algorithms in python
1.0.0
В этом хранилище я буду использовать Python для реализации некоторых известных алгоритмов. Алгоритмы расположены в соответствии с используемой стратегией. Каждый алгоритм будет иметь объяснение проблемы, которую она пытается решить, и некоторые соответствующие ресурсы.
(Цель этого репозитория - создать прекрасную Readme для всех этих блестящих алгоритмов, которые я рассмотрел.)
Содержание:
В этом разделе я расскажу о знаменитой стратегии «Разделение и победит» и покажу некоторые приложения этой стратегии.
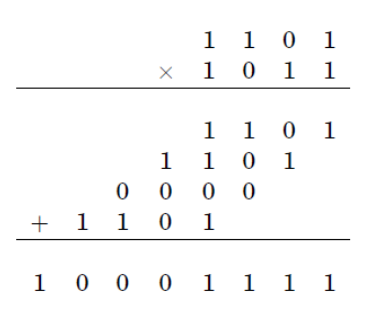
Стандартная процедура для умножения двух N-цифр требует ряд элементарных операций, пропорциональных. Что касается алгоритма карацуба, он уменьшает время работы до максимума
Ключевая идея
Основным шагом алгоритма Карацубы является формула, которая позволяет вычислять продукт двух больших чисел и использовать три умножения меньших чисел, каждая из которых составляет около половины цифр, а также, плюс некоторые дополнения и цифровые сдвиги.
Характеристики
Back to Top
Худшее время для этого алгоритма - это.
GIF выше показывает, как работает сортировка слияния: 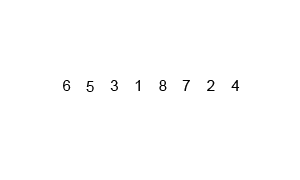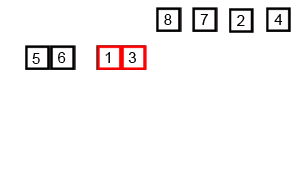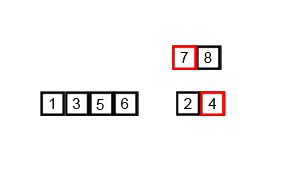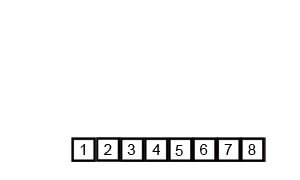
Ключевая идея
Разделите несортированный список на N -сублисты, каждый из которых содержит 1 элемент (список из 1 элемента считается отсортированным) и неоднократно объединяет сублисты для создания новых отсортированных сублистов, пока остается только 1 сублисты. Это будет отсортированный список.
Характеристики
Back to Top
Ключевая идея
Как и рисунок выше, когда мы впервые принимаем элемент с правой подоружкой в операции слияния, что указывает на то, что правый элемент меньше (длина левой подрайки-индекс левого элемента) элементов.
По мере развития алгоритма добавить все инверсии даст нам общие инверсии.
Характеристики
Back to Top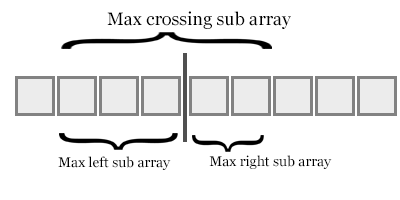
Характеристики
Back to TopВ этом разделе я расскажу о двух алгоритмах, которые использовали случайную величину внутри.
Ключевая идея
QuickSort сначала делит большой массив на две меньшие суб-борьбы: низкие элементы и высокие элементы относительно случайно выбранного элемента. QuickSort может затем рекурсивно сортировать суб-магистрали. Таким образом, ключевым моментом в быстром сортировке является выбор элемента раздела.
Характеристики
Back to Top
Ключевая идея
Повторяя время алгоритма сокращения с независимыми случайными вариантами и возвращая наименьший сокращение, вероятность отсутствия минимального разреза
Характеристики
Back to TopРазмещать структуры данных как независимый раздел вводит в заблуждение; Тем не менее, я введу проблемы с озадачивающимися проблемами, которые элегантно решаются структурами данных. Некоторые структуры данных могут иметь стратегию разработки алгоритма, которая еще не была рассмотрена.
