DailyTalk
v0.1.0
Em nosso artigo, apresentamos o DailyTalk, um conjunto de dados de fala conversacional de alta qualidade projetado para falar em fala.
Resumo: A maioria dos conjuntos de dados atuais de texto em fala (TTS), que são coleções de enunciados individuais, contém poucos aspectos de conversação. Neste artigo, introduzimos o DailyTalk, um conjunto de dados de fala conversacional de alta qualidade projetado para TTS de conversação. Amostramos, modificamos e registramos 2.541 diálogos do conjunto de dados de diálogo de domínio aberto DailyDialog herdando seus atributos anotados. No topo do nosso conjunto de dados, estendemos o trabalho anterior como nossa linha de base, onde um TTS não autorregressivo está condicionado a informações históricas em um diálogo. A partir do experimento de linha de base com as métricas gerais e novas, mostramos que o DailyTalk pode ser usado como um conjunto de dados TTS em geral e, mais do que isso, nossa linha de base pode representar informações contextuais do DailyTalk. O conjunto de dados DailyTalk e o código da linha de base estão disponíveis gratuitamente para uso acadêmico com licença CC-BY-SA 4.0.
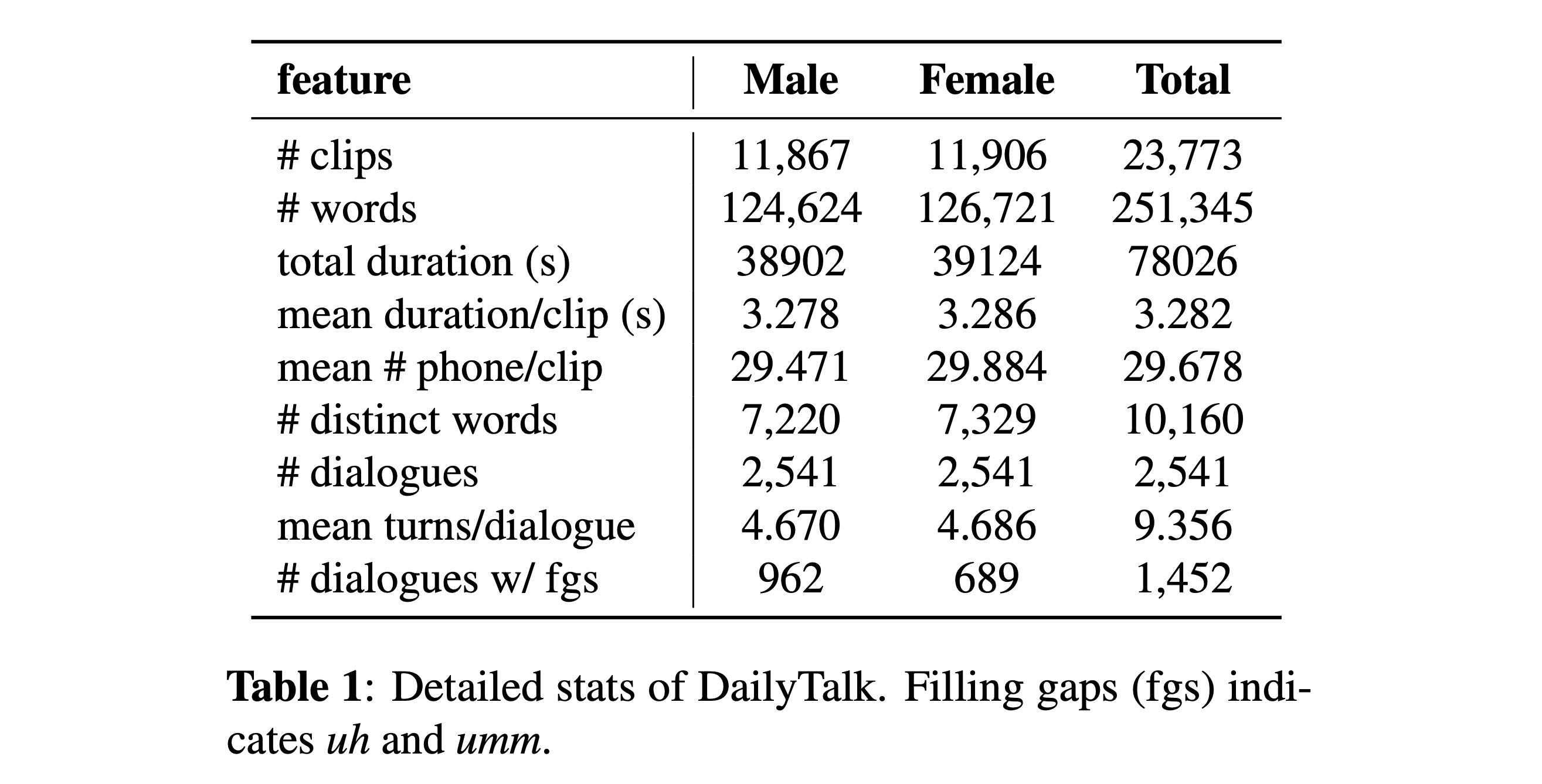
Você pode baixar nosso conjunto de dados. Consulte os detalhes da estatística para obter detalhes.
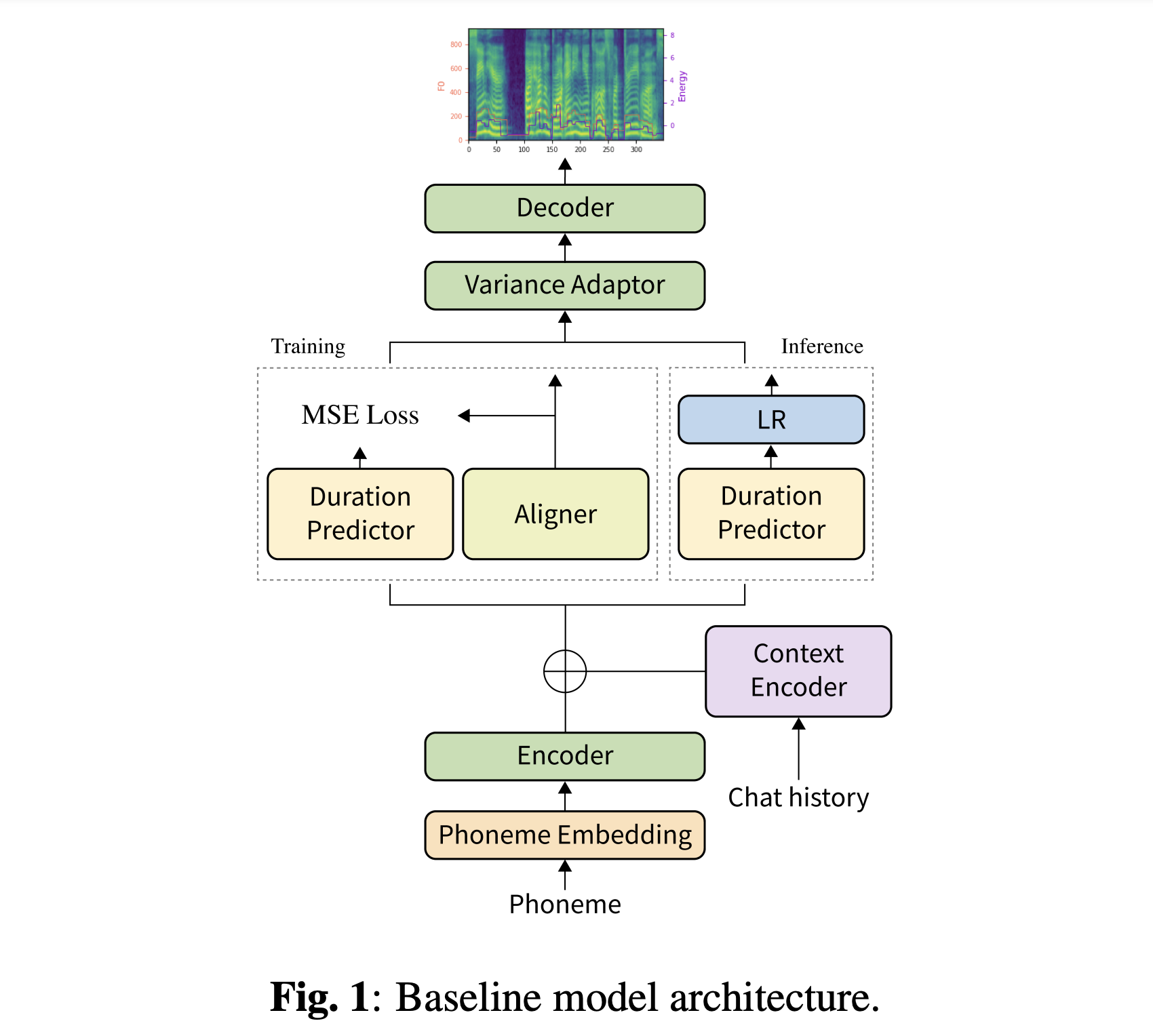
Você pode fazer o download de nossos modelos pré -treinados. Existem dois diretórios diferentes: 'History_None' e 'History_Guo'. O primeiro não possui codificações históricas para que não seja um modelo de conversação com conhecimento de contexto. Este último tem codificações históricas após TTS de ponta a ponta conversacional para agente de voz (Guo et al., 2020).
Alternar o tipo de codificação de história por
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]Você pode instalar as dependências do Python com
pip3 install -r requirements.txt
Além disso, Dockerfile é fornecido para usuários Docker .
Você precisa baixar nosso conjunto de dados. Faça o download de modelos pré -tenhados e coloque -os em output/ckpt/DailyTalk/ . Também UNZIP generator_LJSpeech.pth.tar ou generator_universal.pth.tar na pasta Hifigan. Os modelos são treinados com modelagem de duração não supervisionada no bloco de construção de transformadores e os tipos de codificação de história.
Somente a inferência em lote é suportada, pois a geração de uma virada pode precisar de histórico contextual da conversa. Tentar
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
Para sintetizar todos os enunciados em preprocessed_data/DailyTalk/val_*.txt .
Para um TTS multi-falante com o orador externo incorporador, faça o download do Modelo de Pré-Priendido de Rescnn Softmax+Tripleto do Philipperemy Deepaker para o alto-falante incorporando e localize-o em ./deepspeaker/pretrained_models/ . Observe que nossos modelos pré -teriados não são treinados com isso (eles são treinados com speaker_embedder: "none" ).
Correr
python3 prepare_align.py --dataset DailyTalk
para alguns preparativos.
Para o alinhamento forçado, o alinhador forçado de Montreal (MFA) é usado para obter os alinhamentos entre os enunciados e as seqüências de fonemas. Alinhamentos pré-extraídos para os conjuntos de dados são fornecidos aqui. Você precisa descompactar os arquivos em preprocessed_data/DailyTalk/TextGrid/ . Como alternativa, você pode executar o alinhador sozinho. Observe que nossos modelos pré -ridicularizados não são treinados com modelagem de duração supervisionada (eles são treinados com learn_alignment: True ).
