OpenDiscoverPlatformCaseStudy
1.0.0
انظر Open Discover® SDK للحصول على أمثلة .NET مستودع github
عادةً ما تكون مثيل واحد من واجهة برمجة تطبيقات نظام Open Discover قادرًا على معالجة مجموعات المستندات بمعدل 40-70 جيجابايت/ساعة* (* ستعتمد المعدلات على أجهزة المستخدم وأنواع الملفات في مجموعة البيانات). إنه سريع للغاية في معالجة المستندات مع استخراج المزيد من المحتوى أكثر من معظم برامج eDiscovery (على سبيل المثال ، الكشف عن العنصر/الكيان الحساس و de-nist-ing أثناء المعالجة). تم استخدام تطبيق Open Discover Platform API التجريبي ، platformapidemo.exe ، لمعالجة مجموعة بيانات Enron Outlook PST. يلف تطبيق platformapidemo.exe demo مثيلًا واحدًا من فئة معالجة مستندات API منصة. يتم عرض لقطات الشاشة لمثال PlatformAPideMo.exe معالجة الإخراج في القسم التالي أدناه.
يتم توزيع platformapidemo.exe مع تقييم منصة Discover Open جنبا إلى جنب مع:
في اختبار الأداء حديثًا ، قامت Open Discover SDK بمعالجة مجموعة بيانات Microsoft Outlook 53 جيجابايت من Microsoft PST وإدراجها بشكل كبير في إخراج API من النظام الأساسي (النص/البيانات الوصفية/العناصر الحساسة (PXI) إلى RAVENDB في ما يزيد قليلاً عن 30 دقيقة باستخدام سطح مكتب Windows 4-core.
** كان معدل معالجة دراسة الحالة هذا للإصدار .NET 4.62 من SDK ، إصدار .NET 6 الجديد أكثر أسرع بنسبة 100 ٪ في المتوسط ، جميع مهام معالجة PST على إصدار .NET 6 من OPENDISCOVERPLAT مع معالجتها ، يتم معالجتها في المعالجة (معالجة هذه المعالجة - معالجتها. كمبيوتر سطح المكتب مع وحدة المعالجة المركزية Intel I7 و RAM 16 جيجابايت).
