DailyTalk
v0.1.0
En nuestro artículo, presentamos a DailyTalk, un conjunto de datos de discurso conversacional de alta calidad diseñado para texto a voz.
Resumen: La mayoría de los conjuntos de datos actuales de texto a voz (TTS), que son colecciones de expresiones individuales, contienen pocos aspectos de conversación. En este artículo, presentamos a DailyTalk, un conjunto de datos de discurso conversacional de alta calidad diseñado para TTS conversacionales. Muestras, modificamos y registramos 2,541 diálogos del conjunto de datos de diálogo de dominio abierto DailyDialog heredando sus atributos anotados. Además de nuestro conjunto de datos, extendemos el trabajo previo como nuestra línea de base, donde un TTS no autorgresivo está condicionado a la información histórica en un diálogo. Desde el experimento de referencia con las métricas generales y nuevas, mostramos que DailyTalk puede usarse como un conjunto de datos TTS general, y más que eso, nuestra línea de base puede representar información contextual de DailyTalk. El conjunto de datos DailyTalk y el código de línea de base están disponibles gratuitamente para uso académico con la licencia CC-by-SA 4.0.
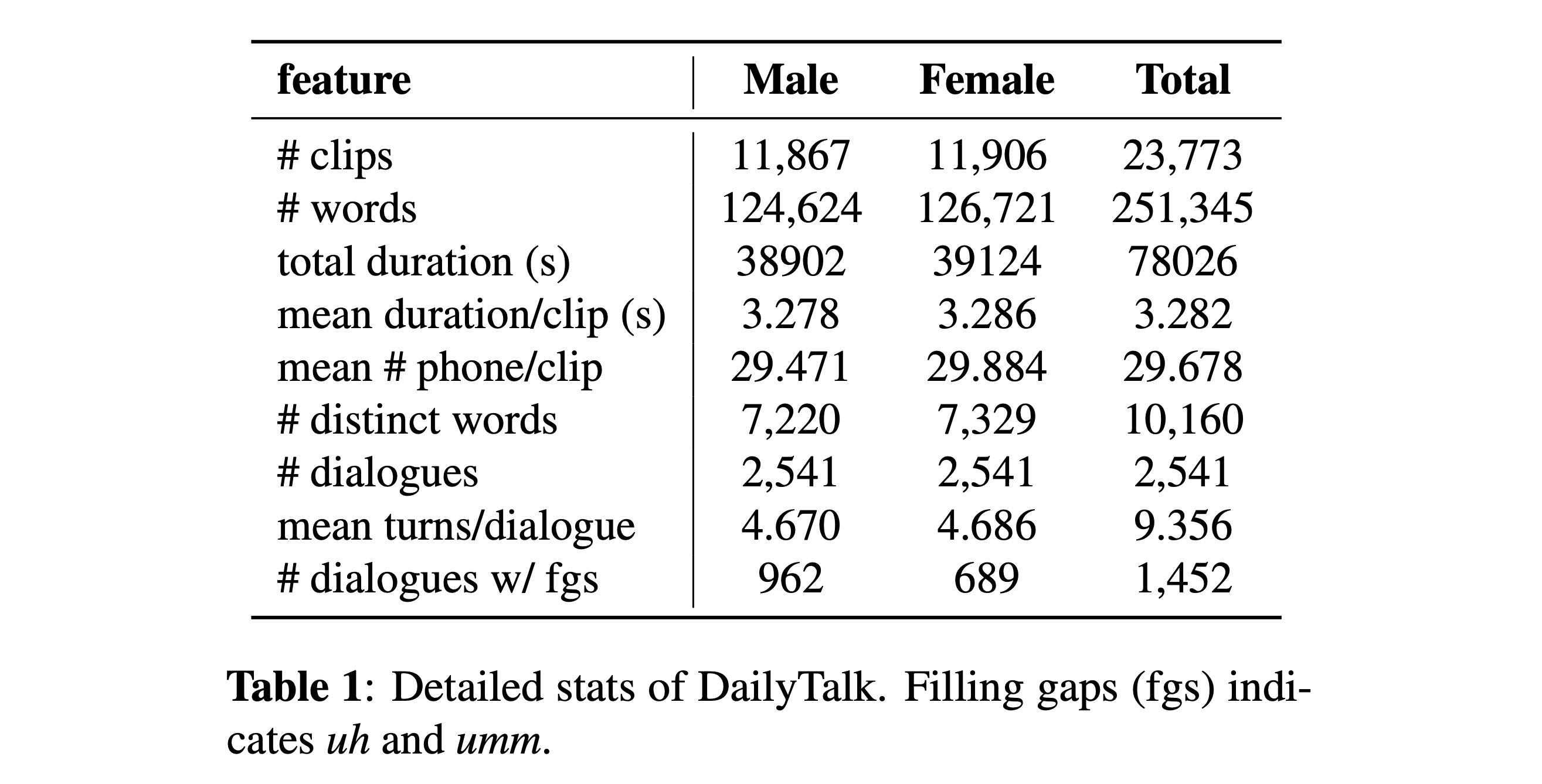
