OpenDiscoverPlatformCaseStudy
1.0.0
Siehe Open Discover® SDK für .NET -Beispiele Github Repository
Eine einzelne Instanz der Open Discover Platform-API kann in der Regel Dokumentsätze bei 40-70 GB/Stunde* verarbeiten (* Die Tarife sind von Benutzerhardware und Dateitypen im Datensatz abhängig). Es ist sehr schnell bei der Verarbeitung von Dokumenten und extrahiert gleichzeitig mehr Inhalte als die meisten EDIScovery-Software (z. B. sensible Gegenstände/Entitätserkennung und De-NIST-Ing während der Verarbeitung). Eine Open Discover Plattform -API -Demo -Anwendung, Platformapidemo.exe, wurde verwendet, um den PST -Datensatz des Enron Outlook -PST -Datensatzes zu verarbeiten. Die Demo -Anwendung von Platformapidemo.exe wickelt eine Instanz der Plattform -API -Dokumentverarbeitungsklasse. Screen -Aufnahmen von Beispiele Platformapidemo.exe -Verarbeitungsausgabe werden im nächsten Abschnitt unten angezeigt.
Die Plattformapidemo.exe wird zusammen mit der Open Discover Platform Evaluation verteilt:
In einem kürzlich durchgeführten Leistungstest verarbeitete der Open Discover SDK den 53-GB-Enron Microsoft Outlook PST-Datensatz und die Masse die Plattform-API-Ausgabe (Text/Metadaten/empfindliche Elemente (PXI)/usw.) in etwas mehr als 30 Minuten mit einem einzigen 4-Core-Windows-Desktop-PC in RAVENDB.
** Diese Fallstudie -Verarbeitungsrate war für die .NET 4.62 -Version von SDK, die neue .NET 6 -Version ist durchschnittlich> 100% schneller, alle PST -Verarbeitungsaufgaben auf der .NET 6 -Version von OpendiscoverPlatform verarbeitet ihre PST -Datensatzaufgaben zwischen 90 bis 100+GB/HR -Raten (basierend I7 CPU und 16 GB RAM).
Der Screenshot unten zeigt einen E -Mail -Element (und seine Anhänge), der aus dem Outlook PST -Container extrahiert und von der Plattformapidemo.exe -Anwendung verarbeitet wurde. Die E -Mail stammt von einem der PSTs von Enron Microsoft Outlook. Die Baumansicht -Steuerung auf der linken Seite des Bildes zeigt die Eltern/untergeordnete Hierarchie aller verarbeiteten Dokumente/Container. Wenn Sie