LangChain Chinese Getting Started Guide
1.0.0
쉽게 읽을 수 있도록 gitbooks가 생성되었습니다 : https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
github 주소 : https://github.com/liaokongvfx/langchain-chinese-getting-started-guide
"Langchain 기술 암호 해독 : 대형 모델 응용 프로그램 구축에 대한 파노라마 가이드"가 지금 게시되었습니다 : https://item.jd.com/14598210.html
저렴한 국내 및 외국 AI 모델 API 전송 : https://api.91ai.me
Langchain 라이브러리가 빠르게 업데이트되고 반복되었지만 문서는 4 월 초에 작성되었으며 개인 에너지가 제한되어 있으므로 Colab의 코드는 다소 구식 일 수 있습니다. 작동에 실패한 경우 먼저 문서가 업데이트되지 않은 경우 문제를 언급하거나 수리 후 PR을 직접 언급하십시오
ChangeLog를 추가하고 새 콘텐츠를 업데이트하여 이전에 읽은 친구들이 새로운 업데이트 된 콘텐츠를 빠르게 볼 수 있습니다.
OpenAI API의 요청 루트 루트를 자신의 프록시 주소로 수정하려면 환경 변수 "OpenAI_API_Base"를 설정하여 수정할 수 있습니다.
관련 참조 코드 : https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0ddd2e9251b375d7070bbef1/openai/__init__.py#l48
또는 OpenAI 관련 모델 객체를 초기화 할 때 "OpenAI_API_BASE"변수를 전달하십시오.
관련 참조 코드 : https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
우리 모두 알다시피, OpenAi의 API는 인터넷에 연결될 수 없으므로 자체 기능을 사용하여 답변을 제공하고 PDF 문서를 요약하고 YouTube 비디오를 기반으로 Q & A를 수행하는 것은 불가능합니다. 따라서 매우 강력한 타사 오픈 소스 라이브러리 인 LangChain 소개하겠습니다.
문서 주소 : https://python.langchain.com/en/latest/
이 라이브러리는 현재 매우 활동적이며 이미 22K 별이 있으며 업데이트 속도는 매우 빠릅니다.
Langchain은 언어 모델로 구동되는 응용 프로그램을 개발하기위한 프레임 워크입니다. 그는 두 가지 주요 능력을 가지고 있습니다.
LLM 모델 : 대형 언어 모델, 대형 언어 모델
LLM 전화
프롬프트 관리는 다양한 사용자 정의 템플릿을 지원합니다
이메일, Markdown, PDF, YouTube와 같은 많은 문서 로더가 있습니다.
인덱스 지원
쇠사슬
위의 소개를 읽은 후 모든 사람이 혼란 스러울 것이라고 믿습니다. 걱정하지 마십시오. 위의 개념은 실제로 학습을 시작한 후에는 위의 내용을 되돌아 볼 때 많은 것을 이해할 것입니다.
그러나 여기에 알려진 몇 가지 개념이 있습니다.
이름에서 알 수 있듯이 지정된 소스에서 데이터를로드하는 것입니다. 예를 들면 : 폴더 DirectoryLoader , Azure Storage AzureBlobStorageContainerLoader , CSV 파일 CSVLoader , Evernote EverNoteLoader , Google GoogleDriveLoader , 모든 웹 페이지 UnstructuredHTMLLoader , PDF PyPDFLoader , S3 S3DirectoryLoader / S3FileLoader ,
YouTube YoutubeLoader 등, 나는 그 중 일부를 간단히 나열했습니다.
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
로더 로더를 사용하여 데이터 소스를 읽은 후에는 데이터 소스를 나중에 사용하기 전에 문서 개체로 변환해야합니다.
이름에서 알 수 있듯이 텍스트 분할은 텍스트를 나누는 데 사용됩니다. 텍스트를 분할 해야하는 이유는 무엇입니까? OpenAI API 또는 OpenAI API 임베딩 기능을 사용하기 위해 propt로 텍스트를 보낼 때마다 문자 제한이 있습니다.
예를 들어, 우리가 300 페이지 PDF를 OpenAI API에 보내고 요약 해달라고 요청하면, 그는 최대 토큰을 초과하는 실수를 확실히보고 할 것입니다. 따라서 로더가 들어오는 문서를 분할하려면 텍스트 스플리터를 사용해야합니다.
데이터 상관 관계 검색은 실제로 벡터 작동이기 때문입니다. 따라서 OpenAI API 임베딩 기능을 사용하든 벡터 데이터베이스를 통해 직접 쿼리하든 벡터 작동 검색을 수행하려면로드 된 데이터 Document 벡터화해야합니다. 벡터로 변환하는 것도 매우 간단합니다. 벡터의 변환을 완료하기 위해 해당 벡터 데이터베이스에 데이터를 저장하면됩니다.
공무원은 또한 우리가 사용할 수있는 많은 벡터 데이터베이스를 제공합니다.
