voicefixer
fix bugs
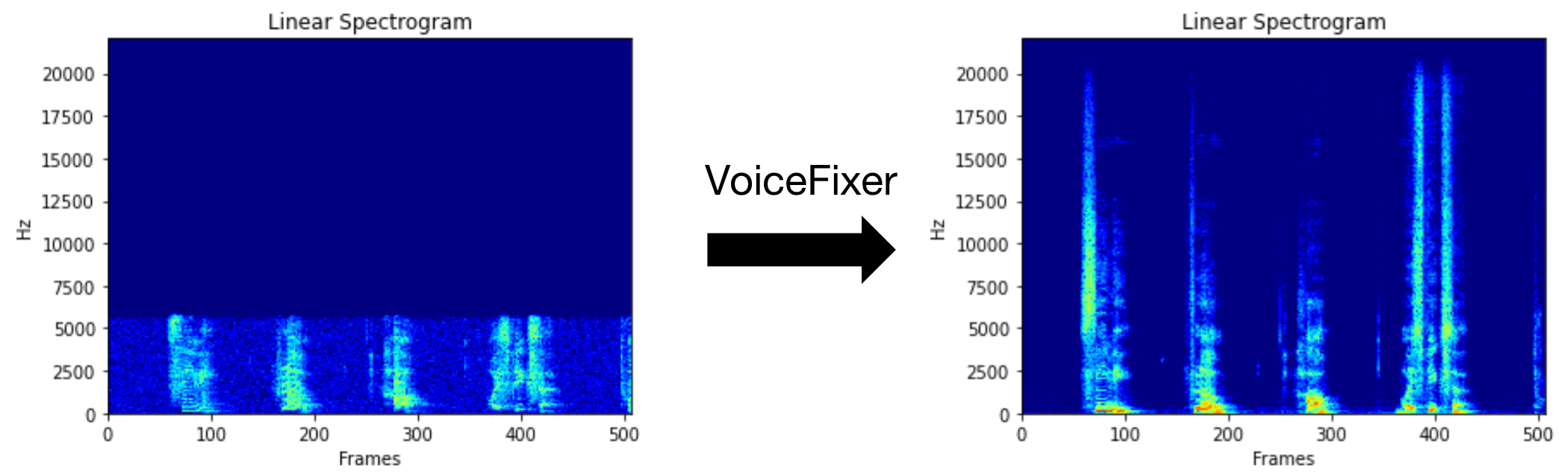
VoiceFixer zielt darauf ab, die menschliche Sprache wiederherzustellen, unabhängig davon, wie ernst sie degradiert ist. Es kann Rauschen, Reveberation, niedrige Auflösung (2kHz ~ 44,1 kHz) und Einschnitten (0,1-1,0 Schwellenwert) innerhalb eines Modells bewältigen.
Dieses Paket enthält:
@misc { liu2021voicefixer ,
title = { VoiceFixer: Toward General Speech Restoration With Neural Vocoder } ,
author = { Haohe Liu and Qiuqiang Kong and Qiao Tian and Yan Zhao and DeLiang Wang and Chuanzeng Huang and Yuxuan Wang } ,
year = { 2021 } ,
eprint = { 2109.13731 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
}Bitte besuchen Sie die Demo -Seite, um anzuzeigen, was VoiceFixer tun kann.
| Modus | Beschreibung |
|---|---|
0 | Originalmodell (standardmäßig vorgeschlagen) |
1 | Vorverarbeitungsmodul hinzufügen (höhere Frequenz entfernen) |
2 | Zugmodus (könnte manchmal auf ernsthaft verschlechterte reale Sprache funktionieren) |
all | Führen Sie alle Modi aus - Ausgabe 1 WAV -Datei für jeden unterstützten Modus. |
Installieren Sie zunächst VoiceFixer über PIP:
pip install git+https://github.com/haoheliu/voicefixer.gitVerarbeiten Sie eine Datei:
# Specify the input .wav file. Output file is outfile.wav.
voicefixer --infile test/utterance/original/original.wav
# Or specify a output path
voicefixer --infile test/utterance/original/original.wav --outfile test/utterance/original/original_processed.wavVerarbeiten Sie Dateien in einem Ordner:
voicefixer --infolder /path/to/input --outfolder /path/to/outputÄnderungsmodus (der Standardmodus ist 0):
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode 1Führen Sie alle Modi aus:
# output file saved to `/path/to/output-modeX.wav`.
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode allLaden Sie die Gewichte nur ohne tatsächliche Verarbeitung vor:
voicefixer --weight_prepareFür weitere Helferinformationen führen Sie bitte aus:
voicefixer -hDemo auf YouTube (danke @justin John)
Installieren Sie VoiceFixer über PIP:
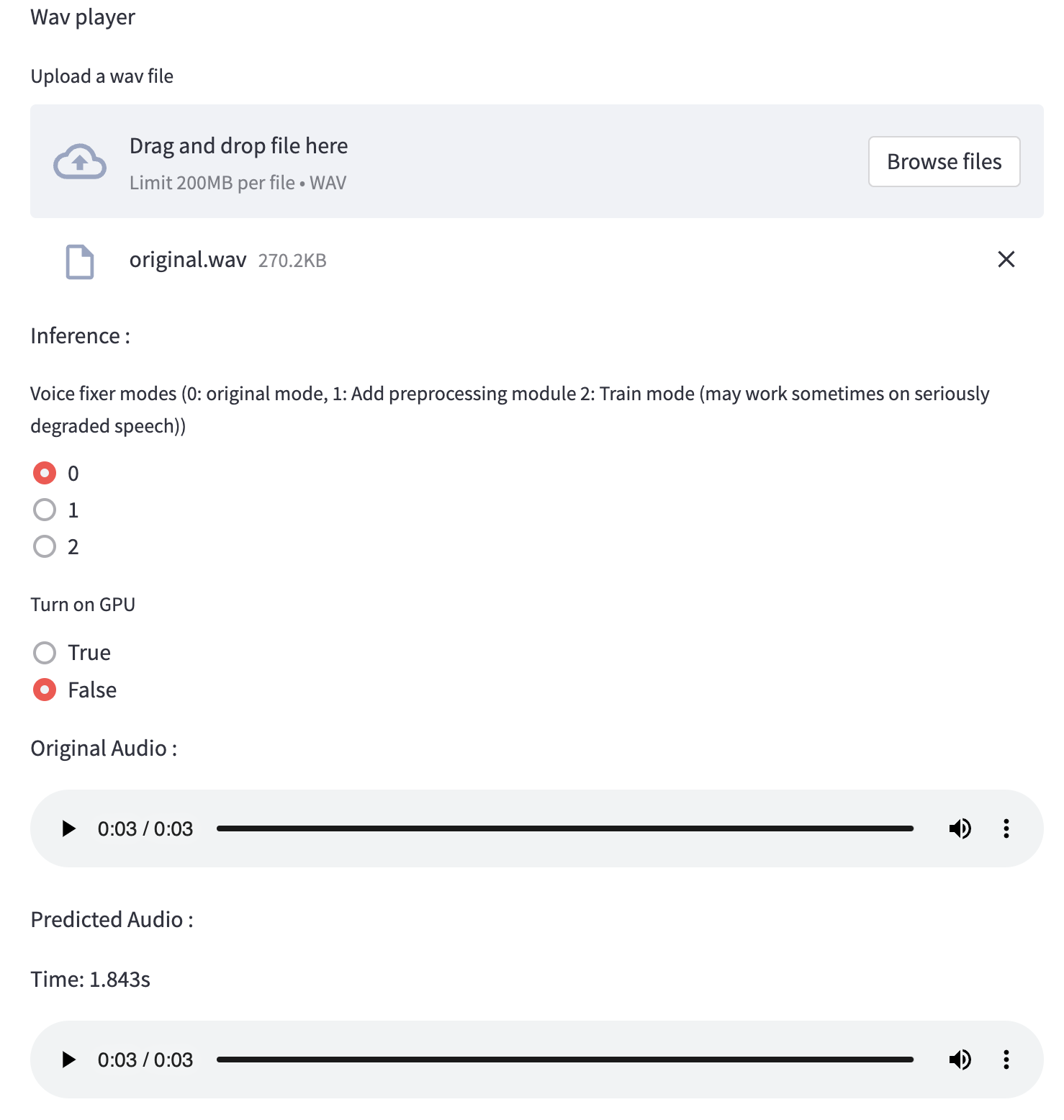
pip install voicefixerSie können Audio -Samples auf Ihrem Desktop testen, indem Sie Website ausführen (betrieben von Streamlit)
git clone https://github.com/haoheliu/voicefixer.git
cd voicefixer # Run streamlit
streamlit run test/streamlit.pyWenn Sie zum ersten Mal ausführen: Die Webseite kann einige Minuten lang für das Herunterladen von Modellen leer bleiben. Sie können das Terminal zum Herunterladen von Fortschritten überprüfen.
