DailyTalk
v0.1.0
우리의 논문에서, 우리는 텍스트 음성 연설을 위해 설계된 고품질 대화 연설 데이터 세트 인 DailyTalk를 소개합니다.
초록 : 개별 발화의 모음 인 TTS (Text-To-Steee) 데이터 세트의 대부분은 대화 측면이 거의 포함되지 않습니다. 이 논문에서는 대화 TTS 용으로 설계된 고품질 대화 연설 데이터 세트 인 DailyTalk를 소개합니다. 우리는 주석이 달린 속성을 상속하는 Open-Domain 대화 데이터 세트 DailyDialog에서 2,541 개의 대화를 샘플링, 수정 및 기록했습니다. 데이터 세트 외에도, 우리는 이전 작업을 기준선으로 확장합니다. 여기서 비유로 인한 TTS가 대화에서 역사적 정보에 대해 조절됩니다. 일반적인 메트릭과 소설 메트릭의 기준 실험에서 우리는 DailyTalk가 일반 TTS 데이터 세트로 사용될 수 있음을 보여줍니다. 그 이상으로 우리의 기준선은 DailyTalk의 상황 정보를 나타낼 수 있음을 보여줍니다. DailyTalk 데이터 세트 및 기준 코드는 CC-By-SA 4.0 라이센스와 함께 학업에 사용할 수 있습니다.
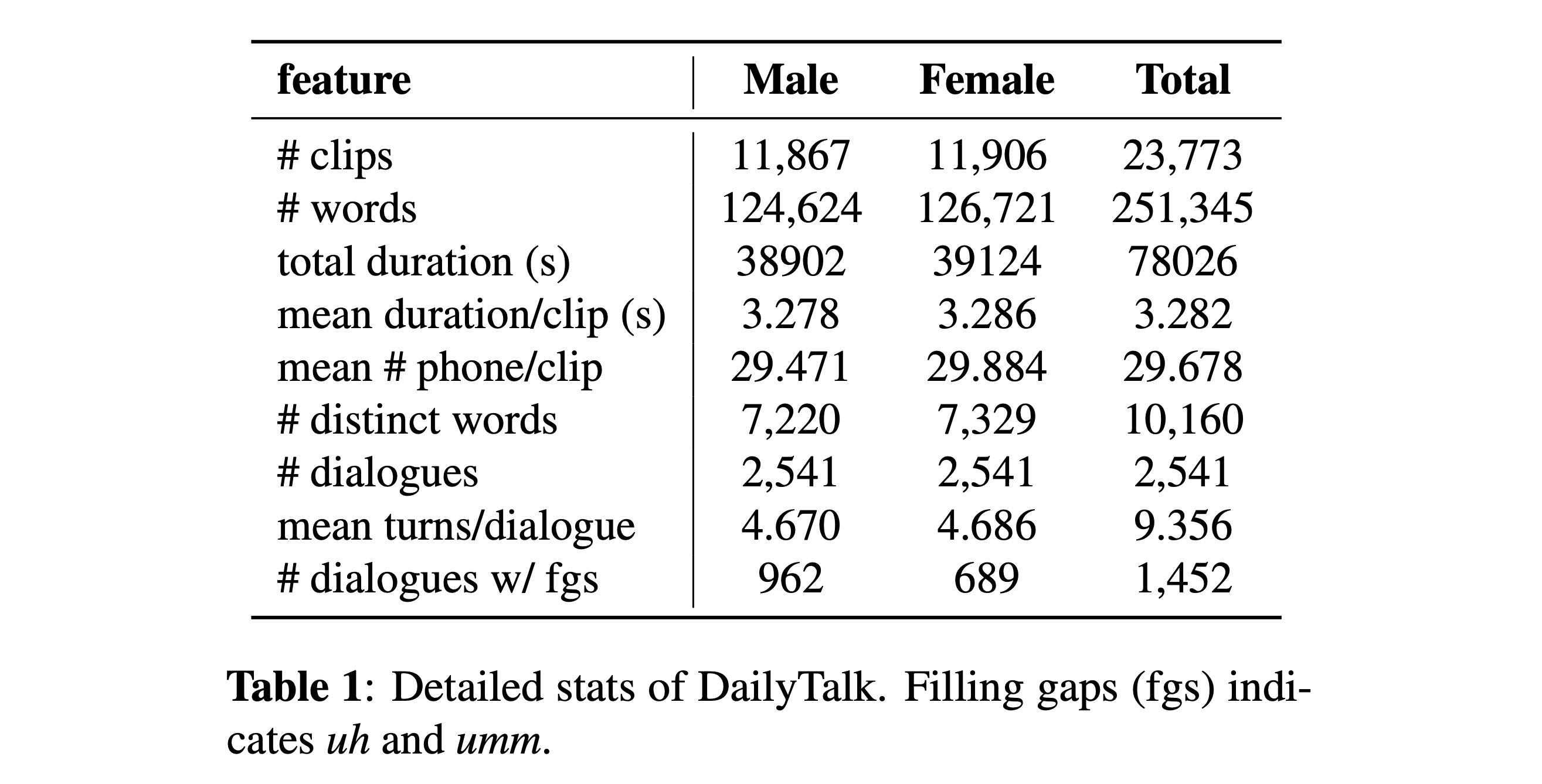
데이터 세트를 다운로드 할 수 있습니다. 자세한 내용은 통계 세부 정보를 참조하십시오.