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
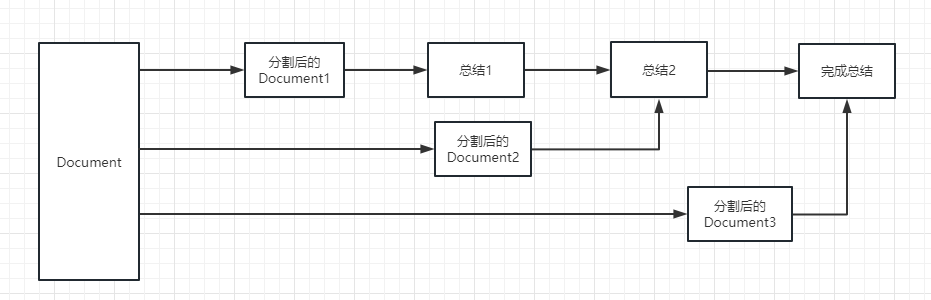
우리는 체인을 작업으로 이해할 수 있습니다. 체인은 작업이며 물론 체인처럼 여러 체인을 하나씩 실행할 수도 있습니다.
체인 또는 기존 도구를 선택하고 호출하는 데 동적으로 도움이 될 수 있다는 것을 간단히 이해할 수 있습니다.
실행 프로세스는 다음 그림을 참조하십시오.
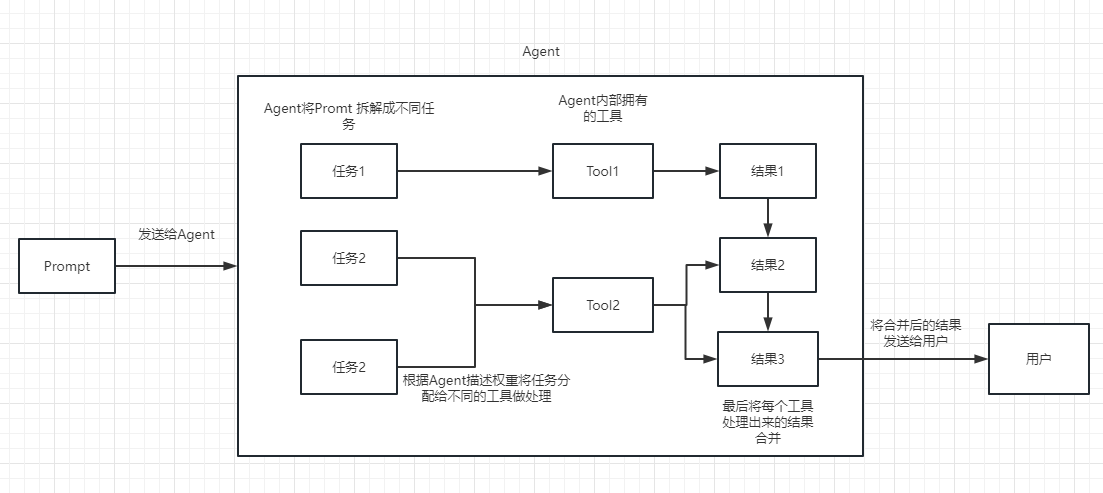
텍스트의 관련성을 측정하는 데 사용됩니다. 이것은 또한 OpenAI API가 자체 지식 기반을 구축하는 능력의 열쇠입니다.
미세 조정에 비해 그의 가장 큰 장점은 새로운 콘텐츠를 한 번 추가하는 대신 훈련 할 필요가 없으며 실시간으로 새로운 콘텐츠를 추가 할 수 있다는 것입니다. 모든 측면의 비용은 미세 조정보다 훨씬 낮습니다.
구체적인 비교 및 선택은이 비디오를 참조하십시오 : https://www.youtube.com/watch?v=9qq6htr7ocw
위의 필수 개념을 통해 Langchain에 대한 특정 이해를 가져야하지만 여전히 약간 혼란 스러울 수 있습니다.
이것들은 모두 작은 질문입니다. 실제 전투를 읽은 후에는 위의 내용을 철저히 이해 하고이 도서관의 진정한 힘을 느낄 것입니다.
OpenAI API는 고급이므로 후속 예제에 사용 된 LLM은 모두 Open AI를 기반으로합니다.
물론이 기사의 끝에서 모든 코드는 Colab IPYNB 파일로 저장되고 모든 사람이 배울 수 있도록 제공됩니다.
다음 예제는 이전 예제에서 지식 지점을 사용하기 때문에 각 예제를 순서대로 보는 것이 좋습니다.
물론, 무언가를 이해하지 못하면 걱정하지 마십시오.
첫 번째 경우 Langchain을 사용하여 OpenAI 모델을로드하고 Q & A를 완료합니다.
시작하기 전에 OpenAI 키를 먼저 설정해야합니다.이 키는 사용자 관리에서 생성 할 수 있습니다.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'그런 다음 가져오고 실행합니다
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
이때 우리는 그가 우리에게 준 결과를 볼 수 있습니다.
다음으로 흥미로운 일을하겠습니다. OpenAI API를 온라인으로 검색하고 답변을 반환하도록합시다.
