OpenDiscoverPlatformCaseStudy
1.0.0
Voir le SDK Open Discover® pour le référentiel GitHub.
Une seule instance d'API de plate-forme Open Discover est généralement capable de traiter les ensembles de documents à 40-70 Go / Hour Taux * (* Les taux dépendront du matériel utilisateur et des types de fichiers dans l'ensemble de données). Il est très rapide dans le traitement des documents tout en extrayant plus de contenu que la plupart des logiciels d'Ediscovery (par exemple, détection sensible des éléments / entités et dénistement pendant le traitement). Une application de démonstration API de plate-forme ouverte de découverte, PlatformApidemo.exe, a été utilisée pour traiter l'ensemble de données ENRON Outlook PST. L'application de démonstration PlatformAPIDEMO.exe enveloppe une instance de la classe de traitement de document API de plate-forme. Les captures d'écran de l'exemple de la sortie de traitement PlatformAPIDEMO.EXE sont affichées dans la section suivante ci-dessous.
La plate-forme-apidemo.exe est distribuée avec l'évaluation de la plate-forme Open Discover avec:
Dans un test de performance récent, le SDK Open Discover a traité l'ensemble de données PST de 53 Go enron Microsoft Outlook et en vrac a inséré la sortie de l'API de la plate-forme (texte / métadonnées / éléments sensibles (PXI) / etc.) dans RavendB en un peu plus de 30 minutes en utilisant un seul PC de bureau Windows à 4 comes.
** Ce taux de traitement de l'étude de cas concernait la version .NET 4.62 de SDK, la nouvelle version .NET 6 est> 100% plus rapide en moyenne, toutes les tâches de traitement PST sur la version .NET 6 de OpenDiscoverPlatform traitées sur leurs tâches de jeu de données PST entre 90-100 + GB / HR I7 CPU et 16 Go de RAM).
