OpenDiscoverPlatformCaseStudy
1.0.0
ดู Open Discover® SDK สำหรับ. NET ตัวอย่างที่เก็บ GitHub
โดยทั่วไปอินสแตนซ์ของ Open Discover Platform API นั้นมีความสามารถในการประมวลผลชุดเอกสารที่อัตรา 40-70 GB/ชั่วโมง* (* อัตราจะขึ้นอยู่กับฮาร์ดแวร์ผู้ใช้และประเภทไฟล์ในชุดข้อมูล) มันเร็วมากในการประมวลผลเอกสารในขณะที่ยังแยกเนื้อหามากกว่าซอฟต์แวร์ Ediscovery ส่วนใหญ่ (เช่นการตรวจจับรายการ/เอนทิตีที่ละเอียดอ่อนและการยกเลิกการใช้งานขณะประมวลผล) แอปพลิเคชั่น Discover Platform API Demo, Platformapidemo.exe ถูกใช้เพื่อประมวลผลชุดข้อมูล Enron Outlook PST แอปพลิเคชั่นสาธิต platformapidemo.exe จะปิดหนึ่งอินสแตนซ์ของคลาสการประมวลผลเอกสารแพลตฟอร์ม API ภาพหน้าจอของตัวอย่าง platformapidemo.exe เอาต์พุตการประมวลผลจะแสดงในส่วนถัดไปด้านล่าง
platformapidemo.exe จัดจำหน่ายด้วยการประเมินผลแพลตฟอร์ม Open Discover พร้อมกับ:
ในการทดสอบประสิทธิภาพเมื่อเร็ว ๆ นี้ Open Discover SDK ประมวลผลชุดข้อมูล PST ของ Enron Microsoft Outlook 53 GB และจำนวนมากแทรกเอาท์พุท API แพลตฟอร์ม (ข้อความ/ข้อมูลเมตา/ข้อมูลที่ละเอียดอ่อน (PXI)/etc) ลงใน Ravendb ในเวลาเพียง 30 นาที
