LangChain Chinese Getting Started Guide
1.0.0
Para uma leitura fácil, os GitBooks foram gerados: https://liaokong.gitbook.io/llm-kai-da-jiao-cheng/
Endereço do Github: https://github.com/liaokongvfx/langchain-chinese-getting-tarted-guide
"Decripção da tecnologia Langchain: um guia panorâmico para a construção de grandes aplicações de modelos" foi publicado agora: https://item.jd.com/14598210.html
Transferência de API do modelo de IA doméstica e estrangeira de baixo preço: https://api.91ai.me
Como a biblioteca Langchain foi rapidamente atualizada e iterando, mas o documento está escrito no início de abril, e eu tenho energia pessoal limitada, para que o código no Colab possa estar um pouco desatualizado. Se houver alguma falha na operação, você poderá primeiro procurar se o documento atual foi atualizado
Adicionei um Changelog e atualizei o novo conteúdo.
Se você deseja modificar a rota raiz da solicitação da API do OpenAI para seu próprio endereço de proxy, poderá modificá -la definindo a variável de ambiente "OpenAI_API_BASE".
Código de referência relacionado: https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbef1/openai/__init__.py#l48
Ou ao inicializar objetos de modelo relacionados ao OpenAI, passe na variável "OpenAi_API_Base".
Código de referência relacionado: https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
Como todos sabemos, a API do OpenAI não pode ser conectada à Internet; portanto, é definitivamente impossível usar suas próprias funções para pesquisar e fornecer respostas, resumir documentos em PDF e executar perguntas e respostas com base em um vídeo do YouTube. Então, vamos apresentar uma biblioteca de código aberto de terceiros muito poderoso: LangChain .
Endereço do documento: https://python.langchain.com/en/latest/
Atualmente, esta biblioteca é muito ativa e iterada todos os dias.
Langchain é uma estrutura para o desenvolvimento de aplicativos alimentados por modelos de idiomas. Ele tem 2 habilidades principais:
Modelo LLM: modelo de linguagem grande, modelo de linguagem grande
LLM CHAMADA
Gerenciamento imediato, suporta vários modelos personalizados
Possui um grande número de carregadores de documentos, como email, markdown, pdf, youtube ...
Suporte para índices
Correntes
Acredito que todos ficarão confusos depois de ler a introdução acima. Não se preocupe, o conceito acima não é muito importante quando começamos a aprender.
No entanto, aqui estão vários conceitos que devem ser conhecidos.
Como o nome indica, isso é carregar dados de uma fonte especificada. Por exemplo: DirectoryLoader de pastas, armazenamento do Azure AzureBlobStorageContainerLoader , arquivo CSV CSVLoader , Evernote EverNoteLoader , Google GoogleDriveLoader , qualquer página da web UnstructuredHTMLLoader , PDF PyPDFLoader , S3DirectoryLoader / S3FileLoader
YouTube YoutubeLoader , etc., eu listei brevemente alguns deles.
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
Depois de ler a fonte de dados usando o carregador, a fonte de dados precisa ser convertida em um objeto de documento antes que ele possa ser usado posteriormente.
Como o nome sugere, a segmentação de texto é usada para dividir o texto. Por que você precisa dividir o texto? Porque toda vez que enviamos texto como propt para o OpenAI API ou usamos a função de incorporação da API do OpenAI, existem restrições de caracteres.
Por exemplo, se enviarmos um PDF de 300 páginas para a API Openai e pedir que ele resuma, ele definitivamente relatará um erro que excede o token máximo. Então, aqui precisamos usar um divisor de texto para dividir o documento em que nosso carregador entra.
Porque a pesquisa de correlação de dados é na verdade uma operação de vetor. Portanto, se usamos a função de incorporação da API OpenAI ou consulta diretamente através do banco de dados do vetor, precisamos vetorizar nosso Document de dados carregado para executar a pesquisa de operação do vetor. A conversão em um vetor também é muito simples.
O funcionário também fornece muitos bancos de dados vetoriais para usarmos.
https://python.langchain.com/en/latest/modules/indexes/vectorstors.html
Podemos entender a cadeia como uma tarefa. Uma corrente é uma tarefa e, é claro, também pode executar várias cadeias, uma a uma como uma corrente.
Podemos simplesmente entender que isso pode nos ajudar dinamicamente a escolher e chamar a cadeia ou ferramentas existentes.
