DailyTalk
v0.1.0
في ورقتنا ، نقدم DailyTalk ، مجموعة بيانات الكلام محادثة عالية الجودة مصممة للنص على نص.
الخلاصة: تحتوي غالبية مجموعات بيانات النص على النص على الكلام (TTS) ، وهي مجموعات من الكلمات الفردية ، على عدد قليل من جوانب المحادثة. في هذه الورقة ، نقدم DailyTalk ، وهي مجموعة بيانات الكلام المحادثة عالية الجودة المصممة ل TTS للمحادثة. قمنا بأخذ عينات من 2،541 مربعًا من مربعات حوار حوار في المجال المفتوح ، وراثيًا ، ويرثت DailyDialog ، و uppliced ، وسجلنا ، من مجموعة بيانات الحوار المفتوح. علاوة على مجموعة البيانات الخاصة بنا ، نقوم بتوسيع نطاق العمل السابق كخط الأساس الخاص بنا ، حيث يتم تكييف TTS غير التابع للمعلومات التاريخية في حوار. من التجربة الأساسية مع كل من General ومقاييسنا الجديدة ، نظهر أنه يمكن استخدام DailyTalk كمجموعة بيانات عامة TTS ، وأكثر من ذلك ، يمكن أن يمثل خطنا الأساسي معلومات سياقية من DailyTalk. تتوفر مجموعة بيانات DailyTalk ورمز خط الأساس مجانًا للاستخدام الأكاديمي مع ترخيص CC-By-SA 4.0.
