OpenDiscoverPlatformCaseStudy
1.0.0
Lihat Buka Discover® SDK untuk .NET Contoh Repositori GitHub
Sebuah instance tunggal dari Open Discover Platform API biasanya mampu memproses set dokumen pada 40-70 GB/Hour Rate* (* tarif akan tergantung pada perangkat keras pengguna dan jenis file dalam dataset). Sangat cepat dalam memproses dokumen sambil juga mengekstraksi lebih banyak konten daripada kebanyakan perangkat lunak eDiscovery (misalnya, deteksi item/entitas sensitif dan de-nist-ing saat diproses). Aplikasi Demo API Platform Temukan Open, PlatformApidemo.exe, digunakan untuk memproses dataset PST Enron Outlook. Aplikasi Demo PlatformApidemo.exe membungkus satu contoh kelas pemrosesan dokumen API platform. Layar bidikan contoh output pemrosesan platformapidemo.exe ditampilkan di bagian berikutnya di bawah ini.
PlatformApidemo.exe didistribusikan dengan evaluasi platform Discover terbuka bersama dengan:
Dalam tes kinerja baru-baru ini, Discover SDK Open memproses dataset PST 53 GB Enron Microsoft Outlook dan Bulk memasukkan output API platform (teks/metadata/sensitif (PXI) item/dll) ke dalam RavendB dalam sedikit lebih dari 30 menit menggunakan PC Desktop Windows Desktop 4-core tunggal.
** Tingkat pemrosesan studi kasus ini adalah untuk versi .NET 4.62 dari SDK, versi .NET 6 baru adalah> 100% lebih cepat lebih cepat, semua tugas pemrosesan PST pada laju dataskara yang lebih baik dalam jumlah yang lebih baik (berdasarkan pada ukuran pst -task. PC desktop tunggal dengan Intel I7 CPU dan 16GB RAM).
