DailyTalk
v0.1.0
In unserem Artikel stellen wir DailyTalk vor, ein hochwertiges Gesprächs-Sprachdatensatz für Text-to-Speech.
Zusammenfassung: Die Mehrheit der TTS-Datensätze (TTS) der aktuellen Text-zu-Sprache, die Sammlungen einzelner Äußerungen sind, enthält nur wenige Konversationsaspekte. In diesem Artikel stellen wir DailyTalk vor, ein hochwertiges Gesprächs-Sprachdatensatz für TTs mit Gesprächen. Wir haben 2.541 Dialoge aus dem Open-Domain-Dialog-Dataset DailyDialog probiert, modifiziert und aufgezeichnet, in dem er seine kommentierten Attribute erbt. Zusätzlich zu unserem Datensatz erweitern wir frühere Arbeit als unsere Grundlinie, bei der ein nicht autoregressives TTS auf historische Informationen in einem Dialog bezieht. Aus dem Baseline -Experiment mit allgemeinen und unseren neuartigen Metriken zeigen wir, dass DailyTalk als allgemeiner TTS -Datensatz verwendet werden kann, und darüber hinaus kann unsere Grundlinie Kontextinformationen aus DailyTalk darstellen. Der DailyTalk-Datensatz und der Basiscode sind für die akademische Verwendung mit CC-by-SA 4.0-Lizenz frei verfügbar.
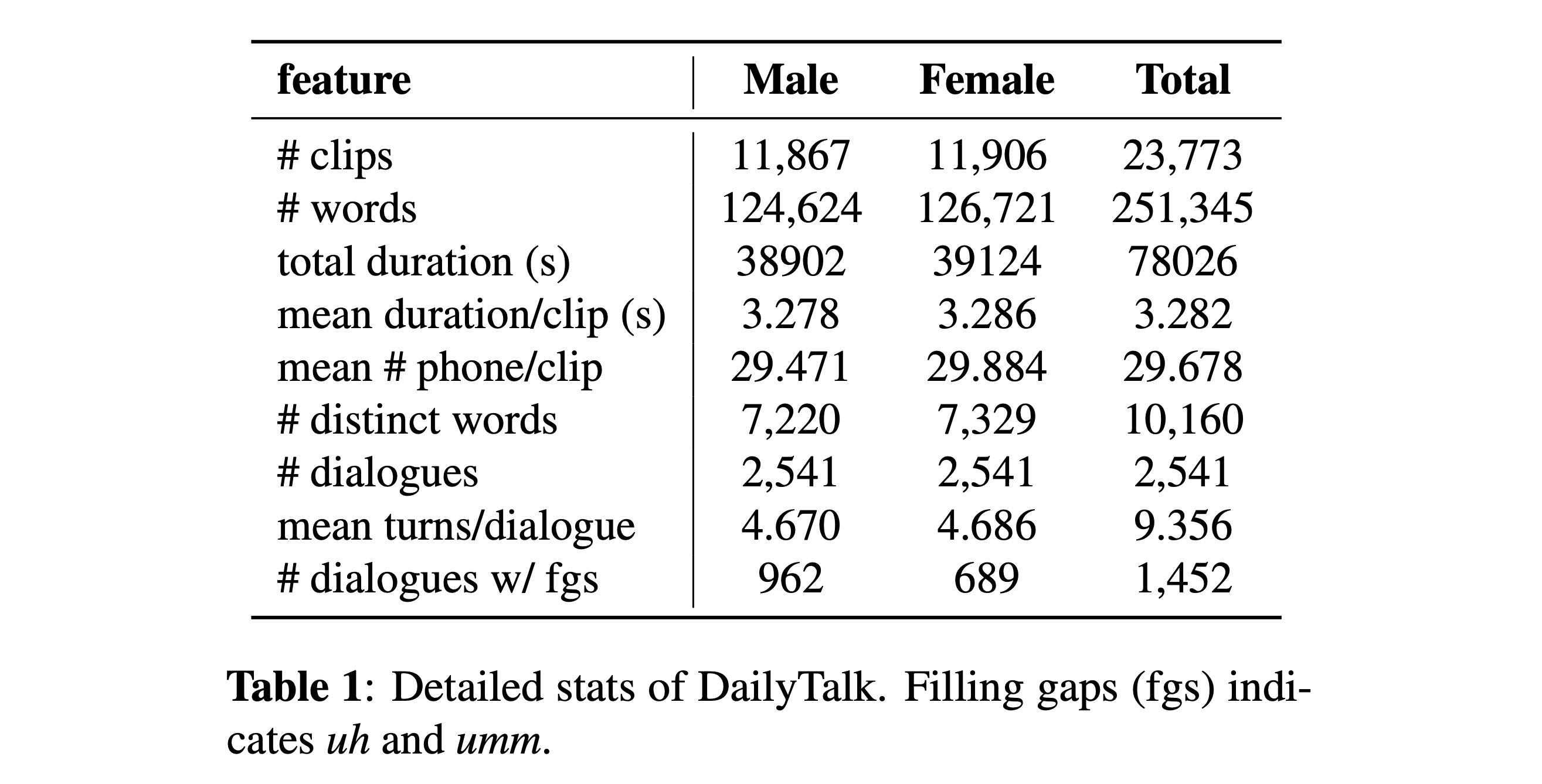
