DailyTalk
v0.1.0
In our paper, we introduce DailyTalk, a high-quality conversational speech dataset designed for Text-to-Speech.
Abstract: The majority of current Text-to-Speech (TTS) datasets, which are collections of individual utterances, contain few conversational aspects. In this paper, we introduce DailyTalk, a high-quality conversational speech dataset designed for conversational TTS. We sampled, modified, and recorded 2,541 dialogues from the open-domain dialogue dataset DailyDialog inheriting its annotated attributes. On top of our dataset, we extend prior work as our baseline, where a non-autoregressive TTS is conditioned on historical information in a dialogue. From the baseline experiment with both general and our novel metrics, we show that DailyTalk can be used as a general TTS dataset, and more than that, our baseline can represent contextual information from DailyTalk. The DailyTalk dataset and baseline code are freely available for academic use with CC-BY-SA 4.0 license.
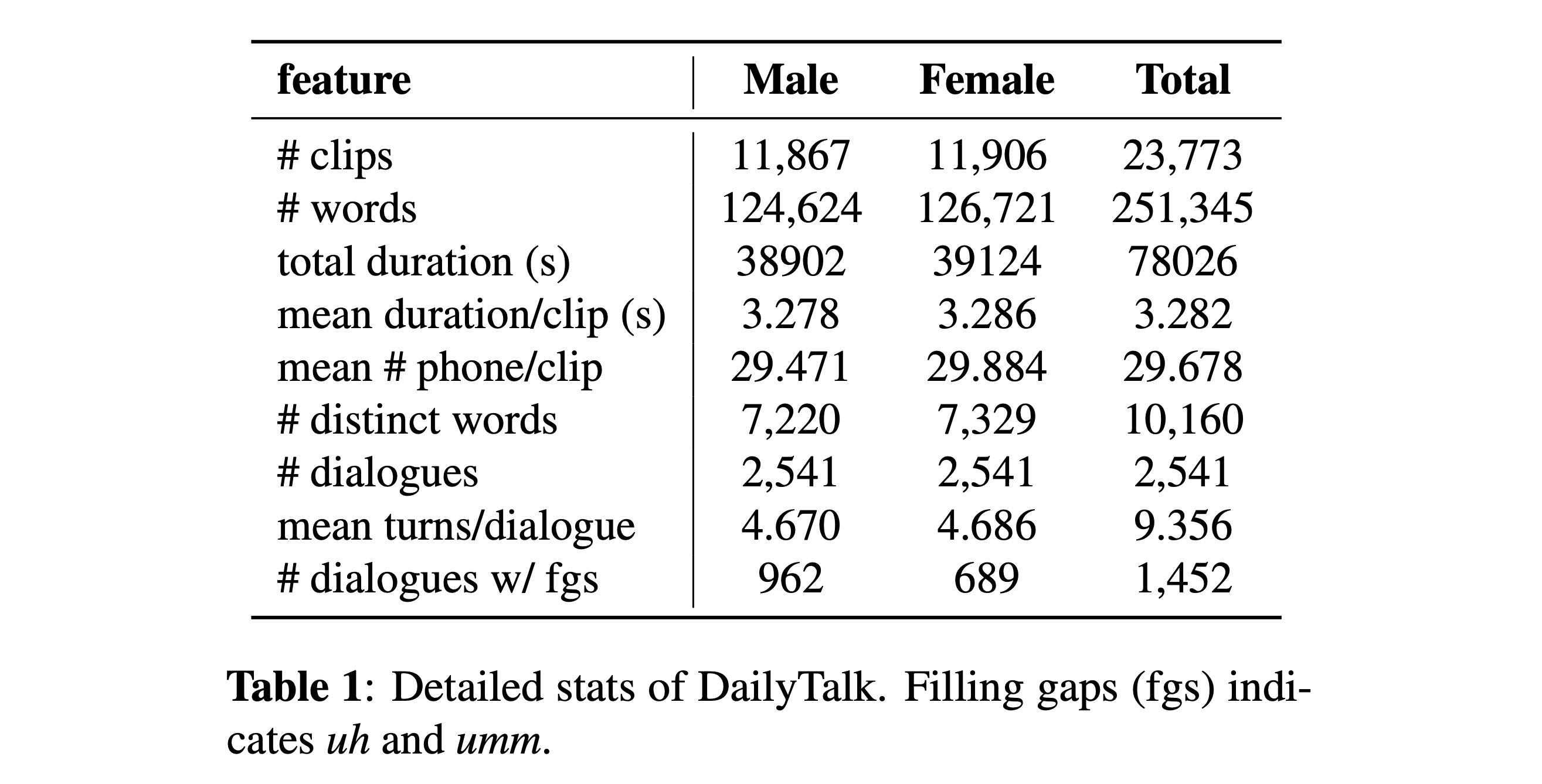
You can download our dataset. Please refer to Statistic Details for details.