auf ein Element in der Baumsteuerung klicken, wird der extrahierte Inhalt angezeigt. Für das ausgewählte Outlook -E -Mail -Element in der Baumansicht können wir feststellen, dass es 6 ms Büro -Word -Dokumente als Anhänge hat, die aus der E -Mail extrahiert wurden. Bei jedem Anhang/eingebettetem Element wurde auch der Inhalt extrahiert (die Verarbeitung wird eine übergeordnete Kinderhierarchie vollständig abrollen, egal wie komplex). Beachten Sie die Ergebnisse der Dateiformatidentifikation, berechnete "Sortdate", verschiedene Dokument-Hashes, die extrahierten Metadaten und andere Registerkartenelemente auf der oberen rechten Seite des Bildes, die andere extrahierte Inhalte enthalten:
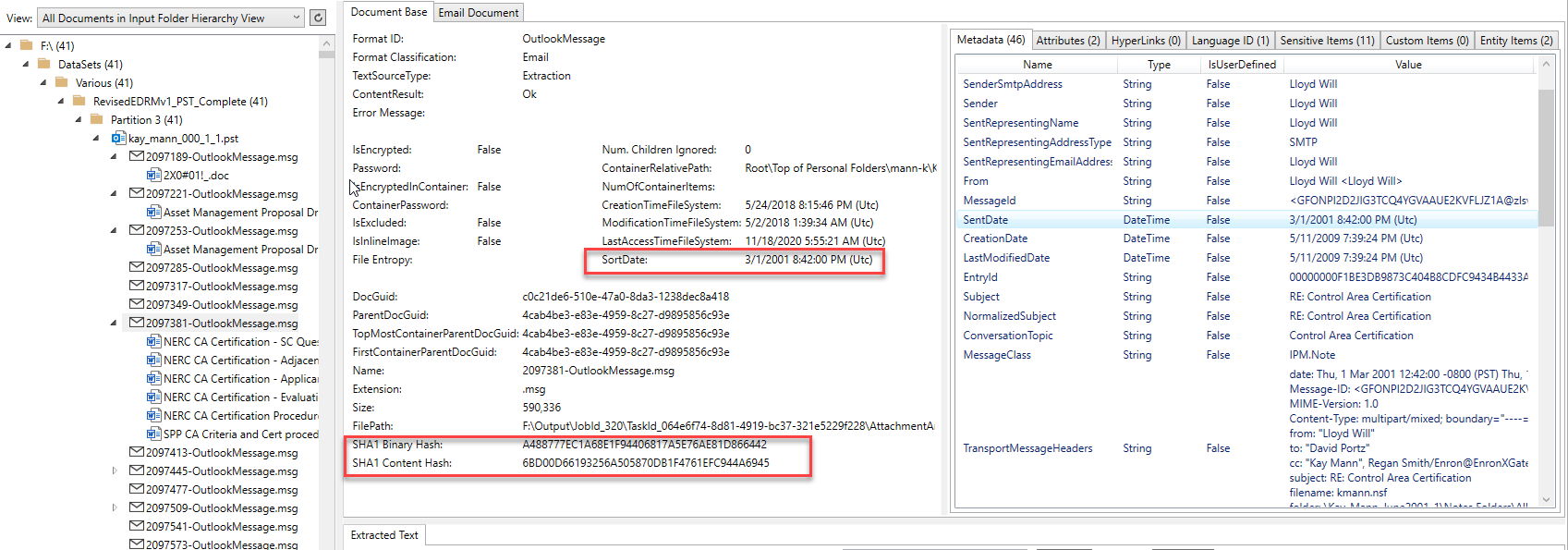
E -Mail spezifische Inhalte wie alle Empfänger und zusätzlichen Hashes:
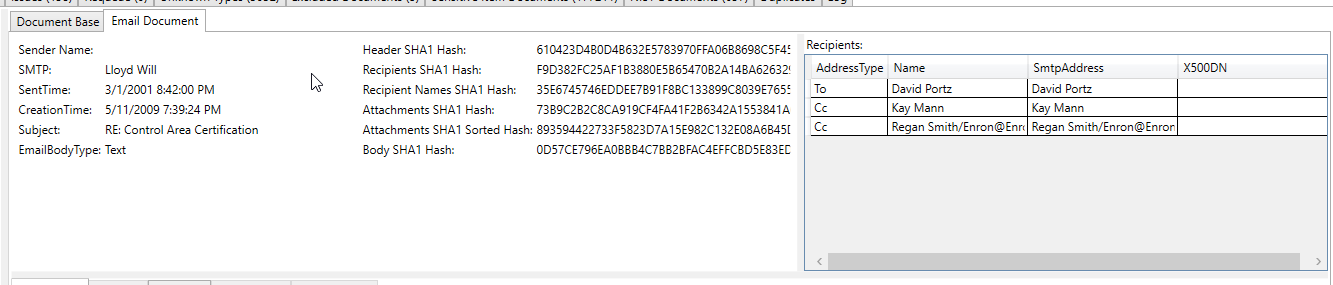
Dieser verarbeitete E -Mail -Screenshot zeigt eine Bankkontonummer, die im extrahierten Text der E -Mail als "sensibler Element" extrahiert/identifiziert wurde (alle extrahierten Text und alle Metadaten werden nach sensiblen Elementen gescannt):
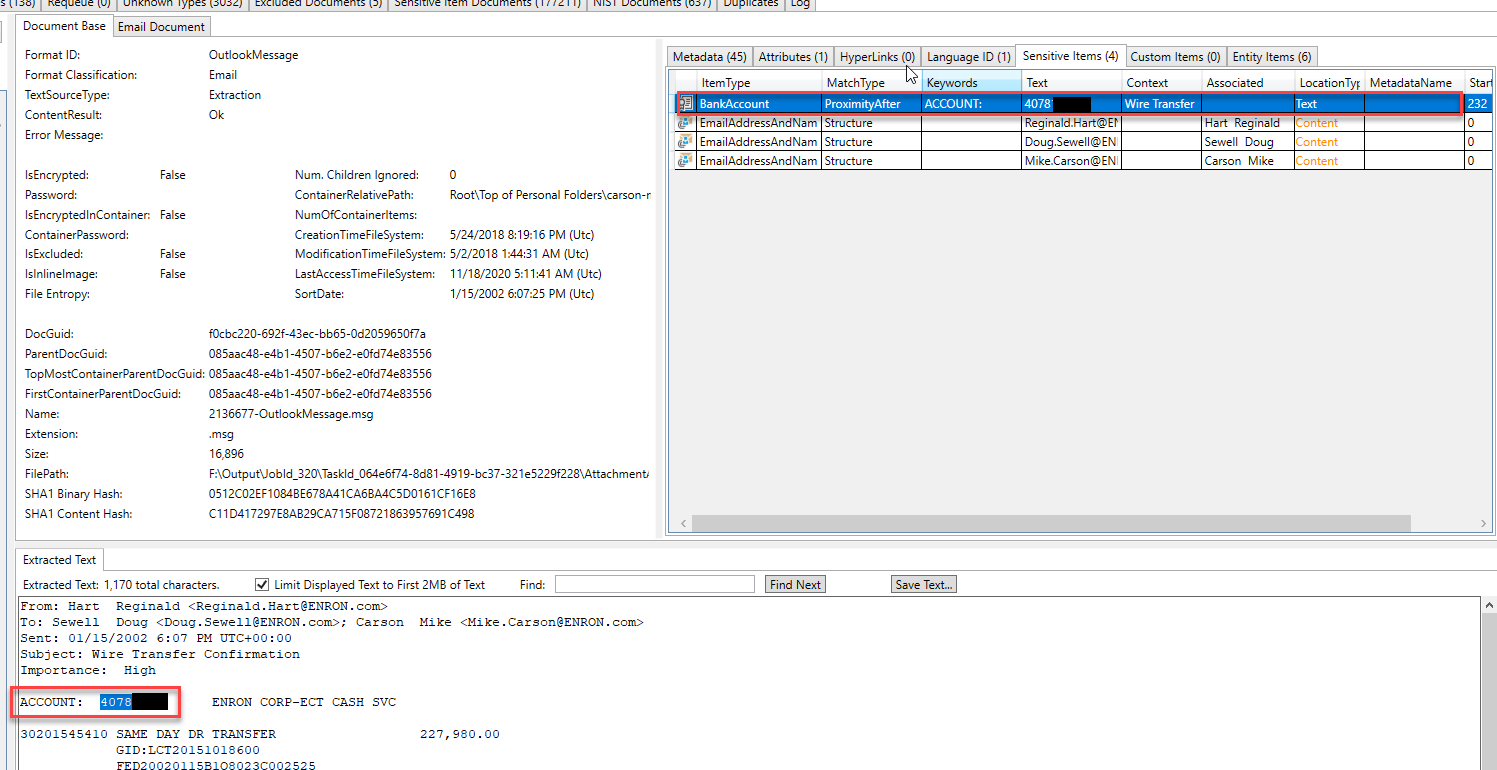
Einige "Entitäten" identifizierten und extrahierten in einer anderen E -Mail. Durch die Überprüfung der in dieser E -Mail gefundenen Unternehmen können wir vermuten, dass die E -Mail eine rechtliche Angelegenheit erörtert:
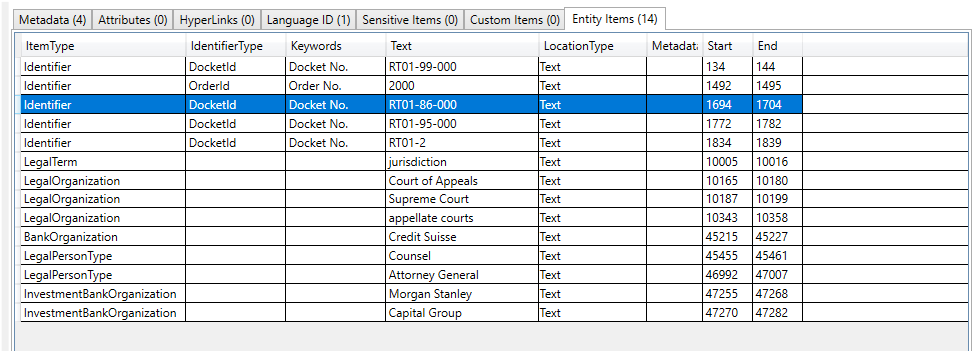
Der Screenshot unten zeigt die Enron -Datenbank in Ravendb Studio, die mit der verarbeiteten Plattform -API -Ausgabe besiedelt ist. Nur einige der in Ravendb gespeicherten Datenbankdokumentfelder könnten in den Screenshot passen, es gibt noch viele weitere Felder. Die Spaltennamen mit einer Annotation mit rotem Rand sind Sammlungen von Objekten:
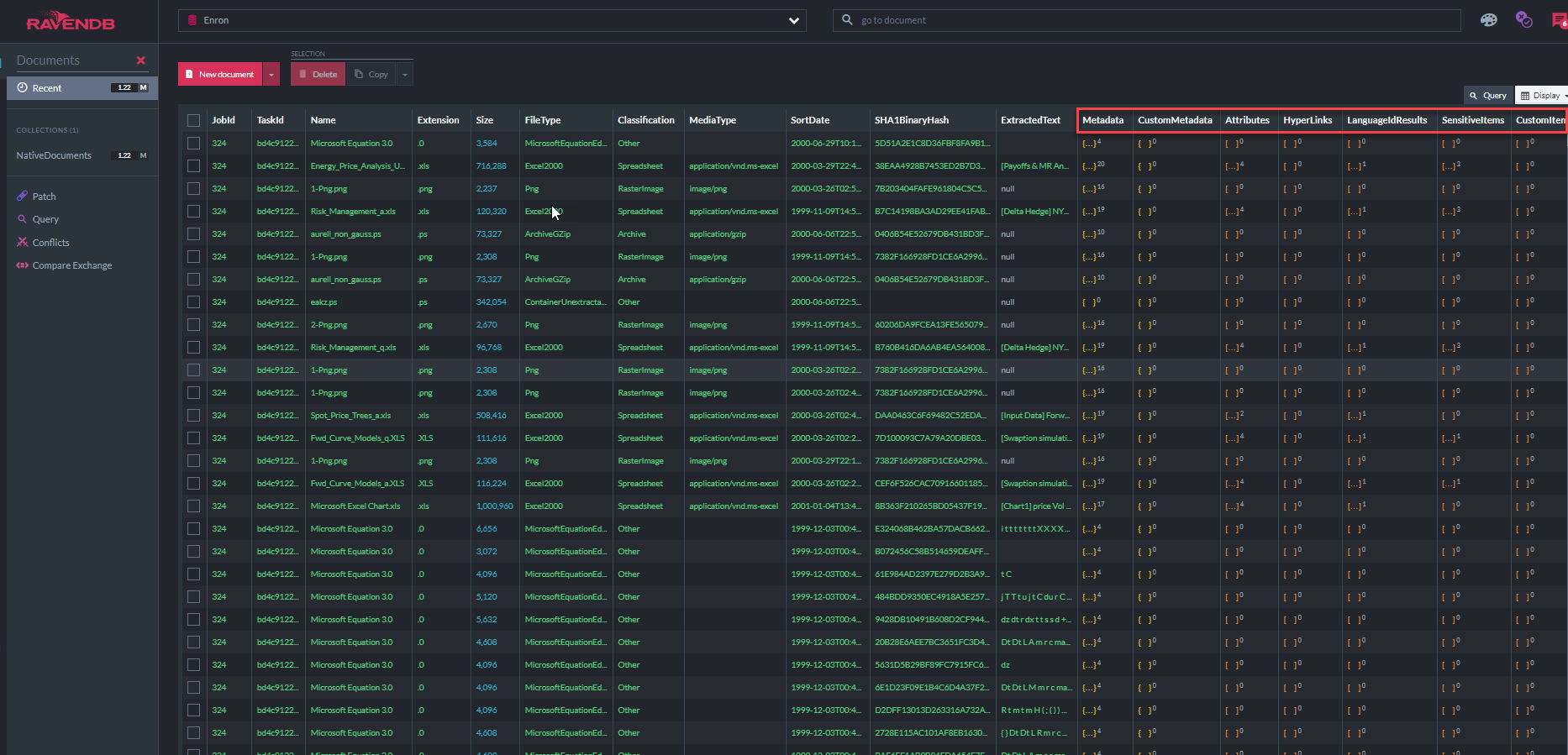
Der Screenshot unten zeigt einige der 31 Ravendb -Indizes, mit denen die "ECA -Demo -App" den Dokumentenstore abfragt (beachten Sie, dass die "metadatapropertyIndex" zeigt, dass in dieser Datenbank 37,7 Millionen Metadaten -Eigenschaften gespeichert sind.
