DailyTalk
v0.1.0
ในบทความของเราเราแนะนำ DailyTalk ซึ่งเป็นชุดข้อมูลการสนทนาที่มีคุณภาพสูงที่ออกแบบมาสำหรับข้อความเป็นคำพูด
บทคัดย่อ: ชุดข้อมูลส่วนใหญ่ของข้อความเป็นคำพูด (TTS) ซึ่งเป็นคอลเลกชันของคำพูดของแต่ละบุคคลมีแง่มุมการสนทนาน้อย ในบทความนี้เราแนะนำ DailyTalk ซึ่งเป็นชุดข้อมูลการสนทนาที่มีคุณภาพสูงที่ออกแบบมาสำหรับ TTS การสนทนา เราสุ่มตัวอย่างแก้ไขและบันทึกบทสนทนา 2,541 จากชุดข้อมูลการสนทนาแบบเปิดโดเมน DailyDialog ที่สืบทอดแอตทริบิวต์คำอธิบายประกอบ ด้านบนของชุดข้อมูลของเราเราขยายงานก่อนหน้านี้เป็นพื้นฐานของเราซึ่ง TTS ที่ไม่ได้อยู่ในระบบจะถูกปรับอากาศในข้อมูลประวัติศาสตร์ในบทสนทนา จากการทดลองพื้นฐานที่มีทั้งตัวชี้วัดทั่วไปและตัวชี้วัดนวนิยายของเราเราแสดงให้เห็นว่า DailyTalk สามารถใช้เป็นชุดข้อมูล TTS ทั่วไปและยิ่งกว่านั้นพื้นฐานของเราสามารถเป็นตัวแทนของข้อมูลบริบทจาก DailyTalk ชุดข้อมูล DailyTalk และรหัสพื้นฐานมีให้บริการอย่างอิสระสำหรับการใช้งานทางวิชาการด้วยใบอนุญาต CC-by-SA 4.0
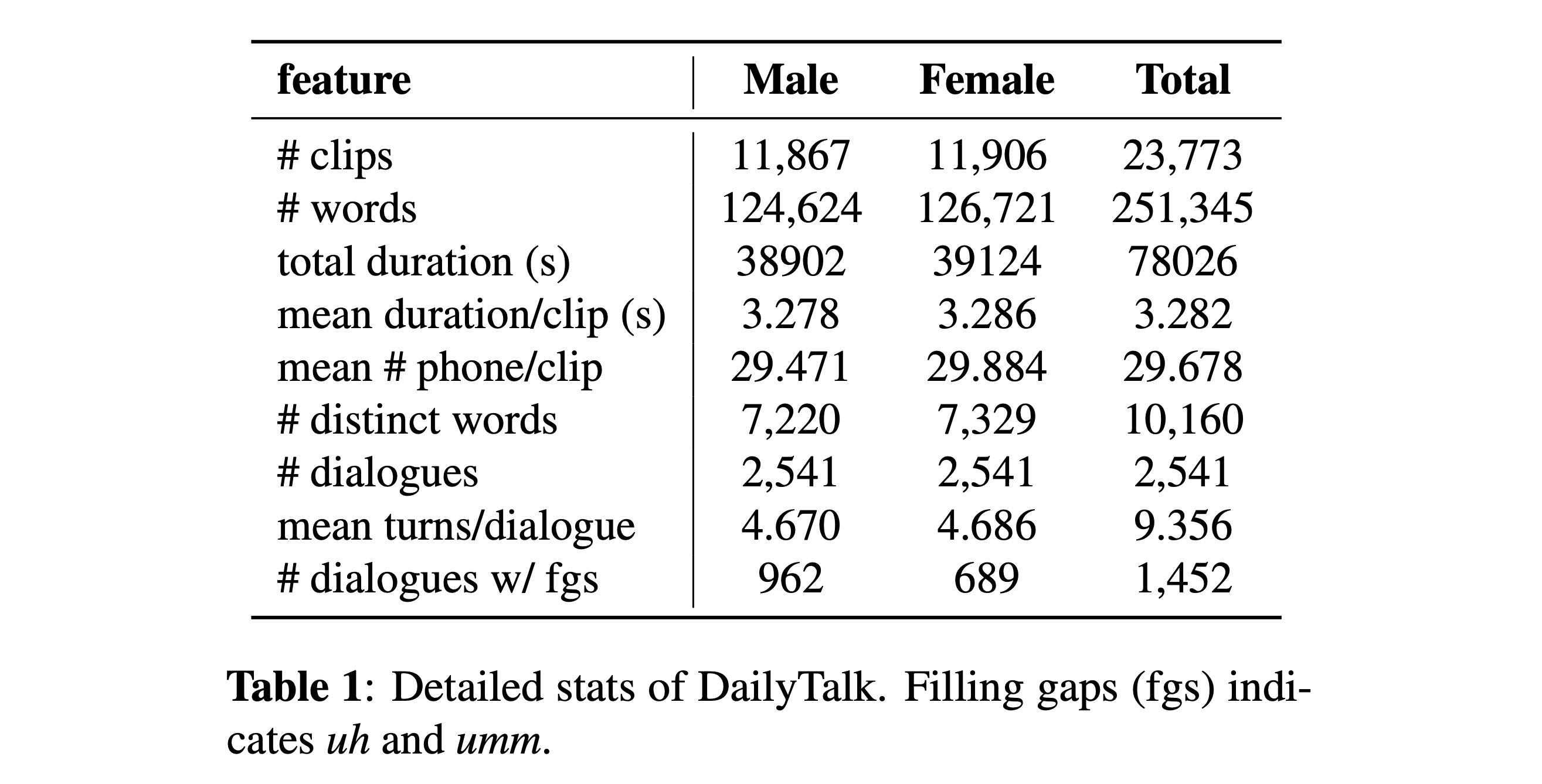
คุณสามารถดาวน์โหลดชุดข้อมูลของเรา โปรดดูรายละเอียดสถิติสำหรับรายละเอียด
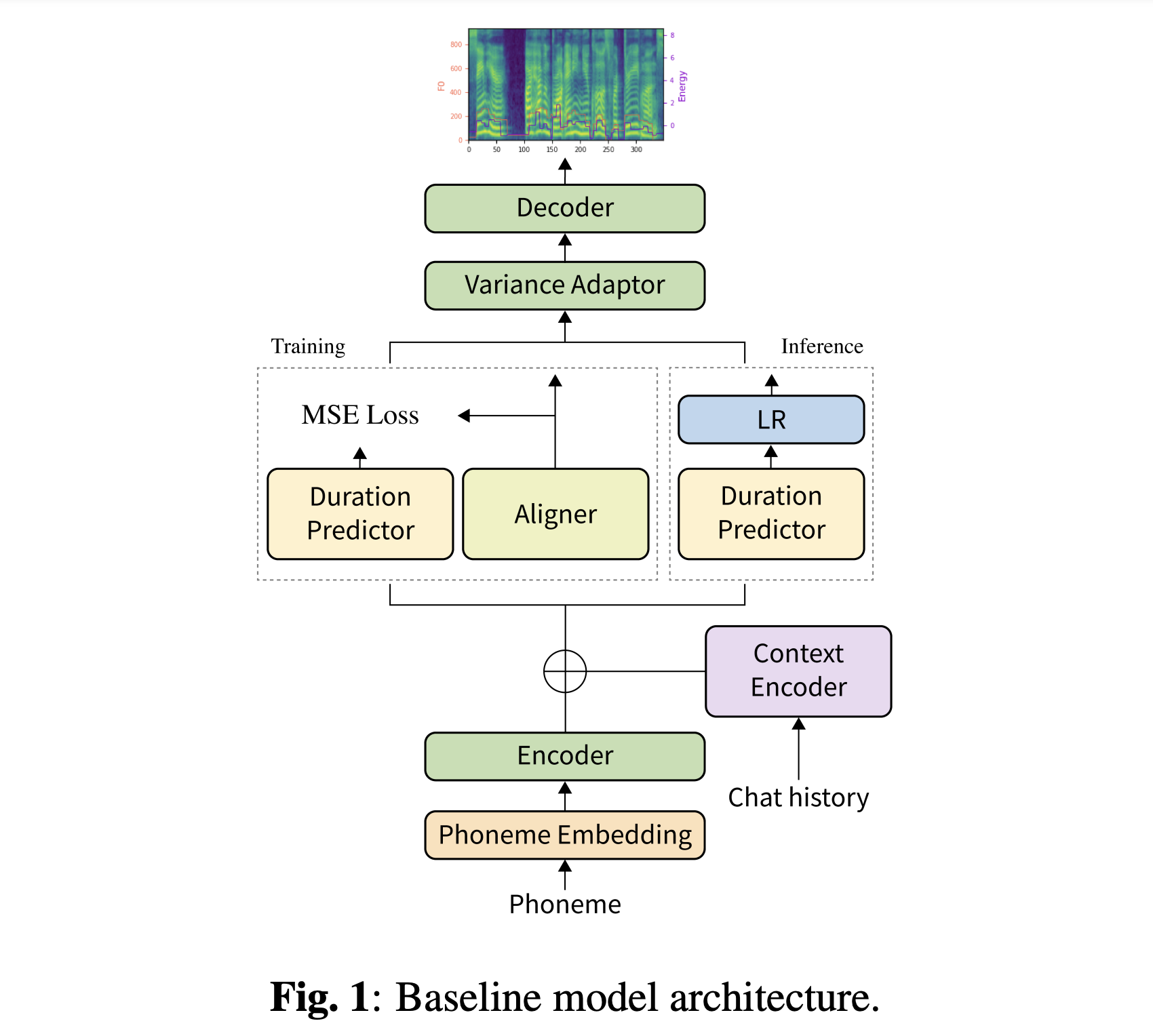
คุณสามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมของเราได้ มีสองไดเรกทอรีที่แตกต่างกัน: 'history_none' และ 'history_guo' อดีตไม่มีการเข้ารหัสประวัติศาสตร์เพื่อไม่ให้โมเดลการสนทนารู้บริบท