OpenDiscoverPlatformCaseStudy
1.0.0
.NETの例については、GitHubリポジトリのOpenDiscover®SDKを参照してください
Open DiscoverプラットフォームAPIの単一のインスタンスは、通常、40〜70 GB/時間レートでドキュメントセットを処理できます(*レートは、データセットのユーザーハードウェアとファイルタイプに依存します)。ドキュメントの処理では非常に高速ですが、ほとんどのediscoveryソフトウェアよりも多くのコンテンツを抽出します(たとえば、処理中に敏感なアイテム/エンティティの検出とデニストング)。 Open Discover Platform API DEMOアプリケーションであるPlatformApidemo.exeを使用して、Enron Outlook PSTデータセットを処理しました。 PlatformApidemo.exeデモアプリケーションは、プラットフォームAPIドキュメント処理クラスの1つのインスタンスをラップします。 PlatformApidemo.exe処理出力の例のスクリーンショットは、以下の次のセクションに示されています。
PlatformApidemo.exeは、以下のオープンディスカバープラットフォームの評価で配布されます。
最近のパフォーマンステストでは、Open Discover SDKが53 GB Enron Microsoft Outlook PST Datasetを処理し、1つの4コアWindowsデスクトップPCを使用して30分強でプラットフォームAPI出力(テキスト/メタデータ/敏感なアイテム/など)をRavendBに挿入しました。