تعرض لقطة الشاشة أدناه عنصر بريد إلكتروني (ومرفقاته) تم استخلاصه من حاوية Outlook PST ومعالجته بواسطة تطبيق platformapidemo.exe. البريد الإلكتروني من أحد Enron Microsoft Outlook PSTS. يُظهر التحكم في عرض الأشجار على الجانب الأيسر من الصورة التسلسل الهرمي للأصل/الطفل لجميع المستندات/الحاويات المعالجة ، والنقر على عنصر في التحكم في الشجرة سيظهر محتواه المستخرج. بالنسبة لعنصر بريد Outlook المحدد في عرض الشجرة ، يمكننا أن نرى أنه يحتوي على مستندات Word Office 6 مللي ثانية كمرفقات تم استخراجها من البريد الإلكتروني. تم استخراج كل عنصر من العناصر المدمجة/المدمجة أيضًا (معالجة أي تسلسل هرمي للطفل ، بغض النظر عن مدى تعقيدها). ملاحظة: نتائج تحديد تنسيق الملف ، محسوبة "sortdate" ، تجزئة المستندات المختلفة ، البيانات الوصفية المستخرجة ، وغيرها من عناصر علامات التبويب على الجانب الأيمن العلوي من الصورة التي تحتوي على محتوى آخر مستخرج:
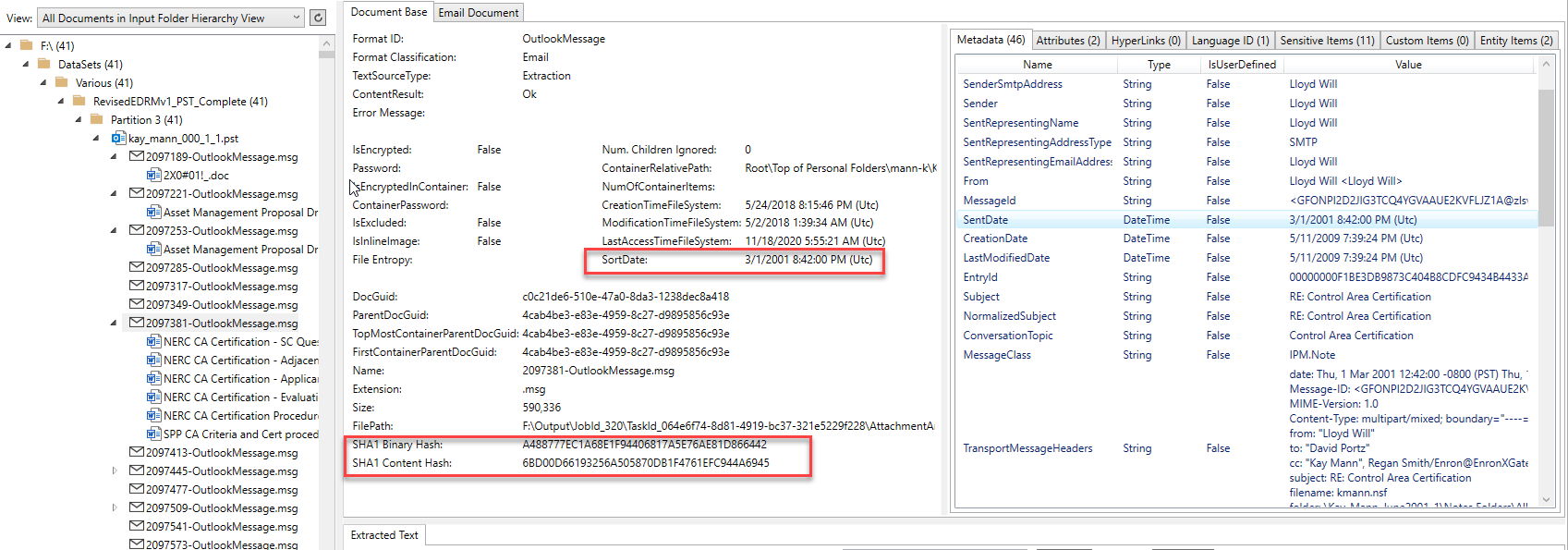
البريد الإلكتروني محتوى محدد مثل جميع المستلمين وتجزئة إضافية:
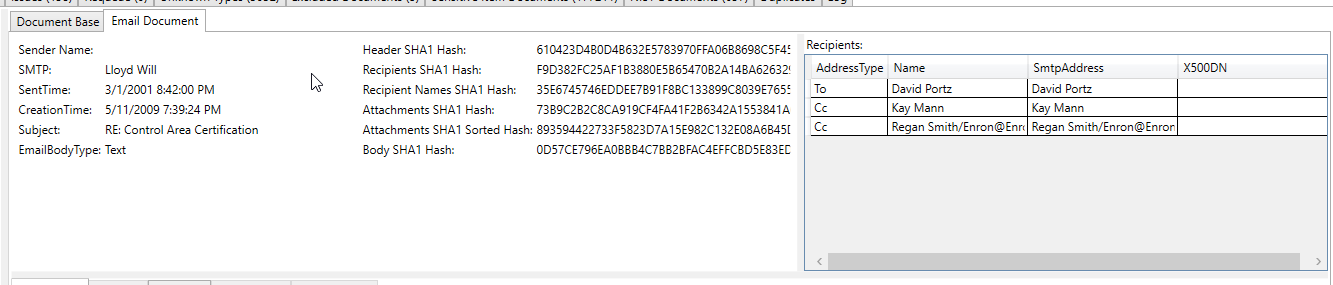
تعرض لقطة شاشة البريد الإلكتروني المعالجة رقم حساب مصرفي تم استخلاصه/تحديده على أنه "عنصر حساس" في النص المستخرج من البريد الإلكتروني (يتم فحص جميع النصوص المستخرجة وجميع البيانات الوصفية للعناصر الحساسة):
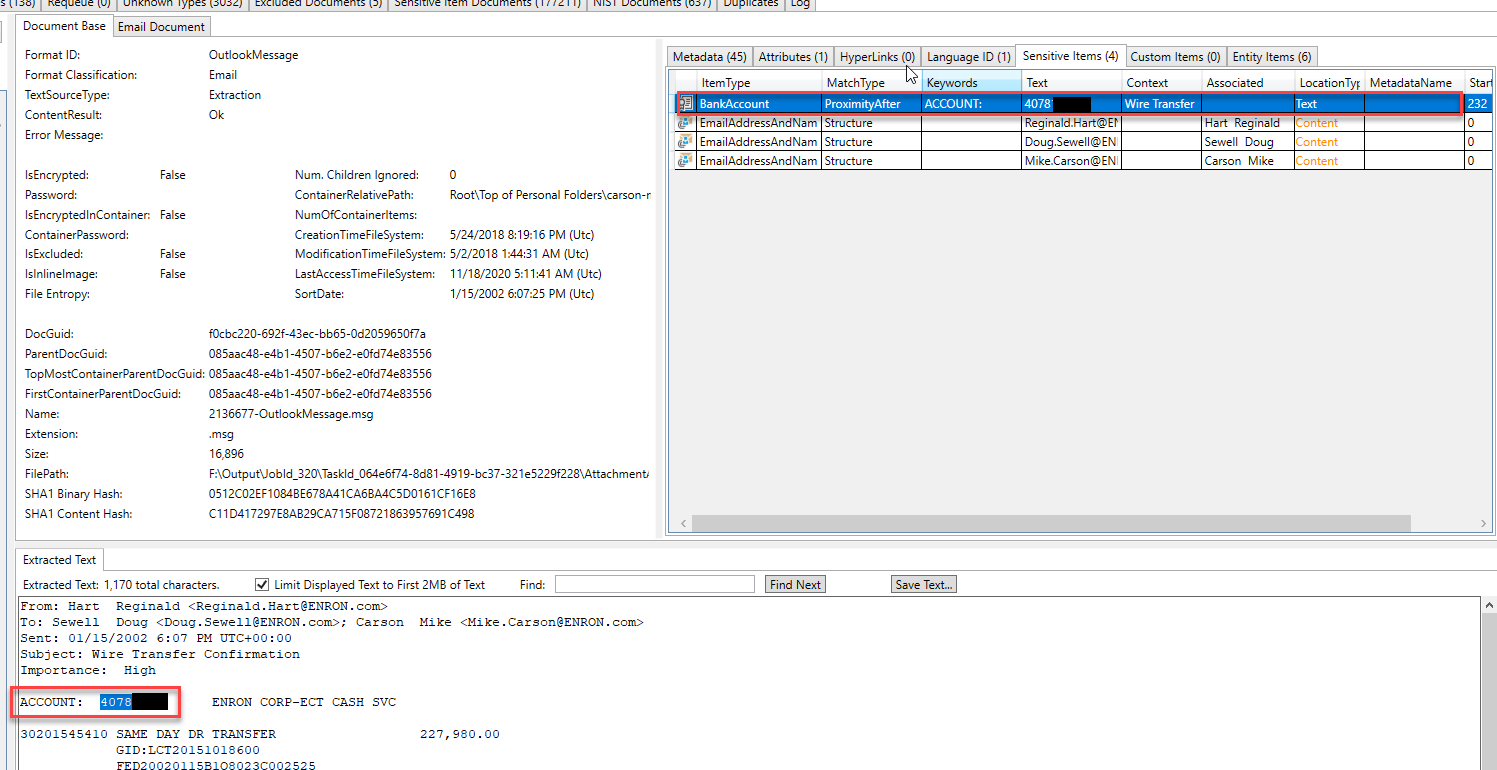
تم تحديد بعض "الكيانات" واستخراجها في بريد إلكتروني مختلف. من خلال فحص أنواع الكيانات الموجودة في هذا البريد الإلكتروني ، يمكننا أن نتوقع أن البريد الإلكتروني يناقش مسألة قانونية:
تُظهر لقطة الشاشة أدناه قاعدة بيانات Enron في Ravendb Studio الملغوبين مع إخراج معالجة API منصة. فقط بعض حقول مستندات قاعدة البيانات المخزنة في Ravendb يمكن أن تتناسب مع لقطة الشاشة ، وهناك العديد من الحقول الأخرى. أسماء الأعمدة ذات التعليقات التوضيحية الحدودية الحمراء هي مجموعات من الكائنات:
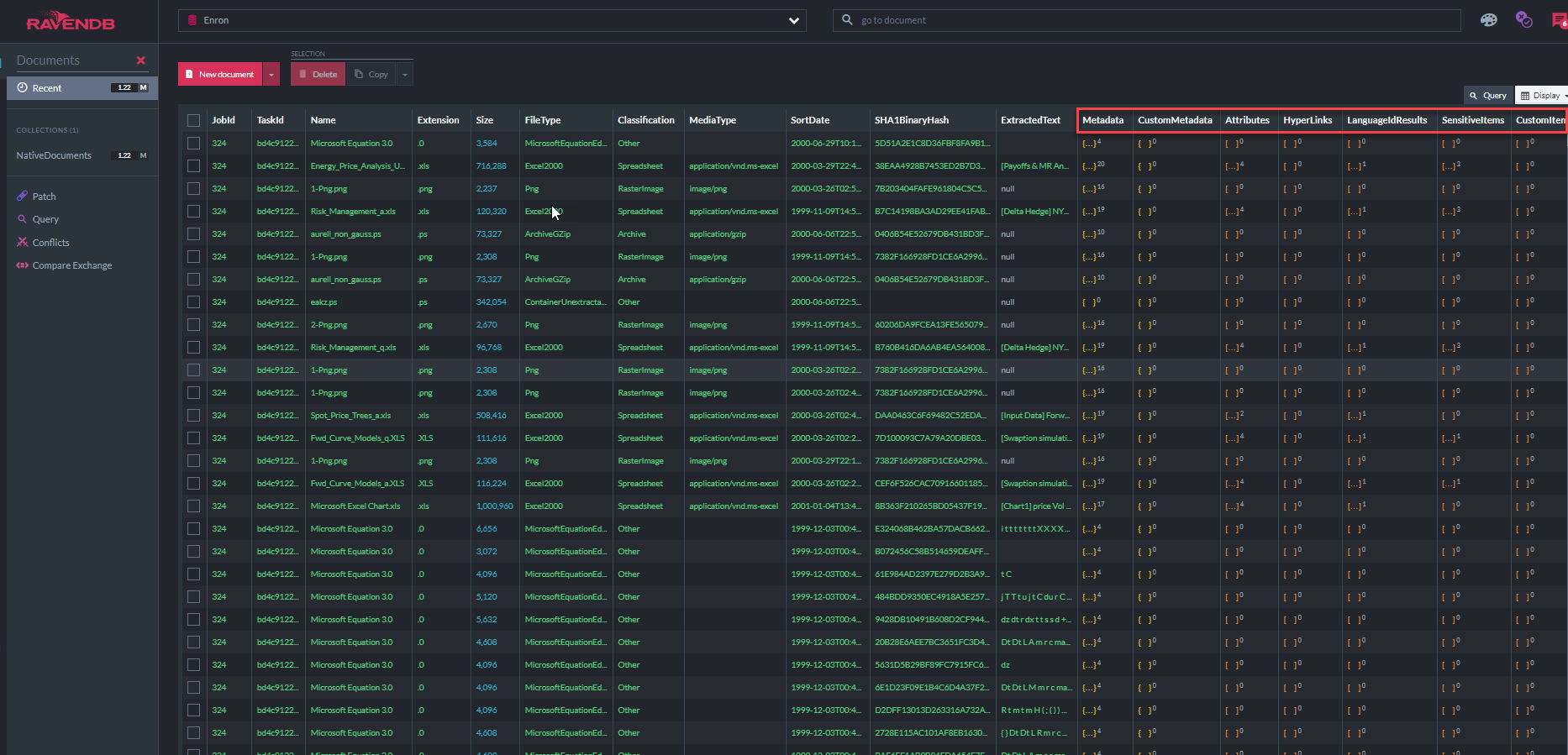
