DailyTalk
v0.1.0
Dans notre article, nous introduisons DailyTalk, un ensemble de données de parole conversationnel de haute qualité conçu pour le texte vocable.
Résumé: La majorité des ensembles de données actuels de texte vocale (TTS), qui sont des collections d'énoncés individuels, contiennent peu d'aspects conversationnels. Dans cet article, nous introduisons DailyTalk, un ensemble de données de parole conversationnel de haute qualité conçu pour les TT conversationnels. Nous avons échantillonné, modifié et enregistré 2 541 dialogues de l'ensemble de données de dialogue de domaine ouvert quotidiennement héritant de ses attributs annotés. En plus de notre ensemble de données, nous étendons les travaux antérieurs comme notre base, où un TTS non autorégressif est conditionné aux informations historiques dans un dialogue. D'après l'expérience de base avec les mesures générales et nos nouvelles, nous montrons que DailyTalk peut être utilisé comme ensemble de données TTS général, et plus que cela, notre ligne de base peut représenter des informations contextuelles de DailyTalk. L'ensemble de données DailyTalk et le code de base sont disponibles gratuitement pour une utilisation académique avec la licence CC-BY-SA 4.0.
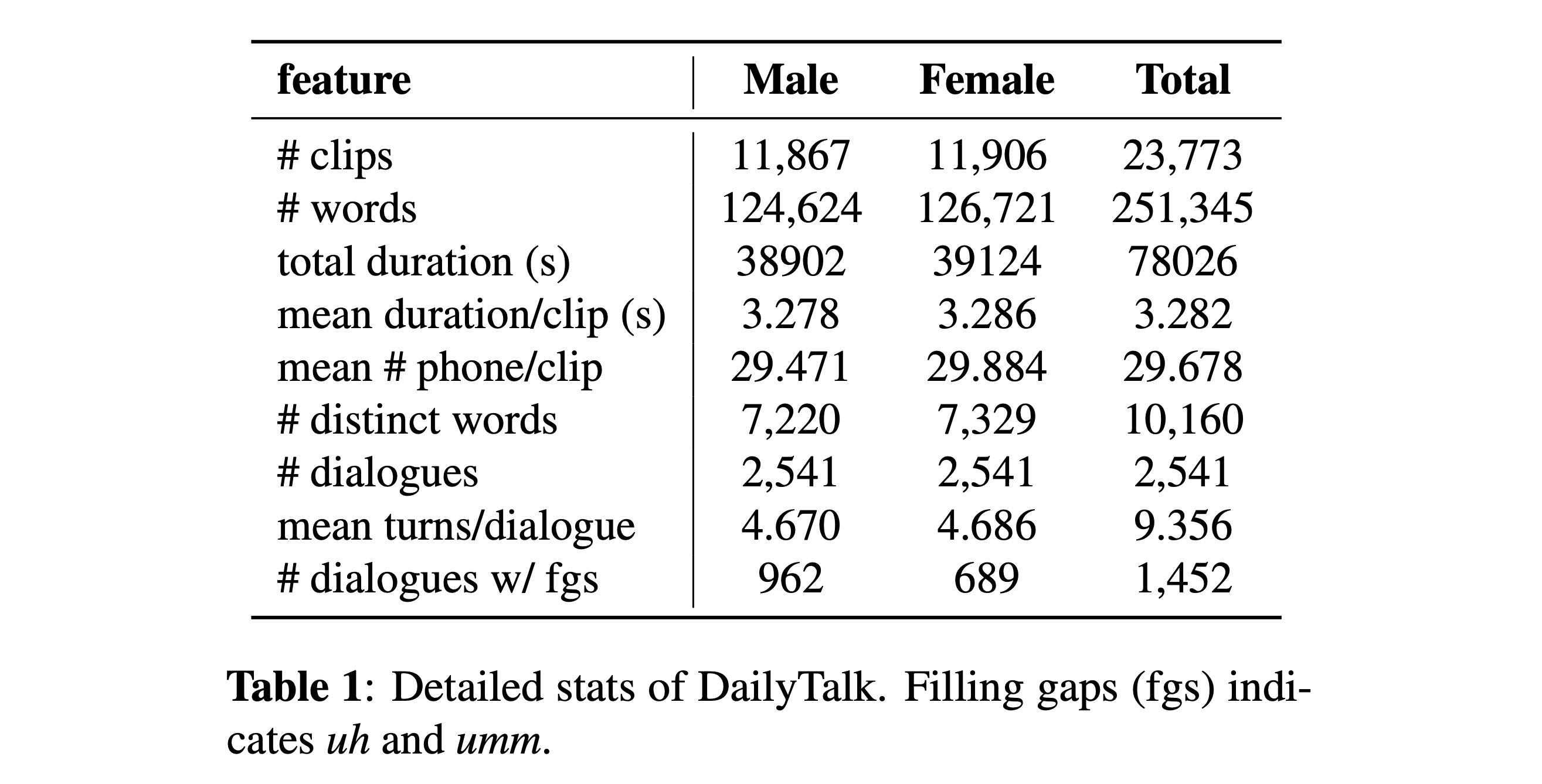
Vous pouvez télécharger notre ensemble de données. Veuillez vous référer aux détails des statistiques pour plus de détails.
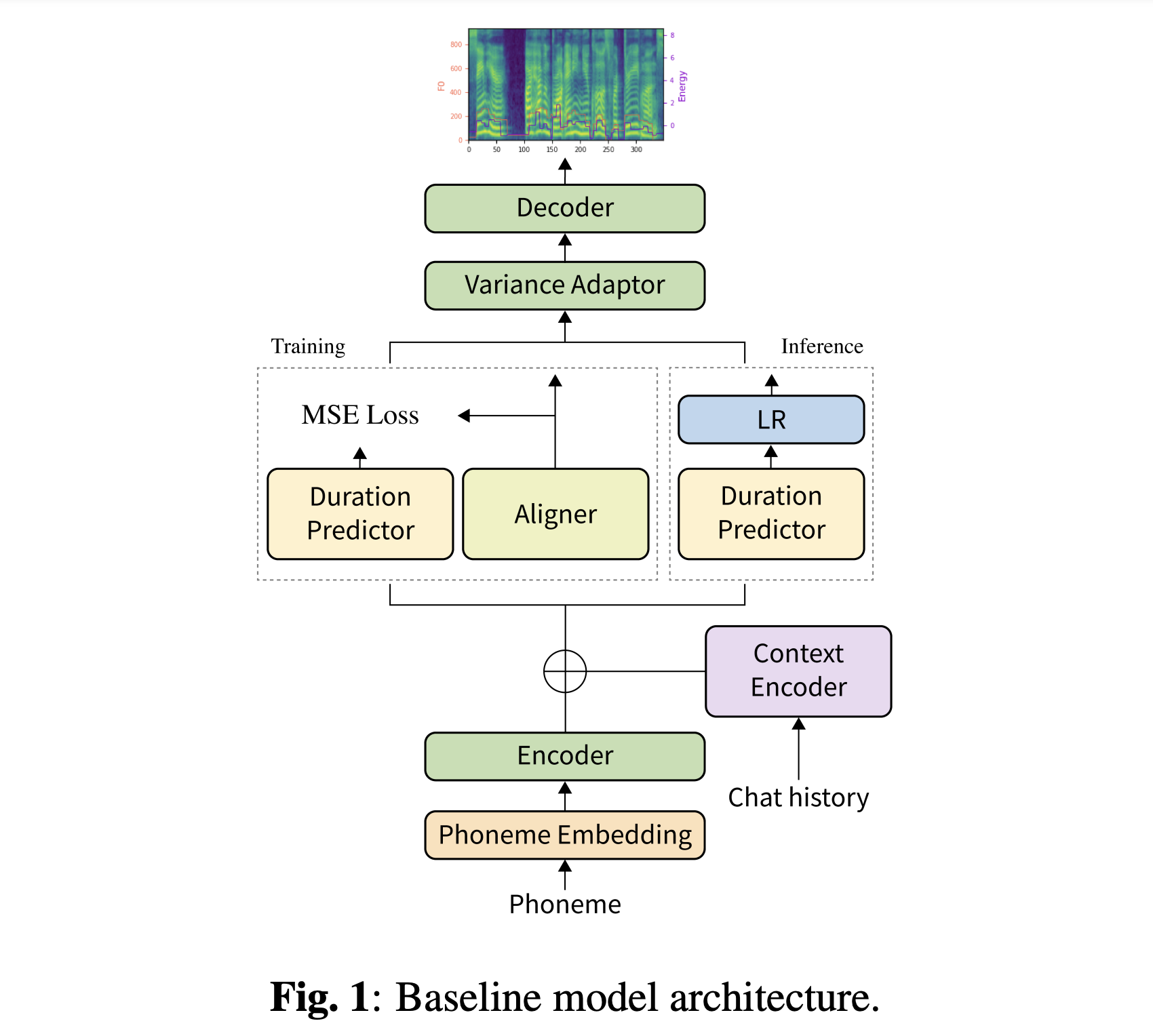
Vous pouvez télécharger nos modèles pré-entraînés. Il y a deux répertoires différents: 'History_none' et 'History_Guo'. Le premier n'a pas d'encodages historiques pour qu'il ne s'agisse pas d'un modèle de contexte conversationnel. Ce dernier a des encodages historiques après des TT de bout en bout conversationnels pour l'agent vocal (Guo et al., 2020).
Basculer le type d'encodages d'histoire par
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]Vous pouvez installer les dépendances Python avec
pip3 install -r requirements.txt
De plus, Dockerfile est fourni pour les utilisateurs Docker .
Vous devez télécharger à la fois notre ensemble de données. Téléchargez des modèles pré-entraînés et mettez-les dans output/ckpt/DailyTalk/ . Unzip generator_LJSpeech.pth.tar ou generator_universal.pth.tar dans le dossier HIFIGAN. Les modèles sont formés avec une modélisation de durée non supervisée sous un bloc de construction du transformateur et les types d'encodage d'historique.