**このケーススタディの処理率は、.NET 4.62バージョンのSDK用でした。新しい.NET 6バージョンは平均して100%> 100%高速であり、OpenDiscoverPlatformの.NET 6バージョンのすべてのPST処理タスクは、90-100+GB/HRレートの間にPSTデータセットタスクを処理しました。 Intel I7 CPUおよび16GB RAM)。
下のスクリーンショットは、Outlook PSTコンテナから抽出され、PlatformApidemo.exeアプリケーションによって処理された電子メールアイテム(およびその添付ファイル)を示しています。このメールは、Enron Microsoft Outlook PSTSの1つからのものです。画像の左側にあるツリービューコントロールは、すべての処理されたドキュメント/コンテナの親/子階層を示しており、ツリーコントロール内のアイテムをクリックすると、抽出されたコンテンツが表示されます。ツリービューで選択したOutlookメールアイテムの場合、電子メールから抽出された添付ファイルとして6ミリ秒のOffice Wordドキュメントがあることがわかります。すべての添付ファイル/埋め込みアイテムにもコンテンツが抽出されました(処理は、どんなに複雑であっても、親子の階層を完全に展開します)。 「SORTDATE」、さまざまなドキュメントハッシュ、抽出されたメタデータ、および他の抽出されたコンテンツを含む画像の右上にあるその他のタブ項目を計算したファイル形式の識別結果に注意してください。
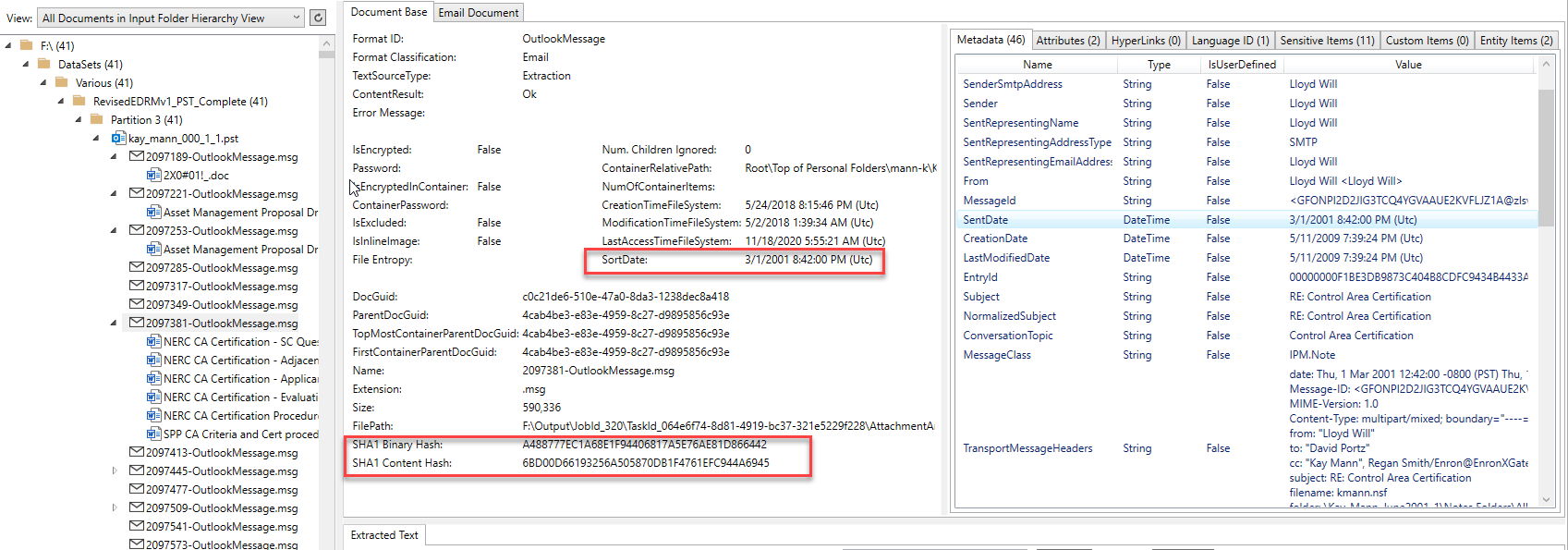
すべての受信者や追加のハッシュなどの特定のコンテンツにメールしてください:
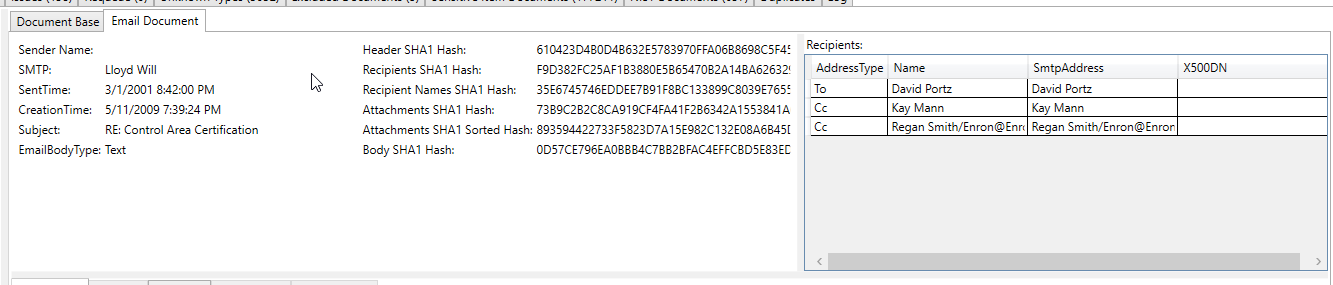
この処理された電子メールスクリーンショットは、電子メールの抽出されたテキストで「敏感なアイテム」として抽出/識別された銀行口座番号を示しています(すべての抽出されたテキストとすべてのメタデータは、敏感なアイテムのためにスキャンされます):
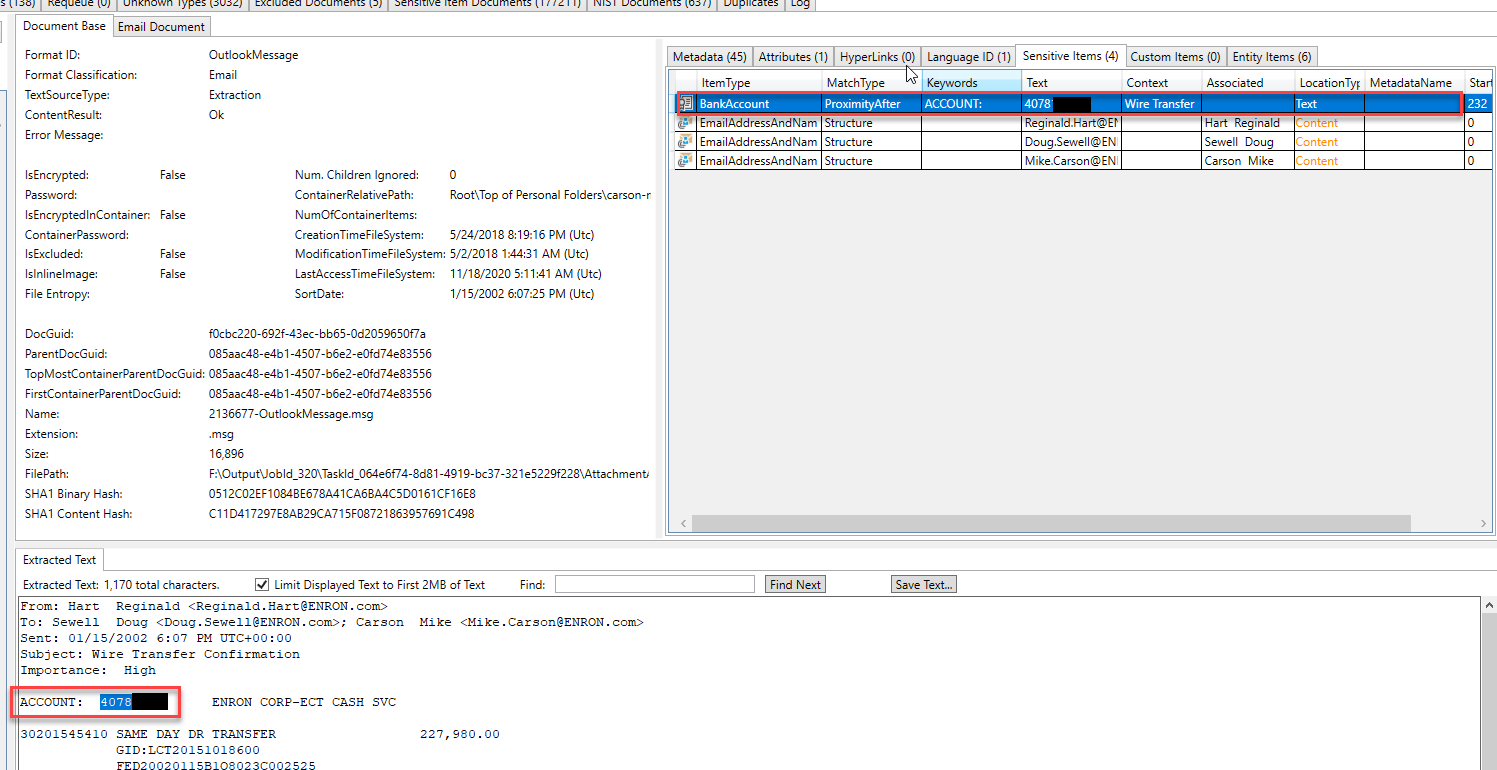
いくつかの「エンティティ」は、別の電子メールで識別および抽出されました。この電子メールにあるエンティティの種類を検査することにより、電子メールが法的問題について議論していることを推測できます。
下のスクリーンショットは、プラットフォームAPIプロセス出力が入力されたRavendb StudioのEnronデータベースを示しています。 RavendBに保存されているデータベースドキュメントフィールドの一部のみが、スクリーンショットに収まることができ、さらに多くのフィールドがあります。赤いボーダー注釈を持つ列名は、オブジェクトのコレクションです。
