voicefixer
fix bugs
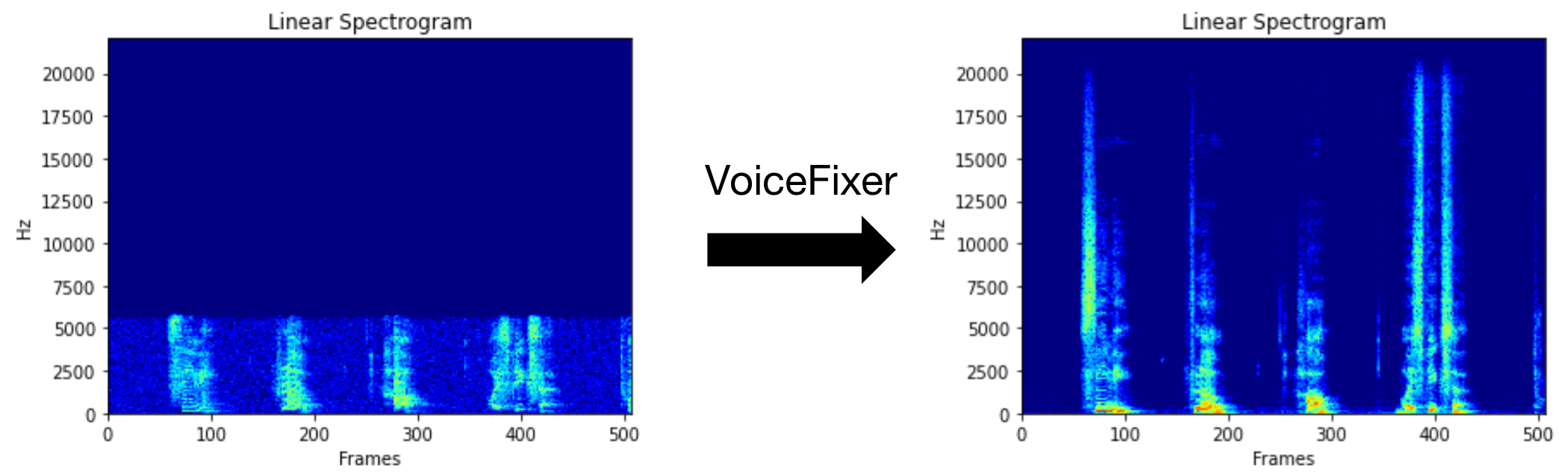
VoiceFixer vise à restaurer le discours humain, quelle que soit la gravité de sa dégradation. Il peut gérer le bruit, la reve bordel, la faible résolution (2 kHz ~ 44,1 kHz) et l'écrêtage (seuil 0,1-1,0) dans un modèle.
Ce package fournit:
@misc { liu2021voicefixer ,
title = { VoiceFixer: Toward General Speech Restoration With Neural Vocoder } ,
author = { Haohe Liu and Qiuqiang Kong and Qiao Tian and Yan Zhao and DeLiang Wang and Chuanzeng Huang and Yuxuan Wang } ,
year = { 2021 } ,
eprint = { 2109.13731 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
}Veuillez visiter la page de démonstration pour voir ce que VoiceFixer peut faire.
| Mode | Description |
|---|---|
0 | Modèle original (suggéré par défaut) |
1 | Ajouter le module de prétraitement (supprimer une fréquence plus élevée) |
2 | Mode de train (pourrait parfois fonctionner sur un vrai discours sérieusement dégradé) |
all | Exécutez tous les modes - sortira 1 fichier wav pour chaque mode pris en charge. |
Installez d'abord VoiceFixer via PIP:
pip install git+https://github.com/haoheliu/voicefixer.gitTraiter un fichier:
# Specify the input .wav file. Output file is outfile.wav.
voicefixer --infile test/utterance/original/original.wav
# Or specify a output path
voicefixer --infile test/utterance/original/original.wav --outfile test/utterance/original/original_processed.wavTraiter les fichiers dans un dossier:
voicefixer --infolder /path/to/input --outfolder /path/to/outputMode de modification (le mode par défaut est 0):
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode 1Exécutez tous les modes:
# output file saved to `/path/to/output-modeX.wav`.
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode allPrécharger les poids uniquement sans aucun traitement réel:
voicefixer --weight_preparePour plus d'informations auxiliaires, veuillez exécuter:
voicefixer -hDemo sur YouTube (merci @Justin John)
Installez VoiceFixer via PIP:
pip install voicefixerVous pouvez tester des échantillons audio sur votre bureau en exécutant un site Web (alimenté par Streamlit)
git clone https://github.com/haoheliu/voicefixer.git
cd voicefixer # Run streamlit
streamlit run test/streamlit.pySi vous exécutez pour la première fois: la page Web peut laisser vide pendant plusieurs minutes pour le téléchargement des modèles. Vous pouvez vérifier le terminal pour le téléchargement des progrès.