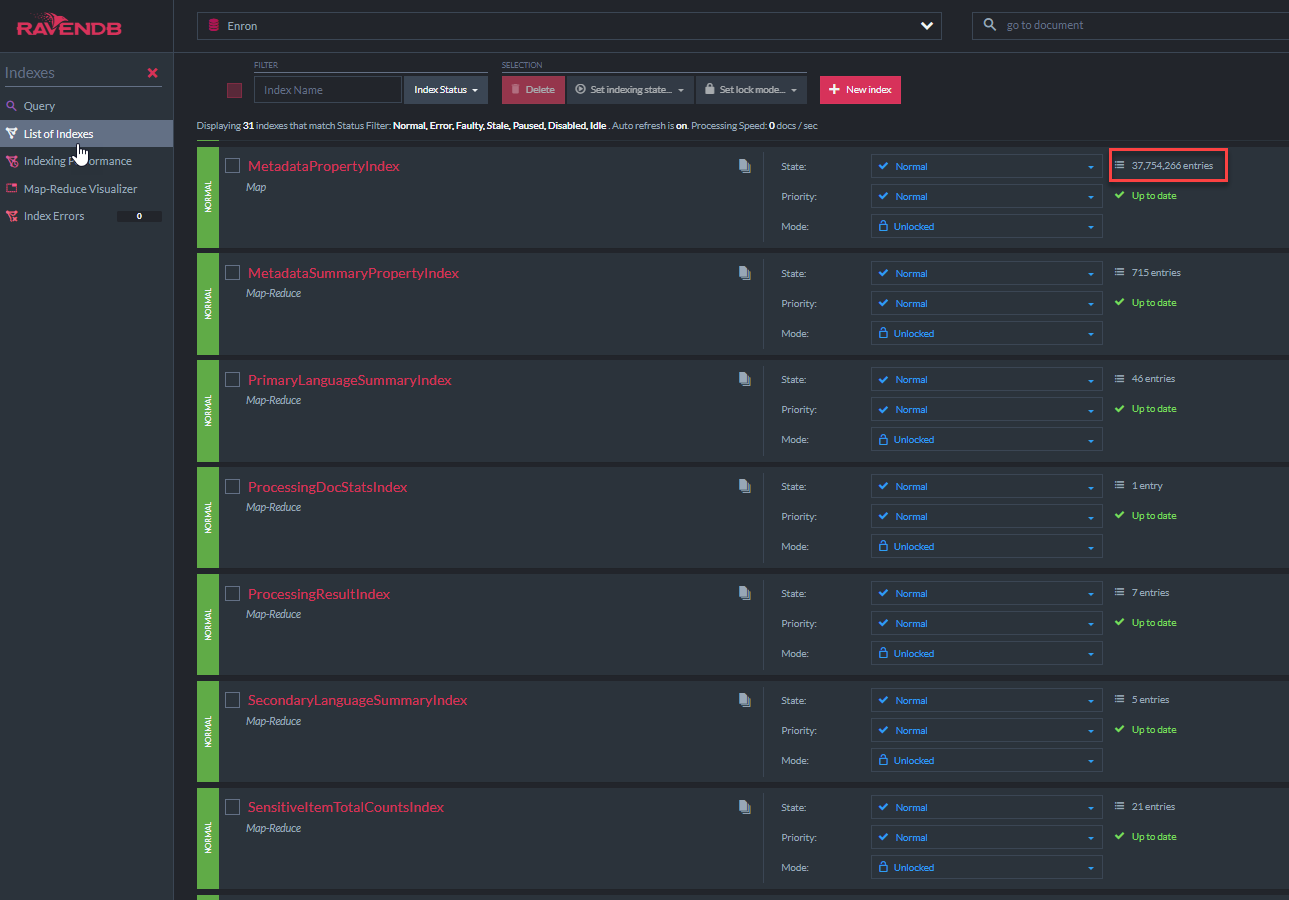
Der C -# -Code "metadatapropertyIndex" C# wird unten angezeigt. Diese Indexklasse stammt aus Ravendbs AbstractIndexcreationTask (ebenso wie alle anderen Indizes in dieser Demo). Dieser Index ermöglicht Lucene, wie Abfragen auf allen Metadatenfeldern. Ein ähnlicher Index für nativedocument.Custommetadata existiert:
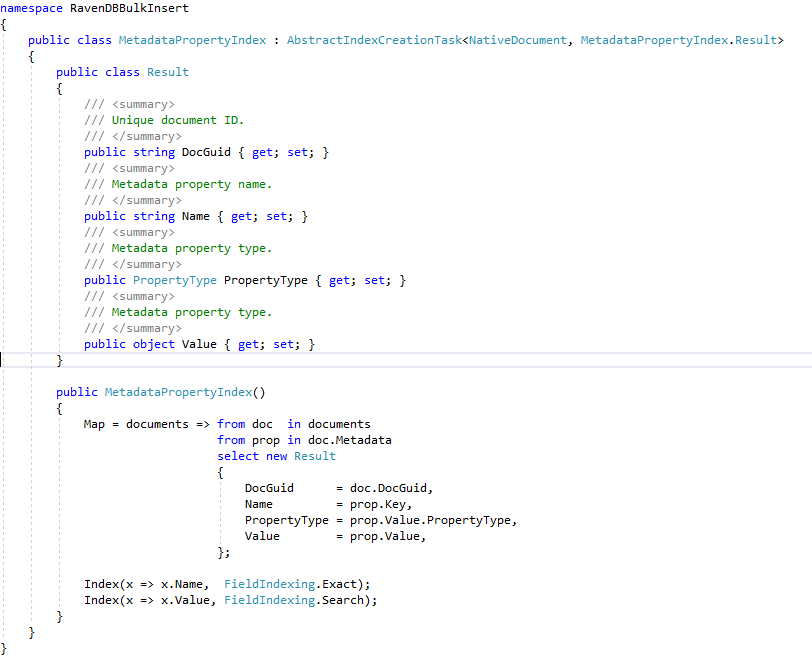
Alle C# definierten Ravendb -Indizes werden in der Ravendb Enron -Datenbank aus der "ECA Demo App" über einen einfachen Ravendb -API -Anruf erstellt:
Der folgende Screenshot zeigt die Verarbeitungsübersichtsstatistik des 189 Microsoft Outlook PST Enron -Datensatzes (1.221.542 E -Mails und Anhänge, die insgesamt verarbeitet wurden). Die meisten E -Mails und Anhänge in diesem Datensatz sind doppelte Dokumente, da die Enron -Mitarbeiter, deren Daten während der legalen Entdeckungsphase gesammelt wurden, sich gegenseitig hin und her verschickten - die in Bild unten gezeigten Deduplizierungsstatistiken basieren auf der Binär-/Inhalts -Hash, die wir in der Zukunft in der Zukunft aktualisieren, um die legale Industrie vorzuziehen. Beachten Sie das Kreisdiagramm der Dateiformatklassifizierung, die Zusammenfassung des spezifischen Dateiformatkartendiagramms und die Zusammenfassung der Verarbeitungsergebnisse (Aufzählungstyp mit Werten von OK/WrongPassword/DataError/etc).