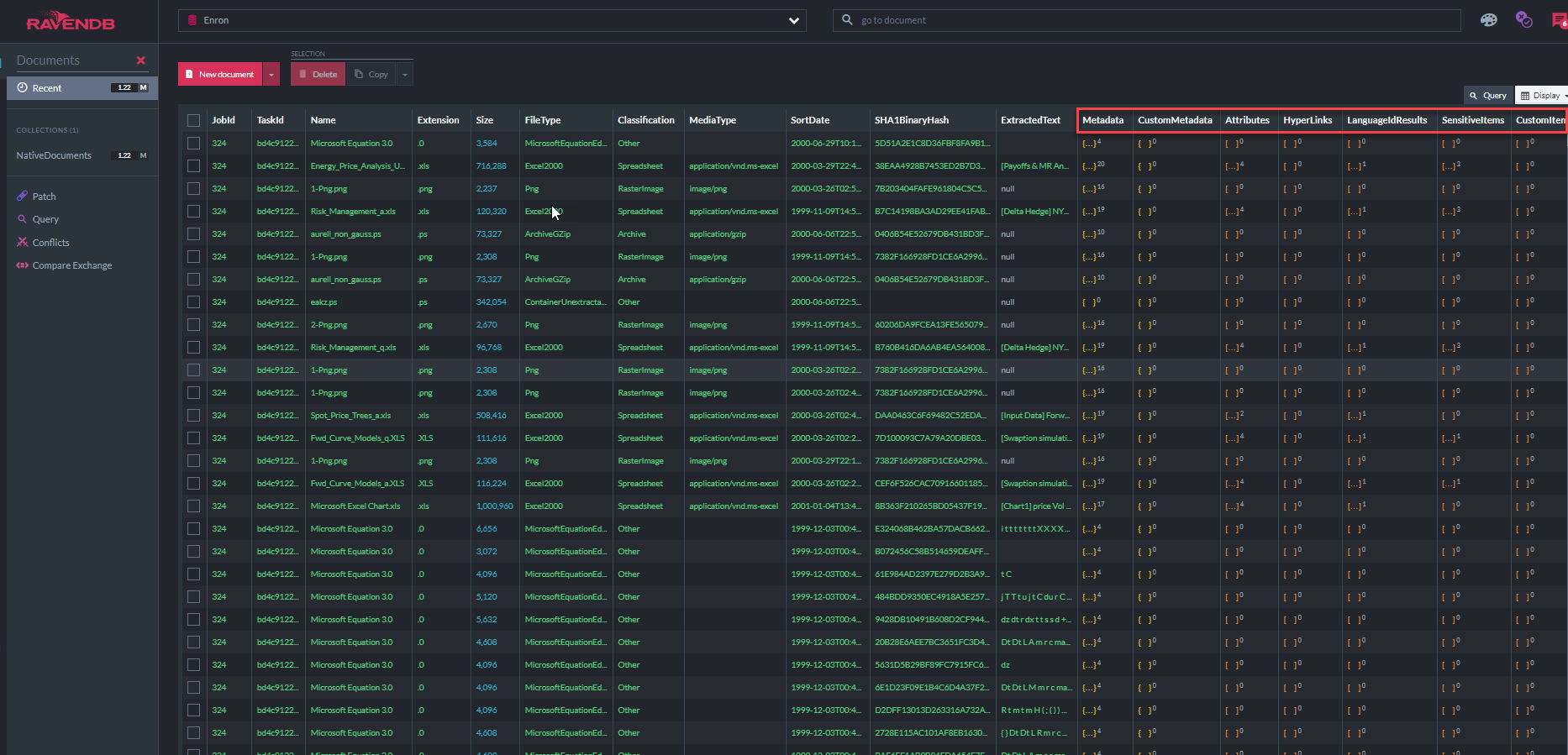
以下のスクリーンショットは、「ECAデモアプリ」がドキュメントストアを照会するために使用する31のRavendBインデックスの一部を示しています(「MetadatapropertyIndex」は、このデータベースに保存されている3770万メタデータプロパティがあることを示しています。
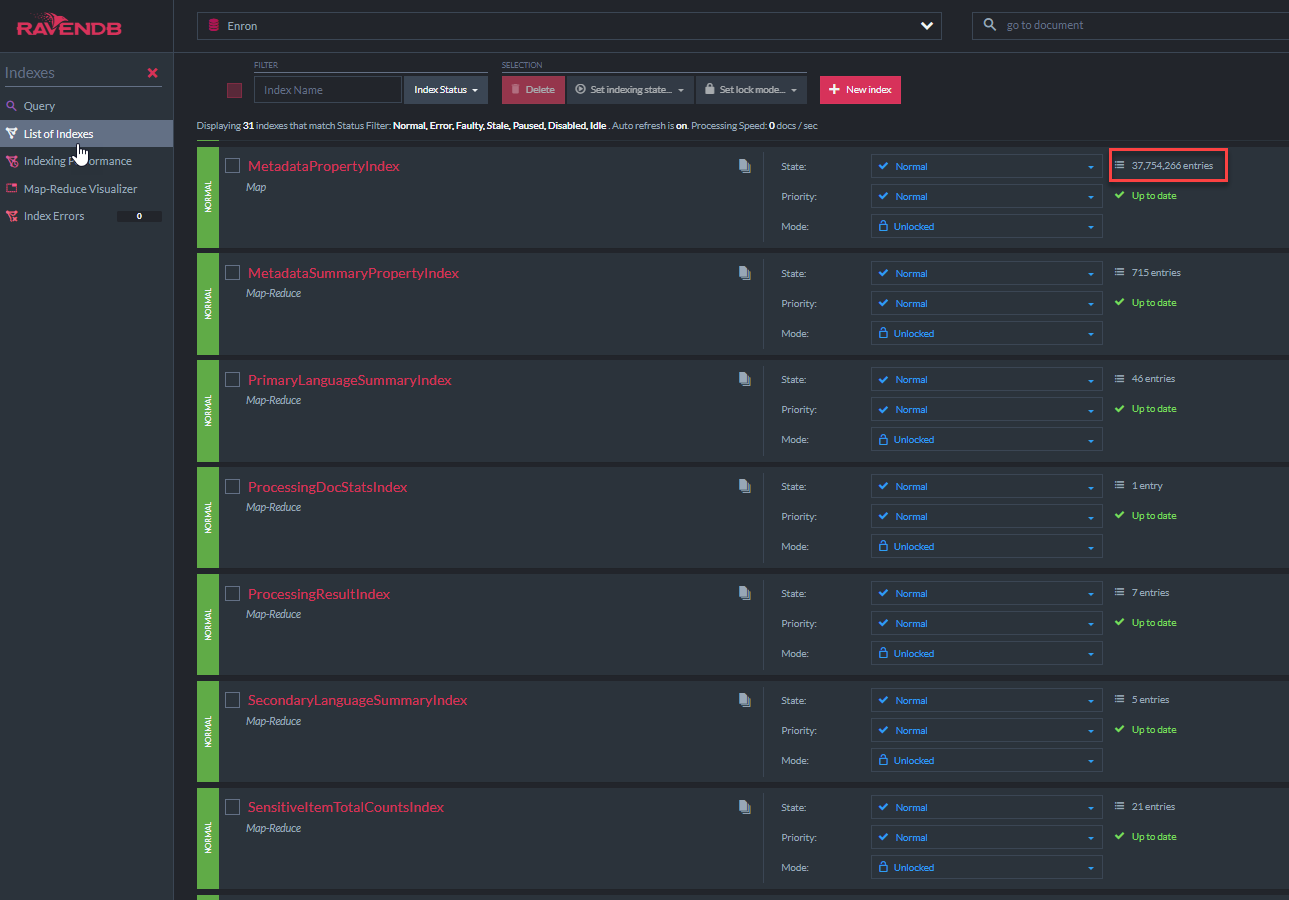
「metadatapropertyindex」C#クラスコードを以下に示します。このインデックスクラスは、RavendBのAbstractIndexCreationTaskから派生しています(このデモの他のすべてのインデックスと同様)。このインデックスにより、すべてのメタデータフィールドでLuceneの「いいね」クエリが可能になります。 nativedocument.custommetadataの同様のインデックスが存在します。
すべてのC#定義されたRavendBインデックスは、単純なRavendB API呼び出しを介して「ECAデモアプリ」からRavendB Enronデータベースに作成されます。
以下のスクリーンショットは、189 Microsoft Outlook PST Enronデータセットの処理概要統計を示しています(合計で処理された1,221,542の電子メールと添付ファイル)。