voicefixer
fix bugs
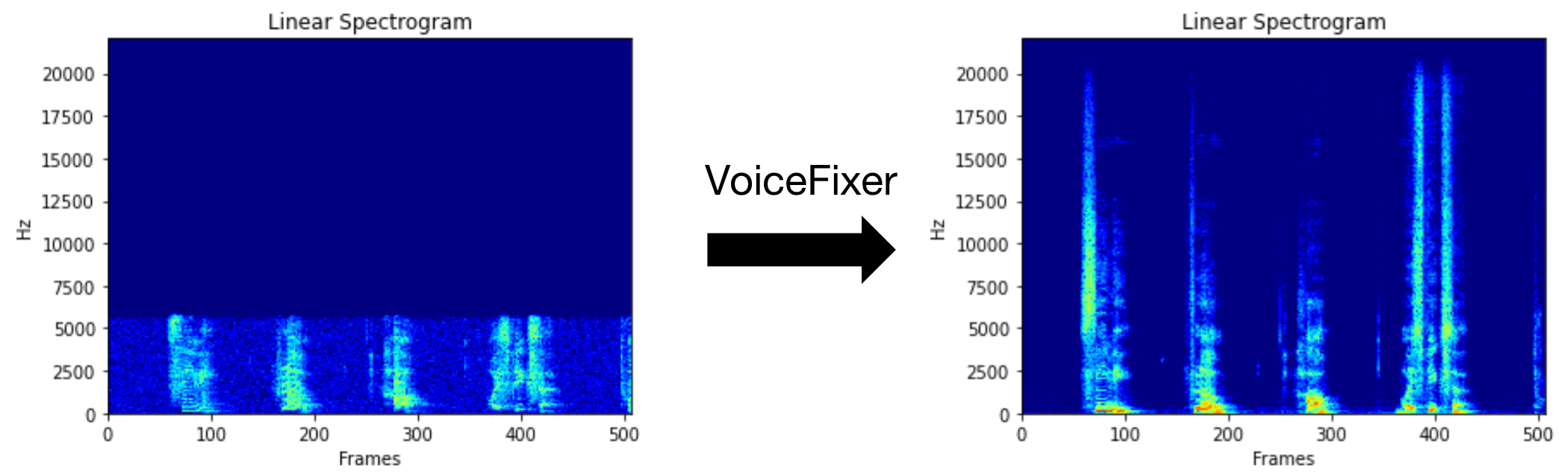
VoiceFixer стремится восстановить человеческую речь независимо от того, насколько серьезно ее унижена. Он может обрабатывать шум, ревеберацию, низкое разрешение (2 кГц ~ 44,1 кГц) и эффект обрезки (0,1-1,0 порога) в одной модели.
Этот пакет предоставляет:
@misc { liu2021voicefixer ,
title = { VoiceFixer: Toward General Speech Restoration With Neural Vocoder } ,
author = { Haohe Liu and Qiuqiang Kong and Qiao Tian and Yan Zhao and DeLiang Wang and Chuanzeng Huang and Yuxuan Wang } ,
year = { 2021 } ,
eprint = { 2109.13731 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
}Пожалуйста, посетите демо -страницу, чтобы просмотреть, что может сделать Voicefixer.
| Режим | Описание |
|---|---|
0 | Исходная модель (предложенная по умолчанию) |
1 | Добавить модуль предварительной обработки (удалить более высокую частоту) |
2 | Режим поезда (иногда может работать над серьезной деградированной реальной речью) |
all | Запустите все режимы - выведет 1 файл WAV для каждого поддерживаемого режима. |
Во -первых, установите голосовой аппарат через PIP:
pip install git+https://github.com/haoheliu/voicefixer.gitОбработайте файл:
# Specify the input .wav file. Output file is outfile.wav.
voicefixer --infile test/utterance/original/original.wav
# Or specify a output path
voicefixer --infile test/utterance/original/original.wav --outfile test/utterance/original/original_processed.wavФайлы процесса в папке:
voicefixer --infolder /path/to/input --outfolder /path/to/outputРежим изменения (режим по умолчанию равен 0):
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode 1Запустите все режимы:
# output file saved to `/path/to/output-modeX.wav`.
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode allПредварительно загружать веса только без какой-либо фактической обработки:
voicefixer --weight_prepareДля получения дополнительной информации, пожалуйста, запустите:
voicefixer -hДемо на YouTube (спасибо @justin John)
Установите голосовое отверстие через PIP:
pip install voicefixerВы можете проверить образцы звука на своем рабочем столе, используя веб -сайт (Powered By Streamlit)
git clone https://github.com/haoheliu/voicefixer.git
cd voicefixer # Run streamlit
streamlit run test/streamlit.pyЕсли вы запустите в первый раз: веб -страница может оставить пустым на несколько минут для загрузки моделей. Вы можете проверить терминал для загрузки прогресса.