Vous pouvez utiliser ce fichier vocal de faible qualité que nous avons fourni pour un test. La page après traitement ressemblera à ce qui suit.
Installez d'abord VoiceFixer via PIP:
pip install voicefixerEnsuite, exécutez les scripts suivants pour un essai:
git clone https://github.com/haoheliu/voicefixer.git ; cd voicefixer
python3 test/test.py # test scriptNous nous attendons à ce qu'il vous donne la sortie suivante:
Initializing VoiceFixer...
Test voicefixer mode 0, Pass
Test voicefixer mode 1, Pass
Test voicefixer mode 2, Pass
Initializing 44.1kHz speech vocoder...
Test vocoder using groundtruth mel spectrogram...
Passtest / test.py contient principalement le test des deux API suivantes:
...
# TEST VOICEFIXER
## Initialize a voicefixer
print ( "Initializing VoiceFixer..." )
voicefixer = VoiceFixer ()
# Mode 0: Original Model (suggested by default)
# Mode 1: Add preprocessing module (remove higher frequency)
# Mode 2: Train mode (might work sometimes on seriously degraded real speech)
for mode in [ 0 , 1 , 2 ]:
print ( "Testing mode" , mode )
voicefixer . restore ( input = os . path . join ( git_root , "test/utterance/original/original.flac" ), # low quality .wav/.flac file
output = os . path . join ( git_root , "test/utterance/output/output_mode_" + str ( mode ) + ".flac" ), # save file path
cuda = False , # GPU acceleration
mode = mode )
if ( mode != 2 ):
check ( "output_mode_" + str ( mode ) + ".flac" )
print ( "Pass" )
# TEST VOCODER
## Initialize a vocoder
print ( "Initializing 44.1kHz speech vocoder..." )
vocoder = Vocoder ( sample_rate = 44100 )
### read wave (fpath) -> mel spectrogram -> vocoder -> wave -> save wave (out_path)
print ( "Test vocoder using groundtruth mel spectrogram..." )
vocoder . oracle ( fpath = os . path . join ( git_root , "test/utterance/original/p360_001_mic1.flac" ),
out_path = os . path . join ( git_root , "test/utterance/output/oracle.flac" ),
cuda = False ) # GPU acceleration
...Vous pouvez cloner ce dépôt et essayer d'exécuter Test.py à l'intérieur du dossier de test .
Actuellement, l'image Docker n'est pas publiée et doit être construite localement, mais de cette façon, vous vous assurez de l'exécuter avec toute la configuration attendue. La taille de l'image générée est d'environ 10 Go et cela est principalement dû aux dépendances qui consomment environ 9,8 Go par elles-mêmes.
Cependant, la couche contenant
voicefixerest la dernière couche ajoutée, faisant toute reconstruction si vous modifiez des sources relativement petites (~ 200 Mo à la fois à mesure que les poids sont rafraîchis sur la construction d'images).
Le Dockerfile peut être consulté ici.
Après avoir cloné le repo:
# To build the image
cd voicefixer
docker build -t voicefixer:cpu .
# To run the image
docker run --rm -v " $( pwd ) /data:/opt/voicefixer/data " voicefixer:cpu < all_other_cli_args_here >
# # Example: docker run --rm -v "$(pwd)/data:/opt/voicefixer/data" voicefixer:cpu --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode all # To build the image
cd voicefixer
./docker-build-local.sh
# To run the image
./run.sh < all_other_cli_args_here >
# # Example: ./run.sh --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode allVous devez d'abord écrire une fonction d'assistance suivante avec votre modèle. Similaire à la fonction d'assistance dans ce dépôt: https://github.com/haoheliu/voicefixer/blob/main/voicefixer/vocoder/base.py#l35
def convert_mel_to_wav(mel):
" " "
:param non normalized mel spectrogram: [batchsize, 1, t-steps, n_mel]
:return: [batchsize, 1, samples]
" " "
return wavEnsuite, passez cette fonction à VoiceFixer.Restore , par exemple:
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0,
your_vocoder_func = convert_mel_to_wav)
Note:
Voir Changelog.md.