Ключевая идея
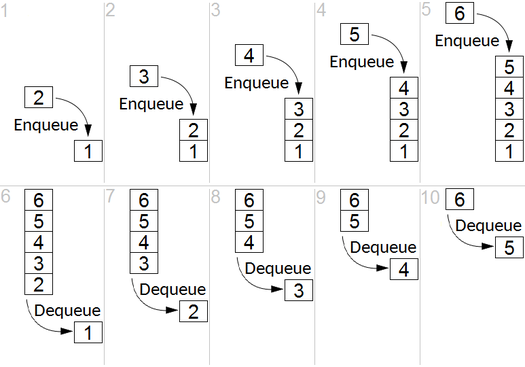
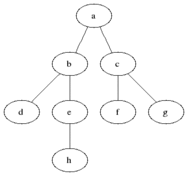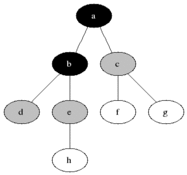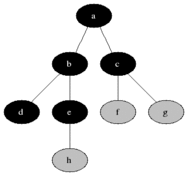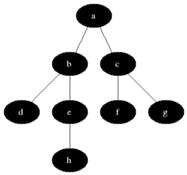
BFS используется для подсчета достижимых узлов из исходного узла в неисправном или направленном графике. Достигаемые узлы напечатаны в найденном порядке. Очередь используется для хранения серых узлов (см. GIF ниже). Термин «ширина» в BFS означает поиск достижимого узла с самой короткой длиной. Ширина расширяет границу между посещаемыми узлами и неоткрытыми узлами.
Характеристики
Back to Top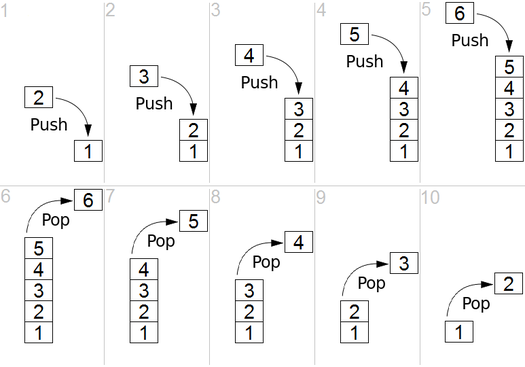
Ключевая идея
И DFS используется в направленном графике и сообщает, сколько узлов может достичь исходного узла, и распечатайте их по заказу, который мы их найдем. Мы используем стек для хранения узлов, которые мы классифицируем как начальные точки для графика. «Глубина» в его имени означает, что этот алгоритм пойдет так глубоко, как и для данного источника, и когда он достигнет конечной точки, он возвращается к начальному узлу.
Характеристики
Back to Top
Средняя проблема обслуживания состоит в том, что если целые числа считываются из потока данных, найдите медиану элементов, читаемые так для эффективного способа. Для простоты предположим, что нет дубликатов.
Ключевая идея
Мы можем использовать максимальную кучу на левой стороне, чтобы представлять элементы, которые менее чем эффективны, и кучу мин на правой стороне, чтобы представлять элементы, которые больше, чем эффективная медиана. Когда разница между размером двух кучей больше или равна 2, мы переключаем один элемент на другую кучу меньшего размера.
Характеристики
Back to Top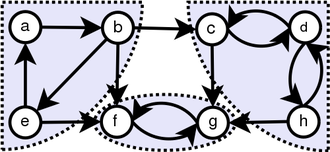
Ключевая идея
Благодаря простому наблюдению, мы обнаруживаем, что Tranpose of Graph имеет те же SCCS, что и исходный график. Мы запускаем DFS дважды. Впервые мы запускаем его на G и вычислите время отделки для каждой вершины. И затем мы запускаем DFS на G^T, но в основной цикле DFS рассмотрим вершины в порядке уменьшения времени отделки.
Характеристики
Back to Top
Ключевая идея
На неориентированном графике мы можем использовать эту структуру данных, чтобы выяснить, сколько SCC. На рисунке ниже показано, как это работает.