La capture d'écran ci-dessous affiche un élément de messagerie (et ses pièces jointes) qui a été extraite de son conteneur Outlook PST et traitée par l'application PlatformAPIDEMO.exe. L'e-mail provient de l'un des PST d'Enron Microsoft Outlook. Le contrôle de l'arborescence sur le côté gauche de l'image montre la hiérarchie parent / enfant de tous les documents / conteneurs traités, et cliquer sur un élément de la commande d'arbre affichera son contenu extrait. Pour l'élément d'e-mail Outlook sélectionné dans l'arborescence, nous pouvons voir qu'il a 6 documents Word MS Office comme des pièces jointes extraites de l'e-mail. Chaque élément d'attachement / intégré a également fait extraire son contenu (le traitement déroule entièrement toute hiérarchie enfant parent, quelle que soit sa complexité). Remarque les résultats d'identification du format de fichier, "Sortdate" calculé, divers hachages de documents, les métadonnées extraites et d'autres éléments d'onglet en haut à droite de l'image qui contiennent d'autres contenus extraits:
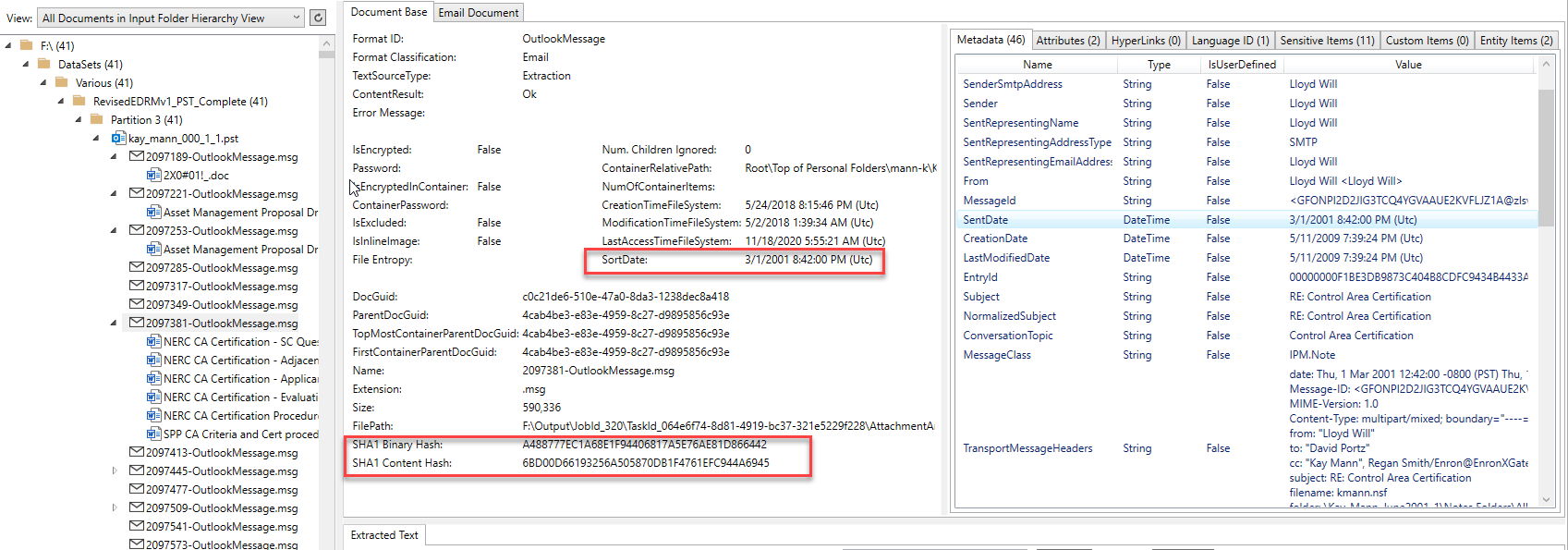
Envoyer un e-mail à un contenu spécifique comme tous les destinataires et les hachages supplémentaires:
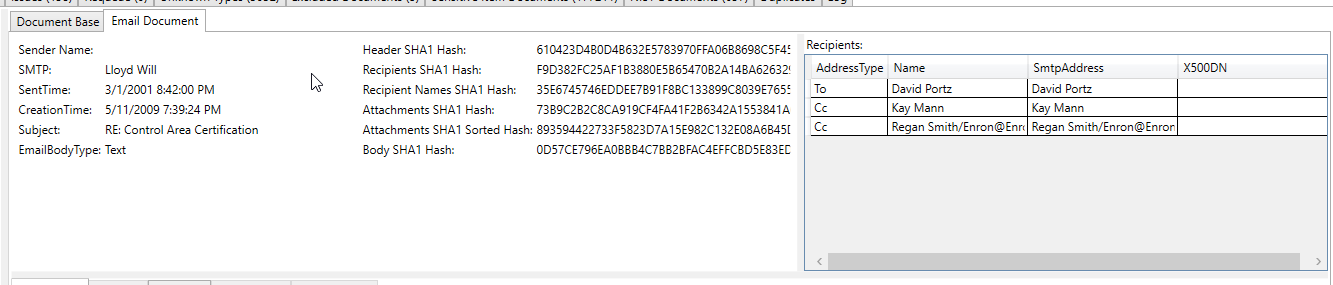
Cette capture d'écran de messagerie traitée affiche un numéro de compte bancaire qui a été extrait / identifié comme un "élément sensible" dans le texte extrait de l'e-mail (tout texte extrait et toutes les métadonnées sont scannés pour les éléments sensibles):
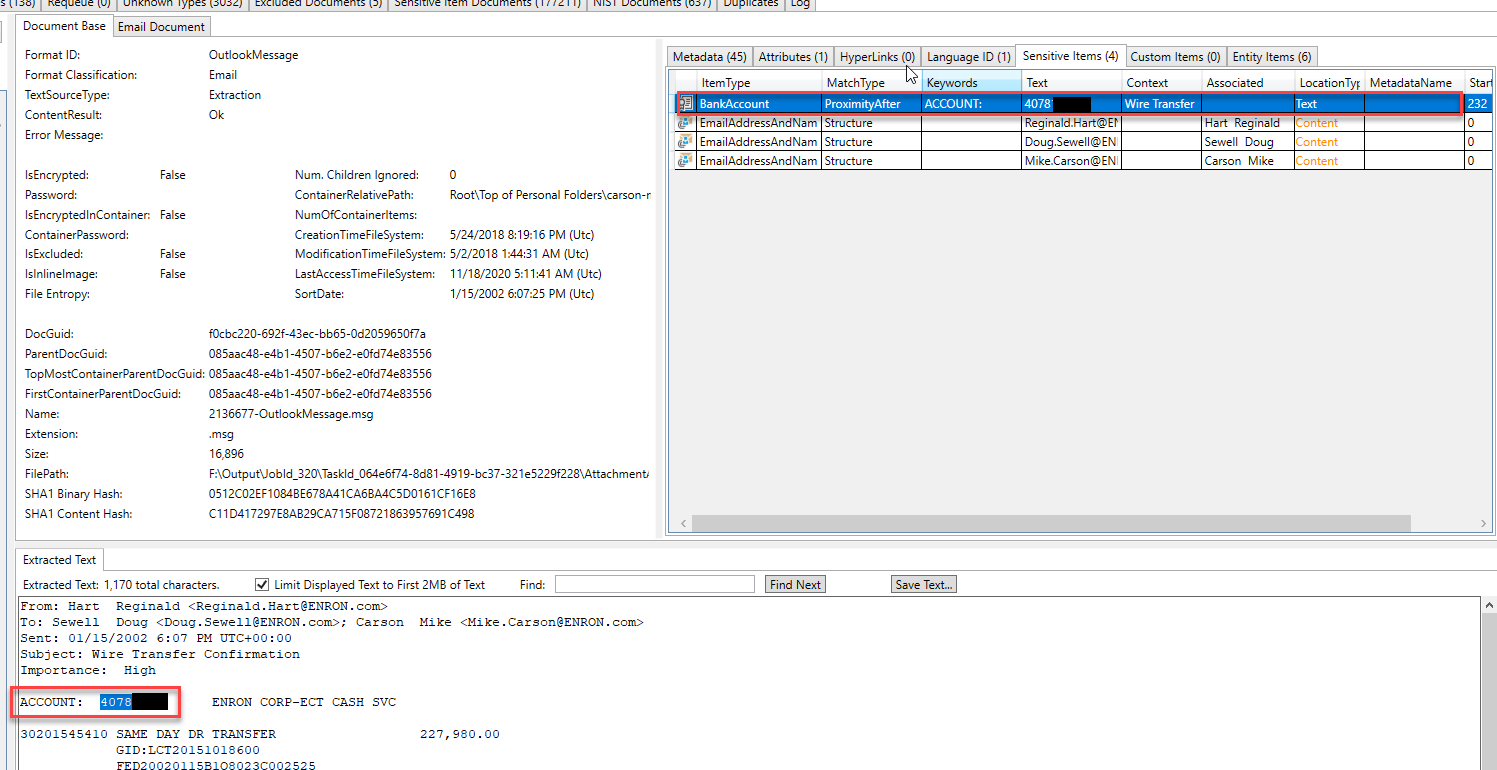
Certaines "entités" ont identifié et extrait dans un e-mail différent. En inspectant les types d'entités trouvées dans cet e-mail, nous pouvons supposer que l'e-mail discute d'une affaire juridique:
La capture d'écran ci-dessous montre la base de données Enron dans Ravendb Studio remplie de sortie traitée API de plate-forme. Seul certains des champs de documents de base de données stockés dans Ravendb pourraient s'intégrer dans la capture d'écran, il y a beaucoup plus de champs. Les noms de colonne avec une annotation de bordure rouge sont des collections d'objets:
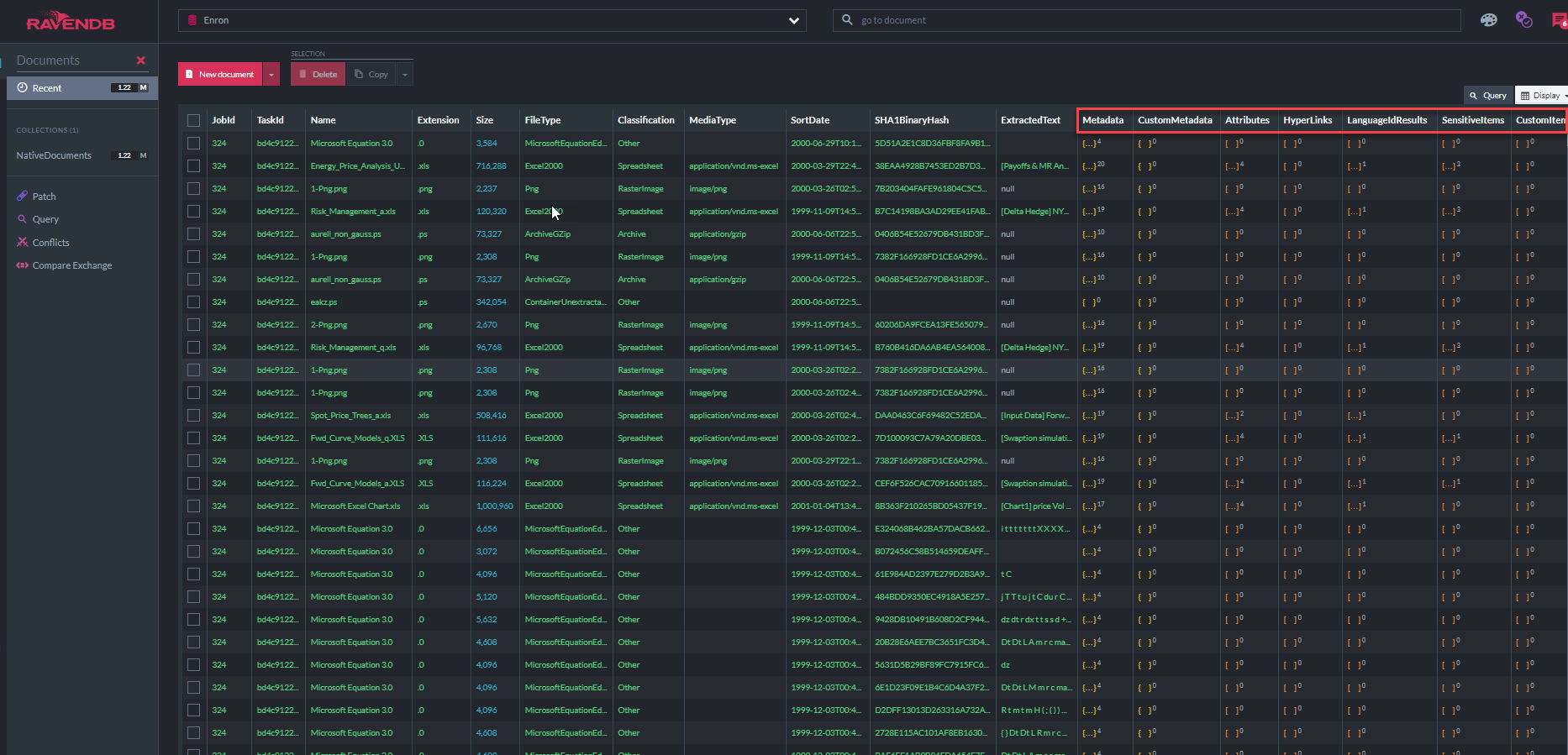
La capture d'écran ci-dessous montre certains des 31 index RavendB que "l'application de démonstration ECA" utilise pour interroger le magasin de documents (notez que "MetadatapropertyIndex" montre qu'il y a 37,7 millions de métadonnées stockées dans cette base de données, principalement des métadonnées par e-mail, en plus de tout le texte extrait):
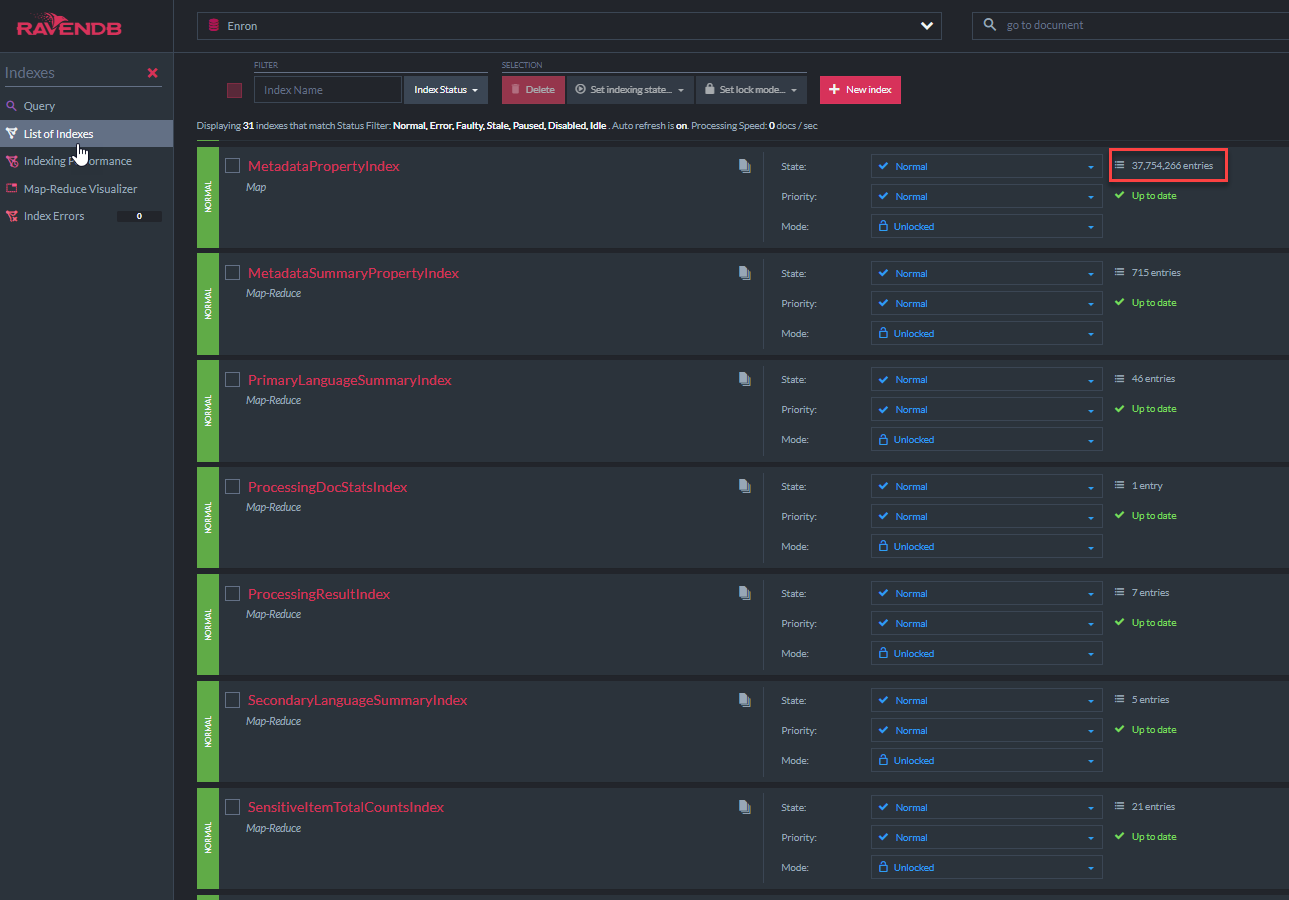
Le code de classe C # "MetadataPropertyIndex" s'affiche ci-dessous. Cette classe d'index dérive de RavendB AbstractIndexcreationTask (tout comme tous les autres index de cette démo). Cet index permettra aux requêtes «like» de lunene sur tous les champs de métadonnées. Un indice similaire pour NativeDocument.Custometadata existe:
Tous les index Ravendb définis C # sont créés dans la base de données RavendB ENRON à partir de "ECA Demo App" via un simple appel API RavendB:
La capture d'écran ci-dessous montre les statistiques de résumé de traitement de l'ensemble de données Microsoft Outlook PST ENRON (1 221 542 e-mails et pièces jointes traitées au total). La plupart des e-mails et des pièces jointes de cet ensemble de données sont des documents en double en raison du fait que les employés d'Enron dont les données ont été collectés pendant la phase de découverte juridique se faisaient envoyer des e-mails - les statistiques de déduplication montrées dans l'image ci-dessous étaient basées sur le hachage binaire / de contenu, à l'avenir, nous mettrons à jour cette étude de cas (avec les indices RavendB) pour l'industrie juridique préférée "Deduplication familiale". Remarquez le graphique à tarte de classification du format de fichier, résumé du graphique à tarte au format de fichier spécifique et résumé du traitement des résultats (type d'énumération avec des valeurs de graphique à tarte OK / tortpassword / dataerror / etc).