Para o processo de execução, consulte a figura a seguir:
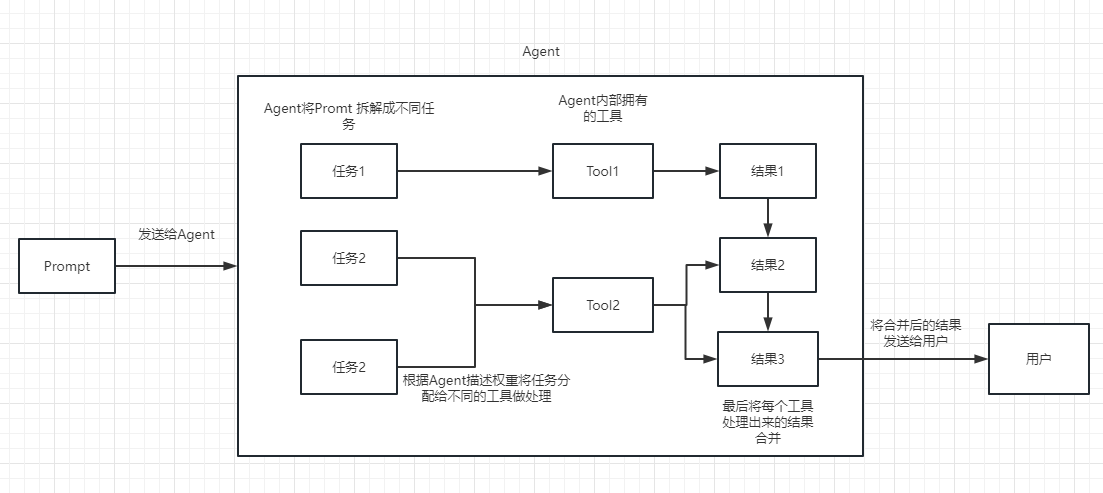
Usado para medir a relevância do texto. Essa também é a chave para a capacidade da API do OpenAI de construir sua própria base de conhecimento.
Sua maior vantagem sobre o ajuste fina é que ele não precisa treinar e pode adicionar novo conteúdo em tempo real, em vez de adicionar novo conteúdo uma vez, e o custo em todos os aspectos é muito menor que o ajuste fino.
Para comparações e seleções específicas, consulte este vídeo: https://www.youtube.com/watch?v=9qq6htr7ocw
Através dos conceitos essenciais acima, você deve ter um certo entendimento de Langchain, mas ainda pode estar um pouco confuso.
Essas são todas pequenas perguntas.
Como nossa API OpenAI é avançada, o LLM usado em nossos exemplos subsequentes é baseado em IA aberta como exemplo.
Obviamente, no final deste artigo, todo o código será salvo como um arquivo do Colab IPYNB e fornecido para que todos aprendam.
Recomenda -se que você olhe para cada exemplo em ordem, porque o próximo exemplo usará os pontos de conhecimento no exemplo anterior.
Obviamente, se você não entende algo, não se preocupe.
No primeiro caso, usaremos o Langchain para carregar o modelo OpenAI e concluir uma sessão de perguntas e respostas.
Antes de iniciar, precisamos configurar nossa chave OpenAI primeiro.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'Então nós importamos e executamos
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
Neste momento, podemos ver o resultado que ele nos deu.
Em seguida, vamos fazer algo interessante. Vamos fazer com que nossa API do Openai pesquise on -line e retorne as respostas para nós.
Aqui precisamos usar o SERPAPI para implementá -lo, que fornece uma interface de API para pesquisa do Google.
Primeiro, precisamos registrar um usuário no site oficial da SERPAPI, https://serpapi.com/ e copiá -lo para gerar a chave da API para nós.
Em seguida, precisamos defini -lo na variável de ambiente, como a chave da API OpenAI acima.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'Então, comece a escrever meu código
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )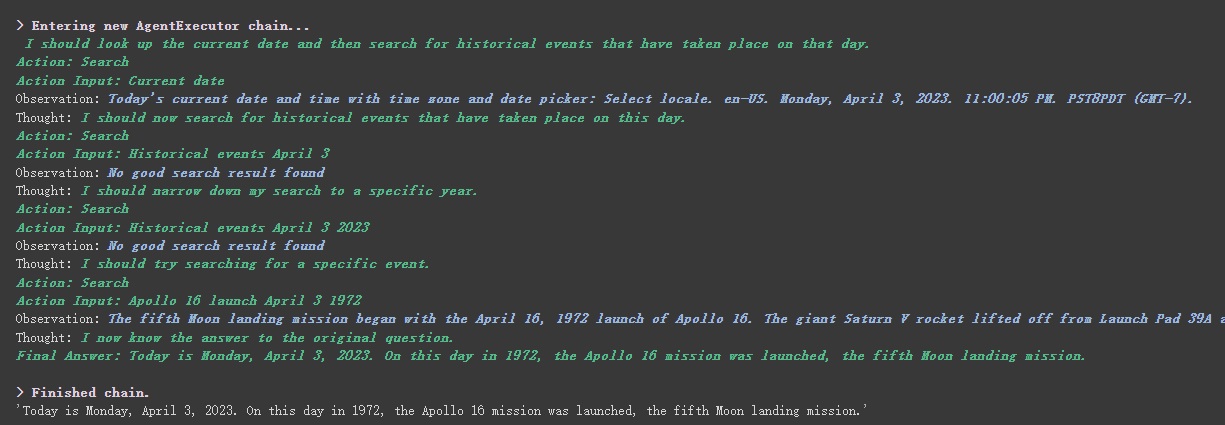
Podemos ver que ele retornou corretamente a data (às vezes diferença) e retornou hoje na história.