Bidikan layar di bawah ini menunjukkan item email (dan lampirannya) yang diekstraksi dari wadah PST Outlook dan diproses oleh aplikasi PlatformApidemo.exe. Email tersebut berasal dari salah satu PST Enron Microsoft Outlook. Kontrol tampilan pohon di sisi kiri gambar menunjukkan hierarki orang tua/anak dari semua dokumen/wadah yang diproses, dan mengklik item dalam kontrol pohon akan menunjukkan konten yang diekstraksi. Untuk item email Outlook yang dipilih dalam tampilan pohon, kita dapat melihat bahwa ia memiliki dokumen kata kantor 6 ms sebagai lampiran yang diekstraksi dari email. Masing -masing dan setiap item lampiran/tertanam juga memiliki kontennya yang diekstraksi (memproses sepenuhnya membuka gulungan hierarki anak orang tua, tidak peduli seberapa rumit). Perhatikan hasil identifikasi format file, "sortDate" yang dihitung, berbagai hash dokumen, metadata yang diekstraksi, dan item tab lainnya di sisi kanan atas gambar yang berisi konten lain yang diekstraksi:
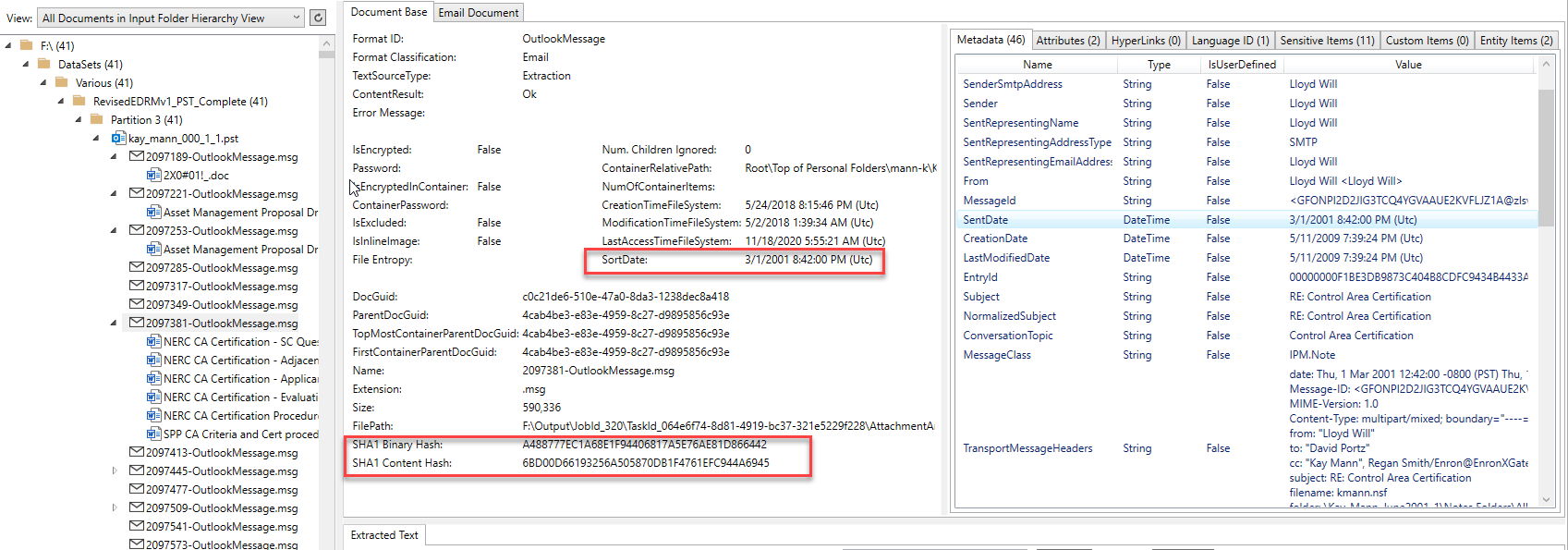
Konten spesifik email seperti semua penerima dan hash ekstra:
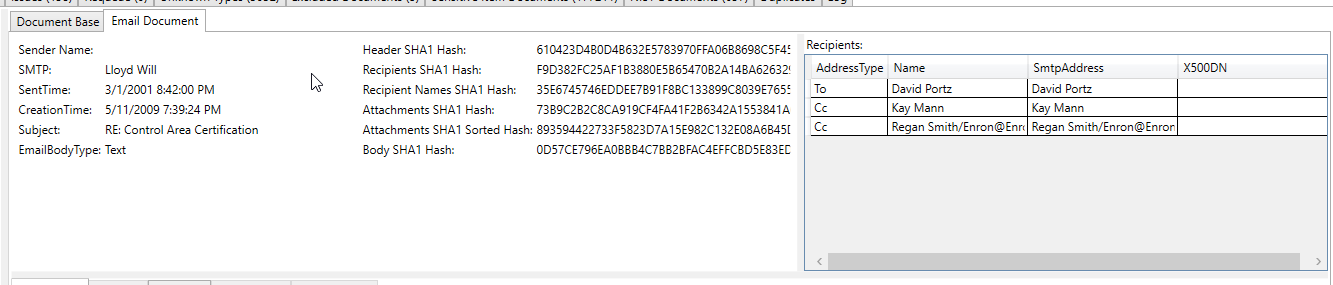
Bidikan layar email yang diproses ini menunjukkan nomor rekening bank yang diekstraksi/diidentifikasi sebagai "item sensitif" dalam teks yang diekstraksi email (semua teks yang diekstraksi dan semua metadata dipindai untuk item sensitif):
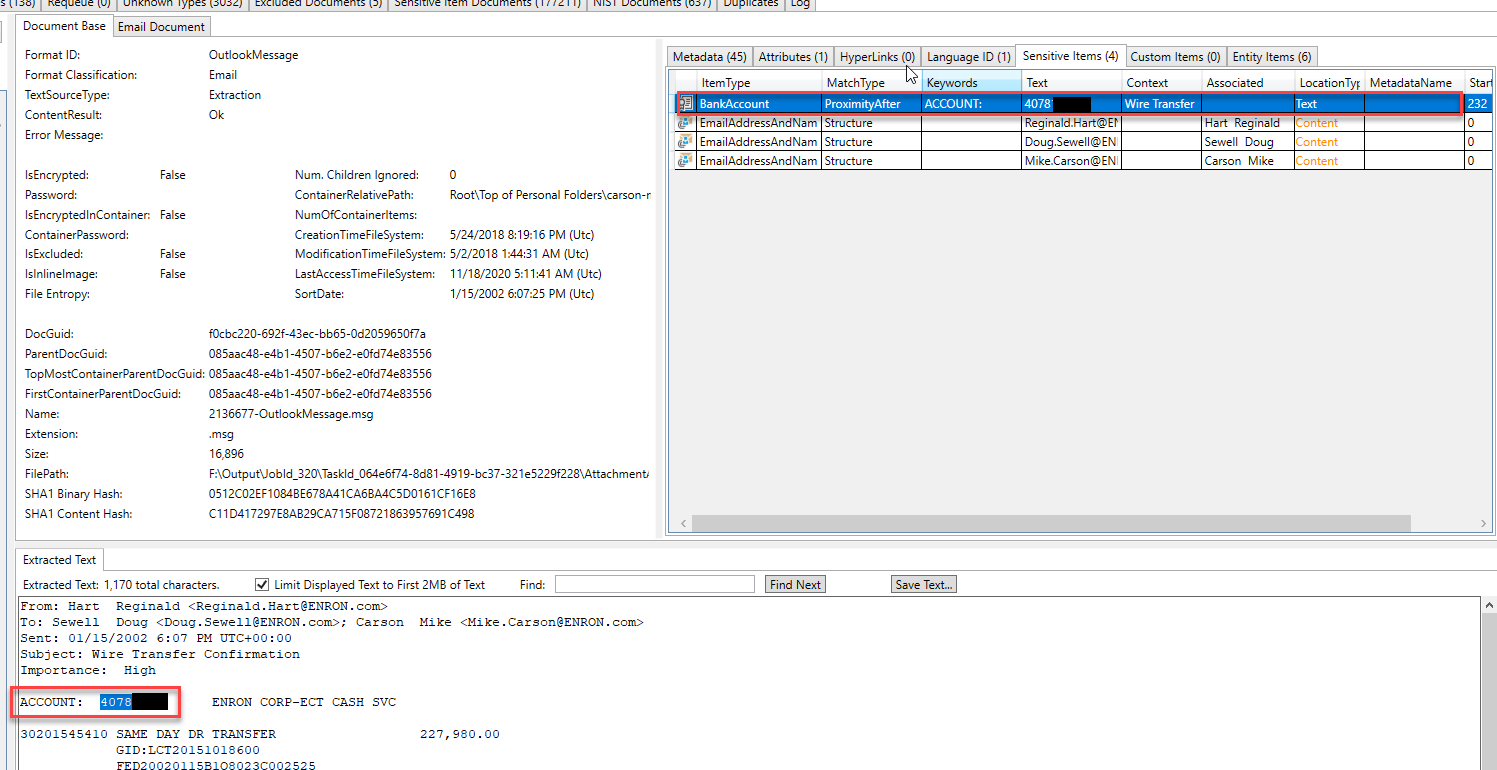
Beberapa "entitas" diidentifikasi dan diekstraksi dalam email yang berbeda. Dengan memeriksa jenis entitas yang ditemukan dalam email ini, kami dapat menduga bahwa email tersebut membahas masalah hukum:
Bidikan layar di bawah ini menunjukkan database Enron di RavendB Studio yang dihuni dengan output yang diproses Platform API. Hanya beberapa bidang dokumen database yang disimpan di Ravendb yang dapat masuk ke dalam tangkapan layar, ada lebih banyak bidang. Nama kolom dengan anotasi perbatasan merah adalah koleksi objek:
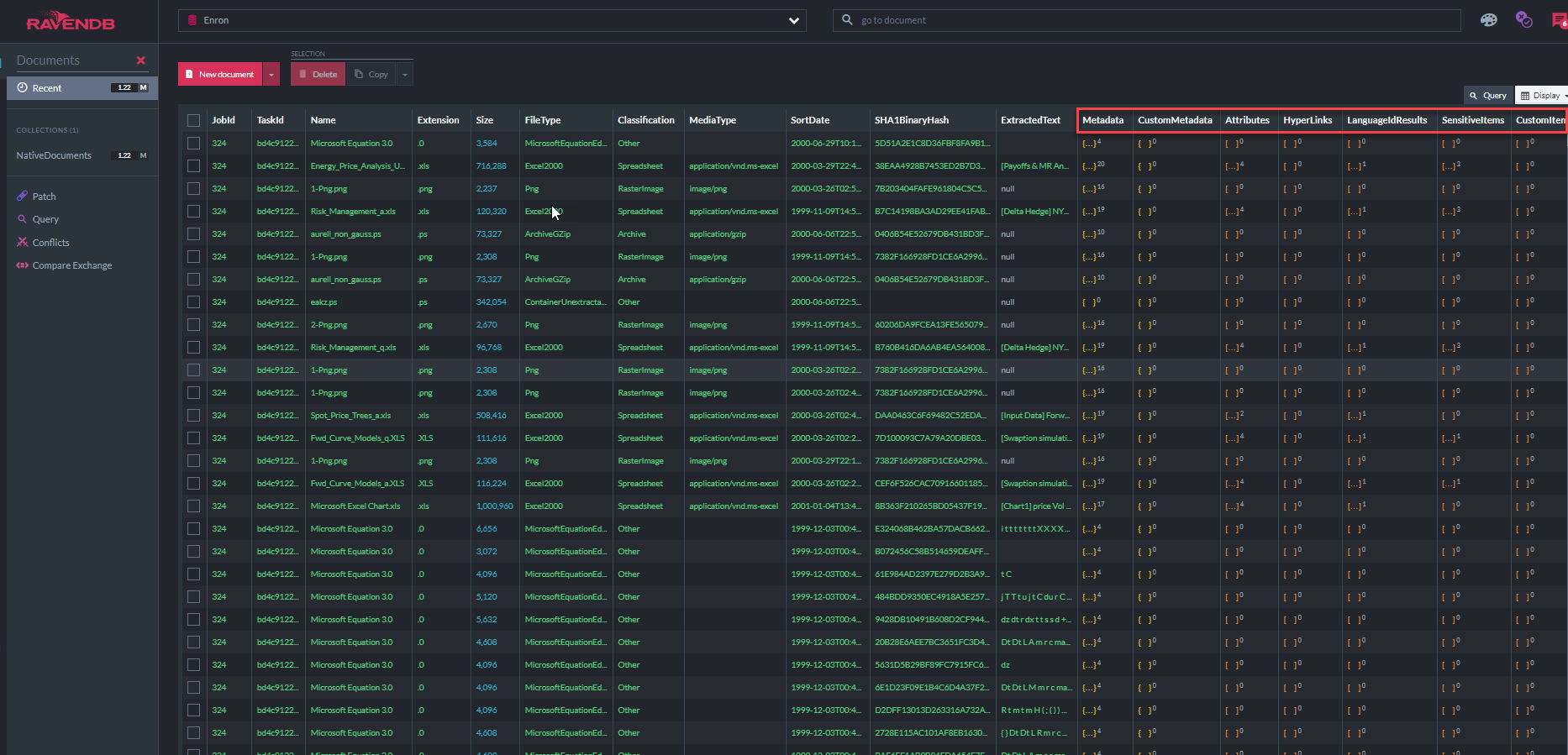
Layar di bawah ini menunjukkan beberapa dari 31 indeks RavendB yang digunakan "aplikasi demo ECA" untuk menanyakan toko dokumen (perhatikan bahwa "metadatapropertyindex" menunjukkan bahwa ada 37,7 juta properti metadata yang disimpan dalam database ini, sebagian besar metadata email, di samping semua teks yang diekstraksi):
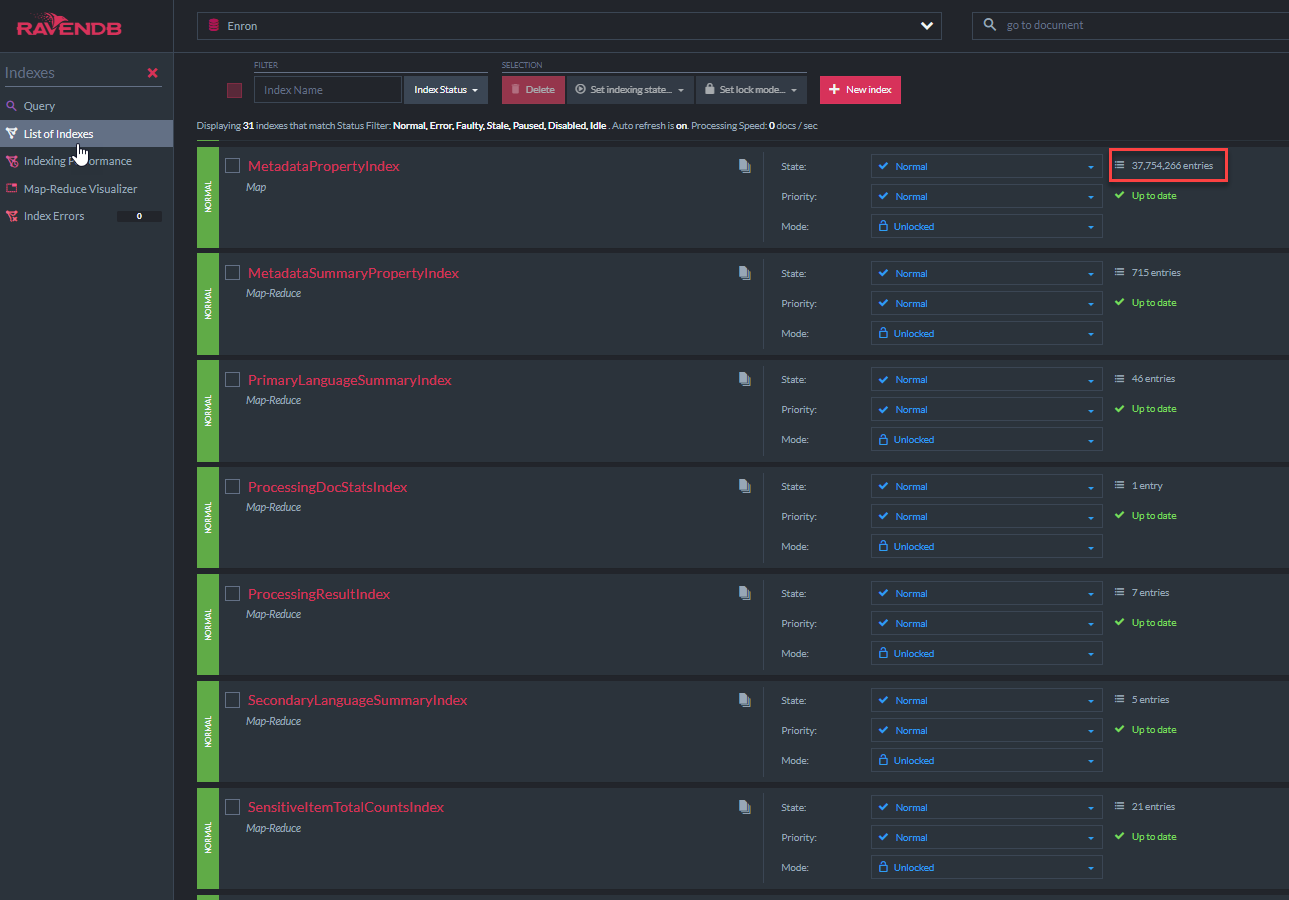
Kode kelas "MetadataPropertyIndex" C# ditampilkan di bawah ini. Kelas indeks ini berasal dari AbstractIndexCreationTask dari RavendB (seperti halnya semua indeks lainnya dalam demo ini). Indeks ini akan memungkinkan kueri Lucene 'Like' di semua bidang metadata. Indeks serupa untuk native -empel.custommetadata ada:
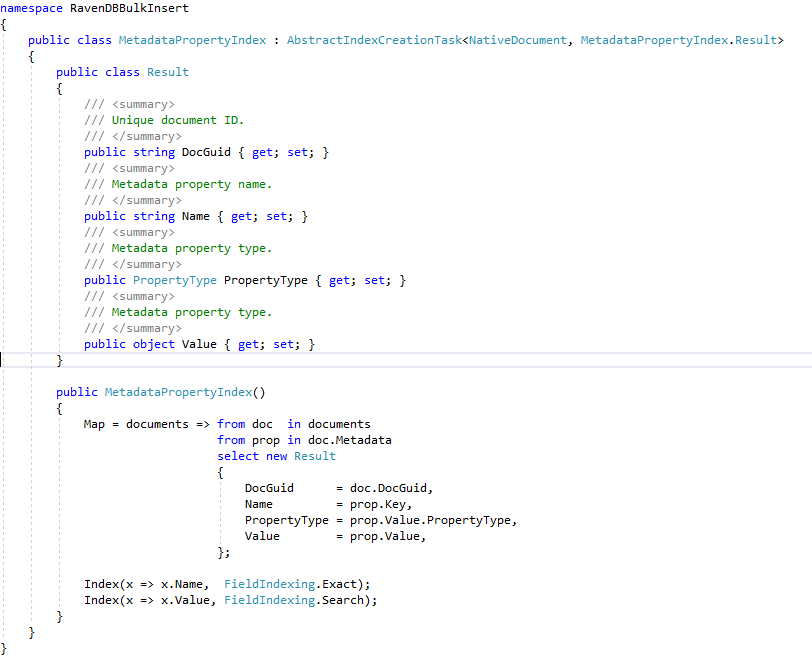
Semua indeks ravendb yang didefinisikan C# dibuat dalam database Ravendb Enron dari "Aplikasi Demo ECA" melalui panggilan API RavendB sederhana:
Bidikan layar di bawah ini menunjukkan statistik ringkasan pemrosesan dari set data 189 Microsoft Outlook PST Enron (1.221.542 email dan lampiran yang diproses secara total). Sebagian besar email dan lampiran dalam dataset ini adalah dokumen duplikat karena fakta bahwa karyawan Enron yang datanya dikumpulkan selama fase penemuan hukum saling mengirim satu sama lain - statistik deduplikasi yang ditunjukkan pada gambar di bawah ini didasarkan pada hash biner/konten, di masa depan, kami akan memperbarui studi kasus ini (bersama dengan indeks Ravendb) yang disertakan industri hukum ". Perhatikan bagan pai klasifikasi format file, ringkasan bagan pai format file tertentu, dan ringkasan hasil pemrosesan (jenis enumerasi dengan nilai -nilai bagan pai ok/salah/dataerror/etc).
