OpenDiscoverPlatformCaseStudy
1.0.0
.NET 예제 GitHub 리포지토리는 Open Discover® SDK를 참조하십시오
Open Discover Platform API의 단일 인스턴스는 일반적으로 문서 세트를 40-70GB/시간 요금으로 처리 할 수 있습니다 (* 요금은 데이터 세트의 사용자 하드웨어 및 파일 유형에 따라 다름). 대부분의 edscovery 소프트웨어보다 더 많은 컨텐츠를 추출하면서 문서를 처리하는 데 매우 빠릅니다 (예 : 처리하는 동안 민감한 항목/엔티티 감지 및 De-Nist-ing). Open Discover Platform API Demo 응용 프로그램 인 Platformapidemo.exe는 Enron Outlook PST 데이터 세트를 처리하는 데 사용되었습니다. PlatformApidemo.exe 데모 애플리케이션은 플랫폼 API 문서 처리 클래스의 한 인스턴스를 랩합니다. 예제 PlatformApidemo.exe 처리 출력의 스크린 샷은 아래의 다음 섹션에 나와 있습니다.
Platformapidemo.exe는 Open Discover Platform 평가와 함께 다음과 같이 배포됩니다.
최근 성능 테스트에서 Open Discover SDK는 53GB Enron Microsoft Outlook PST 데이터 세트를 처리했으며 Bulk는 단일 4 코어 Wind
**이 사례 연구 처리 속도는 .NET 4.62 버전의 SDK에 대한 것이었고, 새로운 .NET 6 버전은 평균적으로> 100% 더 빠르며, .NET 6 버전의 모든 PST 처리 작업은 OpEndscoverPlatform 프로세스의 PST 데이터 세트 작업을 90-100+GB/HR 속도 (입력 크기를 기준으로)의 PST 데이터 세트 작업 (Process rate)을 사용하여 (Processing Rate)를 사용했습니다. 인텔 i7 CPU 및 16GB RAM).
아래 스크린 샷은 Outlook PST 컨테이너에서 추출하고 PlatformApidemo.exe 응용 프로그램에서 처리 한 이메일 항목 (및 첨부 파일)을 보여줍니다. 이메일은 Enron Microsoft Outlook PST 중 하나입니다. 이미지의 왼쪽에있는 트리 뷰 컨트롤은 처리 된 모든 문서/컨테이너의 부모/자식 계층을 보여 주며 트리 컨트롤의 항목을 클릭하면 추출 된 내용이 표시됩니다. 트리 뷰에서 선택한 Outlook 이메일 항목의 경우 이메일에서 추출한 첨부 파일로 6ms 사무실 Word 문서가 있음을 알 수 있습니다. 각각의 모든 첨부/임베디드 품목도 콘텐츠를 추출했습니다 (아무리 복잡하더라도 부모 아동 계층 구조를 완전히 처리합니다). 파일 형식 식별 결과, "SortDate", 다양한 문서 해시, 추출 된 메타 데이터 및 기타 추출 된 컨텐츠를 포함하는 이미지의 오른쪽 상단에있는 기타 탭 항목에 유의하십시오.
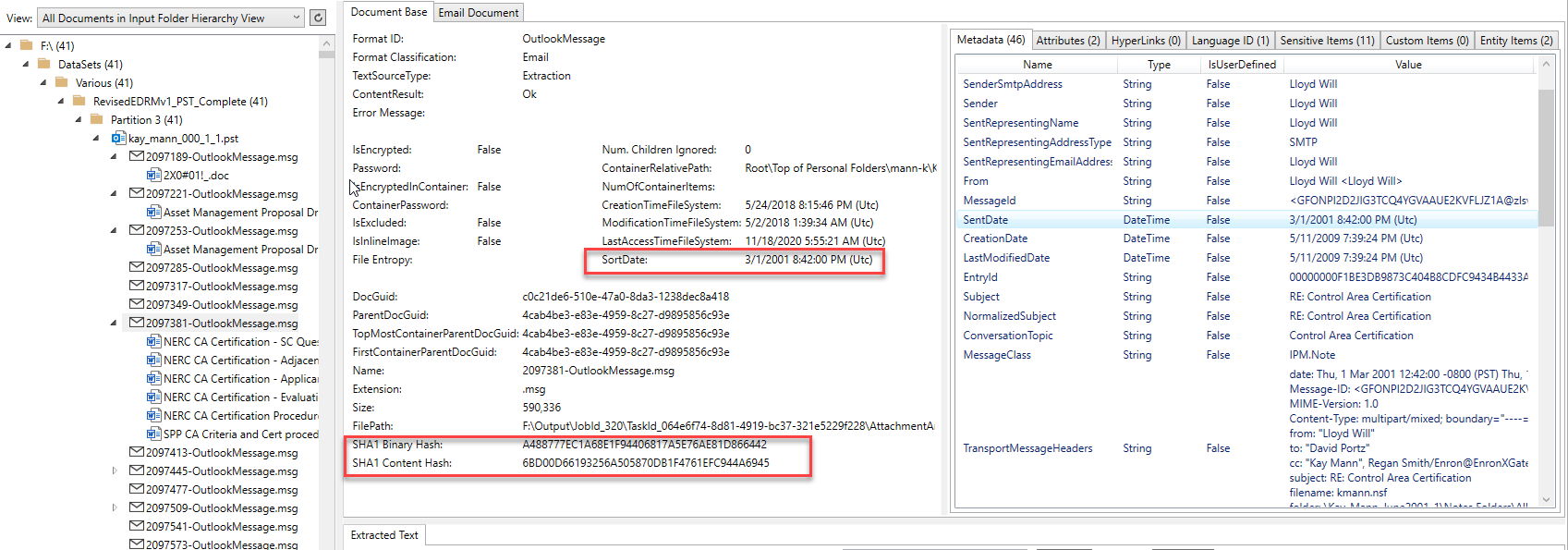
모든 수신자 및 추가 해시와 같은 특정 콘텐츠 이메일 :
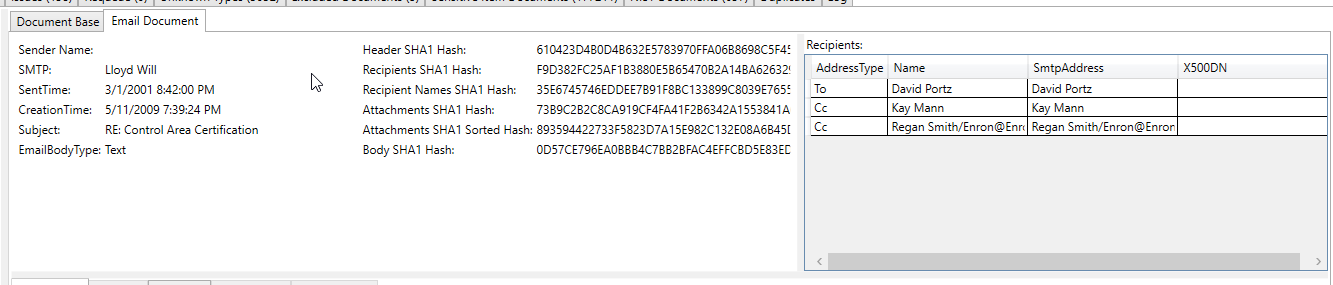
이 처리 된 이메일 스크린 샷은 이메일의 추출 된 텍스트에서 추출/"민감한 항목"으로 추출/식별 된 은행 계좌 번호를 보여줍니다 (모든 추출 된 텍스트 및 모든 메타 데이터는 민감한 항목에 대해 스캔됩니다).