** อัตราการประมวลผลกรณีศึกษานี้สำหรับ. NET 4.62 เวอร์ชัน SDK รุ่น. NET 6 รุ่นใหม่นั้นเร็วกว่า 100% โดยเฉลี่ยแล้วงานประมวลผล PST ทั้งหมดในรุ่น. NET 6 รุ่นของการประมวลผลข้อมูลที่ใช้งานจริง เดสก์ท็อปพีซีที่มี CPU Intel i7 และ RAM 16GB)
ภาพหน้าจอด้านล่างแสดงรายการอีเมล (และไฟล์แนบ) ที่ถูกแยกออกจากคอนเทนเนอร์ PST Outlook และประมวลผลโดยแอปพลิเคชัน Platformapidemo.exe อีเมลมาจากหนึ่งใน Enron Microsoft Outlook PST การควบคุมมุมมองต้นไม้ทางด้านซ้ายของภาพแสดงลำดับชั้นของผู้ปกครอง/เด็กของเอกสาร/คอนเทนเนอร์ที่ประมวลผลทั้งหมดและคลิกที่รายการในการควบคุมต้นไม้จะแสดงเนื้อหาที่แยกออกมา สำหรับรายการอีเมล Outlook ที่เลือกในมุมมองต้นไม้เราจะเห็นว่ามีเอกสารคำศัพท์ MS 6 MS เป็นไฟล์แนบที่ถูกแยกออกจากอีเมล แต่ละรายการสิ่งที่แนบ/ทุกตัวที่ฝังตัวก็มีการสกัดเนื้อหาของพวกเขา (การประมวลผลอย่างเต็มที่จะคลี่คลายลำดับชั้นของเด็กแม่ไม่ว่าจะซับซ้อนเพียงใด) หมายเหตุผลลัพธ์การระบุรูปแบบไฟล์คำนวณ "sortDate", เอกสารต่างๆแฮช, ข้อมูลเมตาดาต้าที่แยกออกมาและรายการแท็บอื่น ๆ ที่ด้านขวาบนของภาพที่มีเนื้อหาที่แยกอื่น ๆ :
