LangChain Chinese Getting Started Guide
1.0.0
簡単に読むために、gitbookが生成されました:https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
githubアドレス:https://github.com/liaokongvfx/langchain-chinese-getting-started-guide
「Langchainテクノロジーの復号化:大規模なモデルアプリケーションを構築するためのパノラマガイド」が現在公開されています:https://item.jd.com/14598210.html
低価格の国内および外国のAIモデルAPI転送:https://api.91ai.me
Langchainライブラリは急速に更新されて反復されているためですが、ドキュメントは4月上旬に書かれており、個人エネルギーが限られているため、Colabのコードはやや時代遅れになる可能性があります。操作に障害がある場合は、現在のドキュメントが更新されていないかどうかを検索できます
Changelogを追加して、新しいコンテンツを作成しました。
OpenAI APIのリクエストルートルートを独自のプロキシアドレスに変更する場合は、環境変数「OpenAI_API_BASE」を設定して変更できます。
関連する参照コード:https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbef1/openai/__init__.py#l48
または、OpenAI関連のモデルオブジェクトを初期化するときは、「OpenAI_API_BASE」変数を渡します。
関連する参照コード:https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
誰もが知っているように、OpenaiのAPIはインターネットに接続できないため、独自の関数を使用して回答を検索し、PDFドキュメントを要約し、YouTubeビデオに基づいてQ&Aを実行することは間違いなく不可能です。それでは、非常に強力なサードパーティのオープンソースライブラリであるLangChain紹介しましょう。
ドキュメントアドレス:https://python.langchain.com/en/latest/
このライブラリは現在非常にアクティブで、毎日繰り返しています。
Langchainは、言語モデルを搭載したアプリケーションを開発するためのフレームワークです。彼には2つの主な能力があります:
LLMモデル:大規模な言語モデル、大きな言語モデル
LLMコール
プロンプト管理は、さまざまなカスタムテンプレートをサポートします
電子メール、Markdown、PDF、YouTubeなど、多数のドキュメントローダーがあります。
インデックスのサポート
チェーン