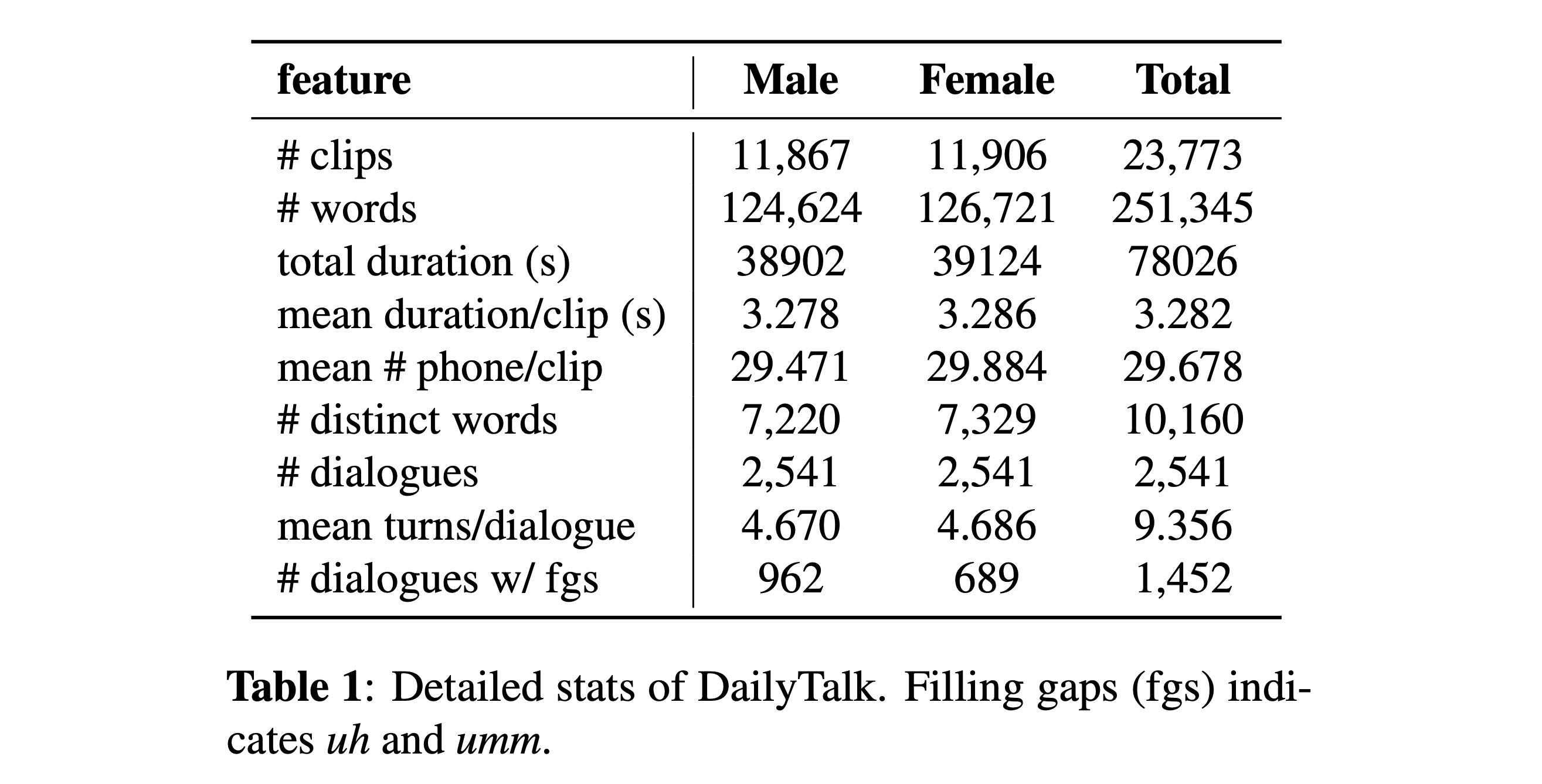
يمكنك تنزيل مجموعة البيانات الخاصة بنا. يرجى الرجوع إلى التفاصيل الإحصائية للحصول على التفاصيل.
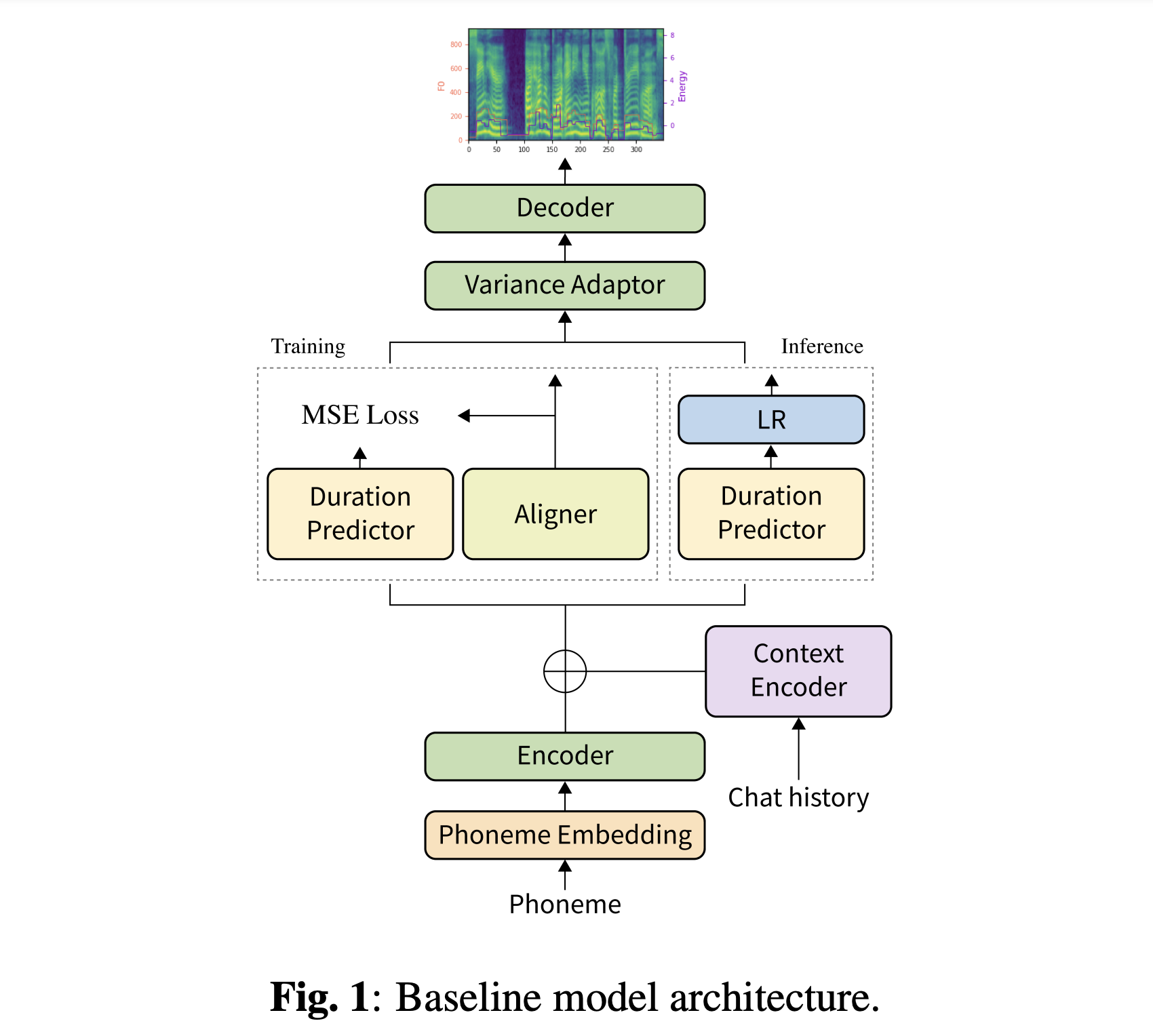
يمكنك تنزيل نماذجنا المسبقة. هناك دليلان مختلفان: "History_None" و "History_Guo". السابق ليس لديه ترميزات تاريخية بحيث لا يكون نموذجًا مدركًا للسياق. هذا الأخير لديه تشفيرات تاريخية بعد TTS المحادثة من طرف إلى طرف للعامل الصوتي (Guo et al. ، 2020).
تبديل نوع ترميزات التاريخ
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]يمكنك تثبيت تبعيات Python مع
pip3 install -r requirements.txt
أيضا ، يتم توفير Dockerfile لمستخدمي Docker .
يجب عليك تنزيل كل من مجموعة البيانات الخاصة بنا. قم بتنزيل النماذج المسبقة ووضعها في output/ckpt/DailyTalk/ . أيضًا unsip generator_LJSpeech.pth.tar أو generator_universal.pth.tar في مجلد Hifigan. يتم تدريب النماذج مع نمذجة المدة غير الخاضعة للإشراف تحت لبنة بناء المحولات وأنواع ترميز التاريخ.