تُظهر لقطة الشاشة أدناه بعضًا من فهارس RAVENDB الـ 31 التي يستخدمها "تطبيق ECA Demo" للاستعلام عن متجر المستندات (لاحظ أن "MetaDataProPertyIndex" يوضح أن هناك 37.7 مليون من خصائص بيانات التعريف المخزنة في قاعدة البيانات هذه ، ومعظمها من بيانات تعريف البريد الإلكتروني ، بالإضافة إلى جميع النص المستخرج):
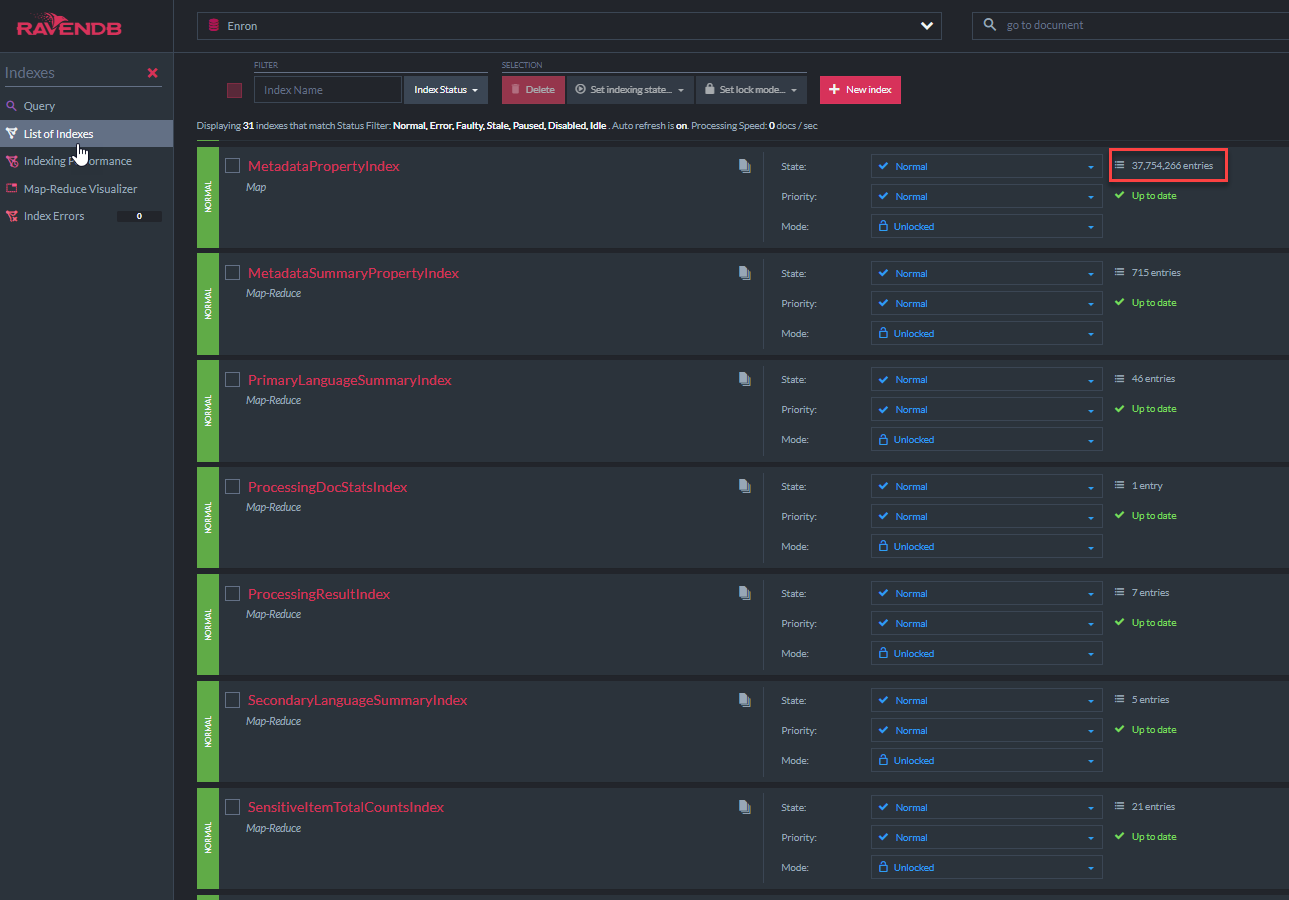
يتم عرض رمز الفئة "metadatapropertyIndex" C# أدناه. مستمدة من فئة الفهرس هذه من RavendB's AbstractIndExcreationTask (كما تفعل جميع الفهارس الأخرى في هذا العرض التوضيحي). سيسمح هذا الفهرس باستعلامات Lucene "مثل" جميع حقول البيانات الوصفية. يوجد فهرس مماثل لـ nativedocument.custommetadata:
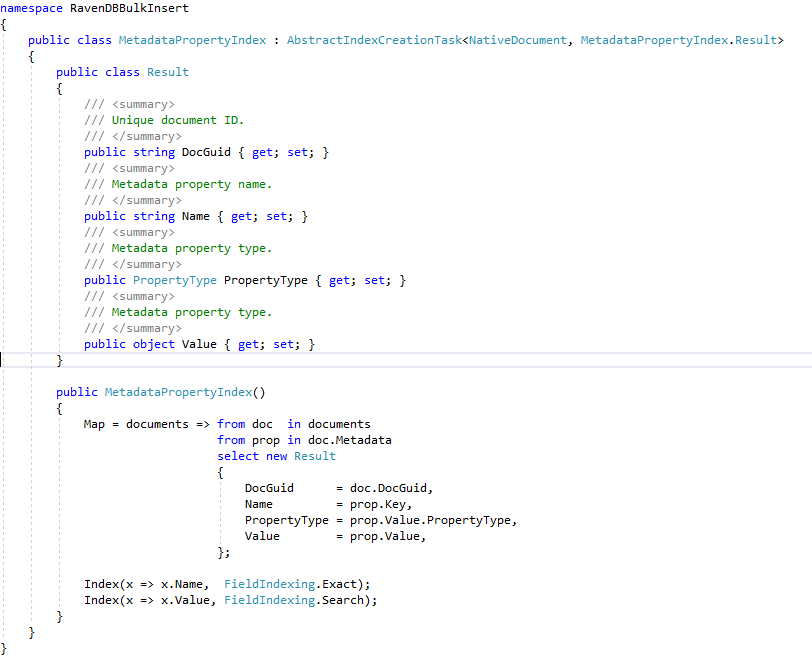
يتم إنشاء جميع فهارس RAVENDB المحددة في قاعدة بيانات RAVENDB ENRON من "تطبيق ECA Demo" عبر مكالمة API RavendB البسيطة:
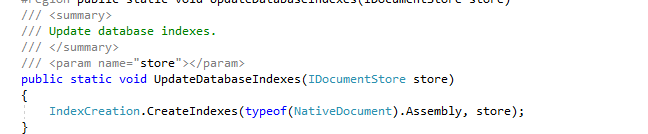
توضح لقطة الشاشة أدناه إحصائيات ملخص المعالجة لمجموعة بيانات Microsoft Outlook PST Enron 189 (1،221،542 رسالة بريد إلكتروني ومرفقات تمت معالجتها في المجموع). معظم رسائل البريد الإلكتروني والمرفقات الموجودة في مجموعة البيانات هذه هي مستندات مكررة بسبب حقيقة أن موظفي Enron الذين تم جمع بياناتهم خلال مرحلة الاكتشاف القانوني كانوا إرسال بريد إلكتروني إلى بعضهم البعض ذهابًا وإيابًا - استندت إحصائيات التكلفة الوهمية الموضحة في الصورة أدناه إلى تجزئة Binary/Content ، في المستقبل ، سنقوم بتحديث دراسة الحالة هذه (إلى جانب فهرس Ravendb) لتشمل الصناعة القانونية "Deduplication". ملاحظة مخطط فطيرة تصنيف تنسيق الملف ، وملخص مخطط فطيرة تنسيق الملفات المحدد ، وملخص نتائج المعالجة (نوع التعداد مع قيم OK/ORCHERPASSWORD/DATAERROR/etc).
