OpenDiscoverPlatformCaseStudy
1.0.0
См. Open Discover® SDK для .NET Примеры репозитория GitHub
Один экземпляр открытого API платформы обнаружения, как правило, способен обрабатывать наборы документов по скорости 40-70 ГБ/час* (* Ставки будут зависеть от пользовательского оборудования и типов файлов в наборе данных). Это очень быстро в обработке документов, а также извлечение большего количества контента, чем большинство программного обеспечения Ediscovery (например, конфиденциальное обнаружение элементов/объекта и де-новое при при обработке). Демонстрационное приложение API Platform Platform Platform, Platformapidemo.exe, использовалось для обработки набора данных Enron Outlook PST. Демонстрационное приложение Platformapidemo.exe завершает один экземпляр класса обработки документов Platform API. Экранные снимки примера PlateryApidemo.exe Выход обработки показан в следующем разделе ниже.
Platformapidemo.exe распределяется с оценкой платформы открытых обнаружений вместе с:
В недавнем тесте на производительность открытый SDK обработал набор данных Microsoft PST PST 53 ГБ, а объемный вывод платформы (текстовые/метаданные/чувствительные (PXI)/и т. Д.) В Ravendb за чуть более 30 минут с использованием одного 4-уровневого настольного компьютера Windows.
** Эта скорость обработки тематического исследования была для версии SDK .net 4.62, новая версия .net 6 в среднем на 100% быстрее, все задачи обработки PST на версии .NET 6 OpendScoverplatform обработали свои задачи набора данных PST между 90-100+GB/HR (на основе размера входных. с процессором Intel I7 и 16 ГБ оперативной памяти).