上記の紹介を読んだ後、誰もが混乱すると思います。心配しないでください。上記の概念は、最初に学習を始めたときにそれほど重要ではありません。
ただし、ここに知られている必要があるいくつかの概念があります。
名前が示すように、これは指定されたソースからデータをロードすることです。例:フォルダーDirectoryLoader 、AzureストレージAzureBlobStorageContainerLoader 、CSV FILE CSVLoader 、Evernote EverNoteLoader 、Google GoogleDriveLoader 、Any WebページUnstructuredHTMLLoader 、PDF PyPDFLoader 、S3 S3 S3DirectoryLoader / S3FileLoader 、
YouTube YoutubeLoaderなど、私はそれらのいくつかを簡単にリストしました。
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
ローダーローダーを使用してデータソースを読み取った後、データソースは後で使用する前にドキュメントオブジェクトに変換する必要があります。
名前が示すように、テキストセグメンテーションはテキストを分割するために使用されます。なぜテキストを分割する必要があるのですか? Openai APIにPROPTとしてテキストを送信するか、OpenAI API埋め込み関数を使用するたびに、文字制限があります。
たとえば、300ページのPDFをOpenai APIに送信して要約するように頼むと、最大トークンを超える間違いを間違いなく報告します。したがって、ここでは、テキストスプリッターを使用して、ローダーが入っているドキュメントを分割する必要があります。
データ相関検索は実際にはベクトル操作であるためです。したがって、OpenAI API埋め込み関数を使用する場合でも、Vectorデータベースを介して直接クエリを使用する場合でも、ベクトル操作検索を実行するには、ロードされたデータDocumentベクトル化する必要があります。ベクトルへの変換も非常に簡単です。
当社は、当社が使用できる多くのベクトルデータベースも提供しています。
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
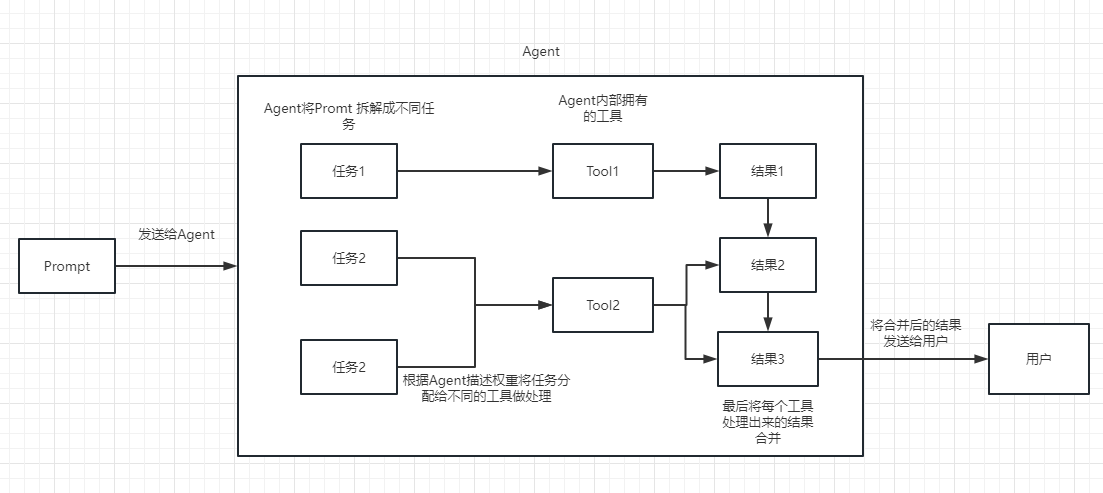
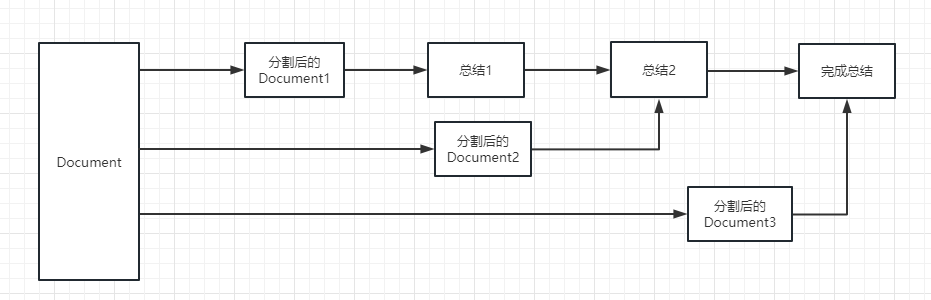
チェーンをタスクとして理解することができます。チェーンはタスクであり、もちろん、チェーンのように複数のチェーンを1つずつ実行することもできます。
チェーンまたは既存のツールを選択して呼び出すのに動的に役立つことを単純に理解できます。
実行プロセスについては、次の写真を参照してください。