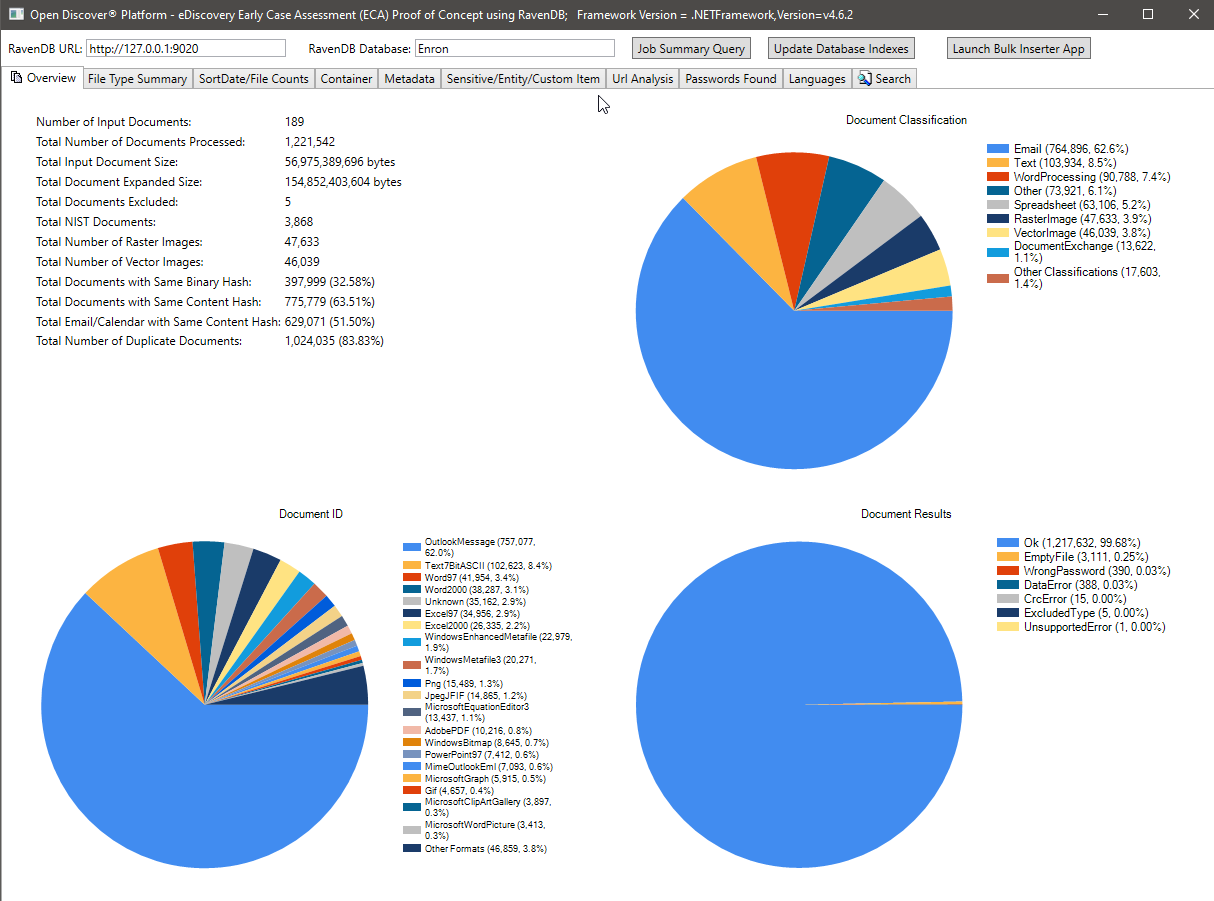
تعداد الملفات بواسطة مخططات ملخص Sortdate:
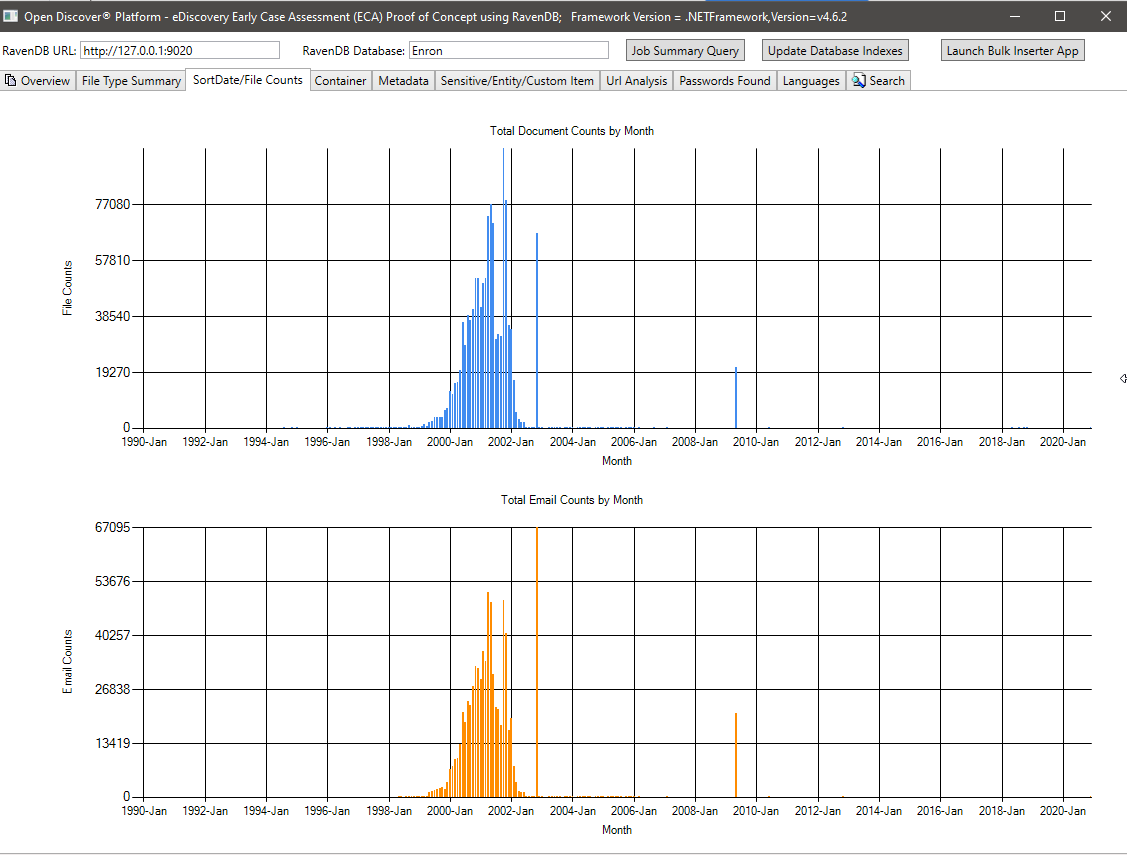
ملخص البيانات الوصفية (اسم حقل البيانات الوصفية/العدد الإجمالي للمستندات) - 715 أسماء حقل البيانات الوصفية الفريدة المعروفة في جميع المستندات و 636 حقول بيانات التعريف المخصصة. يمكن أن يساعد هذا الاستعلام مديري القضايا القانونية على معرفة ما هي حقول البيانات الوصفية المتوفرة في المجموعة للبحث في:
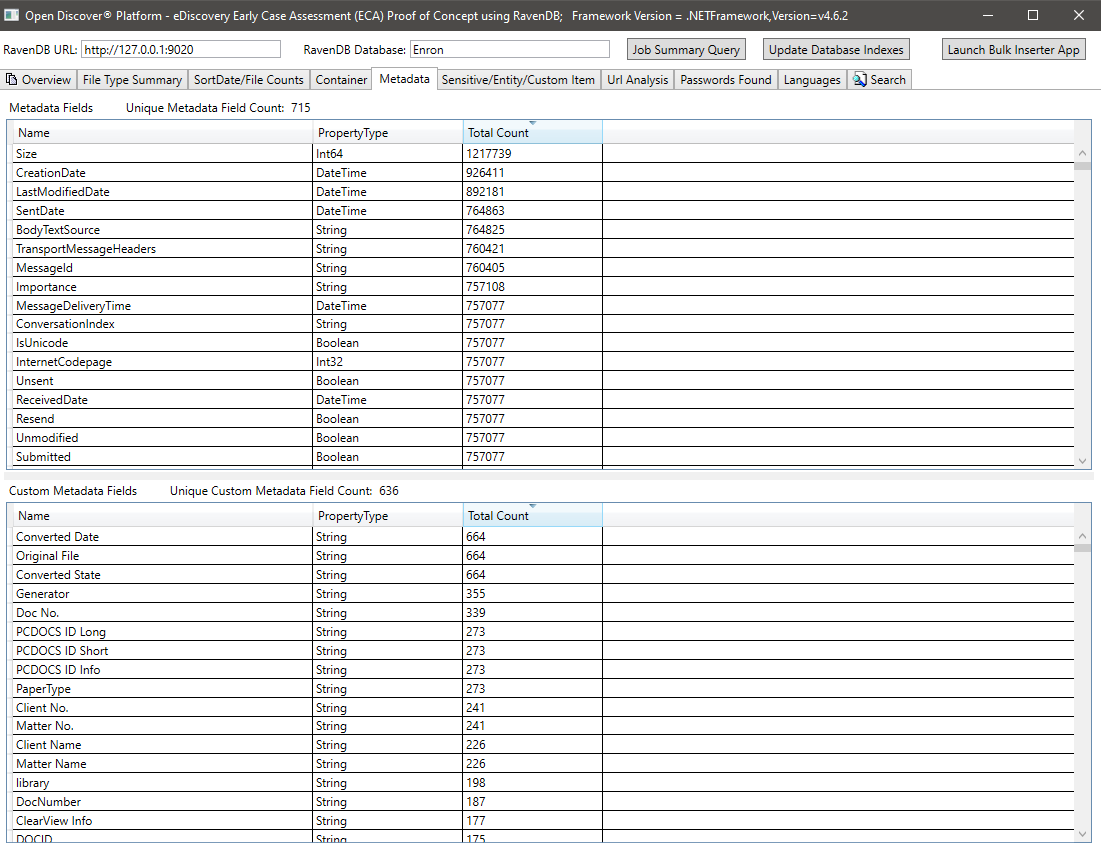
ملخص العنصر/العنصر الحساس لجميع المستندات:
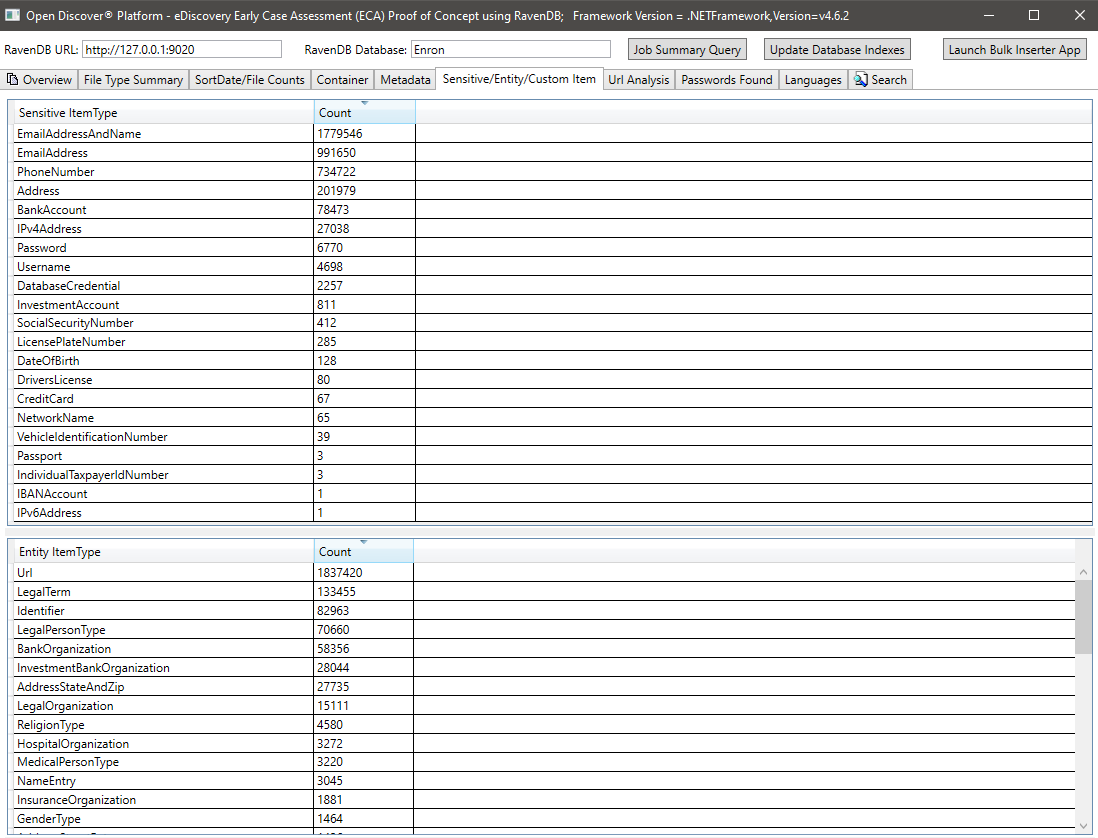
ملخص جميع عناوين URL الفريدة الموجودة في جميع المستندات (قد تكون عناوين URL من كل مستند مفيدة ، على سبيل المثال ، إذا كانت الشركة ترغب في تعقب نقاط دخول URL الضارة المحتملة). Open Discover SDK يكتشف جميع عناوين URL من الارتباطات التشعبية المستند ونص المستند (أي ، غير hyperlink):