Sie können unseren Datensatz herunterladen. Weitere Informationen finden Sie in statistischen Details.
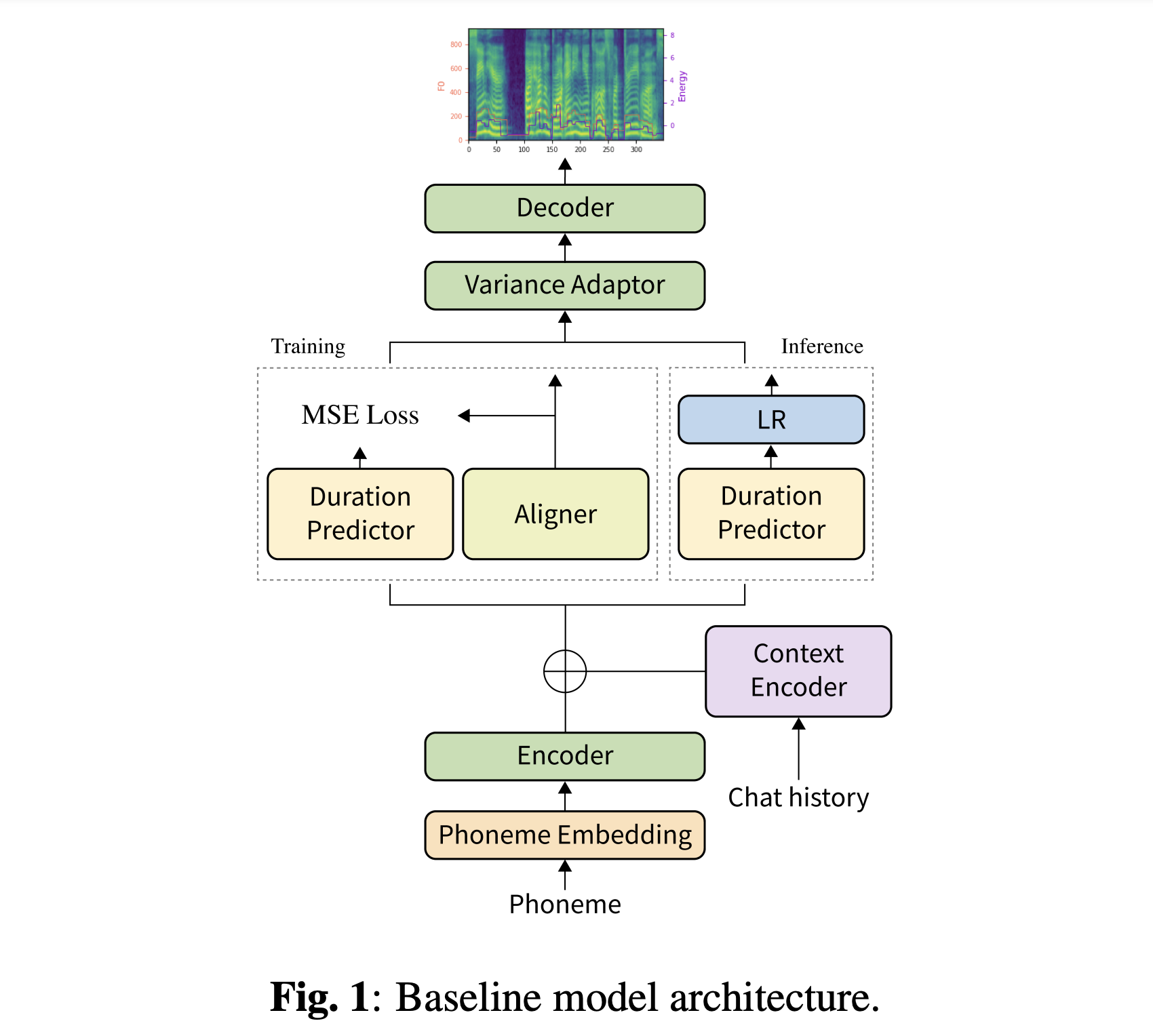
Sie können unsere vorbereiteten Modelle herunterladen. Es gibt zwei verschiedene Verzeichnisse: 'History_None' und 'History_Guo'. Ersteres hat keine historischen Kodierungen, so dass es sich nicht um ein konversatives Kontextmodell handelt. Letzteres hat historische Kodierungen nach Gesprächspartnern für die TTS für Sprachagent (Guo et al., 2020).
Schalten Sie die Art der Geschichtskodierungen durch
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]Sie können die Python -Abhängigkeiten mit installieren
pip3 install -r requirements.txt
Außerdem wird Dockerfile für Docker -Benutzer bereitgestellt.
Sie müssen beide unseren Datensatz herunterladen. Laden Sie vorgezogene Modelle herunter und geben Sie sie in output/ckpt/DailyTalk/ . Auch Unzip generator_LJSpeech.pth.tar oder generator_universal.pth.tar im Hifigan -Ordner. Die Modelle werden mit unbeaufsichtigter Dauermodellierung unter Transformator Building Block und den History Coding -Typen geschult.
Nur die Batch -Inferenz wird unterstützt, da die Erzeugung einer Kurve möglicherweise eine kontextbezogene Geschichte des Gesprächs erfordert. Versuchen