يتم دعم استنتاج الدُفعات فقط لأن توليد منعطف قد يحتاج إلى تاريخ سياق للمحادثة. يحاول
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
لتوليف جميع الكلمات في preprocessed_data/DailyTalk/val_*.txt .
للحصول على TTS متعددة الكلام مع مكبر صوت خارجي ، قم بتنزيل نموذج RAVERMAX+TREPLET PRESTERED من Deepspeaker من Philipperemy لدمجه ويحدد موقعه ./deepspeaker/pretrained_models/ يرجى ملاحظة أن نماذجنا المسبقة ليست مدربة مع هذا (يتم تدريبها باستخدام speaker_embedder: "none" ).
يجري
python3 prepare_align.py --dataset DailyTalk
لبعض الاستعدادات.
بالنسبة للمحاذاة القسرية ، يتم استخدام Montreal القسري Aligner (MFA) للحصول على المحاذاة بين الكلمات وتسلسلات الصوت. يتم توفير محاذاة مسبقًا لمجموعات البيانات هنا. يجب عليك إلغاء ضغط الملفات في preprocessed_data/DailyTalk/TextGrid/ . بالتناوب ، يمكنك تشغيل جهاز Aligner بنفسك. يرجى ملاحظة أن نماذجنا المسبقة لا يتم تدريبها بنمذجة المدة الخاضعة للإشراف (يتم تدريبها على learn_alignment: True ).