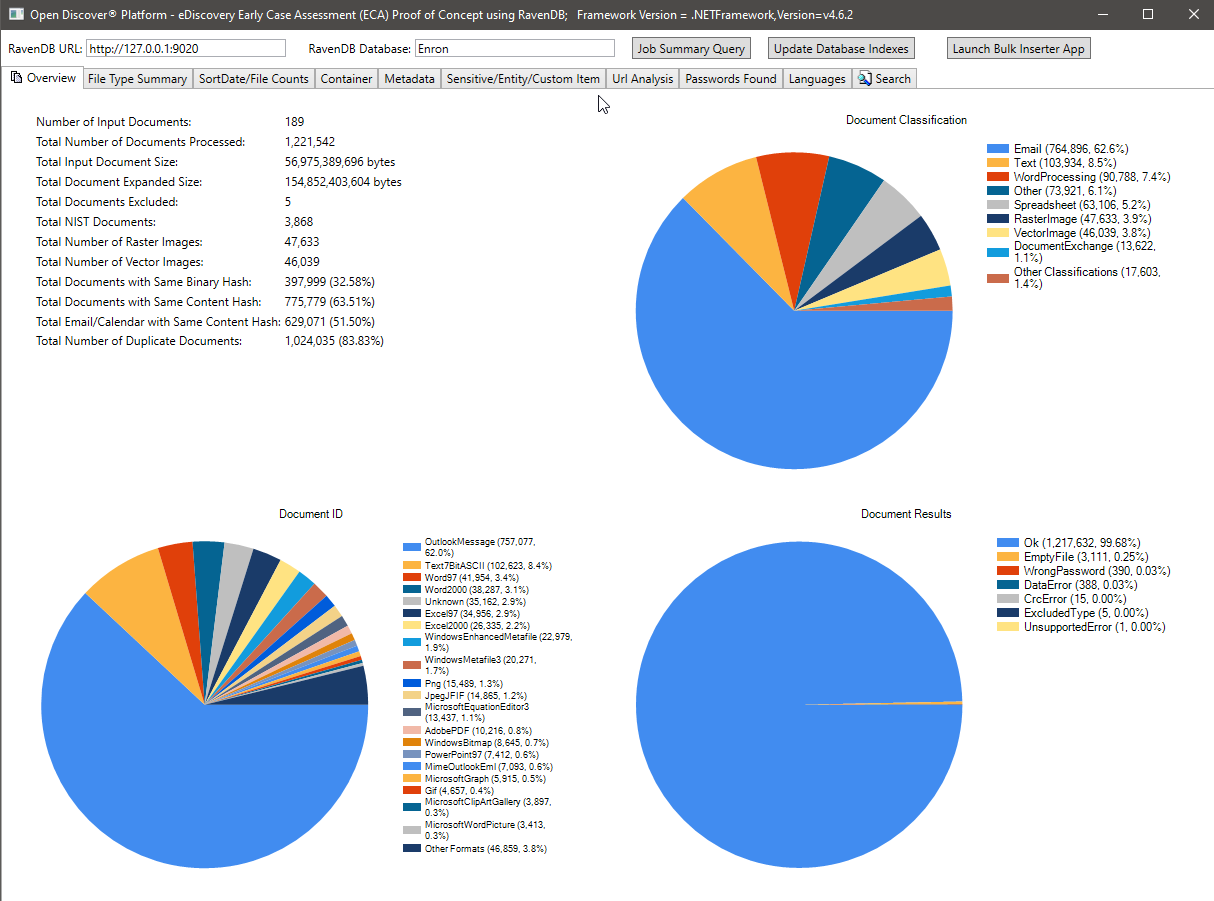
File Counts By SortDate Ringkasan Grafik:
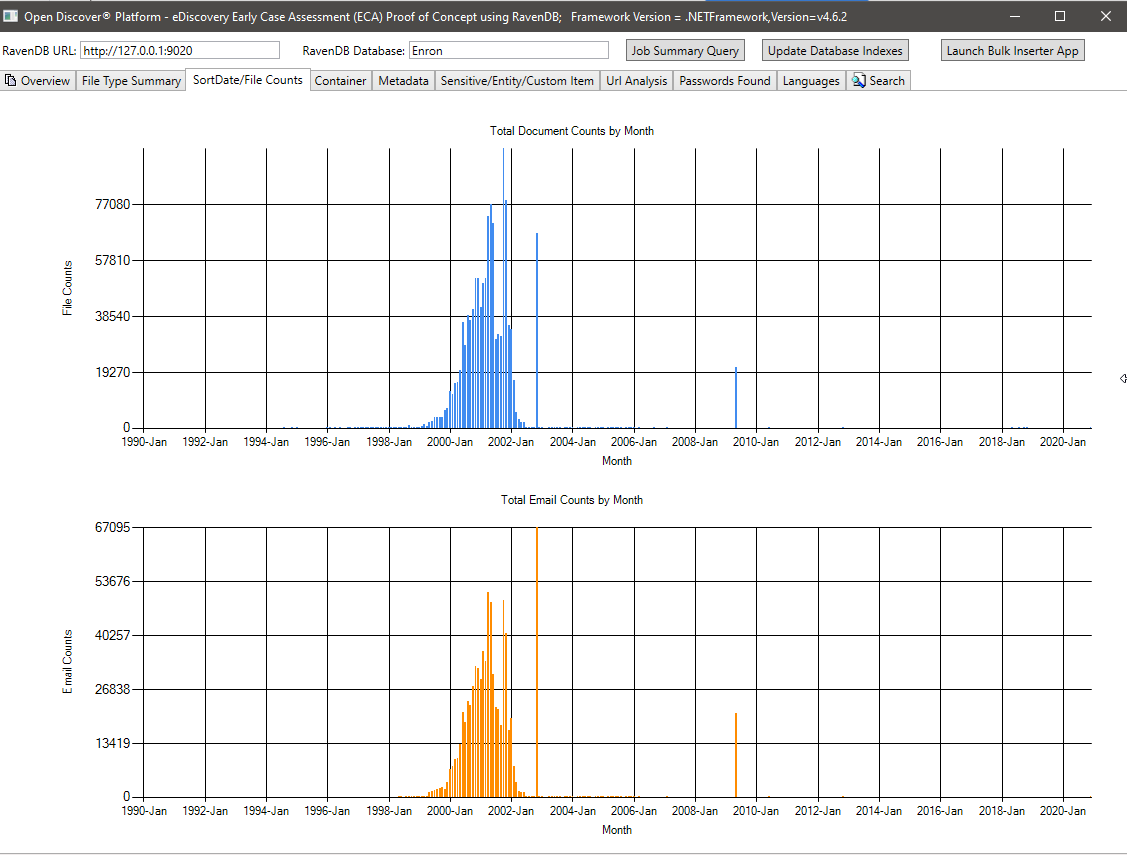
Ringkasan Metadata (Nama Bidang Metadata/Jumlah Total Dokumen) - 715 Nama Bidang Metadata Unik yang Dikenal Di Semua Dokumen dan 636 Bidang Metadata Kustom (Definisi Pengguna). Kueri ini dapat membantu manajer kasus hukum mengetahui bidang metadata apa yang tersedia dalam koleksi untuk dicari:
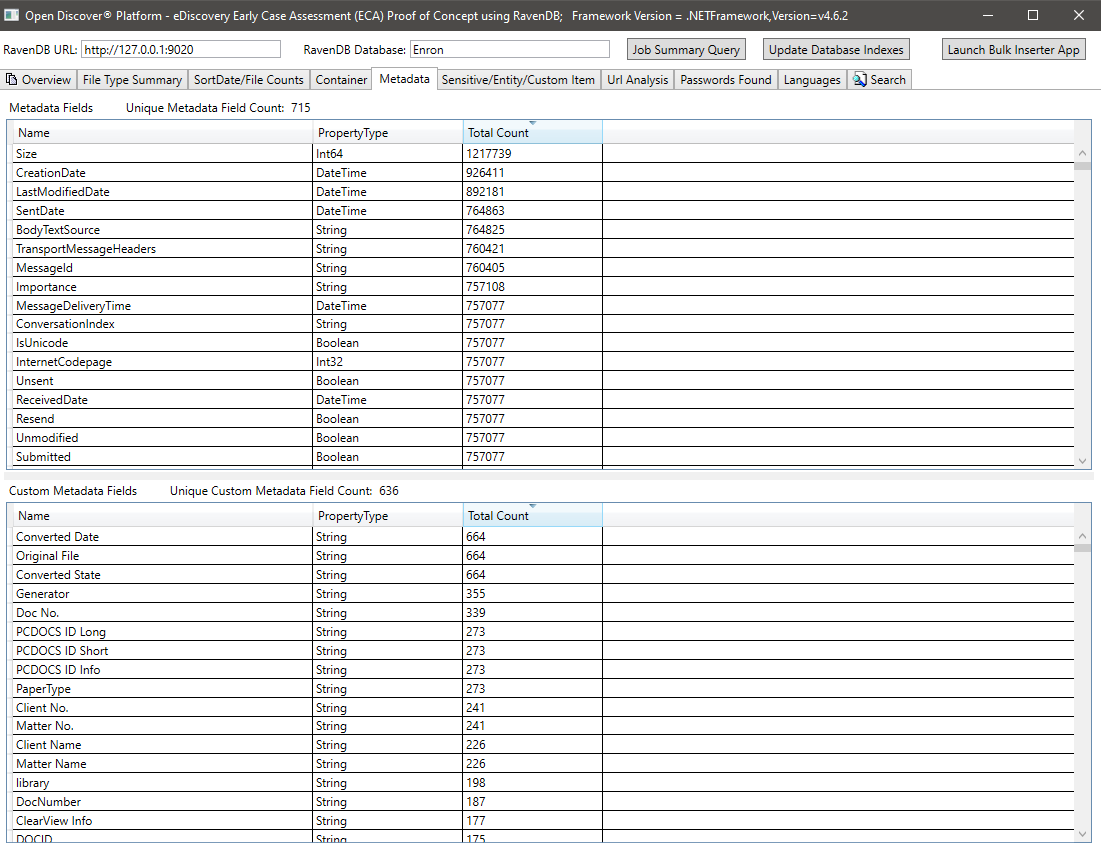
Ringkasan Item/Entitas Sensitif untuk semua dokumen:
Ringkasan semua URL unik yang ditemukan di semua dokumen (URL dari setiap dokumen mungkin berguna, misalnya, jika perusahaan ingin melacak potensi titik masuk URL berbahaya). Buka Temukan SDK mendeteksi semua URL dari hyperlink dokumen dan dalam teks dokumen (yaitu, non-hyperlink):
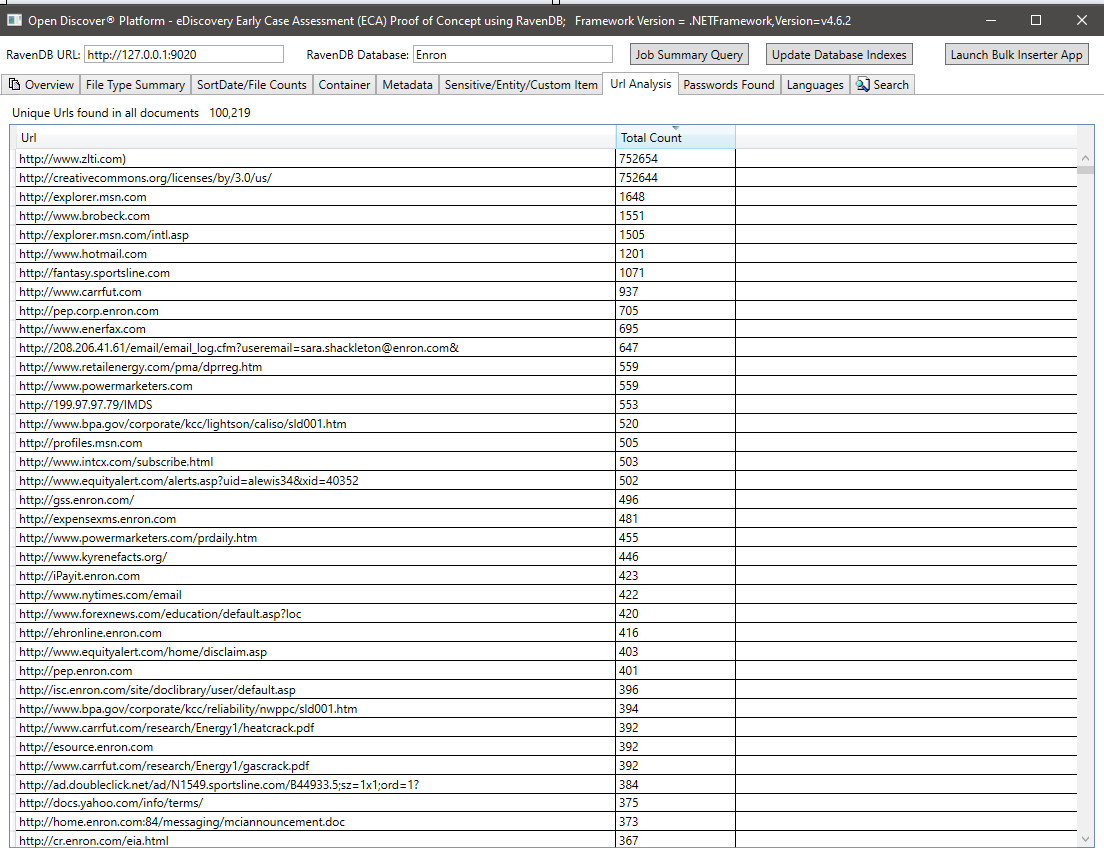
