LangChain Chinese Getting Started Guide
1.0.0
สำหรับการอ่านง่าย gitbooks ได้รับการสร้างขึ้น: https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
ที่อยู่ GitHub: https://github.com/liaokongvfx/langchain-chinese-getting-started-guide
"การถอดรหัสเทคโนโลยี Langchain: คู่มือพาโนรามาในการสร้างแอปพลิเคชันรุ่นใหญ่" ได้รับการเผยแพร่แล้ว: https://item.jd.com/14598210.html
การถ่ายโอน API แบบจำลอง AI ในประเทศและต่างประเทศราคาถูก: https://api.91ai.me
เนื่องจากห้องสมุด Langchain ได้รับการปรับปรุงอย่างรวดเร็วและวนซ้ำ แต่เอกสารถูกเขียนขึ้นในต้นเดือนเมษายนและฉันมีพลังงานส่วนบุคคลที่ จำกัด ดังนั้นรหัสใน colab อาจค่อนข้างล้าสมัย หากมีความล้มเหลวในการดำเนินการคุณสามารถค้นหาได้ก่อนว่าเอกสารปัจจุบันได้รับการอัปเดตหรือไม่
ฉันเพิ่มการเปลี่ยนแปลงและอัปเดตเนื้อหาใหม่
หากคุณต้องการแก้ไขเส้นทางรูทคำขอของ OpenAI API ไปยังที่อยู่พร็อกซีของคุณเองคุณสามารถแก้ไขได้โดยการตั้งค่าตัวแปรสภาพแวดล้อม "OpenAI_API_BASE"
รหัสอ้างอิงที่เกี่ยวข้อง: https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbef1/openai/__init__.py#l48
หรือเมื่อเริ่มต้นวัตถุโมเดลที่เกี่ยวข้องกับ OpenAI ให้ส่งผ่านในตัวแปร "OpenAI_API_BASE"
รหัสอ้างอิงที่เกี่ยวข้อง: https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
อย่างที่เราทราบกันดีว่า API ของ Openai ไม่สามารถเชื่อมต่อกับอินเทอร์เน็ตได้ดังนั้นจึงเป็นไปไม่ได้ที่จะใช้ฟังก์ชั่นของตัวเองเพื่อค้นหาและให้คำตอบสรุปเอกสาร PDF และดำเนินการถาม & ตอบตามวิดีโอ YouTube ดังนั้นเรามาแนะนำไลบรารีโอเพ่นซอร์สของบุคคลที่สามที่ทรงพลังมาก: LangChain
ที่อยู่เอกสาร: https://python.langchain.com/en/latest/
ห้องสมุดนี้มีการใช้งานมากและวนซ้ำทุกวัน
Langchain เป็นกรอบสำหรับการพัฒนาแอพพลิเคชั่นที่ขับเคลื่อนด้วยโมเดลภาษา เขามี 2 ความสามารถหลัก:
รุ่น LLM: โมเดลภาษาขนาดใหญ่รูปแบบภาษาขนาดใหญ่
การโทร LLM
การจัดการที่รวดเร็วรองรับเทมเพลตที่กำหนดเองต่างๆ
มีตัวโหลดเอกสารจำนวนมากเช่นอีเมล, Markdown, PDF, YouTube ...