Seule l'inférence par lots est prise en charge car la génération d'un tour peut nécessiter une histoire contextuelle de la conversation. Essayer
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
Pour synthétiser toutes les énoncés dans preprocessed_data/DailyTalk/val_*.txt .
Pour un TTS multi-haut-parleurs avec un intérêt de haut-parleur externe, téléchargez Rescnn Softmax + Triplet Pretraind Model of Philippermy's DeepPeaker pour le haut-parleur incorpore et le localisez dans ./deepspeaker/pretrained_models/ . Veuillez noter que nos modèles pré-entraînés ne sont pas formés avec cela (ils sont formés avec speaker_embedder: "none" ).
Courir
python3 prepare_align.py --dataset DailyTalk
pour certaines préparatifs.
Pour l'alignement forcé, l'aligneur forcé de Montréal (MFA) est utilisé pour obtenir les alignements entre les énoncés et les séquences de phonèmes. Les alignements pré-extractés pour les ensembles de données sont fournis ici. Vous devez décompresser les fichiers dans preprocessed_data/DailyTalk/TextGrid/ . Alternativement, vous pouvez exécuter l'aligneur par vous-même. Veuillez noter que nos modèles pré-entraînés ne sont pas formés avec une modélisation de durée supervisée (ils sont formés avec learn_alignment: True ).