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
So synthetisieren Sie alle Äußerungen in preprocessed_data/DailyTalk/val_*.txt
Download für ein Multi-Sprecher-TTS mit einem externen Lautsprecher-Einbettder Rescnn Softmax+Triplet Pretrainierte Modell von Philipperemy's Deepspeaker für den Lautsprecher-Einbettung und lokalisiert es in ./deepspeaker/pretrained_models/ . Bitte beachten Sie, dass unsere vorbereiteten Modelle nicht damit trainiert sind (sie werden mit speaker_embedder: "none" ).
Laufen
python3 prepare_align.py --dataset DailyTalk
Für einige Vorbereitungen.
Für die erzwungene Ausrichtung wird Montreal erzwungene Aligner (MFA) verwendet, um die Ausrichtungen zwischen den Äußerungen und den Phonemsequenzen zu erhalten. Vorextrahierte Ausrichtungen für die Datensätze werden hier bereitgestellt. Sie müssen die Dateien in preprocessed_data/DailyTalk/TextGrid/ entpacken. Alternativ können Sie den Aligner selbst ausführen. Bitte beachten Sie, dass unsere vorbereiteten Modelle nicht mit beaufsichtigter Dauermodellierung ausgebildet sind (sie werden mit learn_alignment: True trainiert).