여기서 Google 검색을위한 API 인터페이스를 제공하는 Serpapi를 사용하여 구현해야합니다.
먼저 Serpapi 공식 웹 사이트 https://serpapi.com/에 사용자를 등록하고 복사하여 API 키를 생성해야합니다.
그런 다음 위의 OpenAI API 키와 같은 환경 변수로 설정해야합니다.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'그런 다음 내 코드를 작성하십시오
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )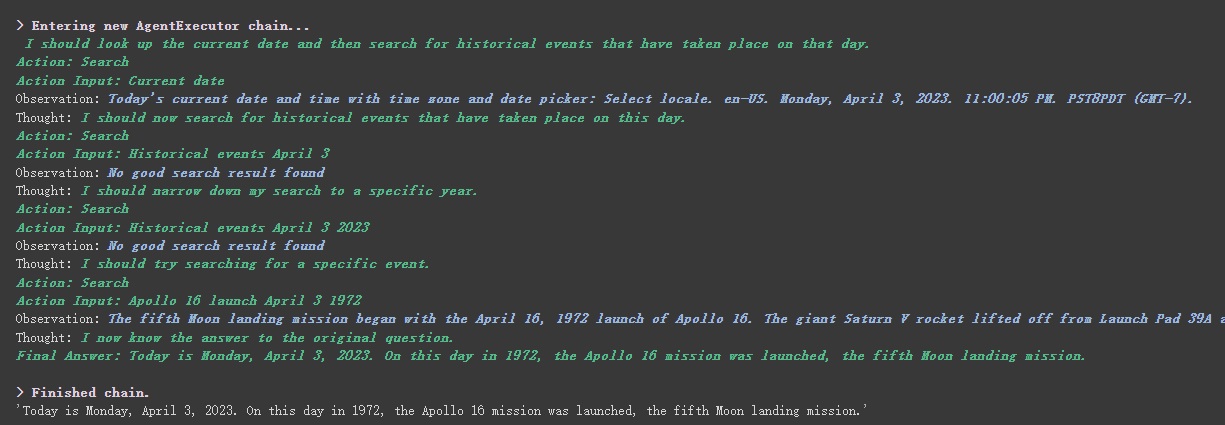
우리는 그가 날짜 (때로는 차이)를 올바르게 반환하고 역사상 오늘으로 돌아 왔음을 알 수 있습니다.
체인 및 에이전트 객체에 매개 verbose 가 있습니다. 이것은 매우 유용한 매개 변수입니다.
위에서 반환 된 결과에서 볼 수 있듯이, 그는 우리의 질문을 여러 단계로 나누고 최종 답변을 단계별로 얻습니다.
에이전트 유형에 대한 여러 옵션의 의미와 관련하여 (이해할 수 없다면 다음 학습에 영향을 미치지 않습니다. 너무 많이 사용하면 자연스럽게 이해하게됩니다).
Search 및 Lookup 도구를 사용하십시오. 전자는 검색에 사용되며 후자는 예를 들어 Wipipedia TOOL을 찾는 데 사용됩니다.Google search API 텍스트에 포함).https://arxiv.org/pdf/2210.03629.pdf에 대해서는이 내용을 볼 수 있습니다
LLM의 반응 패턴의 Python 구현 : https://til.simonwillison.net/llms/python-react-pattern
에이전트 유형 공식 설명 :
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-react-description
주목할만한 점은이
serpapi중국어에 그다지 친숙하지 않은 것처럼 보이므로 영어를 사용하는 것이 좋습니다.
물론 공무원은 ChatGPT Plugins 의 에이전트를 작성했습니다.
그러나 현재 승인이 필요없는 플러그인 만 사용될 수 있습니다.
관심있는 사람들은이 문서를 읽을 수 있습니다 : https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
Chatgpt는 공무원을 위해서만 돈을 벌 수 있으며 OpenAi API는 나를 위해 돈을 벌 수 있습니다.
OpenAI API를 사용하여 텍스트 단락을 요약하려면 일반적인 방법은 요약하기 위해 API로 직접 보내는 것입니다. 그러나 텍스트가 API의 최대 토큰 한계를 초과하면 오류 가보고됩니다.
이 시점에서, 우리는 일반적으로 Tiktoken을 통해 계산 및 나누기와 같은 기사를 세분화 한 다음 각 단락을 API로 보내 요약하고 마지막으로 각 단락의 요약을 요약합니다.
Langchain을 사용하는 경우, 그는이 과정을 잘 처리하는 데 도움이되었으므로 코드를 작성하기가 매우 쉽습니다.
더 이상 고민하지 않고 코드를 업로드하십시오.
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
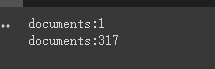
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])먼저, 절단 전에 문서의 수를 인쇄 할 수 있습니다.
마지막으로, 처음 5 문서의 요약은 출력입니다.

다음은 몇 가지 매개 변수입니다.