สนับสนุนดัชนี
โซ่
ฉันเชื่อว่าทุกคนจะสับสนหลังจากอ่านบทนำข้างต้น ไม่ต้องกังวลแนวคิดข้างต้นไม่สำคัญมากเมื่อเราเริ่มเรียนรู้ครั้งแรก
อย่างไรก็ตามนี่คือแนวคิดหลายประการที่ต้องรู้จัก
ตามชื่อหมายถึงนี่คือการโหลดข้อมูลจากแหล่งที่มา S3FileLoader เช่น: DirectoryLoader โฟลเดอร์, Azure Storage AzureBlobStorageContainerLoader , ไฟล์ CSV CSVLoader PyPDFLoader Evernote EverNoteLoader , Google GoogleDriveLoader , UnstructuredHTMLLoader ใด S3DirectoryLoader
YouTube YoutubeLoader ฯลฯ ฉันเพิ่งแสดงรายการสั้น ๆ
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
หลังจากอ่านแหล่งข้อมูลโดยใช้ตัวโหลดตัวโหลดแล้วแหล่งข้อมูลจะต้องถูกแปลงเป็นวัตถุเอกสารก่อนที่จะสามารถใช้งานได้ในภายหลัง
ตามชื่อแนะนำการแบ่งส่วนข้อความใช้เพื่อแบ่งข้อความ ทำไมคุณต้องแยกข้อความ? เนื่องจากทุกครั้งที่เราส่งข้อความเป็น propt ไปยัง OpenAI API หรือใช้ฟังก์ชันการฝัง OpenAI API มีข้อ จำกัด ของตัวละคร
ตัวอย่างเช่นหากเราส่ง PDF 300 หน้าไปยัง OpenAI API และขอให้เขาสรุปเขาจะรายงานความผิดพลาดที่เกินโทเค็นสูงสุดอย่างแน่นอน ดังนั้นที่นี่เราต้องใช้ตัวแยกข้อความเพื่อแยกเอกสารที่ตัวโหลดของเราเข้ามา
เนื่องจากการค้นหาความสัมพันธ์ของข้อมูลเป็นการดำเนินการเวกเตอร์ ดังนั้นไม่ว่าเราจะใช้ฟังก์ชั่นการฝัง OpenAI API หรือสอบถามโดยตรงผ่านฐานข้อมูล Vector เราจำเป็นต้องใช้ Vectorize Document Data ของเราเพื่อทำการค้นหาการดำเนินการเวกเตอร์ การแปลงเป็นเวกเตอร์นั้นง่ายมาก
เจ้าหน้าที่ยังให้ฐานข้อมูลเวกเตอร์จำนวนมากเพื่อให้เราใช้
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
เราสามารถเข้าใจโซ่เป็นงาน ห่วงโซ่เป็นงานและแน่นอนว่ามันยังสามารถดำเนินการหลายโซ่ทีละตัวเหมือนโซ่
เราสามารถเข้าใจได้ว่ามันสามารถช่วยให้เราเลือกและโทรสายโซ่หรือเครื่องมือที่มีอยู่ได้แบบไดนามิก
สำหรับกระบวนการดำเนินการโปรดดูภาพต่อไปนี้:
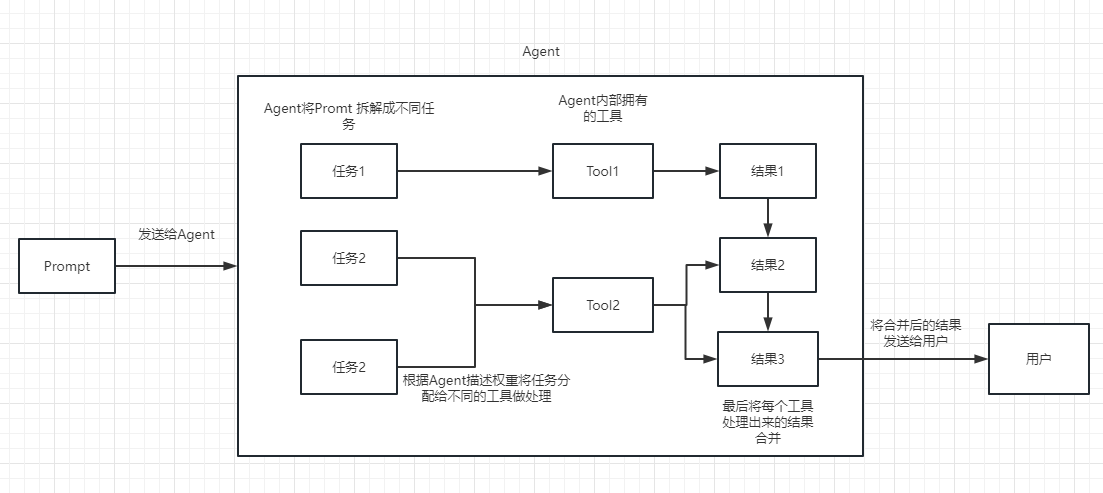
ใช้ในการวัดความเกี่ยวข้องของข้อความ นี่เป็นกุญแจสำคัญในความสามารถของ OpenAI API ในการสร้างฐานความรู้ของตัวเอง