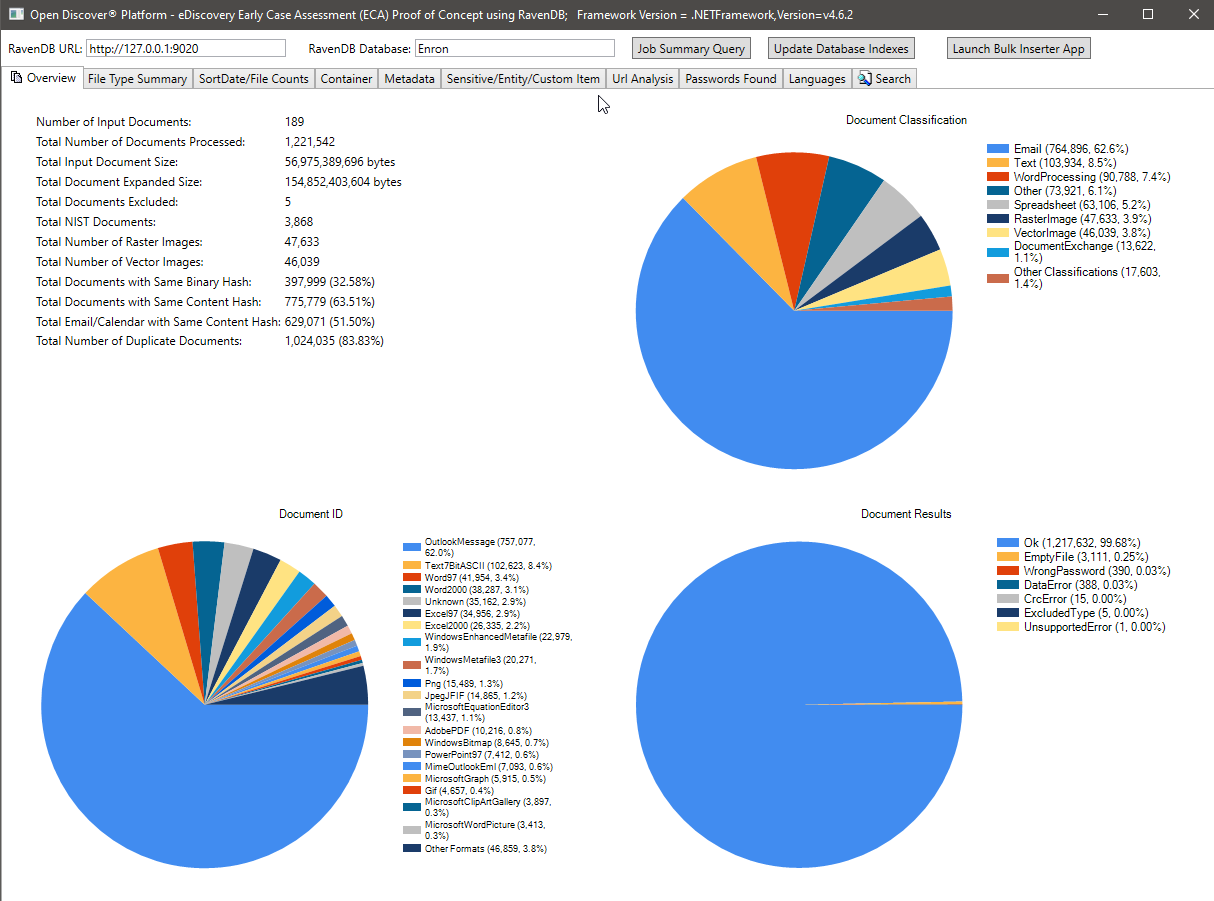
Die Datei zählt nach Sortdate Summary -Diagramme:
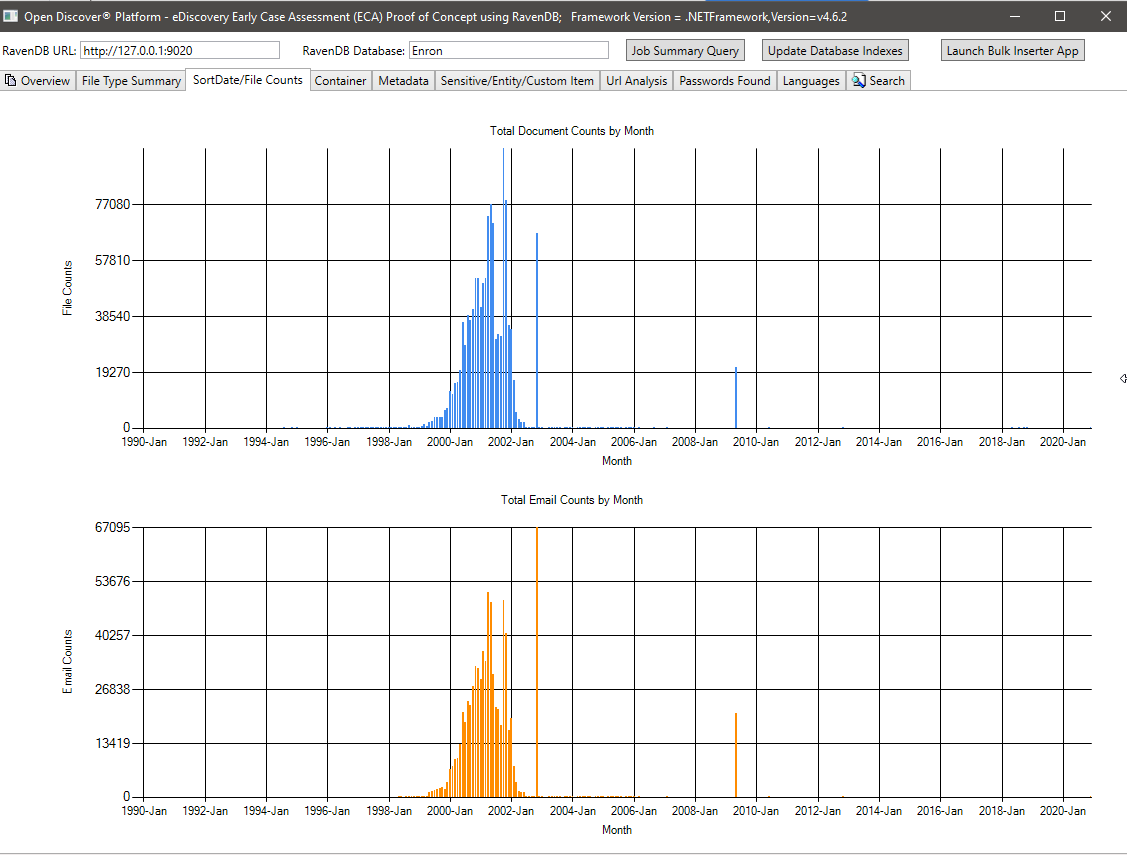
Metadatenübersicht (Feldname/Gesamtzahl der Dokumente Metadaten) - 715 Bekannte eindeutige Metadaten -Feldnamen in allen Dokumenten und 636 benutzerdefinierte (benutzerdefinierte) Metadatenfelder. Diese Abfrage kann dem Rechtsuntersuchungsverwalter helfen, zu wissen, welche Metadatenfelder in der Sammlung verfügbar sind, um zu suchen:
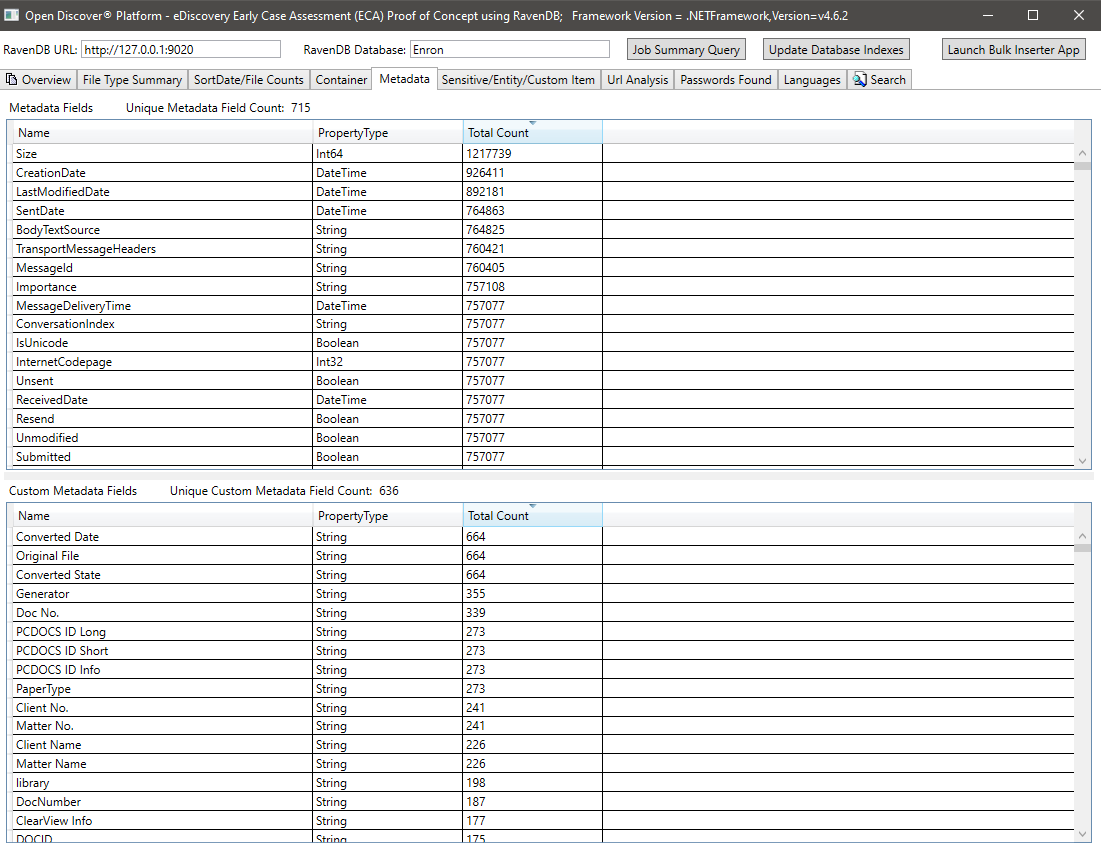
Sensibilis/Entitätselement Zusammenfassung für alle Dokumente:
Zusammenfassung aller einzigartigen URLs in allen Dokumenten (URLs aus jedem Dokument können nützlich sein, wenn ein Unternehmen potenzielle böswillige URL -Einstiegspunkte aufspüren möchte). Open Discover SDK erkennt alle URLs aus Dokumenthyperlinks und im Dokumenttext (dh Nicht-Hyperlink):
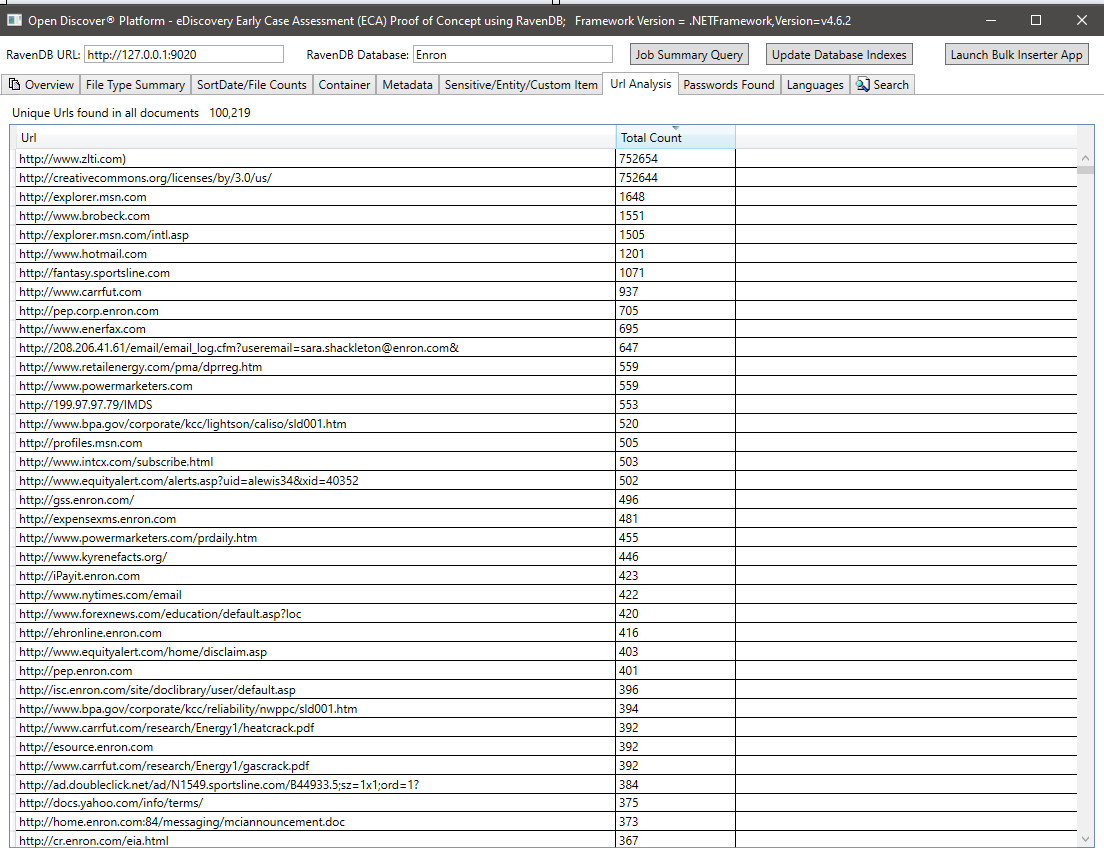