텍스트 스플리터의 chunk_overlap 매개 변수
이는 절단 후 각 문서에서 여러 이전 문서로 끝나는 내용을 말합니다. 예 chunk_overlap=2 들어, chunk_overlap=0 인 경우 첫 번째 문서는 aaaaaaa이고, 두 번째 문서는 bbbbbb입니다.
그러나 이것은 절대적이지 않으며 사용 된 텍스트 세분화 모델 내부의 특정 알고리즘에 따라 다릅니다.
텍스트 스플리터에 대해서는이 문서를 참조 할 수 있습니다 : https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
체인의 chain_type 매개 변수
이 매개 변수는 주로 문서가 LLM 모델로 전달되는 방식을 제어하며 총 4 가지 방법이 있습니다.
stuff : 이것은 가장 간단하고 조잡하며 요약을 위해 모든 문서를 한 번에 LLM 모델로 전달합니다. 문서가 많이있는 경우 필연적으로 최대 토큰 제한을 초과하는 오류를보고하므로 텍스트를 요약 할 때 일반적으로 선택되지 않습니다.
map_reduce :이 방법은 먼저 각 문서를 요약하고 마지막으로 모든 문서에서 요약 된 결과를 요약합니다.
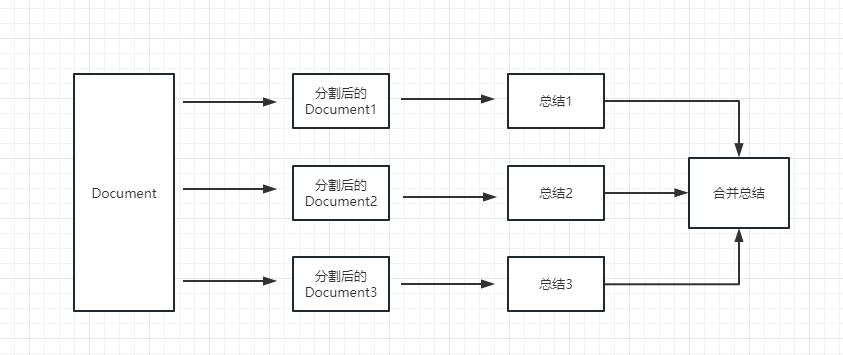
refine :이 메소드는 먼저 첫 번째 문서를 요약 한 다음 첫 번째 문서와 두 번째 문서에서 요약 된 내용을 LLM 모델로 보냅니다. 이 방법의 장점은 후자의 문서를 요약 할 때 이전 문서가 요약되어 요약 해야하는 문서에 컨텍스트를 추가하고 요약 내용의 일관성을 높이는 것입니다.
map_rerank :이 유형의 체인은 일반적으로 요약되어 있지 않지만 실제로는 답변과 일치하는 방법입니다. 먼저 질문에 따라 질문에 답변하기 위해 각 문서에 대한 확률 점수를 계산 한 다음이 문서를 질문 (질문 + 문서)의 프롬프트로 변환하여 LLM 모델로 전송해야합니다.
이 예에서는 미국에서 여러 문서를 읽음으로써 지식 기반을 구축하는 방법을 설명하고 OpenAI API를 사용하여 지식 기반에서 답변을 제공합니다.
이것은 회사의 비즈니스를 쉽게 도입 할 수있는 로봇이나 제품을 소개하는 로봇과 같은 매우 유용한 튜토리얼입니다.
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )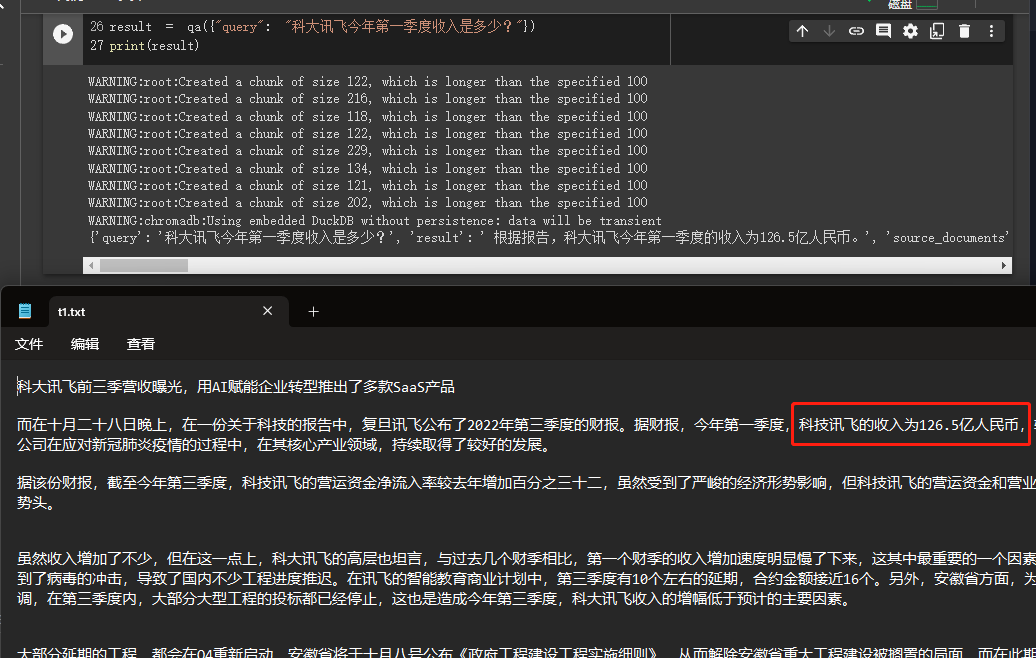
결과를 통해 그가 우리가 제공 한 데이터에서 정답을 성공적으로 얻었음을 알 수 있습니다.