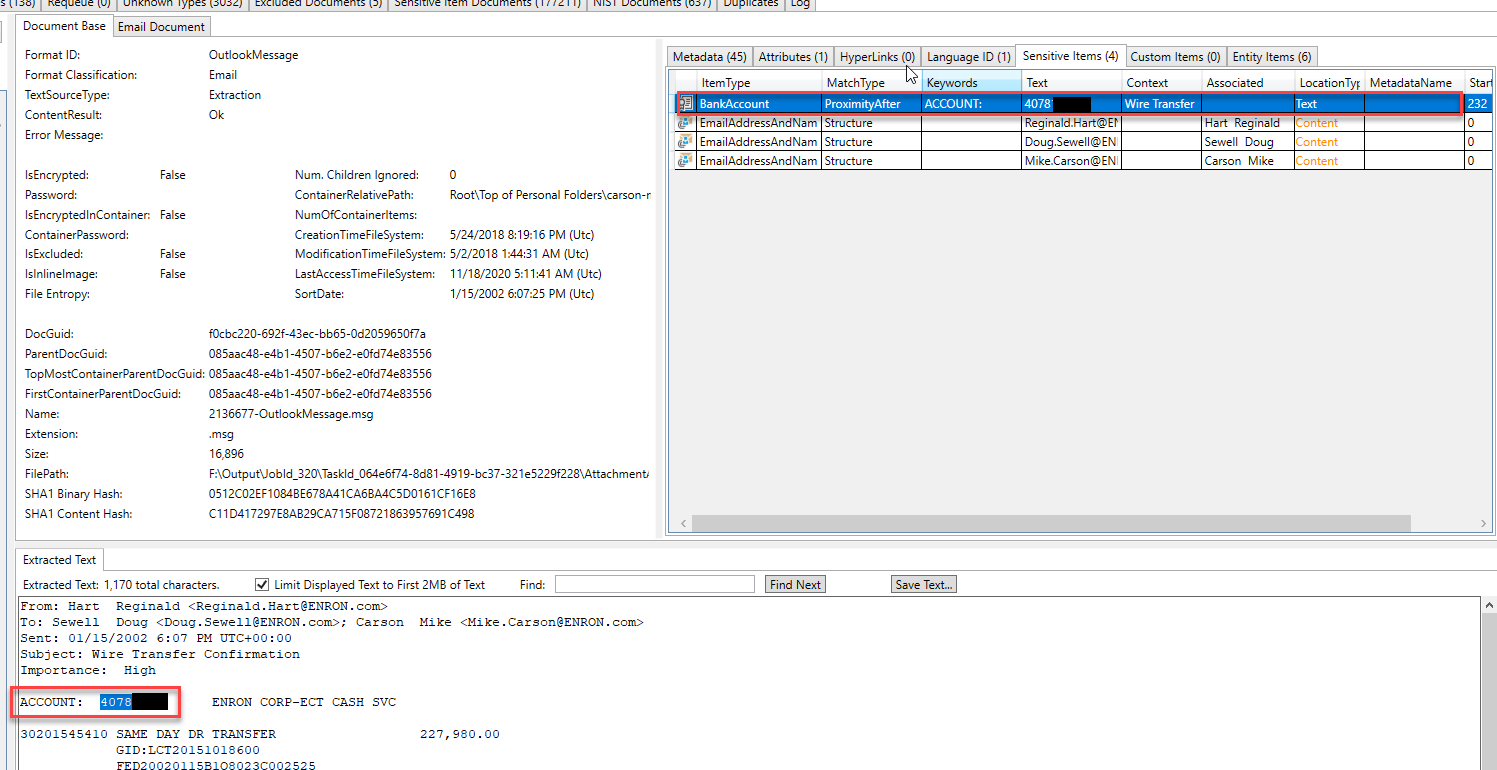
일부 "엔티티"는 다른 이메일로 식별 및 추출되었습니다. 이 이메일에서 발견 된 엔티티 유형을 검사함으로써 이메일이 법적 문제에 대해 논의하고 있음을 추측 할 수 있습니다.
아래의 스크린 샷은 Ravendb Studio의 Enron 데이터베이스가 플랫폼 API 처리 된 출력으로 채워진 것을 보여줍니다. RavEndB에 저장된 일부 데이터베이스 문서 필드 만 스크린 샷에 적합 할 수 있으며 더 많은 필드가 있습니다. 빨간색 테두리 주석이있는 열 이름은 객체 모음입니다.
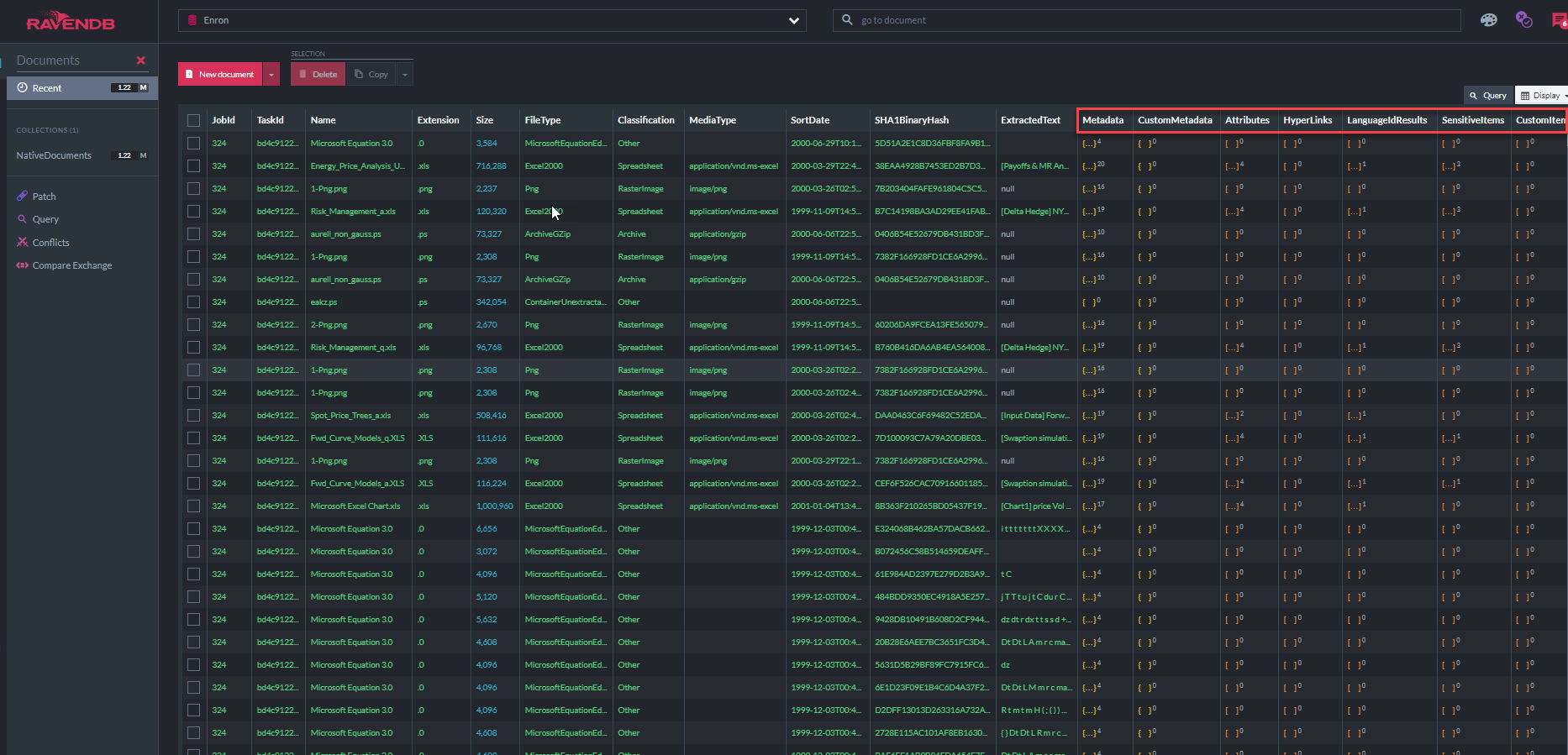
아래의 스크린 샷은 "ECA 데모 앱"이 문서 저장소를 쿼리하는 데 사용하는 31 개의 RavendB 인덱스 중 일부를 보여줍니다 ( "MetadatapropertyIndex"는이 데이터베이스, 대부분 이메일 메타 데이터에 저장된 3,770 만 메타 데이터 속성이 추출 된 모든 텍스트에 추가되어 있음을 보여줍니다.