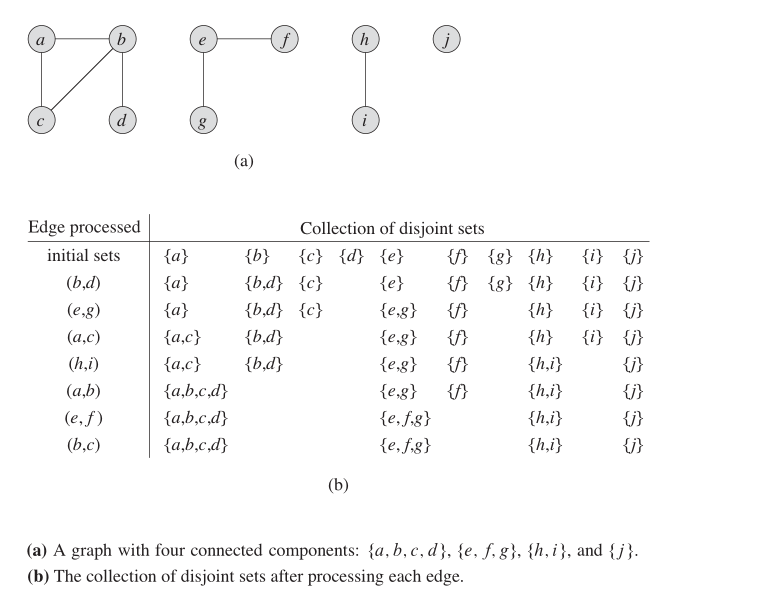
Характеристики
Back to Top В этом разделе я собираюсь ввести жадные алгоритмы, одну мощную стратегию дизайна алгоритма.
Из Википедии жадный алгоритм представляет собой алгоритмическую парадигму, которая следует за эвристикой решения проблем, позволяющей сделать локально оптимальный выбор на каждом этапе [1] с надеждой найти глобальный оптимум. Во многих проблемах жадная стратегия в целом не производит оптимальное решение, но, тем не менее, жадная эвристика может дать локально оптимальные решения, которые приближаются к глобальному оптимальному решению в разумное время.
В проблеме выбора активности каждое действие имеет свой вес и длину. И наша цель - минимизировать сумму веса*длины. Это очень простой и отличный пример, чтобы показать, как работает жадный алгоритм, и предоставить элегантное доказательство с использованием техники обмена аргументами.
Ключевая идея
Если мы сортируем активность по значению веса/длины, мы можем доказать, что существующая оптимальная структура не может быть лучше, чем это расположение. 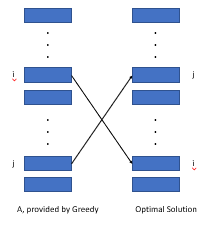
Как показано выше, мы рассмотрим стоимость, вызванные двумя видами деятельности, которые по -разному варьируются в двух расположениях (i, j). Мы обнаруживаем, что стоимость жадного алгоритма меньше оптимальной структуры по значению wi*lj - wj*li, что больше или равно 0.
Характеристики
Back to Top
Ключевая идея
Мы отсортировали массив в соответствии с его временем завершения. Алгоритм поместил первую работу, время начала которого больше, чем время за последней работой.
Характеристики
Back to Top
Один из способов кодирования этой книги - использовать кодирование фиксированной длины. Как показано ниже:
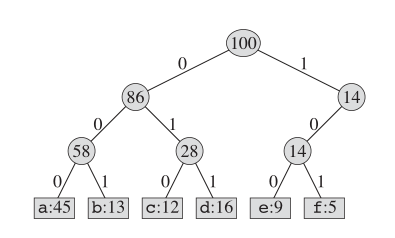
Что касается кодирования Хаффмана, реальная структура дерева выглядит следующим образом:
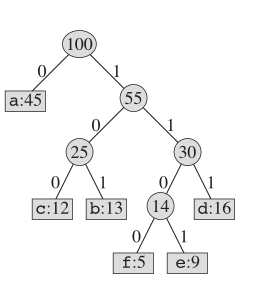
Ключевая идея
Мы поддерживаем двоичное дерево и создаем новый узел в качестве родителя для двух наименее нечастого буква. И ключом для этого нового узла является сумма ключей для двух детей. Мы повторяем это, пока в этой «книге» не осталось узлов.
Характеристики
Back to TopАлгоритм Дейкстры является алгоритмом для поиска кратчайших путей между узлами на графике. Тем не менее, он имеет одну предпосылку, все пути должны быть больше или равны 0.