Führen Sie danach das Vorverarbeitungskript durch
python3 preprocess.py --dataset DailyTalk
Trainieren Sie Ihr Modell mit
python3 train.py --dataset DailyTalk
Nützliche Optionen:
--use_amp Argument für den obigen Befehl.CUDA_VISIBLE_DEVICES=<GPU_IDs> an.Verwenden
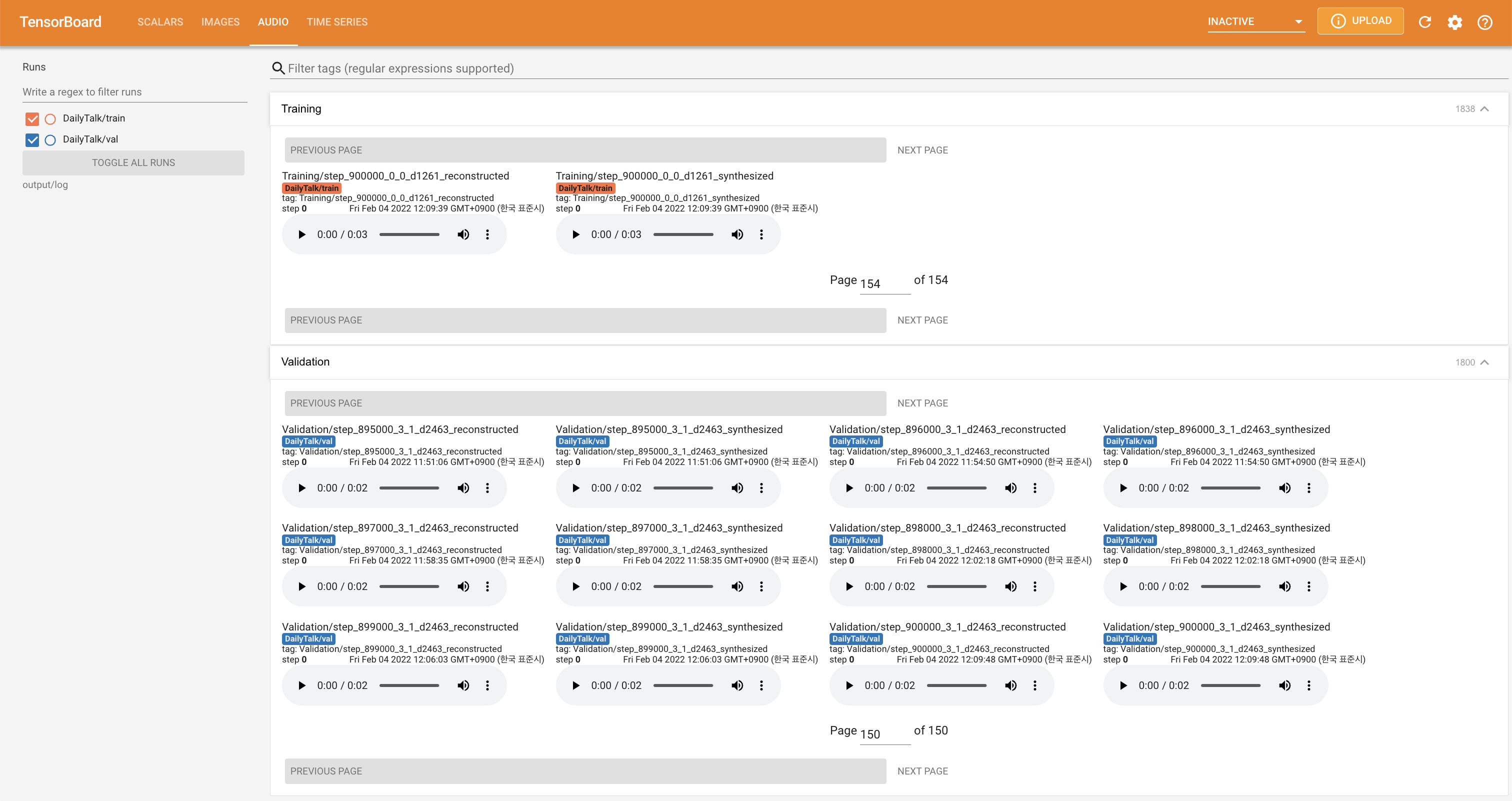