テキストの関連性を測定するために使用されます。これは、独自の知識ベースを構築するOpenai APIの能力の鍵でもあります。
微調整よりも彼の最大の利点は、彼が新しいコンテンツを1回追加する代わりに、トレーニングする必要がなく、リアルタイムで新しいコンテンツを追加できることであり、あらゆる面でのコストは微調整よりもはるかに低いことです。
具体的な比較と選択については、このビデオを参照してください:https://www.youtube.com/watch?v=9qq6htr7ocw
上記の本質的な概念を通して、Langchainを特定の理解を深める必要がありますが、それでも少し混乱している可能性があります。
これらはすべて小さな質問です。実際の戦闘を読んだ後、上記のコンテンツを徹底的に理解し、このライブラリの真の力を感じます。
OpenAI APIは高度であるため、後続の例で使用されているLLMはすべて、オープンAIに基づいています。
もちろん、この記事の最後に、すべてのコードがColab iPynbファイルとして保存され、誰もが学習できるように提供されます。
次の例では、前の例の知識ポイントを使用するため、各例を順番に見ることをお勧めします。
もちろん、あなたが何かを読み続けることは、何かを読み続けることができます。
最初のケースでは、Langchainを使用してOpenaiモデルをロードし、Q&Aを完了します。
開始する前に、最初にOpenAIキーをセットアップする必要があります。そのため、ここで詳しく説明することはできません。
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'次に、インポートして実行します
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
現時点では、彼が私たちに与えた結果を見ることができます。
次に、何か面白いことをしましょう。 Openai APIをオンラインで検索して、回答を返してみましょう。
ここでは、Serpapiを使用してそれを実装する必要があります。これにより、Google検索にAPIインターフェイスが提供されます。
まず、Serpapiの公式Webサイトhttps://serpapi.com/にユーザーを登録し、コピーしてAPIキーを生成する必要があります。
次に、上記のOpenai APIキーのように、環境変数に設定する必要があります。
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'次に、私のコードの書き込みを開始します
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )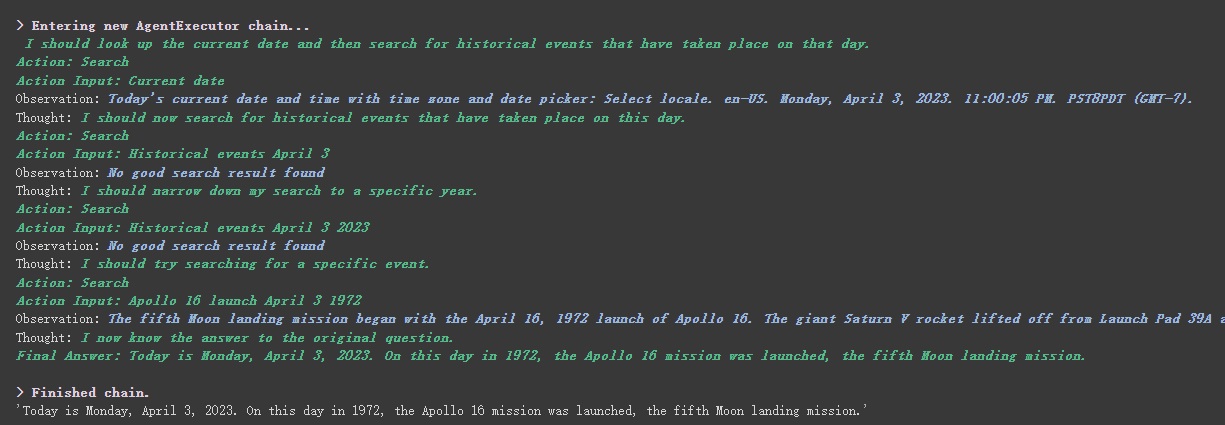
彼は日付を正しく返し(時には違い)、歴史の中で今日に戻ったことがわかります。
チェーンverboseとエージェントオブジェクトには、これが非常に便利なパラメーターがあります。