ข้อได้เปรียบที่ยิ่งใหญ่ที่สุดของเขาในการปรับแต่งอย่างละเอียดคือเขาไม่จำเป็นต้องฝึกอบรมและสามารถเพิ่มเนื้อหาใหม่ในเวลาจริงแทนที่จะเพิ่มเนื้อหาใหม่หนึ่งครั้งและค่าใช้จ่ายในทุกด้านนั้นต่ำกว่าการปรับจูน
สำหรับการเปรียบเทียบและการเลือกเฉพาะโปรดดูวิดีโอนี้: https://www.youtube.com/watch?v=9QQ6HTR7OCW
ผ่านแนวคิดที่สำคัญข้างต้นคุณควรมีความเข้าใจบางอย่างเกี่ยวกับ Langchain แต่คุณอาจสับสนเล็กน้อย
นี่เป็นคำถามเล็ก ๆ ทั้งหมด
เนื่องจาก OpenAI API ของเราสูงขึ้น LLM ที่ใช้ในตัวอย่างที่ตามมาของเราทั้งหมดขึ้นอยู่กับ Open AI เป็นตัวอย่างในภายหลังคุณสามารถเปลี่ยนเป็นรุ่น LLM ที่คุณต้องการตามงานของคุณเอง
แน่นอนในตอนท้ายของบทความนี้รหัสทั้งหมดจะถูกบันทึกเป็นไฟล์ colab ipynb และให้ทุกคนเรียนรู้
ขอแนะนำให้คุณดูแต่ละตัวอย่างตามลำดับเนื่องจากตัวอย่างถัดไปจะใช้จุดความรู้ในตัวอย่างก่อนหน้า
แน่นอนถ้าคุณไม่เข้าใจอะไรบางอย่างไม่ต้องกังวล
ในกรณีแรกเราจะใช้ Langchain เพื่อโหลดโมเดล OpenAI และทำคำถามและคำตอบให้เสร็จสมบูรณ์
ก่อนที่จะเริ่มต้นเราต้องตั้งค่าคีย์ OpenAI ของเราก่อน
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'จากนั้นเรานำเข้าและดำเนินการ
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
ในเวลานี้เราสามารถเห็นผลลัพธ์ที่เขาให้กับเรา
ต่อไปมาทำสิ่งที่น่าสนใจกันเถอะ มารับ Openai API ของเราเพื่อค้นหาออนไลน์และส่งคืนคำตอบให้เรา
ที่นี่เราต้องใช้ Serpapi เพื่อนำไปใช้ซึ่งมีอินเตอร์เฟส API สำหรับการค้นหาของ Google
ก่อนอื่นเราต้องลงทะเบียนผู้ใช้บนเว็บไซต์ทางการของ Serpapi, https://serpapi.com/ และคัดลอกเพื่อสร้างคีย์ API สำหรับเรา
จากนั้นเราต้องตั้งค่าเป็นตัวแปรสภาพแวดล้อมเช่นคีย์ OpenAI API ด้านบน
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'จากนั้นเริ่มเขียนรหัสของฉัน
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )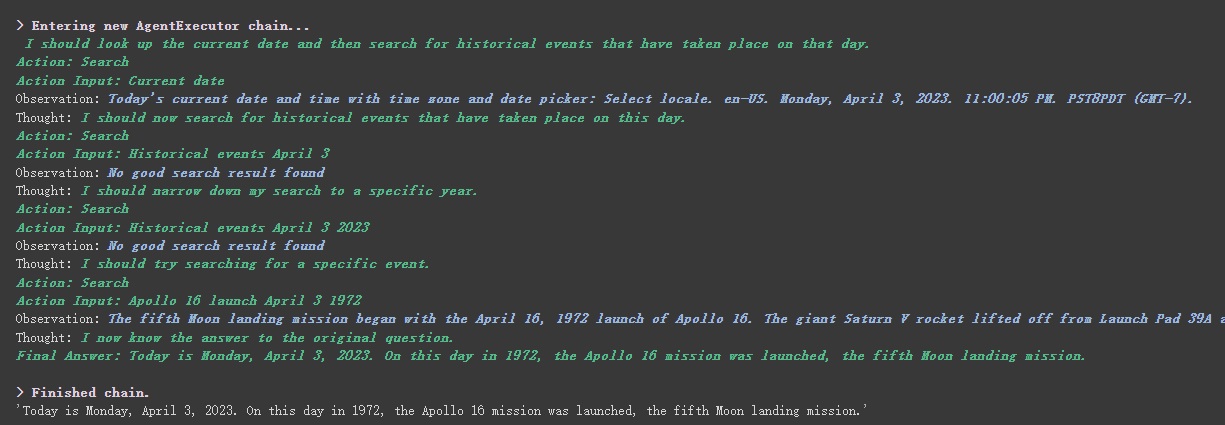
เราจะเห็นได้ว่าเขาส่งคืนวันที่ (บางครั้งความแตกต่าง) อย่างถูกต้องและกลับไปที่วันนี้ในประวัติศาสตร์