Existe o parâmetro verbose nos objetos da cadeia e do agente.
Como você pode ver no resultado retornado acima, ele divide nossa pergunta em várias etapas e depois recebe a resposta final passo a passo.
Em relação ao significado de várias opções para o tipo de agente (se você não conseguir entender, isso não afetará o seguinte aprendizado. Se você o usar demais, você naturalmente o entenderá):
Search e Lookup , o primeiro é usado para pesquisar, e o último é usado para encontrar o termo, por exemplo: Ferramenta WipipediaGoogle search APIVocê pode ver isso para o React Introdução: https://arxiv.org/pdf/2210.03629.pdf
Implementação do Python do padrão de reação de LLM: https://til.simonwillison.net/llms/python-react-pattern
Tipo de agente Explicação oficial:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-react-de-descrição
Uma coisa a ser observada é que esse
serpapiparece não muito amigável com os chineses, então o prompt solicitado é recomendado para usar o inglês.
Obviamente, o funcionário escreveu o agente dos ChatGPT Plugins .
No entanto, atualmente, apenas os plug-ins que não exigem autorização podem ser usados.
Aqueles que estão interessados podem ler este documento: https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
O chatgpt só pode ganhar dinheiro para o oficial, e a API OpenAI pode ganhar dinheiro para mim
Se quisermos usar a API do OpenAI para resumir um parágrafo de texto, nossa maneira usual é enviá -la diretamente à API para que ela resuma. No entanto, se o texto exceder o limite máximo de token da API, um erro será relatado.
Neste momento, geralmente segmentamos o artigo, como calcular e dividir -o através de Tiktoken, depois enviando cada parágrafo à API para resumo e, finalmente, resumindo o resumo de cada parágrafo.
Se você usa Langchain, ele nos ajudou a lidar muito com esse processo, facilitando muito a escrita de código.
Sem mais delongas, basta fazer o upload do código.
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])Primeiro, imprimimos o número de documentos antes e depois do corte.
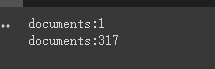
Finalmente, um resumo dos primeiros 5 documentos é emitido.

Aqui estão alguns parâmetros a serem observados:
O parâmetro chunk_overlap do divisor de texto
Isso se refere ao conteúdo que termina com vários documentos anteriores em cada documento após o corte. Por chunk_overlap=2 , quando chunk_overlap=0 , o primeiro documento é AAAAAAA, o segundo é BBBBBB;
No entanto, isso não é absoluto, depende do algoritmo específico dentro do modelo de segmentação de texto usado.
Você pode consultar este documento para divisores de texto: https://python.langchain.com/en/latest/modules/indexs/text_splitters.html
chain_type Parâmetro da cadeia
Este parâmetro controla principalmente a maneira como o documento é passado para o modelo LLM, e há quatro maneiras no total:
stuff : isso é mais simples e grosseiro, e passará todos os documentos para o modelo LLM de uma só vez para resumo. Se houver muitos documentos, ele inevitavelmente relatará um erro que excede o limite máximo de token, portanto, isso geralmente não é selecionado ao resumir o texto.
map_reduce : Este método resumirá primeiro cada documento e, finalmente, resumirá os resultados resumidos por todos os documentos.