Ringkasan semua kata sandi yang ditemukan di semua dokumen. Kata sandi dan nama pengguna hanya 2 dari 25 tipe 'item sensitif' bawaan yang didukung oleh Open Discover SDK/Platform. Kredensial kata sandi/nama pengguna dalam dokumen dapat berupa risiko keamanan, mereka juga dapat digunakan untuk mempromosikan kembali dokumen apa pun yang memiliki hasil pemrosesan dari 'WrongPassword' (karena karyawan di perusahaan yang sama sering mengirim satu sama lain kata sandi ke dokumen kantor terenkripsi yang dibagikan):
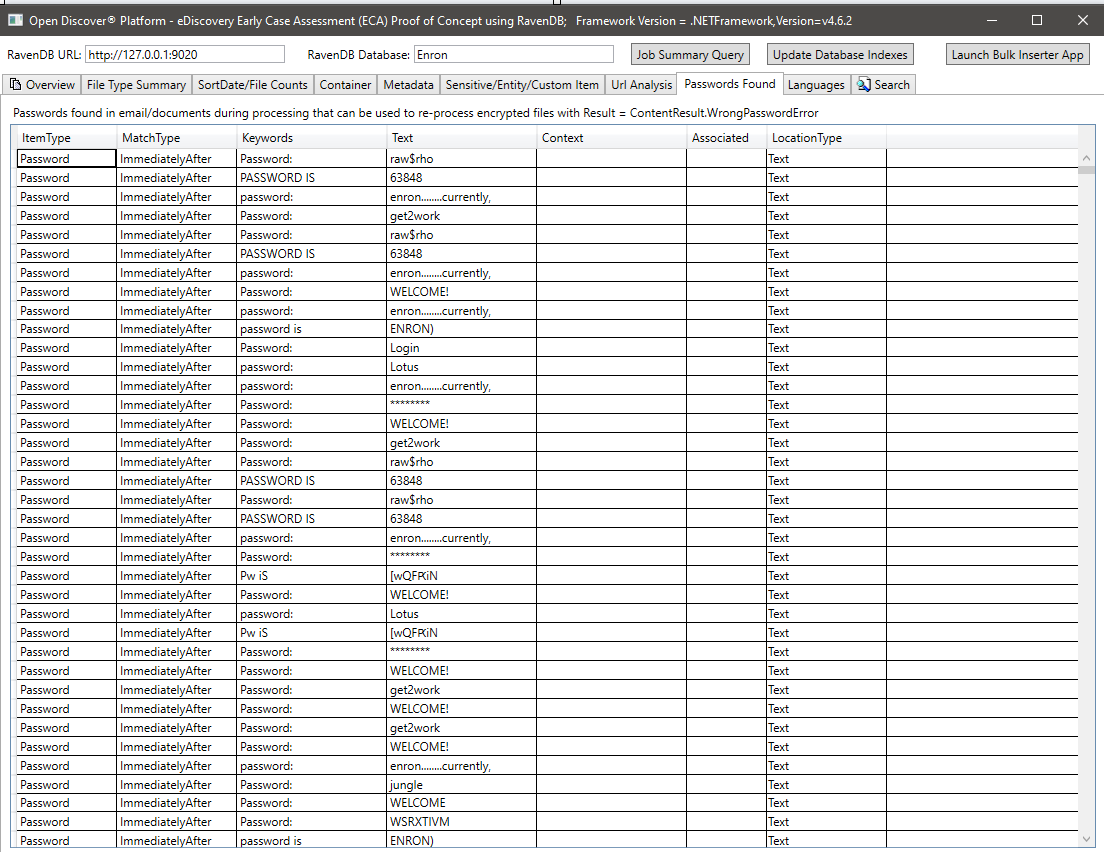
Ringkasan bahasa yang terdeteksi dalam teks yang diekstraksi dari dokumen yang diproses:
Contoh permintaan pencarian teks lengkap (Catatan: Ravendb mendukung kueri Lucene):
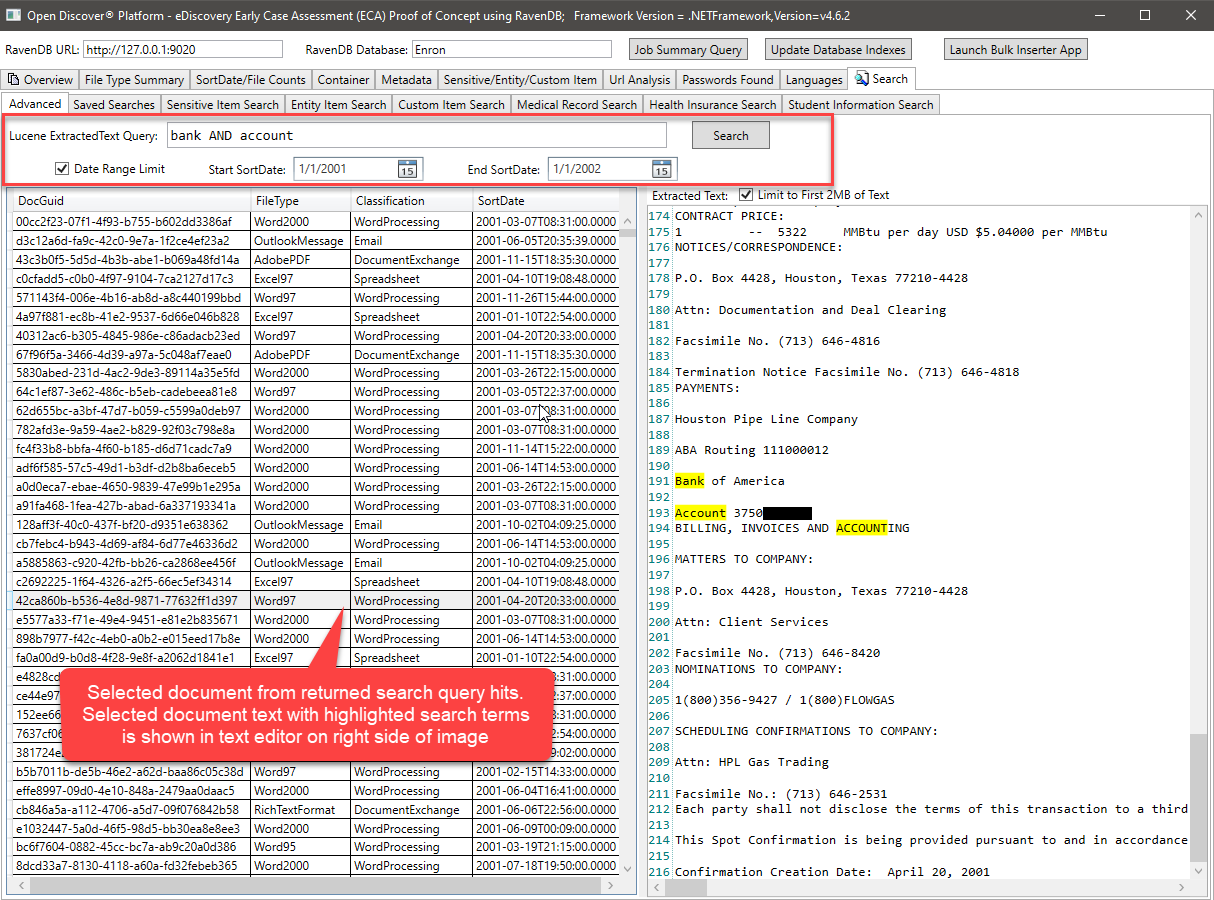
Kueri Lucene di atas, kueri bidang ExtractEdText dan menggunakan (opsional) Min/Max Document SortDate untuk memfilter hasil pencarian