LangChain Chinese Getting Started Guide
1.0.0
لسهولة القراءة ، تم إنشاء GitBooks: https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
عنوان github: https://github.com/liaokongvfx/langchain-chinese-getting-started-guide
تم نشر "Langchain Technology Decryption: دليل بانورامي لبناء تطبيقات نموذجية كبيرة": https://item.jd.com/14598210.html
نقل واجهة برمجة التطبيقات المنزلية المنزلية والأجنبية ذات الأسعار المنخفضة: https://api.91ai.me
نظرًا لأن مكتبة Langchain قد تم تحديثها بسرعة وتكرارها ، لكن الوثيقة مكتوبة في أوائل أبريل ، ولدي طاقة شخصية محدودة ، لذلك قد يكون الكود في كولاب قديمًا إلى حد ما. إذا كان هناك أي فشل في التشغيل ، فيمكنك أولاً البحث عن المستند الحالي
أضفت changelog وقمت بتحديث المحتوى الجديد.
إذا كنت ترغب في تعديل مسار جذر الطلب في API Openai إلى عنوان الوكيل الخاص بك ، فيمكنك تعديله عن طريق ضبط متغير البيئة "Openai_API_Base".
رمز المرجعي ذي الصلة: https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbef1/openai/__init__.py#l48
أو عند تهيئة كائنات النموذج المتعلقة بـ OpenAI ، مرر بمتغير "OpenAI_API_BASE".
رمز المرجع ذي الصلة: https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
كما نعلم جميعًا ، لا يمكن توصيل واجهة برمجة تطبيقات Openai بالإنترنت ، لذلك من المستحيل بالتأكيد استخدام وظائفه الخاصة للبحث وإعطاء الإجابات ، وتلخيص مستندات PDF ، وأداء سؤال وجواب بناءً على فيديو على YouTube. لذلك ، دعونا نقدم مكتبة قوية للغاية لجهة خارجية مفتوحة المصدر: LangChain .
عنوان المستند: https://python.langchain.com/en/latest/
هذه المكتبة حاليًا نشطة للغاية وتتكرر كل يوم.
Langchain هو إطار لتطوير التطبيقات التي تعمل بنماذج اللغة. لديه قدرتان رئيسيتان:
نموذج LLM: نموذج لغة كبير ، نموذج لغة كبير
مكالمة LLM
الإدارة السريعة ، تدعم قوالب مخصصة مختلفة
إنه يحتوي على عدد كبير من لوادر المستندات ، مثل البريد الإلكتروني ، والتنسيق ، و PDF ، و YouTube ...
دعم الفهارس
السلاسل
أعتقد أن الجميع سيتم الخلط بينهم بعد قراءة المقدمة أعلاه. لا تقلق ، فإن المفهوم أعلاه ليس مهمًا جدًا عندما بدأنا التعلم لأول مرة.
ومع ذلك ، إليك العديد من المفاهيم التي يجب أن تكون معروفة.
كما يوحي الاسم ، هذا هو تحميل البيانات من مصدر محدد. على سبيل المثال: DirectoryLoader المجلد ، Azure Storage AzureBlobStorageContainerLoader ، ملف CSV CSVLoader ، Evernote EverNoteLoader ، Google GoogleDriveLoader ، أي صفحة ويب UnstructuredHTMLLoader ، PDF PyPDFLoader ، S3 S3DirectoryLoader / S3FileLoader ،
YouTube YoutubeLoader ، وما إلى ذلك ، لقد أدرجت لفترة وجيزة عدد قليل منها.
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
بعد قراءة مصدر البيانات باستخدام Loader Loader ، يجب تحويل مصدر البيانات إلى كائن مستند قبل استخدامه لاحقًا.
كما يوحي الاسم ، يتم استخدام تجزئة النص لتقسيم النص. لماذا تحتاج إلى تقسيم النص؟ لأنه في كل مرة نرسل فيها نصًا كـ propt إلى Openai API أو استخدام وظيفة تضمين API OpenAI ، هناك قيود على الأحرف.
على سبيل المثال ، إذا أرسلنا PDF من 300 صفحة إلى API Openai واطلب منه تلخيصه ، فسيقوم بالتأكيد بالإبلاغ عن خطأ يتجاوز الحد الأقصى للرمز. لذا ، نحتاج هنا إلى استخدام فاصل نص لتقسيم المستند الذي يأتي فيه المحمل الخاص بنا.
لأن بحث ارتباط البيانات هو في الواقع عملية متجه. لذلك ، سواء كنا نستخدم وظيفة تضمين API Openai أو الاستعلام مباشرة من خلال قاعدة بيانات المتجه ، نحتاج إلى زيادة Document البيانات المحملة من أجل إجراء البحث في تشغيل المتجه. التحويل إلى ناقل بسيط للغاية.
يوفر المسؤول أيضًا الكثير من قواعد بيانات المتجهات التي نستخدمها.