Puede descargar nuestro conjunto de datos. Consulte los detalles estadísticos para obtener detalles.
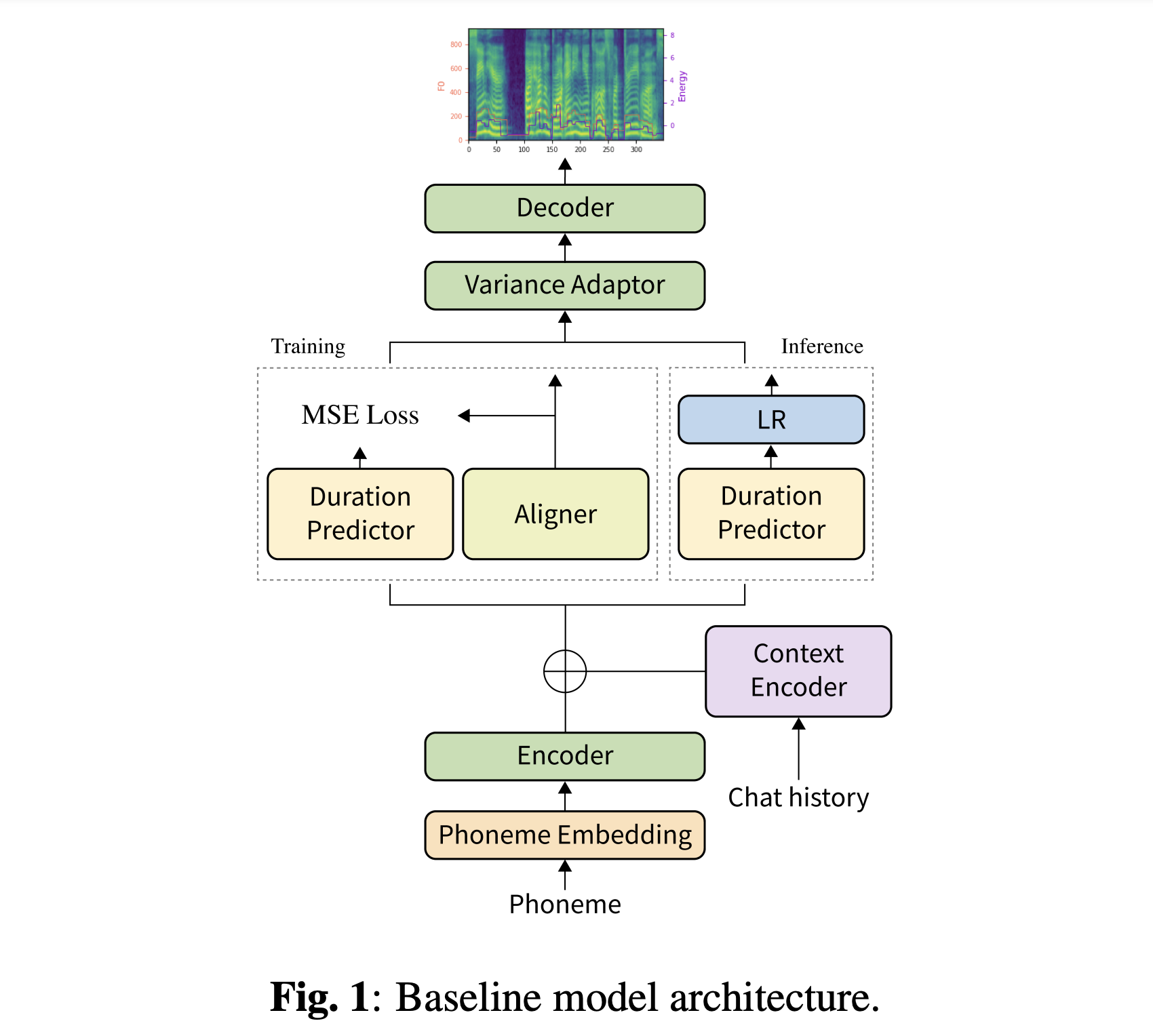
Puede descargar nuestros modelos previos a la aparición. Hay dos directorios diferentes: 'History_None' y 'History_Guo'. El primero no tiene codificaciones históricas para que no sea un modelo de contexto conversacional. Este último tiene codificaciones históricas después de TTS de extremo a extremo conversacional para el agente de voz (Guo et al., 2020).
Alternar el tipo de codificaciones de historial de
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]Puede instalar las dependencias de Python con
pip3 install -r requirements.txt
Además, Dockerfile se proporciona para los usuarios Docker .
Tienes que descargar tanto nuestro conjunto de datos. Descargue los modelos previos a la aparición y póngalos en output/ckpt/DailyTalk/ . También unzip generator_LJSpeech.pth.tar o generator_universal.pth.tar en la carpeta Hifigan. Los modelos están entrenados con modelado de duración no supervisado bajo el bloque de construcción del transformador y los tipos de codificación del historial.
Solo la inferencia por lotes es compatible ya que la generación de un giro puede necesitar historia contextual de la conversación. Intentar
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
Para sintetizar todas las expresiones en preprocessed_data/DailyTalk/val_*.txt .
Para un TTS de múltiples altavoces con un incrustador de altavoces externo, descargue el modelo de retraso previo al petróleo rescnn Softmax+de Filipperemy's DeepSpeaker para la incrustación del altavoz y lo ubique ./deepspeaker/pretrained_models/ Tenga en cuenta que nuestros modelos previos al estado de trabajo no están entrenados con esto (están entrenados con speaker_embedder: "none" ).
Correr
python3 prepare_align.py --dataset DailyTalk
para algunos preparativos.
Para la alineación forzada, el alineador forzado de Montreal (MFA) se usa para obtener las alineaciones entre las expresiones y las secuencias de fonema. Aquí se proporcionan alineaciones preextracidas para los conjuntos de datos. Debe descomprimir los archivos en preprocessed_data/DailyTalk/TextGrid/ . Alternativamente, puede ejecutar el alineador usted mismo. Tenga en cuenta que nuestros modelos previos al estado previamente están capacitados con modelado de duración supervisado (están entrenados con learn_alignment: True ).