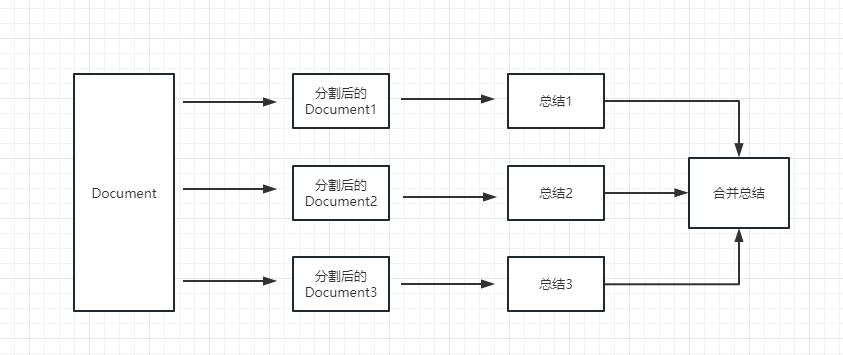
refine : Este método resumirá primeiro o primeiro documento e depois enviará o conteúdo resumido pelo primeiro documento e o segundo documento para o modelo LLM para resumo, e assim por diante. A vantagem desse método é que, ao resumir o último documento, ele levará o documento anterior para resumir, adicionar contexto ao documento que precisa ser resumido e aumentará a consistência do conteúdo resumido.
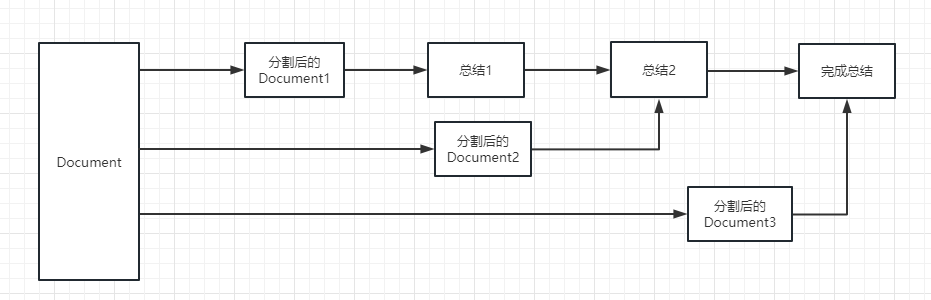
map_rerank : Esse tipo de cadeia geralmente não é usado em resumo, mas em pergunta e cadeia de respostas. Primeiro, você precisa fazer uma pergunta.
Neste exemplo, explicaremos como construir uma base de conhecimento lendo vários documentos de nós localmente e usará a API do OpenAI para pesquisar e dar respostas na base de conhecimento.
Este é um tutorial muito útil, como um robô que pode introduzir facilmente os negócios da empresa ou um robô que introduz um produto.
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )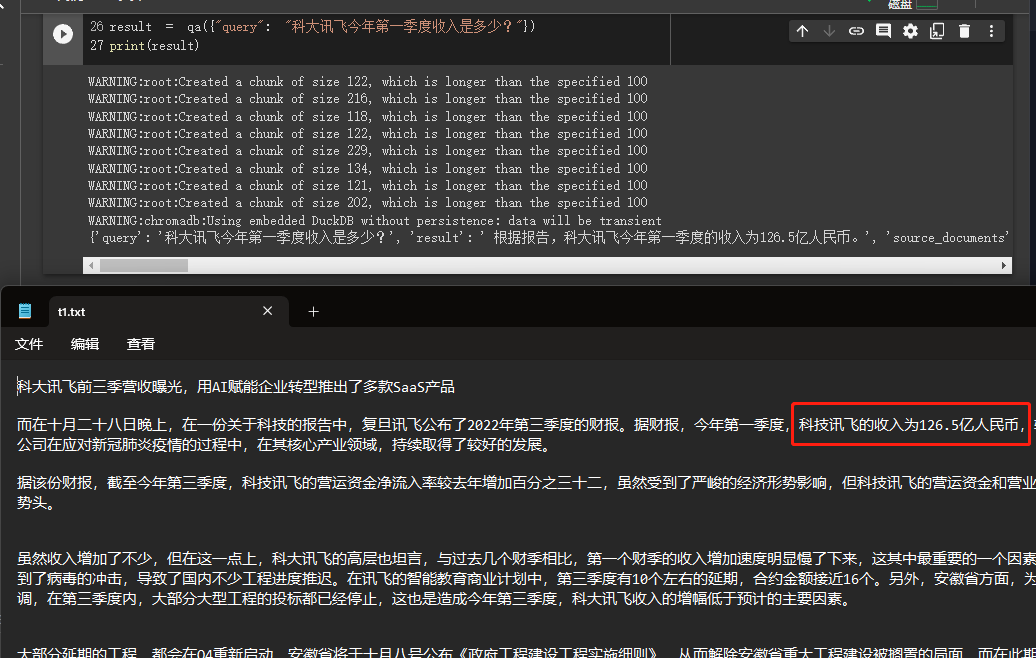
Podemos ver através dos resultados que ele obteve com sucesso a resposta correta dos dados que fornecemos.