Zusammenfassung aller Passwörter in allen Dokumenten. Passwörter und Benutzernamen sind nur 2 von 25 integrierten 'sensiblen Artikeln', die von der Open Discover SDK/Plattform unterstützt werden. Kennwort-/Benutzername-Anmeldeinformationen in Dokumenten können ein Sicherheitsrisiko sein. Sie können auch verwendet werden, um jedes Dokument neu zu bearbeiten, das ein Verarbeitungsergebnis von "WrongPassword" enthält (wie Mitarbeiter in derselben Firma häufig eine E-Mail mit den Kennwörtern mit freigegebenem verschlüsselten Office-Dokumenten senden):
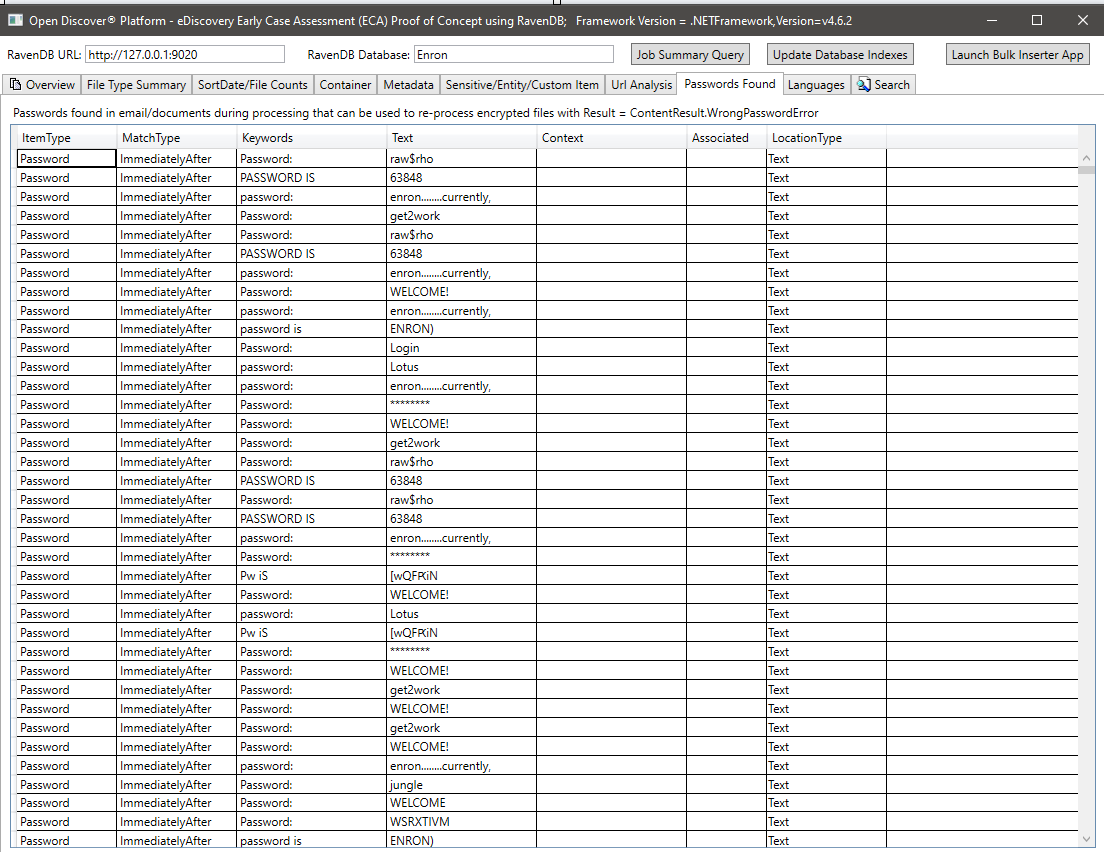
Zusammenfassung der im extrahierten Text der verarbeiteten Dokumente erkannten Sprachen:
Beispiel Volltext-Suchabfrage (Hinweis: Ravendb unterstützt Lucene-Abfragen):
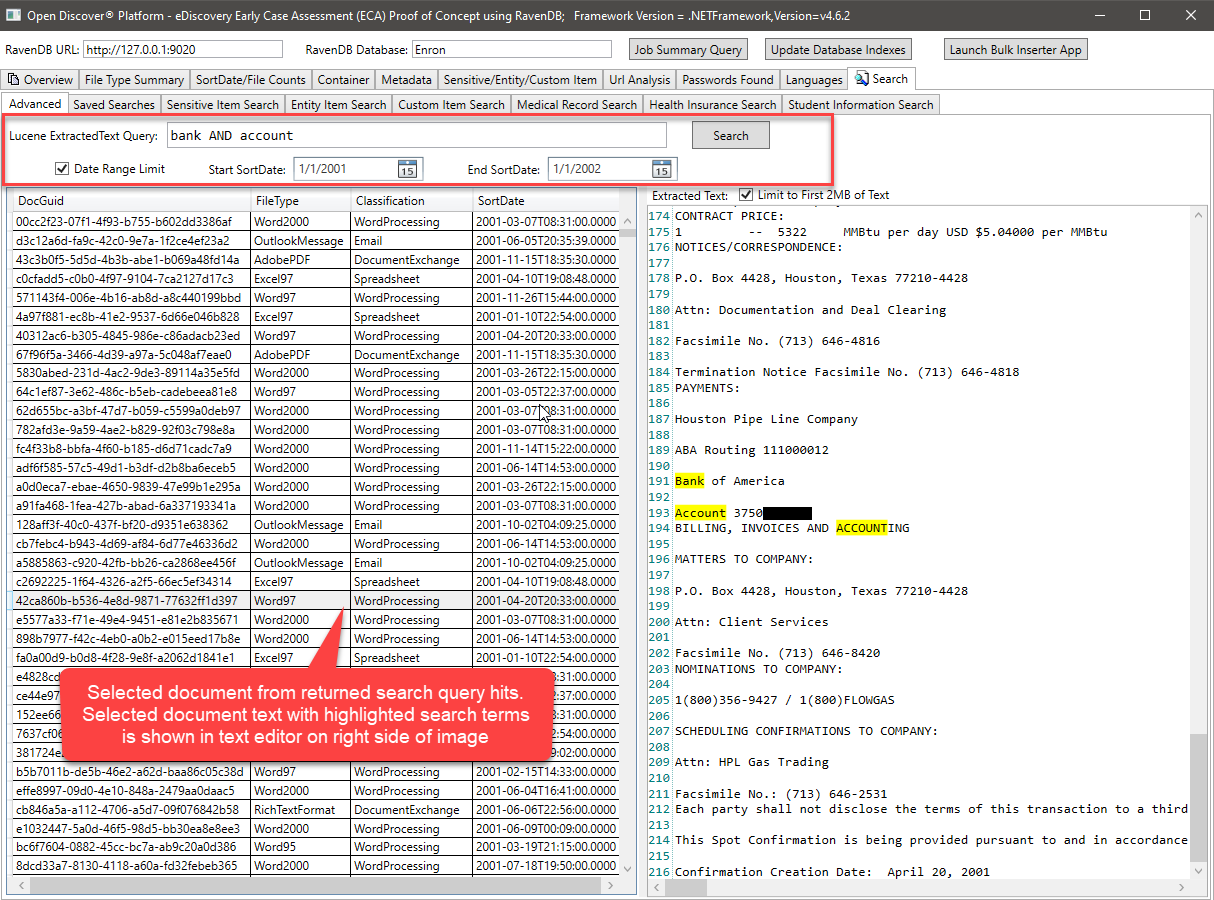