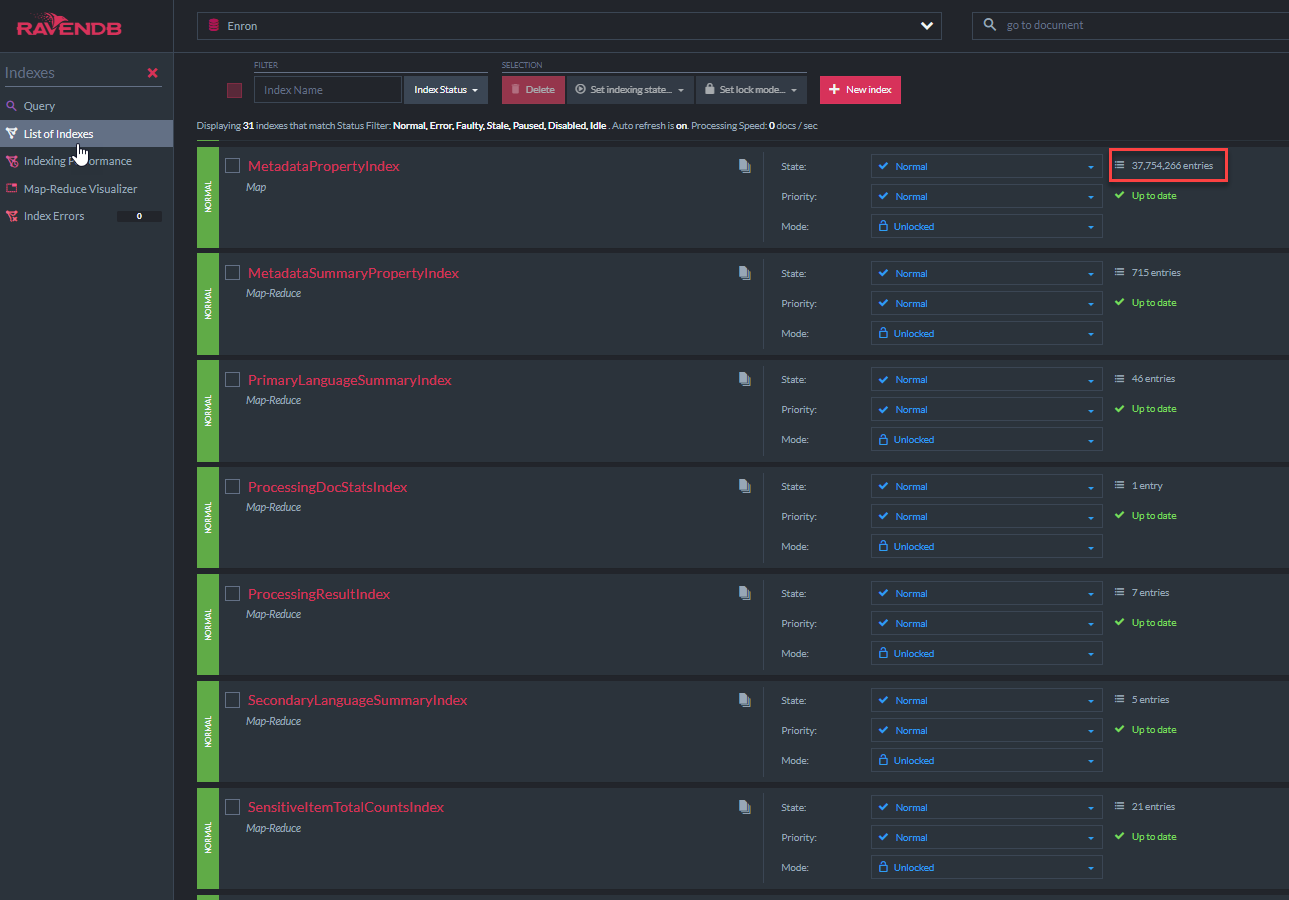
"MetadatapropertyIndex"C# 클래스 코드는 아래에 표시됩니다. 이 색인 클래스는 Ravendb의 AbstractIndexCreationTask에서 파생됩니다 (이 데모의 다른 모든 인덱스와 마찬가지로). 이 색인은 모든 메타 데이터 필드에서 Lucene 'Like'쿼리를 허용합니다. Nativedocument.custommetAdata에 대한 유사한 색인이 있습니다.
모든 C# 정의 된 RavendB 인덱스는 간단한 RavendB API 호출을 통해 "ECA 데모 앱"에서 RAVENDB ENRON 데이터베이스에서 생성됩니다.
아래의 스크린은 189 Microsoft Outlook PST Enron 데이터 세트 (총 1,221,542 개의 이메일 및 첨부 파일)의 처리 요약 통계를 보여줍니다. 이 데이터 세트의 대부분의 이메일 및 첨부 파일은 법적 발견 단계에서 데이터가 수집 된 Enron 직원이 서로 앞뒤로 이메일을 보내고 있다는 사실 때문에 중복 문서입니다. 아래 이미지에 표시된 중복 제거 통계는 이진/콘텐츠 해시를 기반으로 한 것이 었습니다. 앞으로이 사례 연구 (Ravendb 지수와 함께)는 법적 산업을 포함하여 "Family Preplication"을 포함합니다. 파일 형식 분류 파이 차트, 특정 파일 형식 파이 차트 요약 및 처리 결과 요약 (OK/잘못된 Password/DataError/등의 열거 유형) 파이 차트에 유의하십시오.
