DailyTalk
v0.1.0
在我们的论文中,我们介绍了DailyTalk,这是一种专为文本到语音设计的高质量对话演讲数据集。
摘要:当前文本到语音(TTS)数据集的大多数是单个话语的集合,几乎没有对话方面。在本文中,我们介绍了DailyTalk,这是一个专为对话tts设计的高质量对话语音数据集。我们从开放域对话数据集Dabordialog中取样,修改并记录了2,541个对话,以继承其注释的属性。在我们的数据集之外,我们将先前的工作扩展为我们的基准,在该基线中,非自动回忆TTS的对话中的历史信息为条件。从一般和我们的新型指标的基线实验中,我们表明每日talk可以用作一般的TTS数据集,而且我们的基线还可以代表来自DailyTalk的上下文信息。 DailyTalk数据集和基线代码可自由使用CC-BY-SA 4.0许可证。
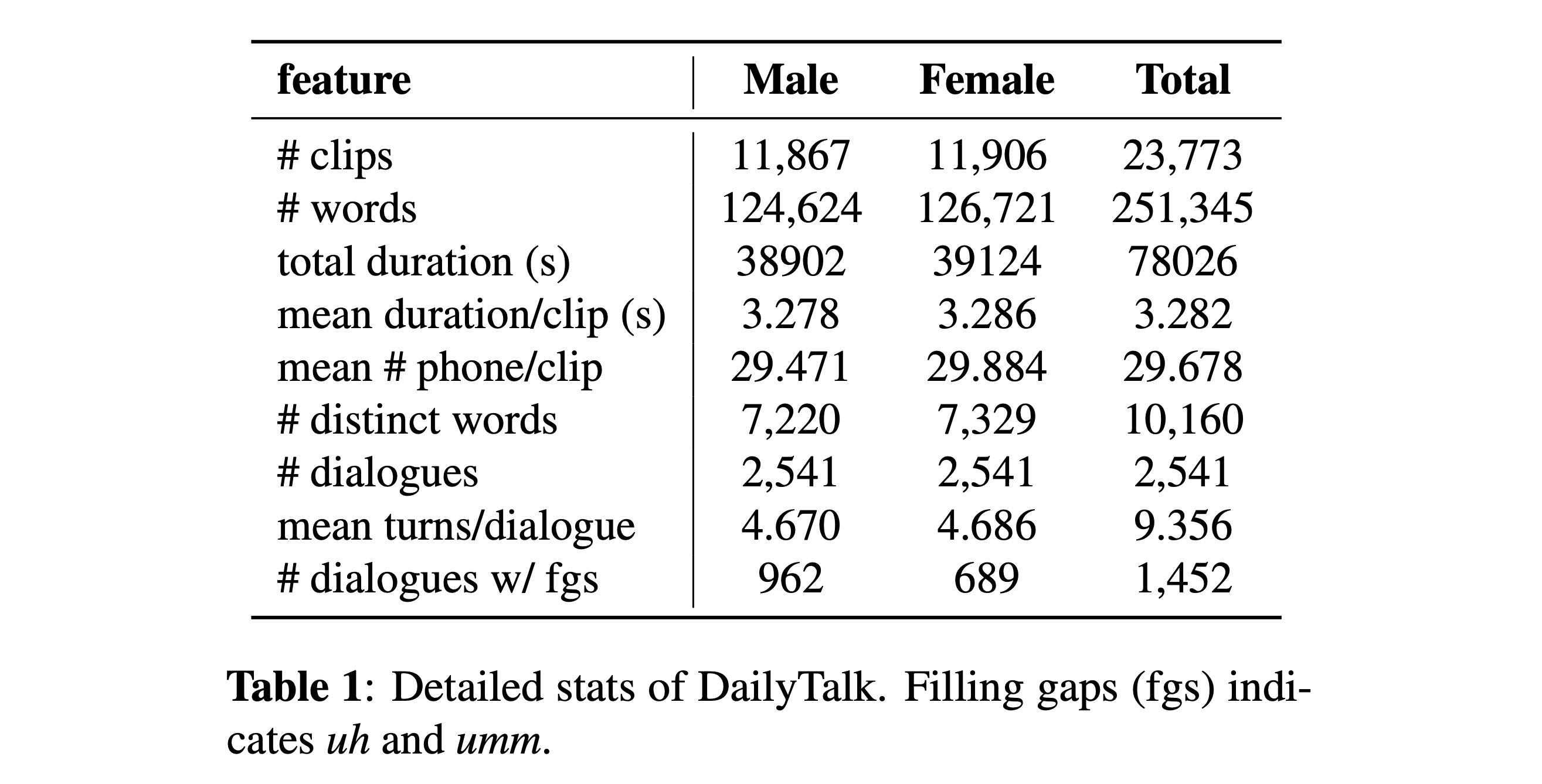
您可以下载我们的数据集。有关详细信息,请参阅统计详细信息。
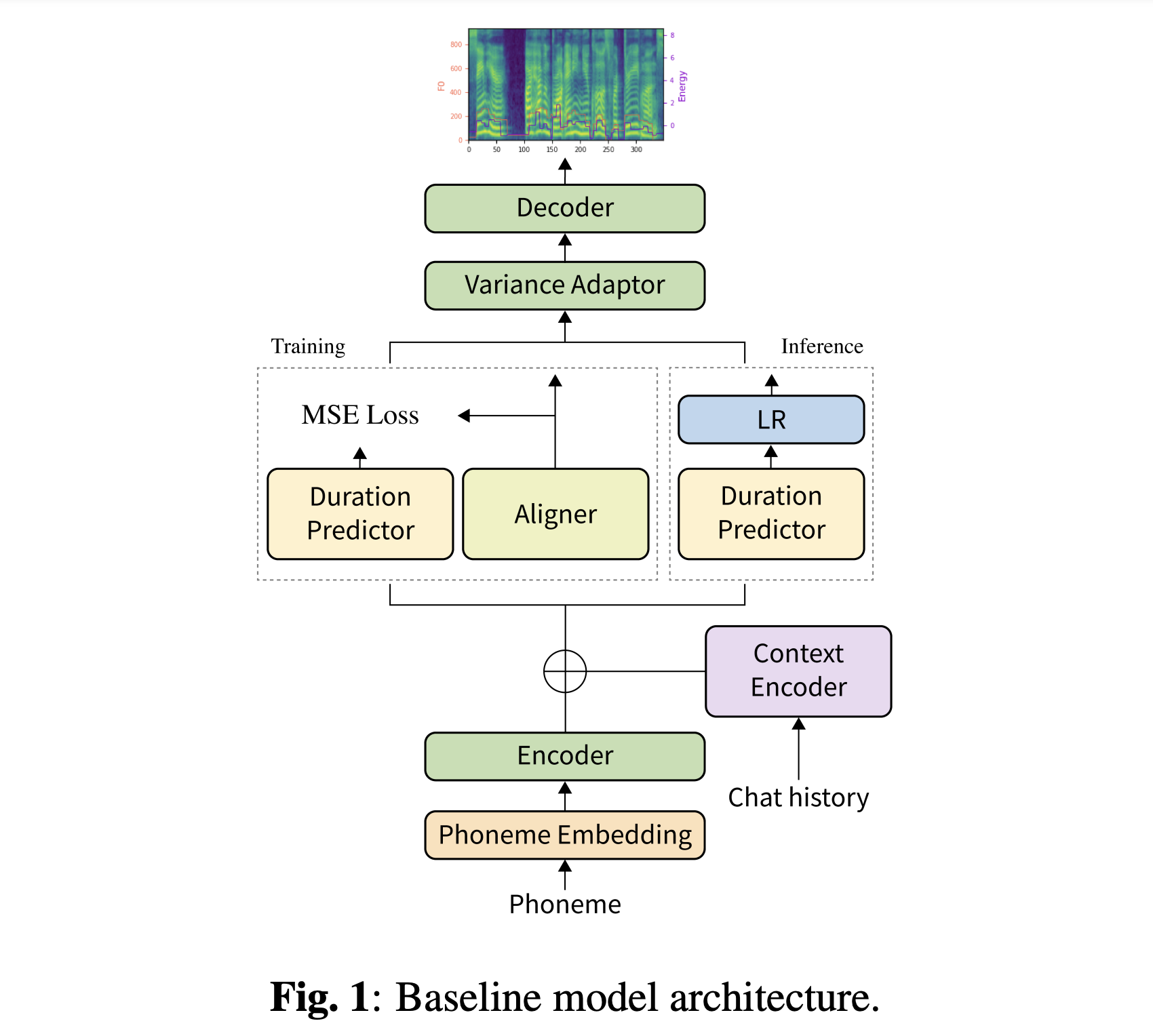
您可以下载我们验证的型号。有两个不同的目录:“ history_none”和“ history_guo”。前者没有历史编码,因此它不是对话性上下文感知的模型。后者具有在语音代理的端到端TTS之后的历史编码(Guo等,2020)。
通过
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]您可以使用
pip3 install -r requirements.txt
此外,还为Docker用户提供Dockerfile 。
