DailyTalk
v0.1.0
私たちの論文では、テキストからスピーチ用に設計された高品質の会話の音声データセットであるDailyTalkを紹介します。
要約:個々の発話のコレクションである現在のテキストからスピーチ(TTS)データセットの大部分には、会話の側面はほとんど含まれていません。この論文では、会話TTS向けに設計された高品質の会話の音声データセットであるDailyTalkを紹介します。オープンドメインダイアログデータセットのDailyDialogからの2,541のダイアログをサンプリング、修正、記録しました。データセットに加えて、以前の作業をベースラインとして拡張します。ここでは、非自動性TTSが対話の履歴情報を条件付けしています。一般的なメトリックと私たちの新しいメトリックの両方を使用したベースライン実験から、DailyTalkを一般的なTTSデータセットとして使用できることを示し、それ以上に、私たちのベースラインはDailyTalkからのコンテキスト情報を表すことができます。 DailyTalkデータセットとベースラインコードは、CC-SA 4.0ライセンスを使用して自由に利用できます。
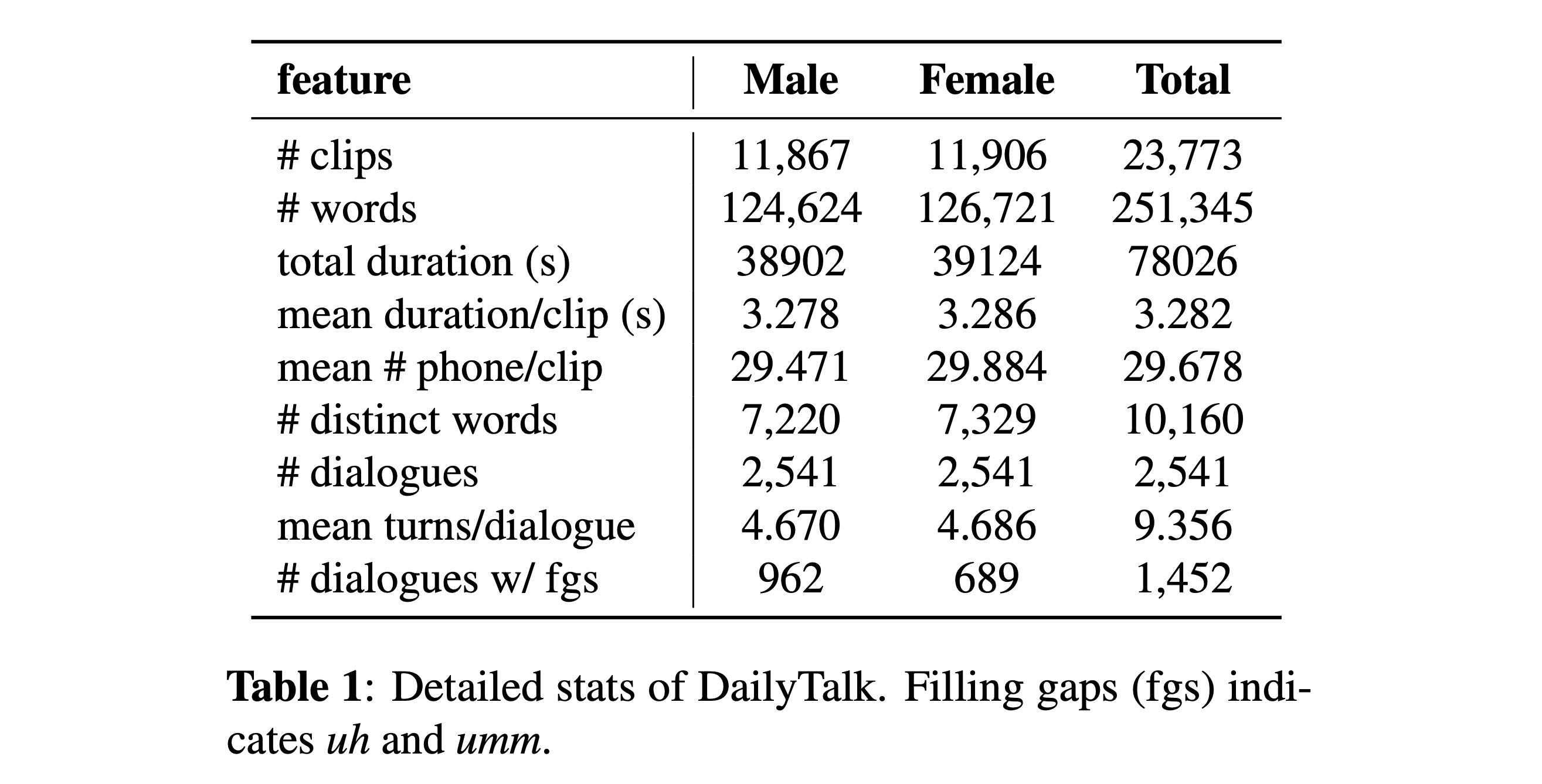
データセットをダウンロードできます。詳細については、統計の詳細を参照してください。
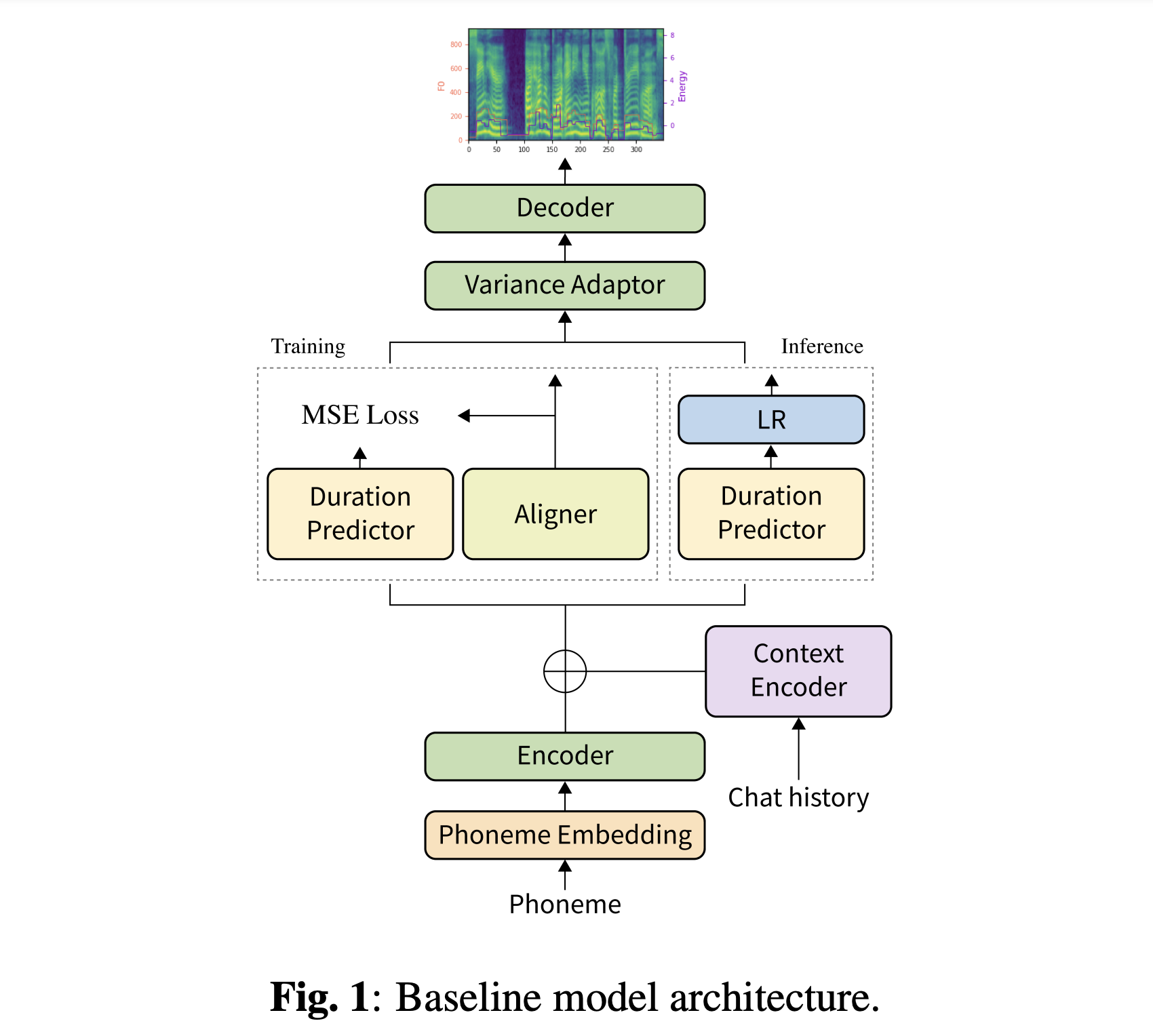
当初のモデルをダウンロードできます。 「history_none」と「history_guo」という2つの異なるディレクトリがあります。前者には歴史的なエンコーディングがないため、会話のコンテキスト対応モデルではありません。後者には、音声エージェント向けの会話型エンドツーエンドTTSに続く歴史的エンコーディングがあります(Guo et al。、2020)。
履歴エンコーディングのタイプを切り替えます