بعد ذلك ، قم بتشغيل البرنامج النصي المسبق
python3 preprocess.py --dataset DailyTalk
تدريب النموذج الخاص بك مع
python3 train.py --dataset DailyTalk
خيارات مفيدة:
--use_amp إلى الأمر أعلاه.CUDA_VISIBLE_DEVICES=<GPU_IDs> في بداية الأمر أعلاه.يستخدم
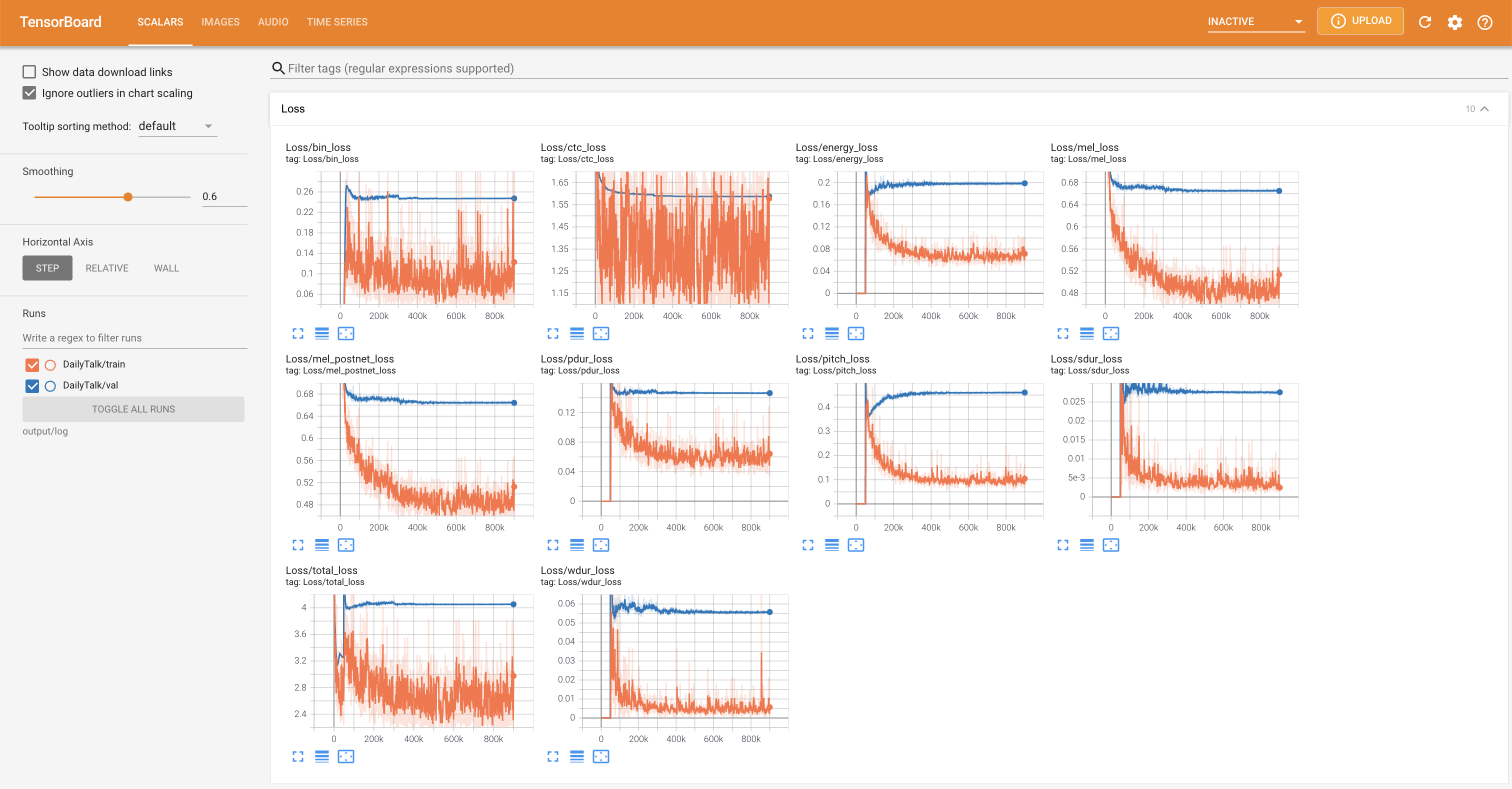
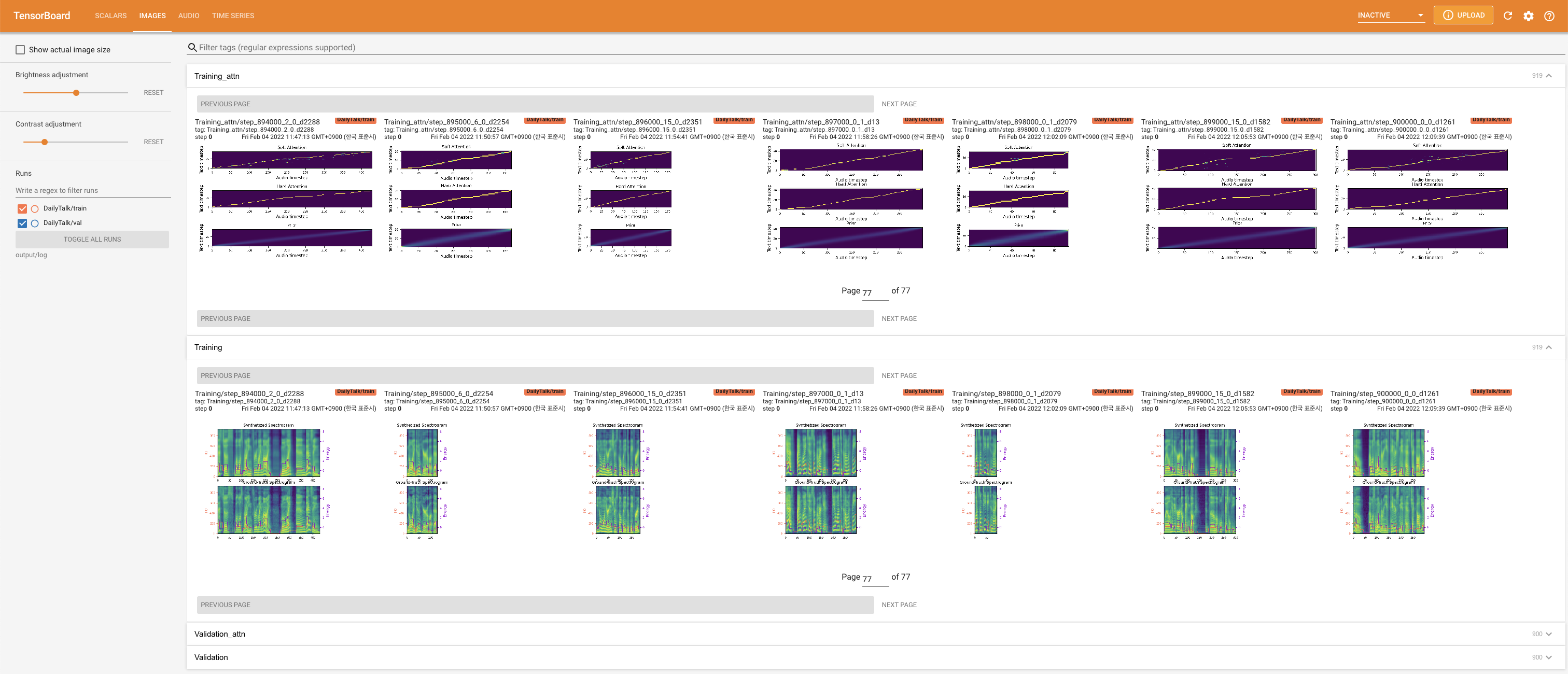
tensorboard --logdir output/log
لخدمة Tensorboard على مضيفك المحلي. يتم عرض منحنيات الخسارة ، وتوليف الطيف الطيف ، والسمعات.