Снимок экрана ниже показывает элемент электронной почты (и его вложения), который был извлечен из его контейнера Outlook PST и обработан приложением Platformapidemo.exe. Электронное письмо от одного из Enron Microsoft Outlook PST. Управление видом на дерево в левой части изображения показывает иерархию родителей/детей всех обработанных документов/контейнеров, а нажатие на элемент в управлении деревами будет отображать его извлеченный контент. Для выбранного элемента электронной почты Outlook в представлении дерева мы видим, что он имеет 6 документов MS Office Word в качестве вложений, которые были извлечены из электронной почты. Каждый привязанность/встроенный элемент также извлекла их содержание (обработка полностью развертывает любую родительскую иерархию детей, независимо от того, насколько сложна). Обратите внимание на результаты идентификации формата файла, рассчитанные «SortDate», различные хэши документов, извлеченные метаданные и другие элементы вкладок в верхней правой части изображения, которые содержат другое извлеченное содержимое:
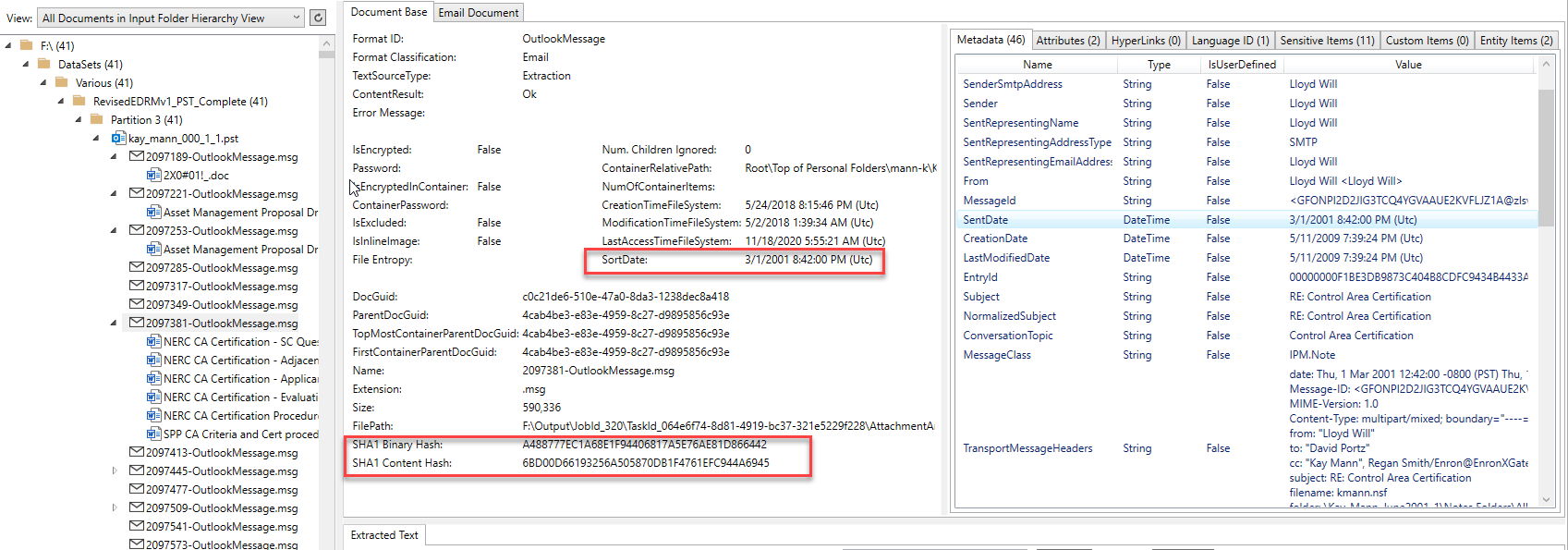
Электронная почта, конкретный контент, такой как все получатели и дополнительные хэши:
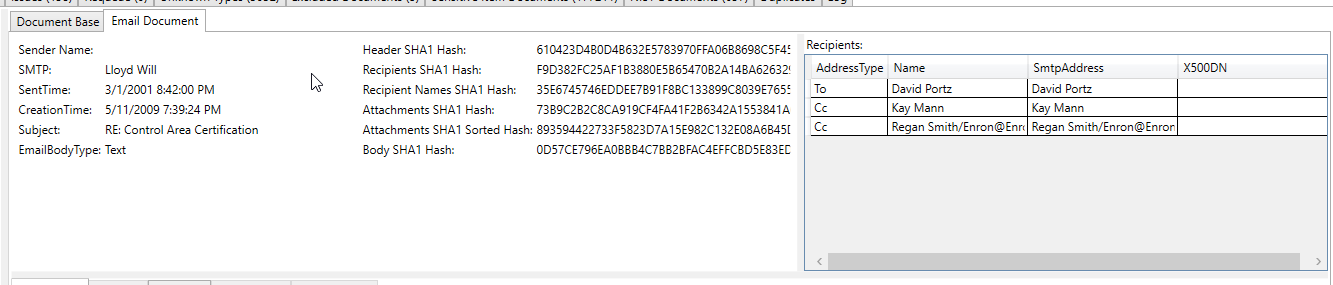
На этом обработанном снимке экрана электронной почты показан номер банковского счета, который был извлечен/идентифицирован как «конфиденциальный элемент» в извлеченном тексте электронной почты (все извлеченные текст и все метаданные сканируются на предмет конфиденциальных элементов):
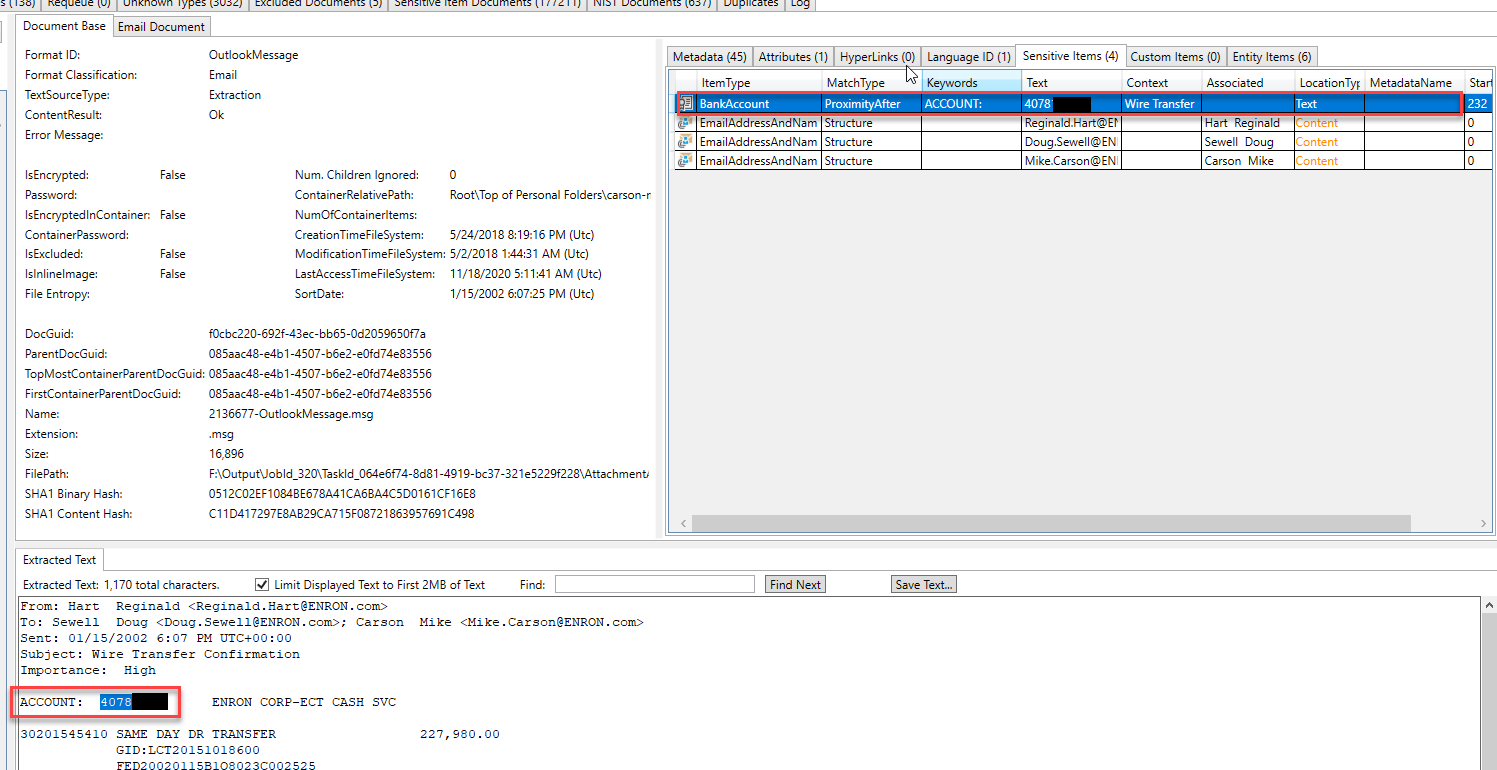
Некоторые «сущности» идентифицированы и извлечены в другом электронном письме. Осмотрев типы объектов, найденных в этом электронном письме, мы можем предположить, что электронное письмо обсуждает юридический вопрос:
Снимок экрана ниже показывает базу данных Enron в Ravendb Studio, заполненную обработанным выводом API платформы. Только некоторые из полей документов базы данных, хранящихся в Ravendb, могут вписаться в снимок экрана, есть гораздо больше полей. Названия столбцов с аннотацией красной границы являются коллекциями объектов:
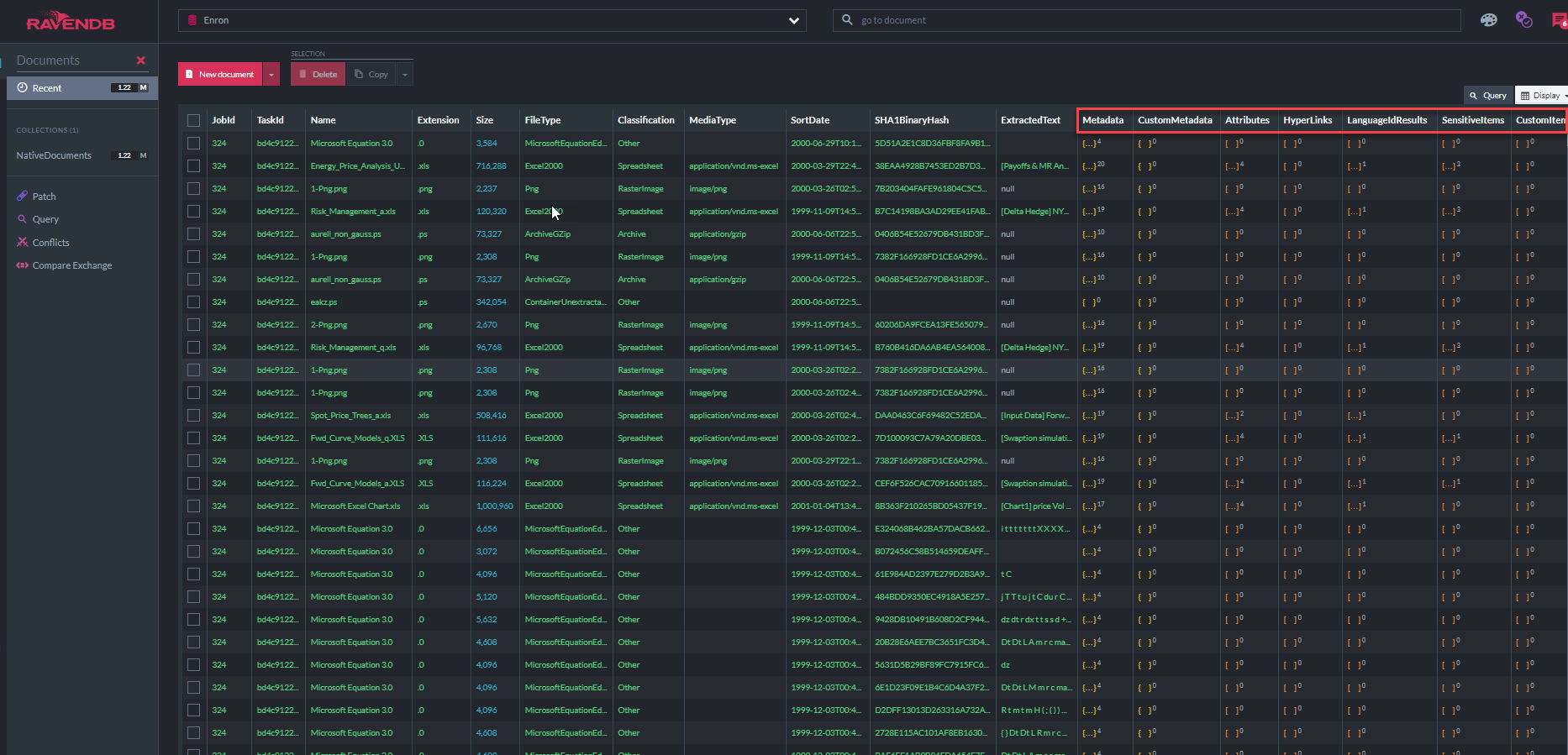
Снимок экрана ниже показывает некоторые из 31 индексов RavendB, которые использует «Демо -приложение ECA» для запроса хранилища документов (обратите внимание, что «метадатапропертииндекс» показывает, что в этой базе данных хранится 37,7 млн. Свойства метаданных: в основном по электронной почте, в дополнение ко всему извлеченному тексту):
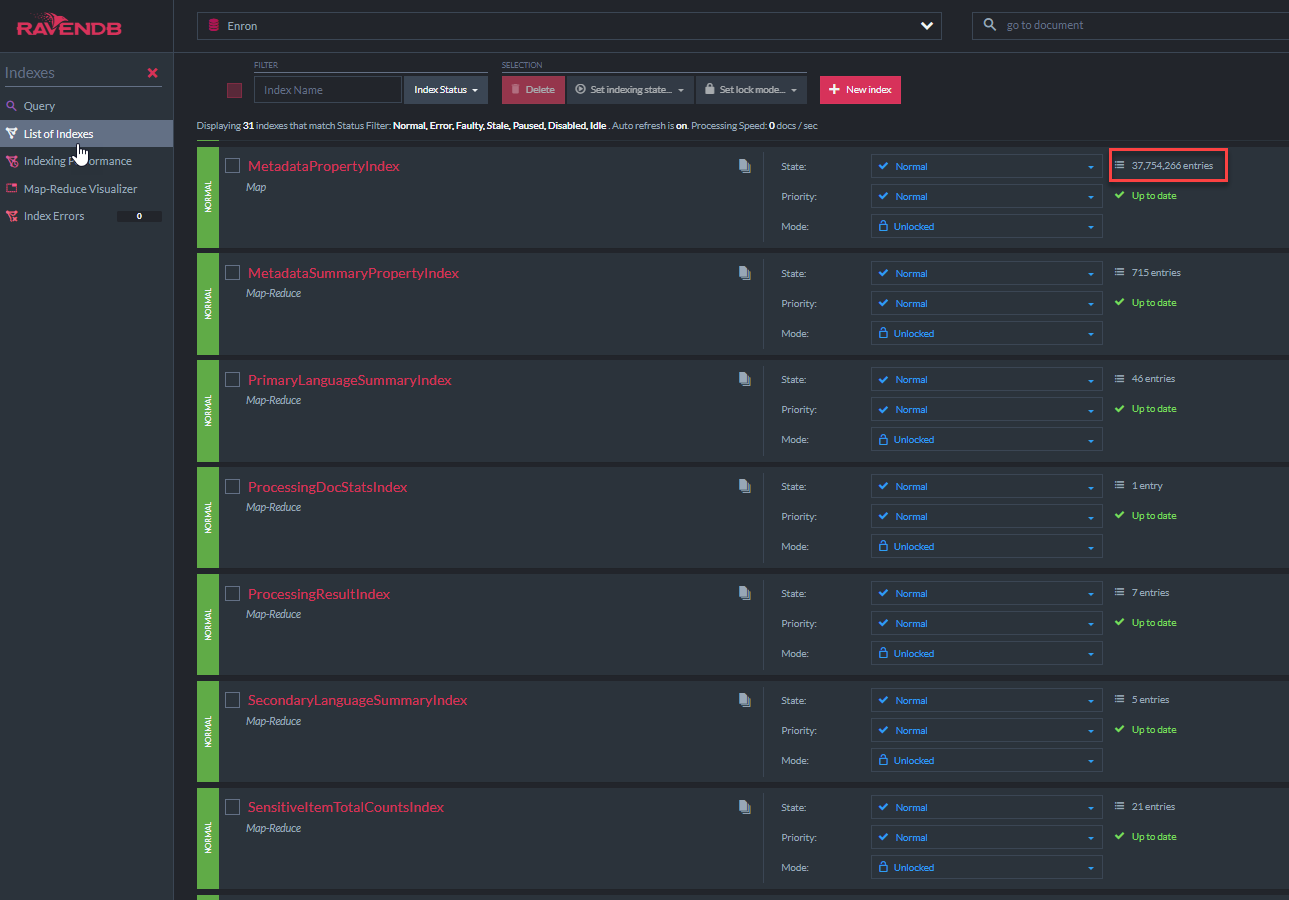
«Metadatapropertyindex» C# код класса отображается ниже. Этот индексный класс происходит от AbstractIndExcreationtask от Ravendb (как и все другие индексы в этой демонстрации). Этот индекс позволит Lucene «как» запросы на всех областях метаданных. Аналогичный индекс для NativedOcument.custommetAdata существует:
Все определенные индексы RAVENDB создаются в базе данных Ravendb Enron из «Демо -приложения ECA» через простой вызов API Ravendb:
Снимок экрана ниже показывает сводную статистику обработки 189 набора данных Microsoft Outlook PST Enron (1 221 542 электронных писем и вложений, обработанных в общей сложности). Большинство электронных писем и вложений в этом наборе данных являются дублирующими документами из -за того, что сотрудники Enron, чьи данные были собраны на этапе юридического обнаружения, писали друг другу электронные письма друг с другом - статистика дедупликации, показанная на изображении ниже, была основана на бинарной/контент -хэш, в будущем мы будем обновлять этот случай (наряду с индексами RavendB), чтобы включить юридическую отрасль «Семейный Deduplication». Обратите внимание на кругоскую диаграмму классификации формата файла, сводку специальной диаграммы формата файла и сводка результатов обработки (тип перечисления со значениями ok/ronfpassword/dataerry/и т. Д.).