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]Python依存関係をインストールできます
pip3 install -r requirements.txt
また、 DockerfileはDockerユーザーに提供されています。
両方のデータセットをダウンロードする必要があります。事前に保護されたモデルをダウンロードして、それらをoutput/ckpt/DailyTalk/に入れます。また、hifiganフォルダーのgenerator_LJSpeech.pth.tarまたはgenerator_universal.pth.tarもunzip。モデルは、変圧器ビルディングブロックと履歴エンコーディングタイプの下で、監視されていない持続時間モデリングでトレーニングされています。
ターンの生成には会話の文脈的履歴が必要になる可能性があるため、バッチ推論のみがサポートされています。試す
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
preprocessed_data/DailyTalk/val_*.txtのすべての発話を合成するには。
外部スピーカーの封入器を備えたマルチスピーカーTTSについては、スピーカーの埋め込み用のPhilipperemyのディープスピーカーのRescnn SoftMax+Triplet Tretrained Modelをダウンロードし、それを./deepspeaker/pretrained_models/に見つけます。私たちの前提条件のモデルはこれで訓練されていないことに注意してください( speaker_embedder: "none"で訓練されています)。
走る
python3 prepare_align.py --dataset DailyTalk
いくつかの準備のために。
強制アライメントのために、モントリオールの強制アライナー(MFA)を使用して、発話と音素シーケンスの間のアライメントを取得します。データセットの事前に抽出されたアライメントはここに記載されています。 preprocessed_data/DailyTalk/TextGrid/でファイルを解凍する必要があります。または、自分でアライナーを実行できます。私たちの冒険モデルは、監視された持続時間モデリングでトレーニングされていないことに注意してください( learn_alignment: Trueでトレーニングされています)。
その後、前処理スクリプトを実行します
python3 preprocess.py --dataset DailyTalk
モデルを訓練します
python3 train.py --dataset DailyTalk
有用なオプション:
--use_amp引数を追加します。CUDA_VISIBLE_DEVICES=<GPU_IDs>を指定します。使用
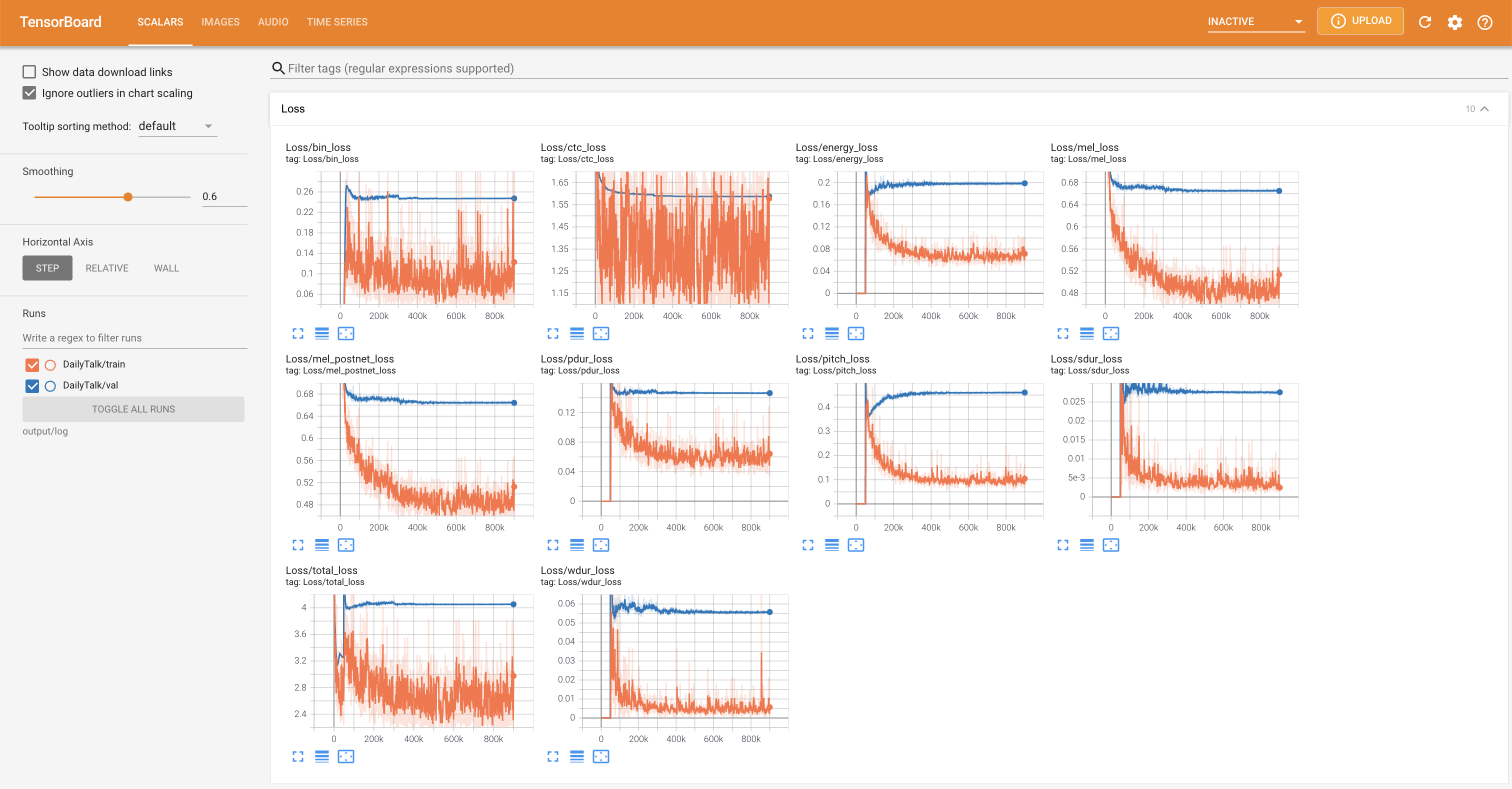