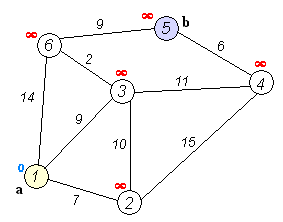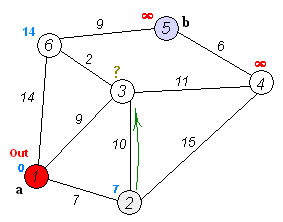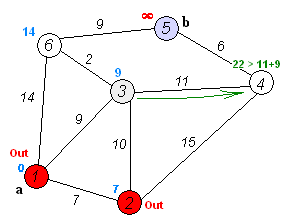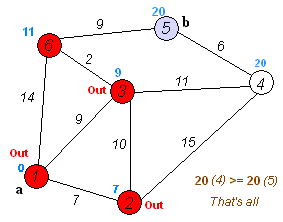
Ключевая идея
Отдельные узлы в две группы, одна группа отмечена как исследованная. И мы обновляем расстояние от неисследованной группы до изучения группы на кратчайшие расстояния.
Характеристики
Back to Top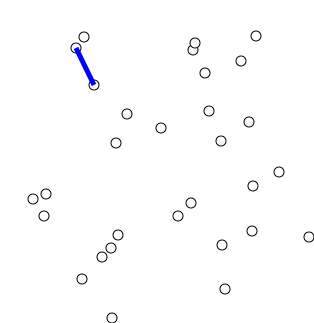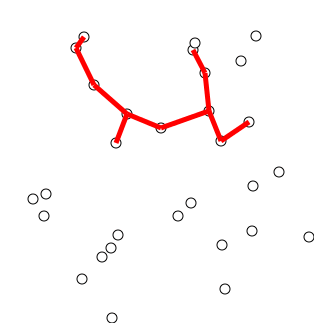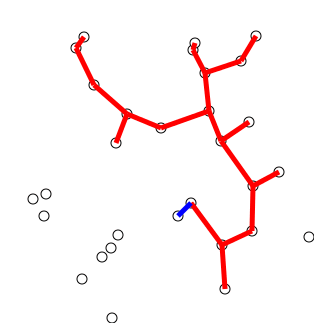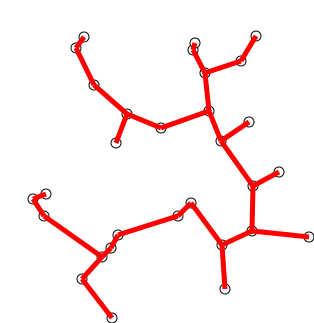
Ключевая идея
Алгоритм можно неформально описать как выполнение следующих шагов:
Инициализируйте дерево с одной вершиной, выбранной произвольно из графика.
Вырастите дерево одним краем: из краев, которые соединяют дерево с вершинами, еще не в дереве, найдите минимальный края и перенесите его на дерево.
Повторите шаг 2 (пока все вершины не будут в дереве).
Характеристики
Back to Top
Ключевая идея
Очень похоже на SCC, мы можем раннее остановить алогрифм, чтобы контролировать количество классов в нашем графике, то есть мы можем снять график.
Характеристики
Back to Top В этом разделе я собираюсь ввести динамические алгоритмы, одну мощную стратегию дизайна алгоритмов.
Из Википедии динамическое программирование (также известное как динамическая оптимизация) - это метод решения сложной проблемы, разбивая ее на набор более простых подпроектов, решая каждую из этих подзадач только один раз и сохраняя свои решения.
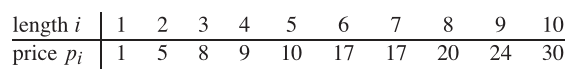
Таким образом, если длина стержня составляет 8, а значения различных частей задаются следующим образом, то максимально достижимое значение составляет 22 (по разрезанию двух частей длины 2 и 6).
Ключевая идея
Мы рассматриваем разложение как состоящую из первого куска длины, я отрезал левый конец, а затем правую оставшуюся часть длины n-i. Итак, псевдокод выглядит как:
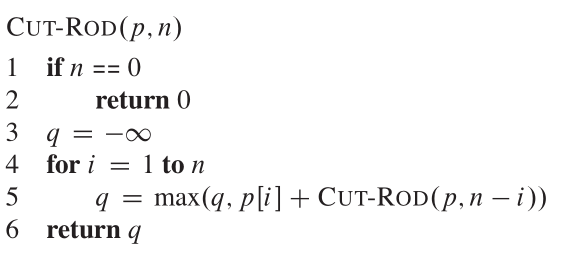
Дерево рекурсии, показывающее рекурсивные вызовы, возникающие в результате вызова cut_rod (p, n), выглядит как:
Чтобы сохранить повторные вычисления для небольших подпрограмм, мы запомнили массив для хранения этих значений.