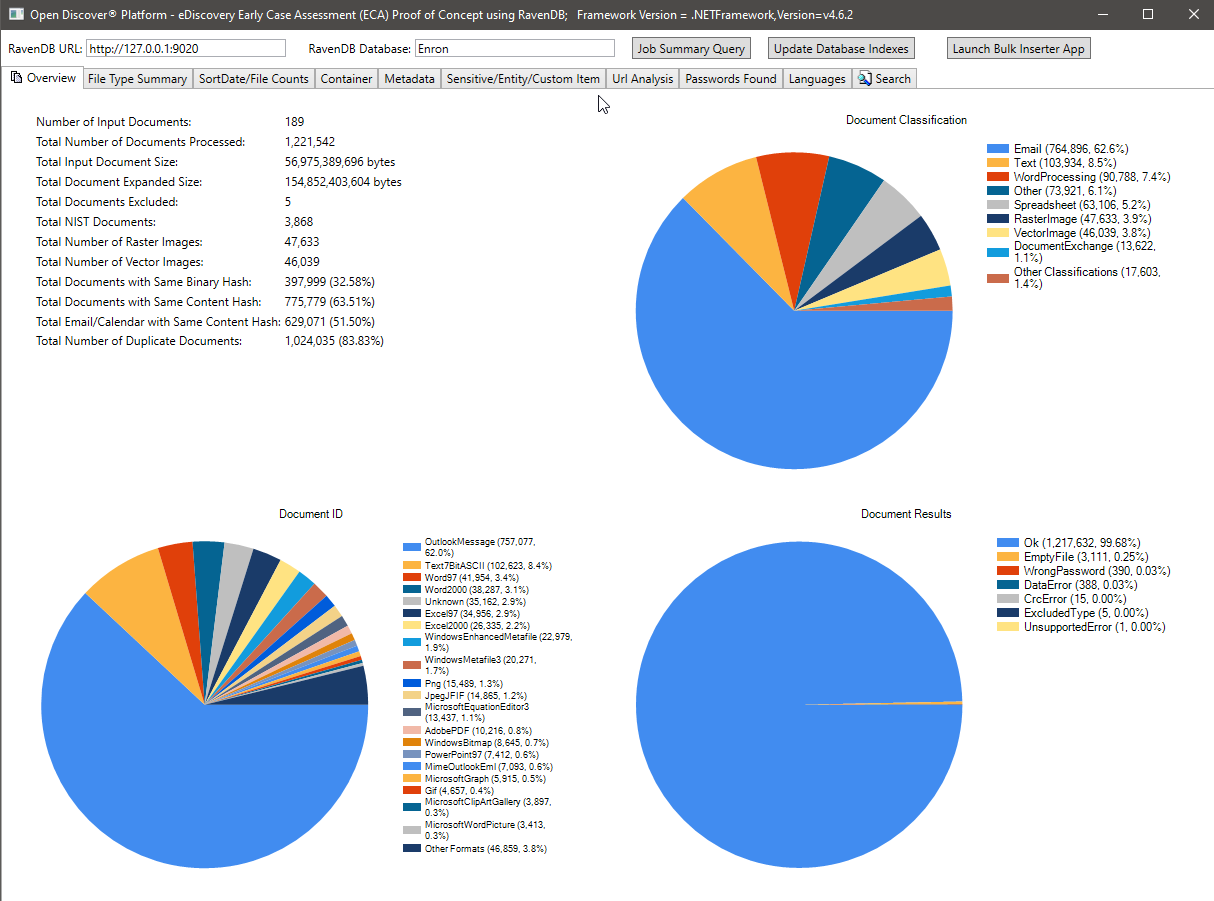
Подсчет файлов по сводным схемам сортировки:
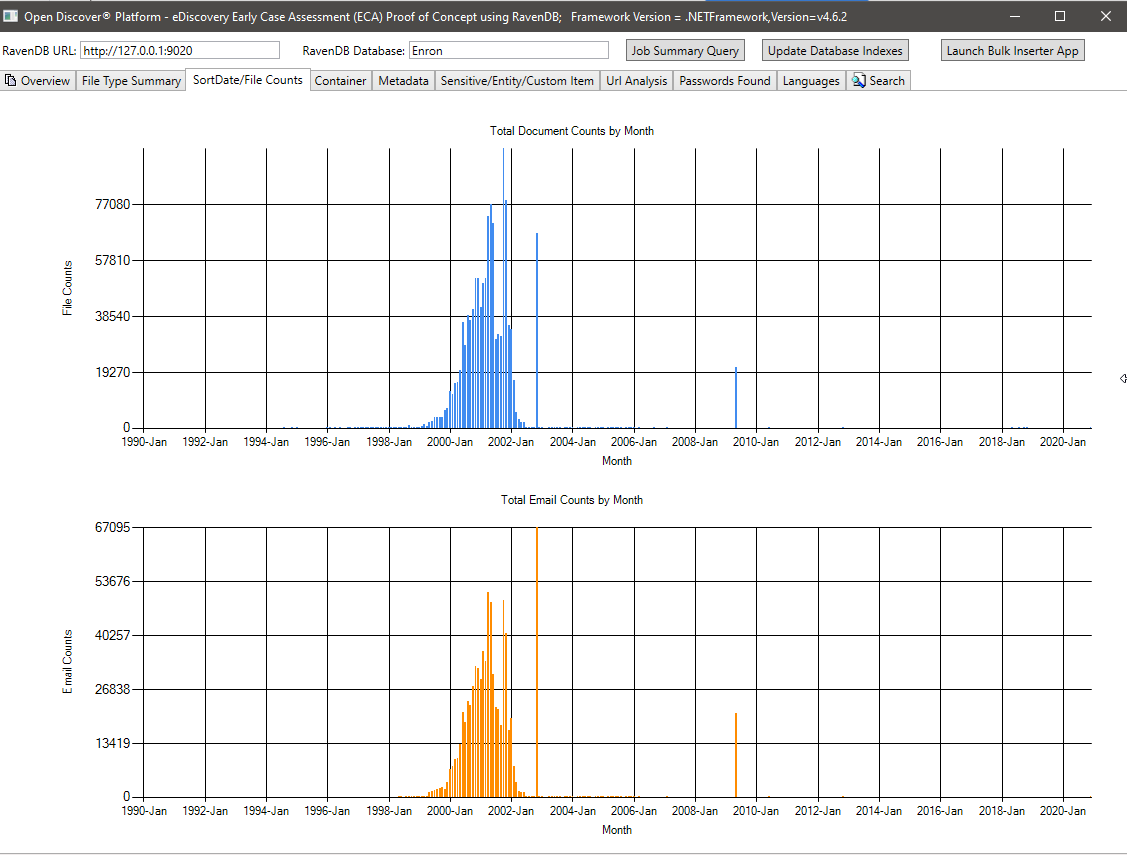
Сводка метаданных (имя поля метаданных/общее количество документов) - 715 Известные уникальные имена поля метаданных во всех документах и 636 пользовательских (определенных пользовательских) полей метаданных. Этот запрос может помочь юридическим управляющим делом узнать, какие поля метаданных доступны в коллекции для поиска:
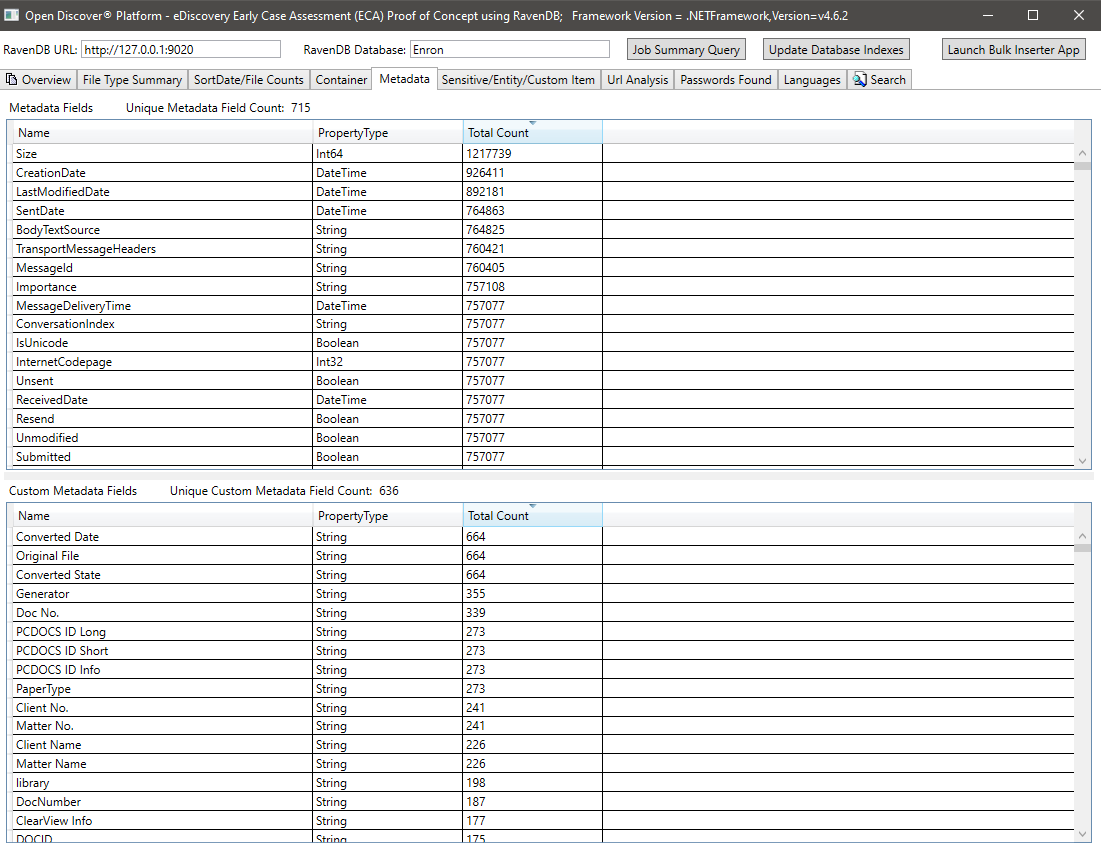
Сводка для конфиденциального элемента/предприятия для всех документов:
Резюме всех уникальных URL -адресов, найденных во всех документах (URL -адреса из каждого документа могут быть полезны, например, если компания хочет отследить потенциальные точки входа в злонамеренные URL). Открыть обнаружение SDK обнаруживает все URL-адреса от гиперссылок документов и в тексте документа (т.е. не Hyperlink):
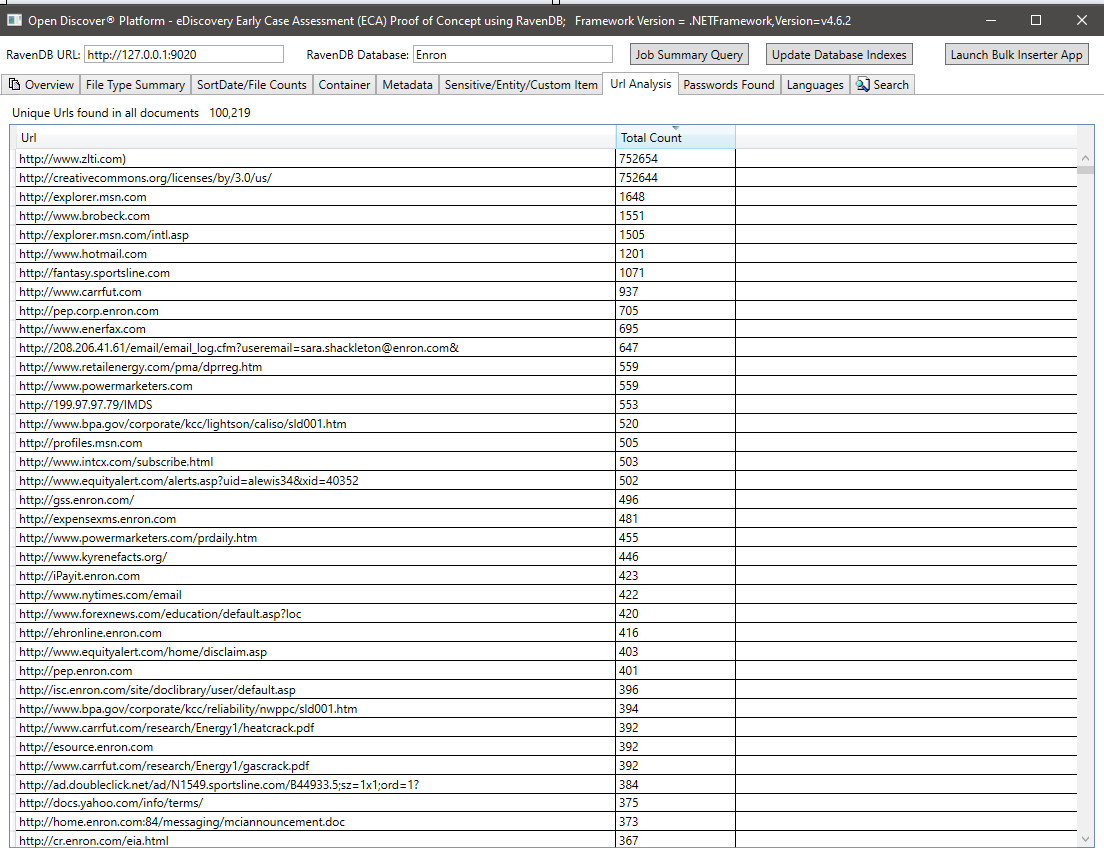