Para detalhes sobre o OpenAi incorpeddings, consulte este link: https://platform.openai.com/docs/guides/embeddings
Uma etapa do nosso caso anterior foi converter informações de documentos em informações de vetores e informações de incorporação e armazená -las temporariamente no banco de dados Chroma.
Como é temporariamente armazenado, quando o código acima é executado, os dados após a vetorização acima serão perdidos. Se você deseja usá -lo na próxima vez, precisará calcular o incorporação novamente, o que definitivamente não é o que queremos.
Portanto, neste caso, falaremos sobre como persistir dados vetoriais através dos dois bancos de dados de Chroma e Pinecone.
Como o Langchain suporta muitos bancos de dados, aqui estão dois que são usados com mais frequência.
Chroma
O Chroma é um banco de dados vetorial local, que fornece um persist_directory para definir o diretório persistente de persistência. Ao ler, você só precisa ligar para o método from_document para carregar.
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )Pinecone
O Pinecone é um banco de dados vetorial online. Portanto, a primeira etapa que ainda posso me registrar e obter a tecla API correspondente. https://app.pinecone.io/
A versão gratuita será limpa automaticamente se o índice não for usado por 14 dias.
Em seguida, crie nosso banco de dados:
Nome do índice: isso é casual
Dimensões: o modelo de embutido-Ada-002 do OpenAI é as dimensões de saída é 1536, então preencemos 1536 aqui
Métrica: pode padrão de cosseno
Selecione o plano inicial
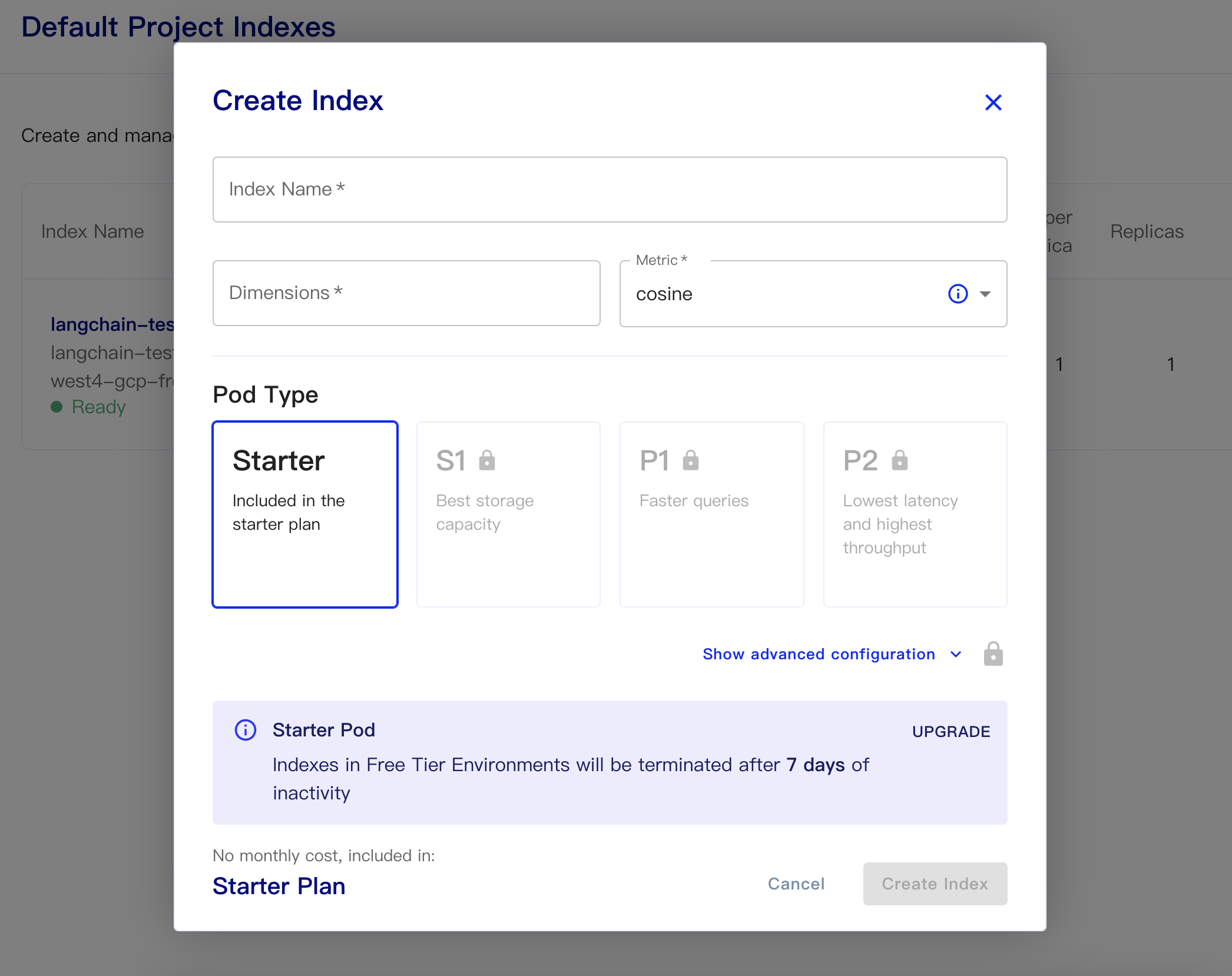
Os dados persistentes e os códigos de dados são os seguintes