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
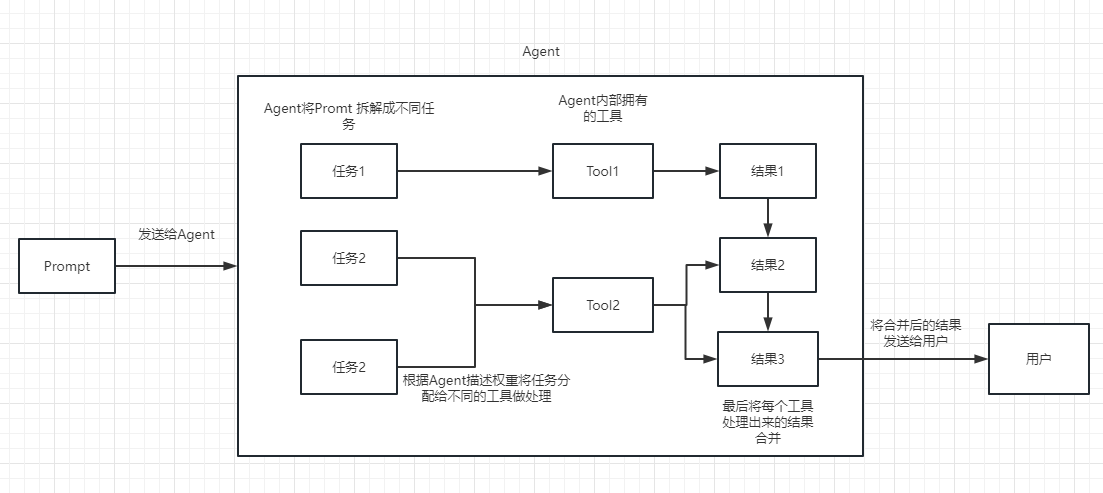
يمكننا أن نفهم السلسلة كمهمة. السلسلة هي مهمة ، وبالطبع يمكنها أيضًا تنفيذ سلاسل متعددة واحدة تلو الأخرى مثل سلسلة.
يمكننا ببساطة أن نفهم أنه يمكن أن يساعدنا بشكل ديناميكي في اختيار وسلسلة الاتصال أو الأدوات الموجودة.
لعملية التنفيذ ، يرجى الرجوع إلى الصورة التالية:
تستخدم لقياس أهمية النص. هذا هو أيضًا مفتاح قدرة Openai API على بناء قاعدة المعرفة الخاصة بها.
إن أكبر ميزة له على صقلها هي أنه لا يحتاج إلى التدريب ويمكنه إضافة محتوى جديد في الوقت الفعلي ، بدلاً من إضافة محتوى جديد مرة واحدة ، والتكلفة في جميع الجوانب أقل بكثير من الضبط.
للحصول على مقارنات وتحديدات محددة ، يرجى الرجوع إلى هذا الفيديو: https://www.youtube.com/watch؟v=9QQ6HTR7OCW
من خلال المفاهيم الأساسية المذكورة أعلاه ، يجب أن يكون لديك فهم معين لـ Langchain ، ولكن قد تظل في حيرة من أمري.
هذه كلها أسئلة صغيرة.
نظرًا لأن API Openai متطورة ، فإن LLM المستخدمة في أمثلةنا اللاحقة تعتمد على AI مفتوحًا.
بالطبع ، في نهاية هذه المقالة ، سيتم حفظ جميع الكود كملف Colab IPYNB ومنصته على الجميع أن يتعلموا.
يوصى بأن تنظر إلى كل مثال بالترتيب ، لأن المثال التالي سيستخدم نقاط المعرفة في المثال السابق.
بالطبع ، إذا كنت لا تفهم شيئًا ، فلا تقلق.
في الحالة الأولى ، سوف نستخدم Langchain لتحميل نموذج Openai وإكمال سؤال وجواب.
قبل البدء ، نحتاج إلى إعداد مفتاح Openai أولاً.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'ثم نستورد وننفذ
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
في هذا الوقت ، يمكننا أن نرى النتيجة التي قدمها لنا.
بعد ذلك ، دعونا نفعل شيئًا مثيرًا للاهتمام. دعنا نحصل على API Openai للبحث عبر الإنترنت وإعادة الإجابات إلينا.
نحتاج هنا إلى استخدام Serpapi لتنفيذها ، والتي توفر واجهة API للبحث في Google.
أولاً ، نحتاج إلى تسجيل مستخدم على موقع Serpapi الرسمي ، https://serpapi.com/ ونسخه لإنشاء مفتاح API لنا.