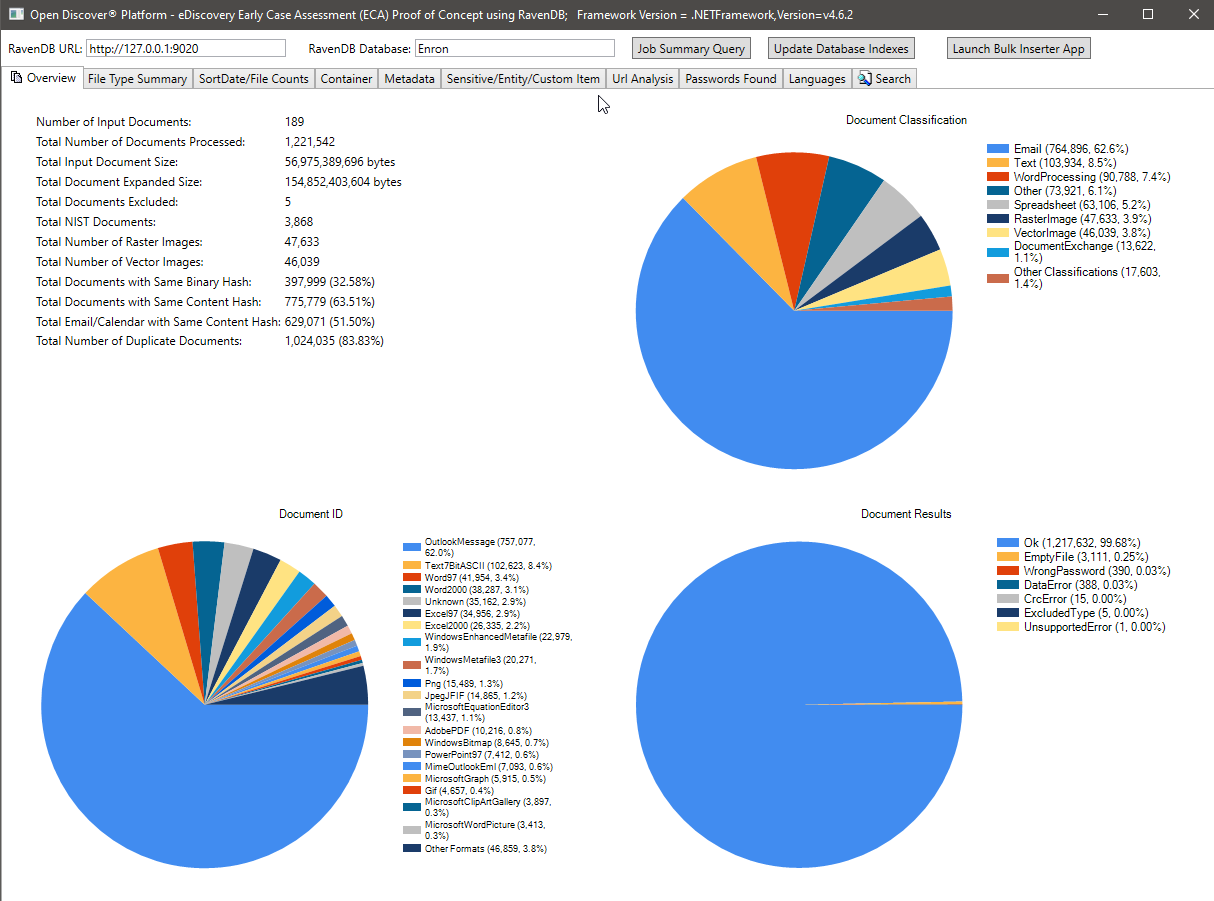
SortDate 요약 차트에 의한 파일 계산 :
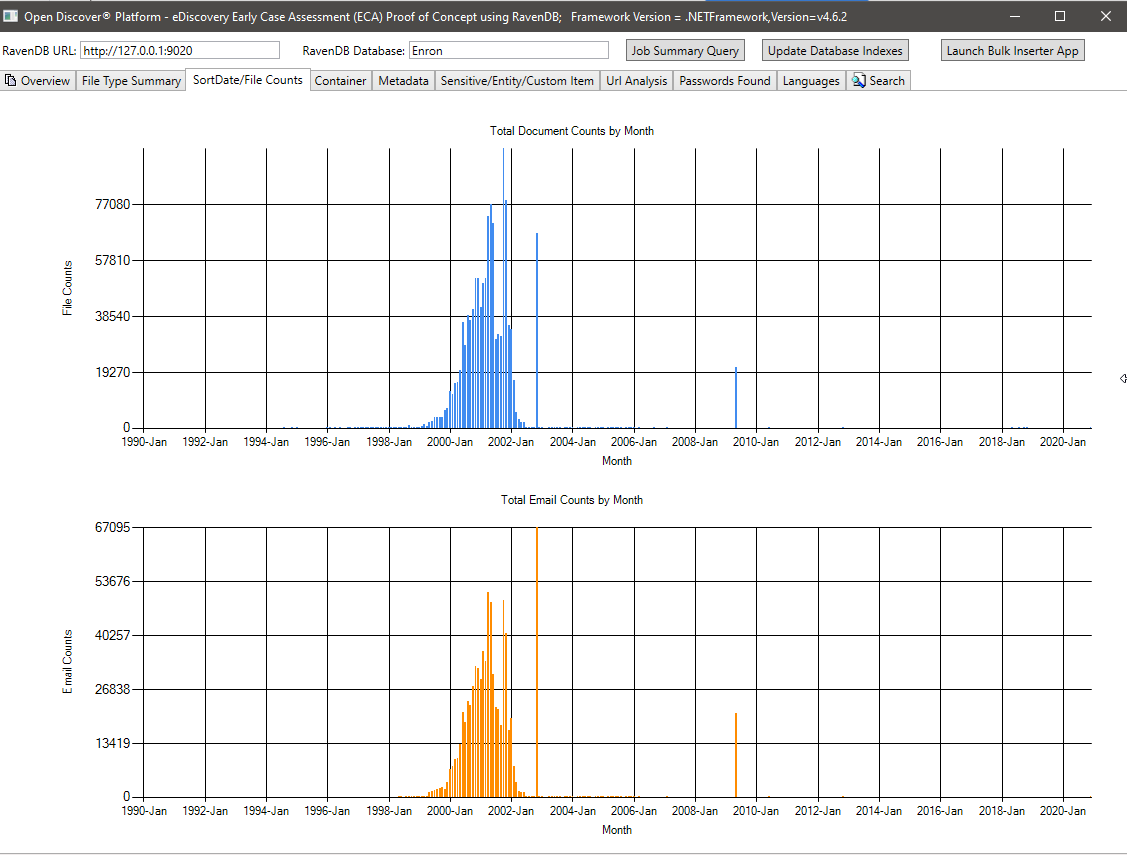
메타 데이터 요약 (메타 데이터 필드 이름/총 문서 번호) -715 모든 문서에서 알려진 고유 한 메타 데이터 필드 이름 및 636 사용자 정의 (사용자 정의) 메타 데이터 필드. 이 쿼리는 법률 사례 관리자가 컬렉션에서 사용할 수있는 메타 데이터 필드를 알 수 있도록 도와줍니다.