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )Um código simples para obter incorporações do banco de dados e responde é o seguinte
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
Depois que a API ChatGPT (ou seja, o modelo GPT-3.5-Turbo) foi lançado, foi amado por todos porque era menos dinheiro, então Langchain também adicionou cadeias e modelos exclusivos.
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])Podemos ver que ele pode responder com precisão perguntas e respostas em torno deste vídeo de tubo de óleo

As respostas de streaming também são muito convenientes
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ()) Usamos principalmente zapier para conectar milhares de ferramentas.
Portanto, nosso primeiro passo é solicitar uma conta e sua chave de API de linguagem natural. https://zapier.com/l/natural-language-actions
Sua chave da API precisa preencher o aplicativo de informações. No entanto, depois de preencher basicamente as informações, você pode basicamente ver o email aprovado no endereço de e -mail em segundos.
Em seguida, abrimos nossa página de configuração da API clicando com o botão direito do mouse na conexão. Clicamos em Manage Actions no direito de configurar quais aplicativos queremos usar.
Eu configurei as ações do Gmail para ler e enviar e -mails aqui, e todos os campos são selecionados pela AI adivinhando.
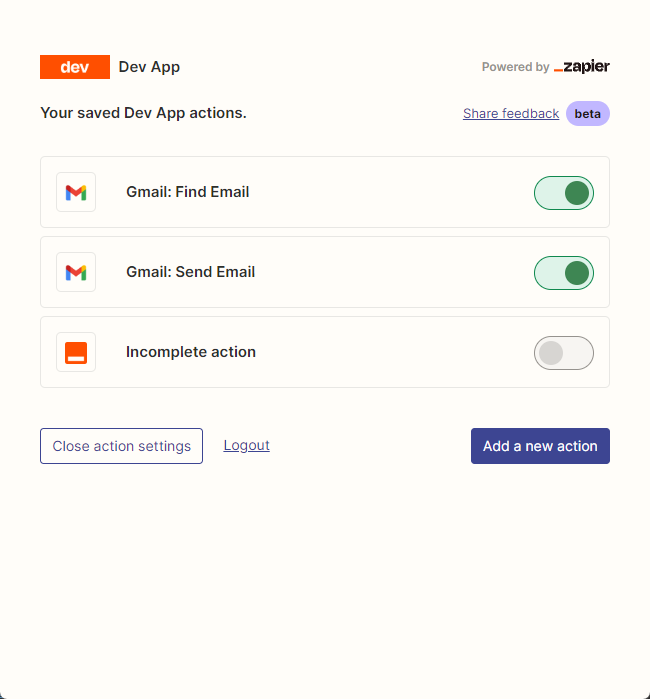
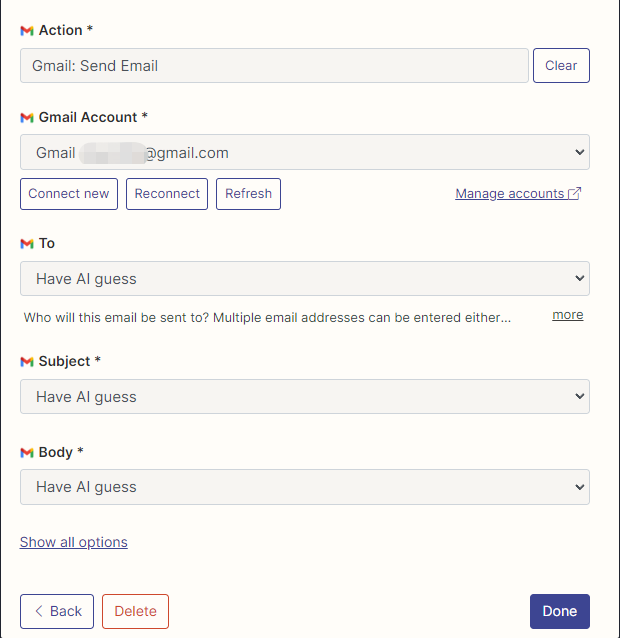
Após a conclusão da configuração, começamos a escrever o código
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
Podemos ver que ele leu com sucesso o último e -mail enviado a ele por ******@qq.com e enviou o conteúdo resumido para ******@qq.com novamente.