Характеристики
Back to Top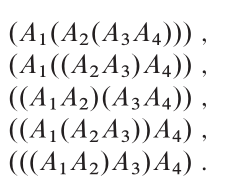
Ключевая идея
Оптимальная структура:
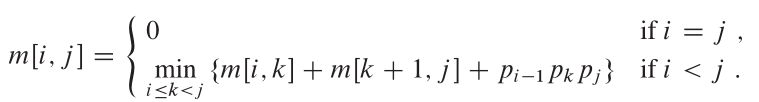
Характеристики
Back to Top Ключевая идея
Из CLR оптимальная структура для этой проблемы такова:
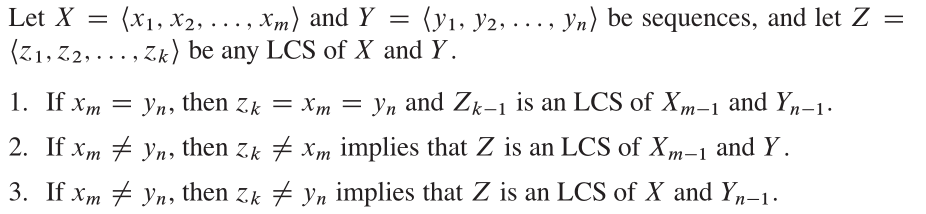
Характеристики
Back to Top Ключевая идея
Этот алгоритм основан на очень интуитивном наблюдении. Предположим, у нас есть подмножество {1, 2, 3, 4, ..., k} (обозначает как v (k)) оригинальной группы вершин {1, 2, 3, ..., n}. Если P - самый короткий путь от I до J в V (k), у нас есть два случая. Во-первых, если K не в P, то P должен быть кратчайшим путем в V (K-1). Во -вторых, если K находится в P, то мы можем разделить путь на два, p1: i K, P2: K. Дж. и P1 должен быть самым коротким путем от I до K с V (K-1), P2 должен быть самым коротким путем от K до J с V (K-1).
Характеристики
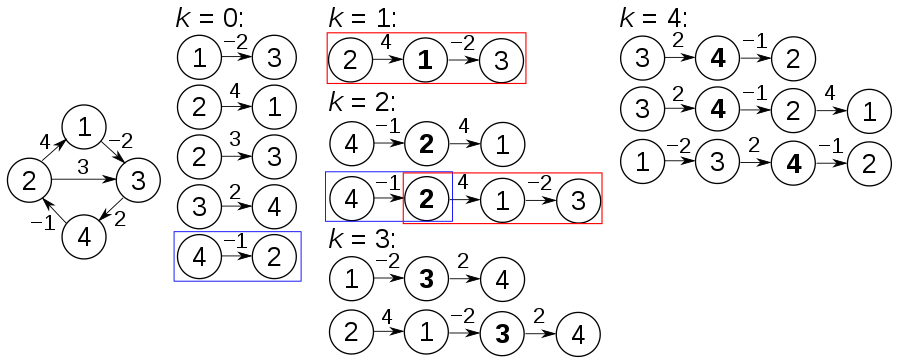
Back to Top Из Wikipedia проблема с решением NP-это та, которая принадлежит как к классам сложности NP, так и к NP-Hard. В этом контексте NP означает «неэнергинизм полиномиального времени». Набор задач NP-полных часто обозначается NP-C или NPC.
В этом разделе я собираюсь представить три очень известные проблемы NPC и объяснить алгоритмы приближения, чтобы приблизиться к ним.
Ключевая идея
Очень сложно найти минимальную крышку вершины, но мы можем найти приблизительное покрытие с большим вдвое больше вершин в полиномиальное время.