มีพารามิเตอร์ verbose บนโซ่และวัตถุตัวแทนนี่เป็นพารามิเตอร์ที่มีประโยชน์มาก
อย่างที่คุณเห็นจากผลลัพธ์ที่ส่งคืนข้างต้นเขาแยกคำถามของเราออกเป็นหลายขั้นตอนจากนั้นได้รับคำตอบสุดท้ายทีละขั้นตอน
เกี่ยวกับความหมายของตัวเลือกหลายอย่างสำหรับประเภทตัวแทน (หากคุณไม่เข้าใจมันจะไม่ส่งผลกระทบต่อการเรียนรู้ต่อไปนี้หากคุณใช้มันมากเกินไปคุณจะเข้าใจตามธรรมชาติ):
Search และ Lookup อดีตที่ใช้ในการค้นหาและหลังใช้เพื่อค้นหาคำเช่น: เครื่องมือ WipipediaGoogle search APIคุณสามารถดูสิ่งนี้สำหรับการแนะนำ React: https://arxiv.org/pdf/2210.03629.pdf
การใช้ Python ของรูปแบบการตอบสนองของ LLM: https://til.simonwillison.net/llms/python-react-pattern
ประเภทตัวแทนอย่างเป็นทางการคำอธิบาย:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-react-description
สิ่งหนึ่งที่ต้องสังเกตคือ
serpapiนี้ดูเหมือนจะไม่เป็นมิตรกับจีนมากนักดังนั้นขอแนะนำให้ใช้ภาษาอังกฤษ
แน่นอนว่าอย่างเป็นทางการได้เขียนตัวแทนของ ChatGPT Plugins
อย่างไรก็ตามในปัจจุบันปลั๊กอินที่ไม่ต้องการการอนุญาตเท่านั้นที่สามารถใช้งานได้
ผู้ที่สนใจสามารถอ่านเอกสารนี้: https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
CHATGPT สามารถสร้างรายได้ให้เป็นทางการเท่านั้นและ OpenAI API สามารถสร้างรายได้ให้ฉันได้
หากเราต้องการใช้ OpenAI API เพื่อสรุปย่อหน้าของข้อความวิธีปกติของเราคือการส่งโดยตรงไปยัง API เพื่อสรุป อย่างไรก็ตามหากข้อความเกินขีด จำกัด โทเค็นสูงสุดของ API จะมีการรายงานข้อผิดพลาด
ในเวลานี้เรามักจะแบ่งบทความเช่นการคำนวณและหารผ่าน tiktoken จากนั้นส่งแต่ละย่อหน้าไปยัง API สำหรับการสรุปและในที่สุดก็สรุปสรุปของแต่ละย่อหน้า
หากคุณใช้ Langchain เขาช่วยเราจัดการกระบวนการนี้ได้เป็นอย่างดีทำให้เราเขียนโค้ดได้ง่ายมาก
โดยไม่ต้องกังวลใจเพิ่มเติมเพียงอัปโหลดรหัส
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
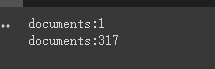
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])ก่อนอื่นเราพิมพ์จำนวนเอกสารก่อนและหลังการตัด
ในที่สุดสรุปเอกสาร 5 ฉบับแรกคือเอาต์พุต