Este é o e -mail que enviei para o Gmail.

Este é o e -mail que ele enviou para seu e -mail QQ.
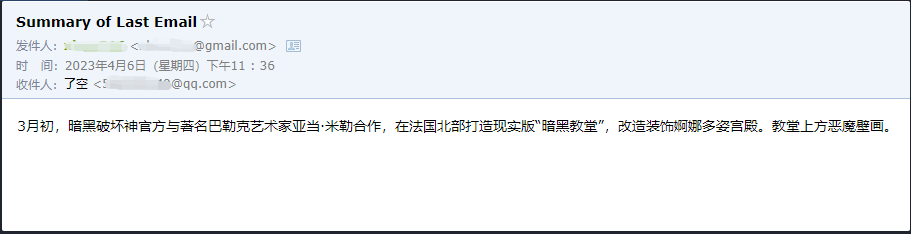
Este é apenas um pequeno exemplo, porque zapier possui milhares de aplicativos, para que possamos facilmente construir nossos próprios fluxos de trabalho com a API do OpenAI.
Alguns dos maiores pontos de conhecimento foram explicados, e o conteúdo a seguir é sobre alguns pequenos exemplos interessantes, como extensões.
Por estar acorrentado, ele também pode executar várias cadeias em sequência.
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )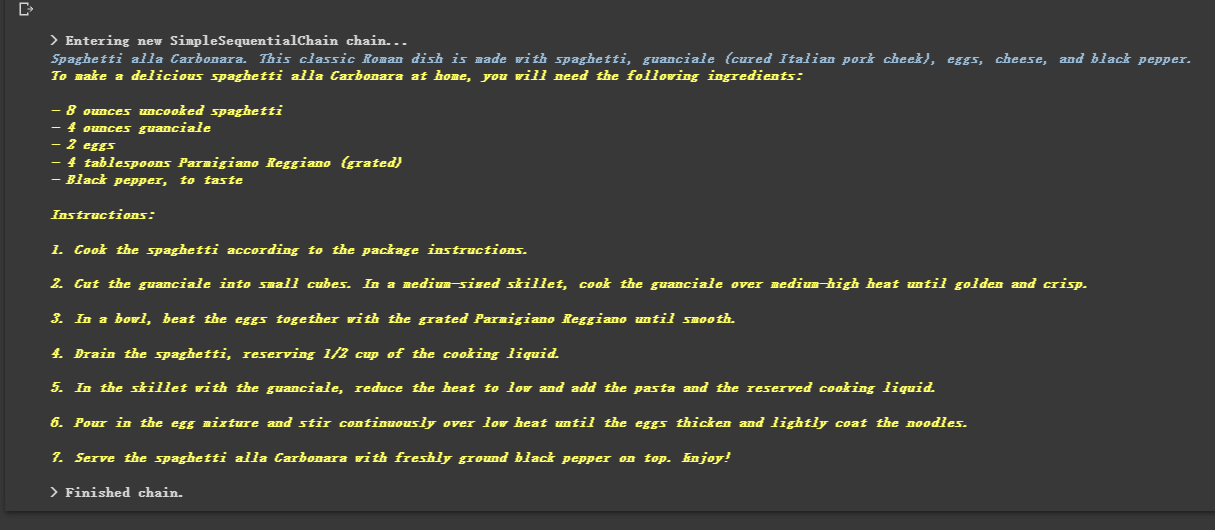
Às vezes, queremos que a saída não seja texto, mas dados estruturados como o JSON.
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
Às vezes precisamos rastejar alguns Estrutura mais forte e as informações na página da web precisam ser devolvidas no modo JSON.
Podemos usar a classe LLMRequestsChain para implementá -la.