OpenAi Embeddings에 대한 자세한 내용은이 링크를 참조하십시오 : https://platform.openai.com/docs/guides/embeddings
이전 사례의 한 단계는 문서 정보를 벡터 정보 및 임베딩 정보로 변환하여 일시적으로 Chroma 데이터베이스에 저장하는 것이 었습니다.
일시적으로 저장되므로 위의 코드가 실행되면 위의 벡터화 후 데이터가 손실됩니다. 다음에 그것을 사용하려면, 당신은 다시 임베딩을 계산해야합니다. 이것은 우리가 원하는 것이 아닙니다.
따라서이 경우 Chroma와 Pinecone의 두 데이터베이스를 통해 벡터 데이터를 지속하는 방법에 대해 이야기합니다.
Langchain은 많은 데이터베이스를 지원하기 때문에 자세한 내용은 다음과 같습니다. https://python.langchain.com/en/latest/modules/indexes/vectorstores/getting _started.html을 참조하십시오
크로마
Chroma는 로컬 벡터 데이터베이스로서 지속성을위한 영구 디렉토리를 설정하기 위해 persist_directory 제공합니다. 읽을 때로드하려면 from_document 메소드 만 호출하면됩니다.
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )피네콘
Pinecone은 온라인 벡터 데이터베이스입니다. 따라서 첫 번째 단계는 여전히 등록하고 해당 API 키를 얻을 수 있습니다. https://app.pinecone.io/
인덱스가 14 일 동안 사용되지 않으면 무료 버전이 자동으로 지워집니다.
그런 다음 데이터베이스를 작성하십시오.
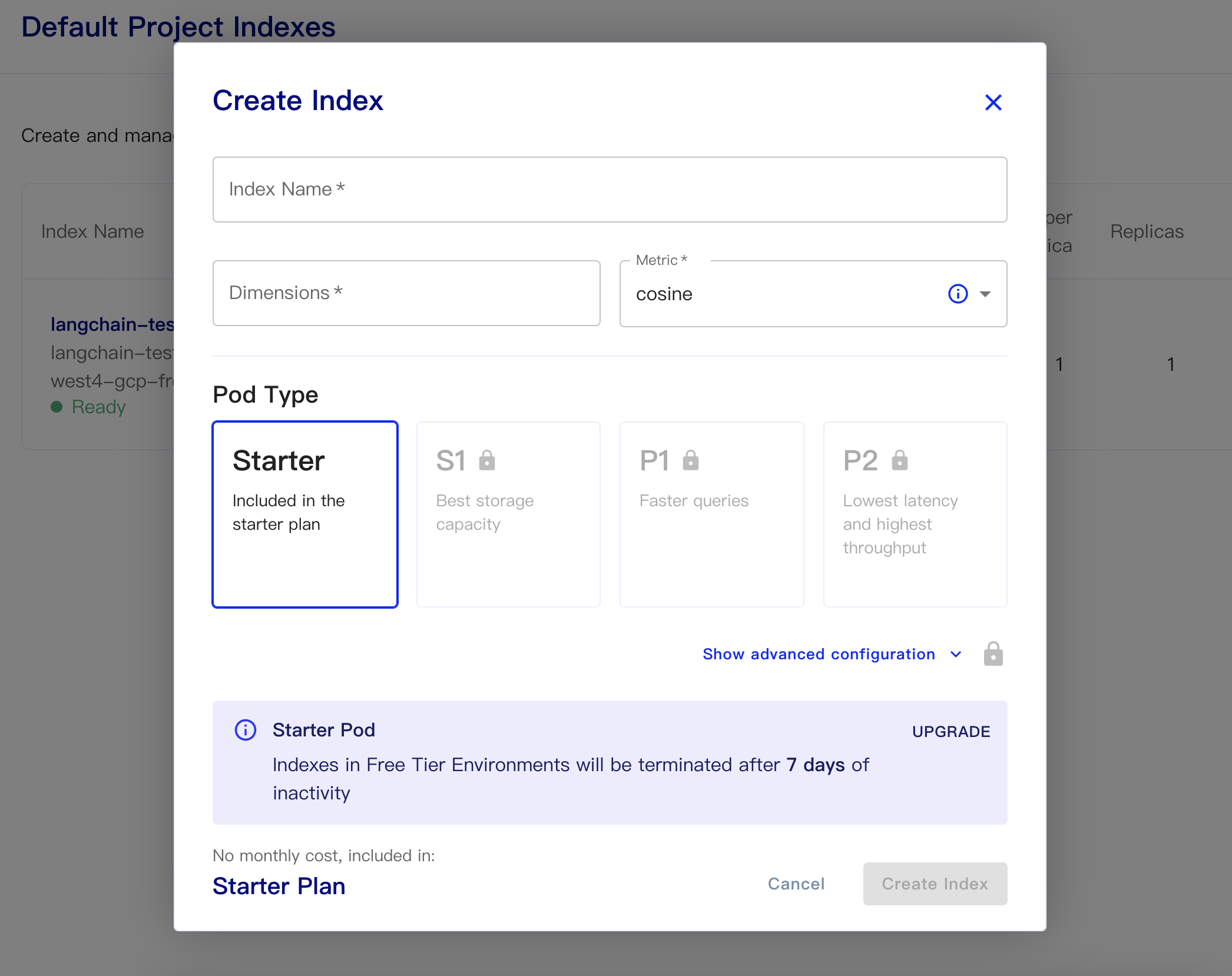
인덱스 이름 : 이것은 캐주얼합니다
치수 : OpenAi의 Text-embedding-ADA-002 모델은 출력 차원이 1536이므로 1536 년을 여기에 작성합니다.