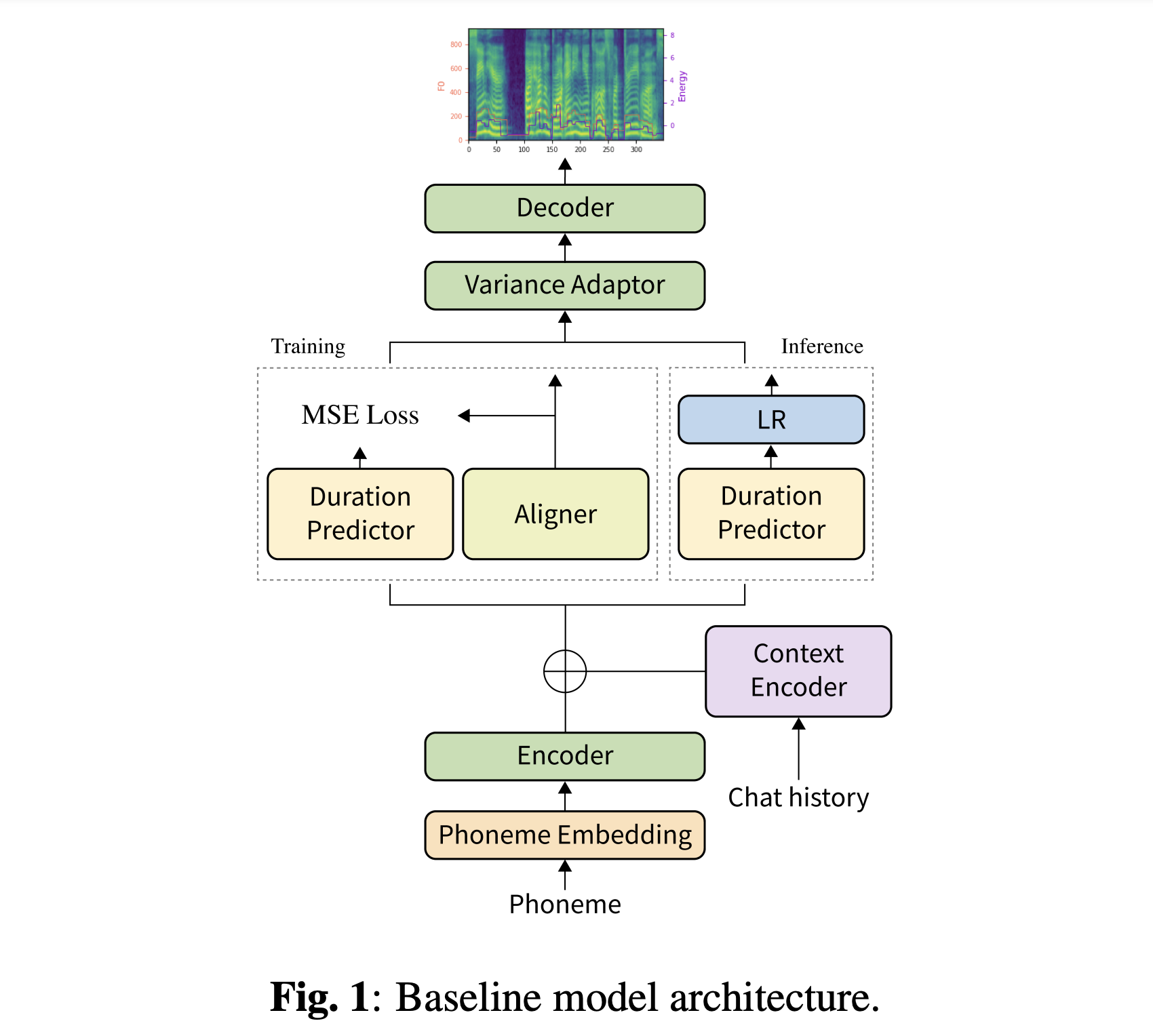
You can download our pretrained models. There are two different directories: 'history_none' and 'history_guo'. The former has no historical encodings so that it is not a conversational context-aware model. The latter has historical encodings following Conversational End-to-End TTS for Voice Agent (Guo et al., 2020).
Toggle the type of history encodings by
# In the model.yaml
history_encoder:
type: "Guo" # ["none", "Guo"]You can install the Python dependencies with
pip3 install -r requirements.txt
Also, Dockerfile is provided for Docker users.
