DailyTalk
v0.1.0
Dalam makalah kami, kami memperkenalkan DailyTalk, dataset pidato percakapan berkualitas tinggi yang dirancang untuk teks-ke-bicara.
Abstrak: Mayoritas dataset teks-ke-speech (TTS) saat ini, yang merupakan koleksi ucapan individu, berisi beberapa aspek percakapan. Dalam makalah ini, kami memperkenalkan DailyTalk, dataset pidato percakapan berkualitas tinggi yang dirancang untuk TTS percakapan. Kami mencicipi, memodifikasi, dan merekam 2.541 dialog dari dataset dialog domain terbuka DailyDialog yang mewarisi atribut beranotasi. Di atas dataset kami, kami memperluas pekerjaan sebelumnya sebagai baseline kami, di mana TTS non-autoregresif dikondisikan pada informasi historis dalam dialog. Dari percobaan dasar dengan metrik umum dan novel kami, kami menunjukkan bahwa DailyTalk dapat digunakan sebagai dataset TTS umum, dan lebih dari itu, baseline kami dapat mewakili informasi kontekstual dari DailyTalk. Dataset DailyTalk dan kode dasar tersedia secara bebas untuk penggunaan akademik dengan lisensi CC-by-SA 4.0.
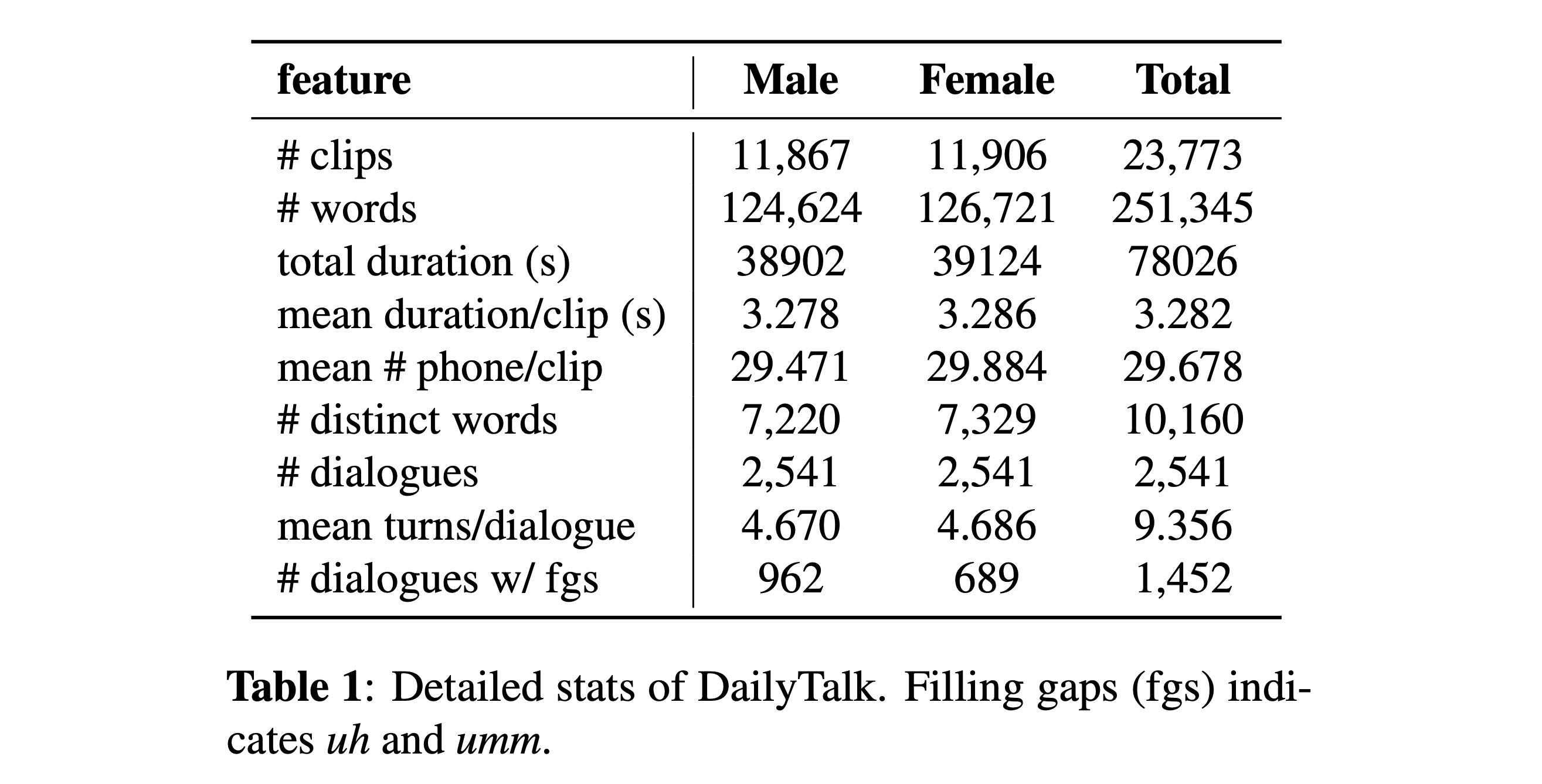