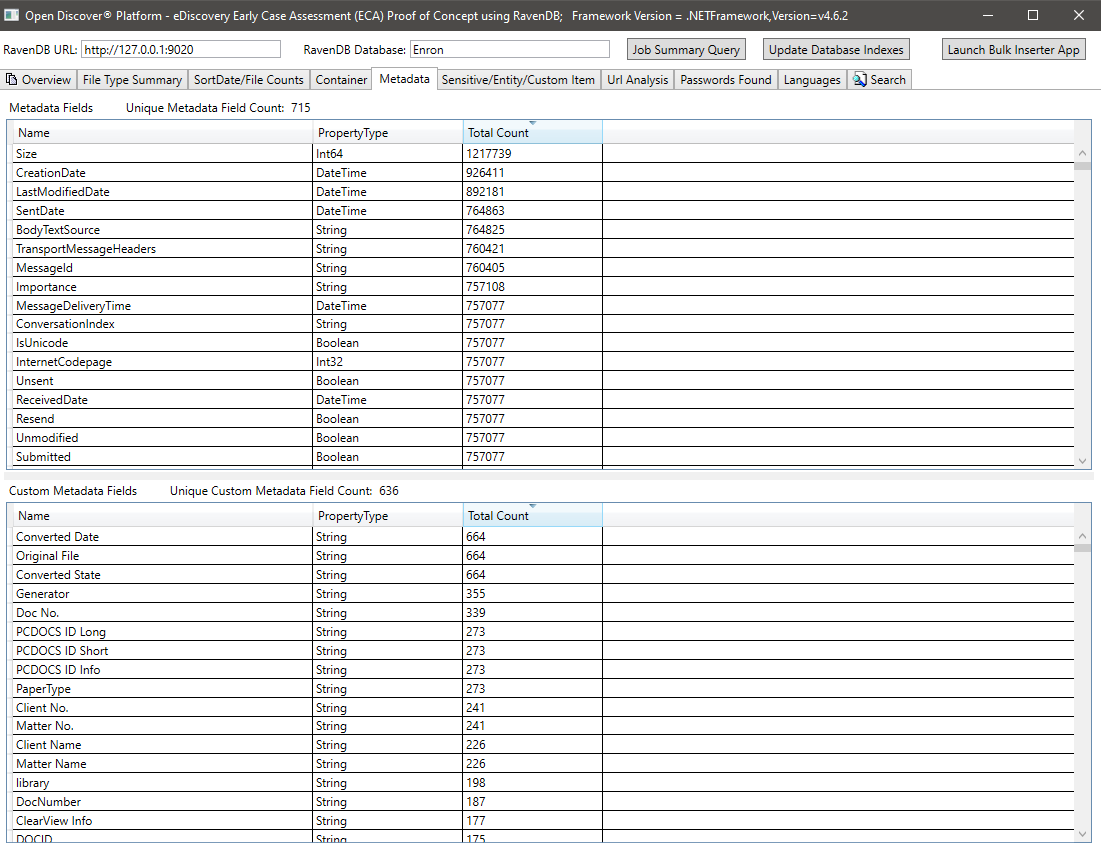
모든 문서에 대한 민감한 항목/엔티티 항목 요약 :
모든 문서에있는 모든 고유 URL의 요약 (예를 들어 회사가 잠재적 인 악성 URL 진입 지점을 추적하려는 경우 모든 문서의 URL이 유용 할 수 있습니다). Open Discover SDK는 문서 하이퍼 링크 및 문서 텍스트 (예 : 비 하이퍼 링크)에서 모든 URL을 감지합니다.
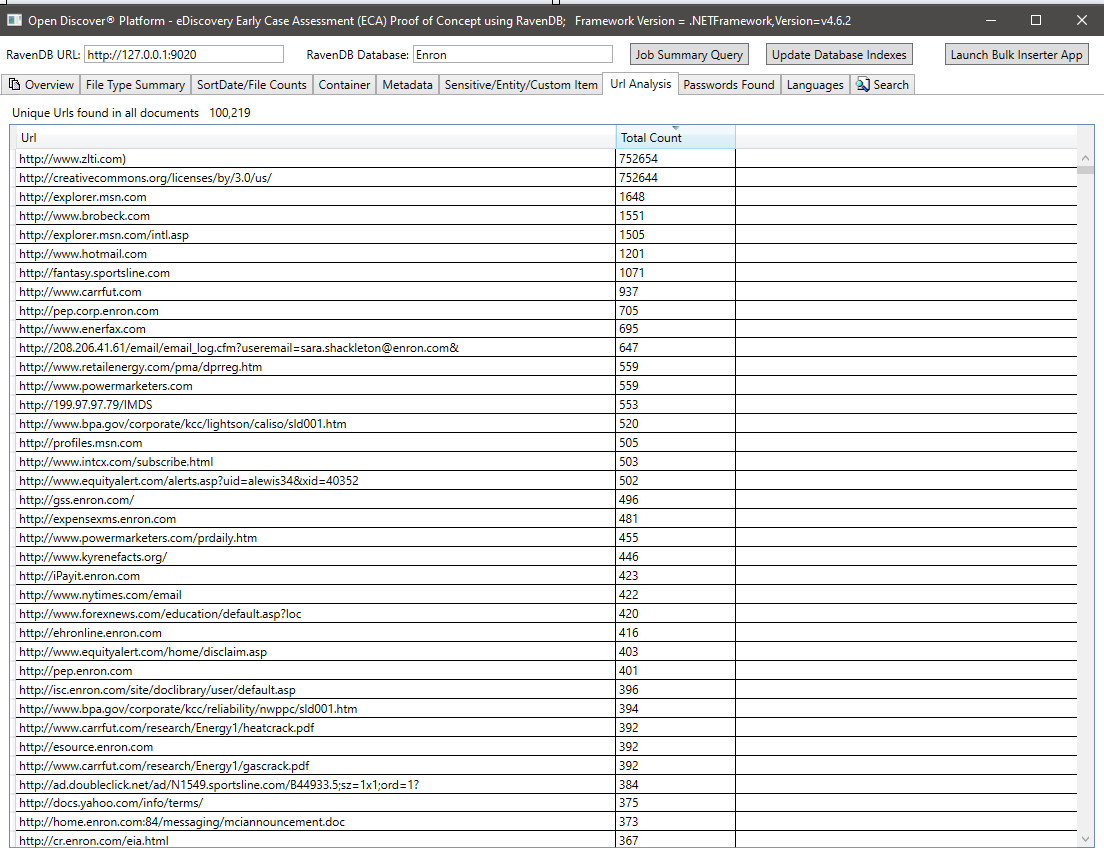
모든 문서에있는 모든 암호 요약. 암호와 사용자 이름은 Open Discover SDK/Platform에서 지원하는 25 개의 내장 '민감한 항목'유형 중 2 개에 불과합니다. 문서의 비밀번호/사용자 이름 자격 증명은 보안 위험이 될 수 있으며, '잘못된 Password'의 처리 결과가있는 모든 문서를 다시 처리하는 데 사용될 수 있습니다 (동일한 회사의 직원이 종종 암호화 된 사무실 문서에 비밀번호를 보내는 경우가 종종 있습니다).