上記の結果からわかるように、彼は私たちの質問をいくつかのステップに分割し、最終的な答えを段階的に取得します。
エージェントタイプのいくつかのオプションの意味について(理解できない場合、それは次の学習に影響しません。それを使いすぎると、自然に理解します):
SearchとLookupツールを使用し、前者は検索に使用され、後者はWipipediaを使用して使用されます。Google search APIツールなど、質問に対する事実に基づいた回答(非GPT生成の回答を参照していますが、すでにネットワーク上のテキストにあります)を見つけることができます。これは、Reactのためにこれを見ることができます:https://arxiv.org/pdf/2210.03629.pdf
LLMのReactパターンのPython実装:https://til.simonwillison.net/llms/python-react-pattern
エージェントタイプの公式説明:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-rect-description
注意すべきことの1つは、この
serpapi中国人にそれほど友好的ではないように見えるので、尋ねられたプロンプトは英語を使用することをお勧めします。
もちろん、役人はChatGPT Pluginsのエージェントを書きました。
ただし、現在、承認を必要としないプラグインのみを使用できます。
興味のある人は、このドキュメントを読むことができます:https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
Chatgptは公式のためにしかお金を稼ぐことができず、Openai APIは私のためにお金を稼ぐことができます
Openai APIを使用してテキストの段落を要約したい場合は、通常の方法がAPIに直接送信して要約することです。ただし、テキストがAPIの最大トークン制限を超えると、エラーが報告されます。
現時点では、一般に、Tiktokenを計算して分割するなど、記事をセグメント化し、各段落を概要のためにAPIに送信し、最後に各段落の要約を要約します。
Langchainを使用している場合、彼は私たちがこのプロセスを非常にうまく処理するのを手伝ってくれたため、コードを簡単に作成できます。
これ以上苦労せずに、コードをアップロードするだけです。
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])まず、切断前と削減の前後に文書を印刷します。
最後に、最初の5つのドキュメントの要約は出力です。

注意すべきいくつかのパラメーターは次のとおりです。
テキストスプリッターのchunk_overlapパラメーター