หลังมีการเข้ารหัสในอดีตหลังจาก TTS แบบ end-to-end สนทนาสำหรับตัวแทนเสียง (Guo et al., 2020)
สลับประเภทของการเข้ารหัสประวัติศาสตร์โดย
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]คุณสามารถติดตั้งการพึ่งพา Python ด้วย
pip3 install -r requirements.txt
นอกจากนี้ Dockerfile ยังมีไว้สำหรับผู้ใช้ Docker
คุณต้องดาวน์โหลดทั้งชุดข้อมูลของเรา ดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมและวางไว้ใน output/ckpt/DailyTalk/ ยังคลายซิป generator_LJSpeech.pth.tar หรือ generator_universal.pth.tar ในโฟลเดอร์ Hifigan แบบจำลองได้รับการฝึกฝนด้วยการสร้างแบบจำลองระยะเวลาที่ไม่ได้รับการดูแลภายใต้การสร้างหม้อแปลงและประเภทการเข้ารหัสประวัติ
มีเพียงการอนุมานแบทช์เท่านั้นที่ได้รับการสนับสนุนเนื่องจากการสร้างเทิร์นอาจต้องใช้ประวัติบริบทของการสนทนา พยายาม
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
เพื่อสังเคราะห์คำพูดทั้งหมดใน preprocessed_data/DailyTalk/val_*.txt
สำหรับ TTS หลายลำโพงที่ มีลำโพง Embedder ดาวน์โหลด Rescnn Softmax+Triplet Pretrained Model ของ Deepspeaker ของ Philipperemy สำหรับการฝังลำโพงและค้นหาใน ./deepspeaker/pretrained_models/ deepspeaker/pretrained_models/ โปรดทราบว่าโมเดลที่ผ่านการฝึกอบรมของเราไม่ได้รับการฝึกฝนเรื่องนี้ (พวกเขาได้รับการฝึกฝนด้วย speaker_embedder: "none" )
วิ่ง
python3 prepare_align.py --dataset DailyTalk