tensorboard --logdir output/log
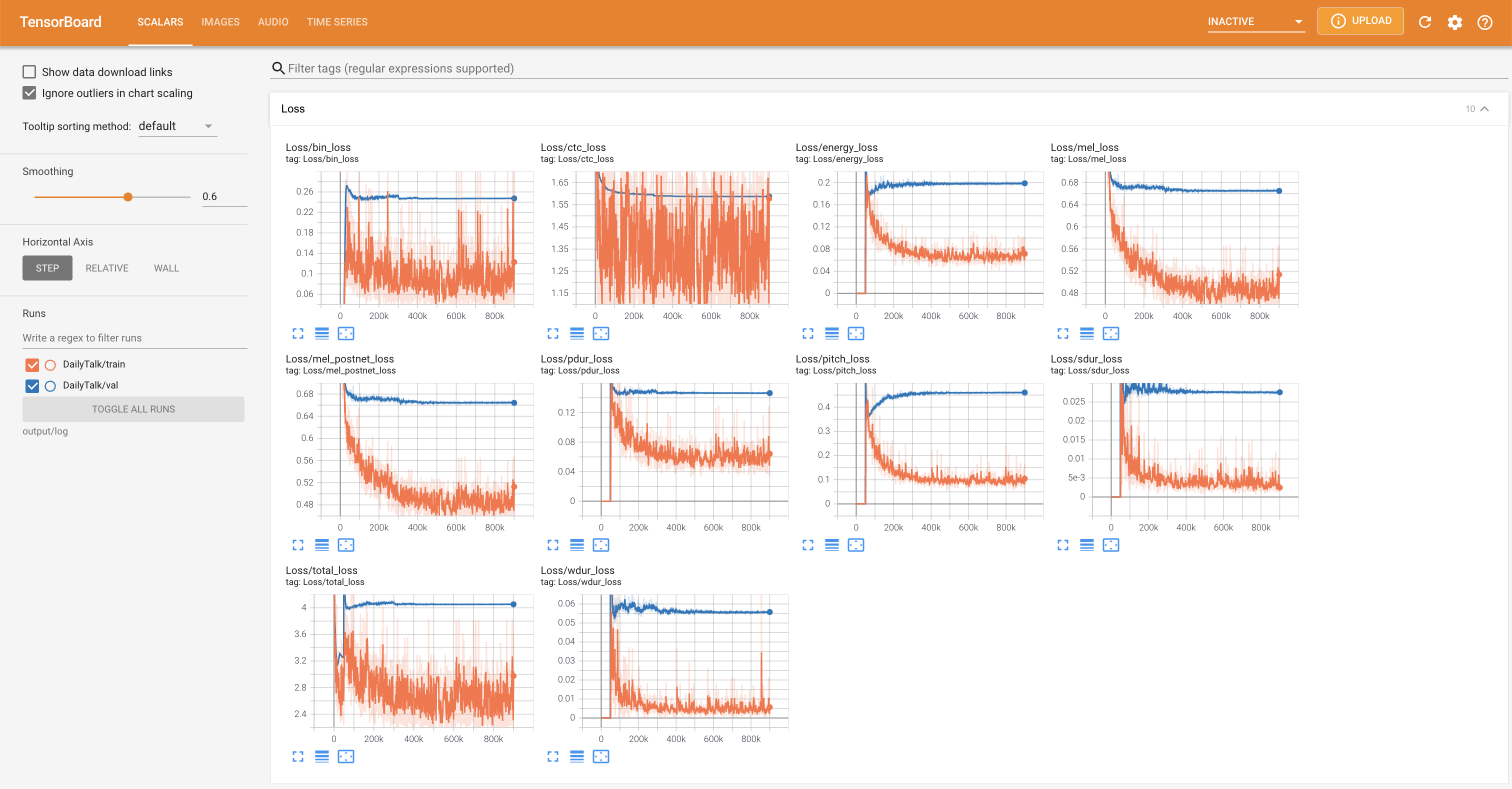
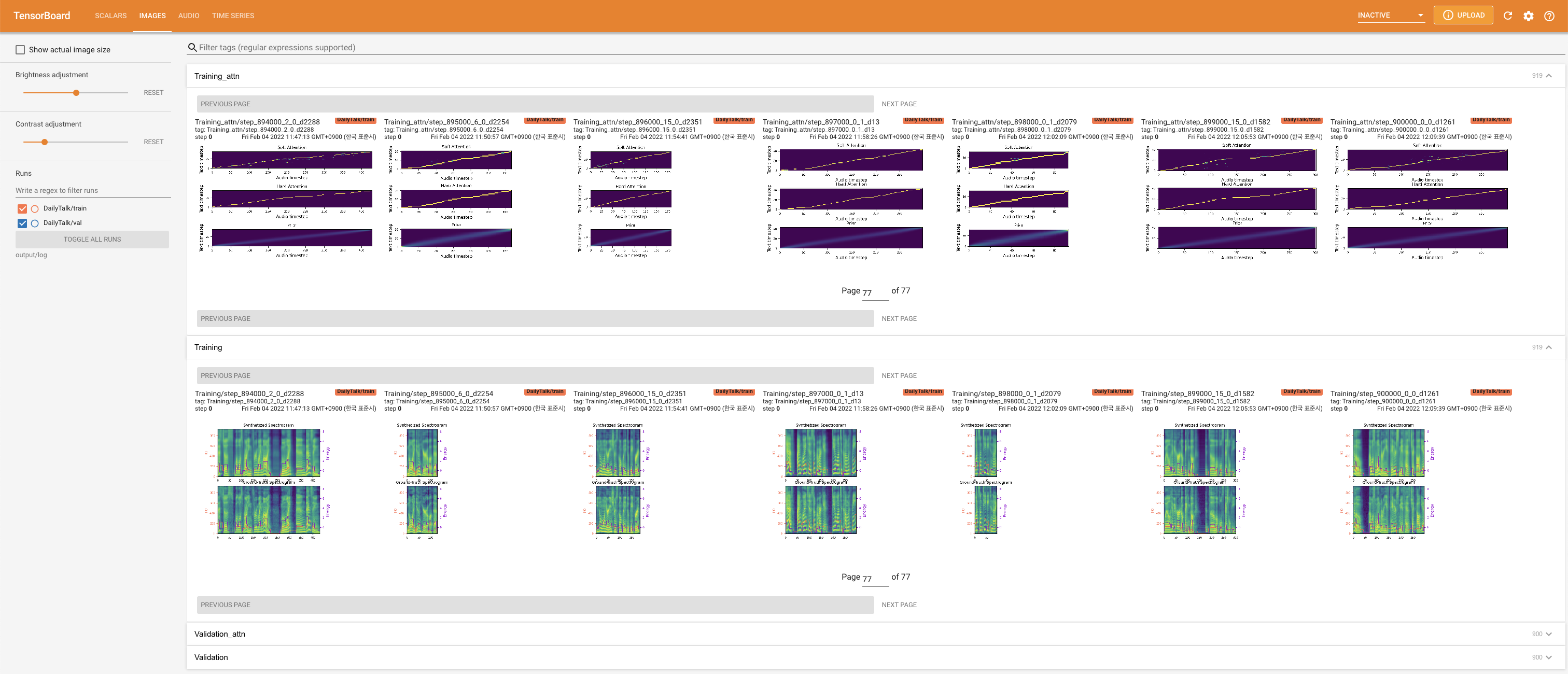
Tensorboard auf Ihrem örtlichen Haus servieren. Die Verlustkurven, synthetisierte Melspektrogramme und Audios werden gezeigt.
'none' und 'DeepSpeaker' ) einstellen.Wenn Sie unseren Datensatz und unseren Code verwenden oder auf unser Papier verweisen möchten, zitieren Sie bitte wie folgt.
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
Diese Arbeit ist im Rahmen einer Creative Commons Attribution-Sharealike 4.0 International Lizenz lizenziert.


