DailyTalk
v0.1.0
В нашей статье мы представляем DailyTalk, высококачественный набор данных разговорной речи, предназначенный для текста в речь.
Аннотация: Большинство текущих наборов данных текста в речь (TTS), которые представляют собой коллекции отдельных высказываний, содержат несколько разговорных аспектов. В этой статье мы вводим DailyTalk, высококачественный набор данных разговорной речи, предназначенный для разговорных TTS. Мы отобрали, модифицировали и записали 2541 диалогов из набора данных диалога с открытым доменом DailyDialog, наследуя его аннотированные атрибуты. Помимо нашего набора данных, мы расширяем предыдущую работу в качестве нашей базовой линии, где неавторегрессивный TTS обусловлен исторической информацией в диалоге. Из базового эксперимента как с General, так и с нашими новыми метриками мы показываем, что DailyTalk можно использовать в качестве общего набора данных TTS, и, более того, наш базовый уровень может представлять контекстную информацию из DailyTalk. Набор данных DailyTalk и базовый код свободно доступны для академического использования с лицензией CC-By-SA 4.0.
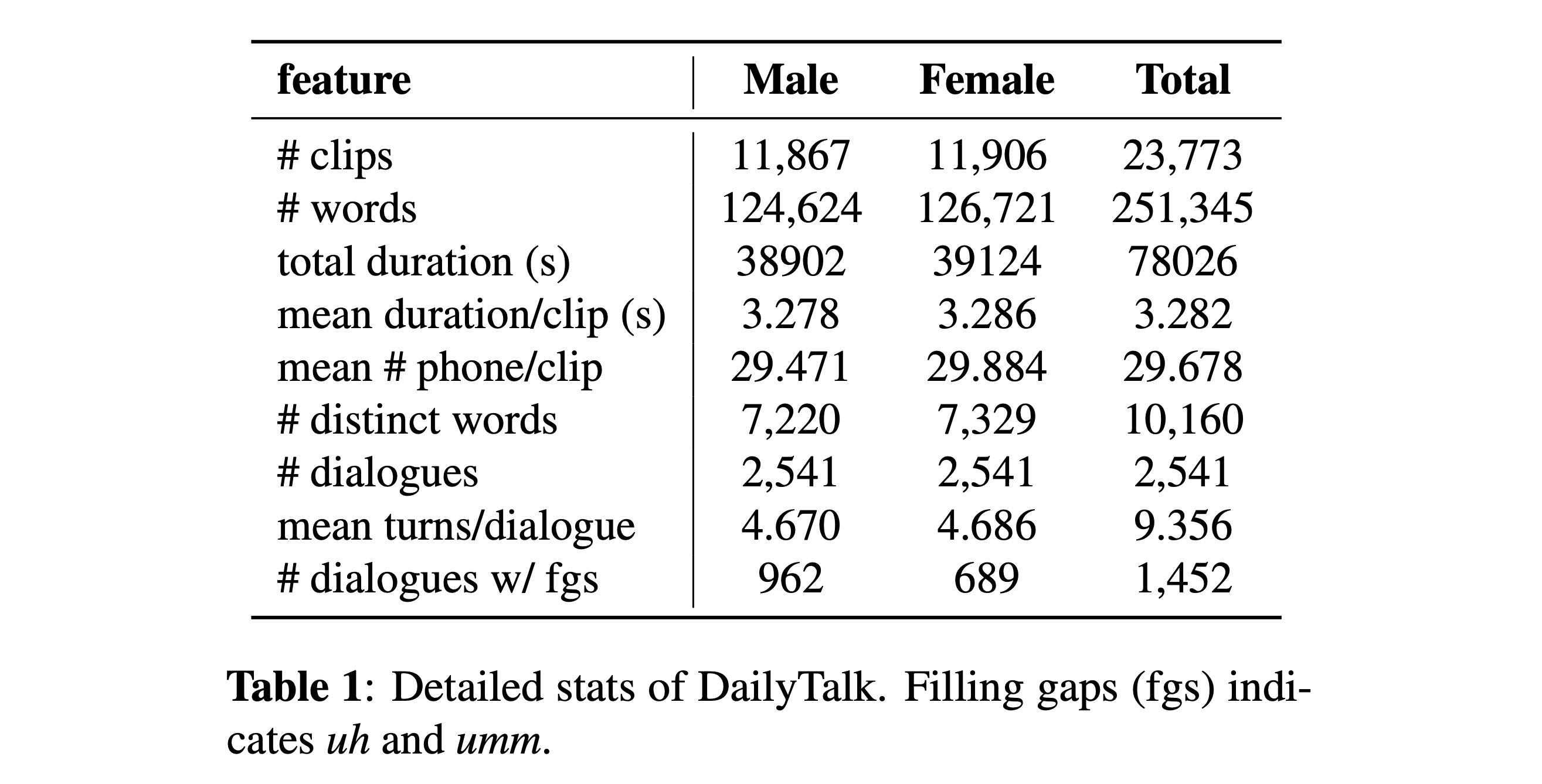