このデータセットの電子メールと添付ファイルのほとんどは、法的発見段階でデータが互いに電子メールを送信していたエンロンの従業員が前後に電子メールを送信しているという事実のために、重複したドキュメントです。以下の画像に示されている重複排除統計は、バイナリ/コンテンツハッシュに基づいています。ファイル形式の分類パイチャート、特定のファイル形式のパイチャートの概要、および処理結果の概要(OK/誤りの値/DataError/etcの値を備えた列挙タイプ)パイチャートに注意してください。
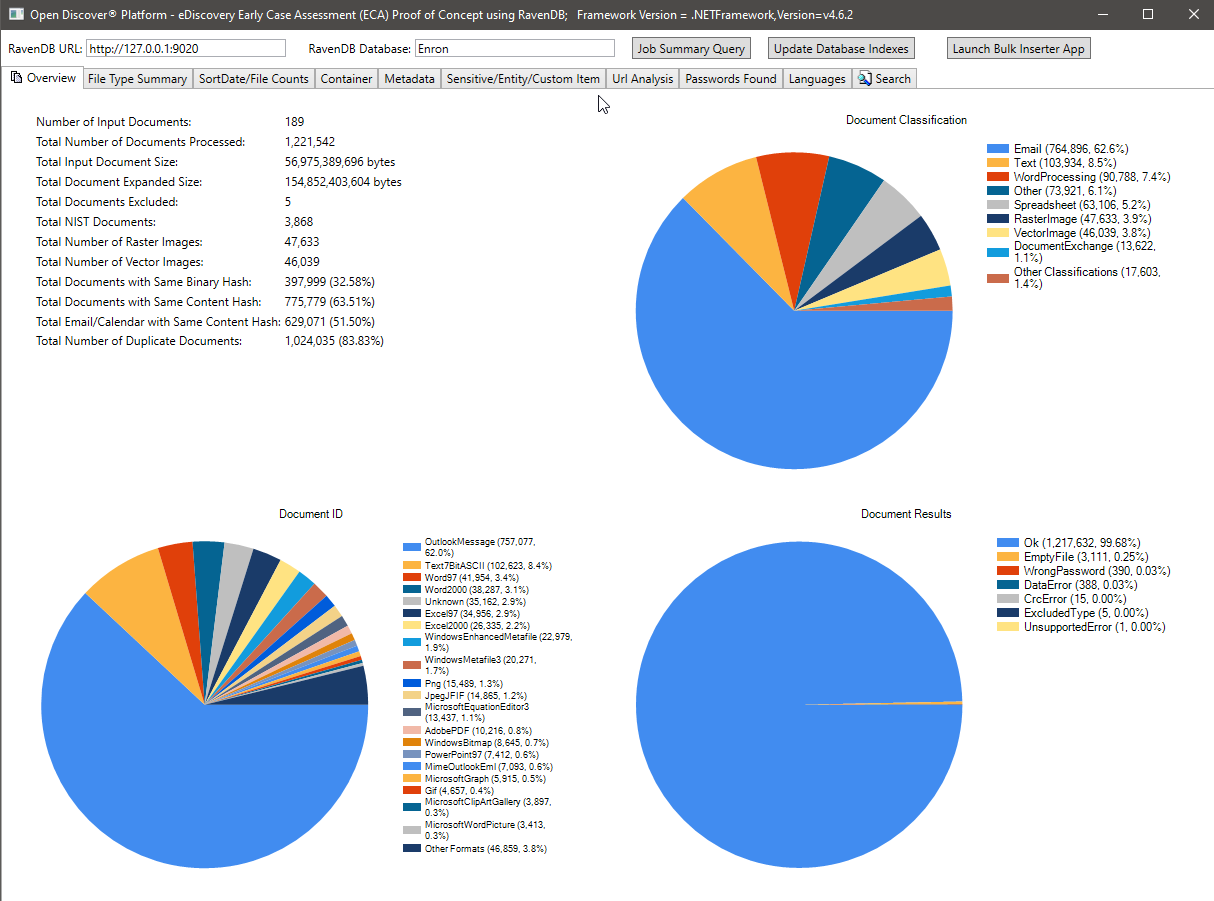
SORTDATEサマリーチャートによるファイルカウント:
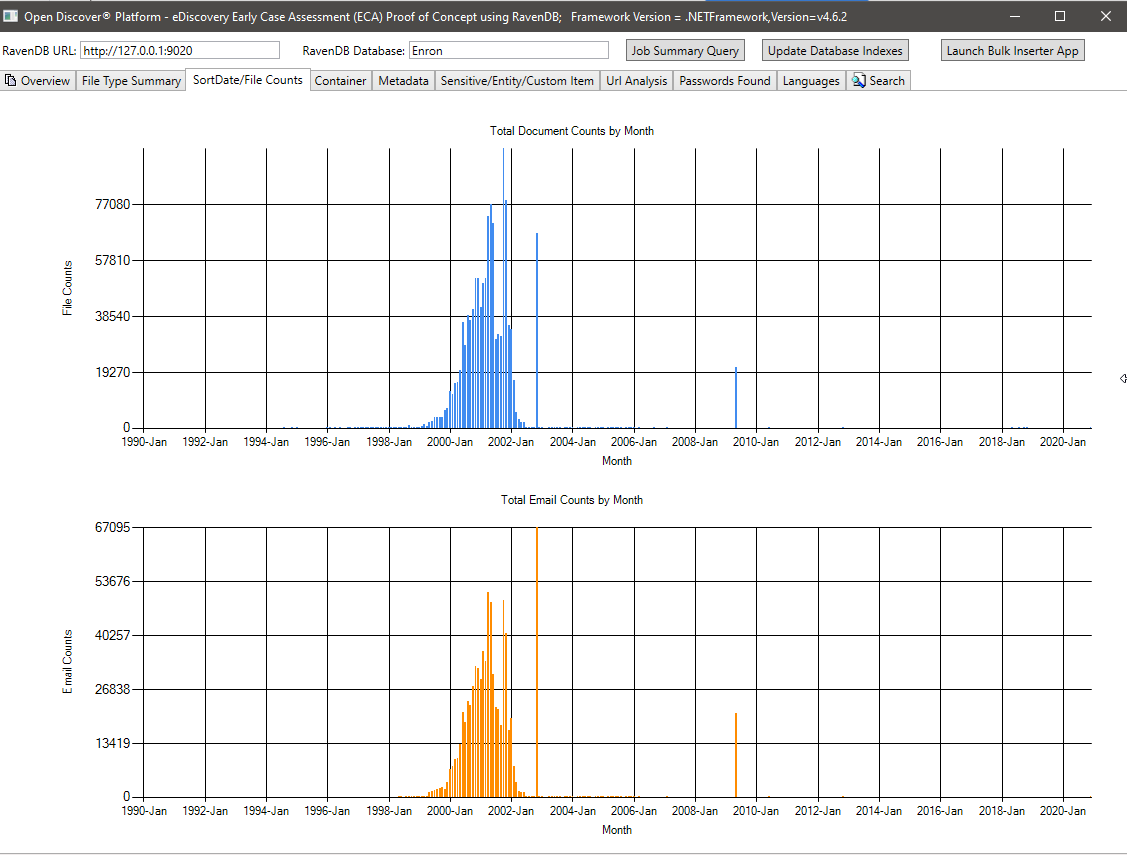
メタデータの概要(メタデータフィールド名/ドキュメントの総数)-715すべてのドキュメントにわたって既知の一意のメタデータフィールド名と636カスタム(ユーザー定義)メタデータフィールド。このクエリは、法的ケースマネージャーがコレクションでどのメタデータフィールドが利用可能であるかを検索するのに役立ちます。
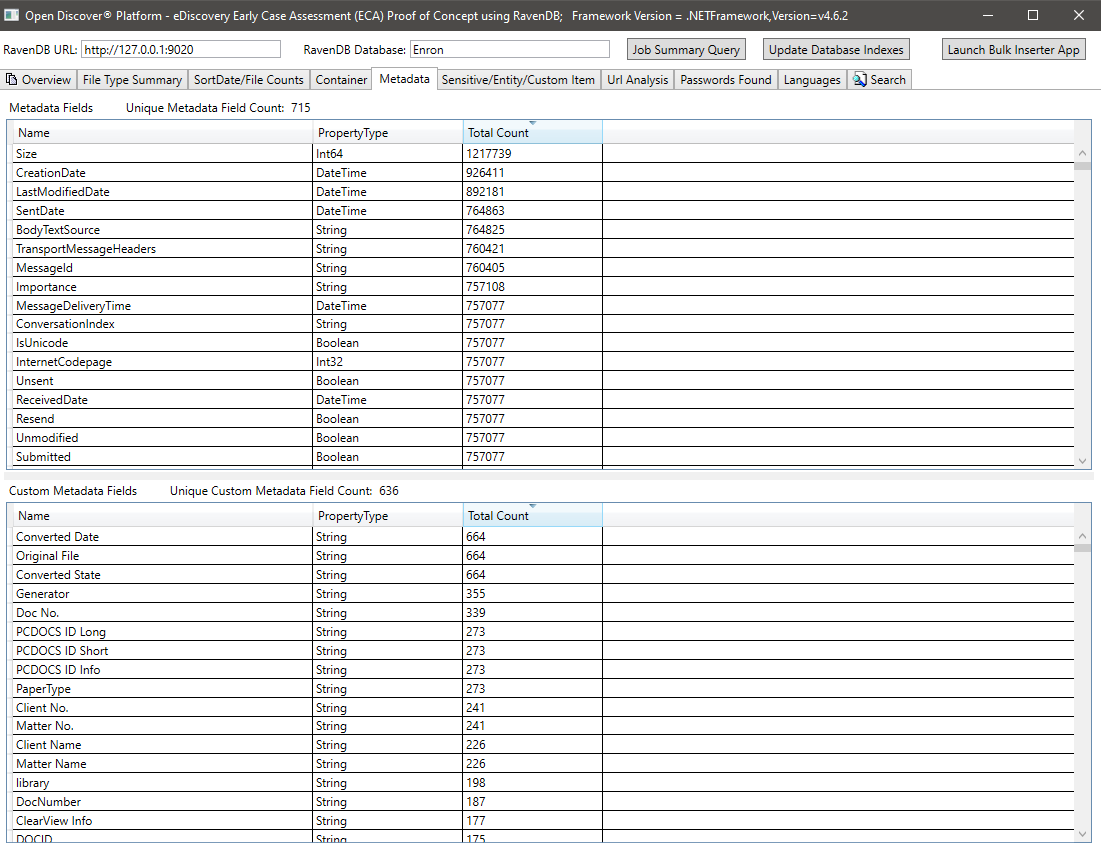
すべてのドキュメントの敏感なアイテム/エンティティアイテムの概要:
すべてのドキュメントで見つかったすべての一意のURLの概要(たとえば、企業が潜在的な悪意のあるURLエントリポイントを追跡したい場合など)。 Open SDKは、ドキュメントハイパーリンクおよびドキュメントテキスト(つまり、非ハイパーリンク)からすべてのURLを検出します。