yang dikembalikan. Akan sangat mudah untuk juga menambahkan pemfilteran hasil dengan filetype dokumen atau klasifikasi format dokumen (WordProcessing/spreadsheet/email/dll). Kode C# yang melakukan kueri Lucene terlihat seperti ini:
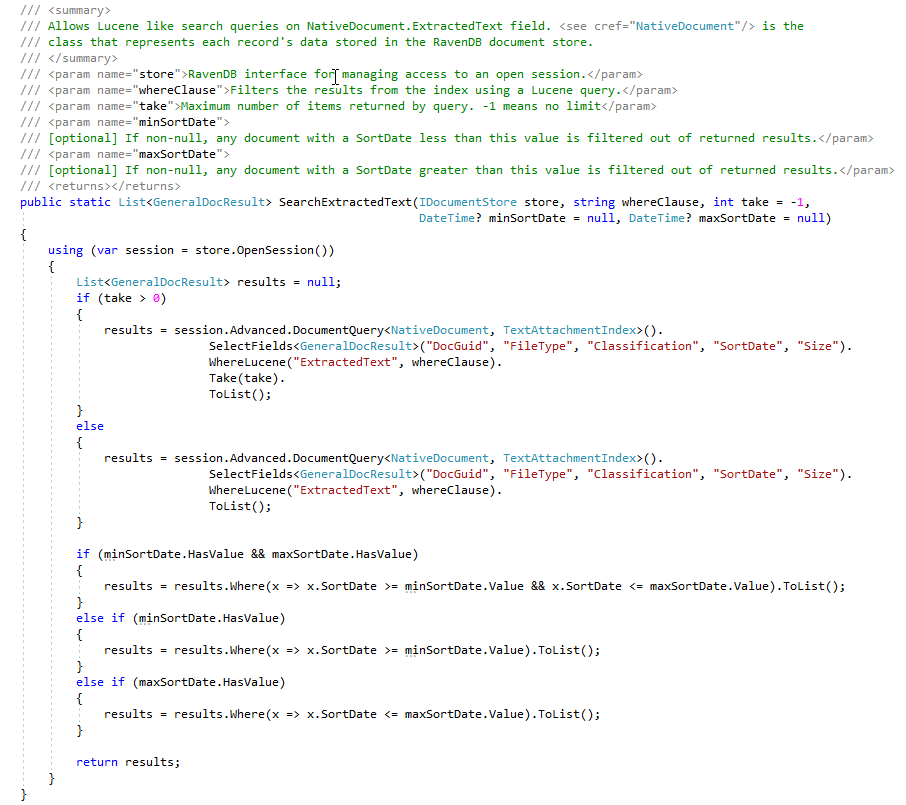
Selama fase ECA, pengacara peninjauan hukum suka membuat berbagai pertanyaan pencarian untuk menemukan dokumen yang menanggapi. Bidikan layar di bawah ini menunjukkan beberapa kueri Lucene yang disimpan dan hasilnya (jumlah hit dokumen dan ukuran total dokumen). Perhatikan bahwa dokumen yang diperhitungkan dalam pencarian yang dibuat pengguna ini berisi jumlah dokumen duplikat, meskipun kami memiliki indeks RavendB yang menghitung jumlah dokumen duplikat, untuk bukti konsep ini, kami belum "bertanda" dokumen di toko dokumen dengan bendera yang menunjukkan master/duplikat (ini adalah 'TODO' oleh pengguna):