これは、各ドキュメントのコンテキストが各ドキュメントのコンテキスト関連を増やすことであることです。たとえば、 chunk_overlap=0の場合、最初のドキュメントはaaaaaaa、2番目はbbbbbb chunk_overlap=2です。
ただし、これは絶対的ではなく、使用されるテキストセグメンテーションモデル内の特定のアルゴリズムに依存します。
テキストスプリッターのこのドキュメントを参照できます:https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
チェーンのchain_typeパラメーター
このパラメーターは、主にドキュメントのLLMモデルに渡される方法を制御し、合計4つの方法があります。
stuff :これは最もシンプルで粗雑であり、要約のためにすべてのドキュメントをLLMモデルに一度に渡します。多くのドキュメントがある場合、最大トークン制限を超えるエラーを必然的に報告するため、これはテキストを要約するときに選択されません。
map_reduce :このメソッドは最初に各ドキュメントを要約し、最後にすべてのドキュメントで要約された結果を要約します。
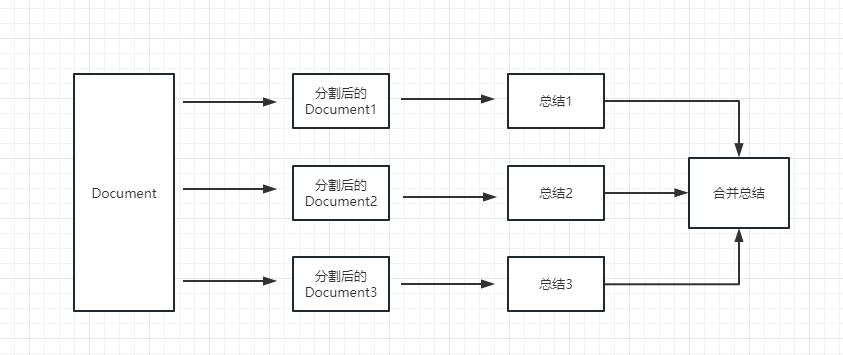
refine :この方法で最初に最初のドキュメントを要約し、次に要約のために最初のドキュメントと2番目のドキュメントによって要約されたコンテンツをLLMモデルに送信します。この方法の利点は、後者のドキュメントを要約すると、以前のドキュメントを要約し、要約する必要があるドキュメントにコンテキストを追加し、概要コンテンツの一貫性を高めることです。
map_rerank :このタイプのチェーンは、一般的に要約ではありませんが、実際には回答と一致する方法です。まず、質問に基づいて質問に回答するために各ドキュメントの確率スコアを計算し、このドキュメントを質問のプロンプト(質問 +ドキュメント)の一部に変換してLLMモデルに送信し、最後にLLMモデルが特定の回答を返します。
この例では、ローカルで複数のドキュメントを読んで、OpenAI APIを使用して知識ベースで回答を検索して提供することにより、知識ベースを構築する方法を説明します。
これは、会社のビジネスを簡単に紹介できるロボットや、製品を導入するロボットなど、非常に便利なチュートリアルです。
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )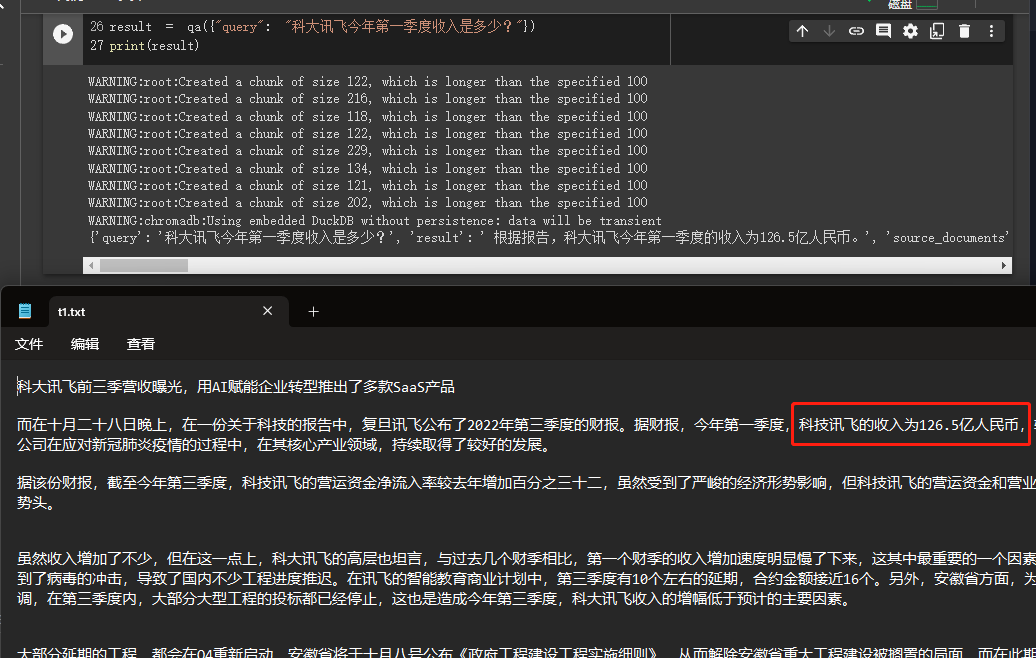
結果を通して、彼が私たちが与えたデータから正しい答えを正常に取得したことを見ることができます。
Openai Embeddingsの詳細については、このリンクを参照してください:https://platform.openai.com/docs/guides/embeddings
以前のケースの1つのステップは、ドキュメント情報をベクトル情報と埋め込み情報に変換し、それを一時的にChromaデータベースに保存することでした。