นี่คือพารามิเตอร์บางอย่างที่ควรทราบ:
พารามิเตอร์ chunk_overlap ของตัวแยกข้อความ
สิ่งนี้หมายถึงเนื้อหาที่ลงท้ายด้วยเอกสารก่อนหน้าหลายฉบับในแต่ละเอกสารหลังจากตัด chunk_overlap=2 เช่นเมื่อ chunk_overlap=0 เอกสารแรกคือ AAAAAAAA ที่สองคือ BBBBBB;
อย่างไรก็ตามนี่ไม่ใช่แบบสัมบูรณ์ แต่ขึ้นอยู่กับอัลกอริทึมเฉพาะภายในรูปแบบการแบ่งส่วนข้อความที่ใช้
คุณสามารถอ้างถึงเอกสารนี้สำหรับตัวแยกข้อความ: https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
chain_type พารามิเตอร์ของโซ่
พารามิเตอร์นี้ส่วนใหญ่ควบคุมวิธีที่เอกสารถูกส่งไปยังโมเดล LLM และมีทั้งหมด 4 วิธี:
stuff : นี่เป็นเรื่องง่ายและหยาบและจะผ่านเอกสารทั้งหมดไปยังโมเดล LLM ในครั้งเดียวเพื่อสรุป หากมีเอกสารจำนวนมากมันจะรายงานข้อผิดพลาดที่เกินขีด จำกัด โทเค็นสูงสุดอย่างหลีกเลี่ยงไม่ได้ดังนั้นโดยทั่วไปจะไม่เลือกเมื่อสรุปข้อความ
map_reduce : วิธีนี้จะสรุปแต่ละเอกสารก่อนและสรุปผลลัพธ์ที่สรุปโดยเอกสารทั้งหมด
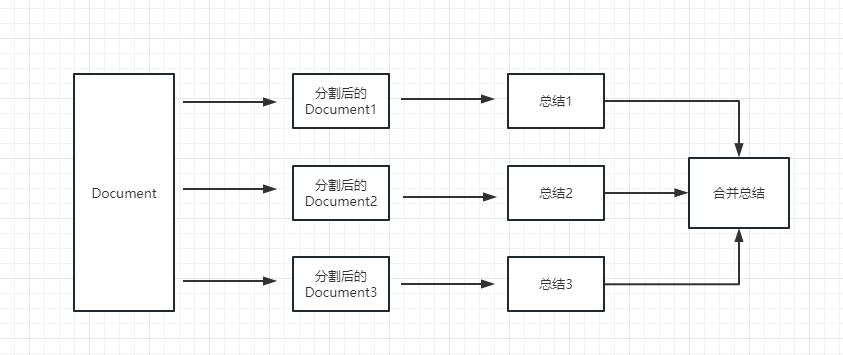
refine : วิธีนี้จะสรุปเอกสารแรกก่อนจากนั้นส่งเนื้อหาสรุปโดยเอกสารแรกและเอกสารที่สองไปยังโมเดล LLM สำหรับการสรุปและอื่น ๆ ข้อดีของวิธีนี้คือเมื่อสรุปเอกสารหลังจะใช้เอกสารก่อนหน้านี้เพื่อสรุปเพิ่มบริบทให้กับเอกสารที่ต้องสรุปและเพิ่มความสอดคล้องของเนื้อหาสรุป
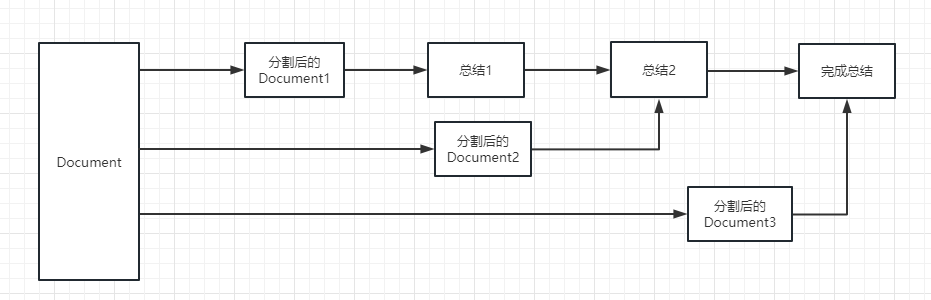
map_rerank : โซ่ประเภทนี้ไม่ได้ใช้โดยสรุป แต่ในห่วงโซ่และตอบคำถาม ก่อนอื่นคุณต้องตั้งคำถาม
ในตัวอย่างนี้เราจะอธิบายวิธีการสร้างฐานความรู้โดยการอ่านเอกสารหลายฉบับจากเราในพื้นที่และใช้ OpenAI API เพื่อค้นหาและให้คำตอบในฐานความรู้
นี่เป็นบทช่วยสอนที่มีประโยชน์มากเช่นหุ่นยนต์ที่สามารถแนะนำธุรกิจของ บริษัท หรือหุ่นยนต์ที่แนะนำผลิตภัณฑ์ได้อย่างง่ายดาย
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )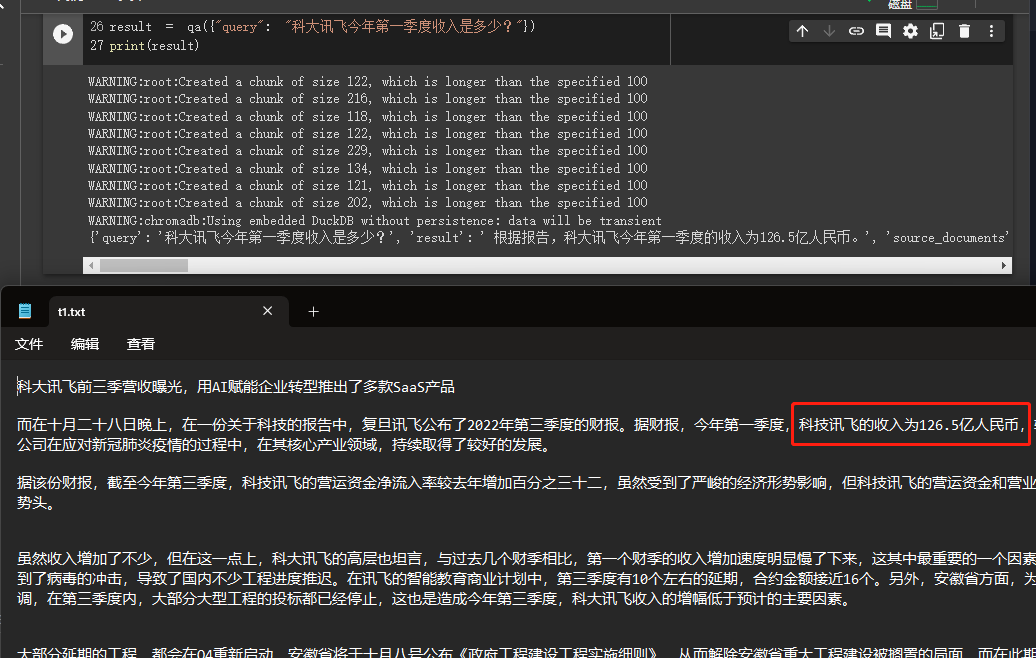
เราสามารถดูผ่านผลลัพธ์ที่เขาได้รับคำตอบที่ถูกต้องจากข้อมูลที่เราให้ความสำเร็จ
สำหรับรายละเอียดเกี่ยวกับ openai embeddings โปรดดูลิงค์นี้: https://platform.openai.com/docs/guides/embeddings