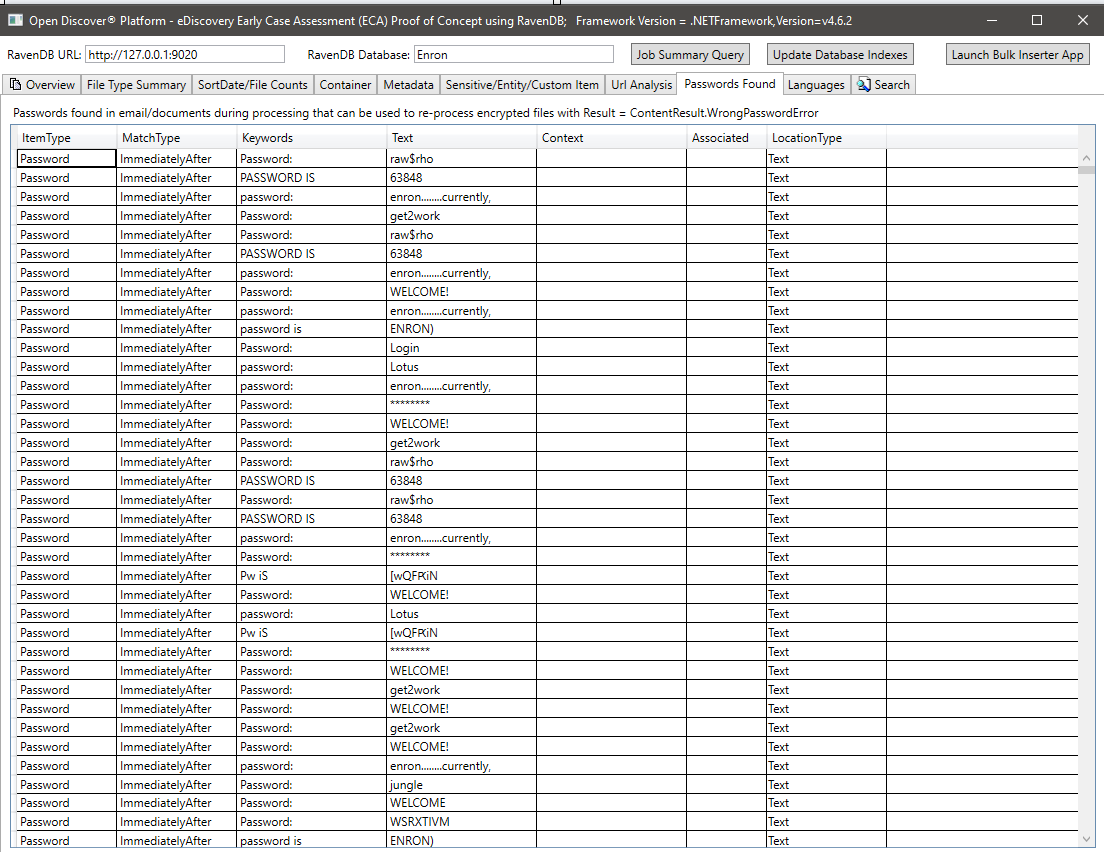
처리 된 문서의 추출 된 텍스트에서 감지 된 언어 요약 :
전체 텍스트 검색 쿼리 예제 (참고 : RavendB는 Lucene 쿼리 지원) :
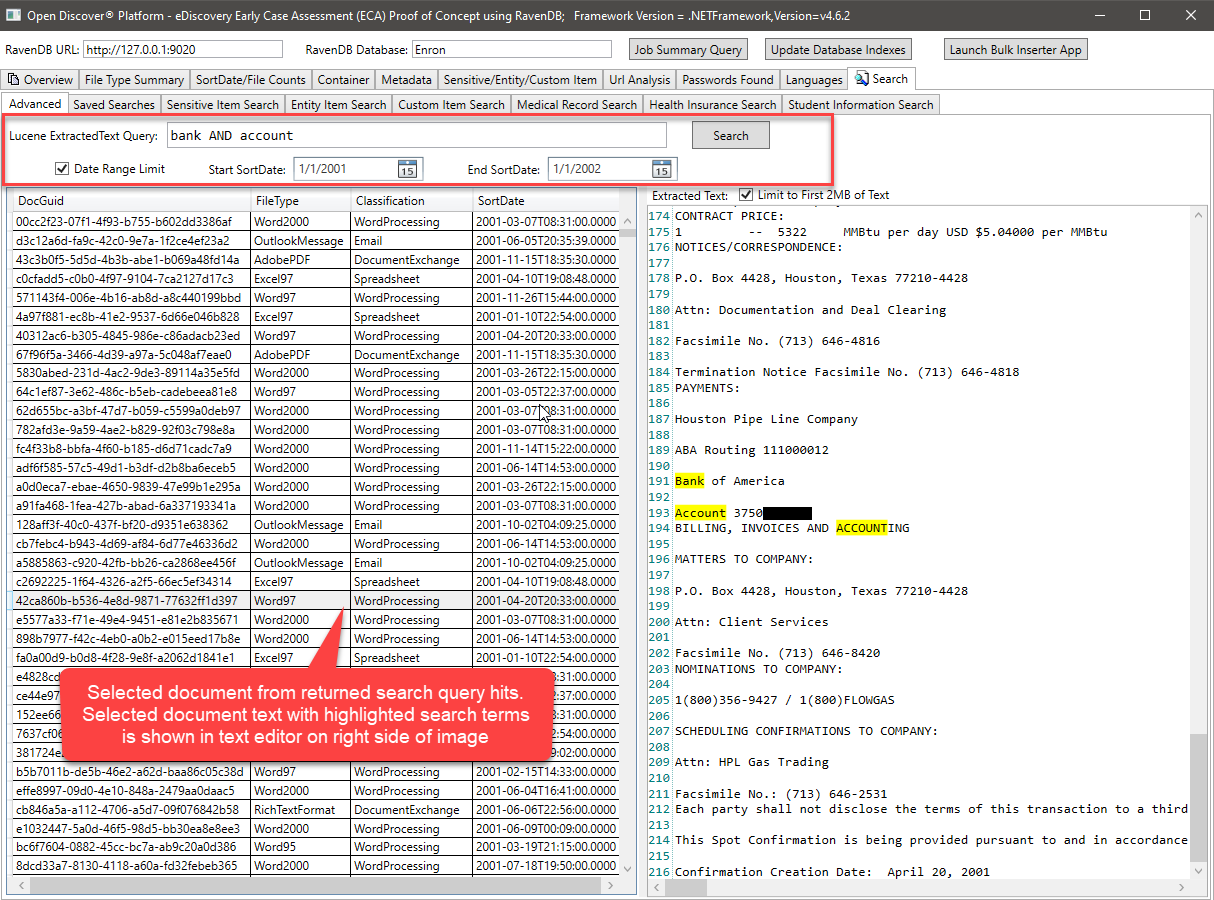
위의 Lucene 쿼리는 ExtractEdText 필드를 쿼리하고 (선택적으로) Min/Max 문서를 사용하여 반환 된 검색 결과를 필터링합니다. Document Filetype 또는 Document Format Classification (WordProcessing/Spreadsheet/Email 등)으로 결과 필터링을 추가하는 것도 매우 쉽습니다. Lucene 쿼리를 수행하는 C# 코드는 다음과 같습니다.
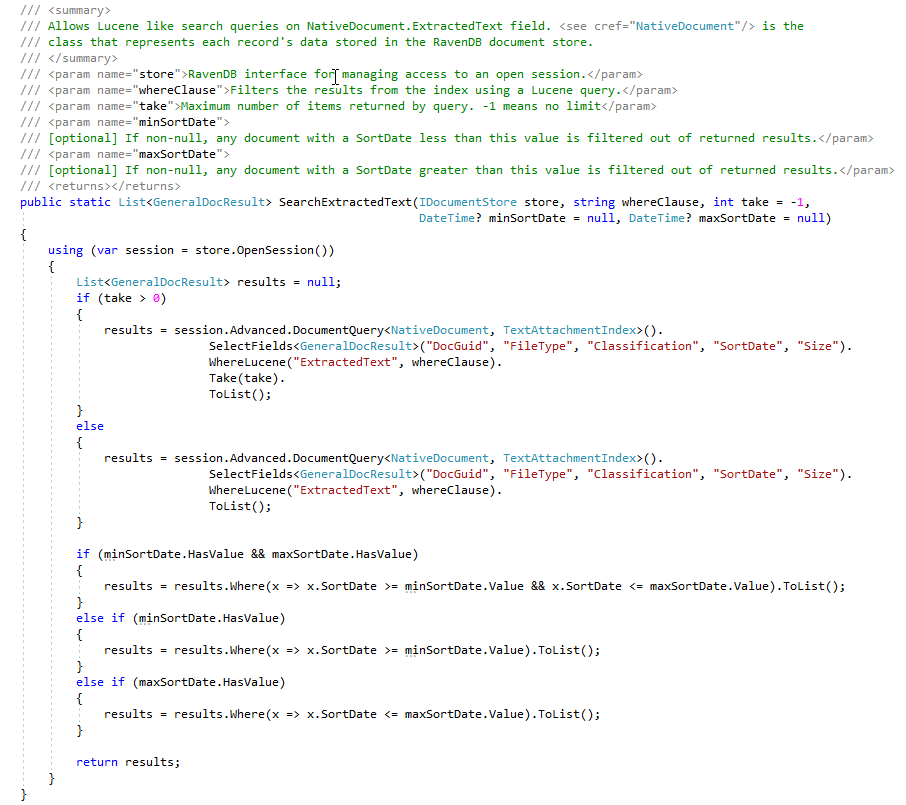
ECA 단계에서 법률 검토 변호사는 응답 문서를 찾기 위해 다양한 검색 쿼리를 작성하려고합니다. 아래 스크린 샷은 몇 가지 저장된 Lucene 쿼리와 결과 (문서 히트 수와 문서의 총 크기)를 보여줍니다. 이 사용자가 생성 한 검색의 문서 수에는 중복 문서 수가 포함되어 있지만, 중복 문서의 수를 계산하는 RavEndB 인덱스가 있지만,이 개념 증명에 대해서는 아직 마스터/중복을 나타내는 플래그가있는 문서 저장에 "표시된"문서가 아직 "표시되지 않았습니다 (사용자의 'todo'입니다).