您必须下载我们的两个数据集。下载验证的型号,并将其放入output/ckpt/DailyTalk/ 。也在hifigan文件夹中的unzip generator_LJSpeech.pth.tar或generator_universal.pth.tar 。在变压器构建块和历史编码类型下,对模型进行了无监督的持续时间建模培训。
仅支持批次推理,因为转弯的产生可能需要对话的上下文历史。尝试
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
综合preprocessed_data/DailyTalk/val_*.txt中的所有话语。
对于带有外部扬声器嵌入式的多扬声器TT ,下载cacknn softmax+三胞胎预算的Philipperemy DeepSpeaker的扬声器嵌入模型,并将其定位在./deepspeaker/pretrained_models/中。请注意,我们验证的模型未接受此培训(他们接受了使用speaker_embedder: "none" )。
跑步
python3 prepare_align.py --dataset DailyTalk
用于一些准备工作。
对于强制对准,蒙特利尔强制对准器(MFA)用于获得发音和音素序列之间的比对。此处提供了数据集的预提取对齐。您必须在preprocessed_data/DailyTalk/TextGrid/中解压缩文件。或者,您可以自己运行对准器。请注意,我们验证的模型未接受有监督的持续时间建模培训(他们接受了learn_alignment: True培训)。
之后,通过
python3 preprocess.py --dataset DailyTalk
培训您的模型
python3 train.py --dataset DailyTalk
有用的选项:
--use_amp参数附加到上述命令。CUDA_VISIBLE_DEVICES=<GPU_IDs> 。使用
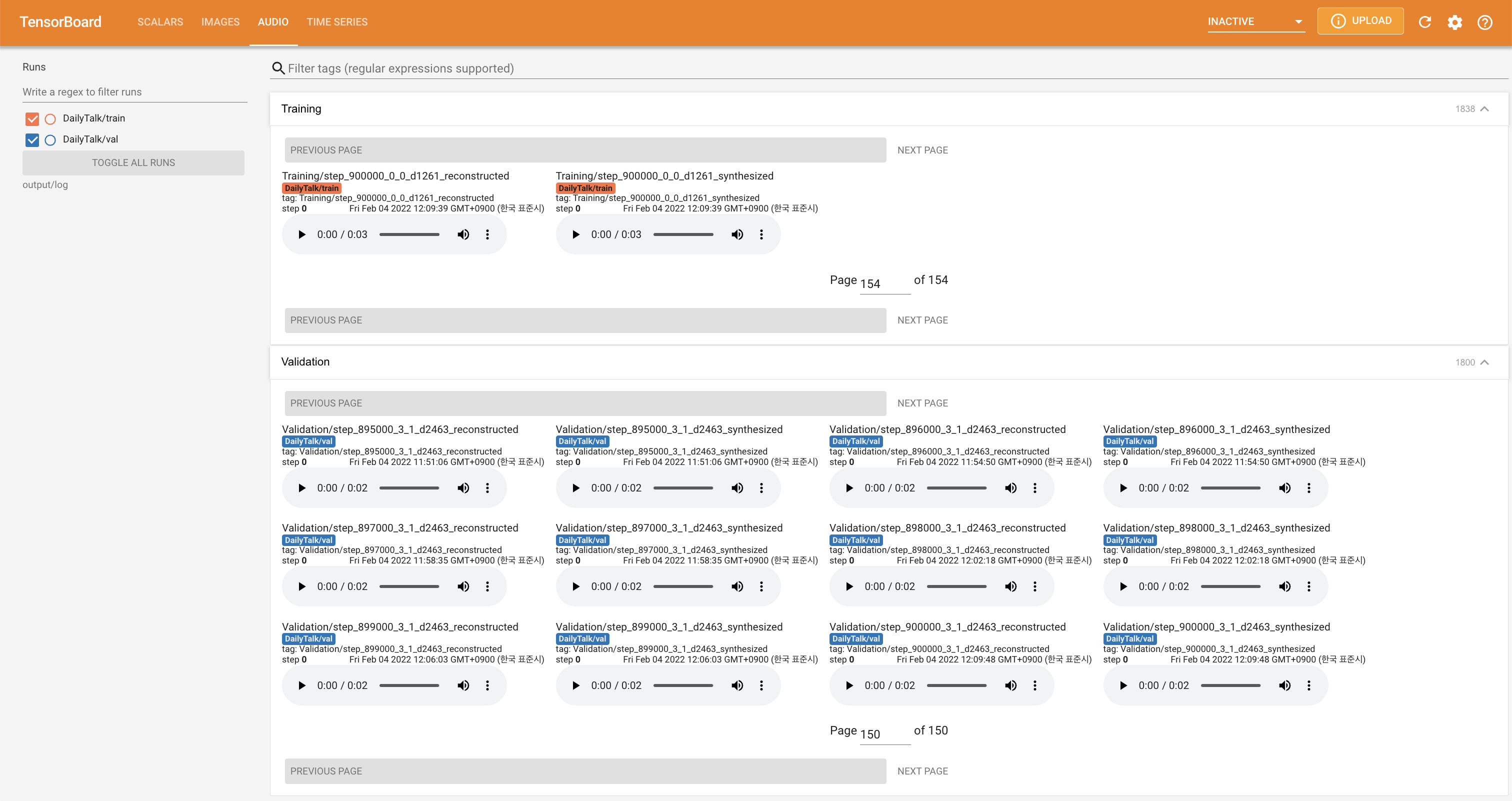
tensorboard --logdir output/log
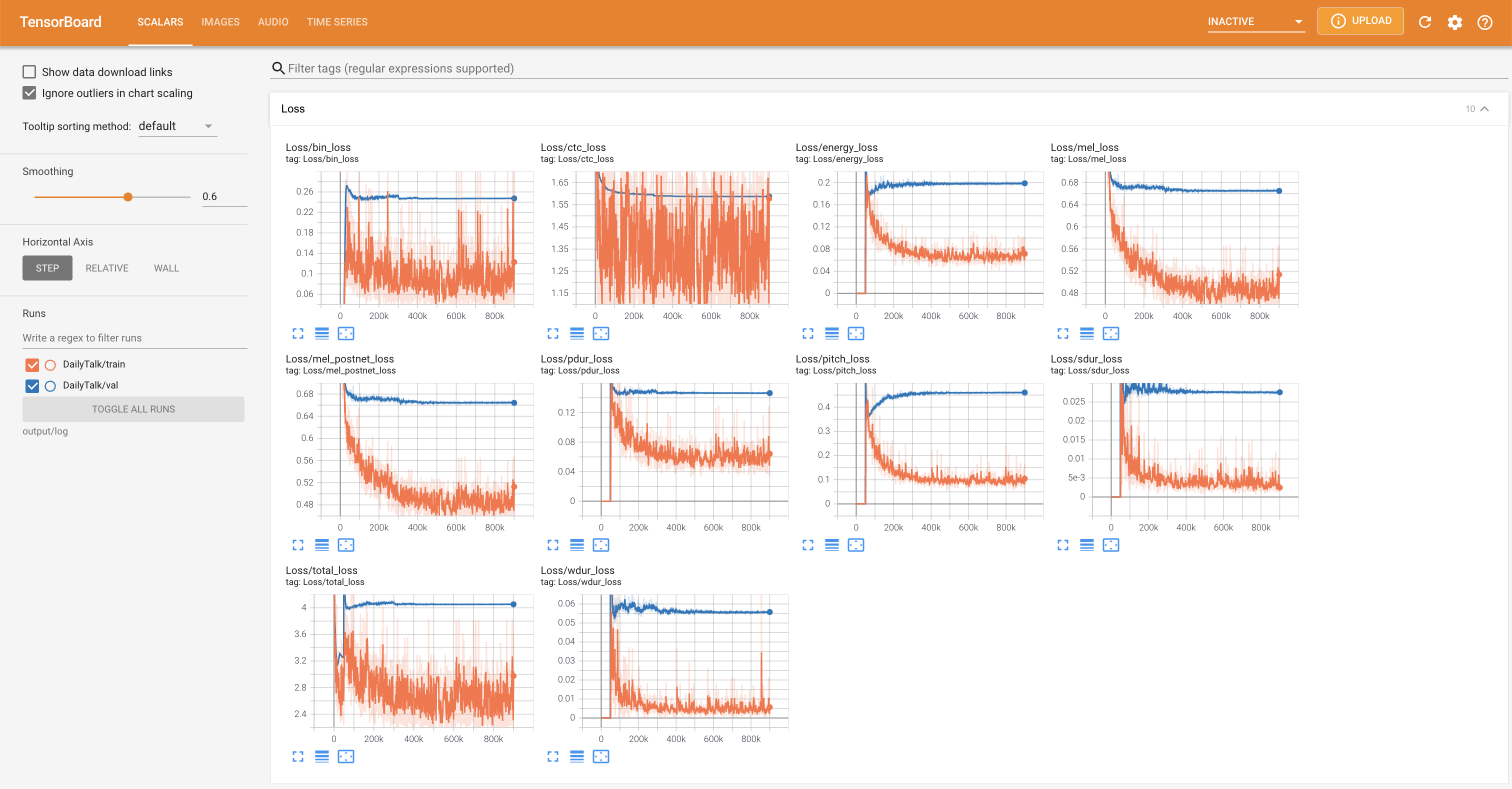
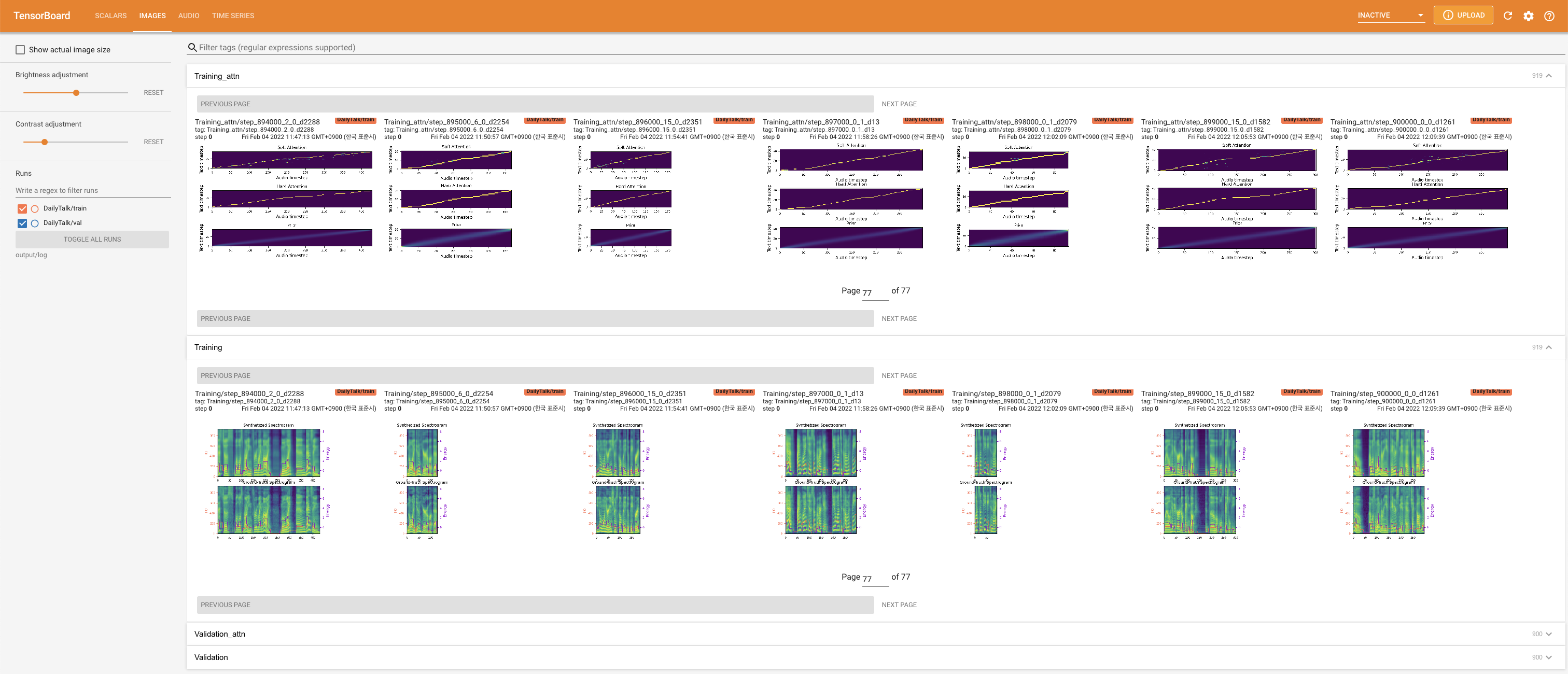
在您的本地主机上提供张板。显示了损耗曲线,合成的MEL光谱图和音频。
'none'和'DeepSpeaker'之间)进行切换。如果您想使用我们的数据集和代码或参考我们的论文,请如下引用。
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
这项工作是根据创意共享归因 - 共享4.0国际许可证获得许可的。