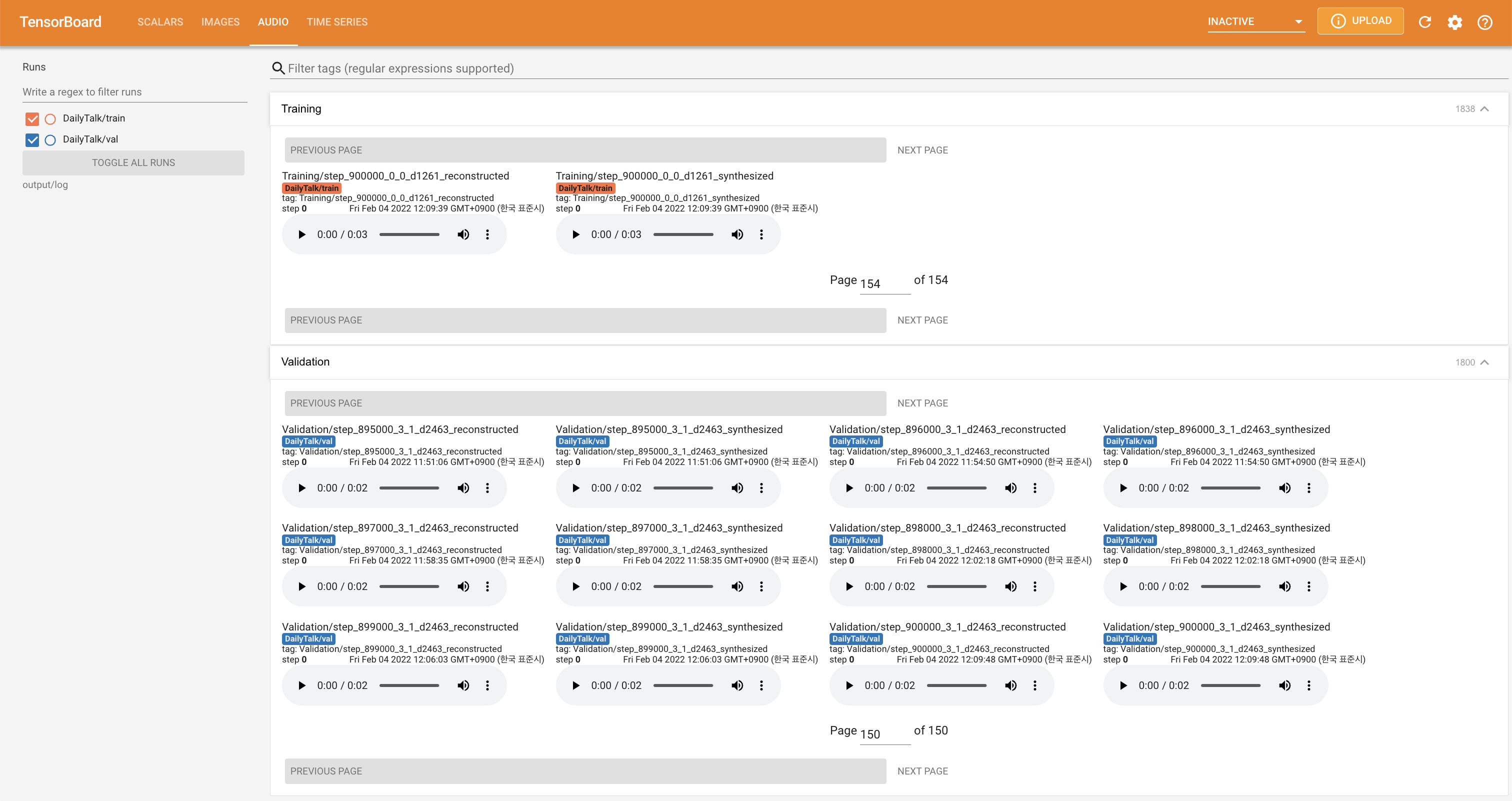
'none' و 'DeepSpeaker' ).إذا كنت ترغب في استخدام مجموعة البيانات والرمز أو الرجوع إلى ورقتنا ، فيرجى الاستشهاد على النحو التالي.
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
هذا العمل مرخص له بموجب ترخيص Creative Commons Commons-Tharealike 4.0 الدولي.