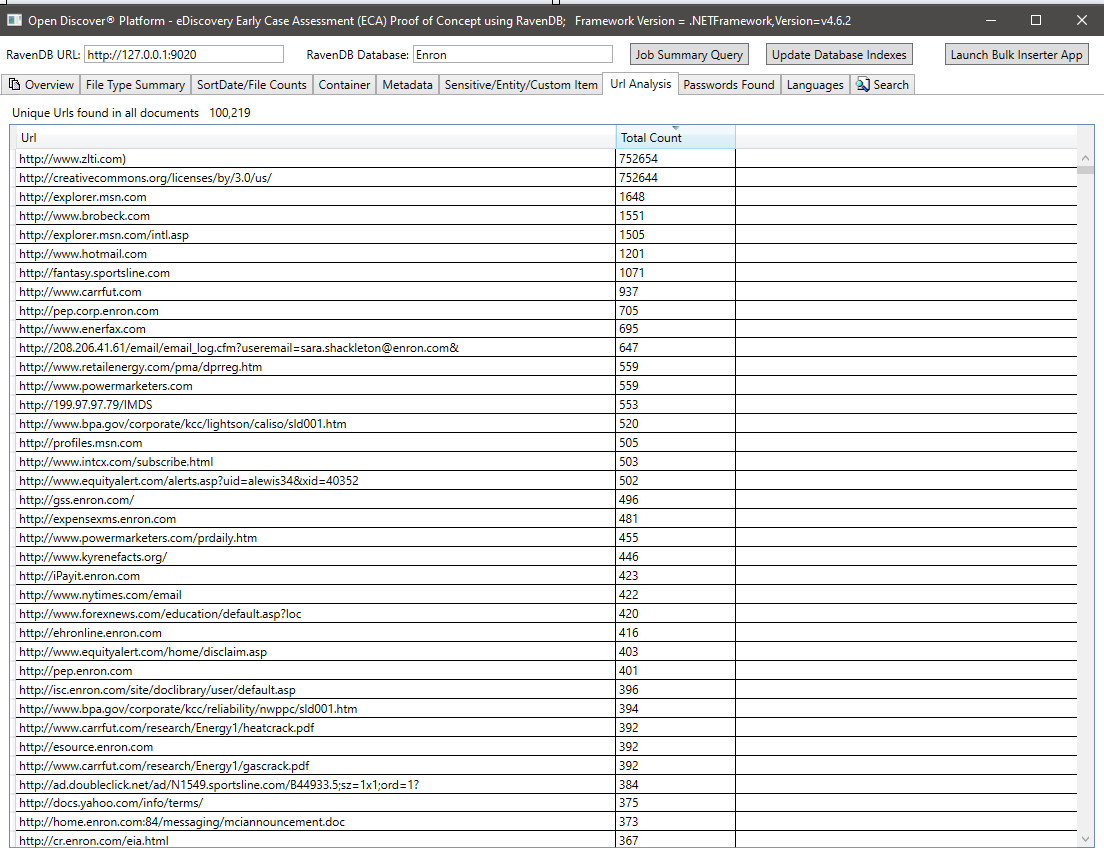
ملخص لجميع كلمات المرور الموجودة في جميع المستندات. تعد كلمات المرور وأسماء المستخدمين فقط 2 من أصل 25 نوعًا مدمجًا "عنصرًا حساسًا" مدعومًا من قبل Open Discover SDK/Platform. يمكن أن تكون بيانات اعتماد كلمة المرور/اسم المستخدم في المستندات بمثابة مخاطر أمان ، ويمكن أيضًا استخدامها لإعادة تشغيل أي وثيقة لها نتيجة معالجة "WrongPassword" (حيث غالبًا ما يقوم الموظفون في نفس الشركة بالبريد الإلكتروني إلى بعض كلمات مرور أخرى إلى مستندات المكتب المشفرة المشتركة):
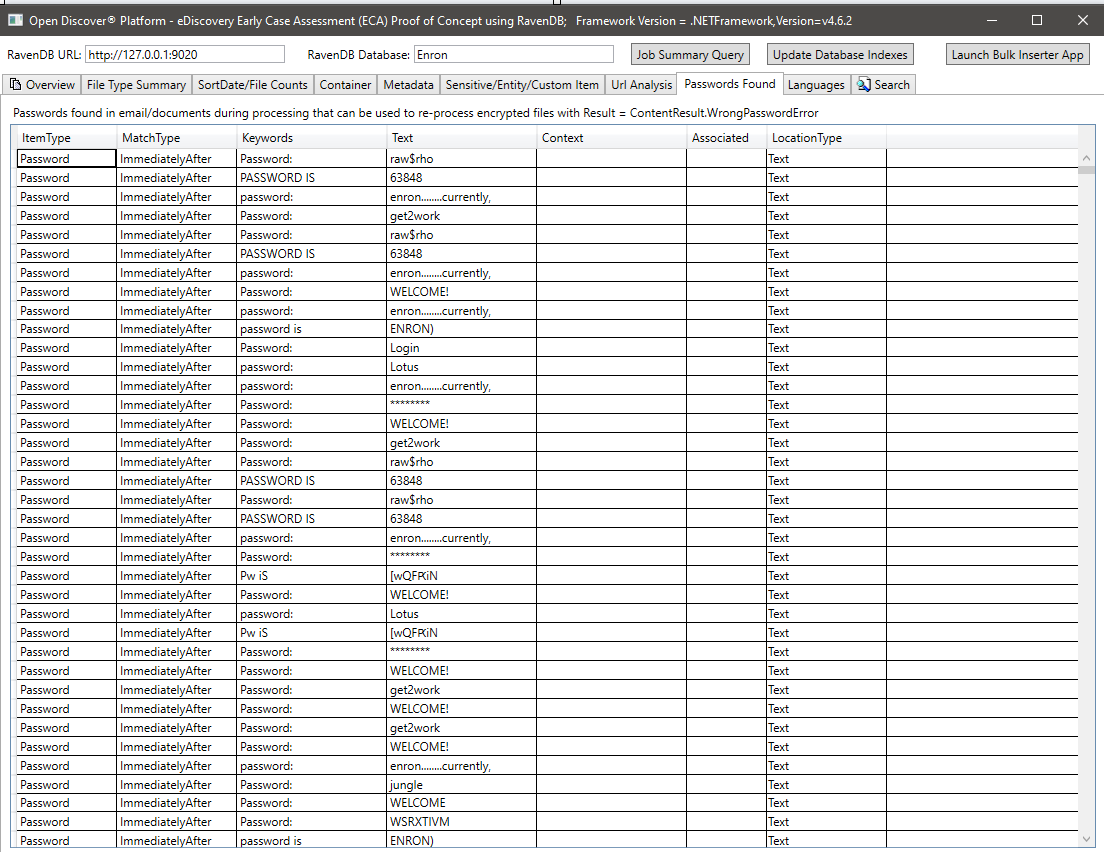
ملخص اللغات المكتشفة في النص المستخرج من المستندات المعالجة:
مثال استعلام البحث الكامل للنص (ملاحظة: Ravendb يدعم استعلامات لوسين):
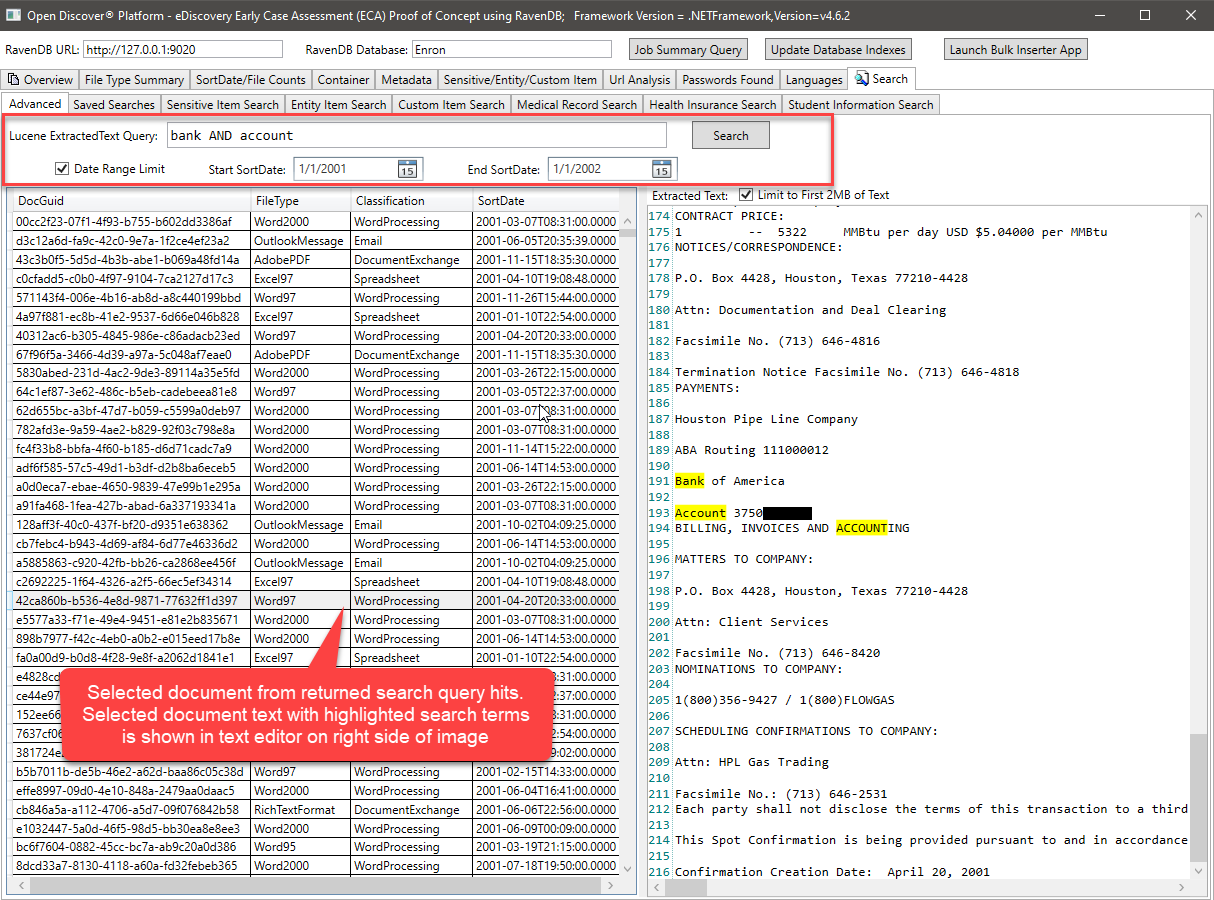