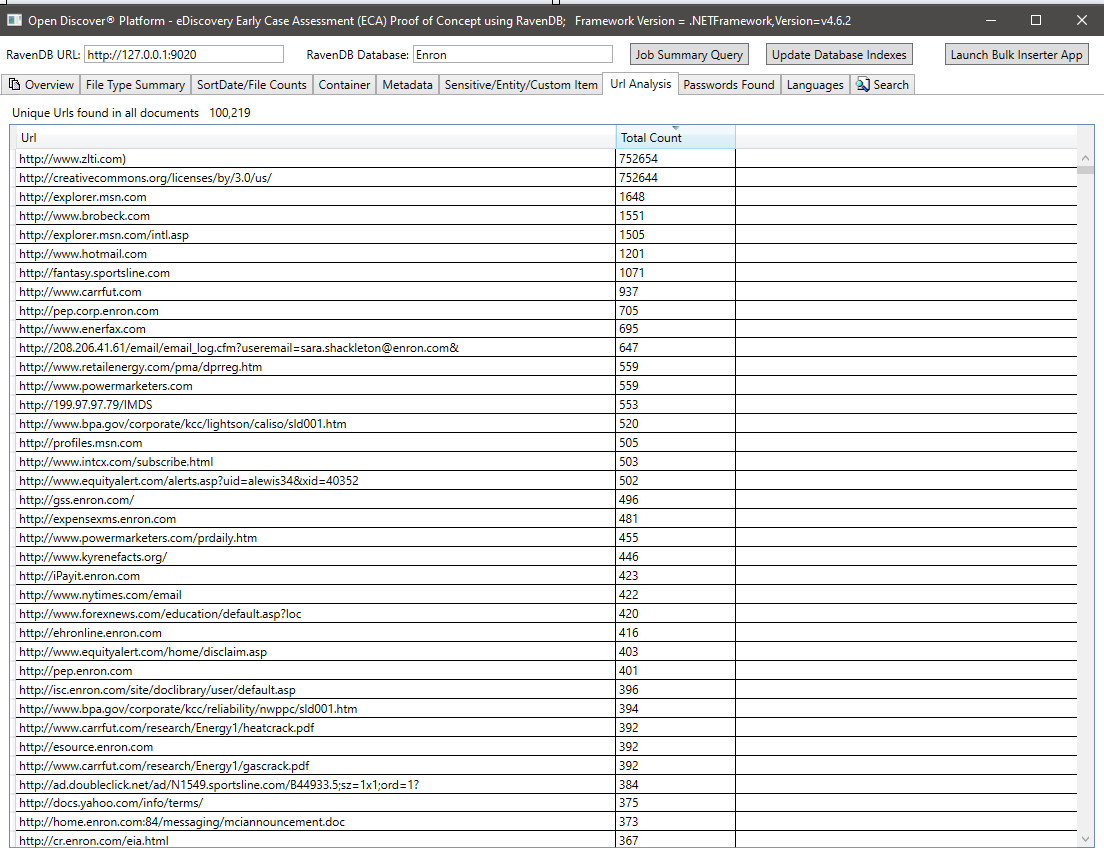
すべてのドキュメントにあるすべてのパスワードの概要。パスワードとユーザー名は、Open Discover SDK/Platformでサポートされている25の組み込みの「敏感なアイテム」タイプのうち2つです。ドキュメントのパスワード/ユーザー名資格情報はセキュリティリスクになる可能性があります。また、「間違ったパスワード」の処理結果があるドキュメントを再処理するために使用することもできます(同じ会社の従業員は、共有された暗号化されたオフィスドキュメントにお互いのパスワードをメールで送信することが多いため):
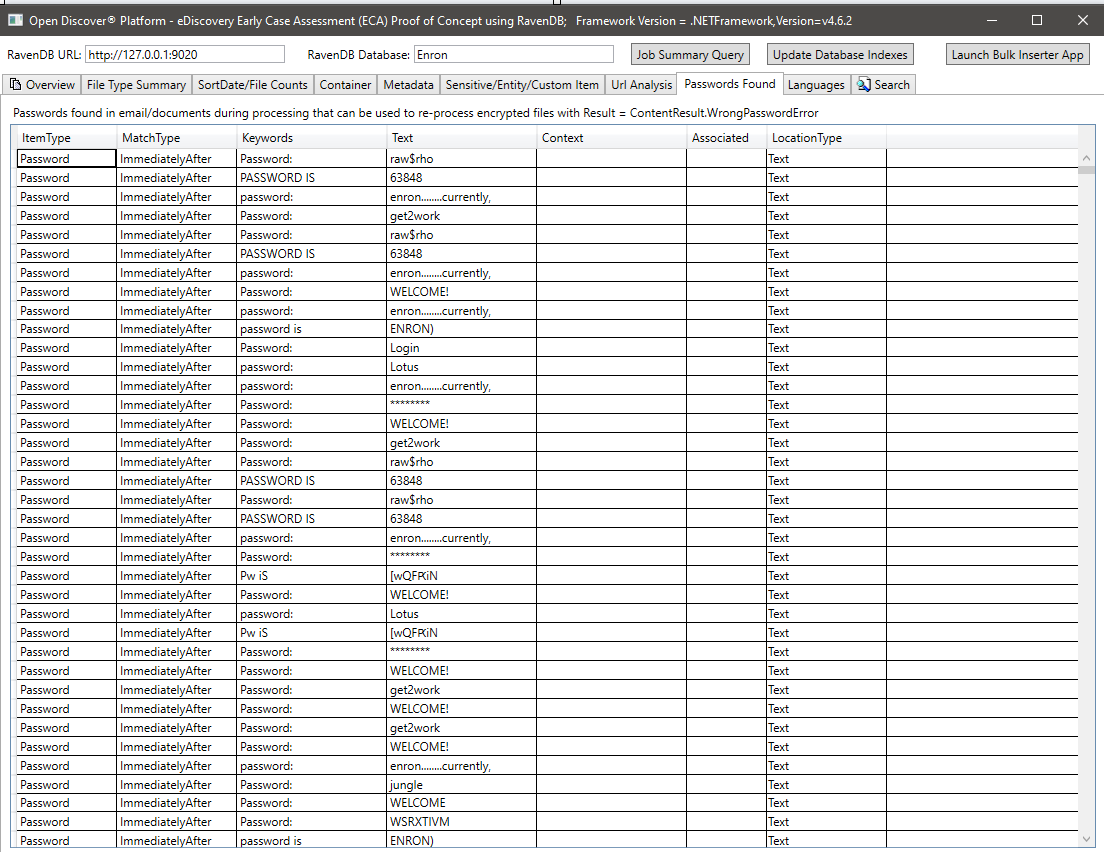
処理されたドキュメントの抽出されたテキストで検出された言語の概要:
フルテキスト検索クエリの例(注:RavendbはLuceneクエリをサポートしています):
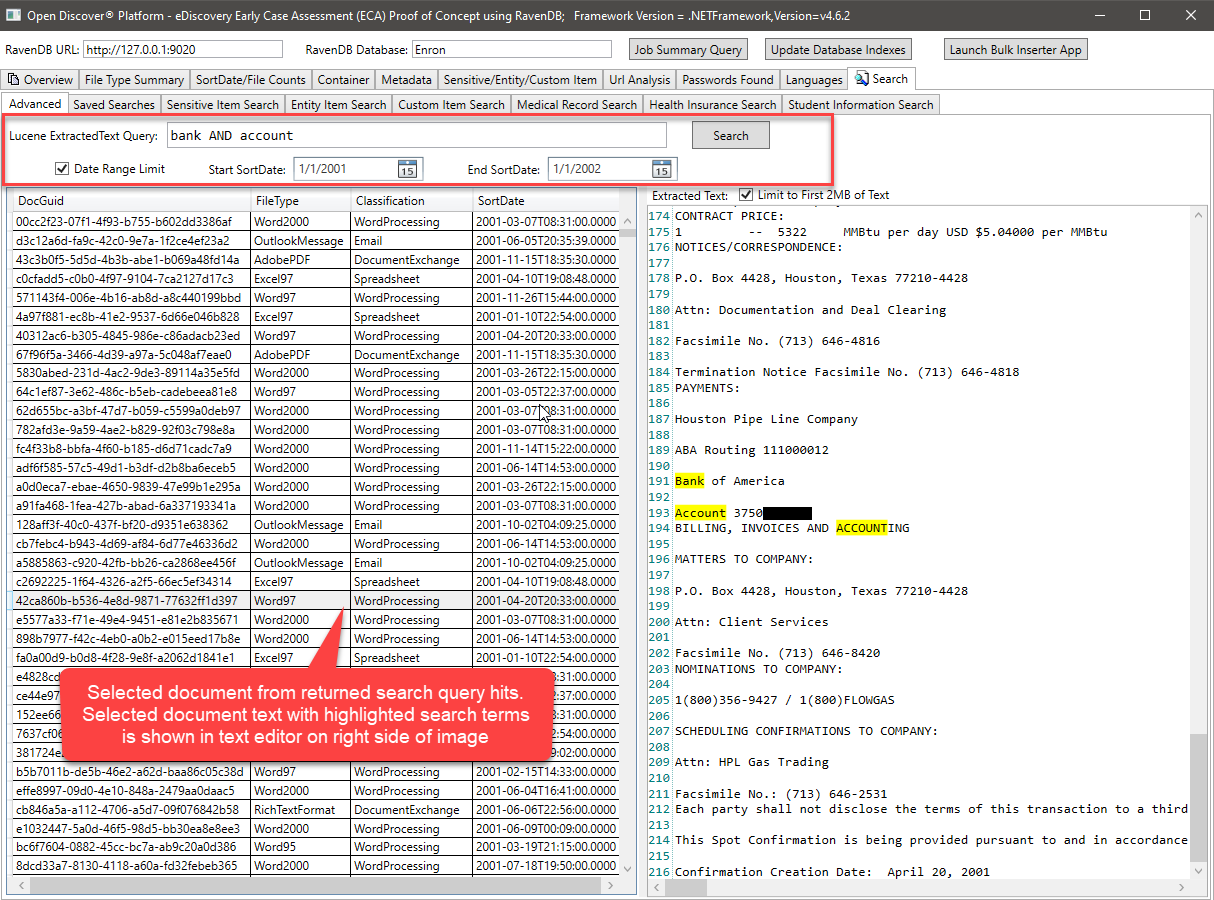
上記のLuceneクエリは、ExtractedTextフィールドをクエリし、(オプションで)Min/Max Document SortDateを使用して、返された検索結果をフィルタリングします。また、ドキュメントのFiletypeまたはドキュメント形式の分類(WordProcessing/Spreadsheet/Emailなど)による結果のフィルタリングを追加することも非常に簡単です。ルーセンクエリを実行するC#コードは次のようになります。