Вы можете скачать наш набор данных. Пожалуйста, обратитесь к статистическим деталям для деталей.
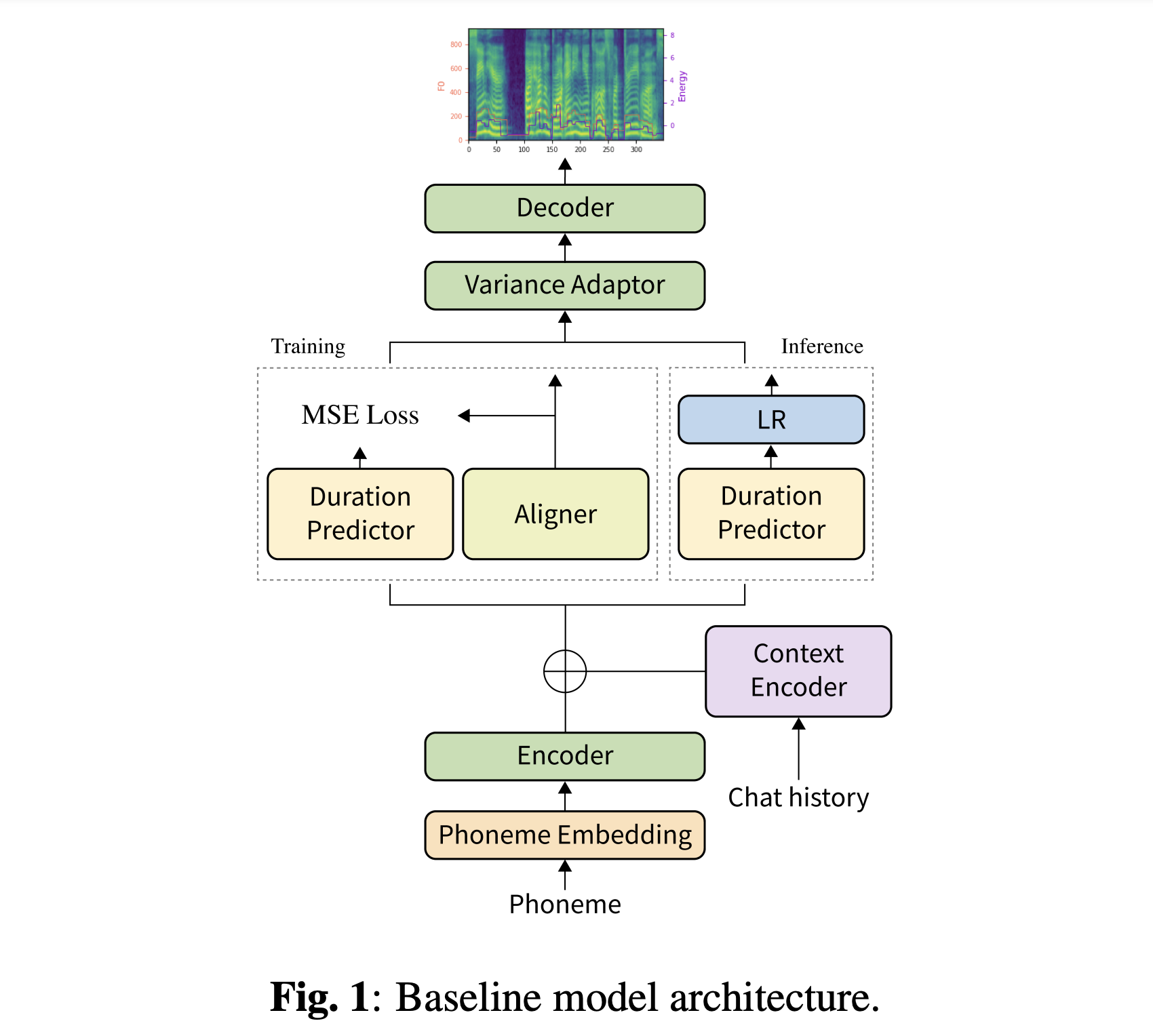
Вы можете скачать наши предварительные модели. Есть два разных каталога: 'storial_none' и 'stirory_guo'. Первый не имеет исторических кодировки, так что это не разговорная модель контекста. Последнее имеет исторические кодирования после разговорных сквозных TTS для голосового агента (Guo et al., 2020).
Переключить тип истории
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]Вы можете установить зависимости Python с
pip3 install -r requirements.txt
Кроме того, Dockerfile предоставлен для пользователей Docker .
Вы должны скачать оба нашего набора данных. Загрузите предварительные модели и поместите их в output/ckpt/DailyTalk/ . Также Unzip generator_LJSpeech.pth.tar или generator_universal.pth.tar в папке Hifigan. Модели обучаются с моделированием неконтролируемой продолжительности в рамках строительного блока трансформатора и типами кодировки истории.
Только пакетный вывод поддерживается, поскольку генерация поворота может нуждаться в контекстной истории разговора. Пытаться
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
Чтобы синтезировать все высказывания в preprocessed_data/DailyTalk/val_*.txt .
Для Multi-Speaker TTS с внешним динамиком Embedder загрузите Rescnn Softmax+триплетный предварительно предварительно предварительно проведенный модели DeepSpeaker Филипперей для динамика, внедряющего его и найдите его в ./deepspeaker/pretrained_models/ . Обратите внимание, что наши предварительные модели не обучены этим (они обучены speaker_embedder: "none" ).
Бегать
python3 prepare_align.py --dataset DailyTalk
для некоторых приготовлений.
Для принудительного выравнивания Монреаль принудительный выравниватель (MFA) используется для получения выравнивания между высказываниями и последовательностями фонем. Предварительные выравнивания для наборов данных представлены здесь. Вы должны расстегнуть разанипировать файлы в preprocessed_data/DailyTalk/TextGrid/ . С другой стороны, вы можете запустить выравниватель самостоятельно. Обратите внимание, что наши предварительные модели не обучены моделированию контролируемой продолжительности (они обучены learn_alignment: True ).