Резюме всех паролей, найденных во всех документах. Пароли и имена пользователей-это всего лишь 2 из 25 встроенных типов «конфиденциальных элементов», поддерживаемых открытым SDK/платформой. Учетные данные пароля/имени пользователя в документах могут быть риском безопасности, их также может использоваться для повторного процесса любого документа, который имеет результат обработки «ronfpassword» (поскольку сотрудники в одной и той же компании часто отправляют друг другу электронные письма по общим зашифрованным офисным документам):
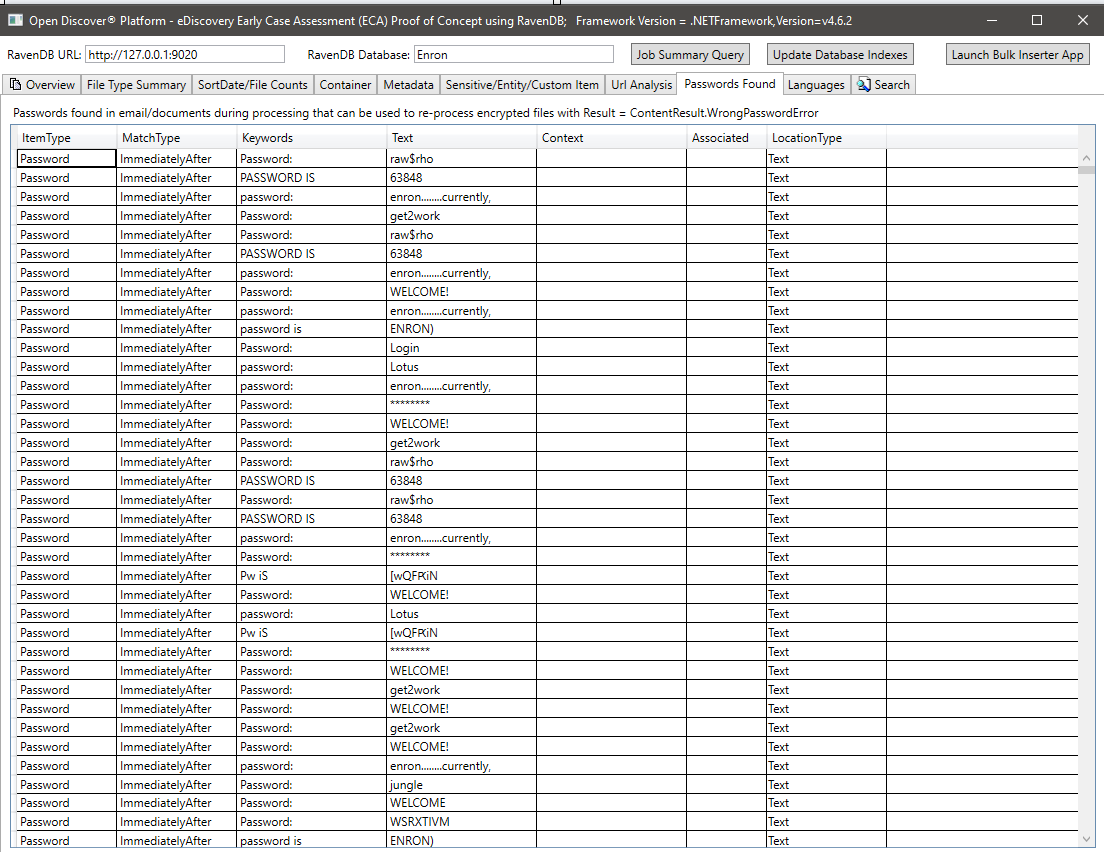
Сводка языков, обнаруженных в извлеченном тексте обработанных документов:
Пример полнотекстового поиска запроса (примечание: Ravendb поддерживает Lucene Queries):
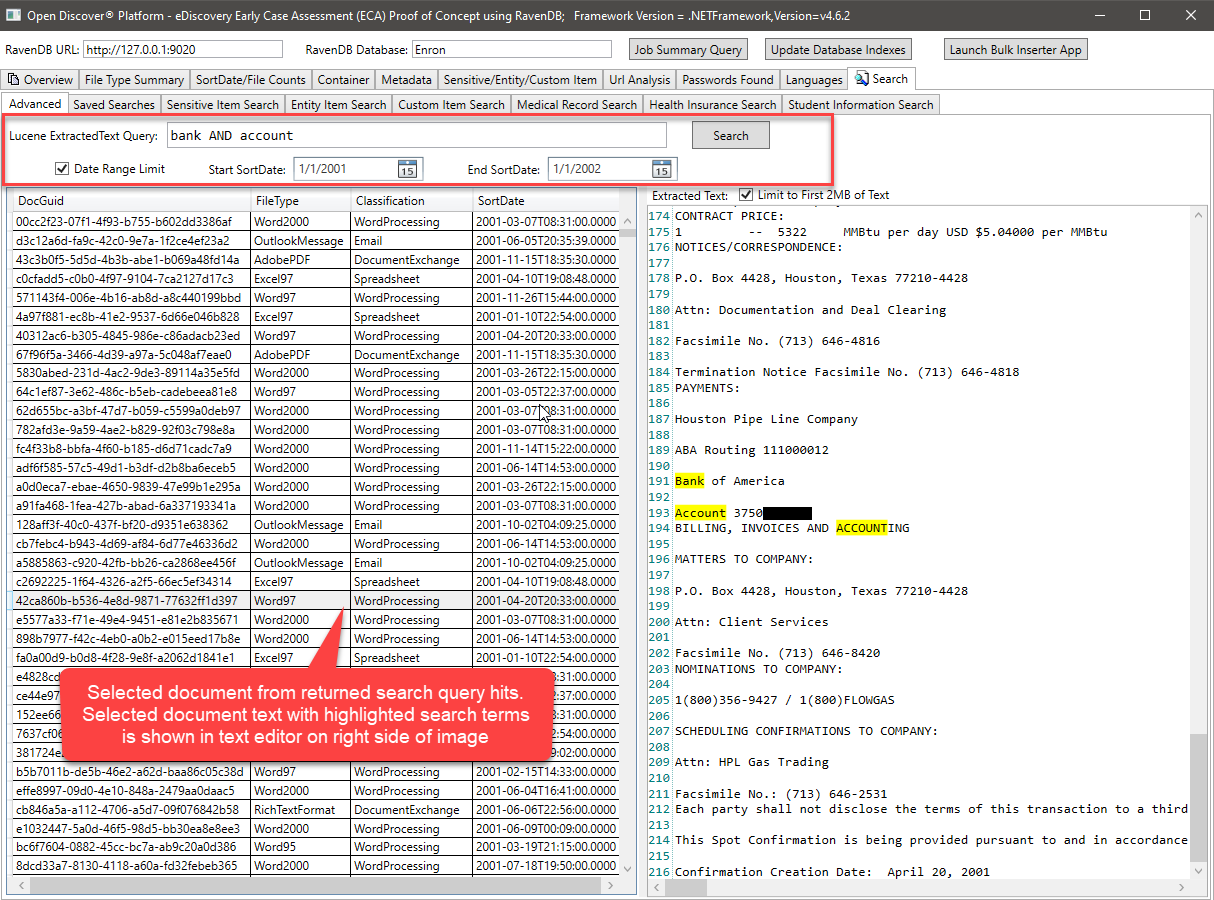