Характеристики
Back to Top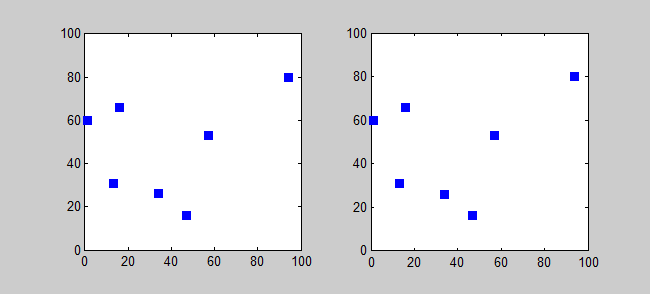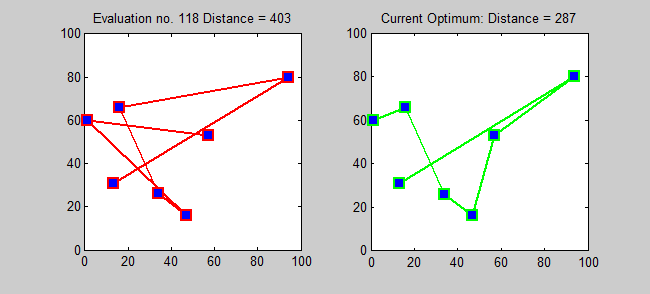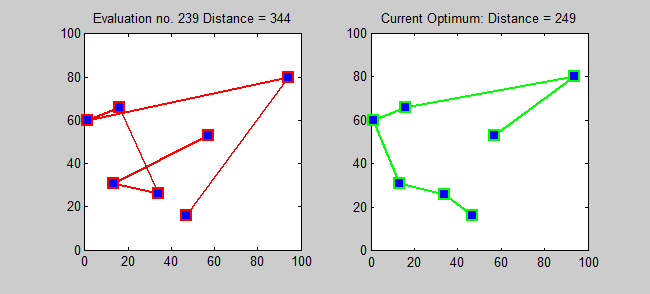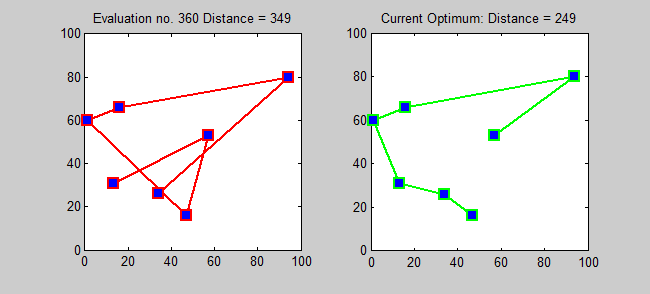
Ключевая идея
Алгоритм приближения для TSP представляет собой жадный алгоритм (CLRS P1114). Здесь я также хочу представить точный алгоритм для TSP с использованием динамического программирования.
Подпрозрачная: для каждого пункта назначения j ∈ {1,2, ..., n}, каждое подмножество s ⊆ {1,2, ..., n}, которое содержит 1 и j, пусть ls, j = минимальная длина пути от 1 до J, который посещает именно вершины S [точно один раз каждый]. Итак, соответствующий рецидив:
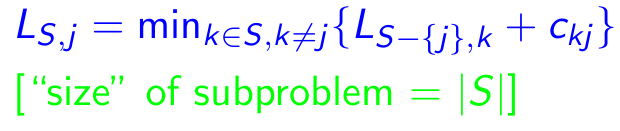
Характеристики
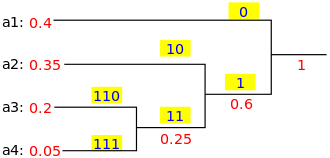
Back to Top 3-SAT является одной из 21 задач KARP, и используется в качестве отправной точки для доказательства того, что другие проблемы также являются NP-Hard.
Здесь я представляю алгоритм Papadimitriou для 2-сат (это очень-очень-очень интересный алгоритм , поэтому я решаю представить его, хотя 2-сат не NPC).
Ключевая идея
Выберите случайное начальное назначение и выберите произвольный неудовлетворенный пункт и переверните значение одной из ее переменной. Вот псевдокод:

Такое случайное дело с предложениями удивительно даст нам очень большую вероятность найти реальный ответ. Механизм лежит в физическом термине (случайная прогулка). Если вы заинтересованы, я настоятельно рекомендую вам рассказать, как случайная прогулка связана с пападимитриу.
Характеристики
Back to Top