메트릭 : 기본적으로 코사인에 기본값을받을 수 있습니다
스타터 계획을 선택하십시오
영구 데이터 및로드 데이터 코드는 다음과 같습니다.
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )데이터베이스에서 임베딩을 얻는 간단한 코드 및 답변은 다음과 같습니다.
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
Chatgpt API (즉, GPT-3.5-Turbo) 모델이 출시 된 후에는 돈이 적기 때문에 모든 사람에게 사랑을 받았기 때문에 Langchain 은이 예제와 모델을 추가하여 사용하는 방법을 확인하십시오.
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])우리는 그가이 오일 파이프 비디오에 대한 질문과 답변에 정확하게 답변 할 수 있음을 알 수 있습니다.

스트리밍 답변도 매우 편리합니다
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ()) 우리는 주로 zapier 사용하여 수천 개의 도구를 연결합니다.
따라서 첫 번째 단계는 계정과 자연어 API 키를 신청하는 것입니다. https://zapier.com/l/natural-language-action
그의 API 키는 정보 응용 프로그램을 작성해야합니다. 그러나 기본적으로 정보를 작성한 후 기본적으로 이메일 주소에서 승인 된 이메일을 몇 초 만에 볼 수 있습니다.
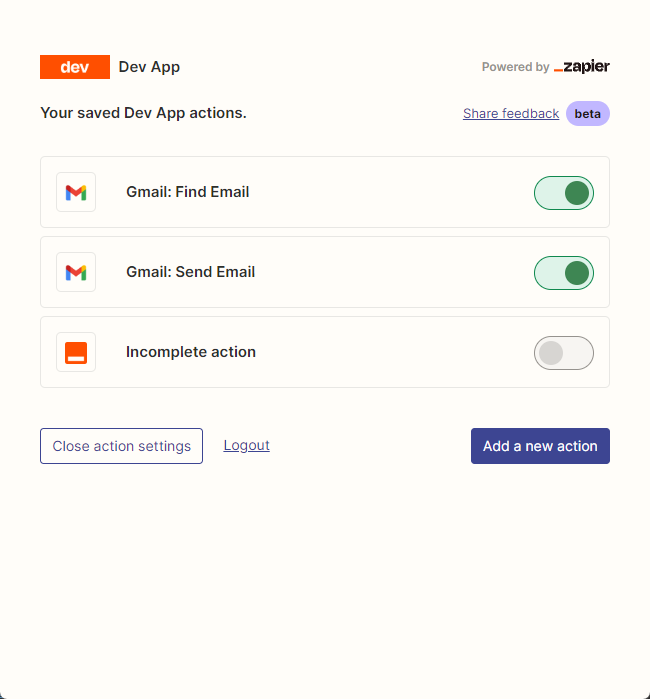
그런 다음 연결을 마우스 오른쪽 버튼으로 클릭하여 API 구성 페이지를 엽니 다. 사용하려는 응용 프로그램을 구성하기 위해 오른쪽의 Manage Actions 클릭합니다.
여기에서 이메일을 읽고 보내는 Gmail의 조치를 구성했으며 모든 필드는 AI 추측으로 선택됩니다.