上記のコードが実行されると、一時的に保存されるため、上記のベクトル化後のデータは失われます。次回使用したい場合は、埋め込みを再度計算する必要があります。これは間違いなく私たちが望むものではありません。
したがって、この場合、ChromaとPineconeの2つのデータベースを介してベクトルデータを持続する方法について説明します。
Langchainは多くのデータベースをサポートしているため、詳細については、より頻繁に使用される2つのデータベースを参照してください
彩度
Chromaはローカルベクトルデータベースであり、Persistent Directoryを設定するためにpersist_directoryを提供します。読むときは、 from_documentメソッドを呼び出してロードする必要があります。
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )松ぼっくり
Pineconeはオンラインベクトルデータベースです。そのため、最初のステップでは、対応するAPIキーを登録して取得できます。 https://app.pinecone.io/
インデックスが14日間使用されない場合、無料版は自動的にクリアされます。
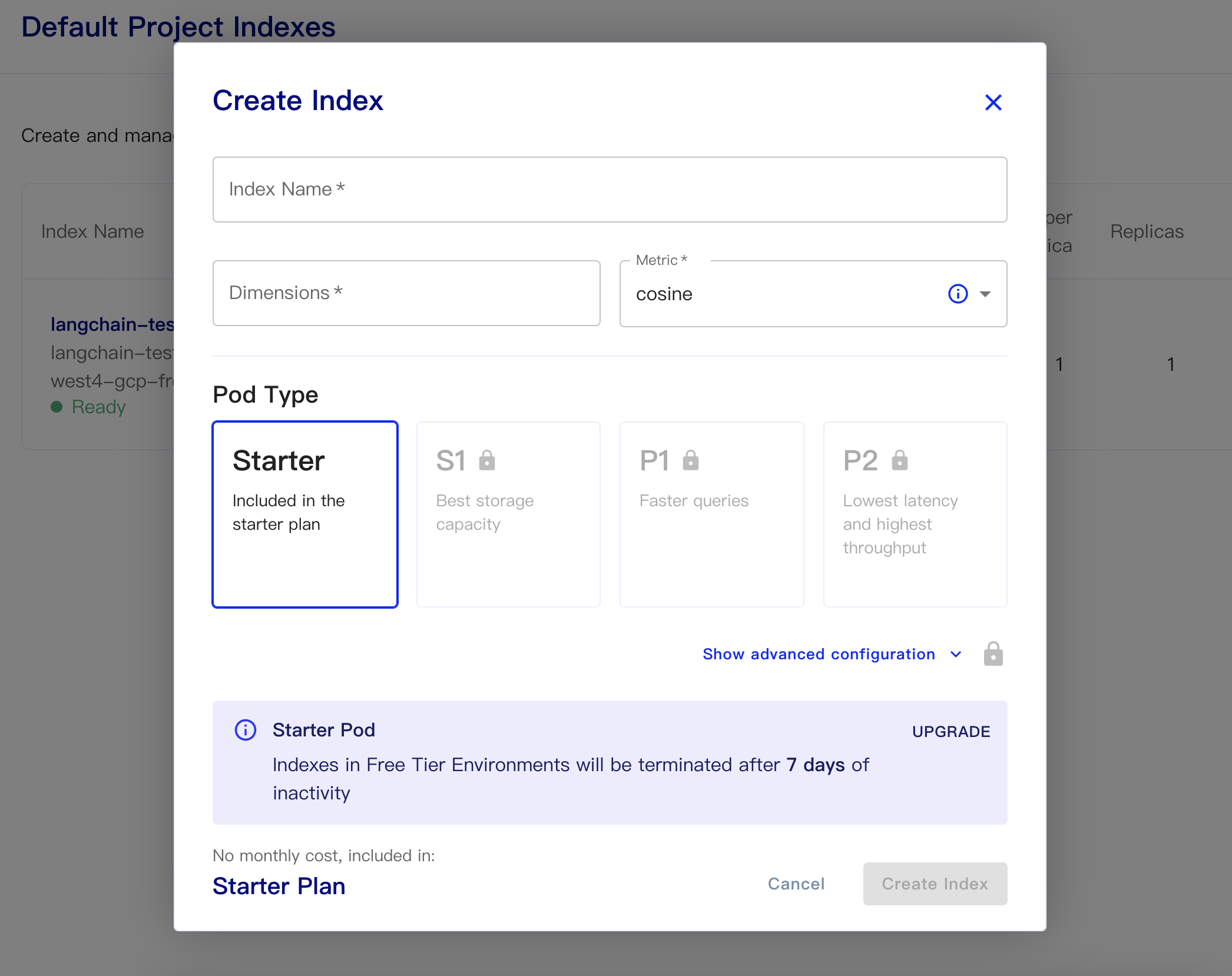
次に、データベースを作成します。
インデックス名:これはカジュアルです
寸法:OpenaiのText-Beding-Ada-002モデルは出力寸法です。
メトリック:デフォルトでコサインになります
スタータープランを選択します
永続的なデータとロードデータコードは次のとおりです
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )データベースから埋め込みを取得して回答するための簡単なコードは次のとおりです
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
ChatGpt API(つまり、GPT-3.5-Turbo)モデルがリリースされた後、それはより少ないお金だったので、すべての人に愛されていたため、Langchainはこの例に従ってそれを使用する方法を確認しました。
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])彼はこのオイルパイプビデオの周りに質問や回答に正確に答えることができることがわかります

ストリーミングの回答も非常に便利です
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ())主にzapierを使用して、何千ものツールを接続しています。
したがって、最初のステップは、アカウントとその自然言語APIキーを申請することです。 https://zapier.com/l/natural-language- actions