Вы можете использовать этот низкокачественный речевой файл, который мы предоставили для тестового запуска. Страница после обработки будет выглядеть следующей.
Во -первых, установите голосовой аппарат через PIP:
pip install voicefixerЗатем запустите следующие сценарии для тестового запуска:
git clone https://github.com/haoheliu/voicefixer.git ; cd voicefixer
python3 test/test.py # test scriptМы ожидаем, что это даст вам следующий выход:
Initializing VoiceFixer...
Test voicefixer mode 0, Pass
Test voicefixer mode 1, Pass
Test voicefixer mode 2, Pass
Initializing 44.1kHz speech vocoder...
Test vocoder using groundtruth mel spectrogram...
Passtest/test.py в основном содержит тест следующих двух API:
...
# TEST VOICEFIXER
## Initialize a voicefixer
print ( "Initializing VoiceFixer..." )
voicefixer = VoiceFixer ()
# Mode 0: Original Model (suggested by default)
# Mode 1: Add preprocessing module (remove higher frequency)
# Mode 2: Train mode (might work sometimes on seriously degraded real speech)
for mode in [ 0 , 1 , 2 ]:
print ( "Testing mode" , mode )
voicefixer . restore ( input = os . path . join ( git_root , "test/utterance/original/original.flac" ), # low quality .wav/.flac file
output = os . path . join ( git_root , "test/utterance/output/output_mode_" + str ( mode ) + ".flac" ), # save file path
cuda = False , # GPU acceleration
mode = mode )
if ( mode != 2 ):
check ( "output_mode_" + str ( mode ) + ".flac" )
print ( "Pass" )
# TEST VOCODER
## Initialize a vocoder
print ( "Initializing 44.1kHz speech vocoder..." )
vocoder = Vocoder ( sample_rate = 44100 )
### read wave (fpath) -> mel spectrogram -> vocoder -> wave -> save wave (out_path)
print ( "Test vocoder using groundtruth mel spectrogram..." )
vocoder . oracle ( fpath = os . path . join ( git_root , "test/utterance/original/p360_001_mic1.flac" ),
out_path = os . path . join ( git_root , "test/utterance/output/oracle.flac" ),
cuda = False ) # GPU acceleration
...Вы можете клонировать это репо и попытаться запустить test.py в тестовой папке.
В настоящее время изображение Docker не опубликовано и должно быть построено локально, но таким образом вы убедитесь, что вы запускаете его со всей ожидаемой конфигурацией. Сгенерированный размер изображения составляет около 10 ГБ, и это в основном связано с зависимостями, которые сами по себе потребляют около 9,8 ГБ.
Тем не менее, слой, содержащий
voicefixerявляется последним добавленным слоем, что делает какую -либо восстановление, если вы измените источники относительно небольшим (~ 200 МБ за раз, поскольку веса обновляются при сборке изображения).
Dockerfile можно посмотреть здесь.
После клонирования репо:
# To build the image
cd voicefixer
docker build -t voicefixer:cpu .
# To run the image
docker run --rm -v " $( pwd ) /data:/opt/voicefixer/data " voicefixer:cpu < all_other_cli_args_here >
# # Example: docker run --rm -v "$(pwd)/data:/opt/voicefixer/data" voicefixer:cpu --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode all # To build the image
cd voicefixer
./docker-build-local.sh
# To run the image
./run.sh < all_other_cli_args_here >
# # Example: ./run.sh --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode allСначала вам нужно написать следующую вспомогательную функцию со своей моделью. Подобно функции Helper в этом репо: https://github.com/haoheliu/voicefixer/blob/main/voicefixer/vocoder/base.py#l35
def convert_mel_to_wav(mel):
" " "
:param non normalized mel spectrogram: [batchsize, 1, t-steps, n_mel]
:return: [batchsize, 1, samples]
" " "
return wavЗатем передайте эту функцию VoiceFixer.Restore , например:
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0,
your_vocoder_func = convert_mel_to_wav)
Примечание:
Смотрите Changelog.md.