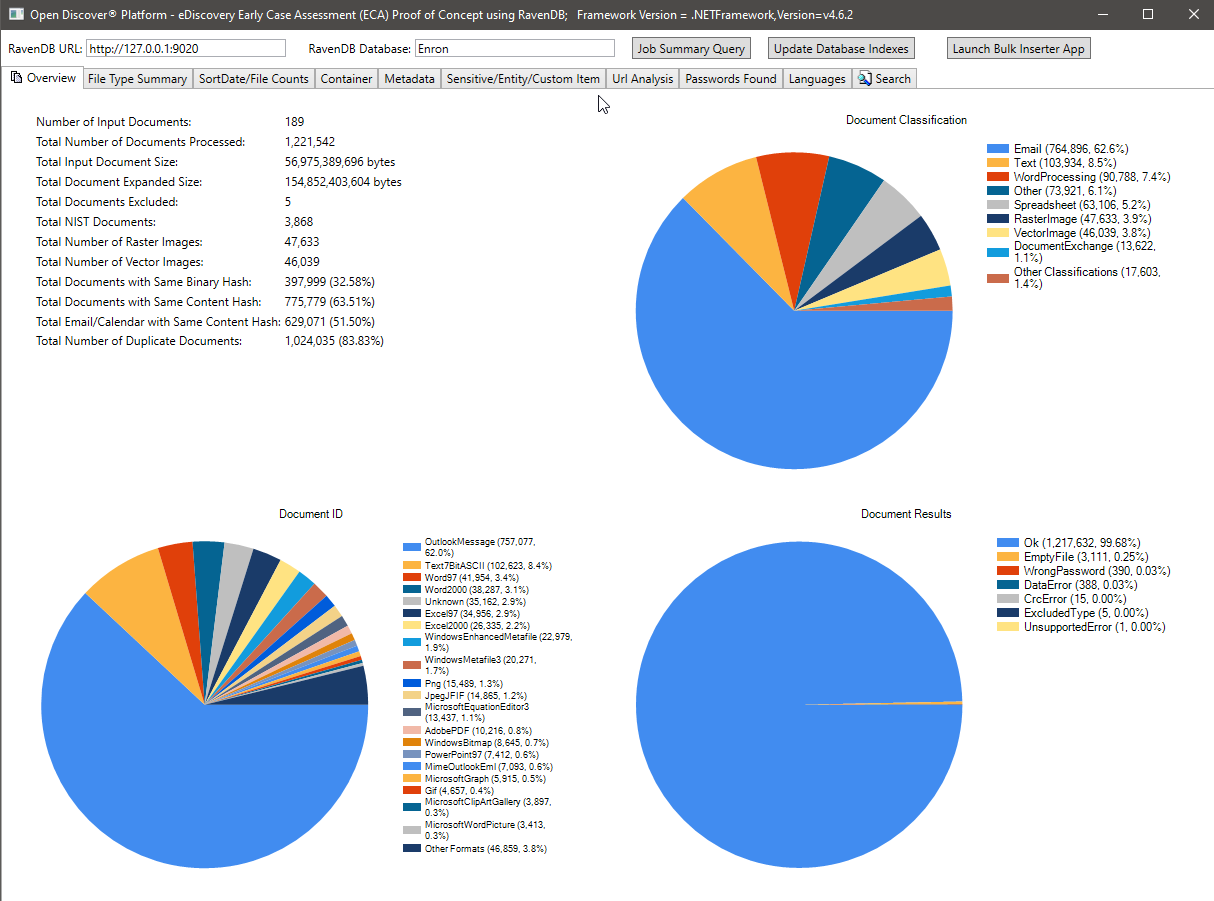
Comptes de fichiers par sortDate Summary Charts:
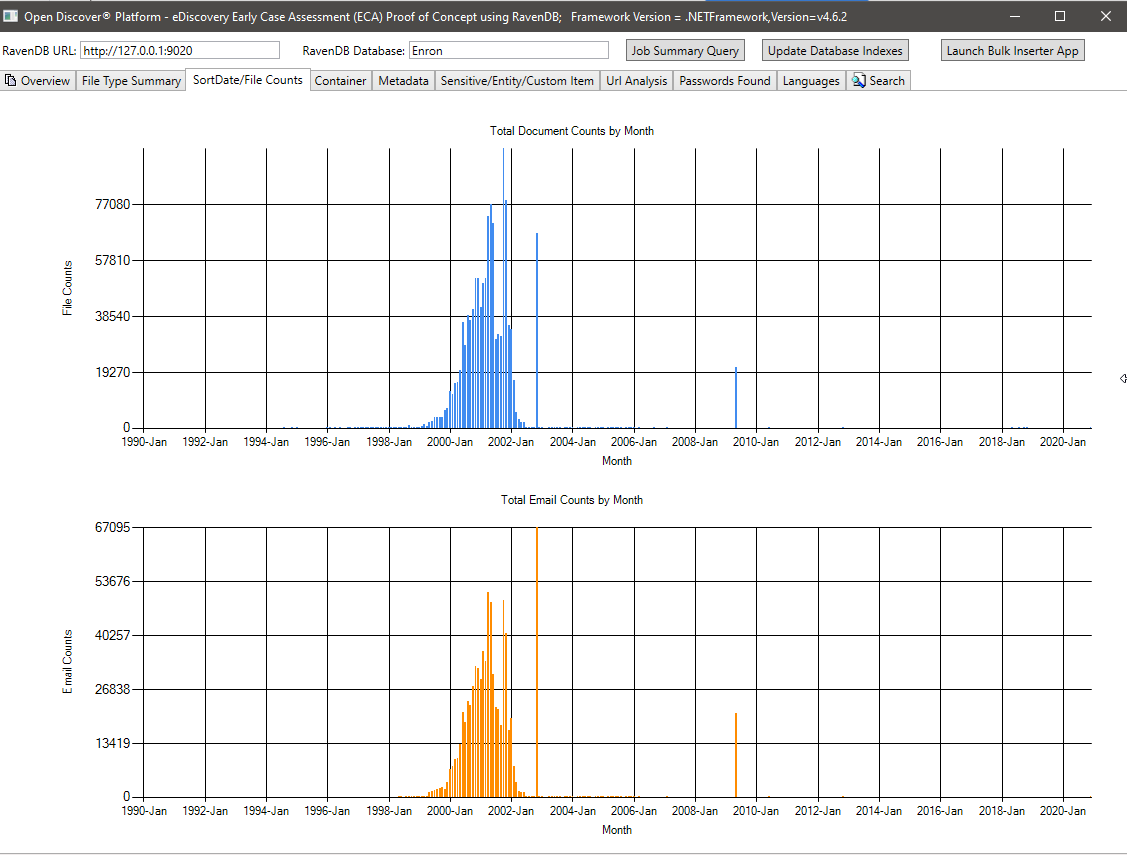
Résumé des métadonnées (Nom du champ de métadonnées / Nombre total de documents) - 715 Noms de champ de métadonnées uniques connus sur tous les documents et 636 champs de métadonnées personnalisées (définies par l'utilisateur). Cette requête peut aider les gestionnaires de cas juridiques à savoir quels champs de métadonnées sont disponibles dans la collection pour rechercher:
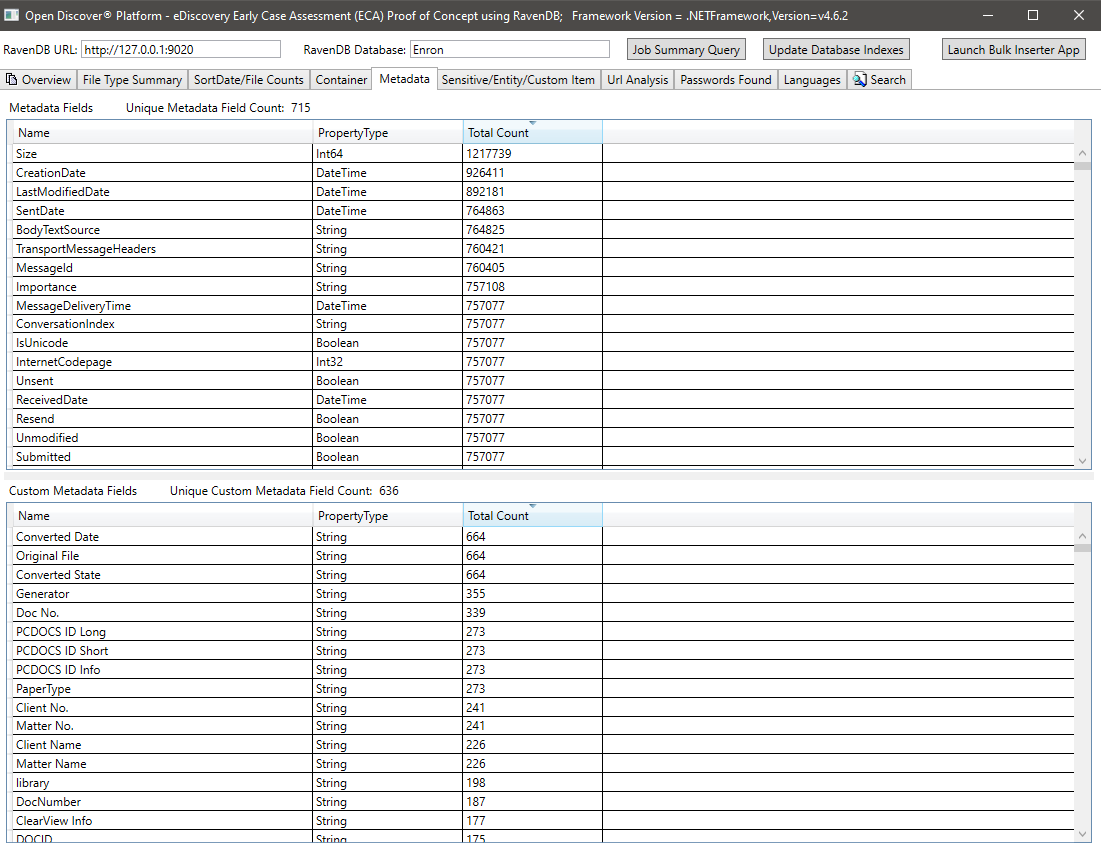
Résumé des éléments d'élément / entité sensibles pour tous les documents:
Résumé de toutes les URL uniques trouvés dans tous les documents (les URL de chaque document peuvent être utiles, par exemple, si une entreprise souhaite retrouver les points d'entrée d'URL potentiels). Open Discover SDK détecte toutes les URL à partir des hyperliens de documents et dans le texte du document (c'est-à-dire non-hyperlink):
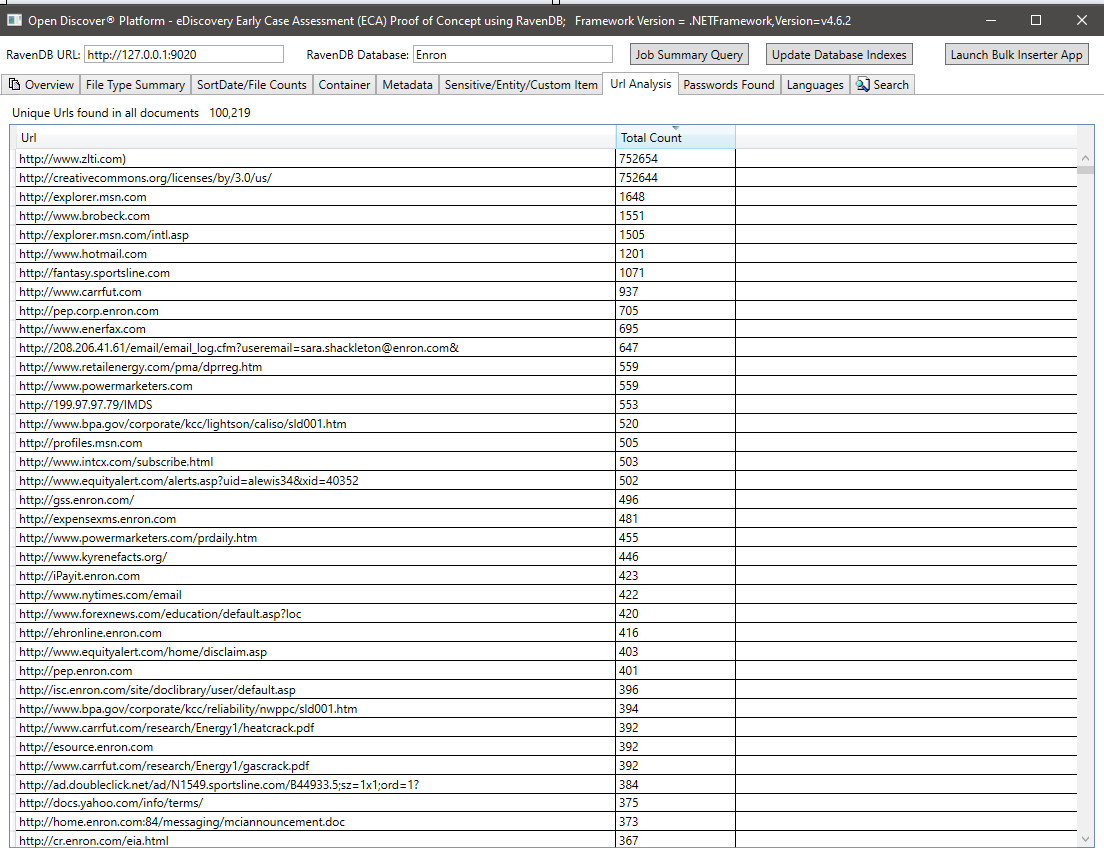
