voicefixer
fix bugs
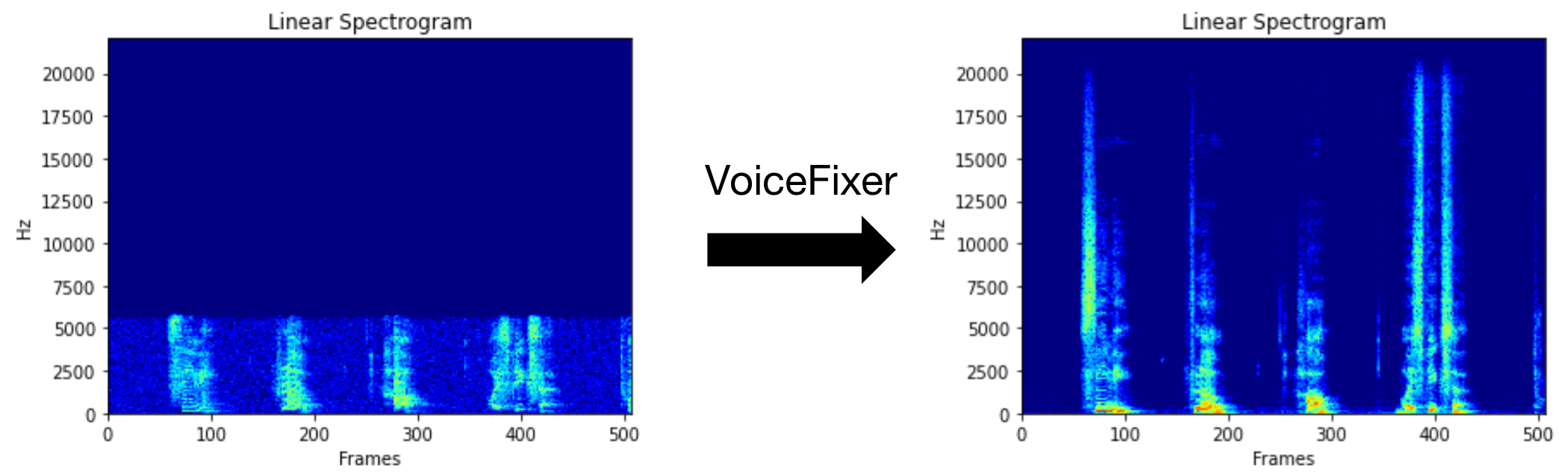
O Bowfixer pretende restaurar a fala humana, independentemente de quão grave sua degradada. Pode lidar com ruído, revelação, baixa resolução (2kHz ~ 44,1kHz) e efeito de corte (limite de 0,1-1,0) em um modelo.
Este pacote fornece:
@misc { liu2021voicefixer ,
title = { VoiceFixer: Toward General Speech Restoration With Neural Vocoder } ,
author = { Haohe Liu and Qiuqiang Kong and Qiao Tian and Yan Zhao and DeLiang Wang and Chuanzeng Huang and Yuxuan Wang } ,
year = { 2021 } ,
eprint = { 2109.13731 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
}Visite a página de demonstração para ver o que o VoiceFixer pode fazer.
| Modo | Descrição |
|---|---|
0 | Modelo original (sugerido por padrão) |
1 | Adicione o módulo de pré -processamento (remova uma frequência mais alta) |
2 | Modo de trem (pode funcionar às vezes em discurso real seriamente degradado) |
all | Execute todos os modos - produzirá 1 arquivo WAV para cada modo suportado. |
Primeiro, instale o VoiceFixer via PIP:
pip install git+https://github.com/haoheliu/voicefixer.gitProcesse um arquivo:
# Specify the input .wav file. Output file is outfile.wav.
voicefixer --infile test/utterance/original/original.wav
# Or specify a output path
voicefixer --infile test/utterance/original/original.wav --outfile test/utterance/original/original_processed.wavProcessar arquivos em uma pasta:
voicefixer --infolder /path/to/input --outfolder /path/to/outputModo de mudança (o modo padrão é 0):
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode 1Execute todos os modos:
# output file saved to `/path/to/output-modeX.wav`.
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode allPré-carregue os pesos apenas sem nenhum processamento real:
voicefixer --weight_preparePara mais informações auxiliares, execute:
voicefixer -hDemonstração no YouTube (obrigado @Justin John)
Instale o VoiceFixer via PIP:
pip install voicefixerVocê pode testar amostras de áudio na sua área de trabalho executando o site (alimentado por streamlit)
git clone https://github.com/haoheliu/voicefixer.git
cd voicefixer # Run streamlit
streamlit run test/streamlit.pySe você correr pela primeira vez: a página da web pode deixar em branco por vários minutos para baixar modelos. Você pode conferir o terminal para download progredir.