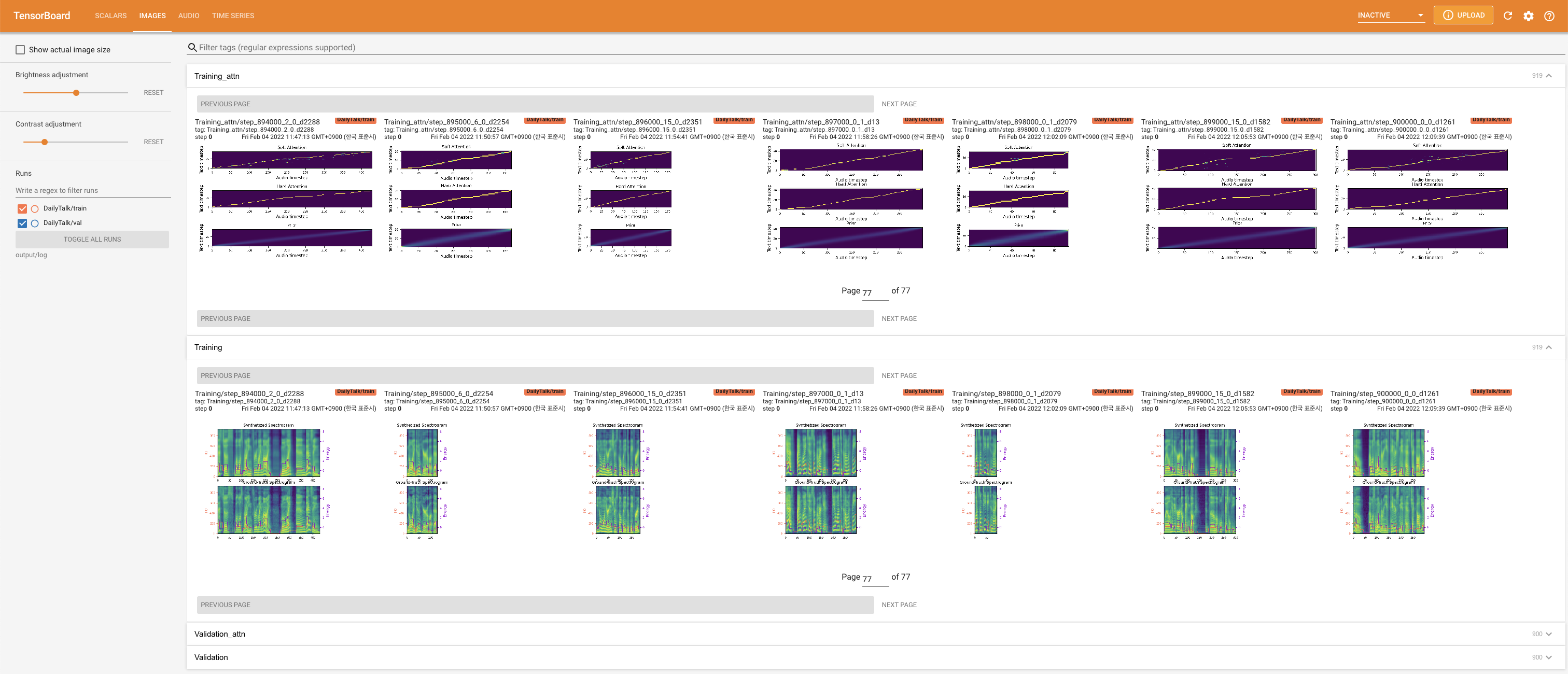
tensorboard --logdir output/log
LocalHostでTensorboardを提供します。損失曲線、合成されたメルスペクトルグラム、およびオーディオが表示されます。
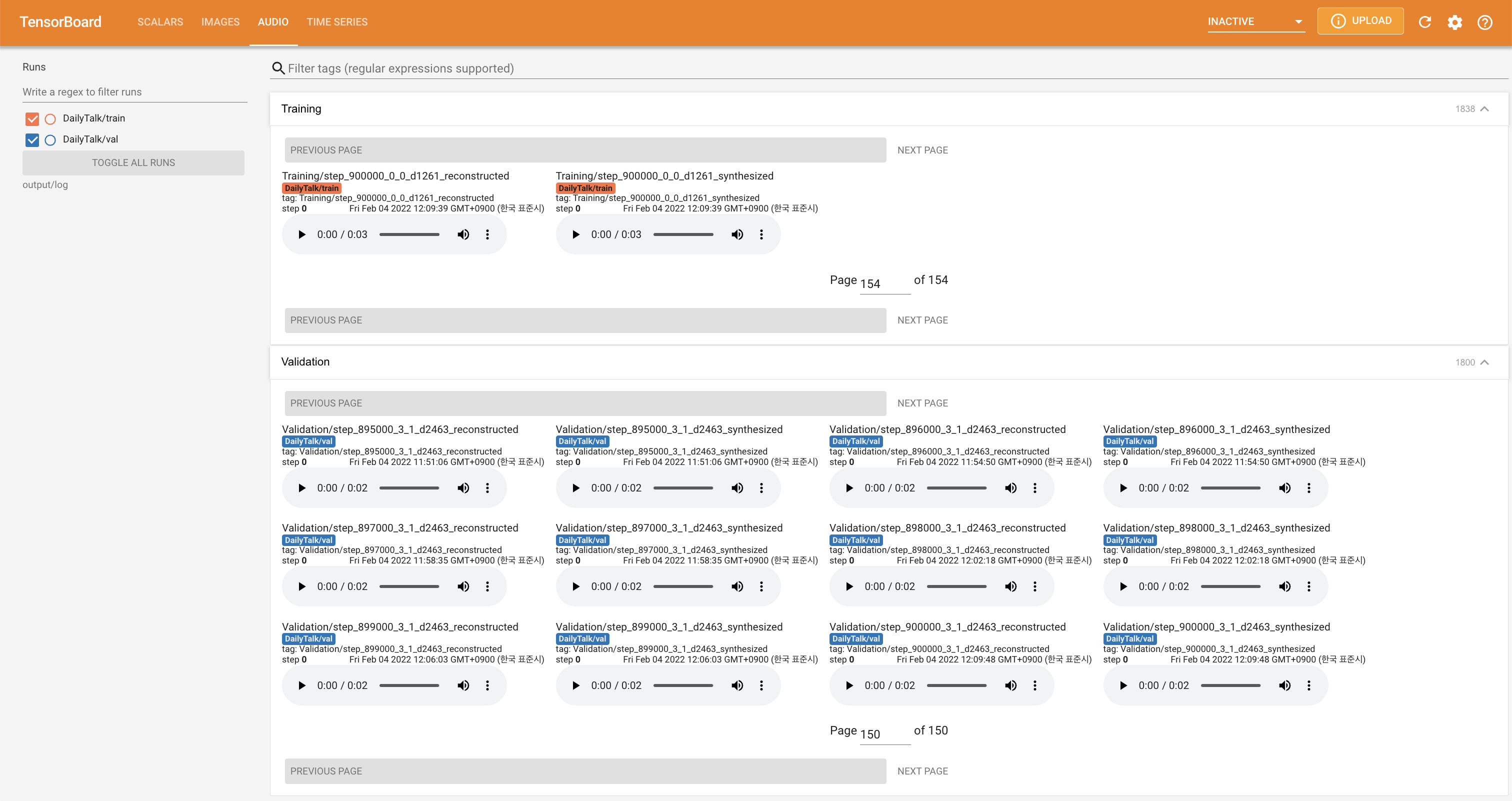
'none'と'DeepSpeaker'の間)を設定して切り替えることができます。データセットとコードを使用する場合、または私たちの論文を参照する場合は、次のように引用してください。
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
この作業は、Creative Commons Attribution-Sharealike 4.0 Internationalライセンスの下でライセンスされています。