Résumé de tous les mots de passe trouvés dans tous les documents. Les mots de passe et les noms d'utilisateur ne sont que 2 types «d'élément sensible» intégrés pris en charge par le SDK / plate-forme Open Discover. Mot de passe / nom d'utilisateur Les informations d'identification dans les documents peuvent être un risque de sécurité, ils peuvent également être utilisés pour re-traiter tout document qui a un résultat de traitement de `` malword de la transmission '' (car les employés de la même entreprise envoient souvent des mots de passe les uns les autres aux documents de bureau cryptés partagés):
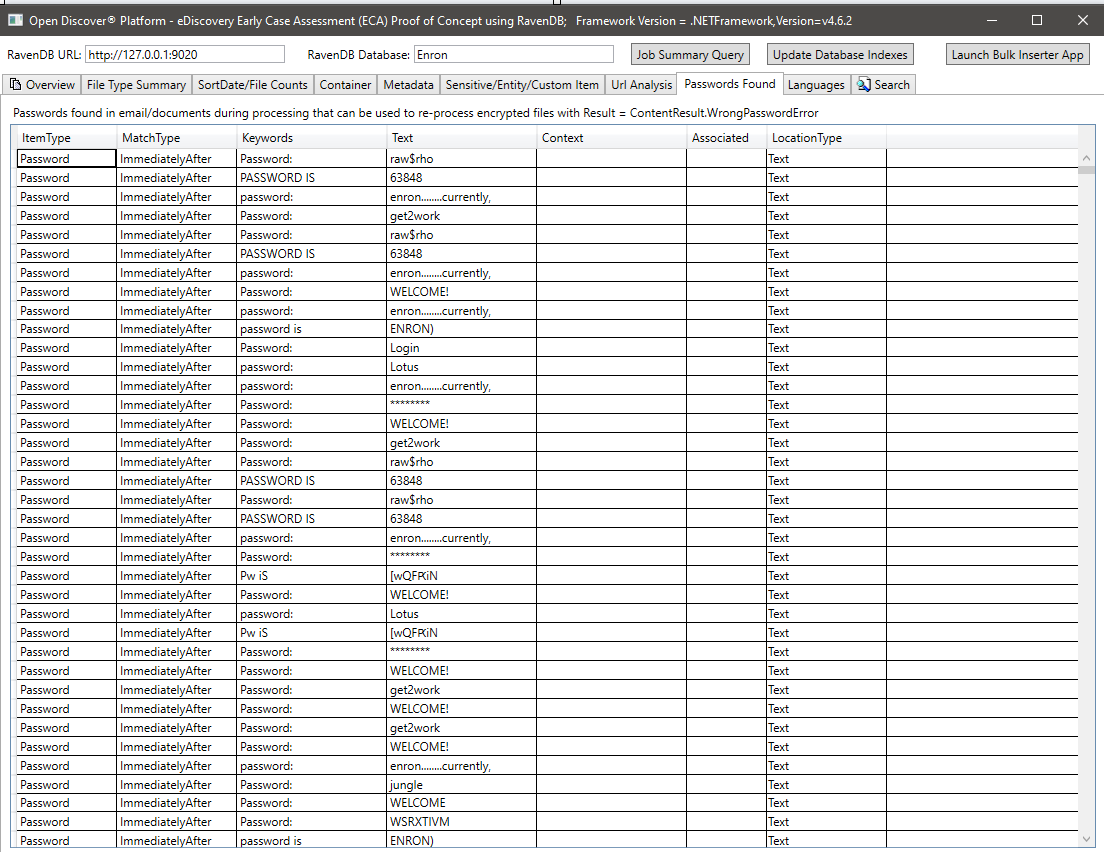
Résumé des langues détectées dans le texte extrait des documents traités:
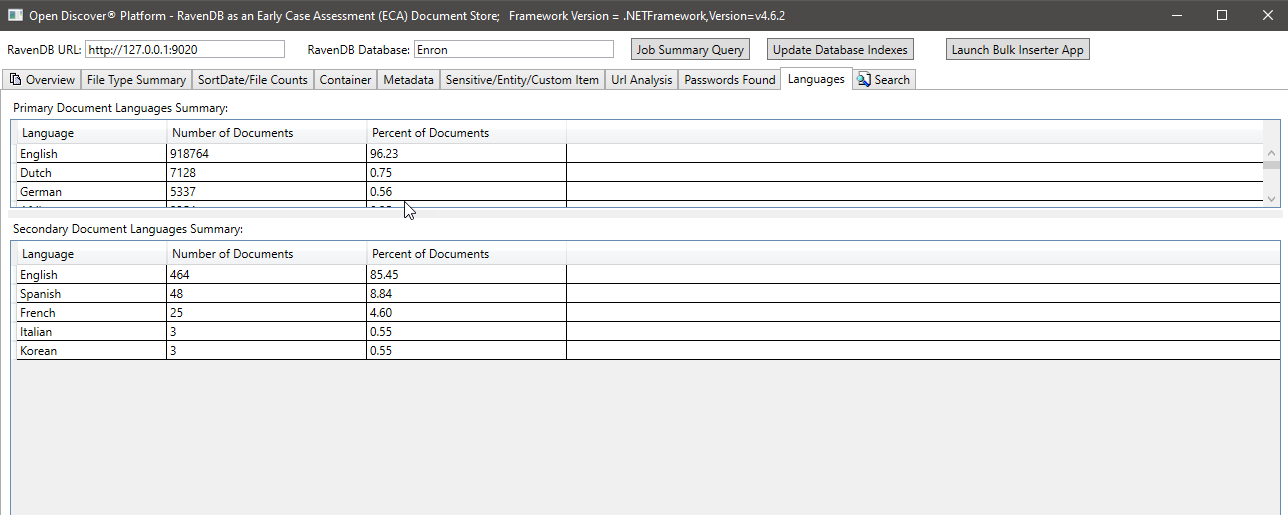
Exemple Recherche de recherche en texte intégral (Remarque: RavendB prend en charge les requêtes Lucene):
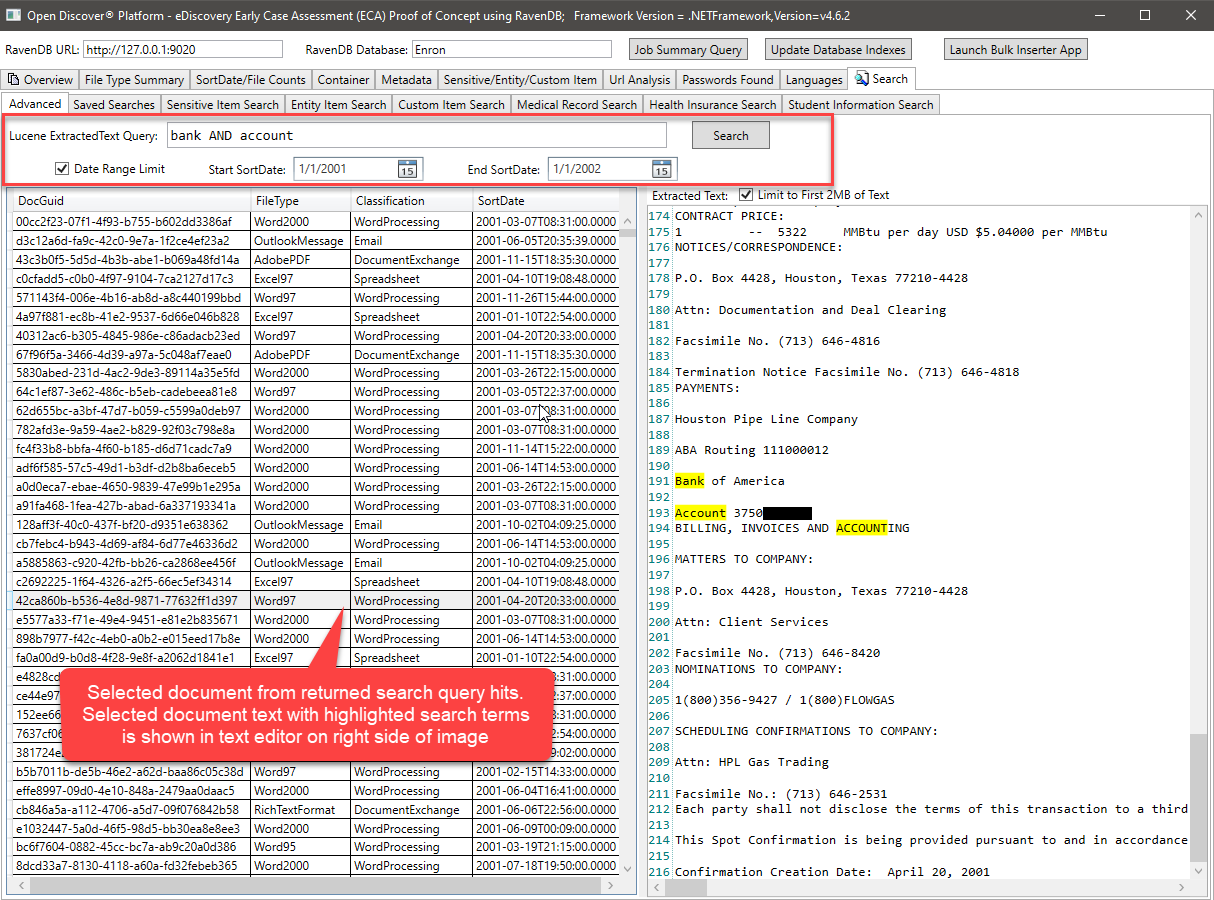