استعلام Lucene أعلاه ، يستفسر حقل ExtractedText ويستخدم (اختياريًا) min/max مستند Sortdate لتصفية نتائج البحث التي تم إرجاعها. سيكون من السهل جدًا أيضًا إضافة تصفية للنتائج حسب تصنيف تنسيق المستند أو تصنيف المستند (WordProcessing/جدول البيانات/البريد الإلكتروني/الخ). يبدو رمز C# الذي يؤدي استعلام Lucene مثل هذا:
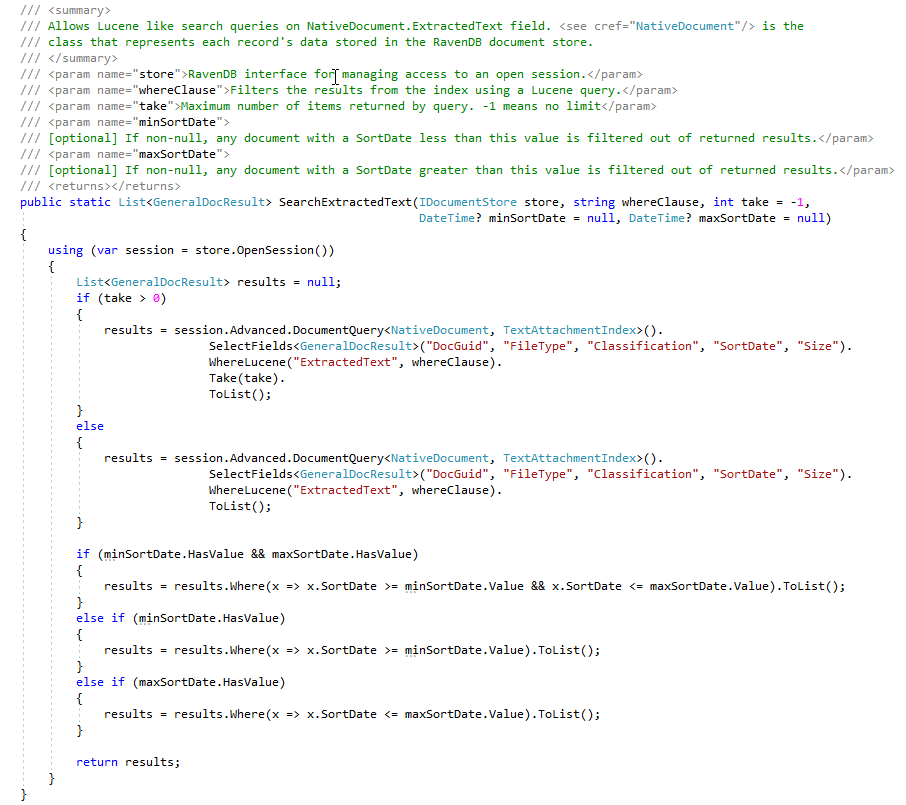
خلال مرحلة ECA ، يحب محامو المراجعة القانونية إنشاء العديد من استعلامات البحث المختلفة للعثور على المستندات المستجيبة. تُظهر لقطة الشاشة أدناه عدد قليل من استعلامات Lucene المحفوظة والنتائج (عدد زيارات المستندات والحجم الكلي للمستندات). لاحظ أن تعداد المستندات في عمليات البحث التي تم إنشاؤها من قبل المستخدم تحتوي على عدد من المستندات المكررة ، على الرغم من أن لدينا فهارس RAVENDB التي تحسب عدد المستندات المكررة ، على هذا الإثبات