ขั้นตอนหนึ่งในกรณีก่อนหน้าของเราคือการแปลงข้อมูลเอกสารเป็นข้อมูลเวกเตอร์และข้อมูลฝังตัวและจัดเก็บไว้ในฐานข้อมูล Chroma ชั่วคราว
เนื่องจากมีการจัดเก็บชั่วคราวเมื่อมีการดำเนินการรหัสด้านบนข้อมูลหลังจากเวกเตอร์ข้างต้นจะหายไป หากคุณต้องการใช้มันในครั้งต่อไปคุณต้องคำนวณ Embeddings อีกครั้งซึ่งไม่ใช่สิ่งที่เราต้องการ
ดังนั้นในกรณีนี้เราจะพูดคุยเกี่ยวกับวิธีการคงข้อมูลเวกเตอร์ผ่านฐานข้อมูลทั้งสองของ Chroma และ Pinecone
เนื่องจาก Langchain รองรับฐานข้อมูลจำนวนมากนี่คือสองที่ใช้บ่อยขึ้น
โครมา
Chroma เป็นฐานข้อมูลเวกเตอร์ท้องถิ่นซึ่งให้บริการ persist_directory เพื่อตั้งค่าไดเรกทอรีถาวรสำหรับการคงอยู่ เมื่ออ่านคุณจะต้องโทรหาวิธีการ from_document เพื่อโหลด
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )Pinecone
Pinecone เป็นฐานข้อมูลเวกเตอร์ออนไลน์ ดังนั้นขั้นตอนแรกที่ฉันยังสามารถลงทะเบียนและรับคีย์ API ที่เกี่ยวข้อง https://app.pinecone.io/
เวอร์ชันฟรีจะถูกล้างโดยอัตโนมัติหากไม่ได้ใช้ดัชนีเป็นเวลา 14 วัน
จากนั้นสร้างฐานข้อมูลของเรา:
ชื่อดัชนี: นี่เป็นแบบไม่เป็นทางการ
ขนาด: โมเดลการฝังตัวของ OpenAI ของ OpenAi-ADA-002 คือขนาดเอาท์พุทคือ 1536 ดังนั้นเราจึงเติมในปี 1536 ที่นี่
ตัวชี้วัด: สามารถเริ่มต้นเป็นโคไซน์ได้
เลือกแผนเริ่มต้น
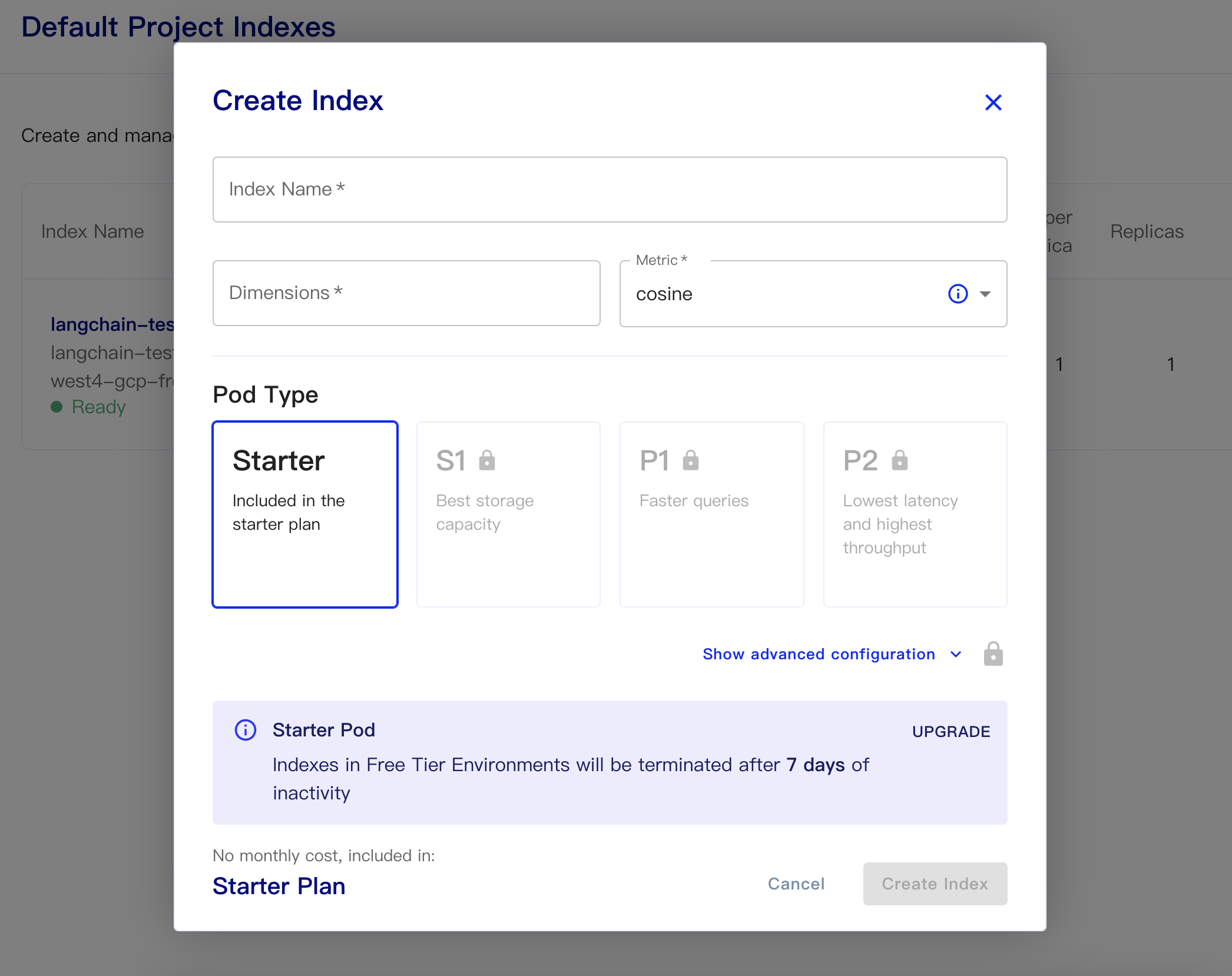
ข้อมูลถาวรและรหัสข้อมูลมีดังนี้
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )รหัสง่าย ๆ ที่จะได้รับการฝังฐานข้อมูลจากฐานข้อมูลและตอบว่าเป็นดังนี้
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
หลังจากรุ่น CHATGPT API (นั่นคือ GPT-3.5-Turbo) ได้รับการปล่อยตัวมันเป็นที่รักของทุกคนเพราะมันเป็นเงินน้อยลงดังนั้น Langchain จึงเพิ่มโซ่และรุ่นพิเศษ
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])เราจะเห็นว่าเขาสามารถตอบคำถามและคำตอบได้อย่างแม่นยำเกี่ยวกับวิดีโอท่อน้ำมันนี้

คำตอบการสตรีมก็สะดวกมาก
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ()) เราใช้ zapier เป็นหลักในการเชื่อมต่อเครื่องมือนับพัน