Anda dapat mengunduh dataset kami. Silakan merujuk ke detail statistik untuk detailnya.
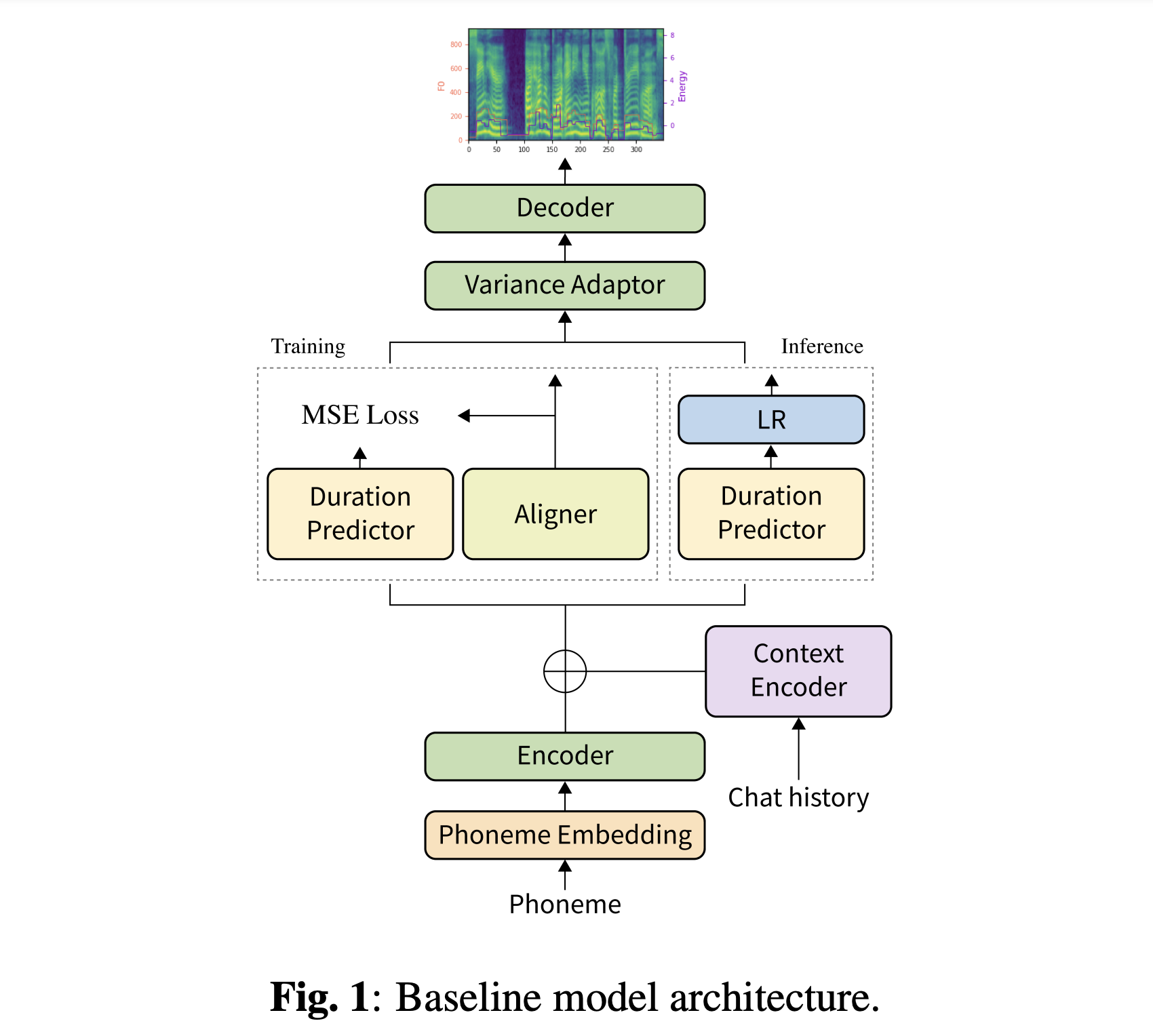
Anda dapat mengunduh model pretrained kami. Ada dua direktori yang berbeda: 'history_none' dan 'history_guo'. Yang pertama tidak memiliki pengkodean historis sehingga bukan model yang sadar konteks percakapan. Yang terakhir memiliki pengkodean historis mengikuti TTS end-to-end percakapan untuk agen suara (Guo et al., 2020).
Beralihnya jenis pengkodean riwayat oleh
# In the model.yaml
history_encoder :
type : " Guo " # ["none", "Guo"]Anda dapat menginstal dependensi Python dengan
pip3 install -r requirements.txt
Juga, Dockerfile disediakan untuk pengguna Docker .
Anda harus mengunduh kedua dataset kami. Unduh model pretrained dan letakkan di output/ckpt/DailyTalk/ . Juga unzip generator_LJSpeech.pth.tar atau generator_universal.pth.tar di folder hifigan. Model dilatih dengan pemodelan durasi tanpa pengawasan di bawah blok bangunan transformator dan jenis pengkodean sejarah.
Hanya inferensi batch yang didukung karena generasi putaran mungkin memerlukan sejarah kontekstual percakapan. Mencoba
python3 synthesize.py --source preprocessed_data/DailyTalk/val_*.txt --restore_step RESTORE_STEP --mode batch --dataset DailyTalk
Untuk mensintesis semua ucapan di preprocessed_data/DailyTalk/val_*.txt .
Untuk TTS multi-speaker dengan embedder speaker eksternal, unduh rescnn softmax+triplet pretrained model Deepspeaker Philipperemy untuk penyematan speaker dan temukan di ./deepspeaker/pretrained_models/ . Harap dicatat bahwa model pretrain kami tidak dilatih dengan ini (mereka dilatih dengan speaker_embedder: "none" ).
Berlari
python3 prepare_align.py --dataset DailyTalk
untuk beberapa persiapan.
Untuk penyelarasan paksa, Montreal memaksa Aligner (MFA) digunakan untuk mendapatkan keberpihakan antara ucapan dan urutan fonem. Penyelarasan yang telah diekstraksi untuk set data disediakan di sini. Anda harus membuka ritsleting file di preprocessed_data/DailyTalk/TextGrid/ . Bergantian, Anda dapat menjalankan pelurus sendiri. Harap dicatat bahwa model pretrain kami tidak dilatih dengan pemodelan durasi yang diawasi (mereka dilatih dengan learn_alignment: True ).