You have to download both our dataset. Download pretrained models and put them in output/ckpt/DailyTalk/. Also unzip generator_LJSpeech.pth.tar or generator_universal.pth.tar in hifigan folder. The models are trained with unsupervised duration modeling under transformer building block and the history encoding types.
Only the batch inference is supported as the generation of a turn may need contextual history of the conversation. Try
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
to synthesize all utterances in preprocessed_data/DailyTalk/val_*.txt.
For a multi-speaker TTS with external speaker embedder, download ResCNN Softmax+Triplet pretrained model of philipperemy's DeepSpeaker for the speaker embedding and locate it in ./deepspeaker/pretrained_models/. Please note that our pretrained models are not trained with this (they are trained with speaker_embedder: "none").
Run
python3 prepare_align.py --dataset DailyTalk
for some preparations.
For the forced alignment, Montreal Forced Aligner (MFA) is used to obtain the alignments between the utterances and the phoneme sequences.
Pre-extracted alignments for the datasets are provided here.
You have to unzip the files in preprocessed_data/DailyTalk/TextGrid/. Alternately, you can run the aligner by yourself. Please note that our pretrained models are not trained with supervised duration modeling (they are trained with learn_alignment: True).
After that, run the preprocessing script by
python3 preprocess.py --dataset DailyTalk
Train your model with
python3 train.py --dataset DailyTalk
Useful options:
--use_amp argument to the above command.CUDA_VISIBLE_DEVICES=<GPU_IDs> at the beginning of the above command.Use
tensorboard --logdir output/log
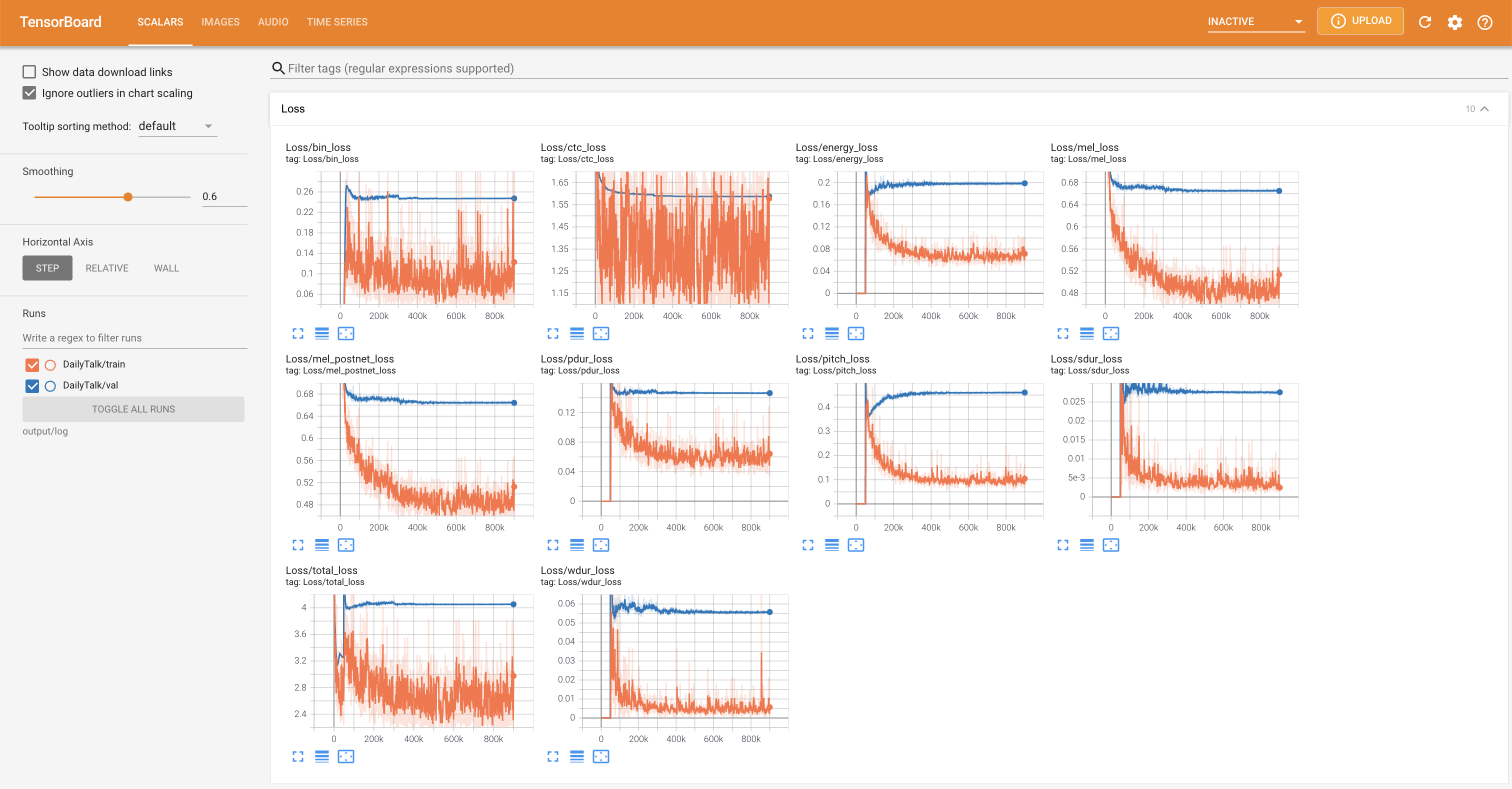
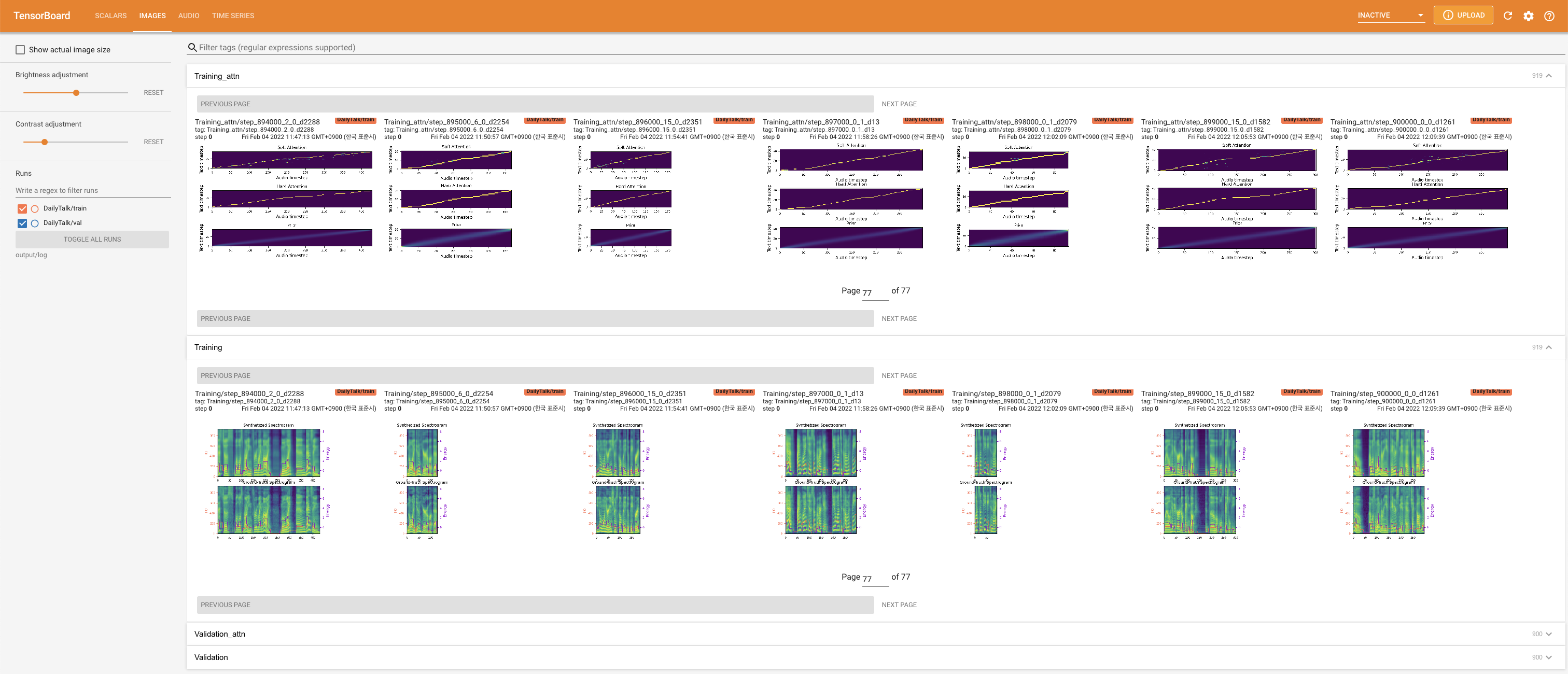
to serve TensorBoard on your localhost. The loss curves, synthesized mel-spectrograms, and audios are shown.
'none' and 'DeepSpeaker').If you would like to use our dataset and code or refer to our paper, please cite as follows.
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.