Après cela, exécutez le script de prétraitement par
python3 preprocess.py --dataset DailyTalk
Former votre modèle avec
python3 train.py --dataset DailyTalk
Options utiles:
--use_amp sur la commande ci-dessus.CUDA_VISIBLE_DEVICES=<GPU_IDs> au début de la commande ci-dessus.Utiliser
tensorboard --logdir output/log
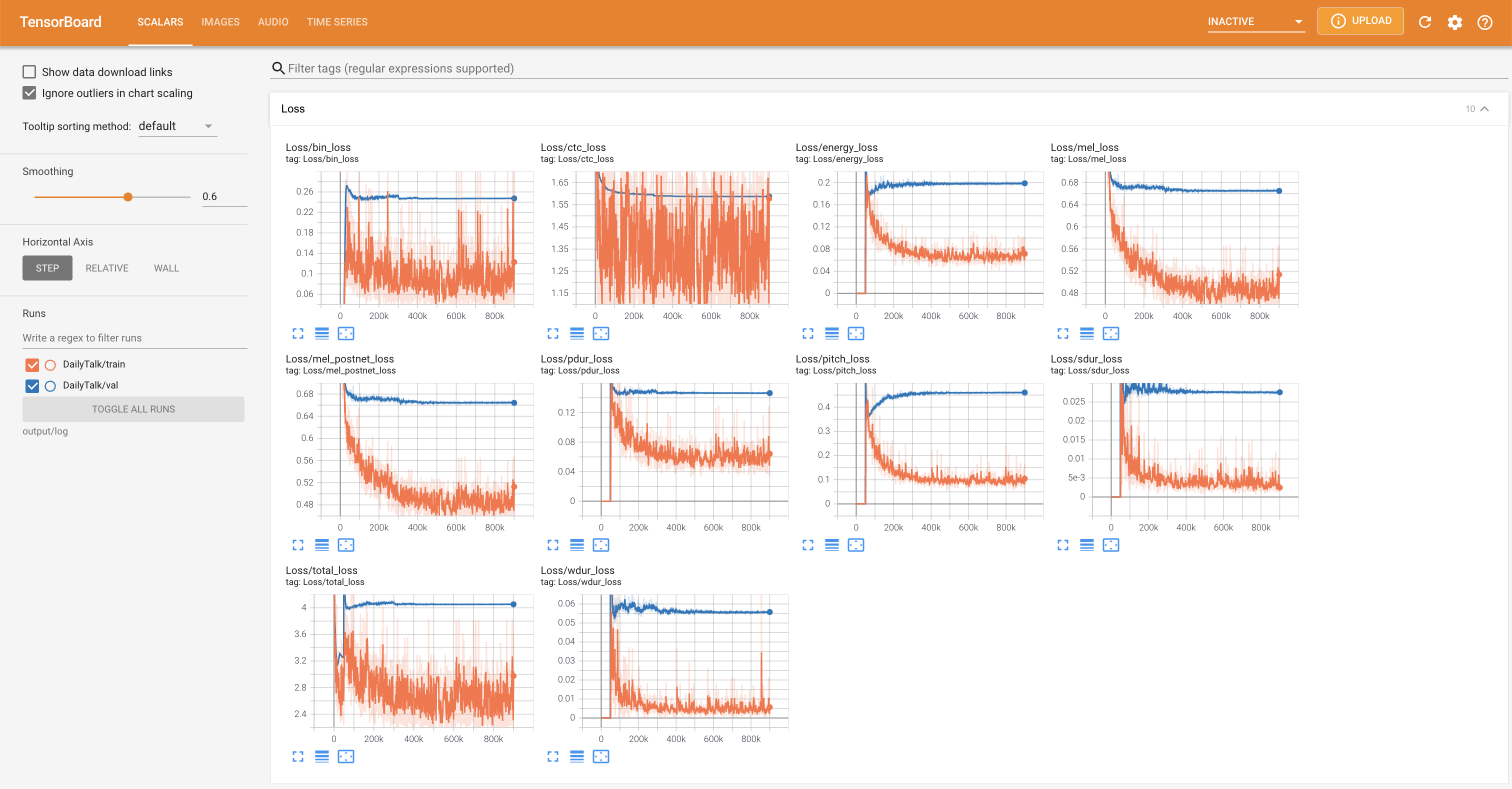
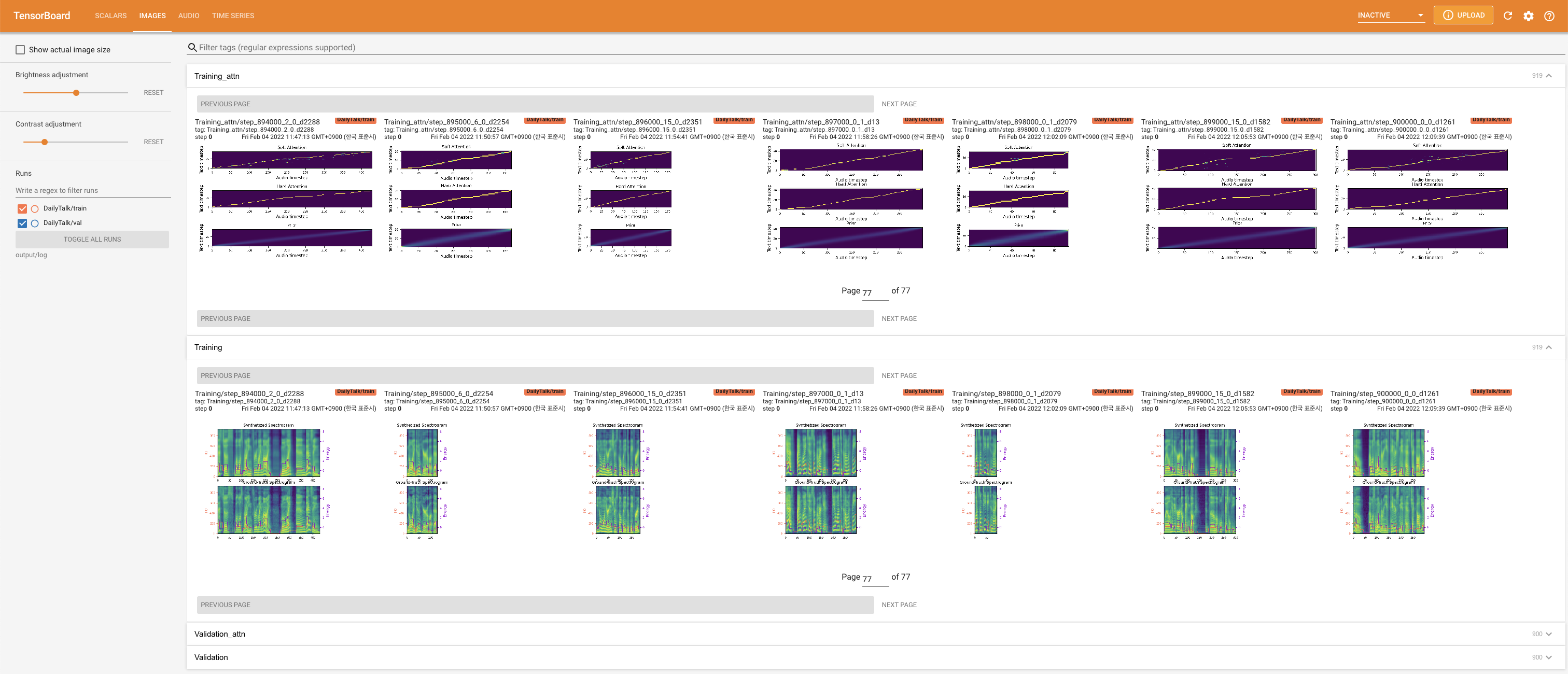
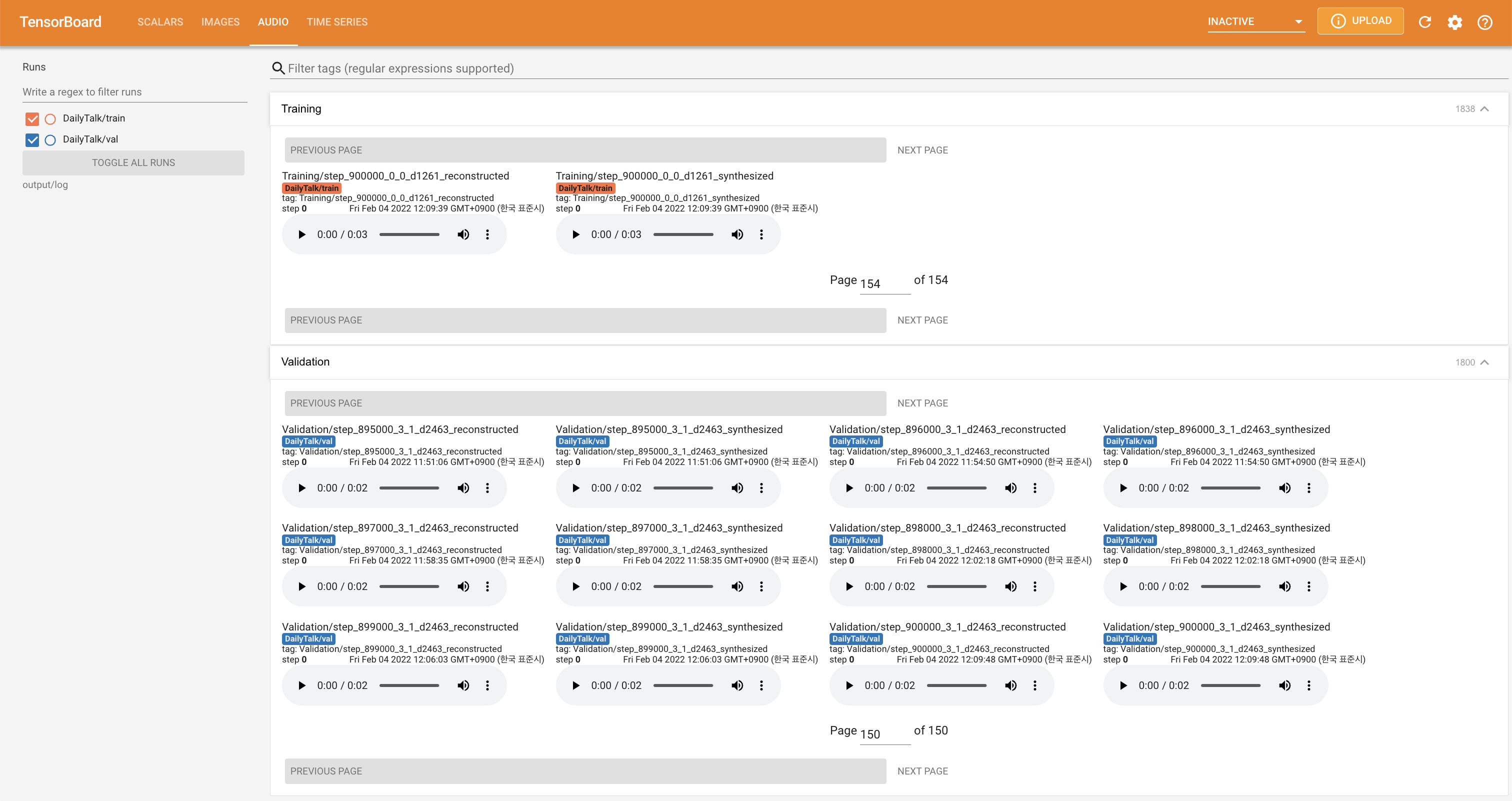
pour servir Tensorboard sur votre hôte local. Les courbes de perte, les spectrogrammes de MEL synthétisés et les audios sont affichés.
'none' et 'DeepSpeaker' ).Si vous souhaitez utiliser notre ensemble de données et notre code ou vous référer à notre article, veuillez citer comme suit.
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
Ce travail est concédé sous licence Creative Commons Attribution-Sharealike 4.0.