После этого запустите сценарий предварительной обработки
python3 preprocess.py --dataset DailyTalk
Тренировать свою модель с
python3 train.py --dataset DailyTalk
Полезные варианты:
--use_amp к вышеуказанной команде.CUDA_VISIBLE_DEVICES=<GPU_IDs> в начале вышеуказанной команды.Использовать
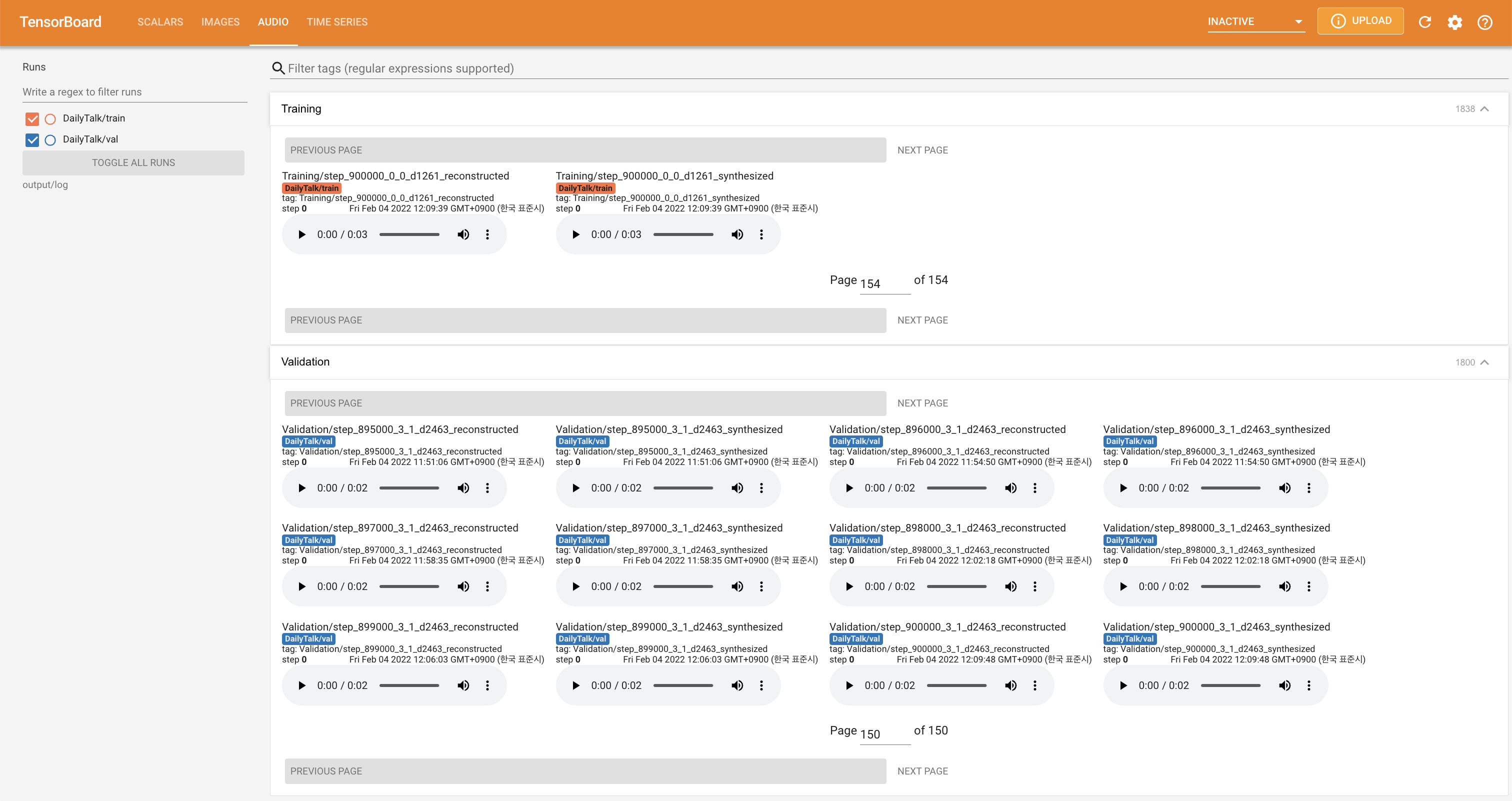
tensorboard --logdir output/log
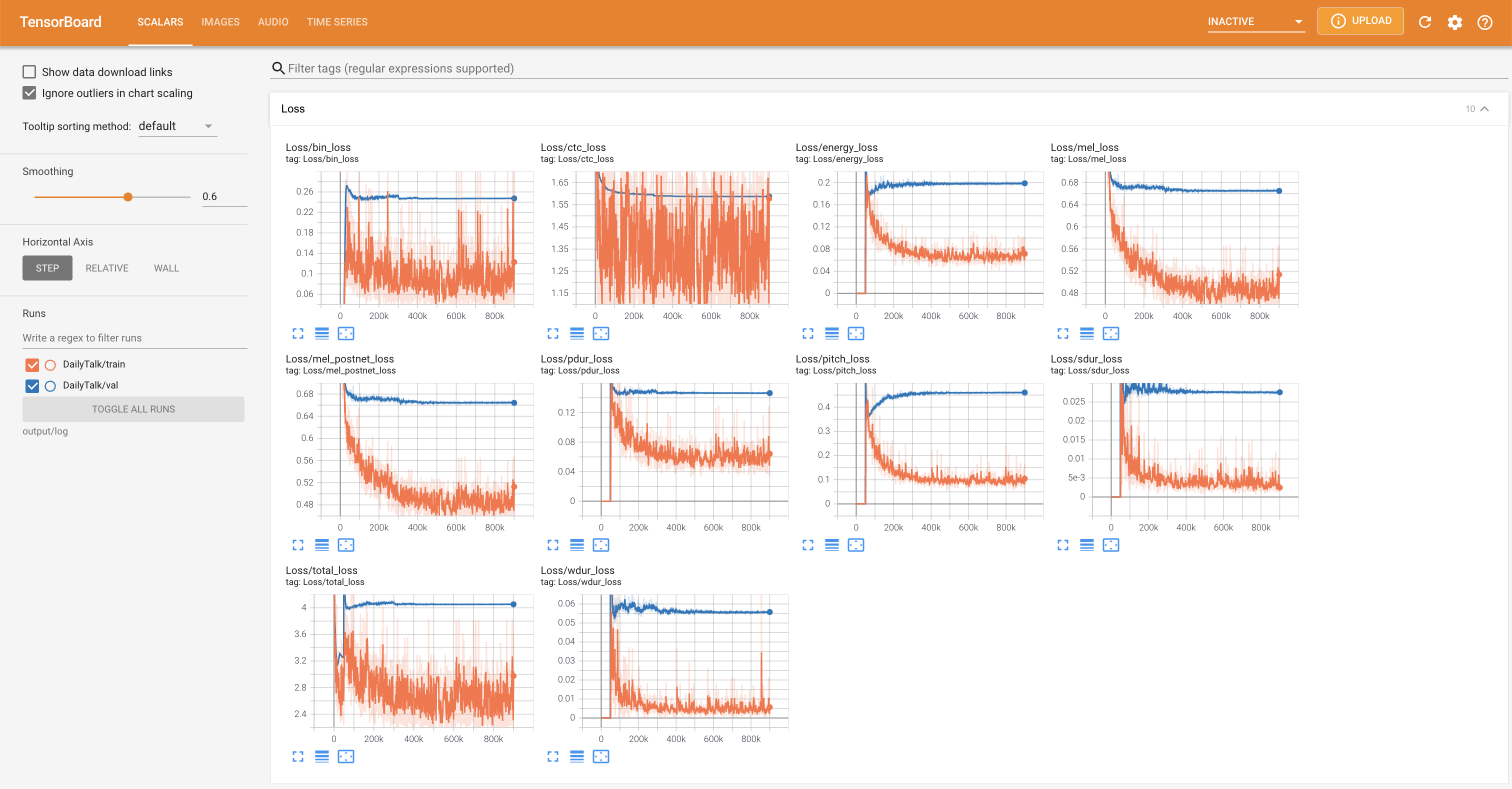
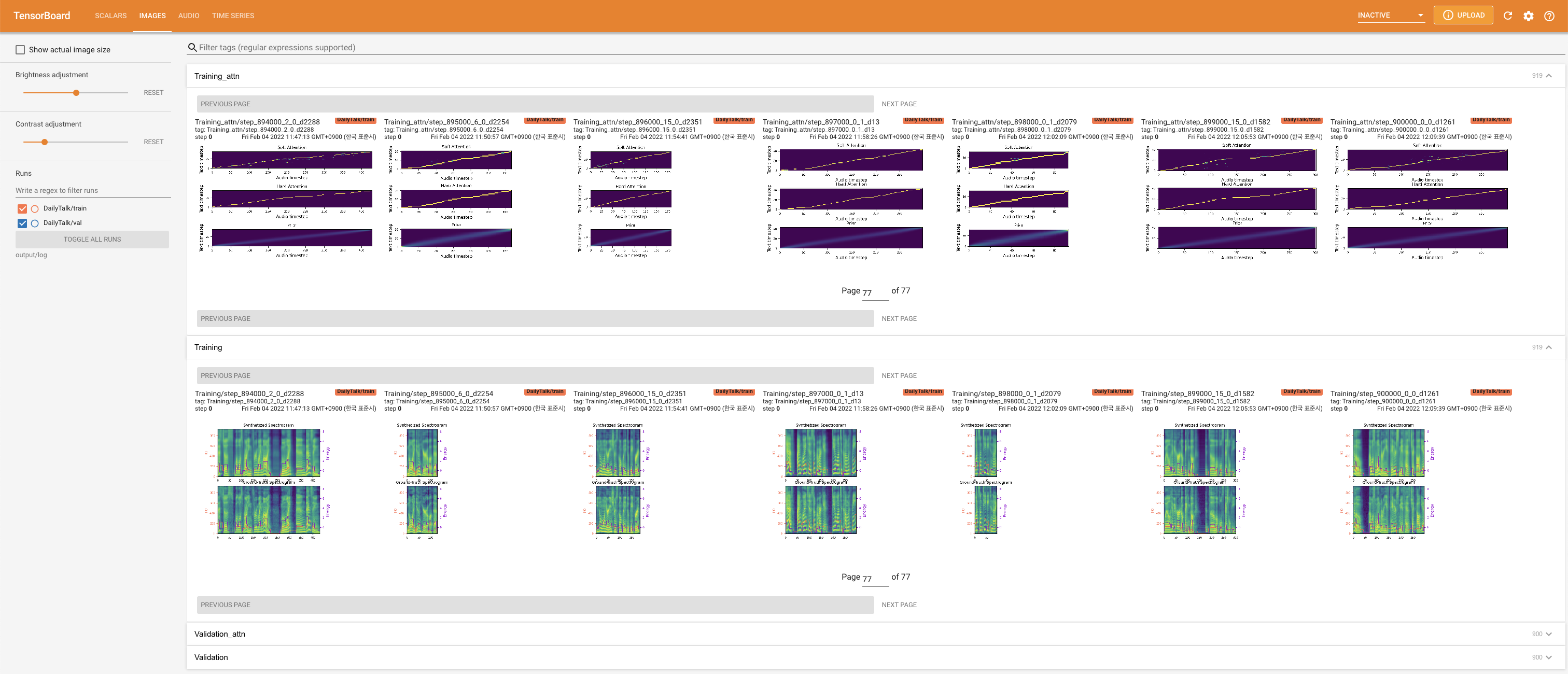
Подавать в Tensorboard на вашем местном хосте. Кривые потерь, синтезированные мель-спектрограммы и аудио показаны.
'none' и 'DeepSpeaker' ).Если вы хотите использовать наш набор данных и код или обратитесь к нашей статье, укажите следующее.
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
Эта работа лицензирована по международной лицензии Creative Commons Attribution-Sharealike 4.0.