Por uma questão de entendimento fácil, usei diretamente o método rápido para formatar os resultados da saída no exemplo, mas não usei
StructuredOutputParserusado no caso anterior para formatá -lo, que também pode ser considerado como fornecendo outra idéia de formatação.
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])Podemos ver que ele produz os resultados formatados muito bem

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )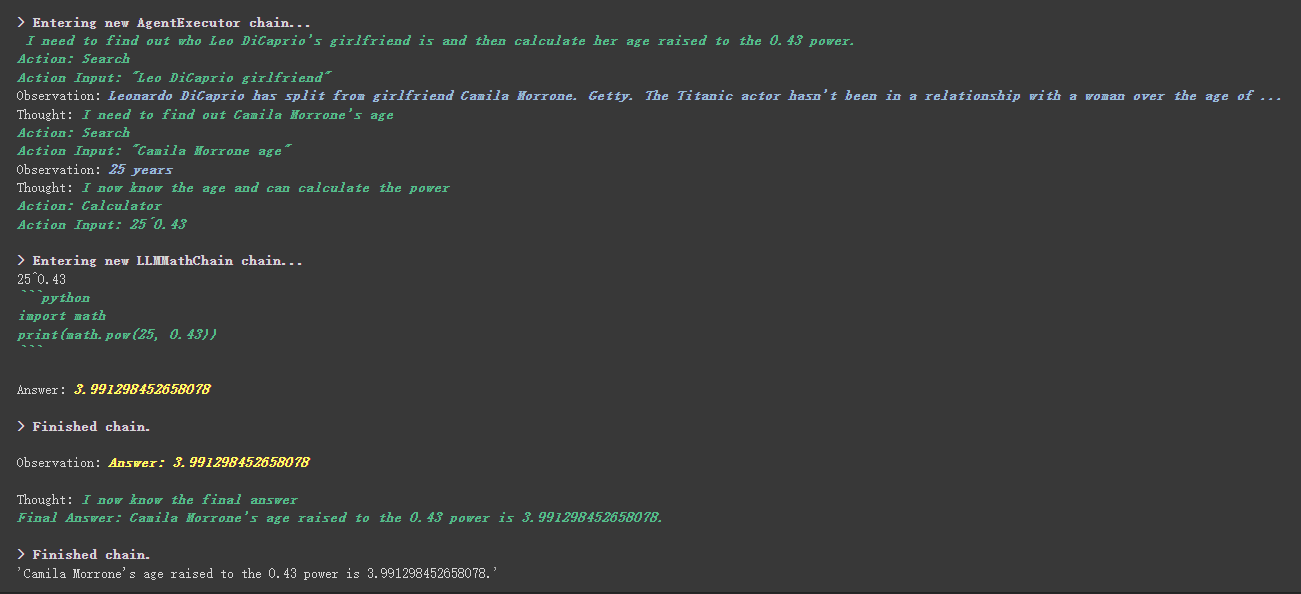
Há uma coisa mais工具中描述内容na ferramenta personalizada.
Por exemplo, a calculadora escreveu na descrição que, se você fizer perguntas sobre matemática, use esta ferramenta. Podemos ver no processo de execução acima que, na parte matemática do nosso Propt solicitado, ele usou a ferramenta de calculadora para cálculos.
No exemplo anterior, usamos a maneira como salvamos a história, personalizando uma lista para armazenar conversas.
Obviamente, você também pode usar o objeto de memória incluído para conseguir isso.
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )Antes de usar o modelo de rosto abraçando, você precisa definir variáveis de ambiente primeiro
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''Usando o Modelo de Abraço de Abraço online
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))Puxe o modelo de rosto abraçado diretamente para usar localmente
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))Benefícios de puxar o modelo para usar localmente:
Podemos implementar comandos SQL através SQLDatabaseToolkit ou SQLDatabaseChain
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )Aqui você pode se referir a esses dois documentos:
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
Todos os casos terminaram basicamente. Este artigo é apenas uma explicação preliminar de Langchain.
E como o Langchain itera muito rapidamente, ele definitivamente iterará melhores funções à medida que a IA continua a se desenvolver, por isso estou muito otimista sobre essa biblioteca de código aberto.
Espero que todos possam combinar o Langchain para desenvolver produtos mais criativos, em vez de apenas criar um monte de produtos que criam clientes de bate -papo com um clique.
Eu adicionei um 01 após este título. Espero que este artigo seja apenas o começo.
Todos os códigos de amostra deste artigo estão aqui, desejo -lhe um feliz aprendizado.
https://colab.research.google.com/drive/1arrvmis-ykhulobhru6bes8ff57ueapq?usp=sharing