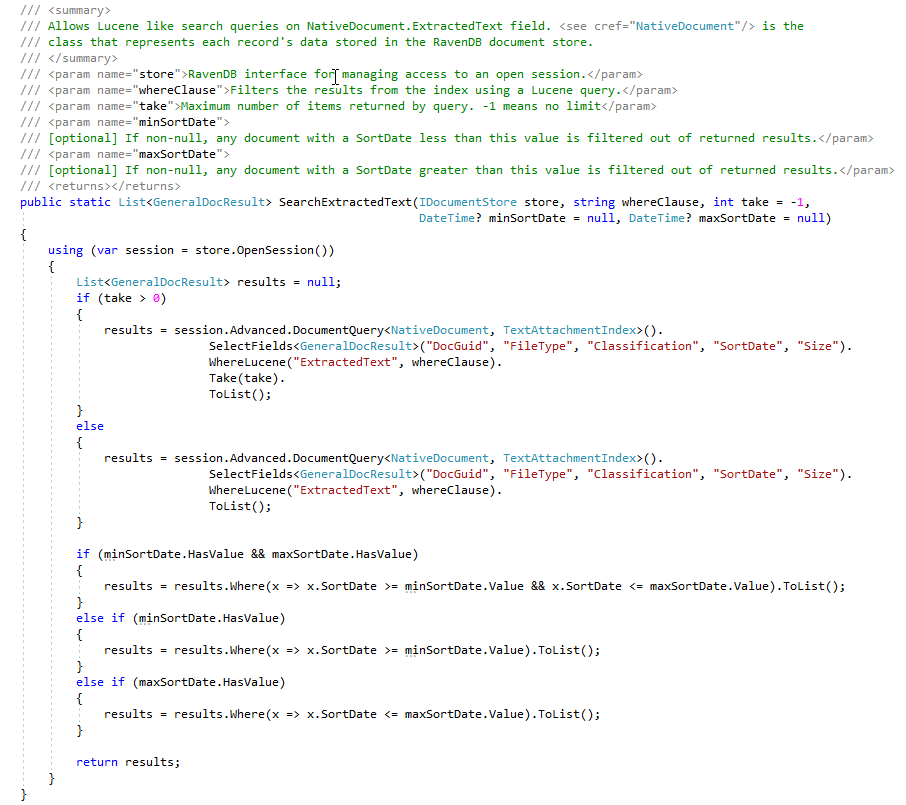
ECA段階では、法律審査弁護士は、応答するドキュメントを見つけるために、さまざまな検索クエリを作成したいと考えています。下のスクリーンショットは、いくつかの保存されたルーセンクエリと結果(ドキュメントのヒット数とドキュメントの合計サイズ)を示しています。これらのユーザー作成された検索でドキュメントカウントには重複したドキュメントカウントが含まれていますが、重複したドキュメントの数をカウントするRavendBインデックスがありますが、この概念の証明については、マスター/重複を示すフラグがあるドキュメントストアでドキュメントストアに「マーク」ドキュメントをまだ「マーク」していません(これはユーザーによる「TODO」です):
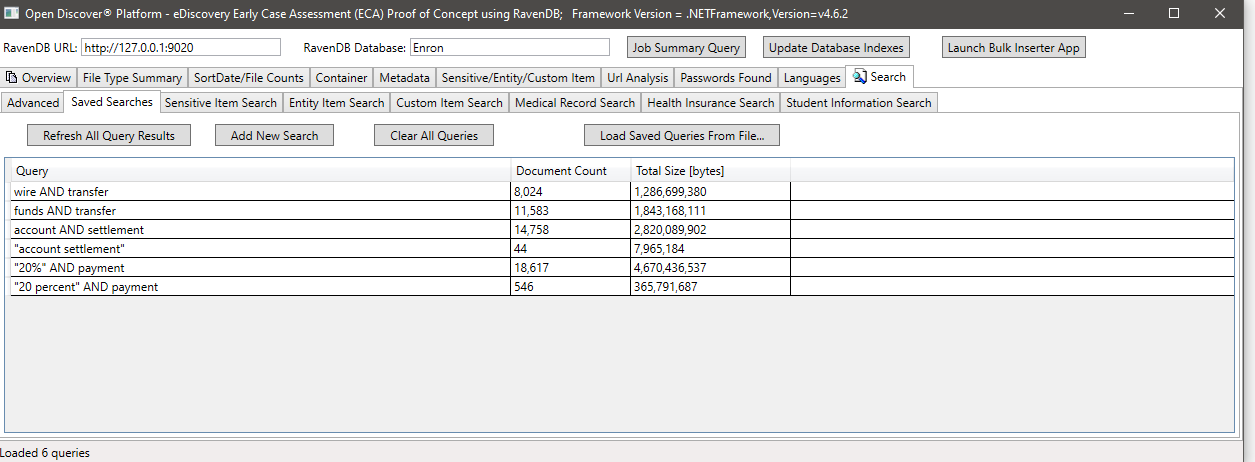
SensitiveItemTypeによる検索の例(機密項目のタイプを識別する検出された感度オブジェクト上のプロパティ)、この例では、SensitiveItemType.bankaccountの機密項目を持つすべてのドキュメントを検索します。
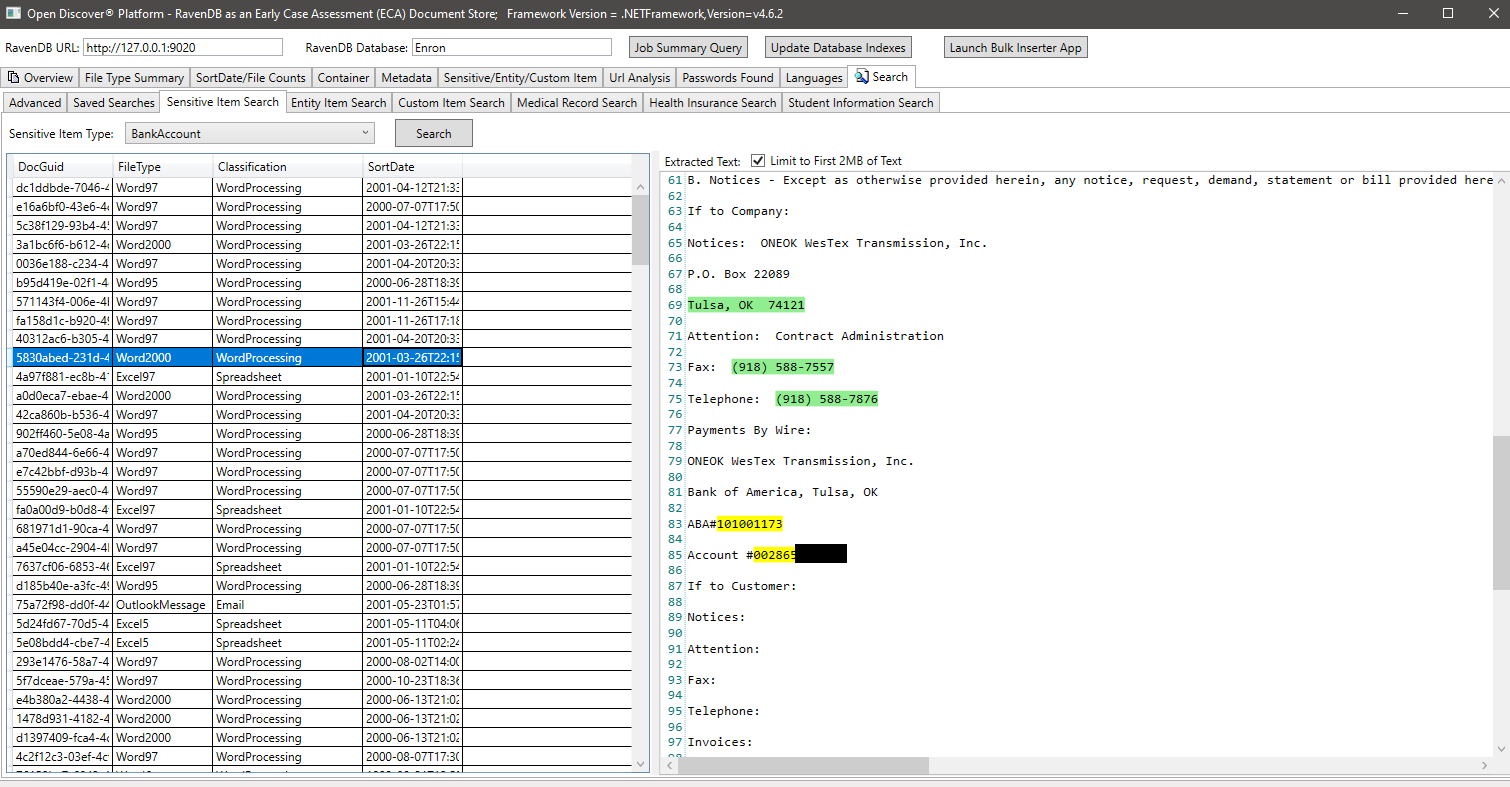