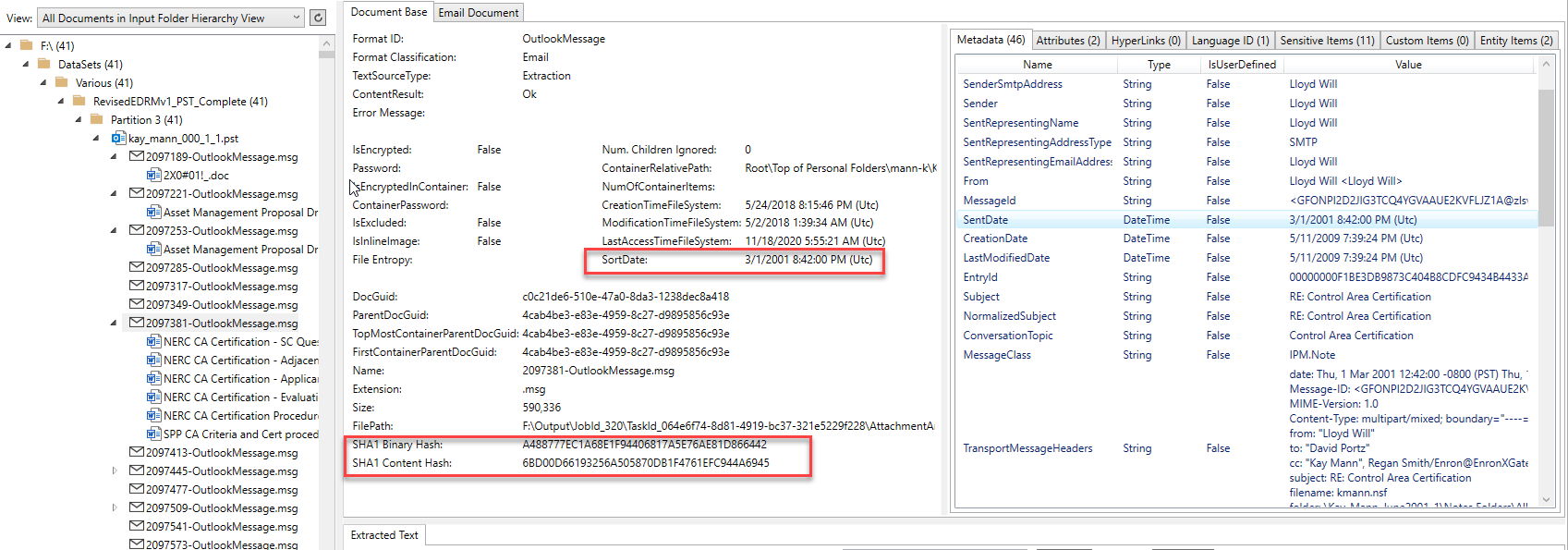
อีเมลเนื้อหาเฉพาะเช่นผู้รับและแฮชพิเศษทั้งหมด:
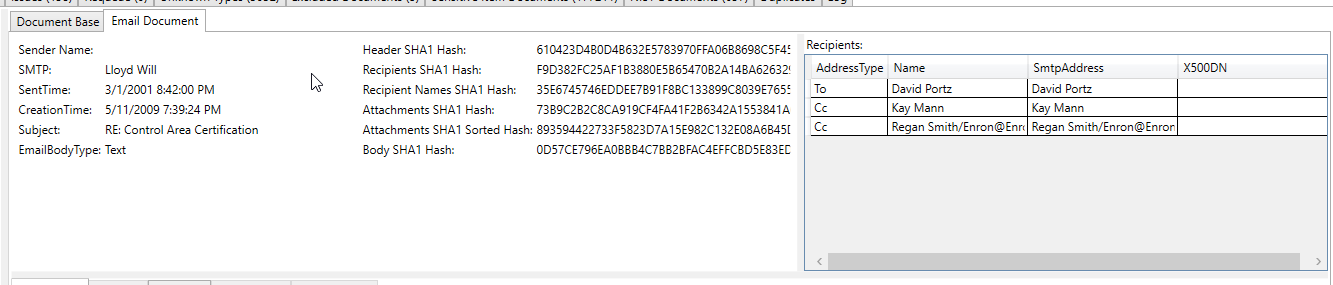
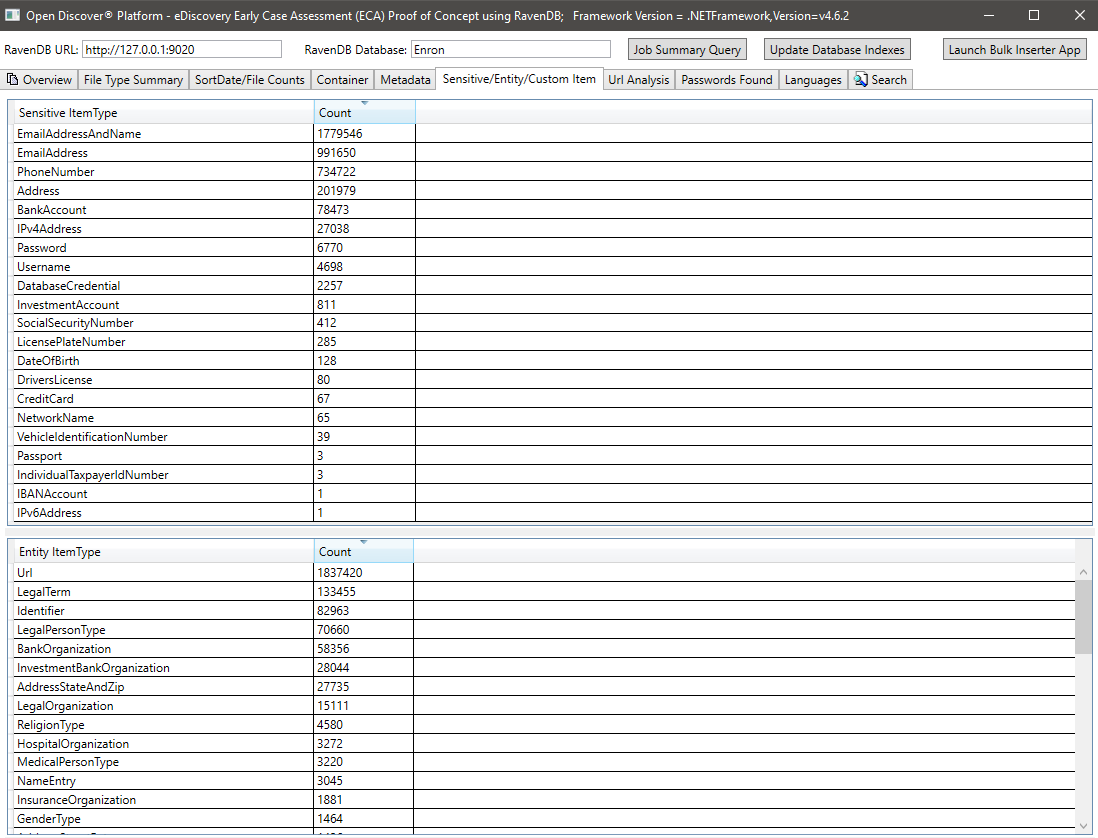
ช็อตหน้าจออีเมลที่ประมวลผลนี้แสดงหมายเลขบัญชีธนาคารที่สกัด/ระบุว่าเป็น "รายการที่ละเอียดอ่อน" ในข้อความที่สกัดจากอีเมล (ข้อความที่แยกทั้งหมดและข้อมูลเมตาทั้งหมดจะถูกสแกนสำหรับรายการที่ละเอียดอ่อน):
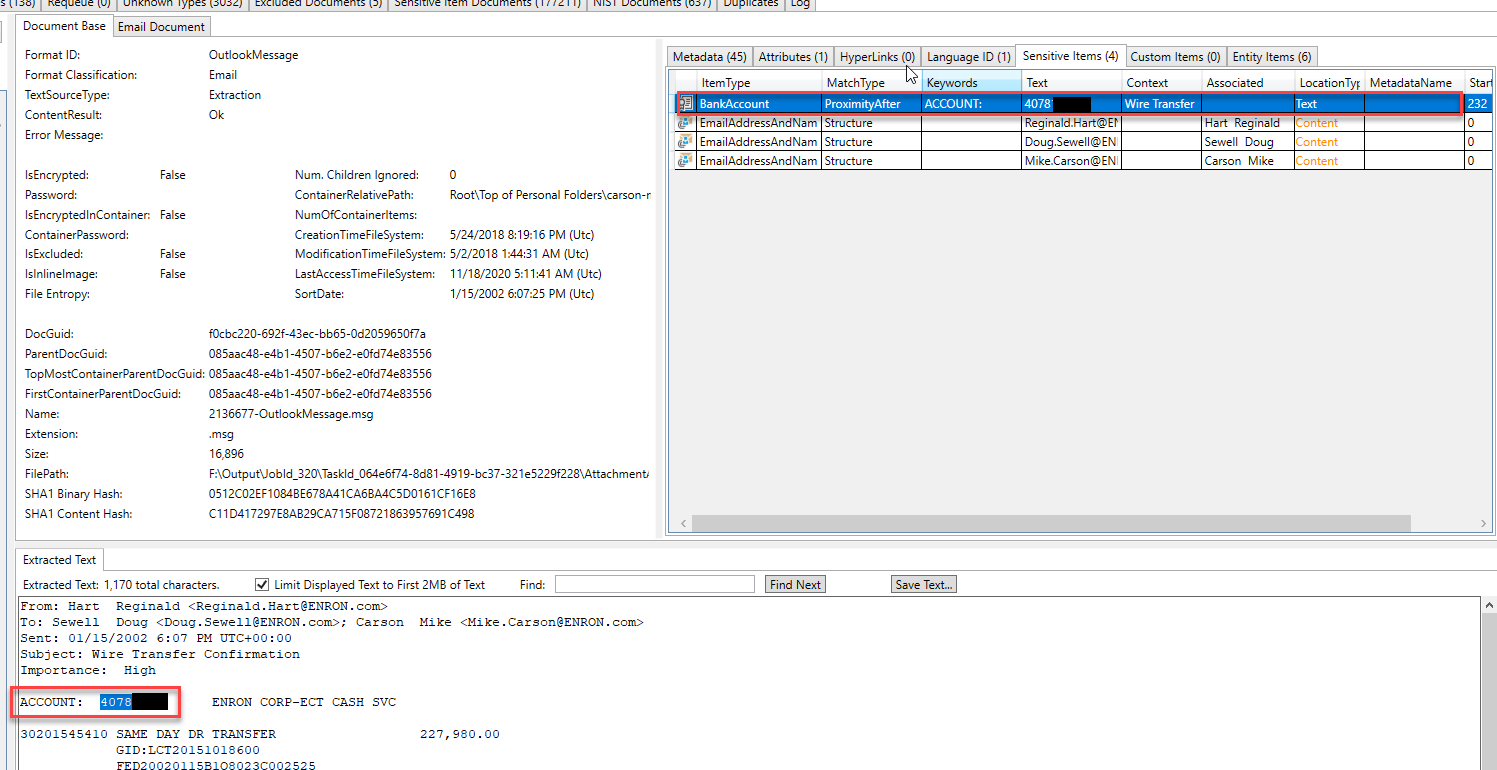
"เอนทิตี" บางตัวที่ระบุและสกัดในอีเมลอื่น โดยการตรวจสอบประเภทของเอนทิตีที่พบในอีเมลนี้เราสามารถคาดการณ์ได้ว่าอีเมลกำลังพูดถึงเรื่องทางกฎหมาย:
ภาพหน้าจอด้านล่างแสดงฐานข้อมูล Enron ในสตูดิโอ Ravendb ที่เต็มไปด้วยแพลตฟอร์ม API เอาต์พุตที่ประมวลผล มีเพียงบางส่วนของฟิลด์เอกสารฐานข้อมูลที่เก็บไว้ใน Ravendb สามารถพอดีกับภาพหน้าจอมีอีกหลายฟิลด์ ชื่อคอลัมน์ที่มีคำอธิบายประกอบชายแดนสีแดงเป็นคอลเลกชันของวัตถุ:
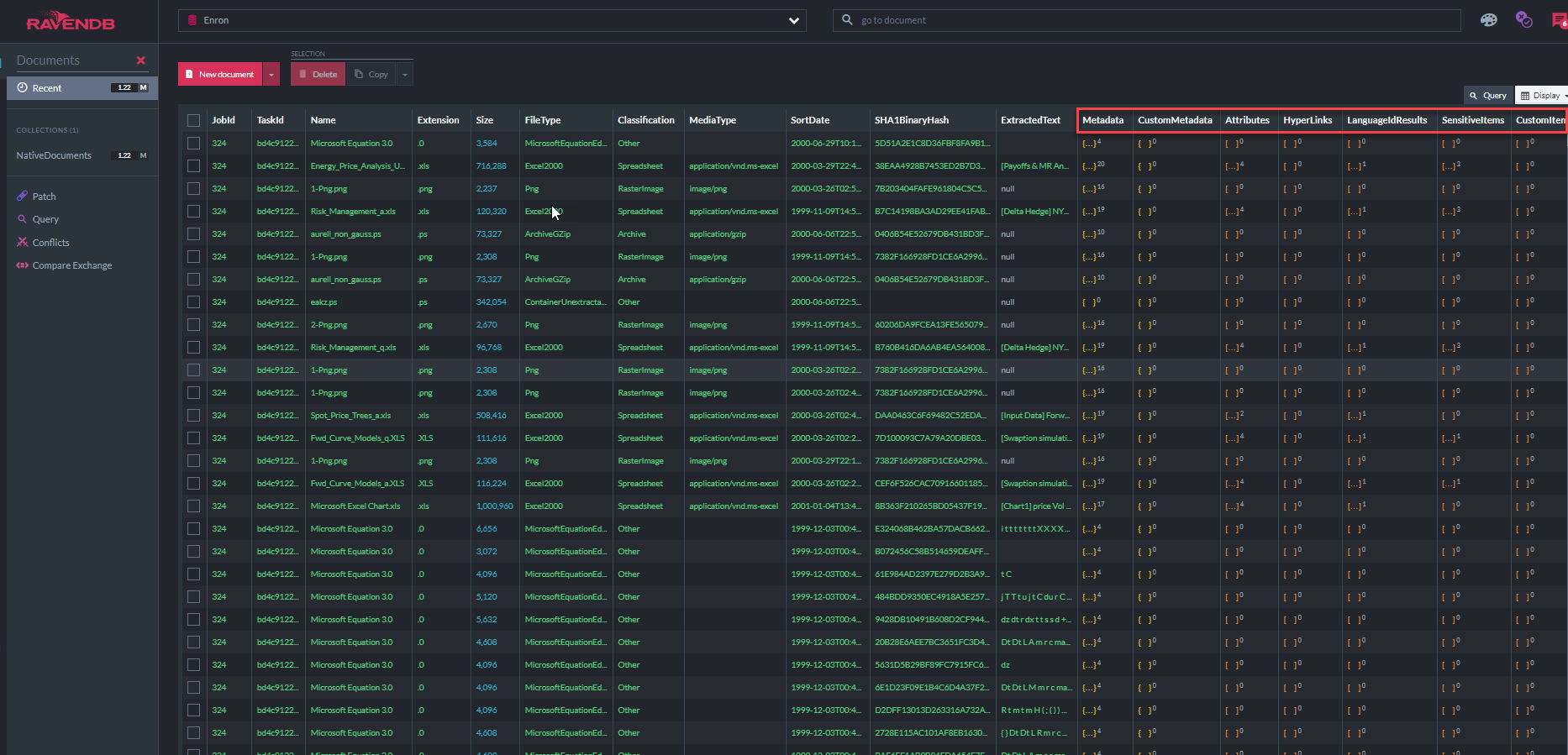