Setelah itu, jalankan skrip preprocessing dengan
python3 preprocess.py --dataset DailyTalk
Latih model Anda dengan
python3 train.py --dataset DailyTalk
Opsi yang berguna:
--use_amp argumen ke perintah di atas.CUDA_VISIBLE_DEVICES=<GPU_IDs> di awal perintah di atas.Menggunakan
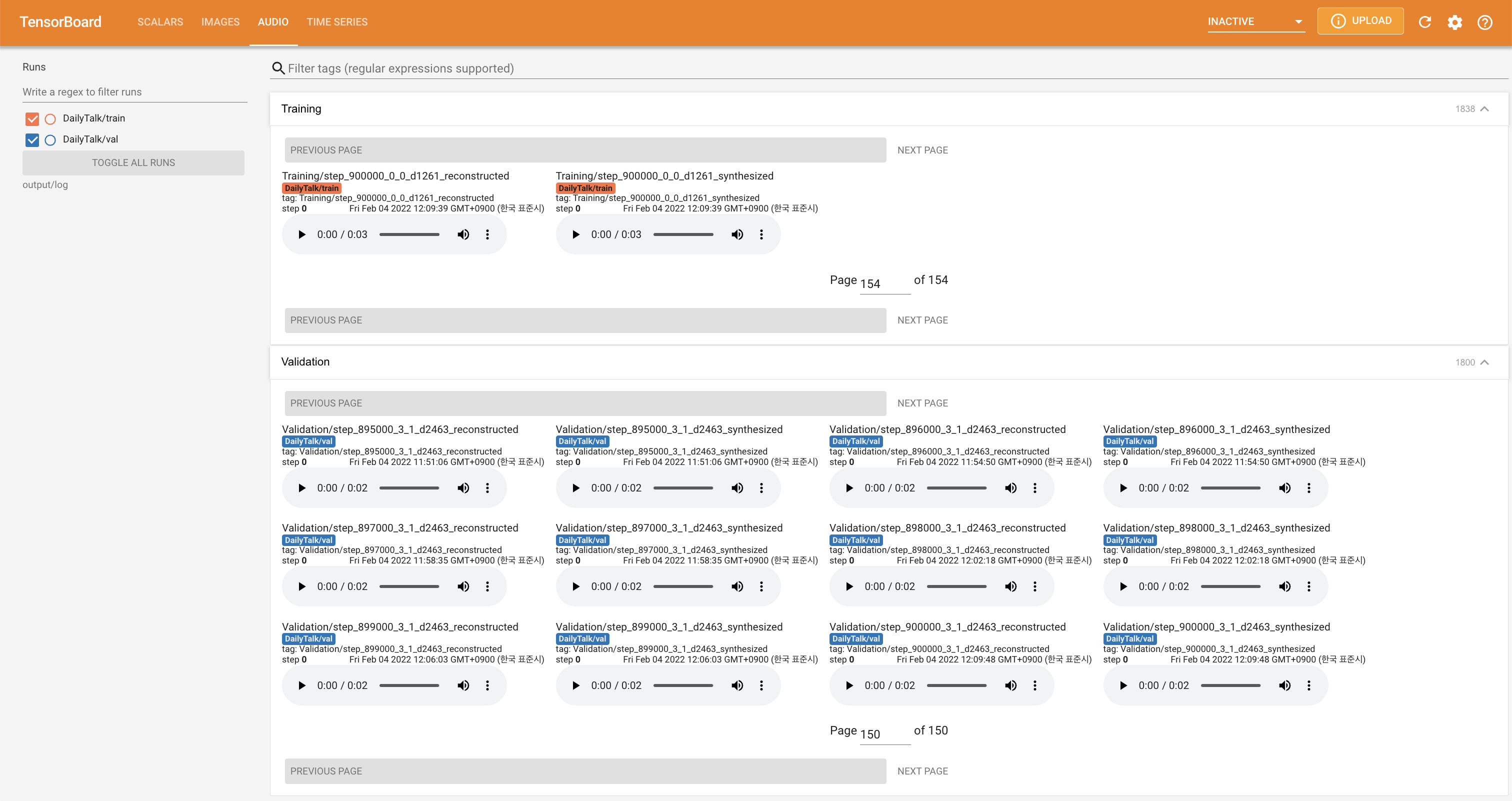
tensorboard --logdir output/log