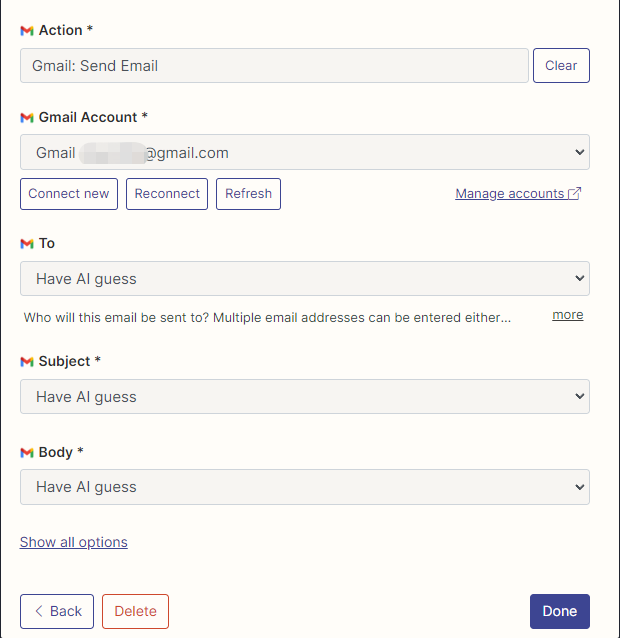
구성이 완료되면 코드 작성을 시작합니다
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
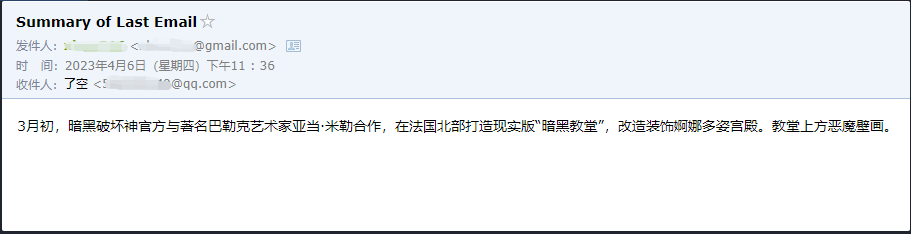
우리는 그가 그에게 보낸 마지막 이메일을 ******@qq.com 으로 성공적으로 읽고 요약 내용을 ******@qq.com 으로 다시 보냈다는 것을 알 수 있습니다.
이것은 내가 Gmail에 보낸 이메일입니다.

이것은 그가 QQ 이메일로 보낸 이메일입니다.
zapier 에는 수천 개의 응용 프로그램이 있으므로 OpenAI API로 자체 워크 플로우를 쉽게 구축 할 수 있기 때문에 이것은 작은 예일뿐입니다.
더 큰 지식 포인트 중 일부가 설명되었으며, 다음 내용은 확장으로서 흥미로운 작은 예제에 관한 것입니다.
묶여 있기 때문에 그는 여러 체인을 순서대로 실행할 수 있습니다.
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )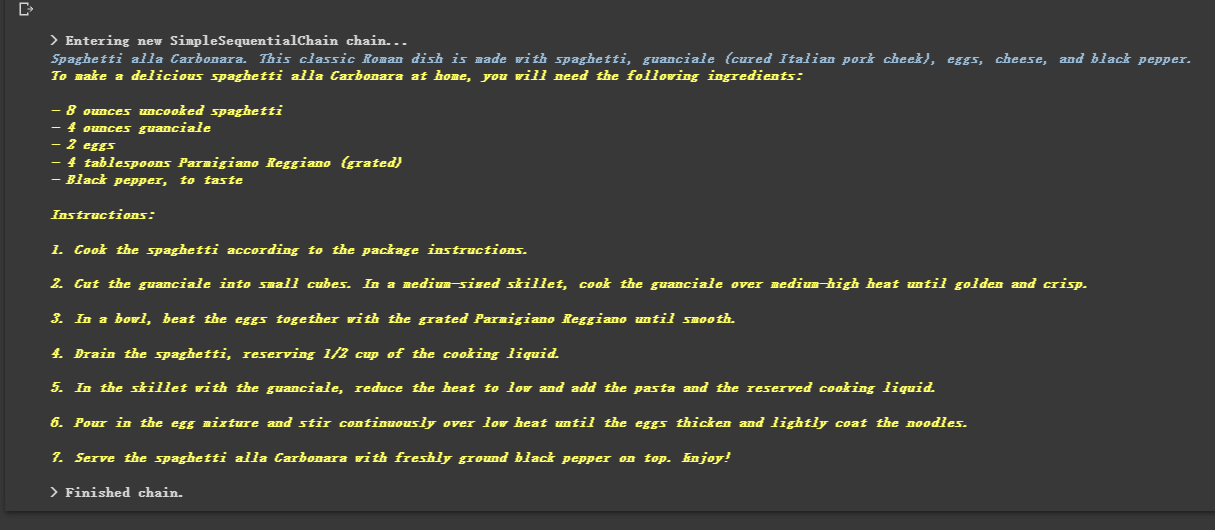
때때로 우리는 출력이 텍스트가 아니라 JSON과 같은 구조화 된 데이터가되기를 원합니다.
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
때때로 우리는 일부를 기어 다닐 필요가 있습니다 더 강한 구조 웹 페이지의 정보는 JSON 모드로 반환해야합니다.
LLMRequestsChain 클래스를 사용하여 자세한 내용은 다음 코드를 참조하십시오
쉽게 이해하기 위해 프롬프트 메소드를 직접 사용하여 예제에서 출력 결과를 형식화했지만 이전 경우에 사용 된
StructuredOutputParser사용하여 포맷하기 위해 다른 형식 아이디어를 제공하는 것으로 간주 될 수 있습니다.