Приведенный выше запрос Lucene, запрашивает поле ExtractedText и использует (необязательно) Min/Max Document SortDate для фильтрации возвращаемых результатов поиска. Было бы очень легко добавить фильтрацию результатов с помощью документов filetype или классификации формата документов (WordProcessing/Spreadsheet/Email/и т. Д.). Код C#, который выполняет запрос Lucene, выглядит следующим образом:
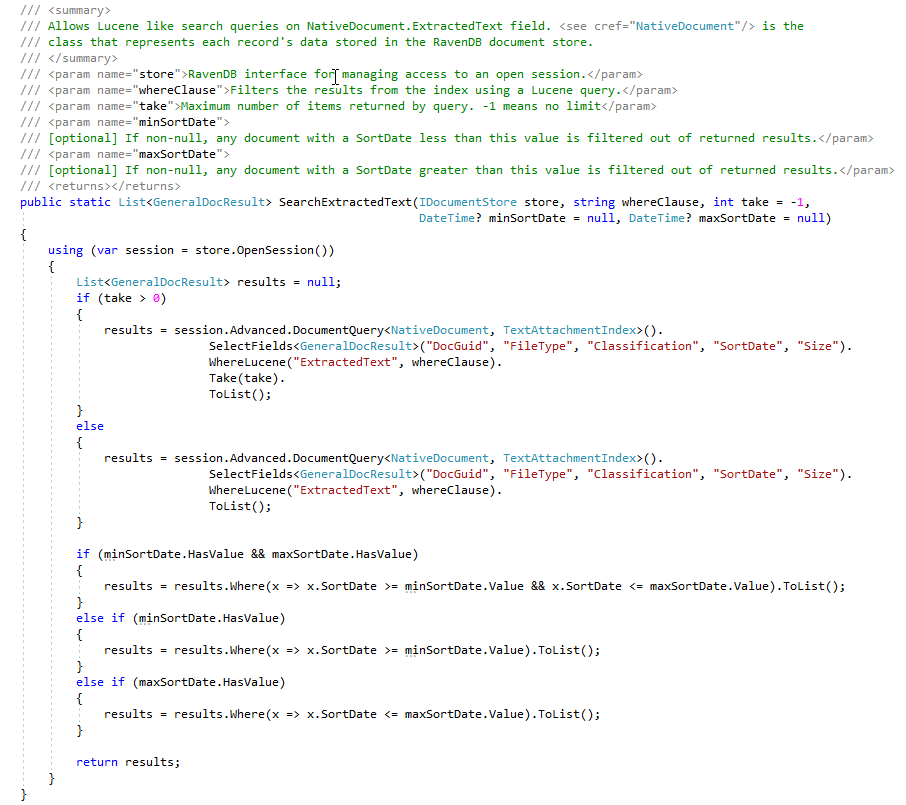
На этапе ECA юристы юридического рассмотрения любят создавать множество различных запросов поиска, чтобы найти ответные документы. Снимок экрана ниже показывает несколько сохраненных запросов Lucene и результатов (количество хитов документов и общий размер документов). Обратите внимание, что количество документов в этих поисках, созданных пользователем, содержит дублирующие количество документов, хотя у нас есть индексы Ravendb, в которых подсчитывается количество дублирующих документов, для этого подтверждения концепции мы еще не «помечены» документы в хранилище документов с флагом, указывающим Master/Doplicate (это «ToDo» от пользователя):: Пользователь «ToDo»):