La requête Lucene ci-dessus, interroge le champ ExtraittedText et utilise (éventuellement) le document min / max sortDate pour filtrer les résultats de recherche retournés. Il serait très facile d'ajouter également le filtrage des résultats par document de base de type FileType ou de format de document (procédure de mots / feuille de calcul / e-mail / etc.). Le code C # qui effectue la requête Lucene ressemble à ceci:
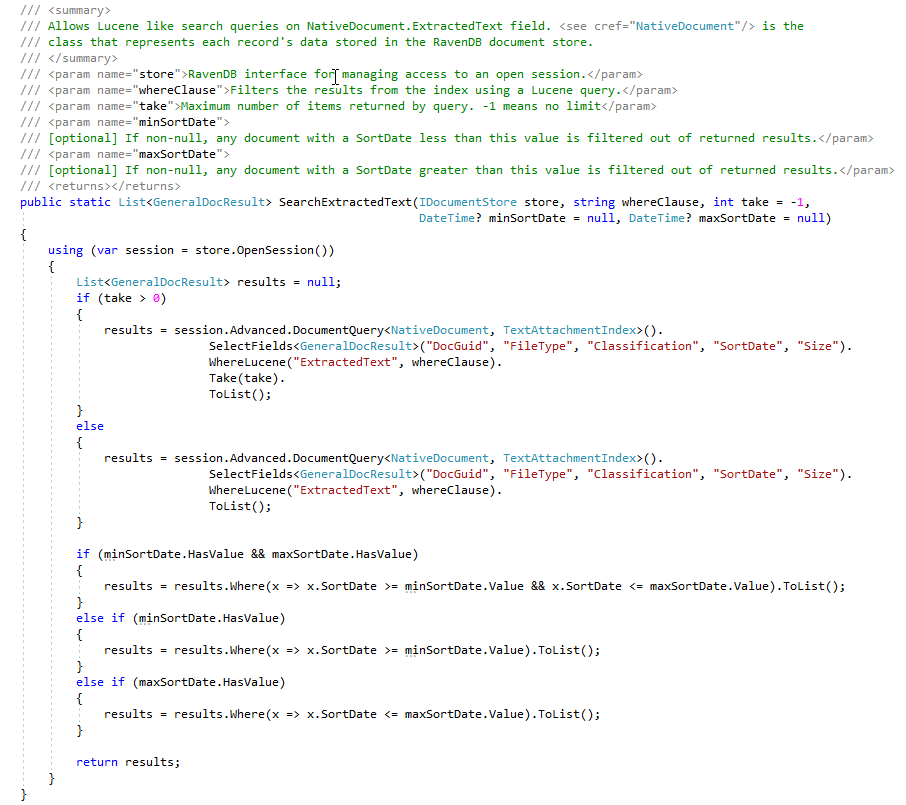
Pendant la phase ECA, les avocats de l'examen juridique aiment créer de nombreuses requêtes de recherche différentes pour trouver des documents répondants. La capture d'écran ci-dessous montre quelques requêtes Lucene enregistrées et les résultats (nombre de coups de document et taille totale des documents). Notez que le nombre de documents dans ces recherches créées par l'utilisateur contient des comptes de documents en double, bien que nous ayons des index RavendB qui comptent le nombre de documents en double, pour cette preuve de concept, nous n'avons pas encore des documents "marqués" dans le magasin de documents avec un indicateur indiquant Master / Duplicate (il s'agit d'un "to" par utilisateur):