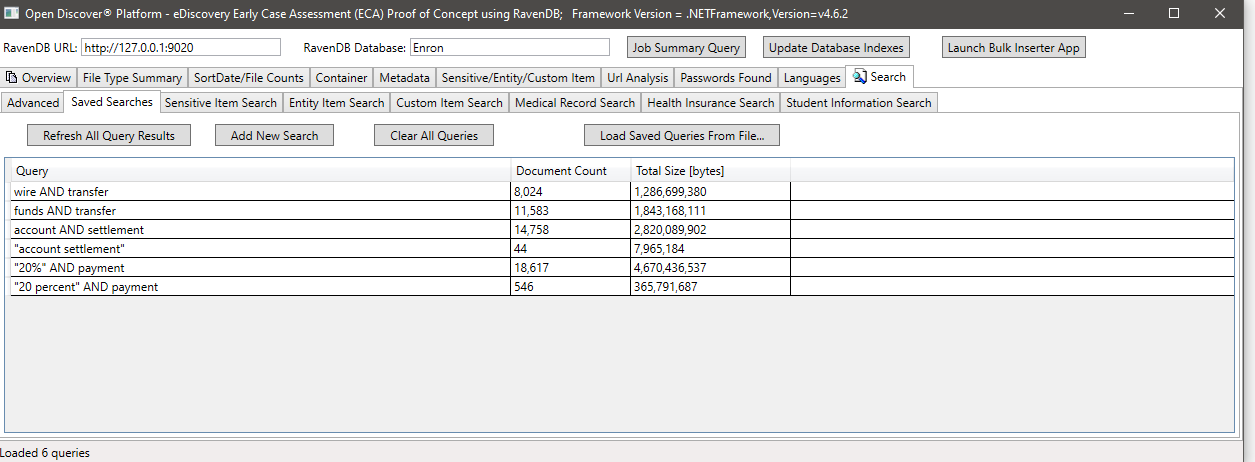
Contoh Pencarian dengan SensitiveTemType (properti pada objek SensitiveTem yang terdeteksi yang mengidentifikasi jenis item sensitif), dalam contoh ini kami mencari semua dokumen yang memiliki item sensitif tipe sensitiveTeMtype.bankAccount:
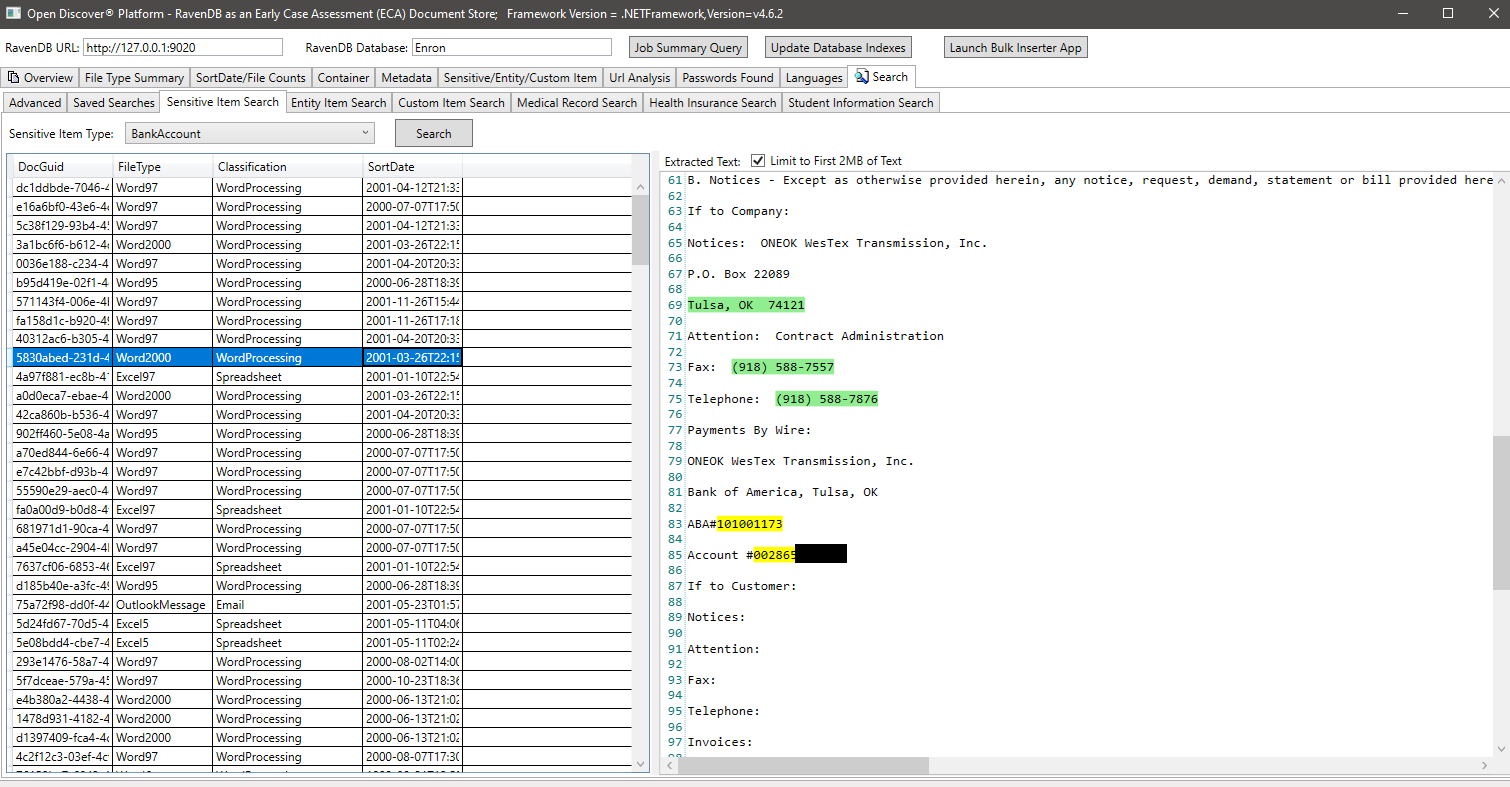
Contoh Pencarian oleh EntityItemType (properti pada objek entityitem yang terdeteksi yang mengidentifikasi jenis item entitas), dalam contoh ini kami mencari semua dokumen yang memiliki item entitas tipe entityitemType.PatientNameEntry:
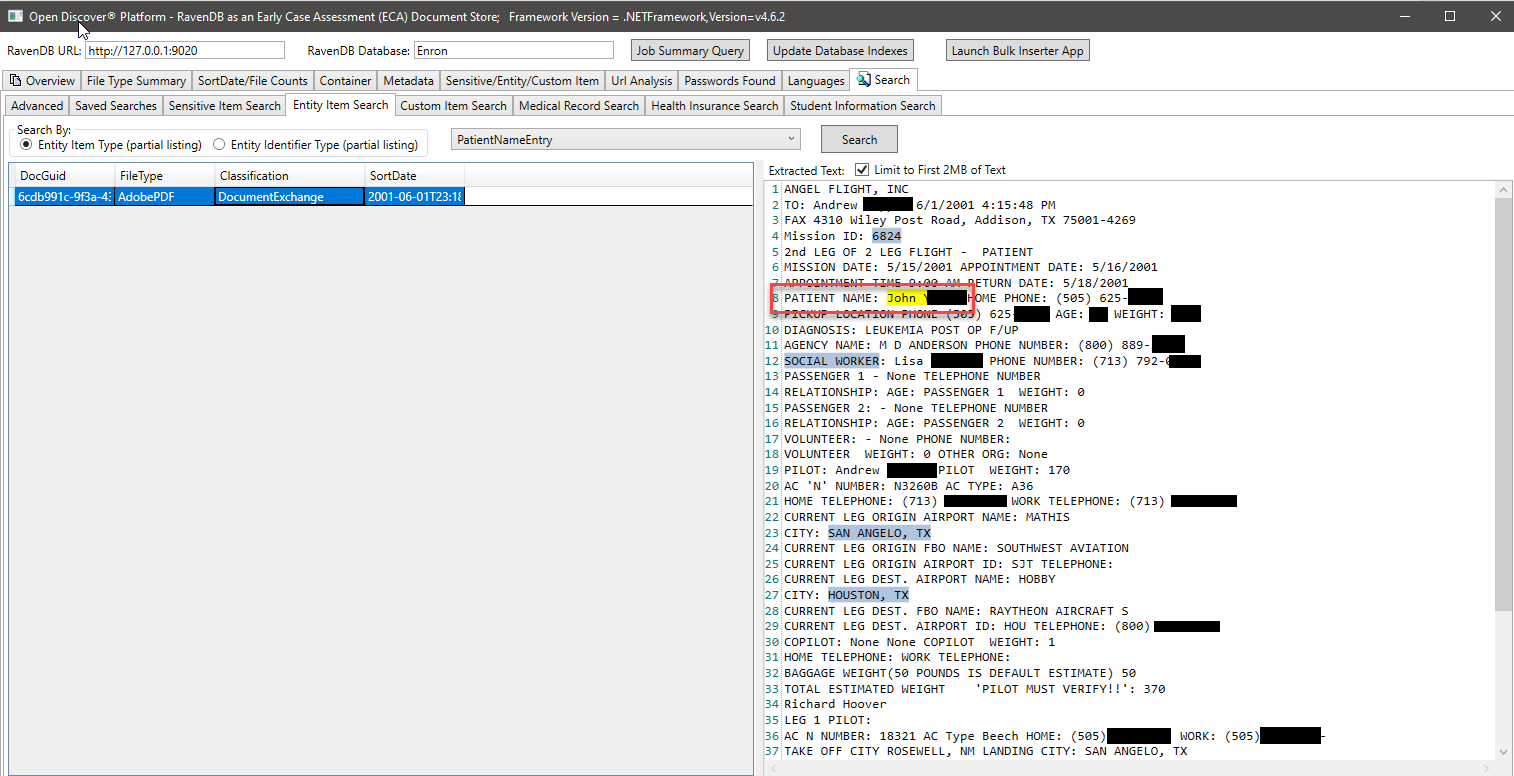
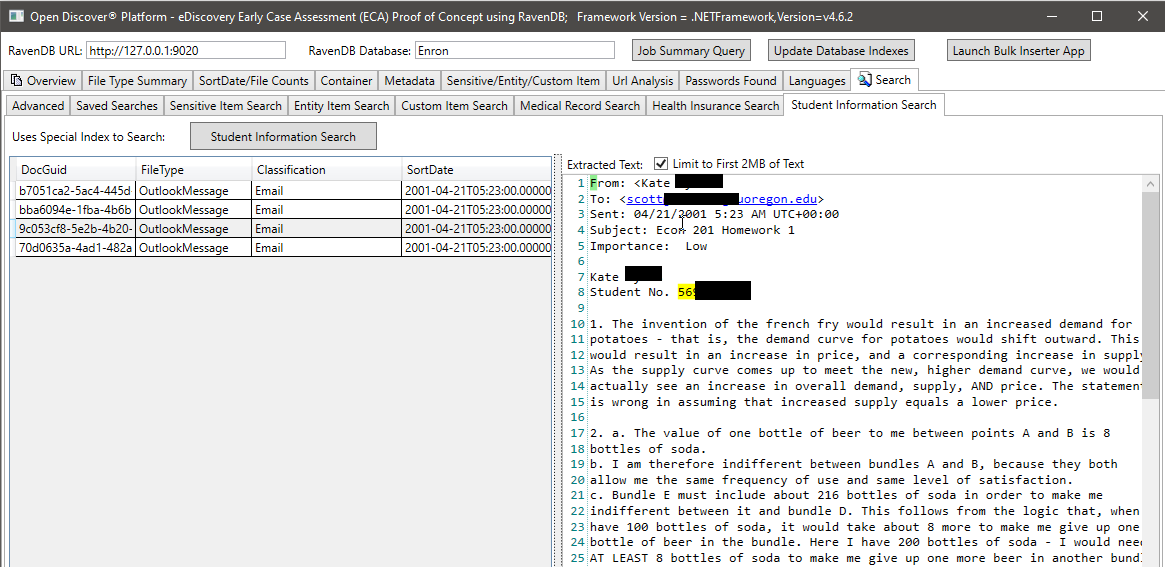
Dalam bidikan layar di bawah ini, kami menggunakan indeks RavendB yang dibuat khusus yang mengindeks spesifik Temukan Jenis Entitas yang Diekstraksi SDK Terkait dengan Informasi Siswa untuk Menemukan Dokumen yang mungkin memiliki informasi siswa (dalam bidikan layar, nama siswa dan ID siswa dihitamkan, ID siswa tampaknya menjadi nomor jaminan sosial yang umum sebelum tahun 2000 -an). Demikian juga, kami memiliki indeks khusus lainnya untuk mencari catatan medis dan informasi pasien:
Output platform Open Discover® yang disimpan dalam database dokumen seperti RavendB dapat menyebabkan aplikasi penilaian kasus awal (ECA) yang sangat kuat dan dikembangkan dengan cepat. Selain itu, aplikasi seperti berikut ini juga dapat dikembangkan dengan cepat:
Jika studi kasus ini telah menggunakan basis data relasional alih -alih database dokumen seperti RavendB, itu akan memakan waktu berbulan -bulan desain skema database dan pengembangan prosedur toko dan bukan 2 minggu dalam waktu yang dibutuhkan penulis untuk mengembangkan bukti konsep penilaian kasus awal (ECA) ini.