Die obige Lucene -Abfrage, fragt das Feld extrahiert und verwendet (optional) Min/Max -Dokument Sortdate, um die zurückgegebenen Suchergebnisse zu filtern. Es wäre sehr einfach, die Filterung von Ergebnissen nach Dokumentenfiletypen oder Dokumentformatklassifizierung (Wortverarbeitung/Tabelle/E -Mail/usw.) hinzuzufügen. Der C# Code, der die Lucene -Abfrage ausführt, sieht so aus:
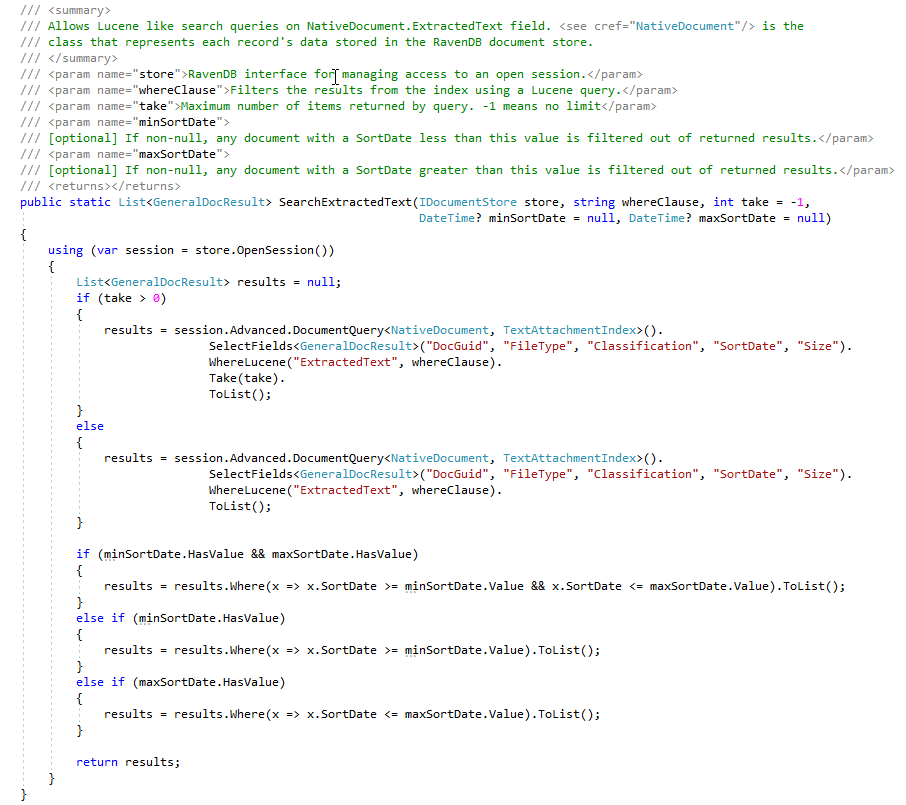
Während der ECA -Phase erstellen Anwälte für rechtliche Überprüfung gerne viele verschiedene Suchanfragen, um antwortende Dokumente zu finden. Der Screenshot unten zeigt einige gespeicherte Lucene -Abfragen und die Ergebnisse (Anzahl der Dokumentenhits und Gesamtgröße der Dokumente). Beachten Sie, dass das Dokument in diesen von Benutzern erstellten Suchvorgängen doppelte Dokumentzählungen enthalten. Obwohl wir Ravendb -Indizes haben, die die Anzahl der doppelten Dokumente zählen, haben wir für diesen Beweis des Konzepts noch nicht "markiert" Dokumente im Dokumentspeicher mit einem Flag, das Master/Duplicate angibt (dies ist ein "Todo" von Benutzer):