Después de eso, ejecute el script de preprocesamiento por
python3 preprocess.py --dataset DailyTalk
Entrena tu modelo con
python3 train.py --dataset DailyTalk
Opciones útiles:
--use_amp al comando anterior.CUDA_VISIBLE_DEVICES=<GPU_IDs> al comienzo del comando anterior.Usar
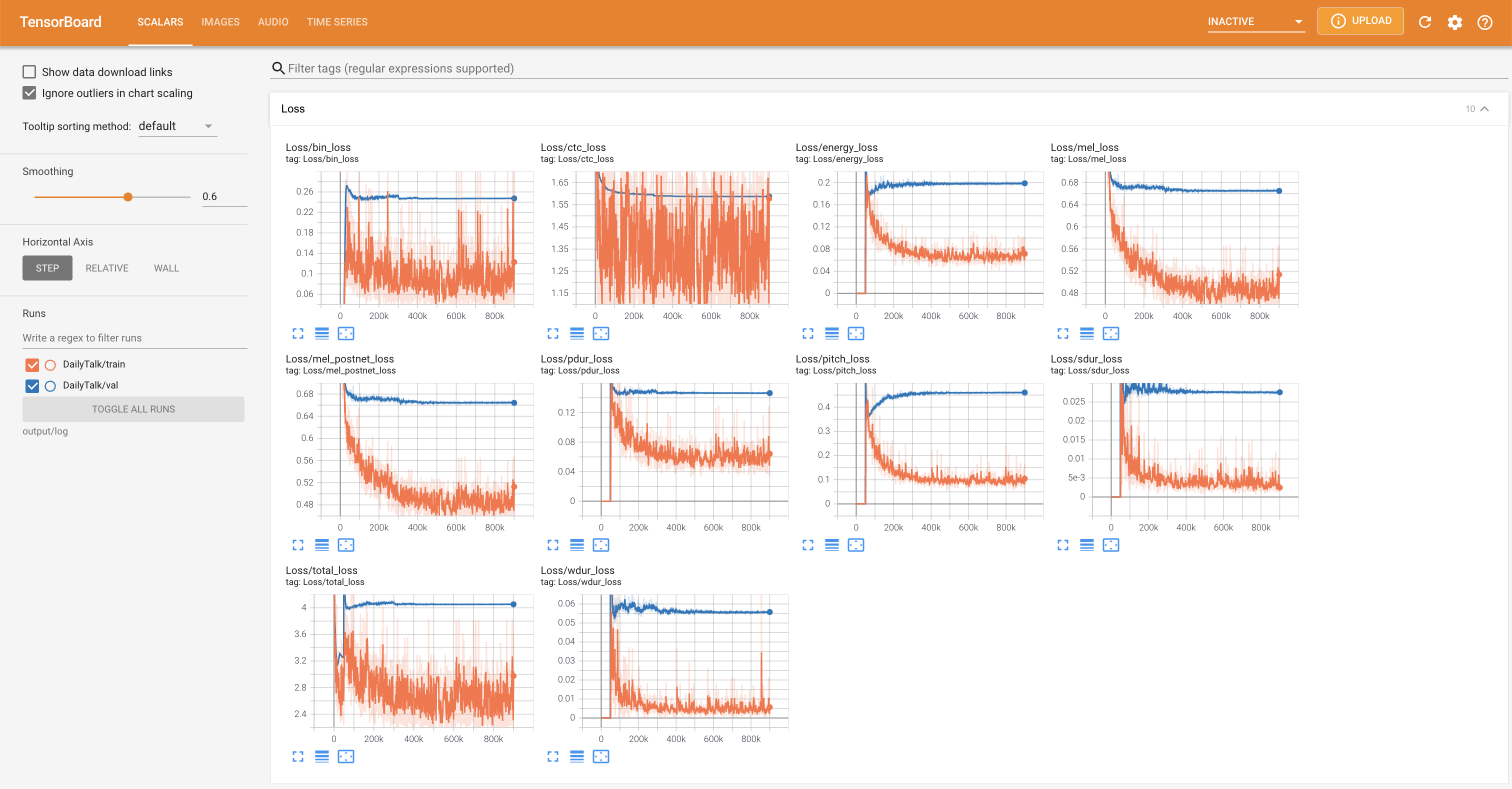
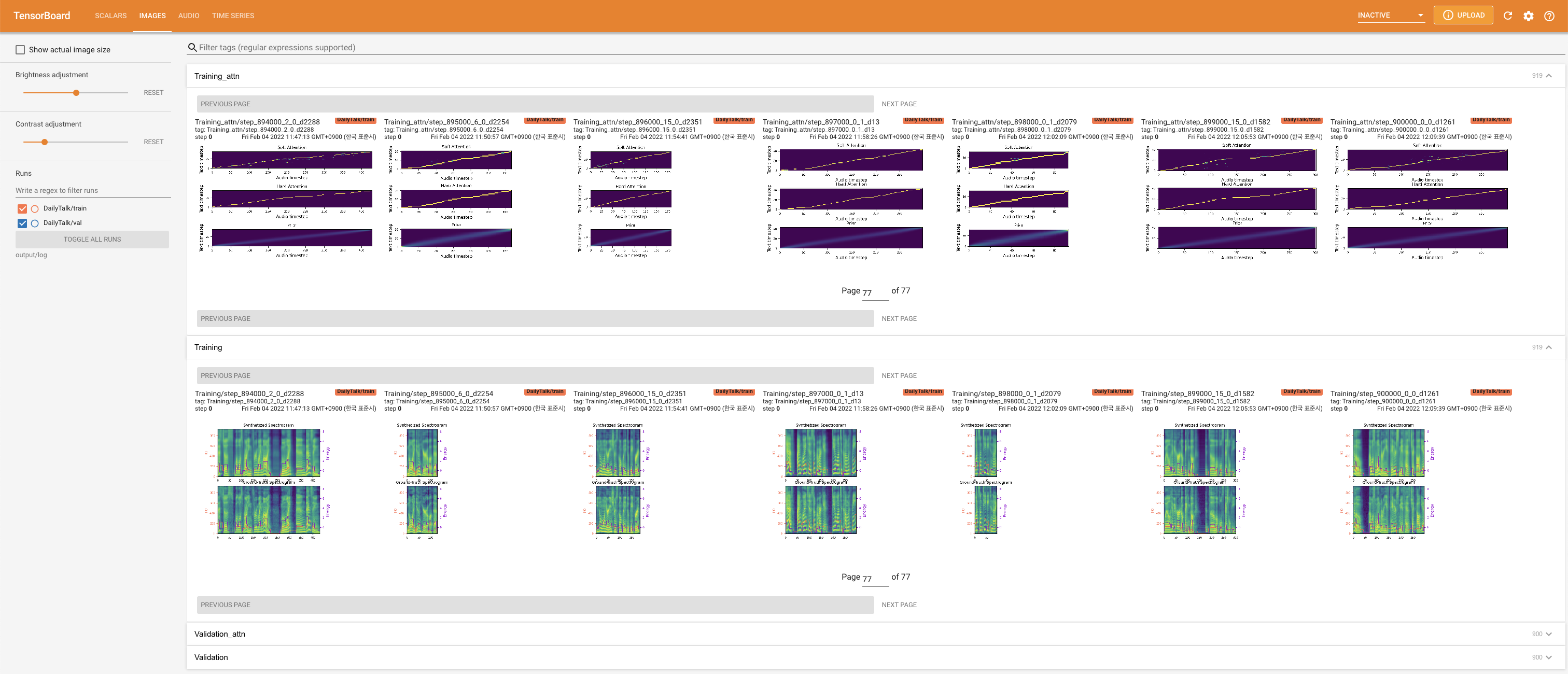
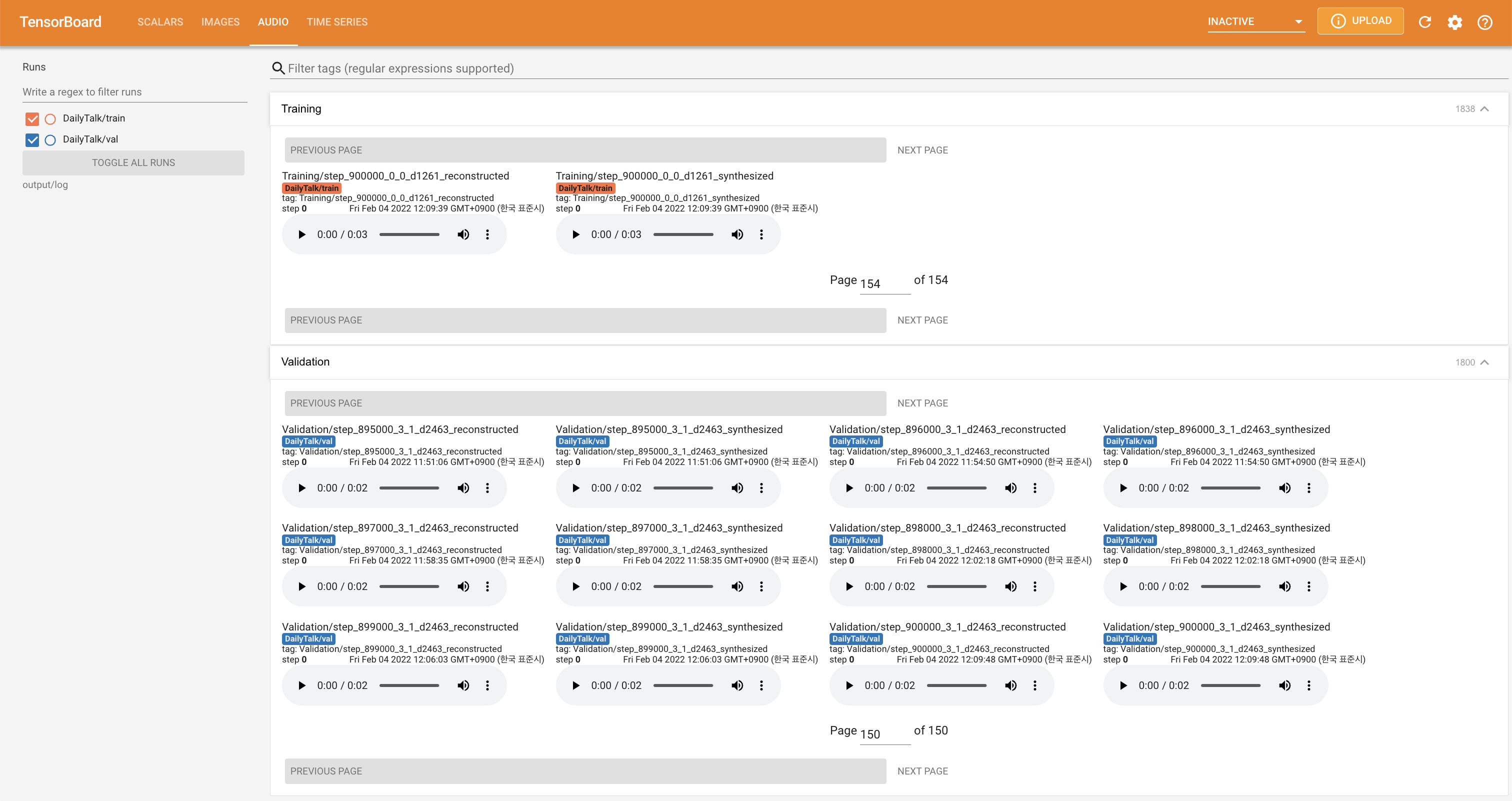
tensorboard --logdir output/log
para servir tensorboard en su localhost. Se muestran las curvas de pérdida, los espectrogramas MEL sintetizados y los audios.
'none' y 'DeepSpeaker' ).Si desea utilizar nuestro conjunto de datos y código o consultar nuestro documento, cite de la siguiente manera.
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
Este trabajo tiene licencia bajo una licencia internacional de atribución de los comunes y sharealike 4.0.