Depois disso, execute o script de pré -processamento por
python3 preprocess.py --dataset DailyTalk
Treine seu modelo com
python3 train.py --dataset DailyTalk
Opções úteis:
--use_amp argumento do comando acima.CUDA_VISIBLE_DEVICES=<GPU_IDs> no início do comando acima.Usar
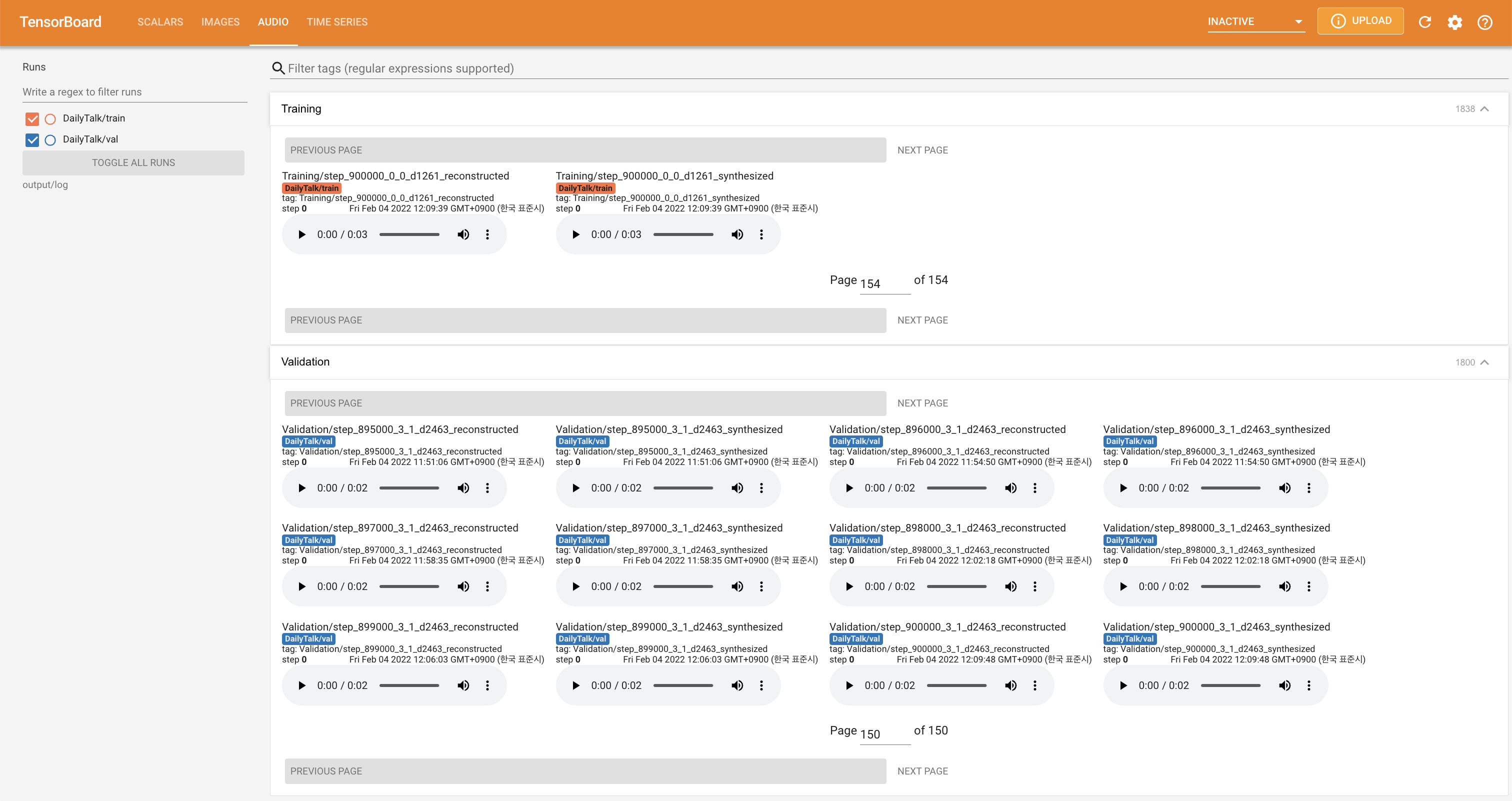
tensorboard --logdir output/log
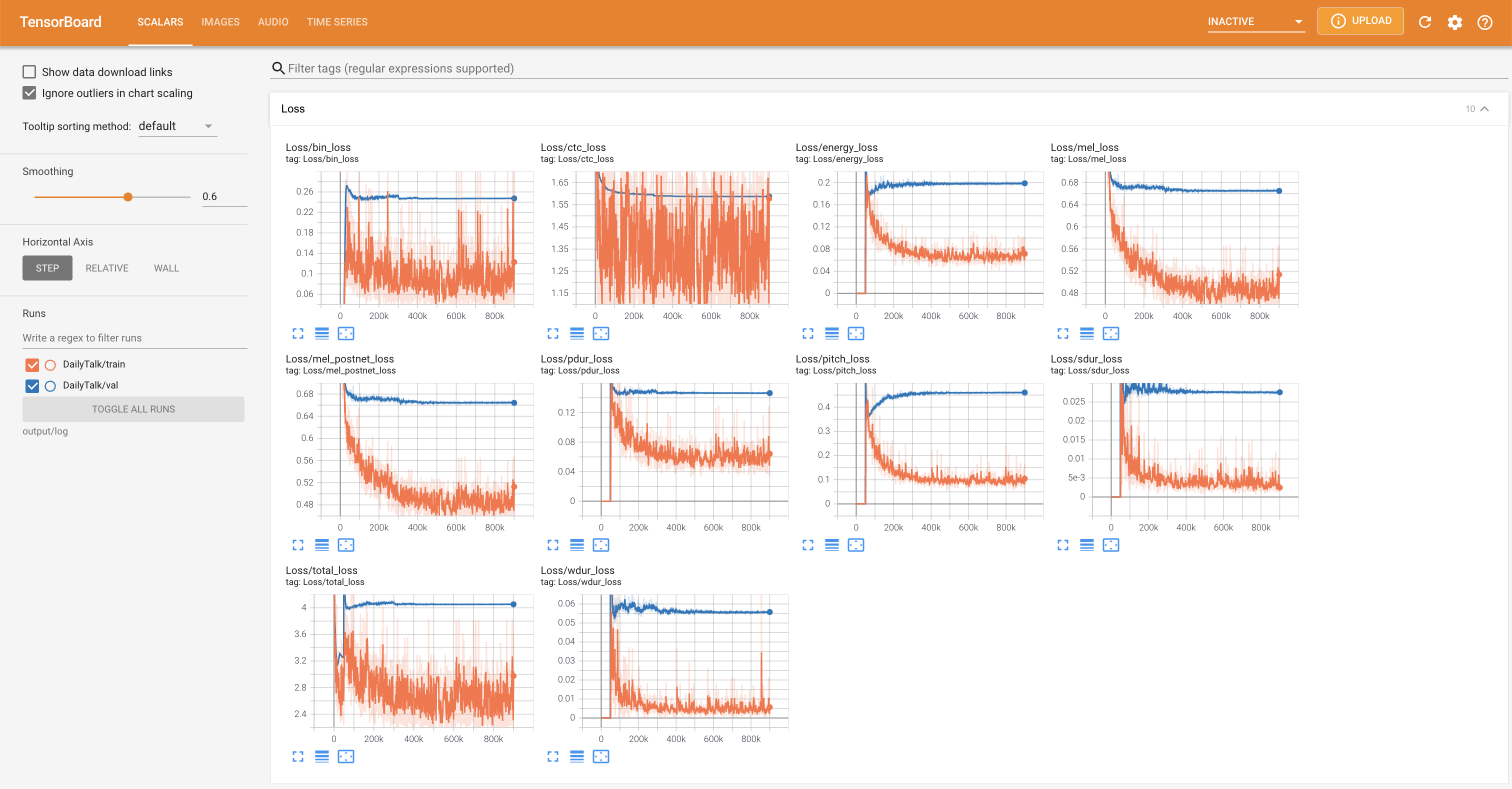
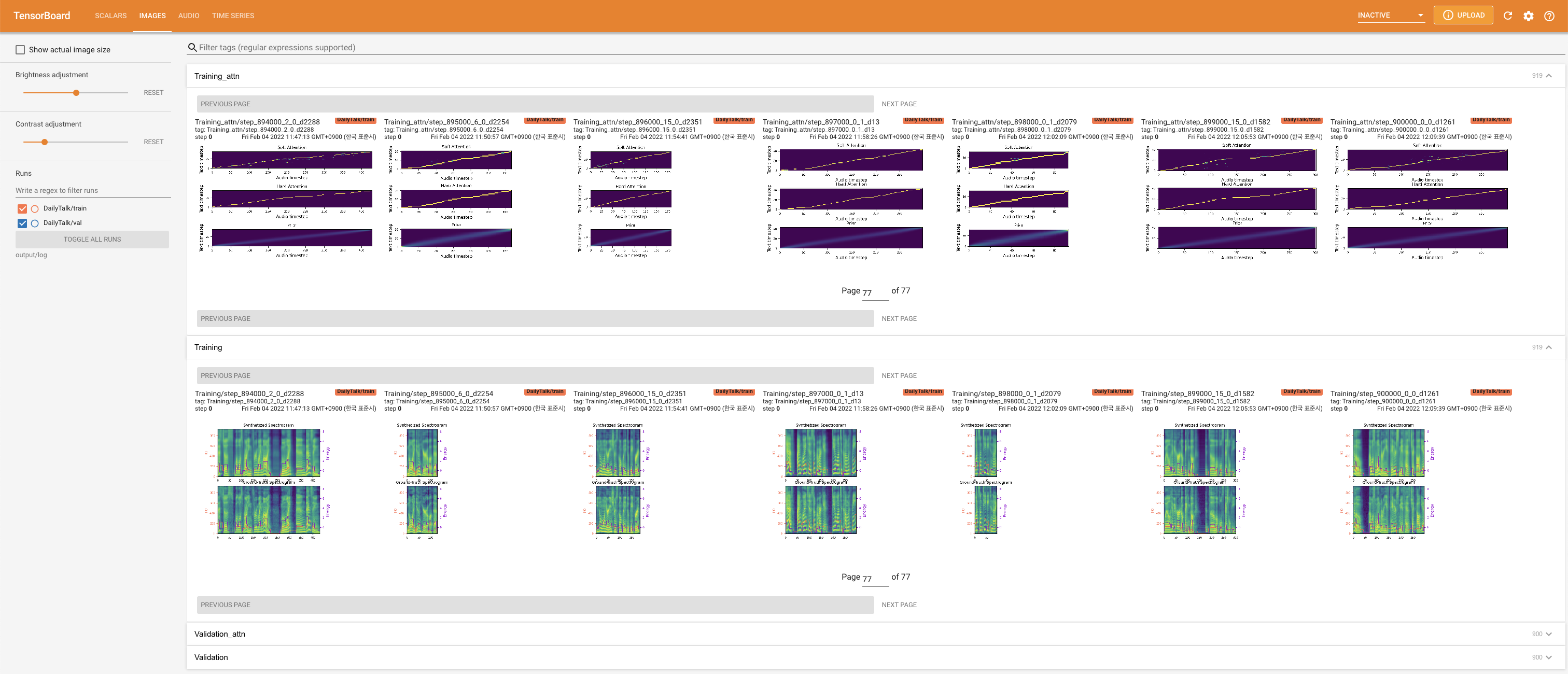
Para servir o Tensorboard em sua localhost. As curvas de perda, os espectrogramas MEL sintetizados e os áudios são mostrados.
'none' e 'DeepSpeaker' ).Se você deseja usar nosso conjunto de dados e codificar ou consultar o nosso artigo, cite o seguinte.
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
Este trabalho é licenciado sob uma licença internacional Creative Commons Attribution-Sharealike 4.0.