للمفهوم ، لم نقم بعد "بمثابة" مستندات في متجر المستندات مع علامة تشير إلى الماجستير/التكرار (هذا هو "من قبل المستخدم":
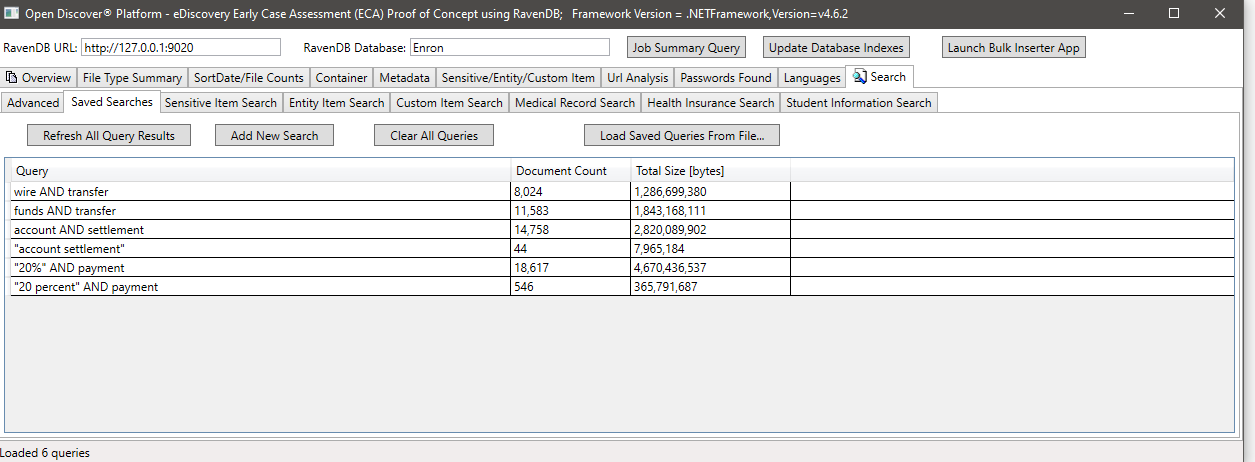
مثال على البحث عن طريق حساس youstype (خاصية على كائنات حساسة يتم اكتشافها تحدد نوع العنصر الحساس) ، في هذا المثال ، نبحث عن جميع المستندات التي لها عنصر حساس من النوع الحساس.
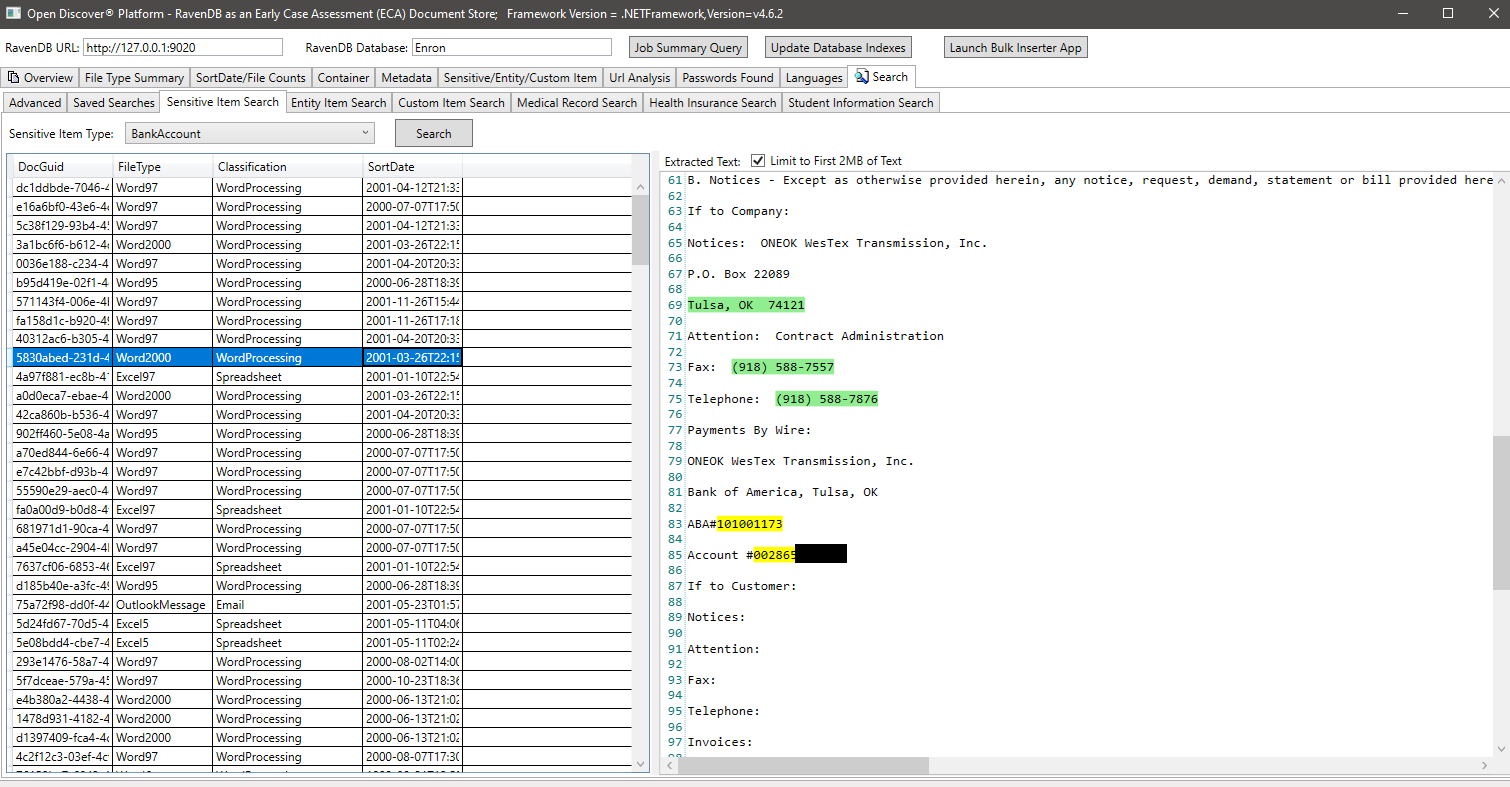
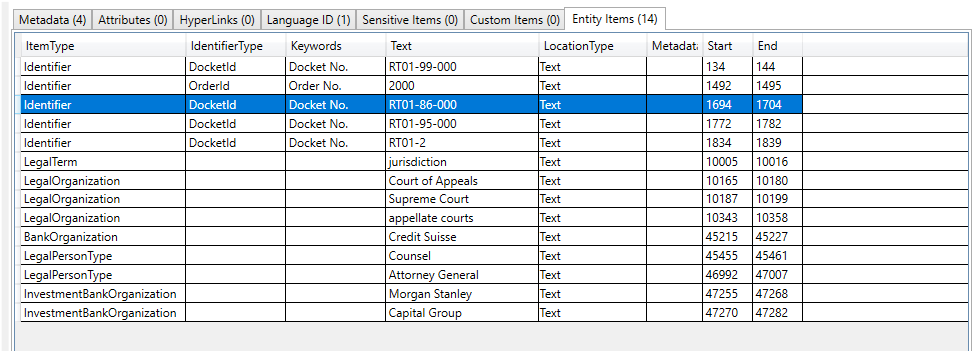
مثال على البحث بواسطة entityitemtype (خاصية على كائنات entityitem المكتشفة التي تحدد نوع عنصر الكيان) ، في هذا المثال ، نبحث عن جميع المستندات التي لها عنصر كيان من النوع entityitemtype.patientNameentry:
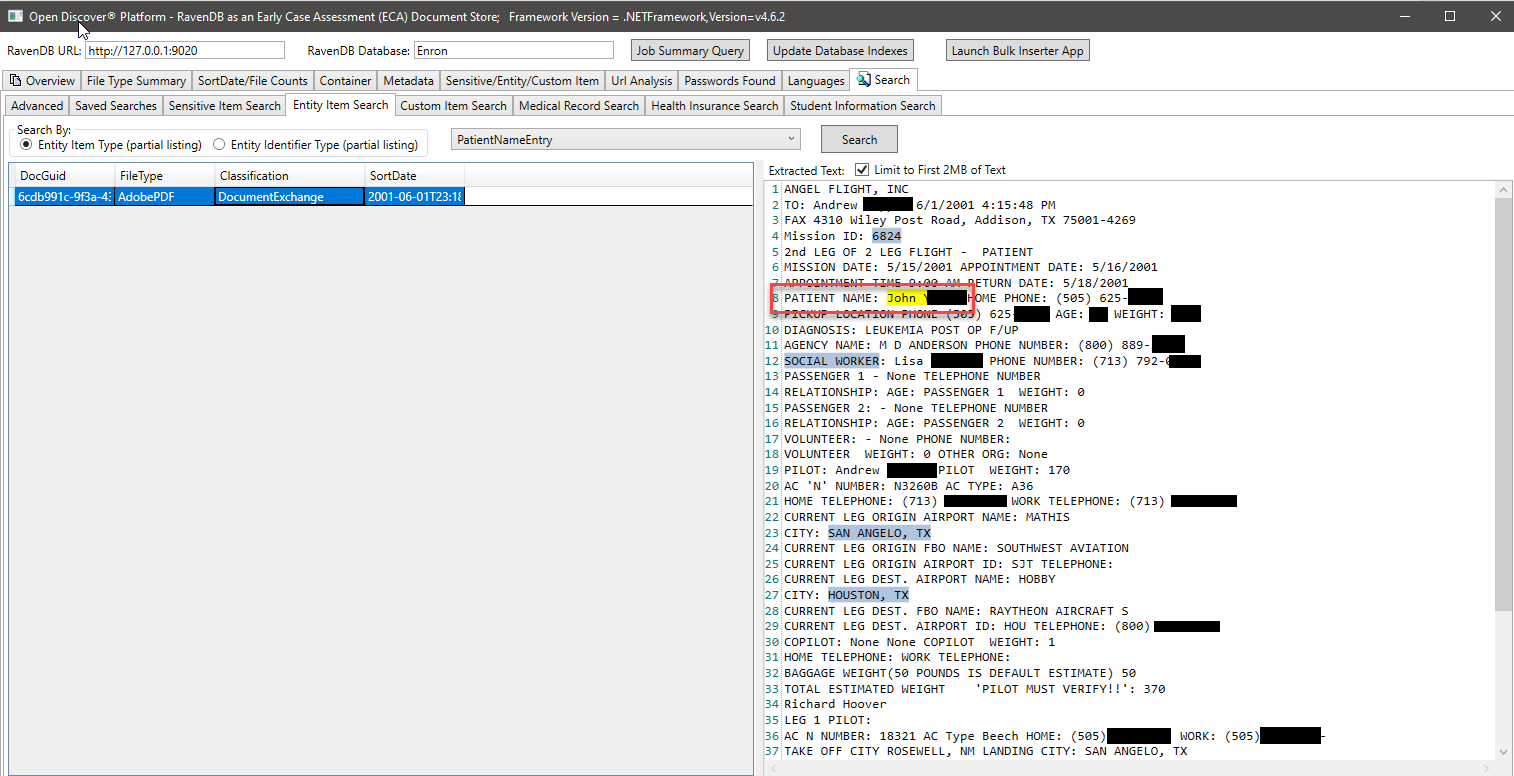
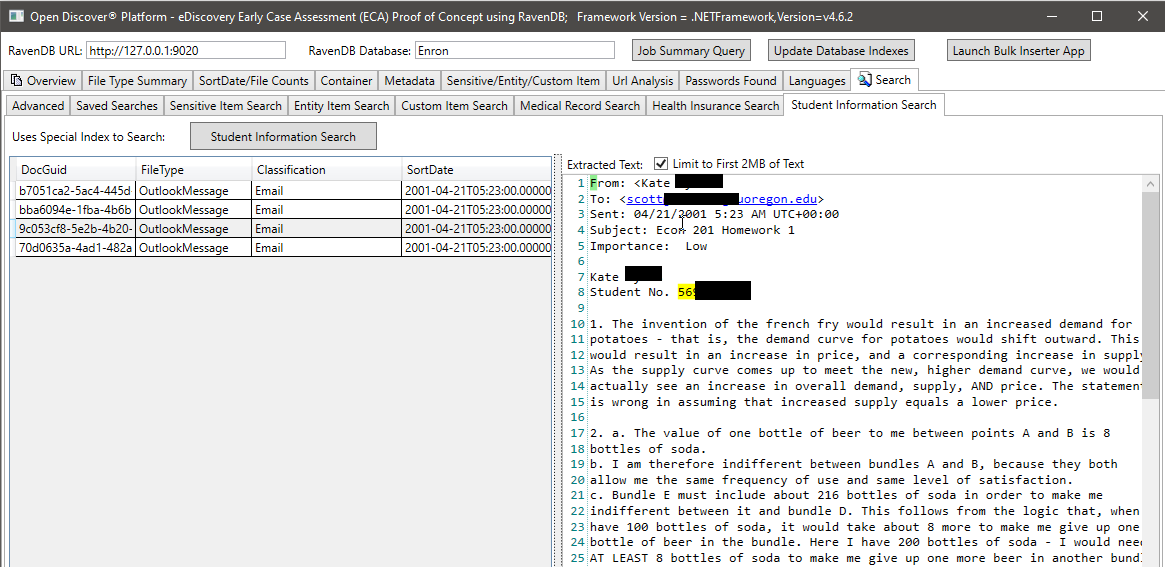
