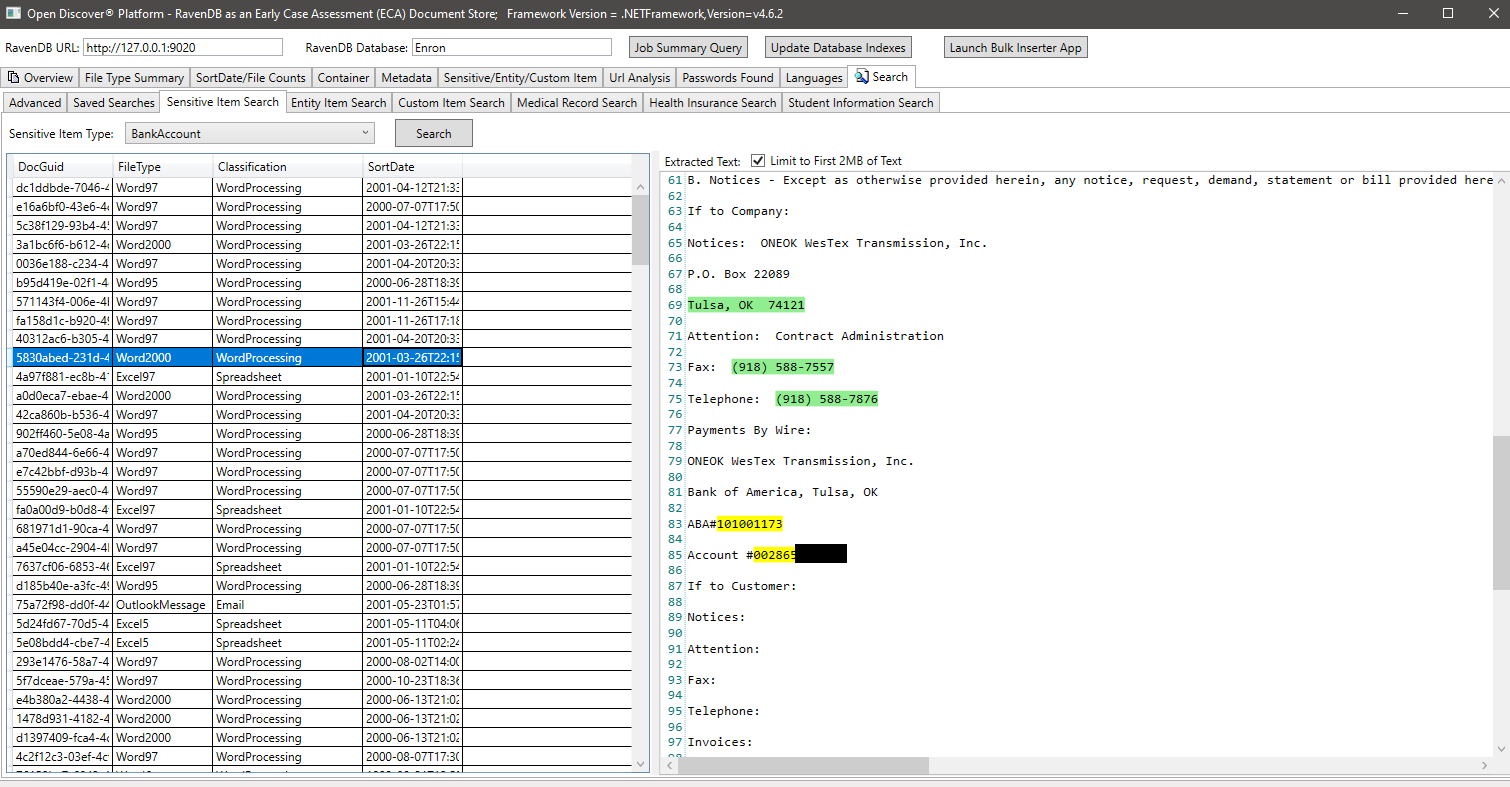
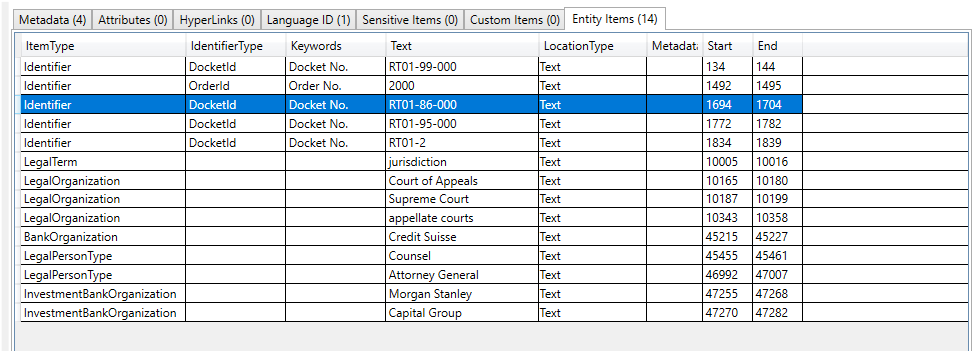
Ejemplo de búsqueda por EntityItemType (una propiedad en objetos de entidad detectados que identifica el tipo de elemento de entidad), en este ejemplo buscamos todos los documentos que tienen un elemento de entidad de tipo entityItemType.patientNameEntry:
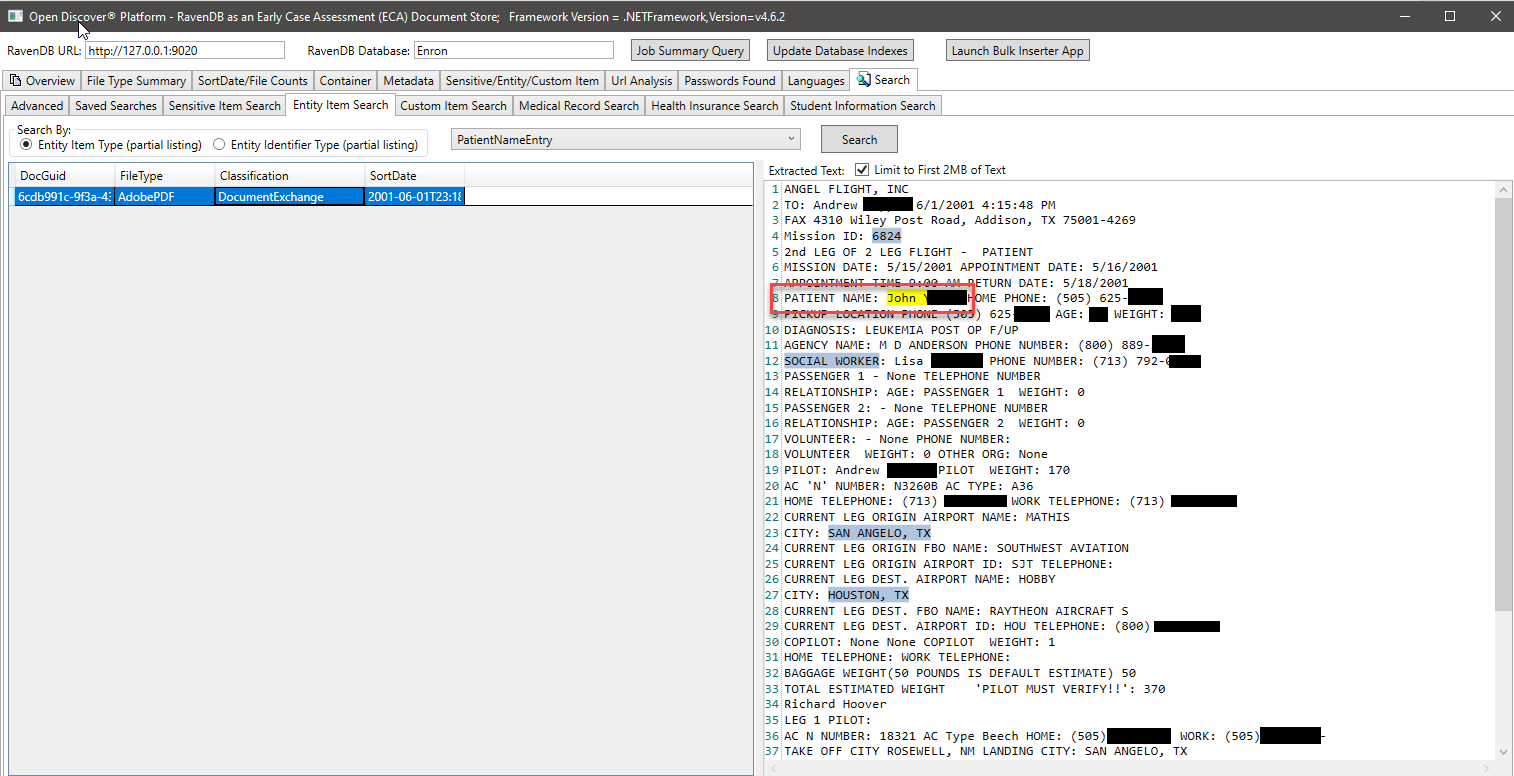
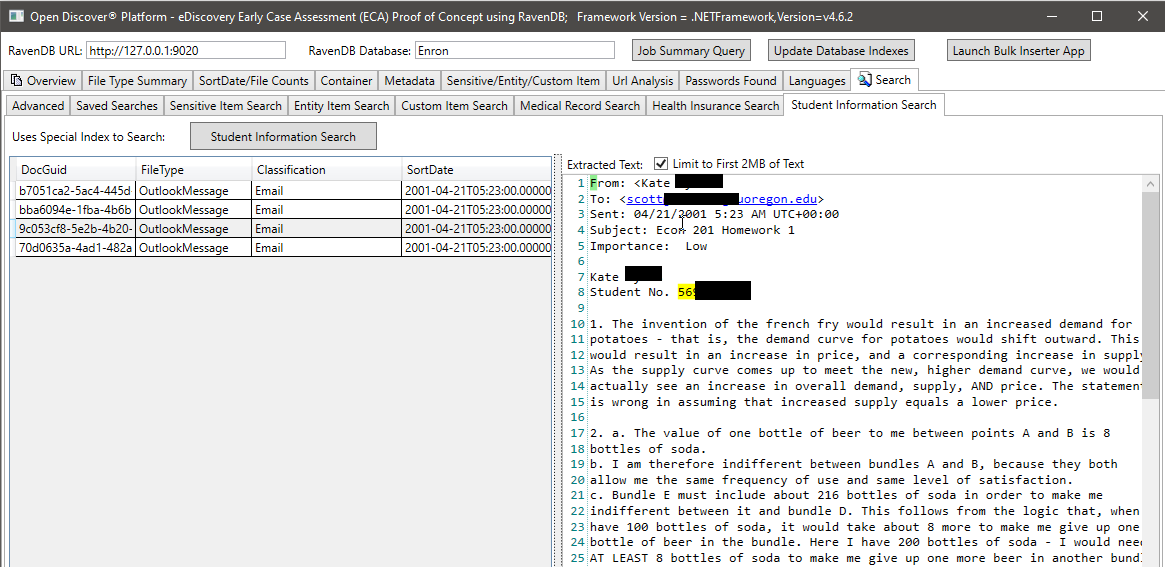
En la captura de pantalla a continuación, utilizamos un índice RavendB especialmente creado que indexa los tipos de entidad extraídos de SDK abiertos específicos relacionados con la información del estudiante para encontrar documentos que puedan tener información del estudiante (en la captura de pantalla, el nombre del estudiante y la identificación del estudiante se bloquean, la identificación del estudiante parece ser un número de seguridad social que era común antes de la década de 2000). Del mismo modo, tenemos otros índices especiales para buscar registros médicos e información del paciente:
La salida de la plataforma Open Discover® almacenada en una base de datos de documentos como RAVENDB puede conducir a aplicaciones de evaluación de casos temprana (ECA) muy potentes y rápidamente desarrolladas. Además, las aplicaciones como las siguientes también se pueden desarrollar rápidamente:
Si este estudio de caso hubiera utilizado una base de datos relacional en lugar de una base de datos de documentos como RAVENDB, habría llevado meses de diseño de esquema de bases de datos y desarrollo de procedimientos de almacenamiento y no las 2 semanas en el tiempo que llevó al autor desarrollar esta prueba de concepto de evaluación de casos temprano (ECA).