ดังนั้นขั้นตอนแรกของเราคือการสมัครบัญชีและคีย์ API ภาษาธรรมชาติ https://zapier.com/l/natural-language-actions
คีย์ API ของเขาจำเป็นต้องกรอกข้อมูลในแอปพลิเคชันข้อมูล อย่างไรก็ตามหลังจากกรอกข้อมูลโดยทั่วไปคุณสามารถเห็นอีเมลที่ได้รับอนุมัติในที่อยู่อีเมลในไม่กี่วินาที
จากนั้นเราเปิดหน้าการกำหนดค่า API ของเราโดยคลิกขวาที่การเชื่อมต่อ เราคลิก Manage Actions ทางด้านขวาเพื่อกำหนดค่าแอปพลิเคชันที่เราต้องการใช้
ฉันได้กำหนดค่าการกระทำของ Gmail เพื่ออ่านและส่งอีเมลที่นี่และการเลือกฟิลด์ทั้งหมดโดย AI คาดเดา
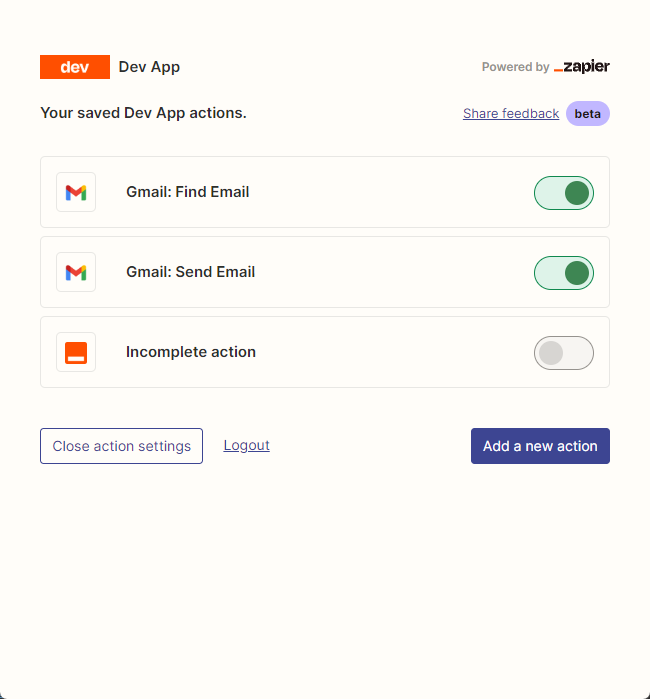
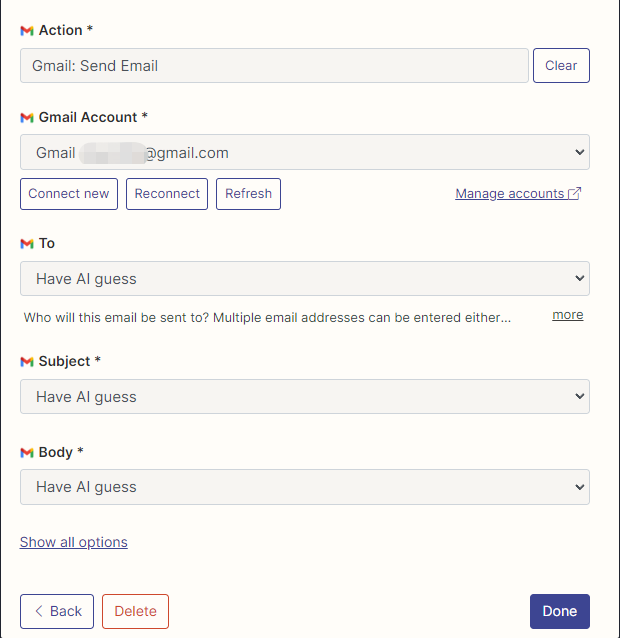
หลังจากการกำหนดค่าเสร็จสมบูรณ์เราเริ่มเขียนโค้ด
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
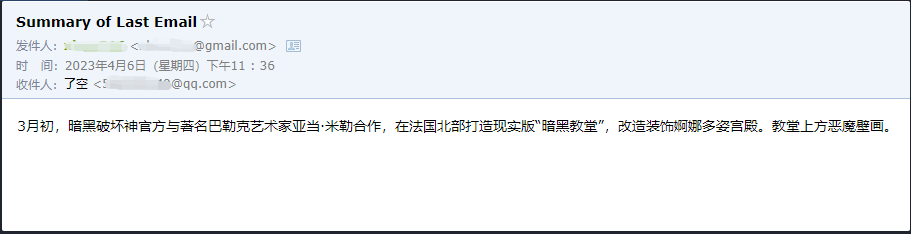
เราจะเห็นได้ว่าเขาอ่านอีเมลฉบับล่าสุดที่ส่งถึงเขาโดย ******@qq.com และส่งเนื้อหาสรุปไปที่ ******@qq.com อีกครั้ง
นี่คืออีเมลที่ฉันส่งไปยัง Gmail

นี่คืออีเมลที่เขาส่งไปยังอีเมล QQ ของเขา
นี่เป็นเพียงตัวอย่างเล็ก ๆ น้อย ๆ เนื่องจาก zapier มีแอพพลิเคชั่นนับพันดังนั้นเราจึงสามารถสร้างเวิร์กโฟลว์ของเราเองด้วย OpenAI API ได้อย่างง่ายดาย
บางจุดความรู้ที่ใหญ่กว่าได้รับการอธิบายและเนื้อหาต่อไปนี้ทั้งหมดเกี่ยวกับตัวอย่างเล็ก ๆ ที่น่าสนใจบางอย่างเป็นส่วนขยาย
เพราะมันถูกล่ามโซ่เขาจึงสามารถดำเนินการหลายโซ่ตามลำดับ
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )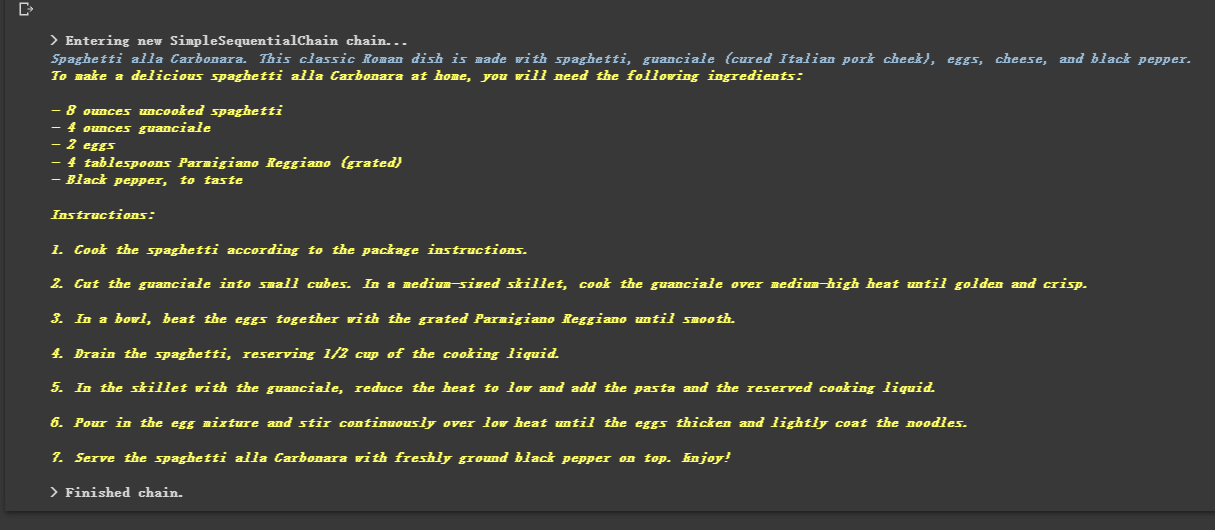
บางครั้งเราต้องการให้เอาต์พุตไม่ใช่ข้อความ แต่ข้อมูลที่มีโครงสร้างเช่น JSON
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
บางครั้งเราต้องคลานไปบ้าง โครงสร้างที่แข็งแกร่งขึ้น และข้อมูลในหน้าเว็บจะต้องส่งคืนในโหมด JSON
เราสามารถใช้คลาส LLMRequestsChain เพื่อนำไปใช้งานได้
เพื่อความเข้าใจที่ง่ายฉันใช้วิธีการแจ้งเตือนโดยตรงเพื่อจัดรูปแบบผลลัพธ์ผลลัพธ์ในตัวอย่าง แต่ไม่ได้ใช้
StructuredOutputParserที่ใช้ในกรณีก่อนหน้าเพื่อจัดรูปแบบซึ่งสามารถถือได้ว่าเป็นแนวคิดการจัดรูปแบบอื่น