ภาพหน้าจอด้านล่างแสดงดัชนี Ravendb 31 รายการที่แอพ "ECA Demo" ใช้ในการสอบถามร้านเอกสาร (โปรดทราบว่า "metadatapropertyindex" แสดงให้เห็นว่ามีคุณสมบัติเมตาดาต้า 37.7 ล้านรายการที่เก็บไว้ในฐานข้อมูลนี้ส่วนใหญ่เป็นอีเมลเมตาดาต้าอีเมล
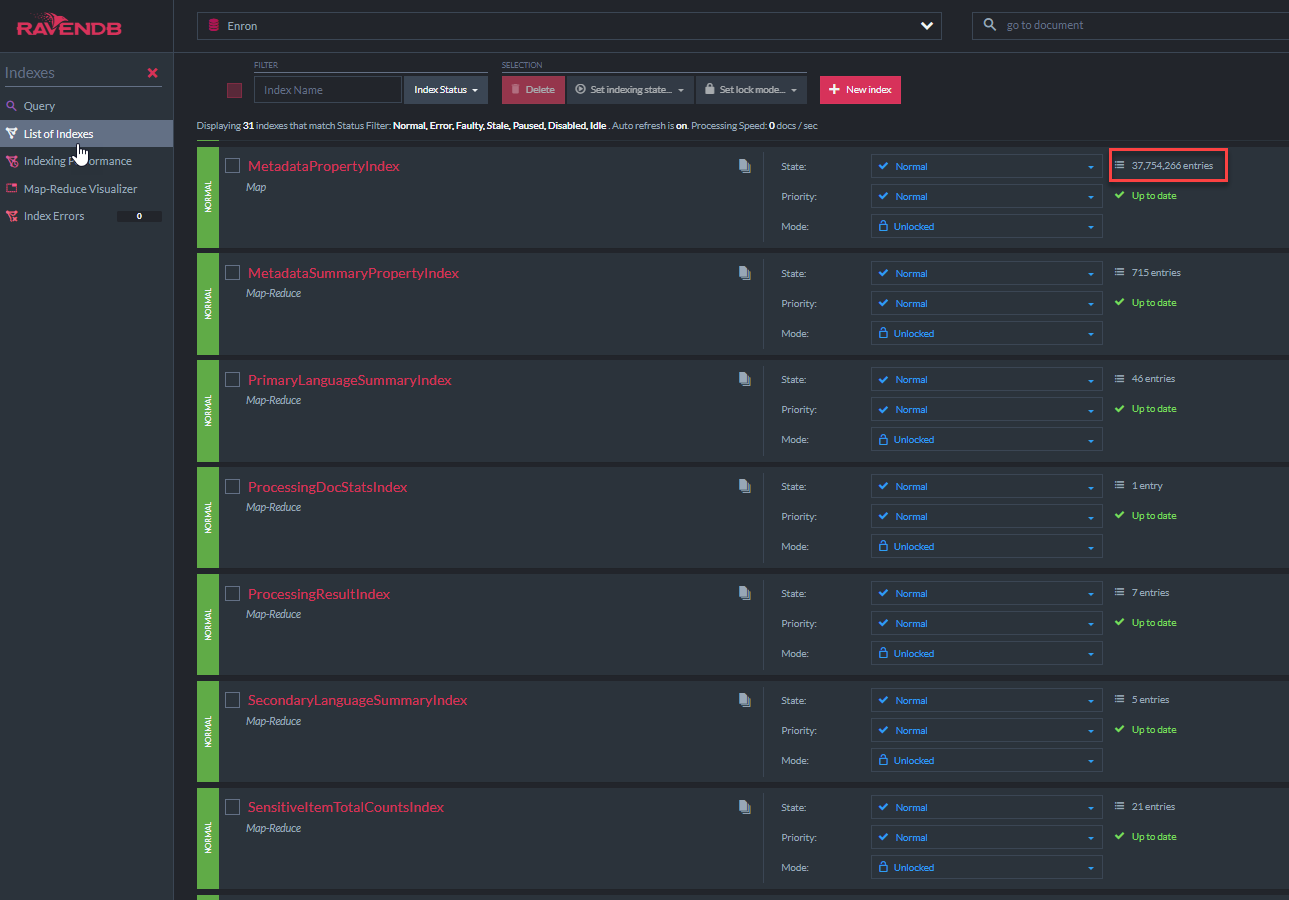
"MetadatapropertyIndex" รหัสคลาส C# จะแสดงด้านล่าง คลาสดัชนีนี้มาจาก AbstractIndexcreationTask ของ Ravendb (เช่นเดียวกับดัชนีอื่น ๆ ทั้งหมดในการสาธิตนี้) ดัชนีนี้จะอนุญาตให้ Lucene 'Like' Queries ในสาขาข้อมูลเมตาทั้งหมด มีดัชนีที่คล้ายกันสำหรับ nativedocument.custommetadata มีอยู่:
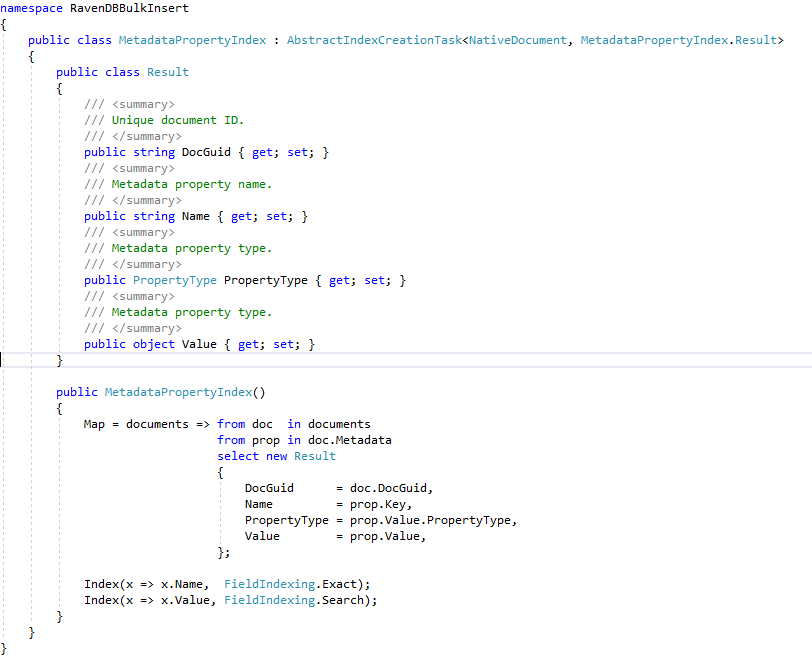
ดัชนี Ravendb ที่กำหนดทั้งหมด C# ทั้งหมดได้รับการสร้างขึ้นในฐานข้อมูล Ravendb Enron จาก "แอป ECA Demo" ผ่านการโทร Ravendb API แบบง่าย ๆ :
ภาพหน้าจอด้านล่างแสดงสถิติสรุปการประมวลผลของชุดข้อมูล PST ENRON 189 Microsoft Outlook (1,221,542 อีเมลและไฟล์แนบที่ประมวลผลทั้งหมด) อีเมลและไฟล์แนบส่วนใหญ่ในชุดข้อมูลนี้เป็นเอกสารที่ซ้ำกันเนื่องจากพนักงาน Enron ที่รวบรวมข้อมูลในระหว่างขั้นตอนการค้นพบทางกฎหมายกำลังส่งอีเมลซึ่งกันและกัน - สถิติการขจัดข้อมูลซ้ำซากที่แสดงในภาพด้านล่างนั้นขึ้นอยู่กับแฮชไบนารี/เนื้อหาในอนาคต หมายเหตุแผนภูมิพายการจำแนกรูปแบบไฟล์สรุปแผนภูมิพายรูปแบบไฟล์เฉพาะและสรุปผลการประมวลผล (ประเภทการแจงนับที่มีค่าของ OK/WrongPassword/DataError/ฯลฯ ) แผนภูมิวงกลม
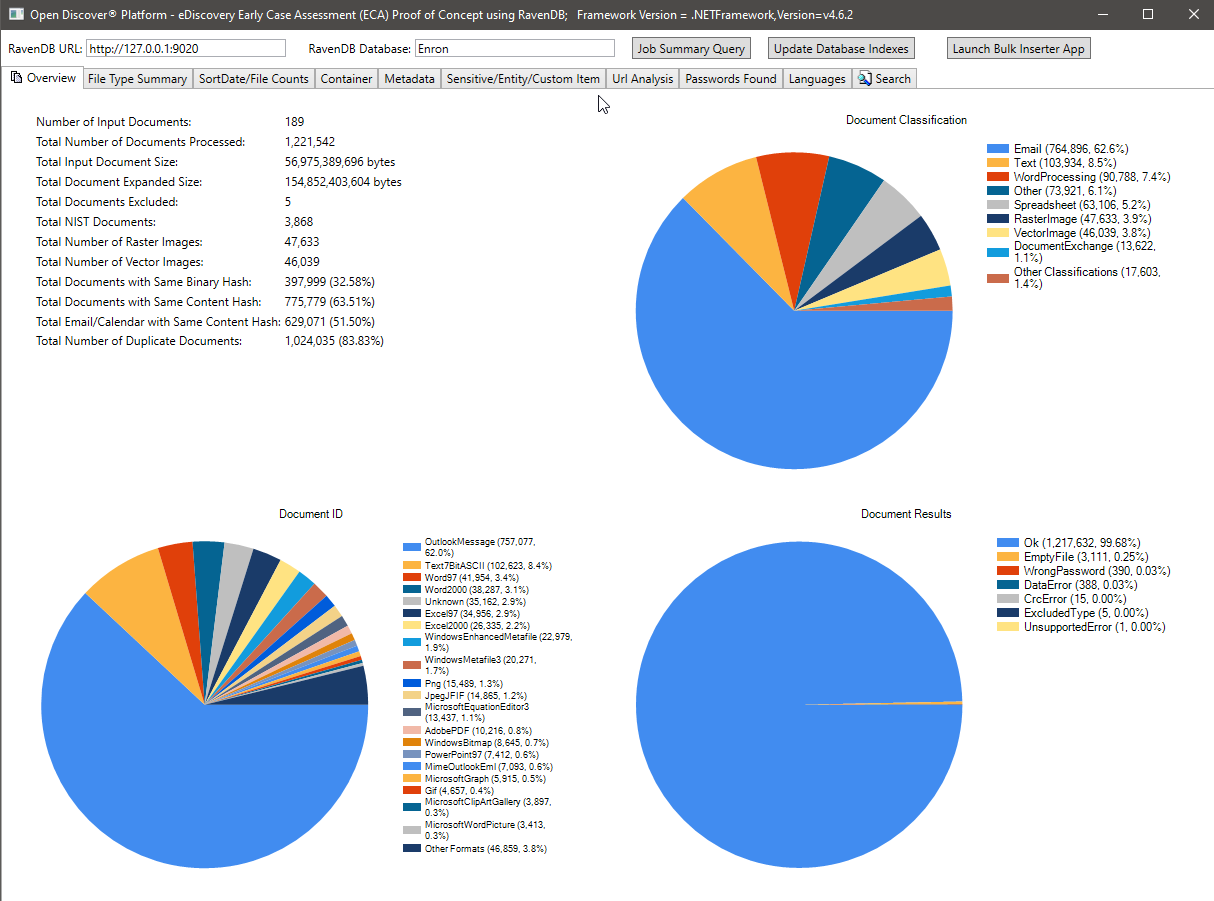
นับจำนวนไฟล์โดยแผนภูมิสรุป SortDate:
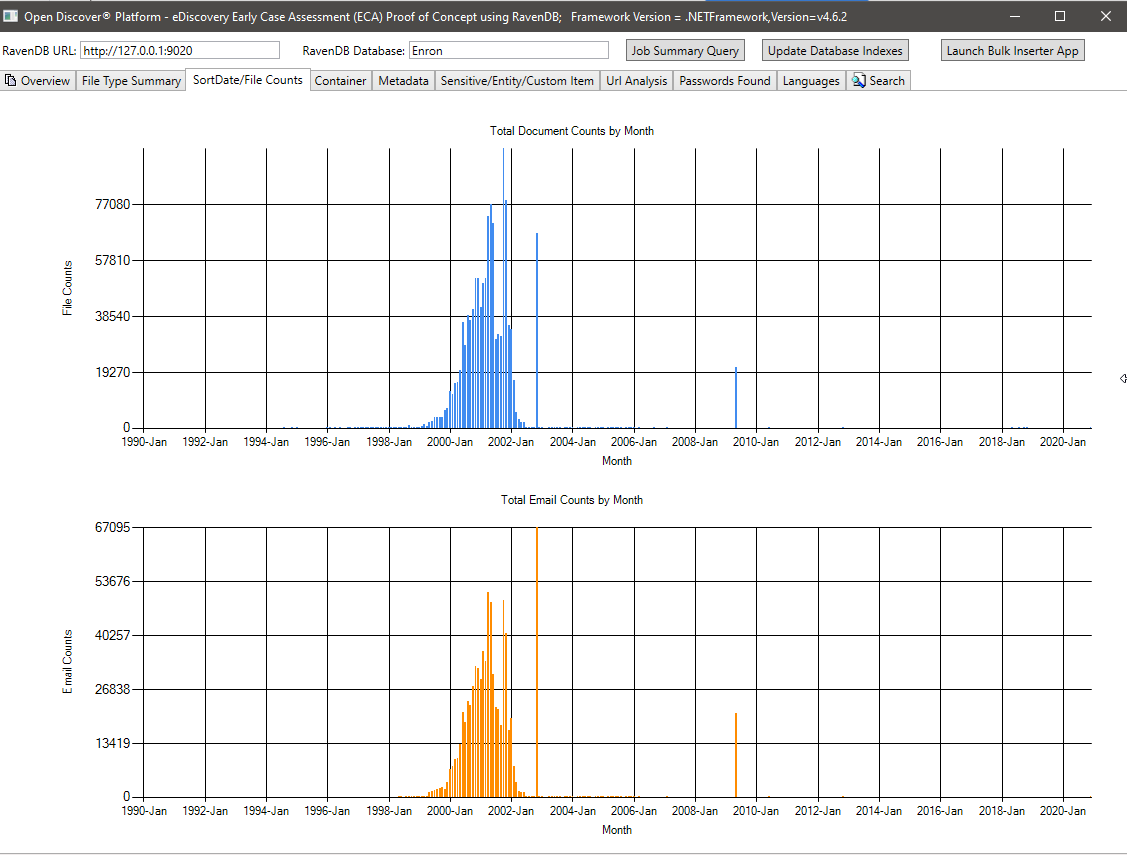
สรุปข้อมูลเมตา (ชื่อฟิลด์ข้อมูลเมตา/จำนวนเอกสารทั้งหมด) - 715 ชื่อฟิลด์เมตาดาต้าที่ไม่ซ้ำกันที่รู้จักกันในเอกสารทั้งหมดและ 636 กำหนดเอง (กำหนดผู้ใช้) ฟิลด์เมตาดาต้า แบบสอบถามนี้สามารถช่วยผู้จัดการกรณีกฎหมายทราบว่ามีฟิลด์ข้อมูลเมตาอะไรในคอลเลกชันเพื่อค้นหา:
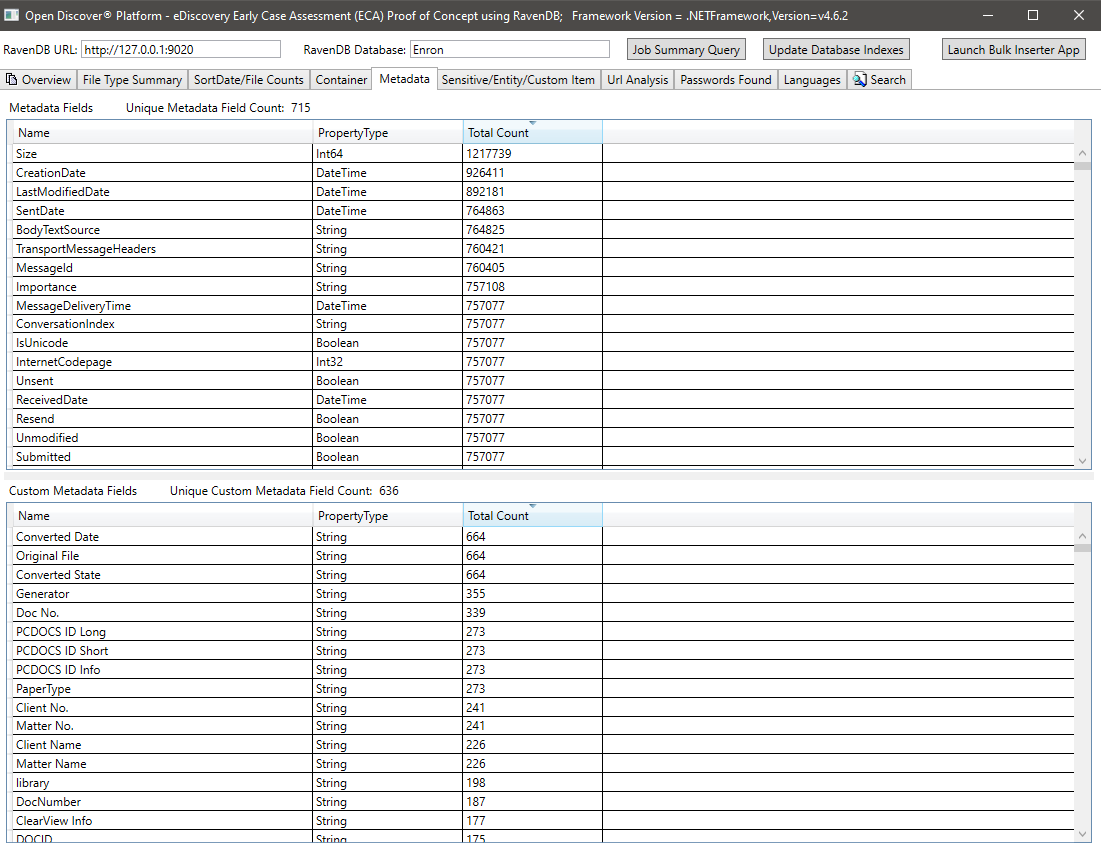
รายการที่ละเอียดอ่อน/รายการสรุปสำหรับเอกสารทั้งหมด:
บทสรุปของ URL ที่ไม่ซ้ำกันทั้งหมดที่พบในเอกสารทั้งหมด (URL จากทุกเอกสารอาจมีประโยชน์เช่นหาก บริษัท ต้องการติดตามจุดเข้า URL ที่เป็นอันตรายที่อาจเกิดขึ้น) เปิด Discover SDK ตรวจพบ URL ทั้งหมดจาก HyperLinks เอกสารและในข้อความเอกสาร (เช่น Non-Hyperlink):