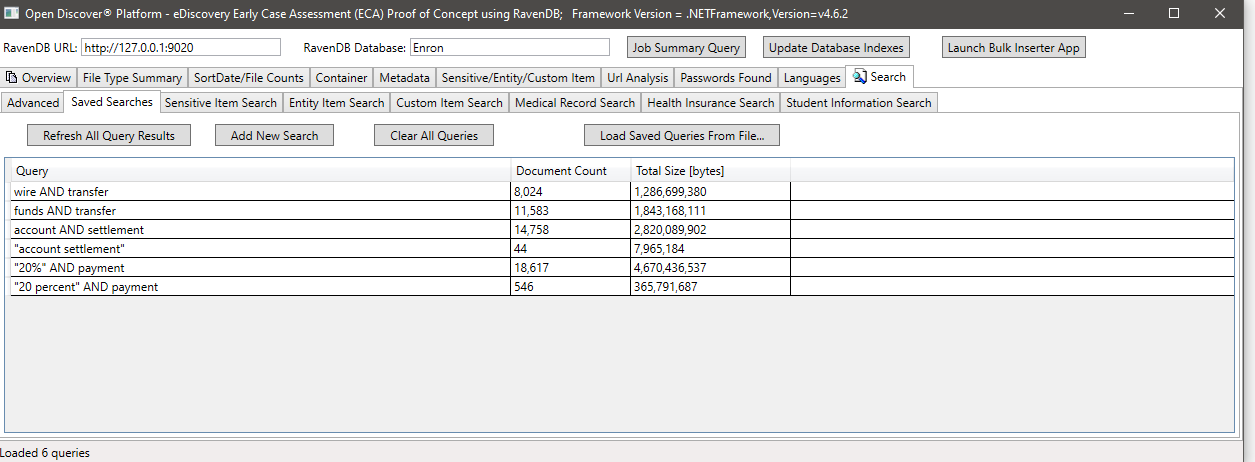
SENSITIVEITEMTYPE (민감한 항목의 유형을 식별하는 감지 된 민감한 객체에 대한 속성)의 예제 검색,이 예에서는 민감한 항목의 민감한 항목이있는 모든 문서를 검색합니다.
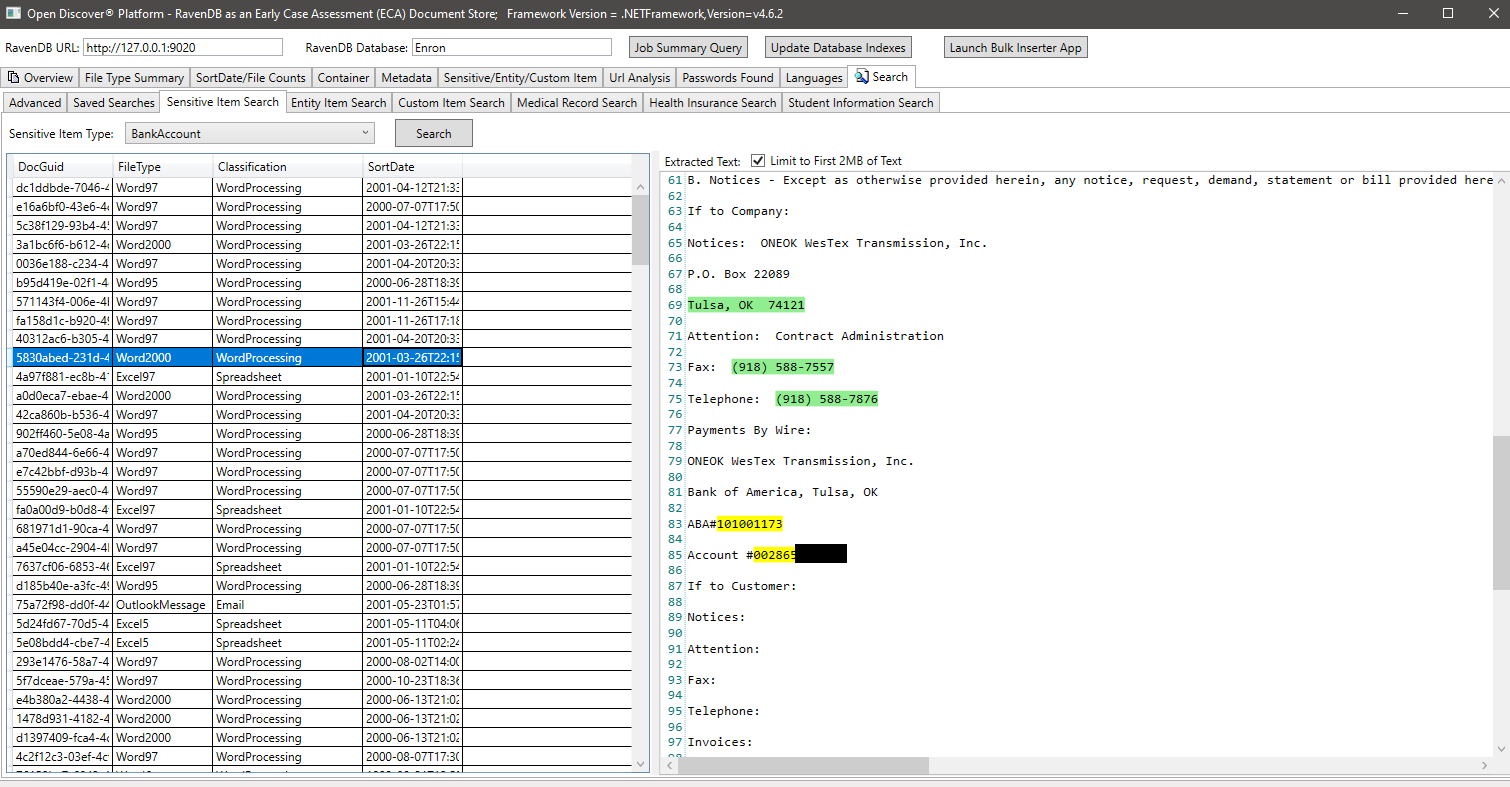
ENTITYITEMTYPE (Entity Object 유형을 식별하는 감지 된 EntityItem 개체의 속성)에 의한 예제,이 예에서는 ENTITYITEMTYPE.PATIENTNAMEENTRY 유형의 엔티티 항목이있는 모든 문서를 검색합니다.