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])เราจะเห็นว่าเขาส่งออกผลลัพธ์ที่จัดรูปแบบได้ดีมาก

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )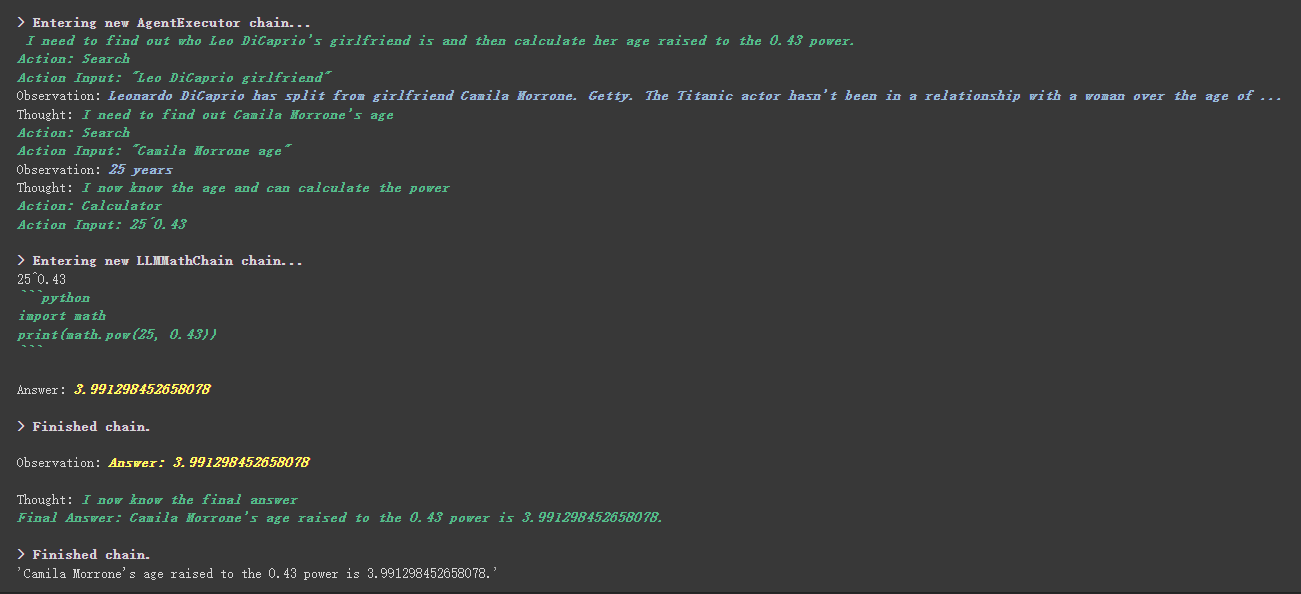
มีสิ่งที่น่า工具中描述内容มากขึ้นในเครื่องมือที่กำหนดเอง
ตัวอย่างเช่นเครื่องคิดเลขเขียนไว้ในคำอธิบายว่าหากคุณถามคำถามเกี่ยวกับคณิตศาสตร์ให้ใช้เครื่องมือนี้ เราสามารถเห็นได้ในกระบวนการดำเนินการข้างต้นว่าในส่วนคณิตศาสตร์ของ Propt ที่เราร้องขอเขาใช้เครื่องมือเครื่องคิดเลขสำหรับการคำนวณ
ในตัวอย่างก่อนหน้านี้เราใช้วิธีที่เราบันทึกประวัติโดยปรับแต่งรายการเพื่อจัดเก็บการสนทนา
แน่นอนคุณสามารถใช้วัตถุหน่วยความจำที่รวมอยู่เพื่อให้ได้สิ่งนี้
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )ก่อนที่จะใช้โมเดล Hugging Face คุณต้องตั้งค่าตัวแปรสภาพแวดล้อมก่อน
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''การใช้โมเดล Hugging Face Online
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))ดึงโมเดลใบหน้ากอดโดยตรงเพื่อใช้ในพื้นที่
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))ประโยชน์ของการดึงโมเดลเพื่อใช้ในพื้นที่:
เราสามารถใช้คำสั่ง SQL ผ่าน SQLDatabaseToolkit หรือ SQLDatabaseChain
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )ที่นี่คุณสามารถอ้างถึงเอกสารทั้งสองนี้:
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
ทุกกรณีสิ้นสุดลงโดยทั่วไป บทความนี้เป็นเพียงคำอธิบายเบื้องต้นของ Langchain
และเนื่องจาก Langchain วนซ้ำอย่างรวดเร็วมันจะทำซ้ำฟังก์ชั่นที่ดีกว่าเนื่องจาก AI ยังคงพัฒนาอย่างต่อเนื่องดังนั้นฉันจึงมองโลกในแง่ดีเกี่ยวกับไลบรารีโอเพนซอร์สนี้
ฉันหวังว่าทุกคนสามารถรวม Langchain เพื่อพัฒนาผลิตภัณฑ์ที่สร้างสรรค์มากขึ้นแทนที่จะสร้างผลิตภัณฑ์มากมายที่สร้างลูกค้าแชทด้วยการคลิกเดียว
ฉันเพิ่ม 01 หลังจากชื่อนี้
รหัสตัวอย่างทั้งหมดในบทความนี้อยู่ที่นี่ฉันขอให้คุณมีความสุขในการเรียนรู้
https://colab.research.google.com/drive/1arrvmis-ykhulobhru6bes8ff57Ueapq?usp=sharing