في لقطة الشاشة أدناه ، نستخدم مؤشر RavendB الذي تم إنشاؤه خصيصًا والذي يفهرس Open Open Discover SDK المستخرجة من أنواع الكيانات المتعلقة بمعلومات الطالب للعثور على مستندات قد يكون لها معلومات طالب (في لقطة الشاشة ، ويتم تمييز اسم الطالب ومعرف الطالب ، ويبدو أن معرف الطالب هو رقم ضمان اجتماعي كان شائعًا قبل 2000). وبالمثل ، لدينا فهارس خاصة أخرى للبحث عن السجلات الطبية ومعلومات المريض:
يمكن أن يؤدي إخراج منصة Open Discover® المخزنة في قاعدة بيانات المستندات مثل RAVENDB إلى تطبيقات تقييم الحالة القانوني القانوني (ECA) القوية للغاية. بالإضافة إلى ذلك ، يمكن أيضًا تطوير تطبيقات مثل ما يلي:
إذا كانت دراسة الحالة هذه قد استخدمت قاعدة بيانات علائقية بدلاً من قاعدة بيانات المستندات مثل RavendB ، فستستغرق شهورًا من تصميم مخطط قاعدة البيانات وتطوير إجراءات المتجر وليس الأسبوعين في الوقت الذي استغرقته المؤلف لتطوير دليل تقييم الحالة المبكر (ECA).