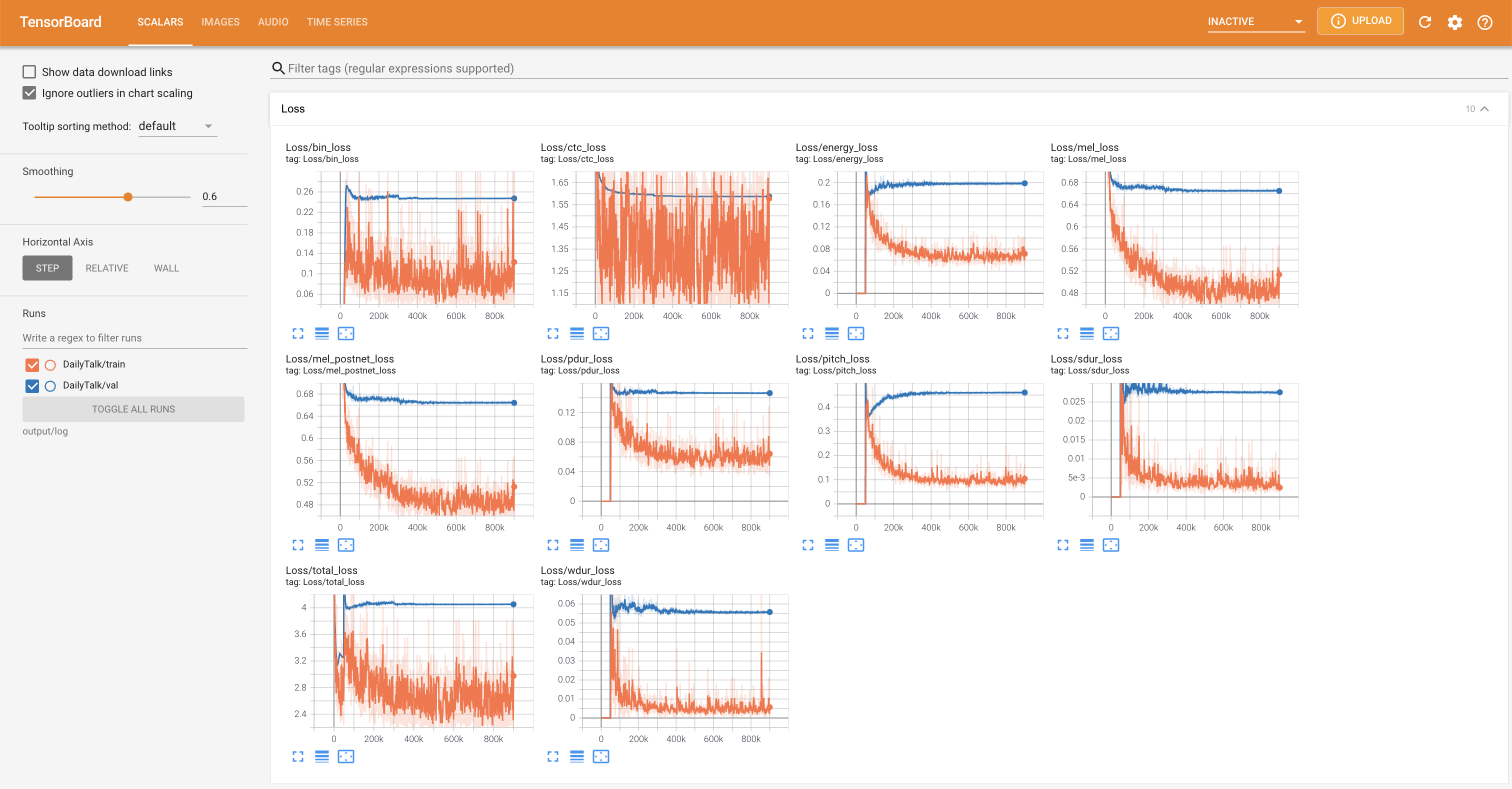
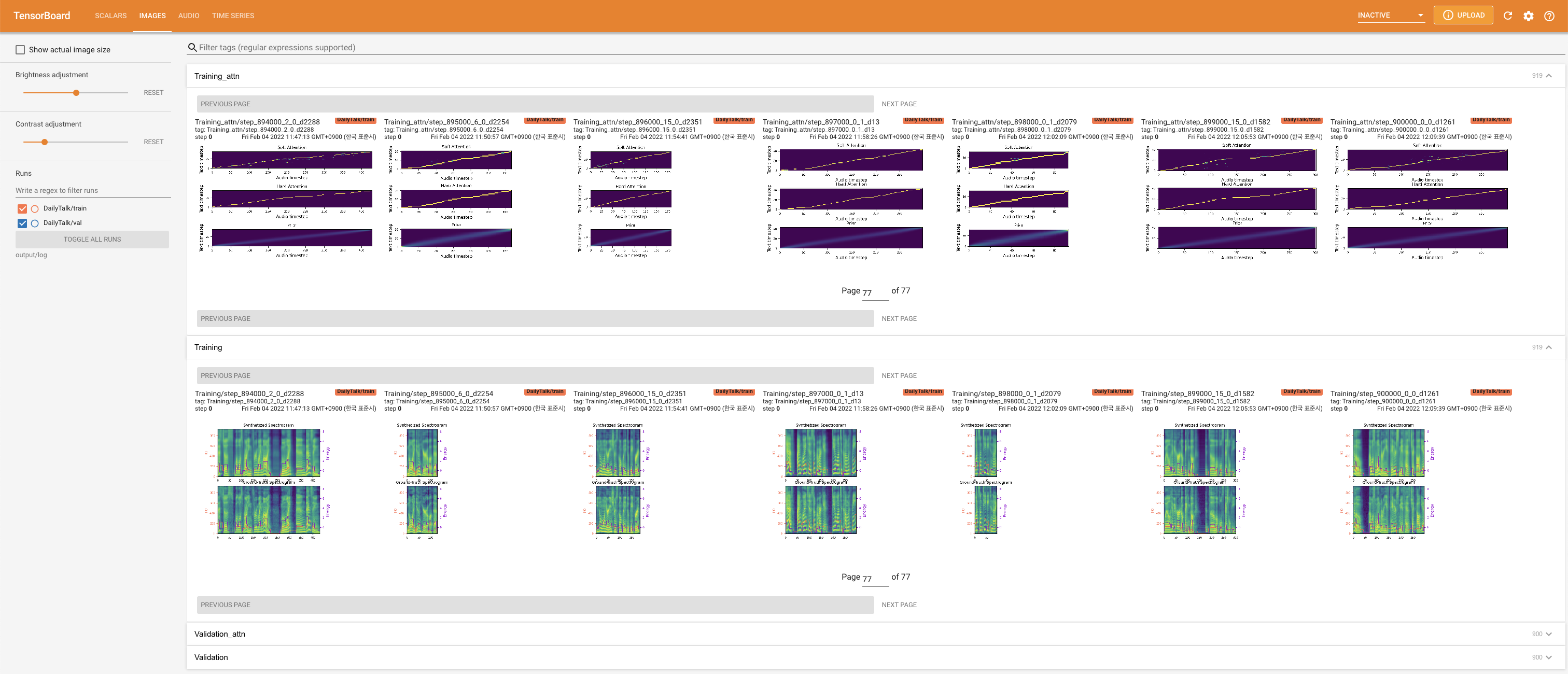
untuk melayani Tensorboard di Localhost Anda. Kurva kehilangan, sintesis mel-spectrograms, dan audio ditampilkan.
'none' dan 'DeepSpeaker' ).Jika Anda ingin menggunakan dataset dan kode kami atau merujuk ke makalah kami, silakan kutip sebagai berikut.
@misc{lee2022dailytalk,
title={DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech},
author={Keon Lee and Kyumin Park and Daeyoung Kim},
year={2022},
eprint={2207.01063},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
Karya ini dilisensikan di bawah lisensi internasional Creative Commons Attribution-Sharealike 4.0.