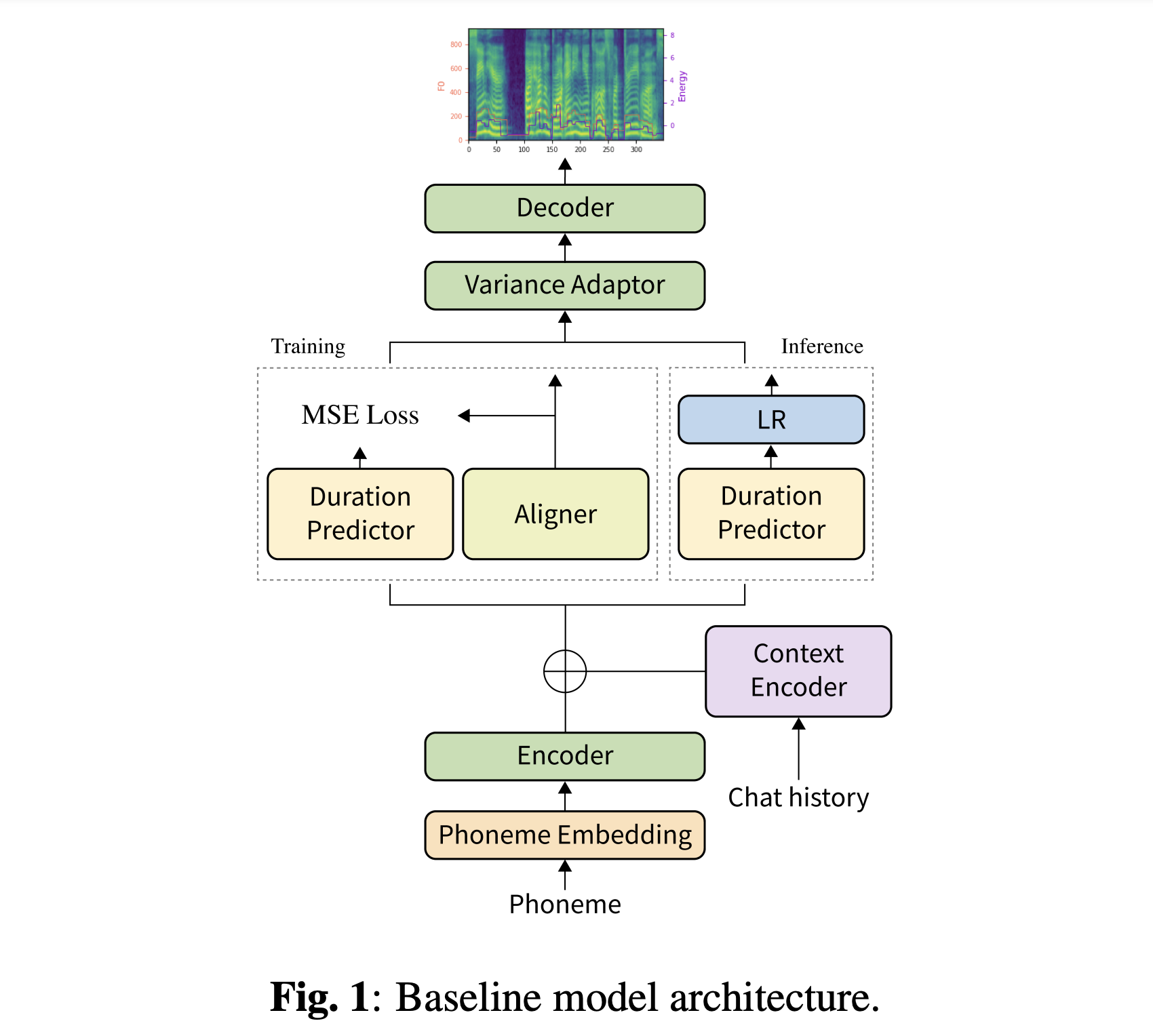
사전에 사전 된 모델을 다운로드 할 수 있습니다. 'history_none'과 'history_guo'의 두 가지 디렉토리가 있습니다. 전자는 역사적 인코딩이 없으므로 대화가있는 맥락 인식 모델이 아닙니다. 후자는 음성 에이전트에 대한 대화적인 엔드 투 엔드 TT에 따른 역사적 인코딩을 가지고있다 (Guo et al., 2020).
역사 인코딩 유형을 전환하십시오
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]파이썬 종속성을 설치할 수 있습니다
pip3 install -r requirements.txt
또한 Dockerfile Docker 사용자에게 제공됩니다.
두 데이터 세트를 모두 다운로드해야합니다. 사전 치료 된 모델을 다운로드하여 output/ckpt/DailyTalk/ 에 넣으십시오. 또한 Unzip generator_LJSpeech.pth.tar 또는 generator_universal.pth.tar hifigan 폴더. 이 모델은 변압기 빌딩 블록 및 이력 인코딩 유형에서 감독되지 않은 지속 시간 모델링으로 훈련됩니다.
턴 생성이 대화의 맥락 기록이 필요할 수 있으므로 배치 추론 만 지원됩니다. 노력하다
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
preprocessed_data/DailyTalk/val_*.txt 의 모든 발화를 종합합니다.
외부 스피커 임베더가있는 멀티 스피커 TT 의 경우 스피커를 포함시키기 위해 Philipperemy의 DeepSpeaker의 Rescnn SoftMax+Triplet Pretrated 모델을 다운로드하여 ./deepspeaker/pretrained_models/ 에서 찾으십시오. 우리의 사전 에식 된 모델은 이것으로 훈련되지 않았습니다 (그들은 speaker_embedder: "none" 으로 훈련됩니다).
달리다
python3 prepare_align.py --dataset DailyTalk
일부 준비.
강제 정렬의 경우, 몬트리올 강제 정렬 (MFA)은 발화와 음소 시퀀스 사이의 정렬을 얻는 데 사용됩니다. 데이터 세트에 대한 사전 추출 된 정렬이 여기에 제공됩니다. preprocessed_data/DailyTalk/TextGrid/ 에서 파일을 압축해야합니다. 또는 혼자서 Aligner를 실행할 수 있습니다. 사전 준비된 모델은 감독 된 지속 시간 모델링으로 훈련되지 않았습니다 ( learn_alignment: True 로 교육을받습니다).