彼のAPIキーは、情報アプリケーションを入力する必要があります。ただし、基本的に情報を記入した後、基本的に承認された電子メールを数秒でメールアドレスに表示できます。
次に、接続を右クリックしてAPI構成ページを開きます。 [右側のManage Actionsをクリックして、使用するアプリケーションを構成します。
ここでメールを読んで送信するようにGmailのアクションを構成しました。すべてのフィールドはAI推測によって選択されます。
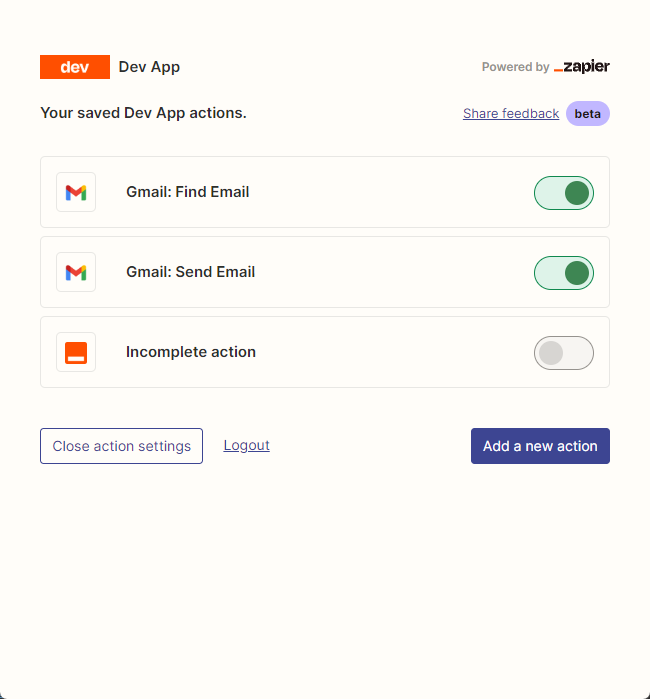
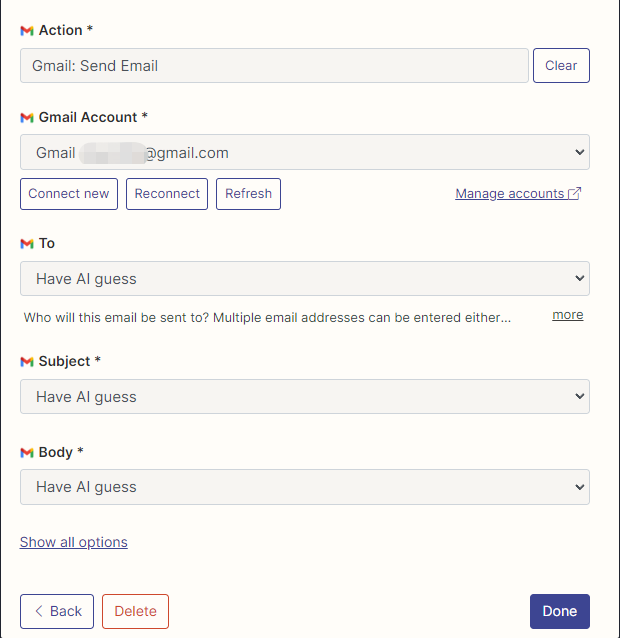
構成が完了したら、コードの書き込みを開始します
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
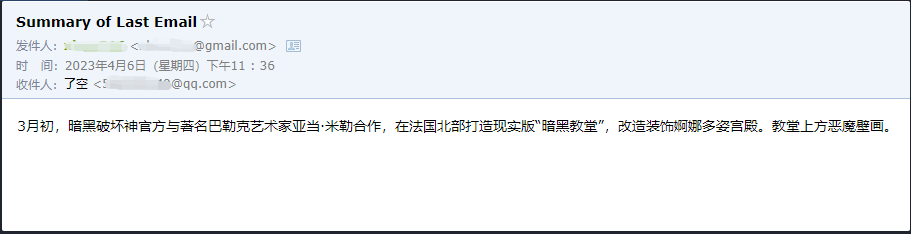
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
彼は******@qq.comから送信された最後のメールを正常に読んで、概要コンテンツを******@qq.comに再度送信したことがわかります。
これは私がGmailに送ったメールです。

これは、彼がQQメールに送信したメールです。
zapierは何千ものアプリケーションがあるため、これはほんの小さな例です。そのため、OpenAI APIで独自のワークフローを簡単に作成できます。
より大きな知識ポイントのいくつかが説明されており、次のコンテンツはすべて、拡張としてのいくつかの興味深い小さな例に関するものです。
鎖でつながれているため、彼は順番に複数のチェーンを実行することもできます。
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )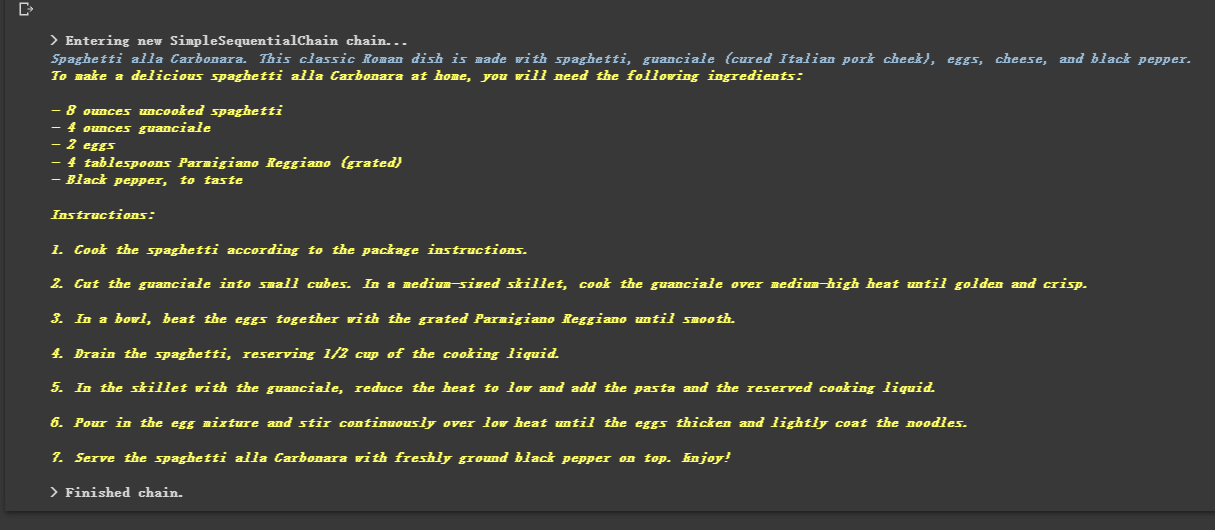
出力をテキストではなく、JSONのような構造化されたデータにしたい場合があります。
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
時々私たちはいくつかをcraう必要がありますより強い構造また、Webページの情報はJSONモードで返される必要があります。
LLMRequestsChainクラスを使用して、次のコードを参照してください
簡単に理解するために、私は迅速な方法を直接使用して、出力結果を例にフォーマットしましたが、前のケースで使用した
StructuredOutputParserを使用してフォーマットしませんでした。
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])彼がフォーマットされた結果を非常にうまく出力していることがわかります