Sie können diese Sprachdatei mit geringer Qualität verwenden, die wir für einen Testlauf zur Verfügung gestellt haben. Die Seite nach der Verarbeitung sieht wie folgt aus.
Installieren Sie zunächst VoiceFixer über PIP:
pip install voicefixerFühren Sie dann die folgenden Skripte für einen Testlauf aus:
git clone https://github.com/haoheliu/voicefixer.git ; cd voicefixer
python3 test/test.py # test scriptWir erwarten, dass es Ihnen die folgende Ausgabe gibt:
Initializing VoiceFixer...
Test voicefixer mode 0, Pass
Test voicefixer mode 1, Pass
Test voicefixer mode 2, Pass
Initializing 44.1kHz speech vocoder...
Test vocoder using groundtruth mel spectrogram...
Passtest/test.py enthält hauptsächlich den Test der folgenden zwei APIs:
...
# TEST VOICEFIXER
## Initialize a voicefixer
print ( "Initializing VoiceFixer..." )
voicefixer = VoiceFixer ()
# Mode 0: Original Model (suggested by default)
# Mode 1: Add preprocessing module (remove higher frequency)
# Mode 2: Train mode (might work sometimes on seriously degraded real speech)
for mode in [ 0 , 1 , 2 ]:
print ( "Testing mode" , mode )
voicefixer . restore ( input = os . path . join ( git_root , "test/utterance/original/original.flac" ), # low quality .wav/.flac file
output = os . path . join ( git_root , "test/utterance/output/output_mode_" + str ( mode ) + ".flac" ), # save file path
cuda = False , # GPU acceleration
mode = mode )
if ( mode != 2 ):
check ( "output_mode_" + str ( mode ) + ".flac" )
print ( "Pass" )
# TEST VOCODER
## Initialize a vocoder
print ( "Initializing 44.1kHz speech vocoder..." )
vocoder = Vocoder ( sample_rate = 44100 )
### read wave (fpath) -> mel spectrogram -> vocoder -> wave -> save wave (out_path)
print ( "Test vocoder using groundtruth mel spectrogram..." )
vocoder . oracle ( fpath = os . path . join ( git_root , "test/utterance/original/p360_001_mic1.flac" ),
out_path = os . path . join ( git_root , "test/utterance/output/oracle.flac" ),
cuda = False ) # GPU acceleration
...Sie können dieses Repo klonen und versuchen, Test.py im Testordner auszuführen.
Derzeit wird das Docker -Bild nicht veröffentlicht und muss lokal erstellt werden. Auf diese Weise stellen Sie jedoch sicher, dass Sie es mit der erwarteten Konfiguration ausführen. Die erzeugte Bildgröße beträgt ungefähr 10 GB und dies ist hauptsächlich auf die Abhängigkeiten zurückzuführen, die sich selbst etwa 9,8 GB verbrauchen.
Die Ebene,
voicefixerenthält, ist jedoch die letzte zusätzliche Ebene, die einen Umbau macht, wenn Sie die Quellen relativ klein ändern (~ 200 MB gleichzeitig, wenn die Gewichte beim Bildbau aktualisiert werden).
Die Dockerfile kann hier angezeigt werden.
Nach dem Klonen des Repos:
# To build the image
cd voicefixer
docker build -t voicefixer:cpu .
# To run the image
docker run --rm -v " $( pwd ) /data:/opt/voicefixer/data " voicefixer:cpu < all_other_cli_args_here >
# # Example: docker run --rm -v "$(pwd)/data:/opt/voicefixer/data" voicefixer:cpu --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode all # To build the image
cd voicefixer
./docker-build-local.sh
# To run the image
./run.sh < all_other_cli_args_here >
# # Example: ./run.sh --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode allZuerst müssen Sie eine folgende Helferfunktion mit Ihrem Modell schreiben. Ähnlich wie bei der Helferfunktion in diesem Repo: https://github.com/haoheliu/voicefixer/blob/main/voicefixer/vocoder/base.py#l35
def convert_mel_to_wav(mel):
" " "
:param non normalized mel spectrogram: [batchsize, 1, t-steps, n_mel]
:return: [batchsize, 1, samples]
" " "
return wavGeben Sie dann diese Funktion an VoiceFixer.restore über, zum Beispiel:
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0,
your_vocoder_func = convert_mel_to_wav)
Notiz:
Siehe ChangeLog.md.