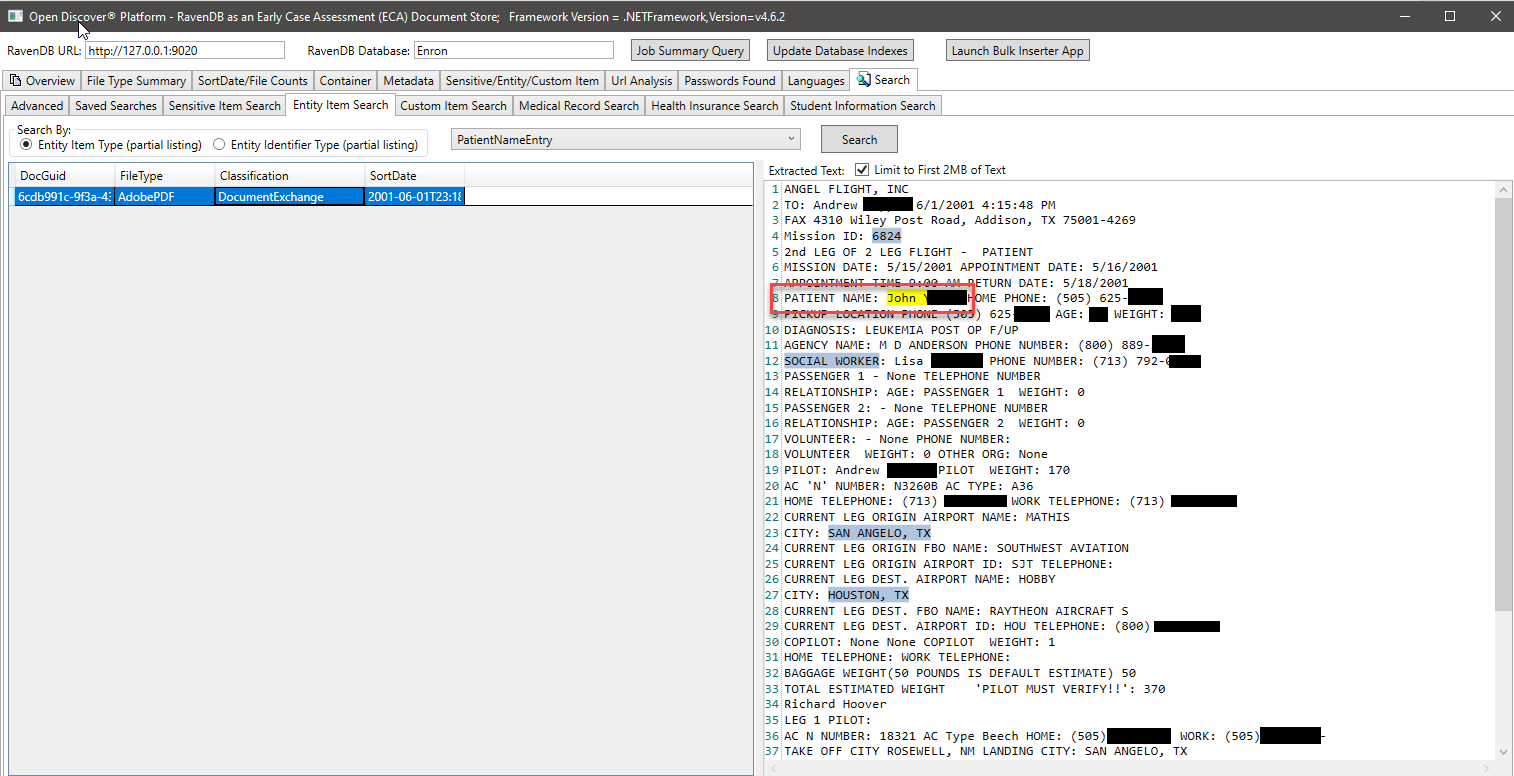
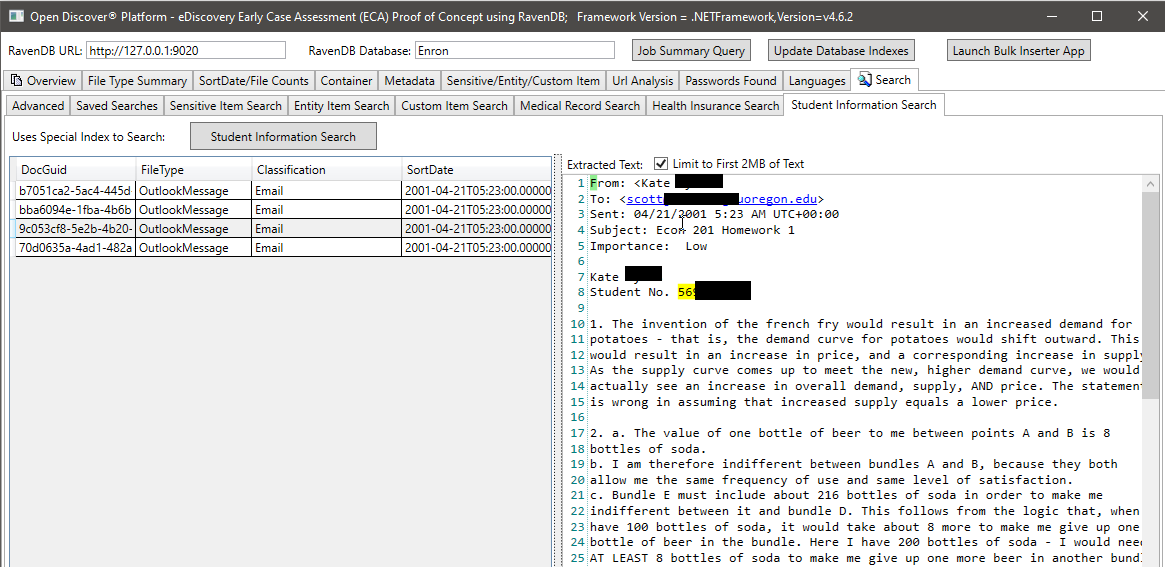
아래의 스크린 샷에서 우리는 학생 정보와 관련된 특정 Open Discover SDK 추출 Entity 유형을 색인화하여 학생 정보를 찾을 수있는 문서를 찾는 특별히 생성 된 RAVENB 인덱스를 사용합니다 (스크린 샷, 학생의 이름 및 학생 ID는 검은 색으로 표시되며 학생 ID는 2000 년 이전에 공통적 인 사회 보장 번호로 보입니다). 마찬가지로 의료 기록 및 환자 정보를 검색 할 다른 특수 지수가 있습니다.
RAVENDB와 같은 문서 데이터베이스에 저장된 Open Discover® 플랫폼 출력은 매우 강력하고 빠르게 개발 된 법적 초기 사례 평가 (ECA) 응용 프로그램으로 이어질 수 있습니다. 또한 다음과 같은 응용 프로그램도 빠르게 개발할 수 있습니다.
이 사례 연구가 RABENDB와 같은 문서 데이터베이스 대신 관계형 데이터베이스를 사용했다면, 수개월의 데이터베이스 스키마 설계 및 저장 절차 개발이 걸렸을 것이며, 2 주 동안이 초기 사례 평가 (ECA) 증명서를 개발하는 데 걸리는 시간이 지났습니다.