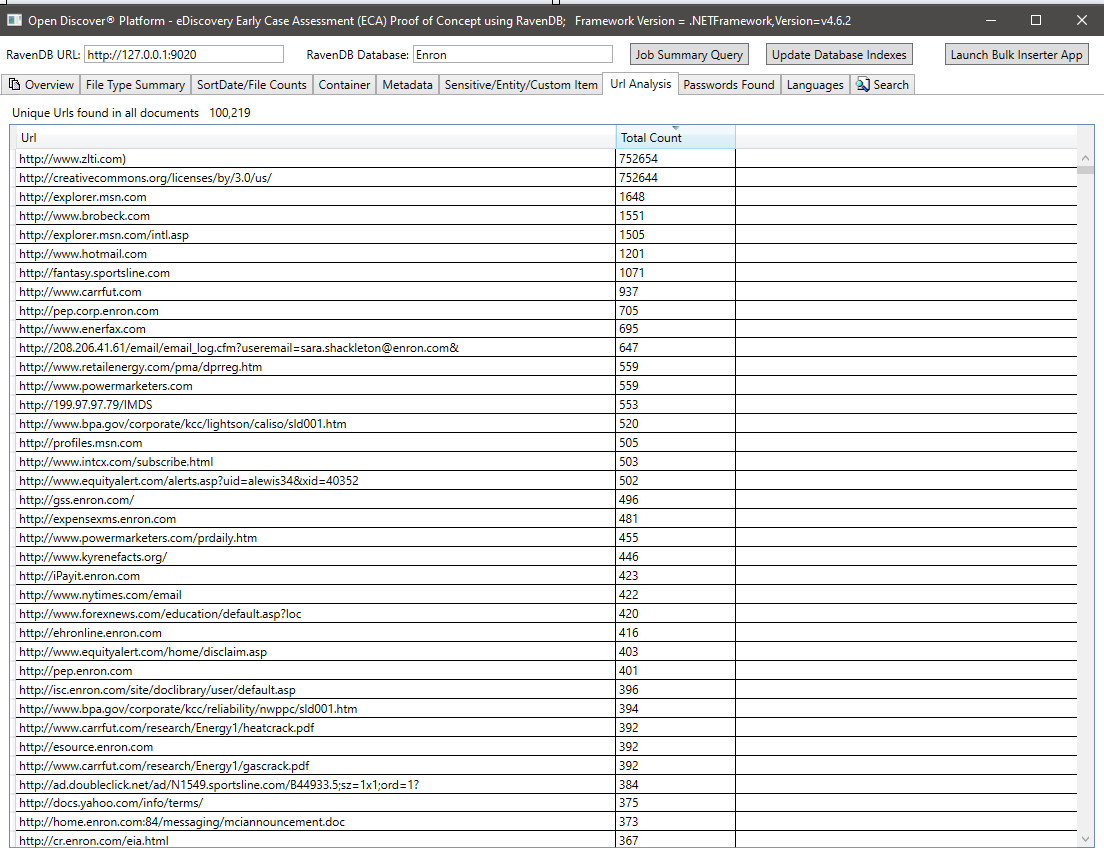
สรุปรหัสผ่านทั้งหมดที่พบในเอกสารทั้งหมด รหัสผ่านและชื่อผู้ใช้เป็นเพียง 2 จาก 25 ประเภท 'รายการที่ละเอียดอ่อน' ในตัวที่รองรับโดย Open Discover SDK/แพลตฟอร์ม รหัสผ่าน/ชื่อผู้ใช้ชื่อในเอกสารอาจเป็นความเสี่ยงด้านความปลอดภัยพวกเขายังสามารถใช้ในการประมวลผลเอกสารใด ๆ ที่มีผลการประมวลผลของ 'WrongPassword' (ในฐานะพนักงานใน บริษัท เดียวกันมักส่งอีเมลรหัสผ่านอื่น ๆ ไปยังเอกสารสำนักงานที่เข้ารหัสที่แชร์
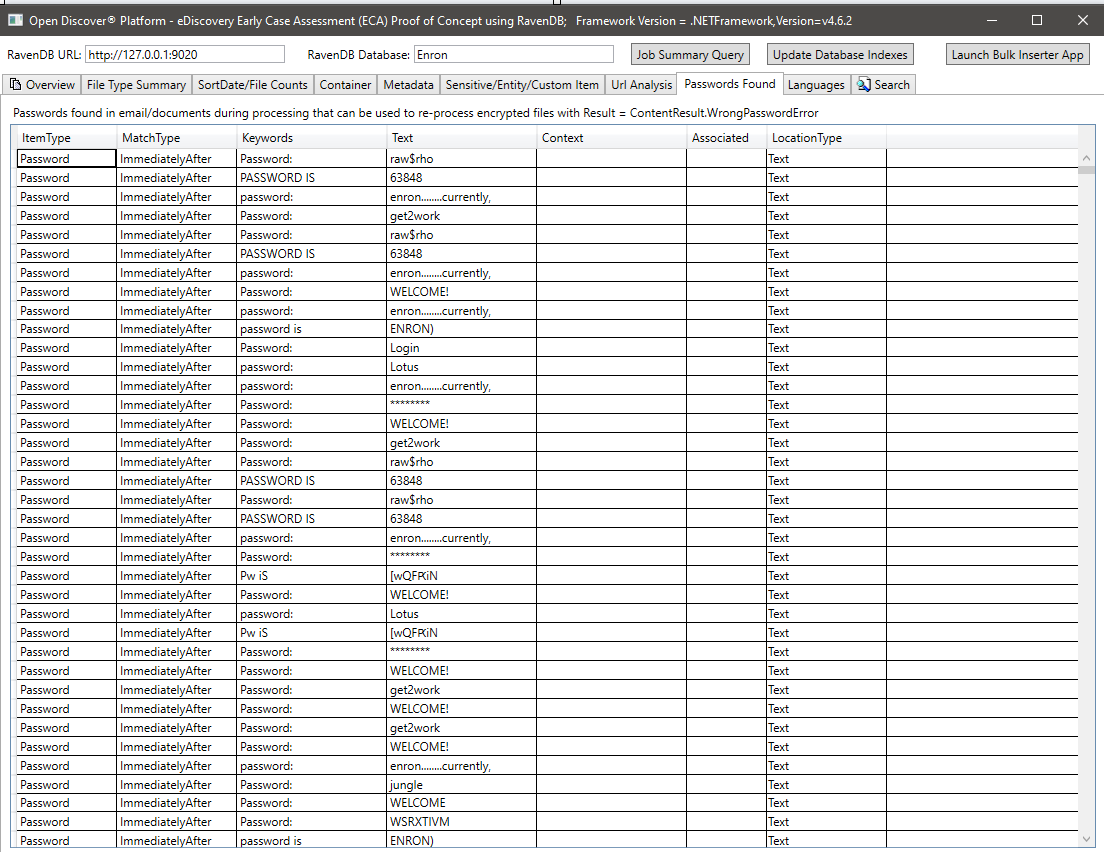
บทสรุปของภาษาที่ตรวจพบในข้อความที่สกัดของเอกสารที่ประมวลผล:
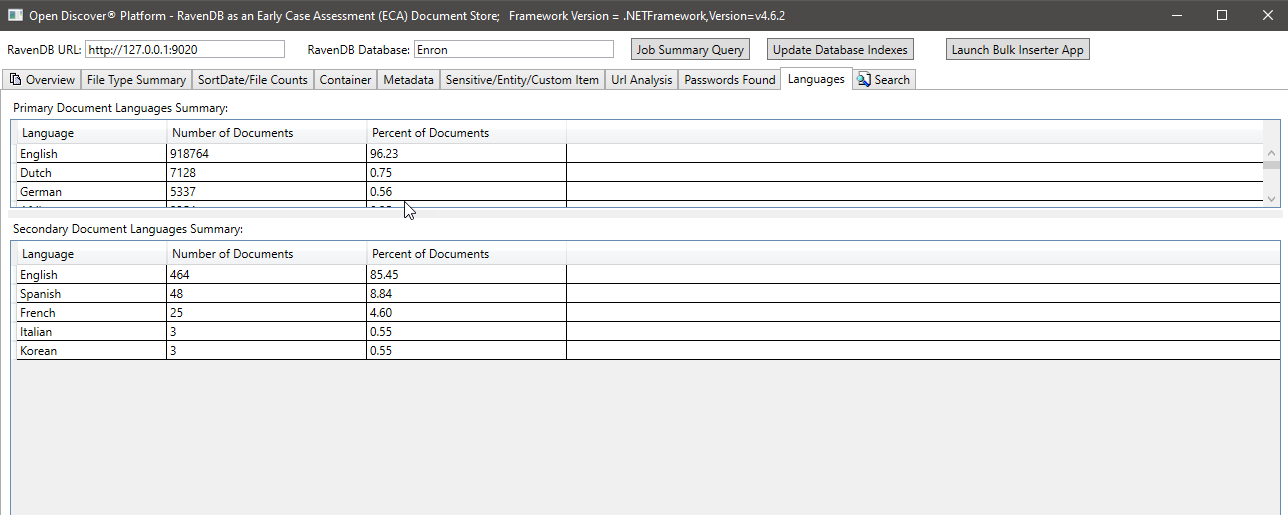
ตัวอย่างข้อความค้นหาข้อความแบบเต็ม (หมายเหตุ: Ravendb รองรับ Lucene Queries):
แบบสอบถาม Lucene ข้างต้นสอบถามฟิลด์ ExtractEdText และใช้ (เป็นทางเลือก) MIN/MAX Document SortDate เพื่อกรองผลการค้นหาที่ส่งคืน มันจะง่ายมากที่จะเพิ่มการกรองผลลัพธ์โดยเอกสารการจำแนกประเภทเอกสารหรือการจำแนกรูปแบบเอกสาร (การประมวลผล WordProcessing/สเปรดชีต/อีเมล/etc) รหัส C# ที่ทำแบบสอบถาม Lucene มีลักษณะเช่นนี้:
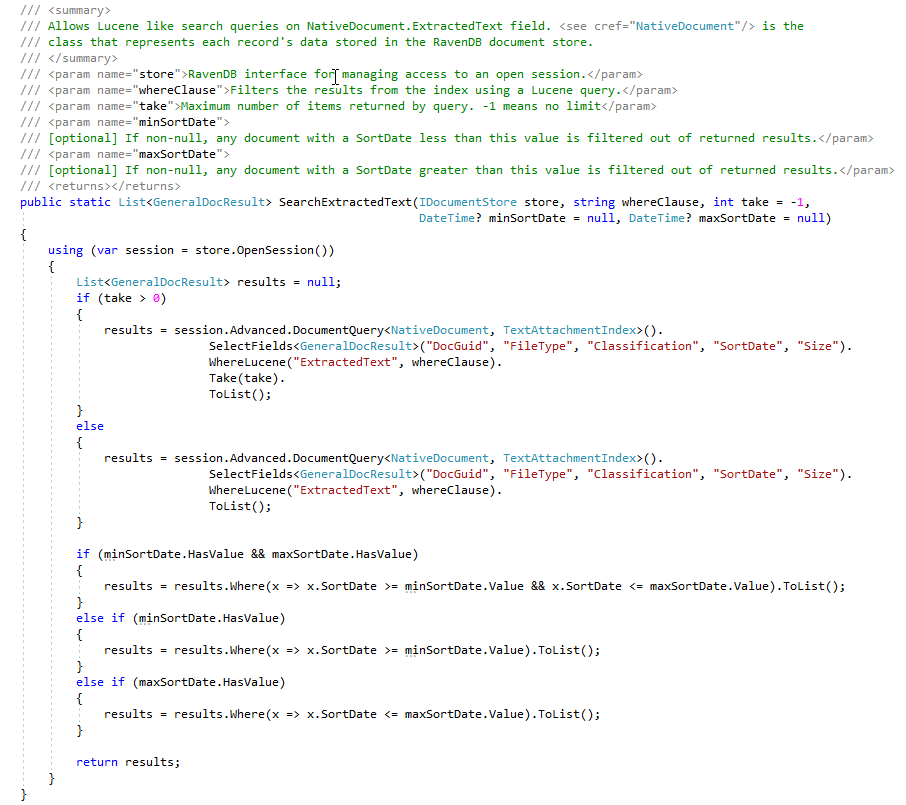
ในช่วง ECA ระยะเวลานักกฎหมายตรวจสอบทางกฎหมายต้องการสร้างคำค้นหาการค้นหาที่แตกต่างกันมากมายเพื่อค้นหาเอกสารที่ตอบสนอง ภาพหน้าจอด้านล่างแสดงการสืบค้น Lucene ที่บันทึกไว้สองสามรายการและผลลัพธ์ (จำนวนเอกสารที่ฮิตและขนาดทั้งหมดของเอกสาร) โปรดทราบว่าเอกสารนับในผู้ใช้เหล่านี้สร้างการค้นหามีจำนวนเอกสารที่ซ้ำกันแม้ว่าเราจะมีดัชนี Ravendb ที่นับจำนวนเอกสารที่ซ้ำกันสำหรับการพิสูจน์แนวคิดนี้เรายังไม่ได้ "ทำเครื่องหมาย" เอกสารในร้านเอกสารที่มีธงที่ระบุต้นแบบ/ซ้ำ (นี่คือ 'toDo' โดยผู้ใช้):
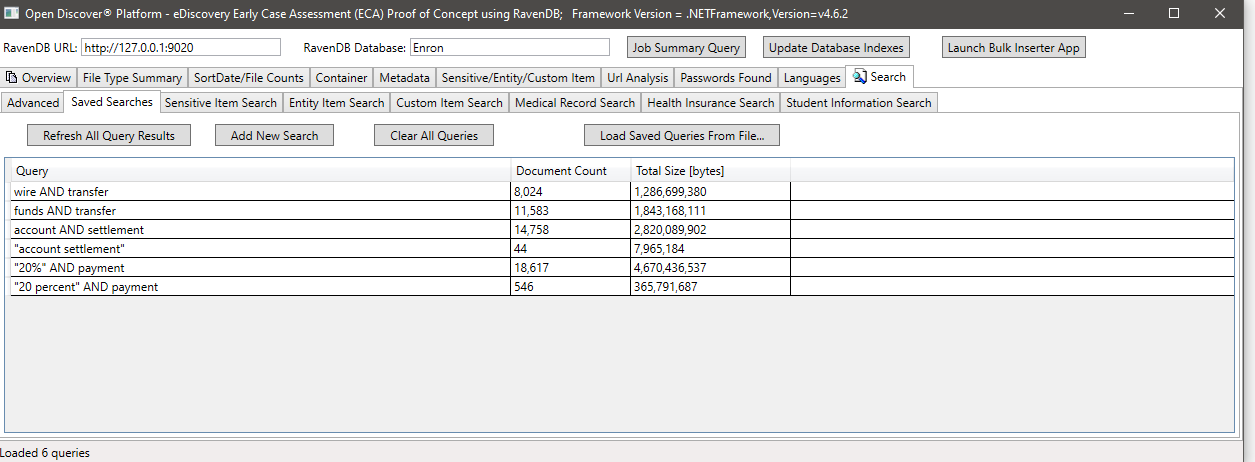
การค้นหาตัวอย่างโดย SensiveTemType (คุณสมบัติในวัตถุที่ตรวจพบ SensitiveItem ที่ระบุประเภทของรายการที่ละเอียดอ่อน) ในตัวอย่างนี้เราค้นหาเอกสารทั้งหมดที่มีรายการที่ละเอียดอ่อน
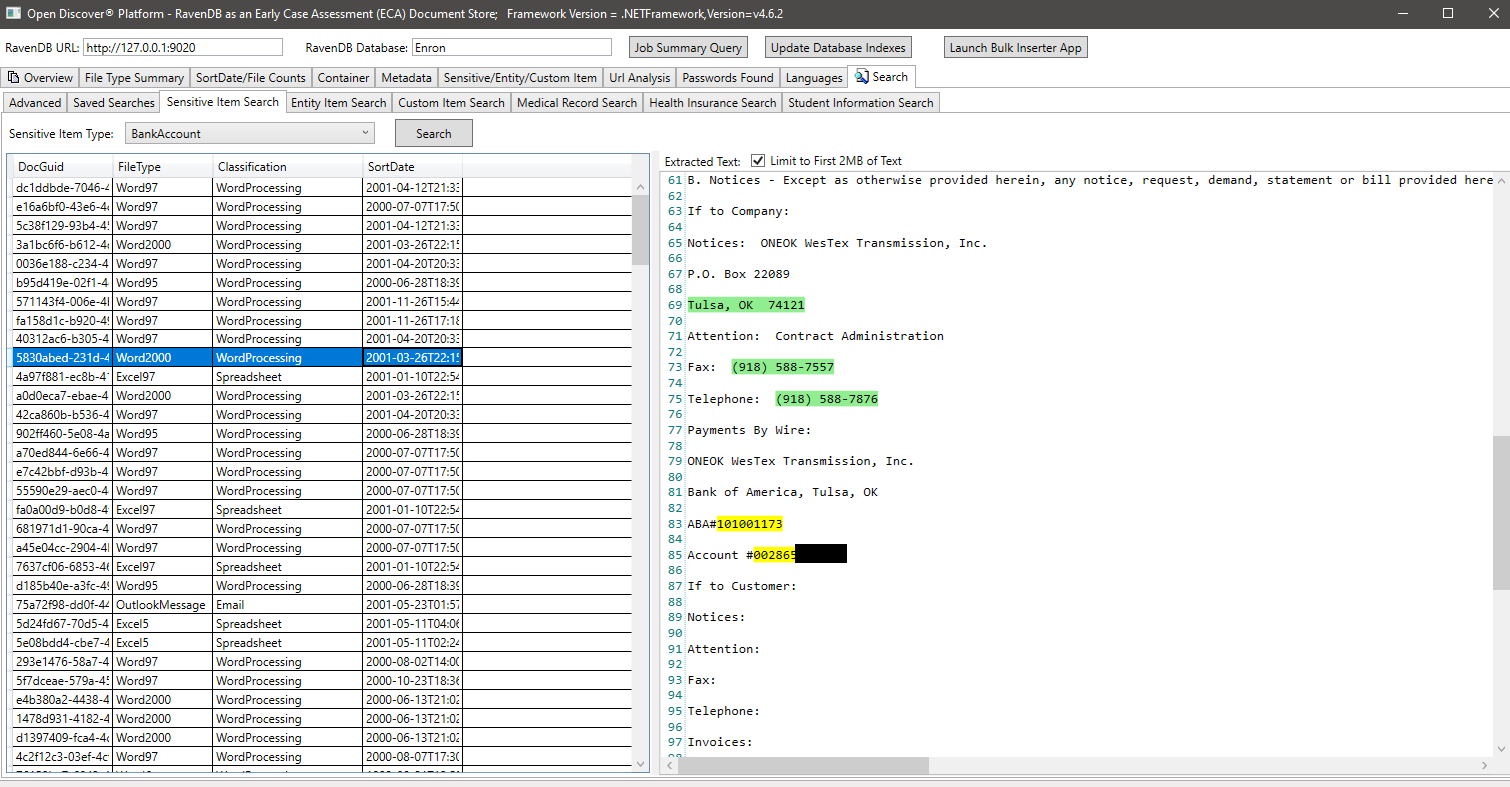
การค้นหาตัวอย่างโดย EntityItemType (คุณสมบัติในวัตถุที่ตรวจพบ entityItem ที่ระบุประเภทของรายการเอนทิตี) ในตัวอย่างนี้เราค้นหาเอกสารทั้งหมดที่มีรายการเอนทิตีประเภท EntityItemType.PatientNameEntry:
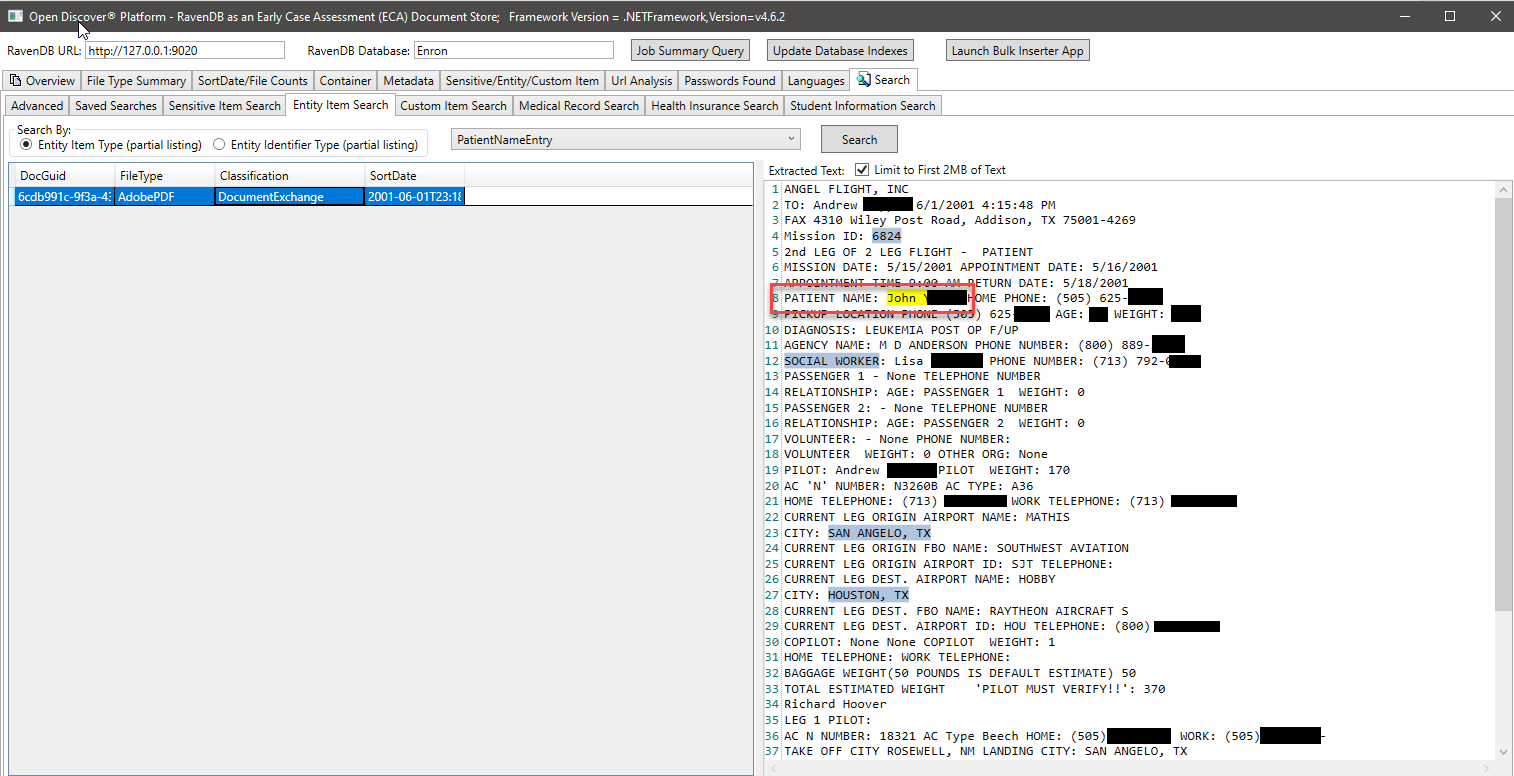
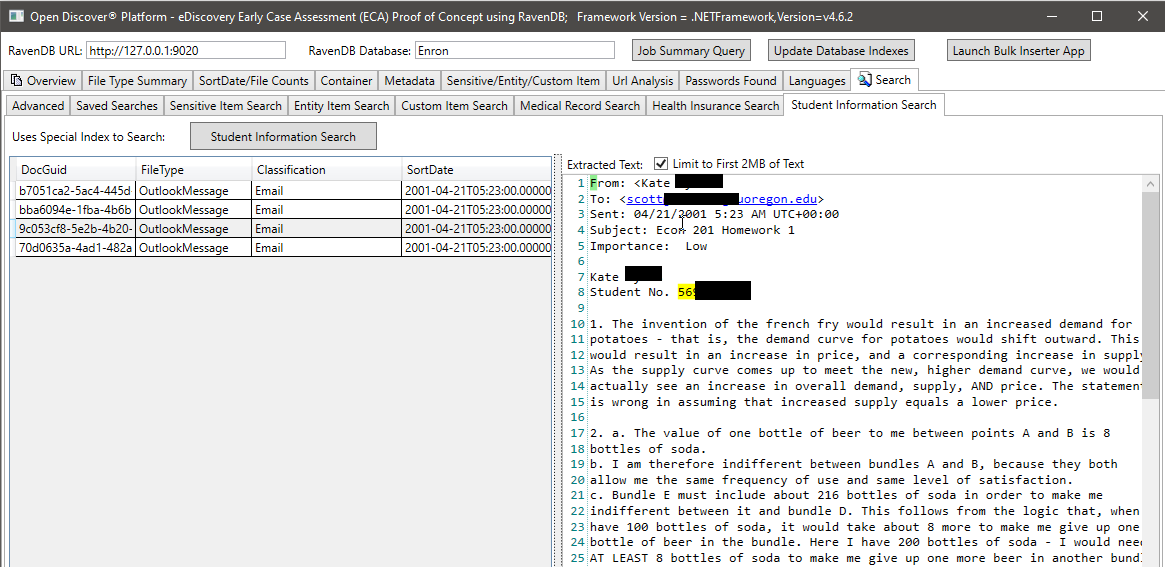
ในภาพหน้าจอด้านล่างเราใช้ดัชนี Ravendb ที่สร้างขึ้นเป็นพิเศษซึ่งจัดทำดัชนีการค้นพบแบบเปิดเฉพาะ SDK ที่สกัดจากข้อมูลที่เกี่ยวข้องกับข้อมูลนักเรียนเพื่อค้นหาเอกสารที่อาจมีข้อมูลนักเรียน (ในการถ่ายภาพหน้าจอชื่อนักเรียนและรหัสนักเรียนจะถูกปิดกั้นรหัสนักเรียนดูเหมือนจะเป็นหมายเลขประกันสังคมซึ่งเป็นเรื่องธรรมดาก่อนปี 2000 ในทำนองเดียวกันเรามีดัชนีพิเศษอื่น ๆ เพื่อค้นหาเวชระเบียนและข้อมูลผู้ป่วย:
Open Discover®เอาต์พุตแพลตฟอร์มที่เก็บไว้ในฐานข้อมูลเอกสารเช่น RavendB สามารถนำไปสู่แอปพลิเคชันการประเมินกรณีก่อนกำหนด (ECA) ที่มีประสิทธิภาพและพัฒนาอย่างรวดเร็ว นอกจากนี้แอปพลิเคชันเช่นต่อไปนี้สามารถพัฒนาได้อย่างรวดเร็ว:
หากกรณีศึกษานี้ใช้ฐานข้อมูลเชิงสัมพันธ์แทนฐานข้อมูลเอกสารเช่น RavendB มันจะต้องใช้เวลาหลายเดือนในการออกแบบสคีมาฐานข้อมูลและการพัฒนาขั้นตอนการจัดเก็บและไม่ใช่ 2 สัปดาห์ในเวลาที่ผู้เขียนพัฒนาหลักฐานการประเมินกรณี (ECA) ของแนวคิด