Você pode usar este arquivo de fala de baixa qualidade que fornecemos para uma execução de teste. A página após o processamento será a seguinte.
Primeiro, instale o VoiceFixer via PIP:
pip install voicefixerEm seguida, execute os seguintes scripts para uma execução de teste:
git clone https://github.com/haoheliu/voicefixer.git ; cd voicefixer
python3 test/test.py # test scriptEsperamos que isso lhe dê a seguinte saída:
Initializing VoiceFixer...
Test voicefixer mode 0, Pass
Test voicefixer mode 1, Pass
Test voicefixer mode 2, Pass
Initializing 44.1kHz speech vocoder...
Test vocoder using groundtruth mel spectrogram...
Passtest/test.py contém principalmente o teste das duas APIs a seguir:
...
# TEST VOICEFIXER
## Initialize a voicefixer
print ( "Initializing VoiceFixer..." )
voicefixer = VoiceFixer ()
# Mode 0: Original Model (suggested by default)
# Mode 1: Add preprocessing module (remove higher frequency)
# Mode 2: Train mode (might work sometimes on seriously degraded real speech)
for mode in [ 0 , 1 , 2 ]:
print ( "Testing mode" , mode )
voicefixer . restore ( input = os . path . join ( git_root , "test/utterance/original/original.flac" ), # low quality .wav/.flac file
output = os . path . join ( git_root , "test/utterance/output/output_mode_" + str ( mode ) + ".flac" ), # save file path
cuda = False , # GPU acceleration
mode = mode )
if ( mode != 2 ):
check ( "output_mode_" + str ( mode ) + ".flac" )
print ( "Pass" )
# TEST VOCODER
## Initialize a vocoder
print ( "Initializing 44.1kHz speech vocoder..." )
vocoder = Vocoder ( sample_rate = 44100 )
### read wave (fpath) -> mel spectrogram -> vocoder -> wave -> save wave (out_path)
print ( "Test vocoder using groundtruth mel spectrogram..." )
vocoder . oracle ( fpath = os . path . join ( git_root , "test/utterance/original/p360_001_mic1.flac" ),
out_path = os . path . join ( git_root , "test/utterance/output/oracle.flac" ),
cuda = False ) # GPU acceleration
...Você pode clonar este repositório e tentar executar test.py dentro da pasta de teste .
Atualmente, a imagem do Docker não é publicada e precisa ser construída localmente, mas dessa maneira você garante que a executa com toda a configuração esperada. O tamanho da imagem gerado é de cerca de 10 GB e isso se deve principalmente às dependências que consomem cerca de 9,8 GB por conta própria.
No entanto, a camada que contém
voicefixeré a última camada adicionada, tornando qualquer reconstrução se você alterar as fontes relativamente pequenas (~ 200 MB por vez, à medida que os pesos são atualizados na construção da imagem).
O Dockerfile pode ser visto aqui.
Depois de clonar o repositório:
# To build the image
cd voicefixer
docker build -t voicefixer:cpu .
# To run the image
docker run --rm -v " $( pwd ) /data:/opt/voicefixer/data " voicefixer:cpu < all_other_cli_args_here >
# # Example: docker run --rm -v "$(pwd)/data:/opt/voicefixer/data" voicefixer:cpu --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode all # To build the image
cd voicefixer
./docker-build-local.sh
# To run the image
./run.sh < all_other_cli_args_here >
# # Example: ./run.sh --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode allPrimeiro, você precisa escrever uma função auxiliar seguinte com seu modelo. Semelhante à função ajudante neste repo: https://github.com/haoheliu/voicefixer/blob/main/voicefixer/vocoder/base.py#l35
def convert_mel_to_wav(mel):
" " "
:param non normalized mel spectrogram: [batchsize, 1, t-steps, n_mel]
:return: [batchsize, 1, samples]
" " "
return wavEm seguida, passe esta função para o botefixer.restore , por exemplo:
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0,
your_vocoder_func = convert_mel_to_wav)
Observação:
Veja Changelog.md.