그 후, 전처리 스크립트를 실행하십시오
python3 preprocess.py --dataset DailyTalk
모델을 훈련하십시오
python3 train.py --dataset DailyTalk
유용한 옵션 :
--use_amp 인수를 추가하십시오.CUDA_VISIBLE_DEVICES=<GPU_IDs> 지정하십시오.사용
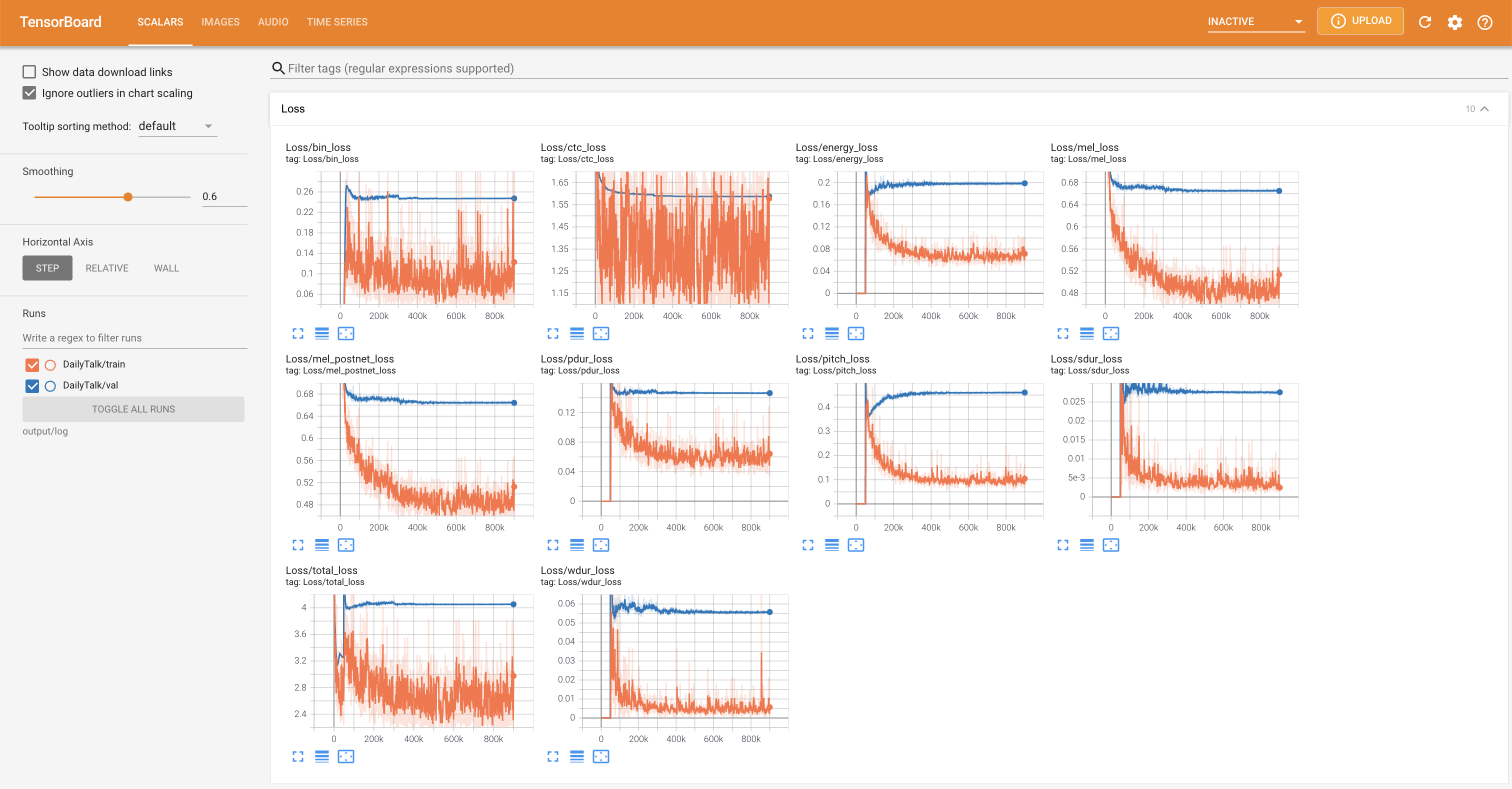