ENTITYITEMTYPEによる検索の例(エンティティアイテムのタイプを識別する検出されたエンティティイエントオブジェクトのプロパティ)、この例では、entityItemType.patientNameEntryのタイプのエンティティアイテムを持つすべてのドキュメントを検索します。
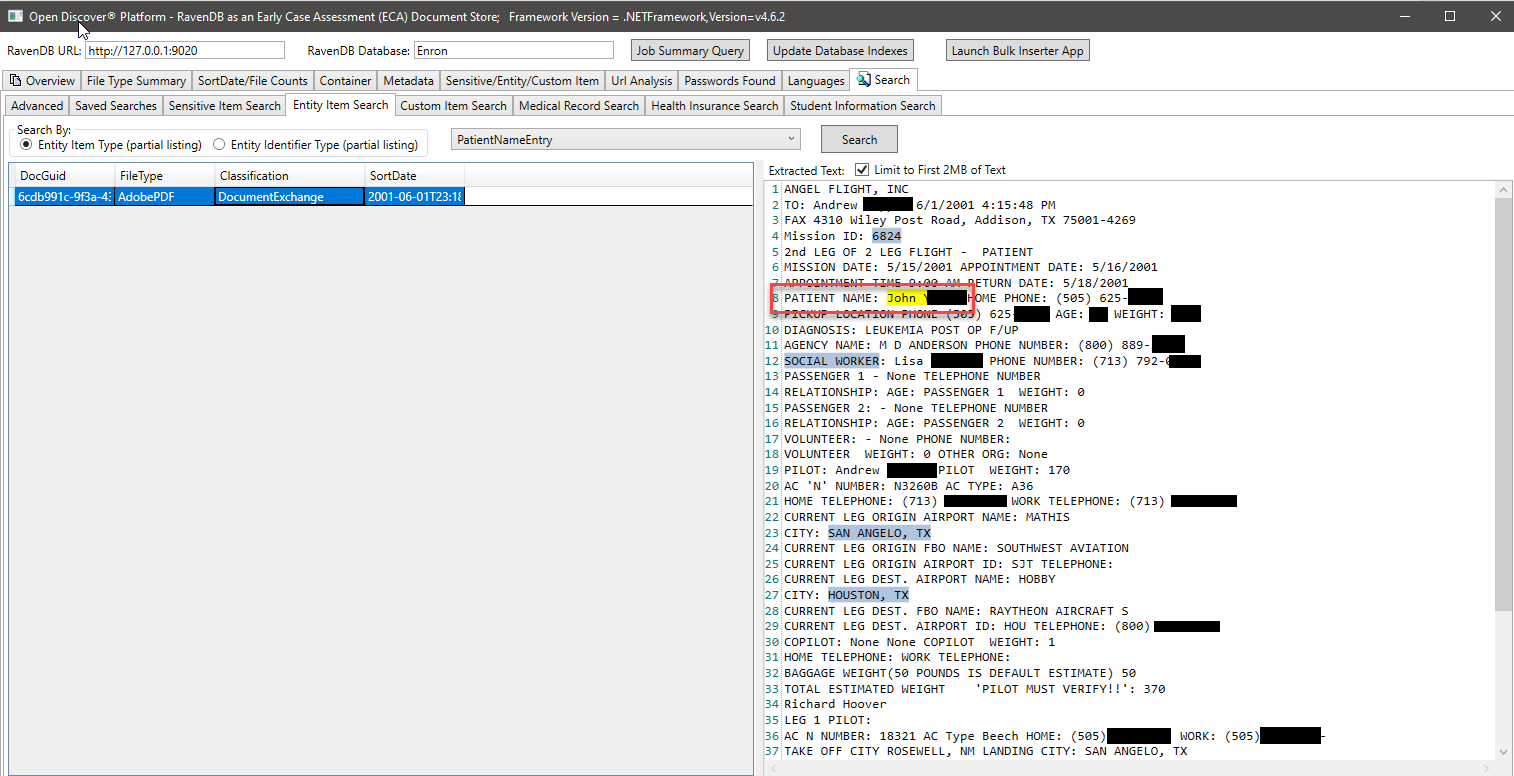
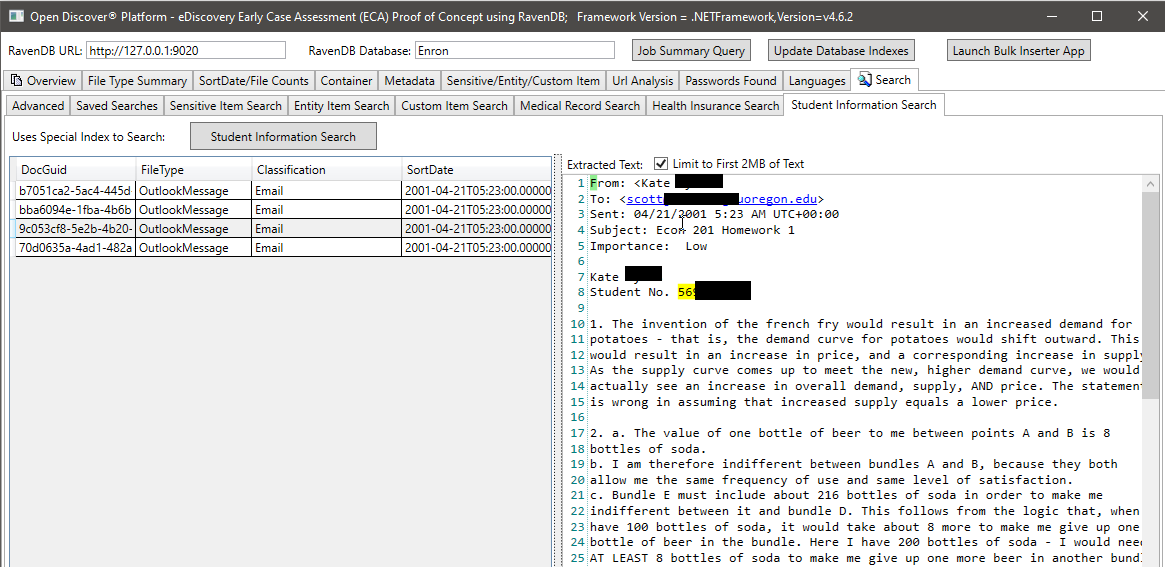
以下のスクリーンショットでは、学生情報に関連する特定のオープンディスカバーSDK抽出エンティティタイプをインデックス化する特別に作成されたRavendBインデックスを使用して、学生情報を持っている可能性のあるドキュメントを見つけます(スクリーンショット、学生の名前と学生IDは2000年代以前に一般的な社会保障番号のように見えます)。同様に、医療記録や患者情報を検索する他の特別なインデックスがあります。
RavendBなどのドキュメントデータベースに保存されているOpenIsducag®プラットフォーム出力は、非常に強力で急速に開発された法的早期症例評価(ECA)アプリケーションにつながる可能性があります。さらに、次のようなアプリケーションも迅速に開発できます。
このケーススタディがRavendBなどのドキュメントデータベースの代わりにリレーショナルデータベースを使用していた場合、この初期症例評価(ECA)の概念実証を開発するのに2週間ではなく、データベーススキーマの設計と保存手順の開発を数か月かけていました。