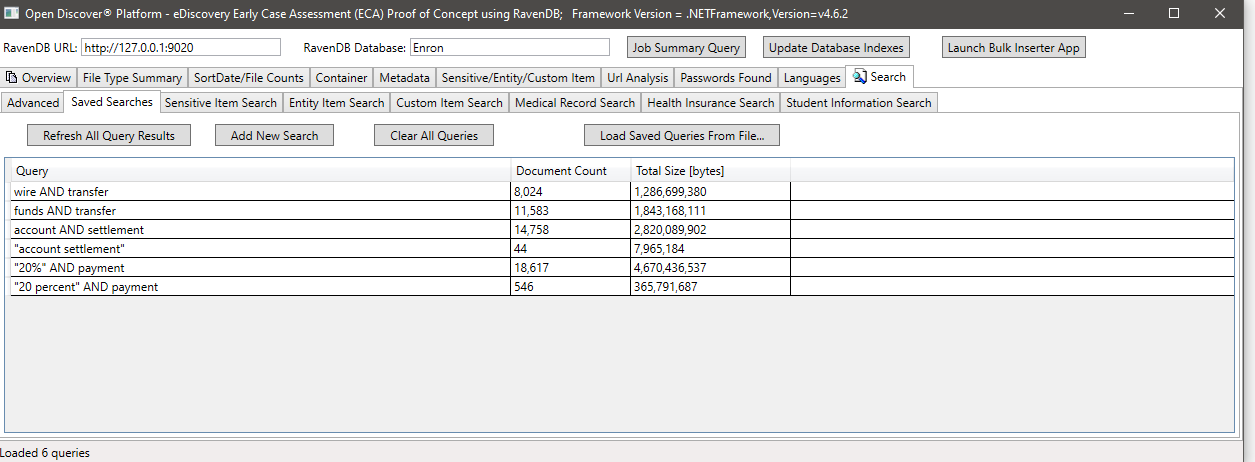
Exemple de recherche par SensitiveItemType (une propriété sur des objets SensitiveItem détectés qui identifie le type d'élément sensible), dans cet exemple, nous recherchons tous les documents qui ont un élément sensible de type SensitiveItemType.BankAccount:
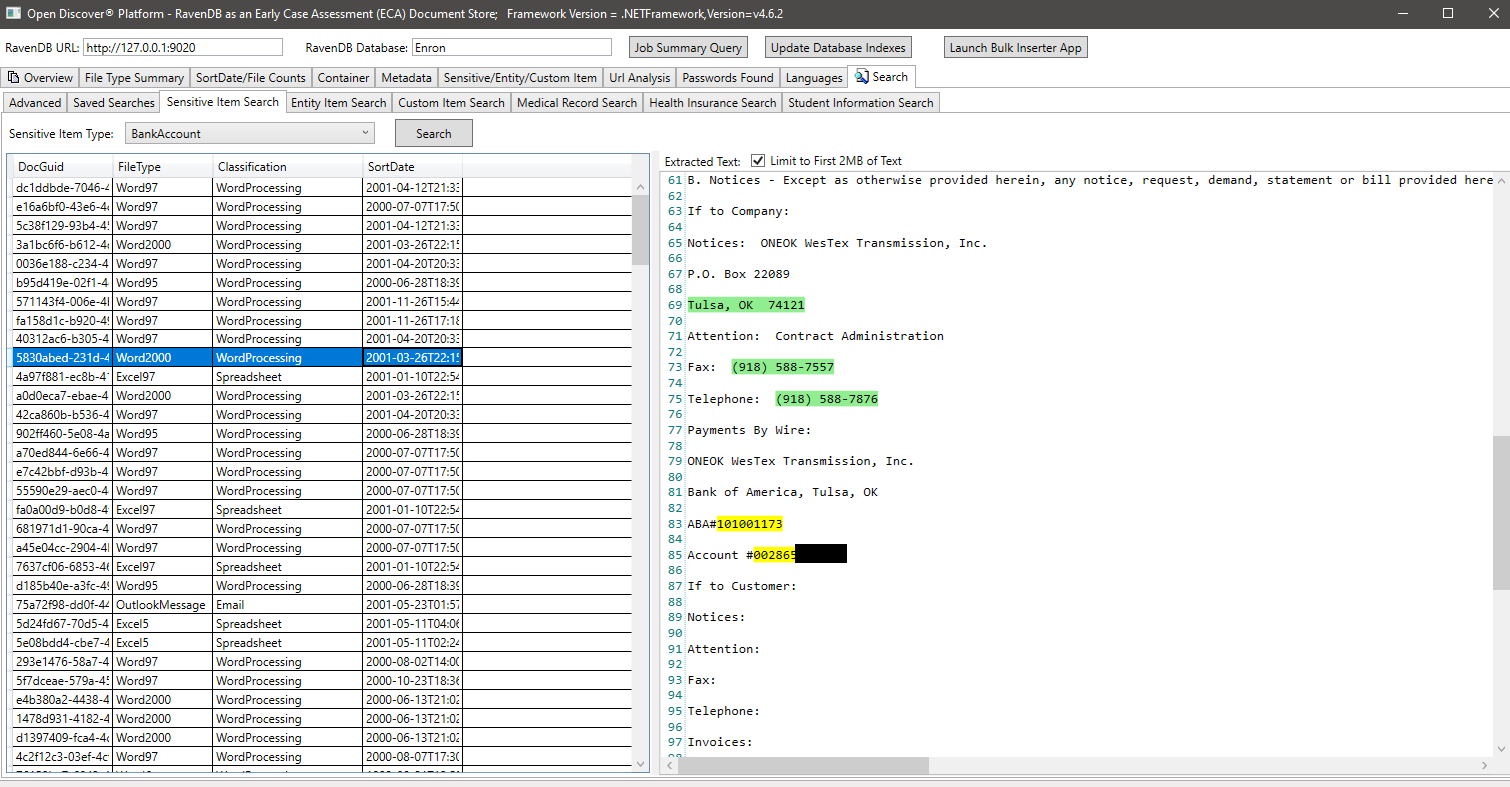
Exemple de recherche par EntityItemType (une propriété sur des objets entityItem détectés qui identifie le type d'élément d'entité), dans cet exemple, nous recherchons tous les documents qui ont un élément d'entité de type entityItemType.patientNameEntry:
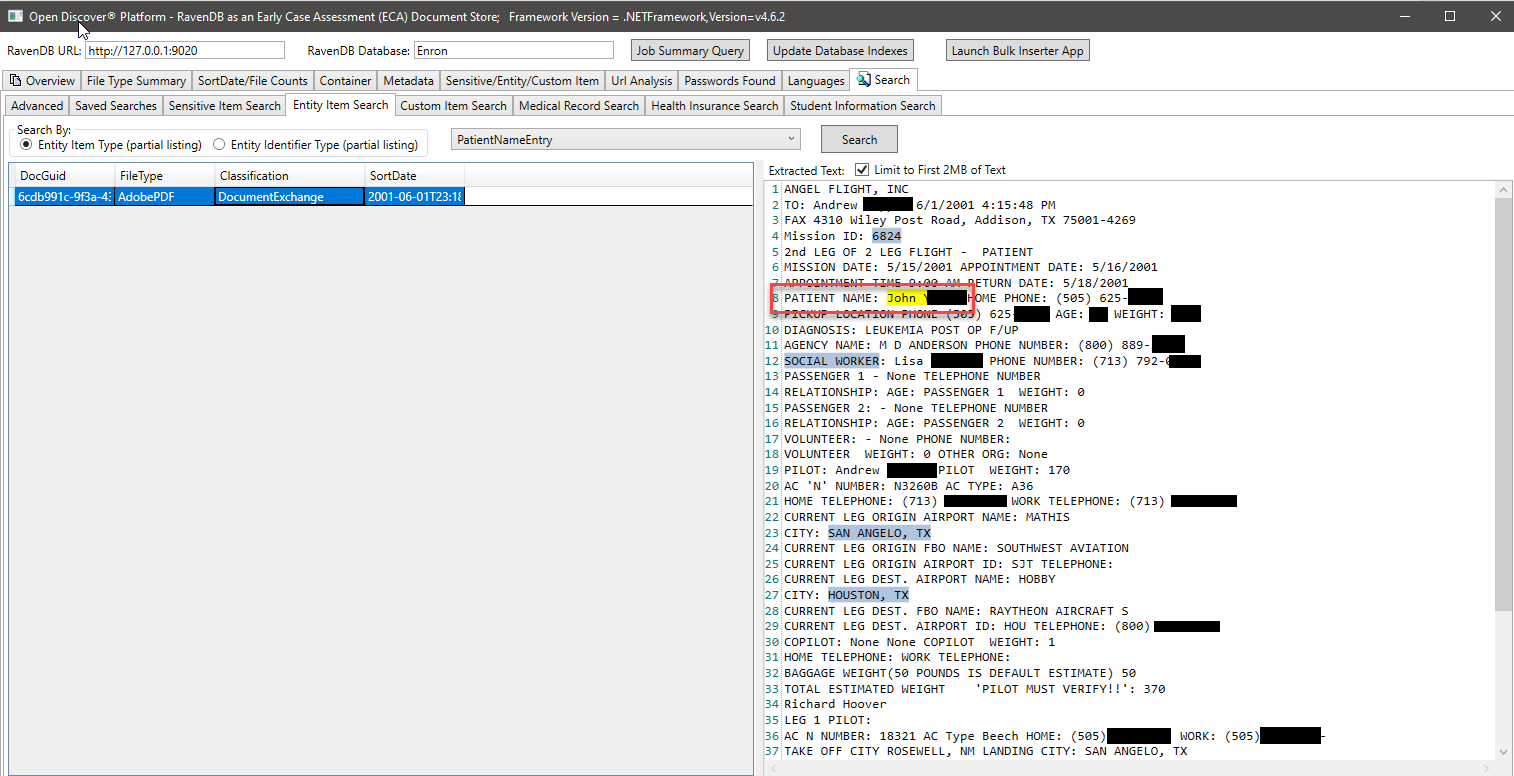
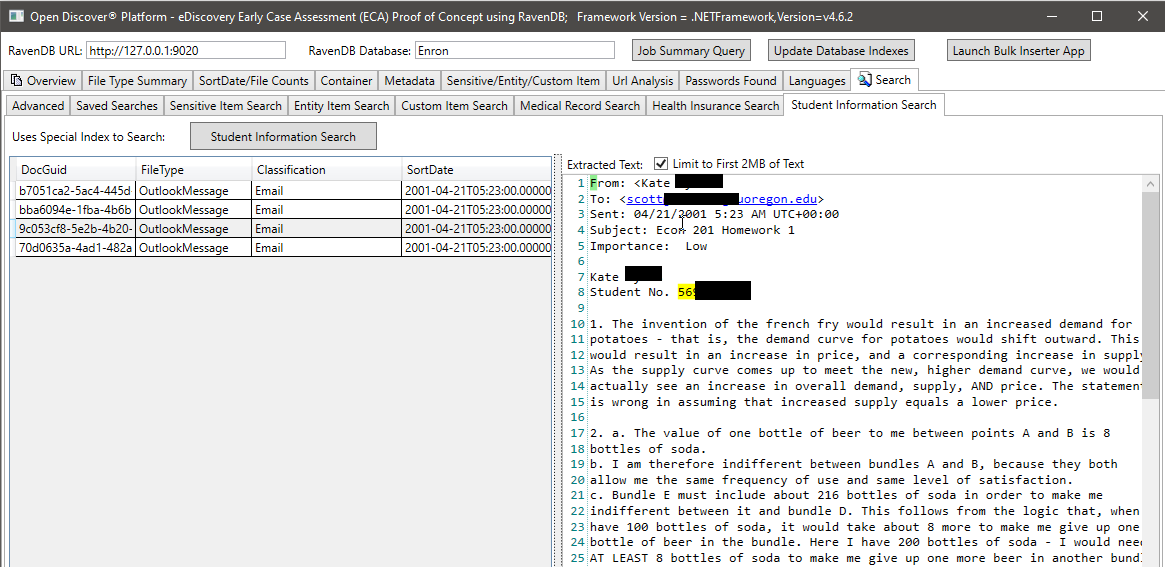
Dans la capture d'écran ci-dessous, nous utilisons un index RavendB spécialement créé qui index des types d'entités extraits SDK Open Discover liés aux informations des étudiants pour trouver des documents qui peuvent avoir des informations sur les élèves (dans la capture d'écran, le nom de l'étudiant et l'identification des étudiants sont évanouis, l'identification de l'étudiant semble être un numéro de sécurité sociale qui était commun avant les années 2000). De même, nous avons d'autres index spéciaux pour rechercher des dossiers médicaux et des informations sur les patients:
La sortie de la plate-forme Open Discover® stockée dans une base de données de documents telle que RavendB peut conduire à des applications ECCA (Early Case Assessment) très puissantes et rapidement développées. De plus, des applications telles que les éléments suivantes peuvent également être développées rapidement:
Si cette étude de cas avait utilisé une base de données relationnelle au lieu d'une base de données de documents telle que RavendB, il aurait fallu des mois de conception de schéma de base de données et de développement de procédures de magasin et non les 2 semaines, il a fallu à l'auteur pour développer cette preuve de concept d'évaluation des cas précoces (ECA).