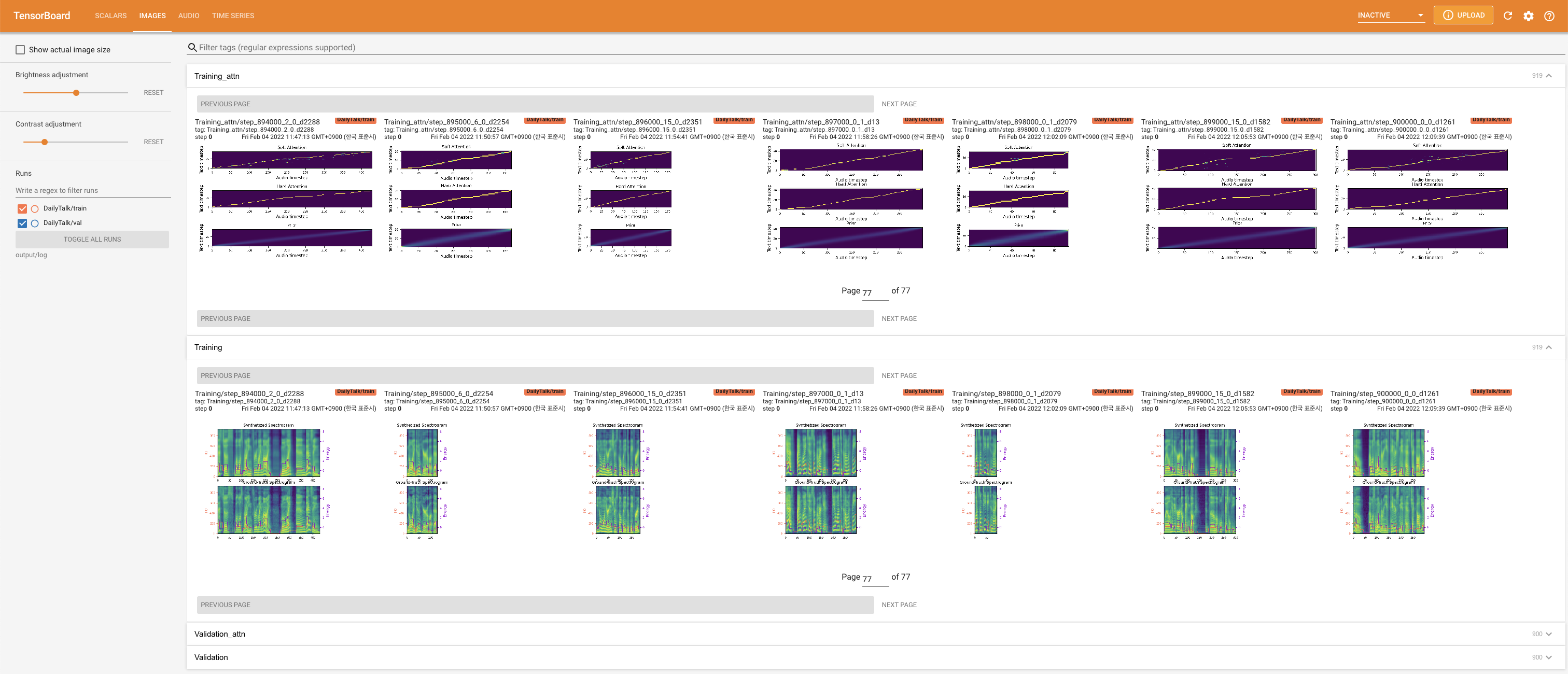
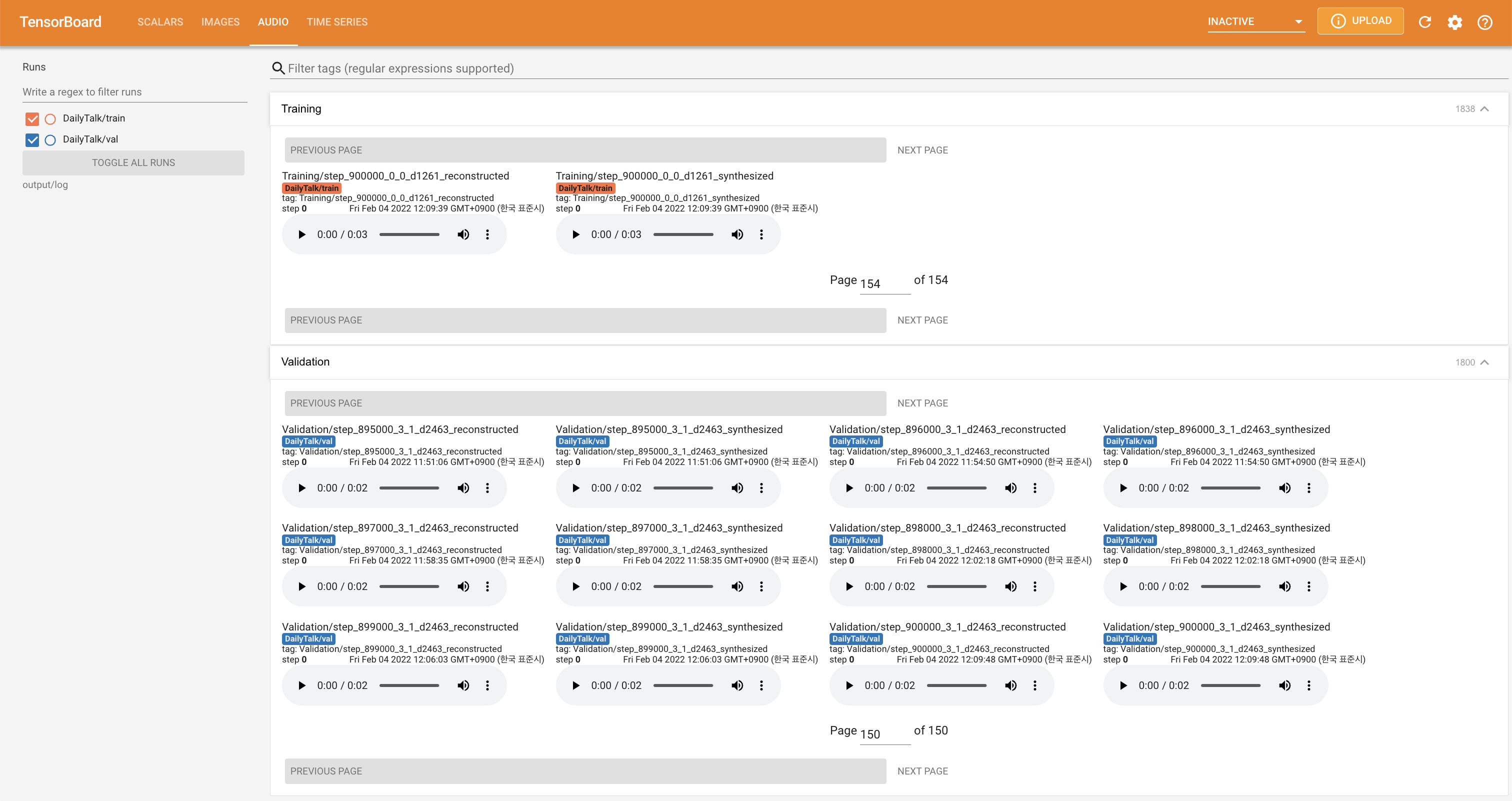
tensorboard --logdir output/log
지역 호스트에서 텐서 보드를 제공합니다. 손실 곡선, 합성 된 멜 스피어 그램 및 오디오가 표시됩니다.
'none' 과 'DeepSpeaker' 사이)를 설정하여 전환 할 수 있습니다.데이터 세트와 코드를 사용하거나 논문을 참조하려면 다음과 같이 인용하십시오.
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
이 작품은 Creative Commons Attribution-Sharealike 4.0 International 라이센스에 따라 라이센스가 부여됩니다.