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])우리는 그가 형식의 결과를 아주 잘 출력한다는 것을 알 수 있습니다.

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )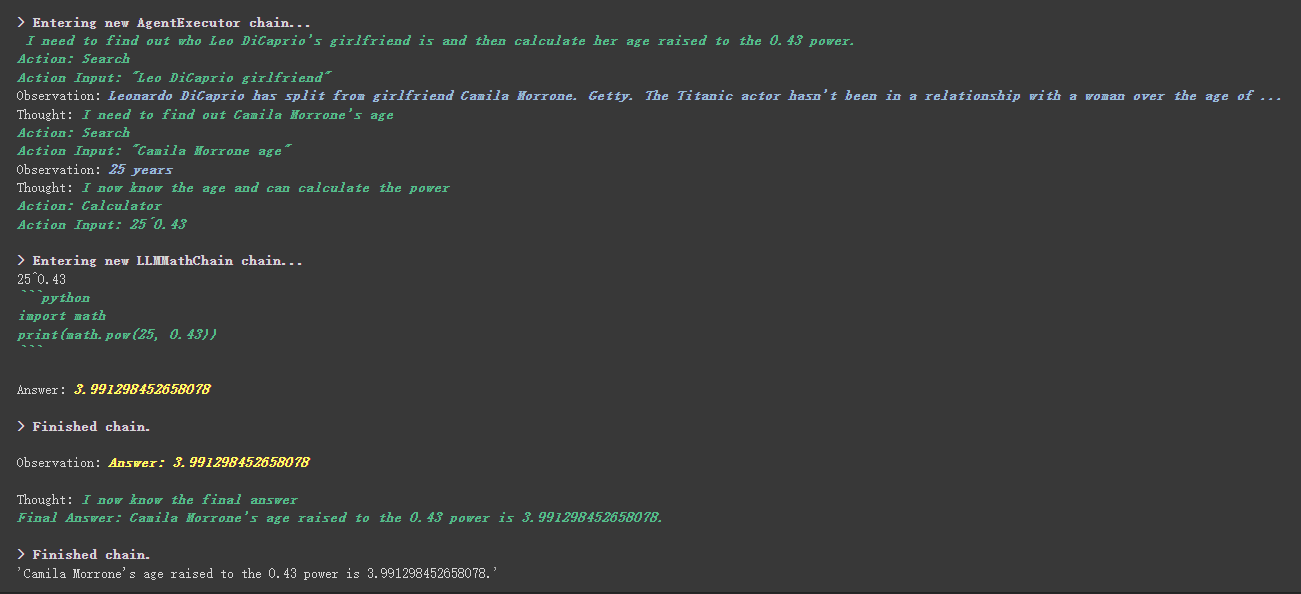
사용자 정의 도구에는 더 흥미로운 것이 있습니다.工具中描述内容기반으로 가중치를 달성하는 데 사용되는 도구가 있습니다.
예를 들어, 계산기는 설명에 수학에 대해 질문하면이 도구를 사용한다는 것을 썼습니다. 위의 실행 프로세스에서 요청 된 Propt의 수학 부분에서 계산기 도구를 사용하여 계산에 사용했음을 알 수 있습니다.
이전 예에서는 대화를 저장하기 위해 목록을 사용자 정의하여 역사를 저장하는 방식을 사용했습니다.
물론 포함 된 메모리 객체를 사용하여이를 달성 할 수도 있습니다.
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )Hugging Face 모델을 사용하기 전에 먼저 환경 변수를 설정해야합니다.
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''Hugging Face 모델 온라인 사용
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))포옹 페이스 모델을 직접 잡아 당겨 현지에서 사용하십시오
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))로컬에서 사용하도록 모델을 당기는 이점 :
SQLDatabaseToolkit 또는 SQLDatabaseChain 통해 SQL 명령을 구현할 수 있습니다
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )여기서는이 두 문서를 참조 할 수 있습니다.
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
모든 사례는 기본적으로 끝났습니다. 이 기사는 단지 Langchain에 대한 예비 설명입니다.
Langchain은 매우 빠르게 반복되기 때문에 AI가 계속 발전함에 따라 더 나은 기능을 반복 할 것이므로이 오픈 소스 라이브러리에 대해 매우 낙관적입니다.
모든 사람이 Langchain을 결합하여 한 번의 클릭으로 채팅 클라이언트를 구축하는 많은 제품을 만들기보다는 더 창의적인 제품을 개발할 수 있기를 바랍니다.
이 기사가 시작된 후에 01 더 나은 기술이 나중에 등장 할 수 있기를 바랍니다.
이 기사의 모든 샘플 코드는 여기에 있습니다. 나는 당신에게 행복한 학습을 기원합니다.
https://colab.research.google.com/drive/1arrvmis-ykhulobhru6bes8ff57ueapq?usp=sharing