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )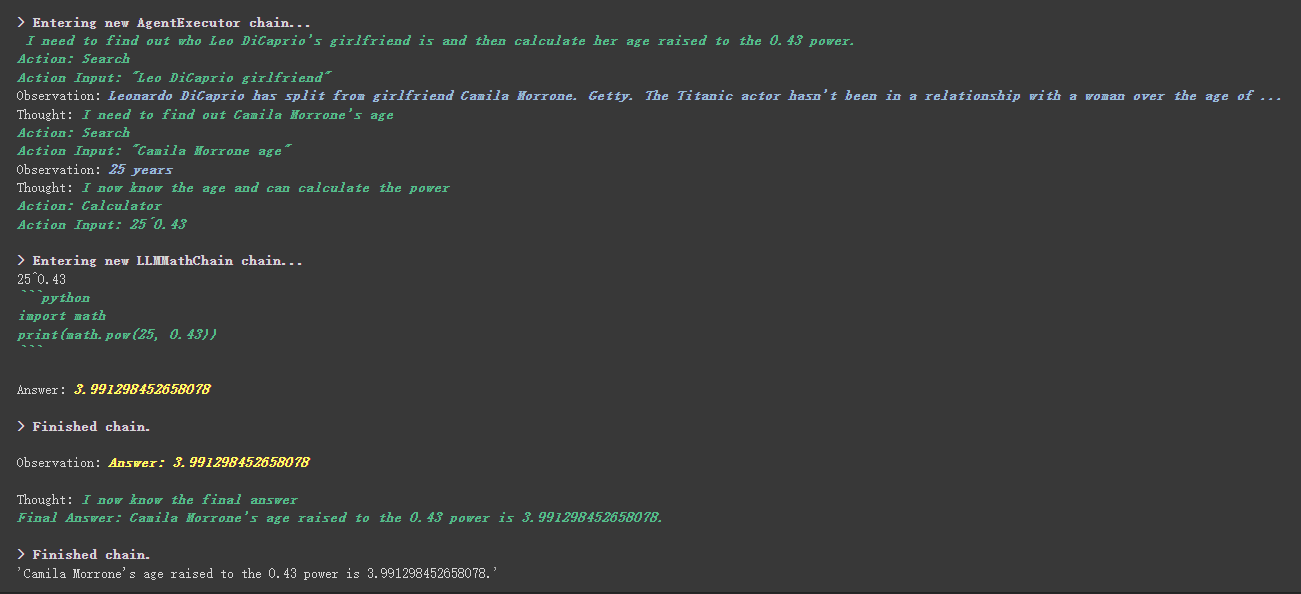
カスタムツールには、より興味深いものがあります。これは、工具中描述内容に基づいて重みを達成するために使用されます。これは、数値を制御する以前のプログラミングとは完全に異なります。
たとえば、Calculatorは、数学について質問する場合、このツールを使用すると説明しました。上記の実行プロセスで、要求されたProptの数学部分で、彼は計算に計算ツールを使用したことがわかります。
前の例では、会話を保存するためにリストをカスタマイズすることにより、履歴を保存する方法を使用しました。
もちろん、付属のメモリオブジェクトを使用してこれを達成することもできます。
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )ハグする顔モデルを使用する前に、最初に環境変数を設定する必要があります
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''オンラインで抱きしめる顔モデルを使用します
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))抱きしめる顔モデルを直接引いて、ローカルで使用します
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))ローカルで使用するためにモデルを引くことの利点:
SQLDatabaseToolkitまたはSQLDatabaseChainを介してSQLコマンドを実装できます
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )ここでは、これら2つのドキュメントを参照できます。
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
すべてのケースは基本的に終了しました。この記事は、Langchainの予備的な説明にすぎません。
そして、Langchainは非常に迅速に反復するため、AIが開発を続けるにつれて、より良い機能を確実に繰り返すため、このオープンソースライブラリについて非常に楽観的です。
Langchainを組み合わせて、ワンクリックでチャットクライアントを構築する多くの製品を作成するだけでなく、より創造的な製品を開発できることを願っています。
このタイトルの後に、 01記事が後で登場することを願っています。
この記事のすべてのサンプルコードはこちらです。幸せな学習をお祈りします。
https://colab.research.google.com/drive/1arrvmis-ykhulobhru6bes8ff57ueapq?usp=sharing