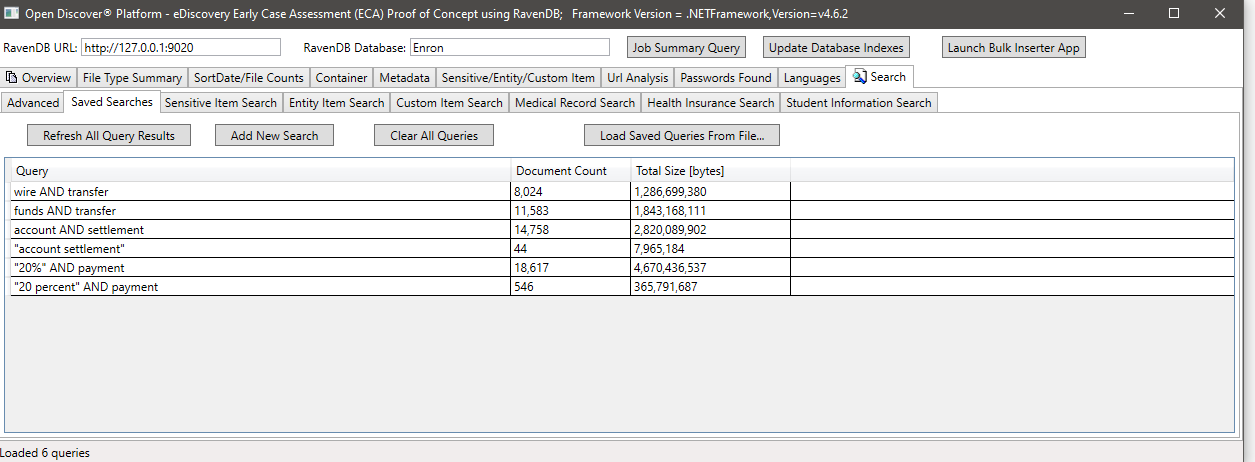
Пример поиска с помощью SensitiveItemType (свойство на обнаруженных объектах SensitiveItem, которое идентифицирует тип конфиденциального элемента), в этом примере мы ищем все документы, которые имеют конфиденциальное элемент типа SELTICATIONTEMTYPE.BankAccount:
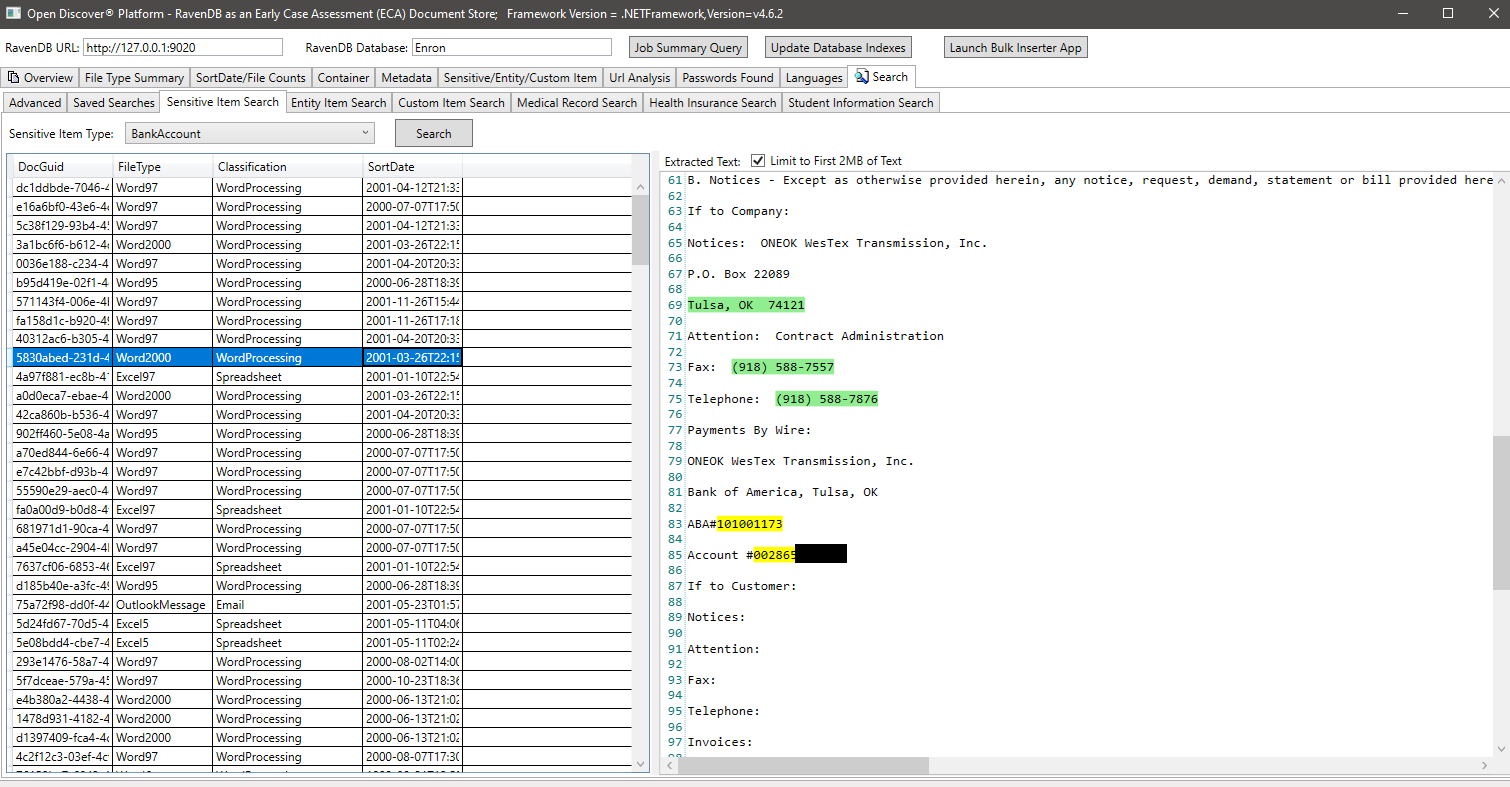
Пример Поиск по объекту EntityItemType (свойство на обнаруженных объектах EntityItem, которое идентифицирует тип элемента объекта), в этом примере мы ищем все документы, которые имеют элемент объекта типа EntityIteMtype.PatientNameEntry:
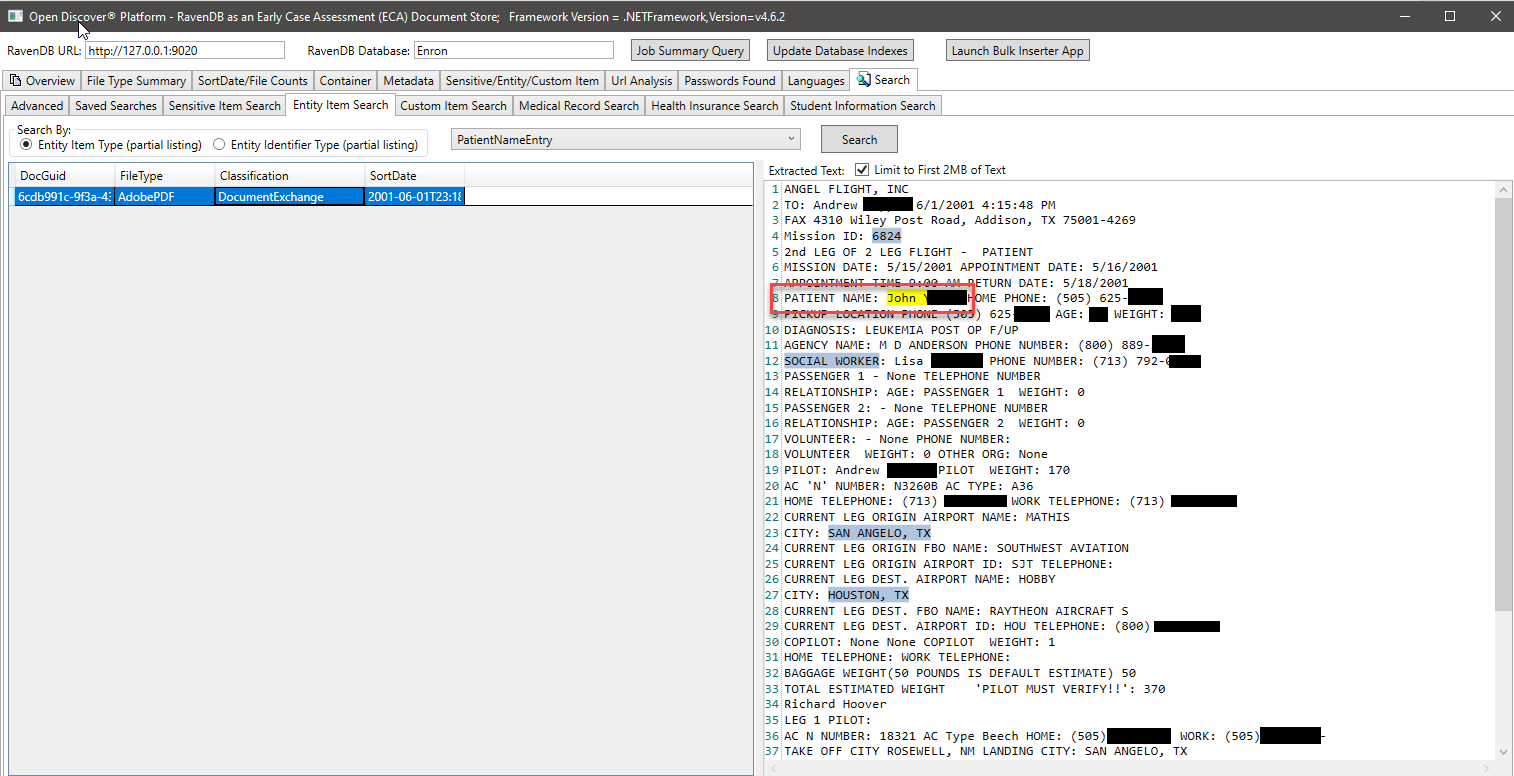
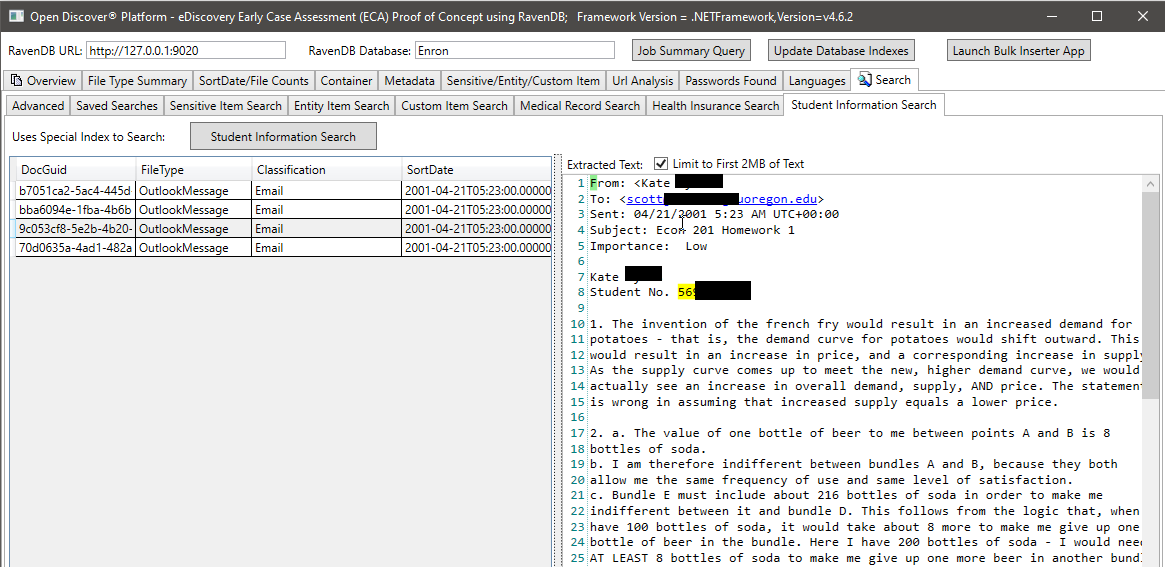
При снимке на экране мы используем специально созданный индекс Ravendb, который индексирует конкретные открытые открытые SDK, извлеченные типы объектов, связанные с информацией о студенте, для поиска документов, которые могут иметь информацию студента (в снимке экрана, имя студента и идентификатор студента отключены, идентификатор студента, по -видимому, является номером социального обеспечения, которое было распространено до 2000 -х годов). Аналогичным образом, у нас есть другие специальные индексы для поиска медицинских карт и информации о пациентах:
Открытые вывод платформы Discover®, хранящийся в базе данных документов, таких как Ravendb, может привести к очень мощным и быстро разработанным приложениям юридической оценки ранней оценки (ECA). Кроме того, такие приложения, как следующее, также могут быть быстро разработаны:
Если бы в этом тематическом исследовании использовалась реляционная база данных вместо базы данных документов, такой как Ravendb, потребовалось бы месяцы разработки схемы базы данных и разработки процедур хранилища, а не на 2 недели, необходимо для разработки этого раннего оценки оценки (ECA).