สำหรับการเตรียมการบางอย่าง
สำหรับการจัดตำแหน่งที่ถูกบังคับมอนทรีออลบังคับให้ผู้จัดตำแหน่ง (MFA) ใช้เพื่อให้ได้การจัดตำแหน่งระหว่างคำพูดและลำดับฟอนิม การจัดตำแหน่งที่สกัดไว้ล่วงหน้าสำหรับชุดข้อมูลมีให้ที่นี่ คุณต้องคลายซิปไฟล์ใน preprocessed_data/DailyTalk/TextGrid/ อีกวิธีหนึ่งคุณสามารถเรียกใช้การจัดตำแหน่งด้วยตัวเอง โปรดทราบว่าแบบจำลองที่ผ่านการฝึกอบรมของเราไม่ได้รับการฝึกฝนด้วยการสร้างแบบจำลองระยะเวลาภายใต้การดูแล (พวกเขาได้รับการฝึกฝนด้วย learn_alignment: True )
หลังจากนั้นเรียกใช้สคริปต์การประมวลผลล่วงหน้าโดย
python3 preprocess.py --dataset DailyTalk
ฝึกอบรมแบบจำลองของคุณด้วย
python3 train.py --dataset DailyTalk
ตัวเลือกที่มีประโยชน์:
--use_amp กับคำสั่งด้านบนCUDA_VISIBLE_DEVICES=<GPU_IDs> ที่จุดเริ่มต้นของคำสั่งด้านบนใช้
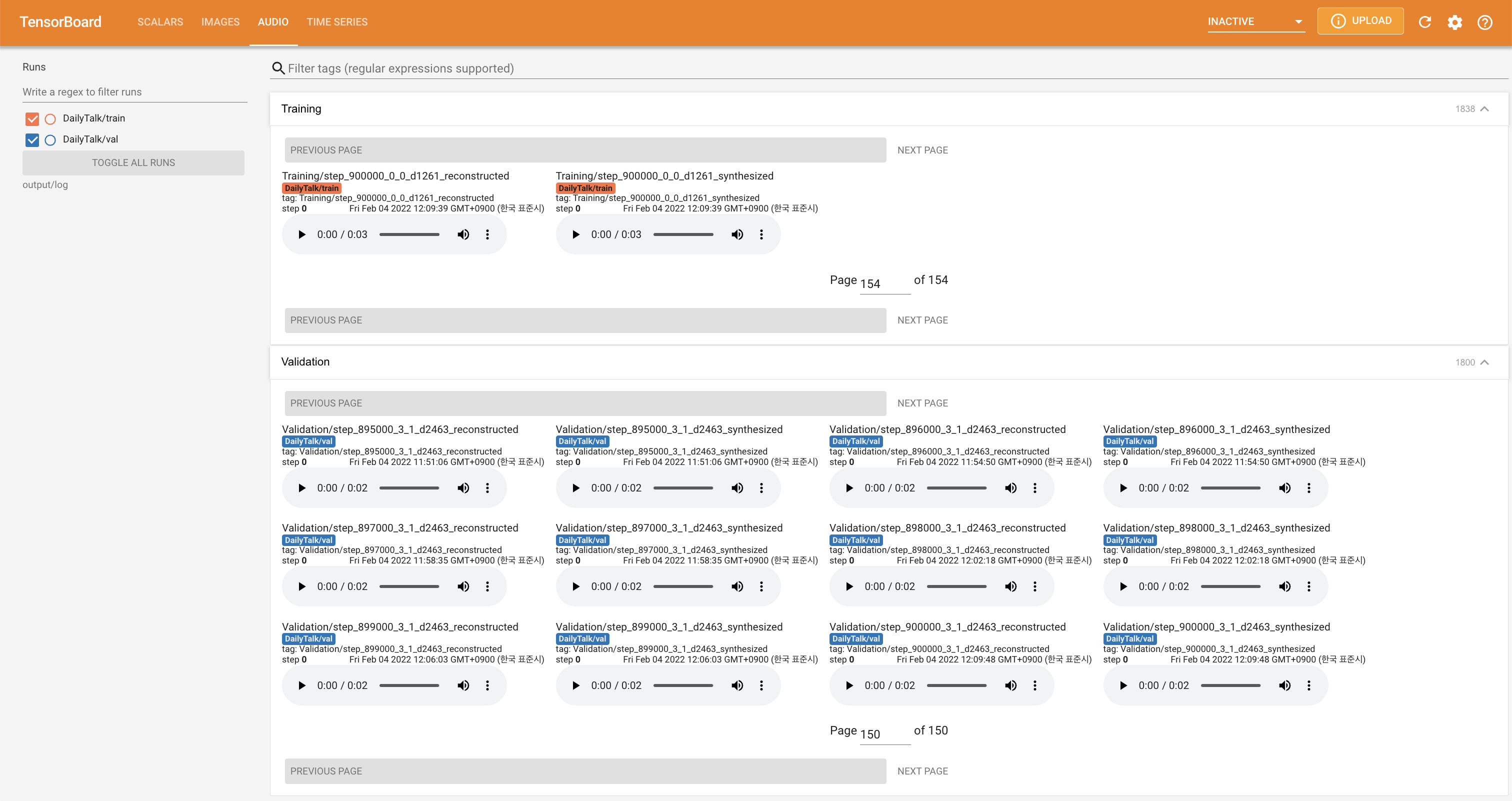
tensorboard --logdir output/log
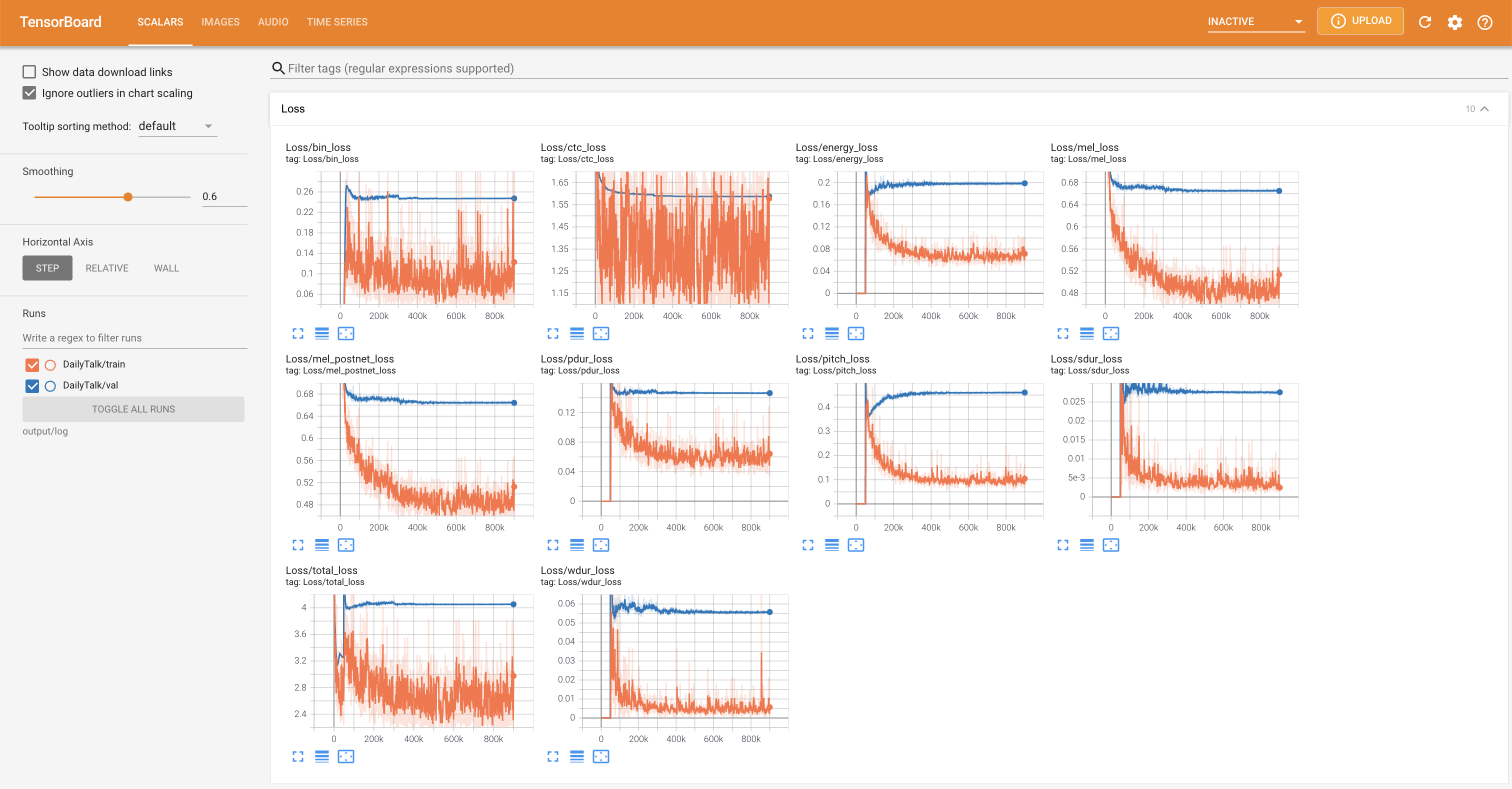
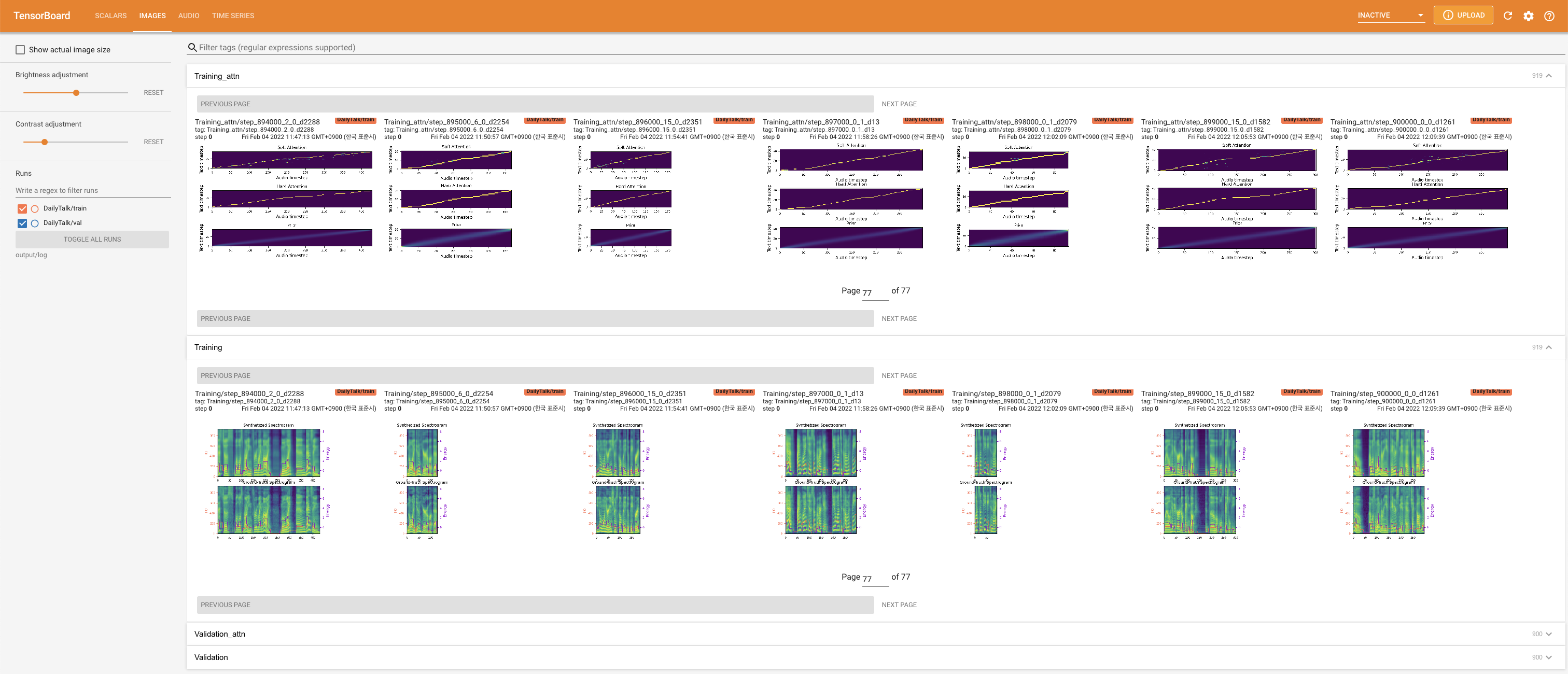
เพื่อให้บริการ Tensorboard บนบ้านของคุณ เส้นโค้งการสูญเสีย mel-spectrograms สังเคราะห์และเสียงจะแสดง
'none' และ 'DeepSpeaker' )หากคุณต้องการใช้ชุดข้อมูลและรหัสของเราหรือดูเอกสารของเราโปรดอ้างอิงดังนี้
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
งานนี้ได้รับใบอนุญาตภายใต้ใบอนุญาตสร้างสรรค์ที่มีการระบุแหล่งที่มาของคอมมอนส์ 4.0