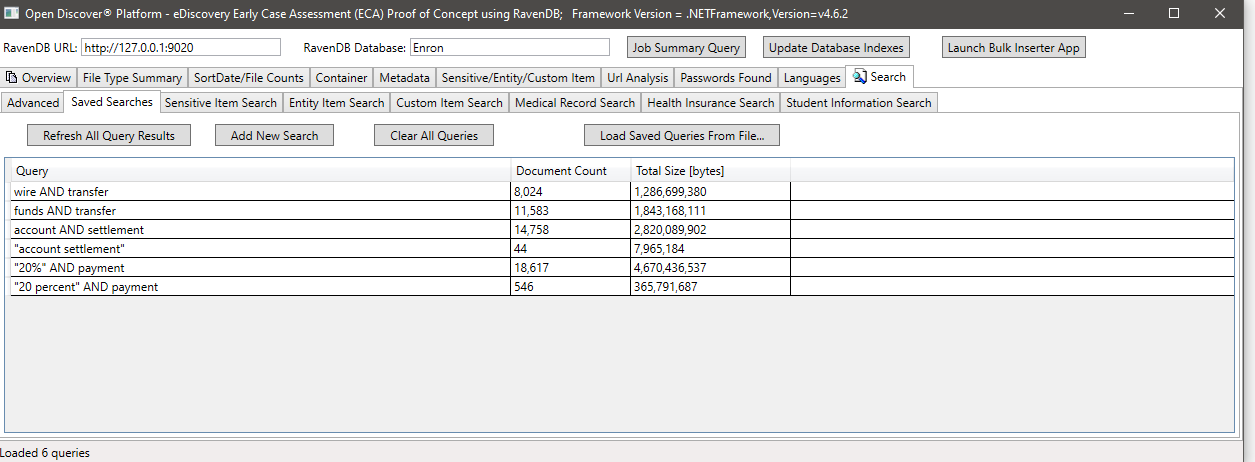
Beispiel Suche nach sensitivenItemtype (eine Eigenschaft auf erkannten sensitiven Objekten, die den Typ des sensiblen Elements identifiziert), suchen wir in diesem Beispiel nach allen Dokumenten, die ein sensitives Element des Typs sensitiveItemTeMtyPe.BankAccount haben:
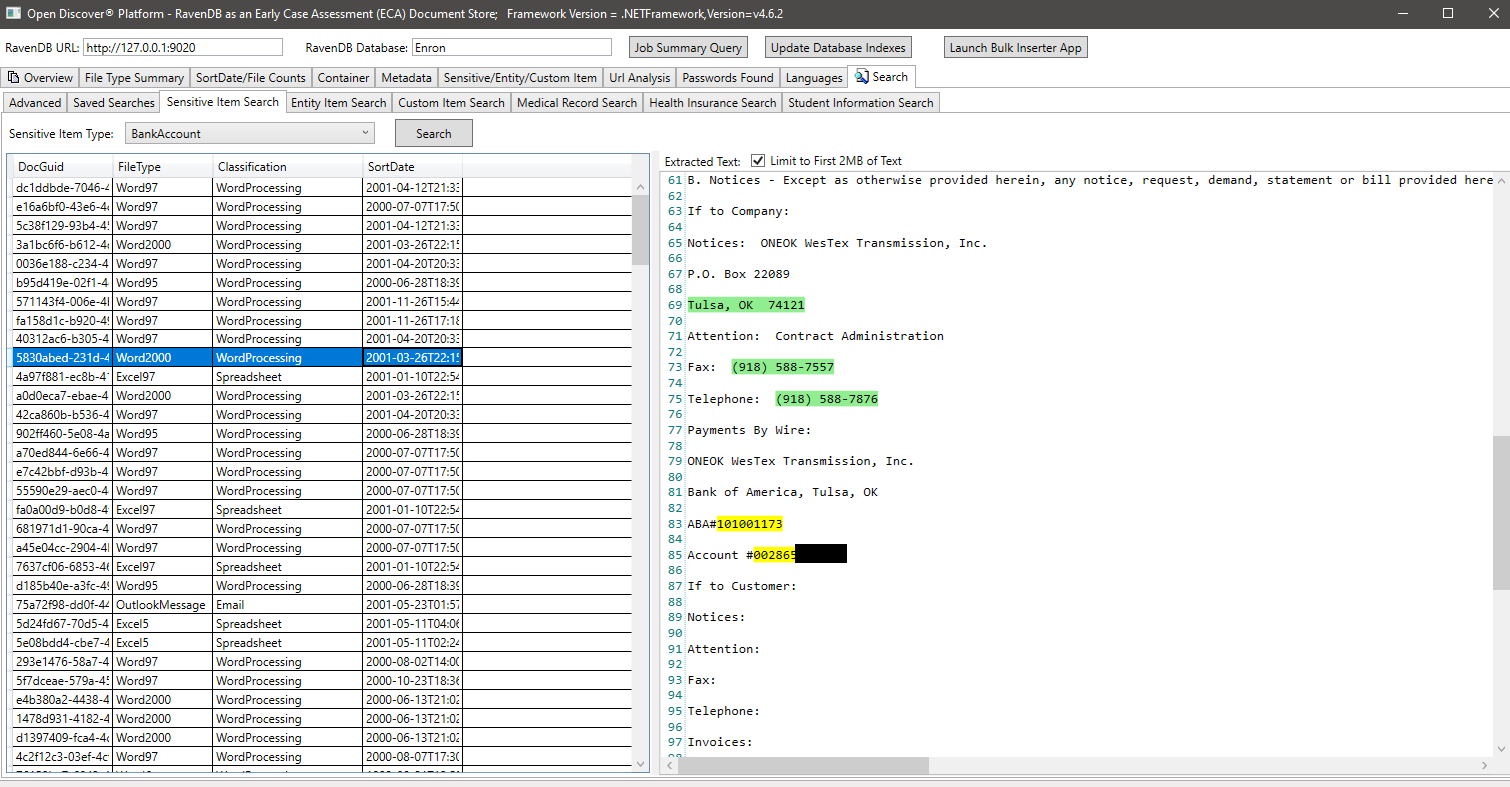
Beispiel Suche nach EntityItemtyPe (eine Eigenschaft auf erkannten EntitätIntem -Objekten, die den Typ des Entitätspunkts identifiziert), suchen wir in diesem Beispiel nach allen Dokumenten, die ein Entitätselement vom Typ EntityItemTyPe.patientnameEntry haben:
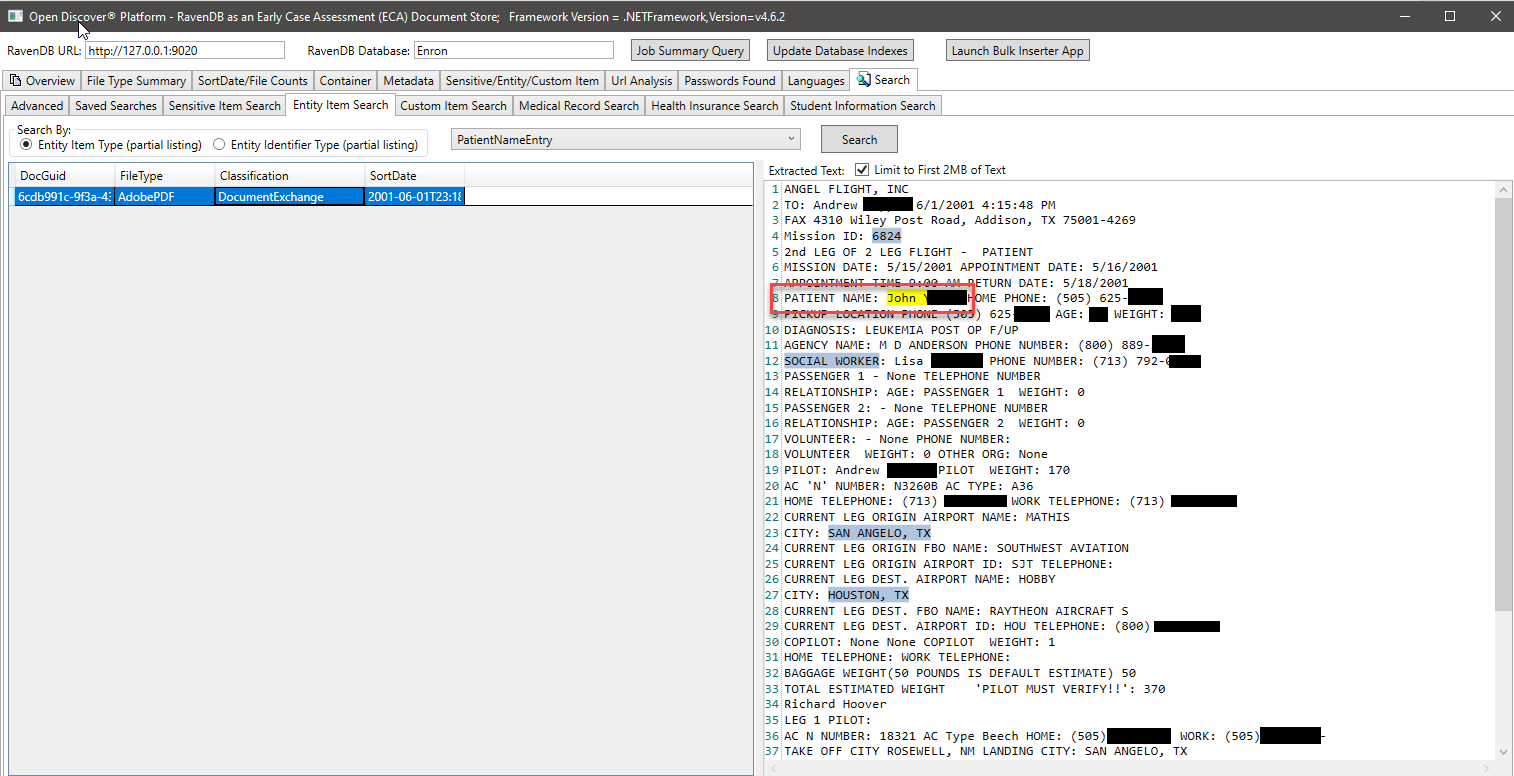
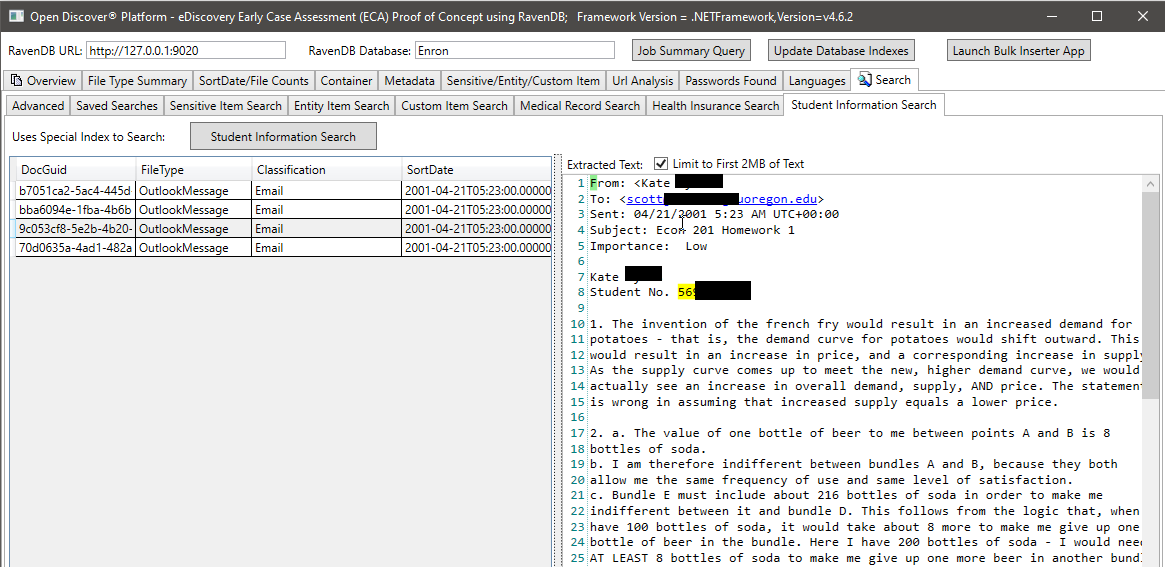
Im folgenden Screenshot verwenden wir einen speziell erstellten Ravendb -Index, in dem bestimmte offene Entitätstypen für Open Discover SDK extrahierte, die sich auf Schülerinformationen beziehen, um Dokumente zu finden, die möglicherweise über Schülerinformationen verfügen (im Screenshot, der Name und die Schüler -ID des Schülers werden ausgestrahlt. Ebenso haben wir andere spezielle Indizes, um nach medizinischen Unterlagen und Patienteninformationen zu suchen:
In einer Dokumentdatenbank wie Ravendb gespeicherte Plattformplattform kann zu sehr leistungsstarken und schnell entwickelten Anwendungen für die frühe Fallbewertung (ECA) führen. Darüber hinaus können Anwendungen wie Folgendes schnell entwickelt werden:
Wenn diese Fallstudie eine relationale Datenbank anstelle einer Dokumentendatenbank wie Ravendb verwendet hätte, hätte sie Monate nach dem Datenbankschema -Design- und -speicher -Verfahrensentwicklung und nicht der zwei Wochen, in der der Autor gebraucht wurde, um diesen ECA -Proof of Concept (Early Case Assessment) zu entwickeln.