ثم نحتاج إلى ضبطه في متغير البيئة مثل مفتاح API Openai أعلاه.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'ثم ابدأ في كتابة الكود الخاص بي
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )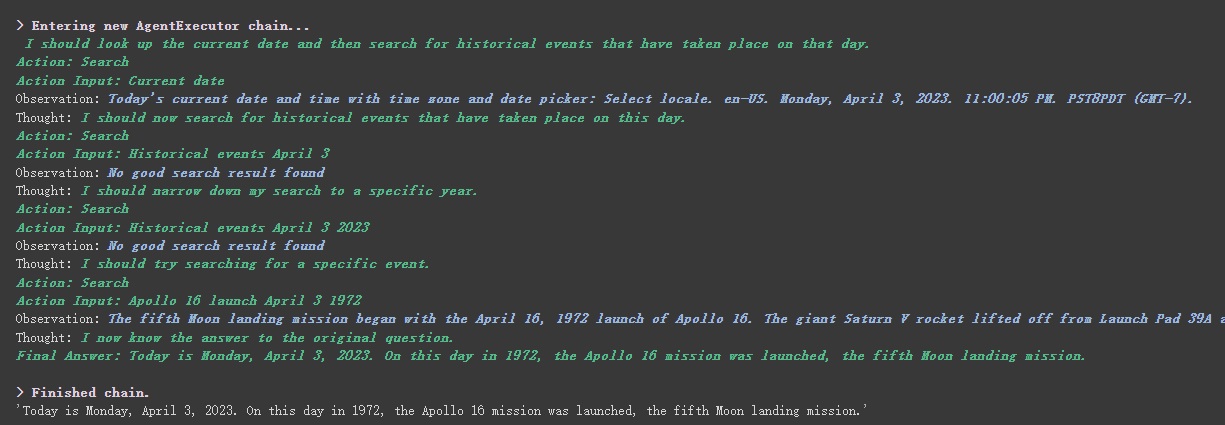
يمكننا أن نرى أنه أعاد التاريخ بشكل صحيح (الاختلاف في بعض الأحيان) وعاد إلى اليوم في التاريخ.
هناك معلمة verbose على كائنات السلسلة والوكيل.
كما ترون من النتيجة التي تم إرجاعها أعلاه ، يقسم سؤالنا إلى عدة خطوات ثم يحصل على الإجابة النهائية خطوة بخطوة.
فيما يتعلق بمعنى العديد من الخيارات لنوع الوكيل (إذا لم تتمكن من فهمه ، فلن يؤثر ذلك على التعلم التالي. إذا كنت تستخدمه كثيرًا ، فسوف تفهمه بشكل طبيعي):
Search Lookup ، ويستخدم الأول للبحث ، ويتم استخدام الأخير للعثور على المصطلح ، على سبيل المثال: أداة WipipediaGoogle search APIيمكنك رؤية هذا لمقدمة React: https://arxiv.org/pdf/2210.03629.pdf
Python تنفيذ نمط React من LLM: https://til.simonwillison.net/llms/python-react-patern
تفسير نوع الوكيل الرسمي:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html؟highlight=zero-shot-react-description
شيء واحد يجب الإشارة إليه هو أن هذا
serpapiلا يبدو ودودًا للغاية مع الصينيين ، لذلك يوصى باستخدام المطالبة باستخدام اللغة الإنجليزية.
بطبيعة الحال ، كتب المسؤول وكيل ChatGPT Plugins .
ومع ذلك ، في الوقت الحاضر ، يمكن استخدام المكونات الإدارية فقط التي لا تتطلب التفويض.
يمكن للمهتمين قراءة هذا المستند: https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
لا يمكن لـ ChatGPT كسب المال إلا للمسؤول ، ويمكن لـ Openai API كسب المال من أجلي
إذا أردنا استخدام API Openai لتلخيص فقرة نصية ، فإن طريقتنا المعتادة هي إرسالها مباشرة إلى واجهة برمجة التطبيقات لتلخيصها. ومع ذلك ، إذا تجاوز النص الحد الأقصى للرمز المميز لواجهة برمجة التطبيقات ، فسيتم الإبلاغ عن خطأ.
في هذا الوقت ، نقوم عمومًا بتقسيم المقالة ، مثل حسابها وتقسيمها عبر tiktoken ، ثم إرسال كل فقرة إلى واجهة برمجة التطبيقات للملخص ، وأخيراً تلخيص ملخص كل فقرة.
إذا كنت تستخدم Langchain ، فقد ساعدنا في التعامل مع هذه العملية بشكل جيد للغاية ، مما يجعل من السهل جدًا علينا كتابة التعليمات البرمجية.
دون مزيد من اللغط ، فقط قم بتحميل الرمز.
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])أولاً ، نطبع عدد المستندات قبل القطع وبعدها.
أخيرًا ، يتم إخراج ملخص للمستندات الخمس الأولى.

فيما يلي بعض المعلمات التي يجب ملاحظة:
المعلمة chunk_overlap من خائن النص
يشير هذا إلى المحتويات التي تنتهي بعدة وثيقة سابقة في كل وثيقة بعد القطع. على سبيل المثال ، عندما chunk_overlap=2 chunk_overlap=0 ، فإن المستند الأول هو aaaaaa ، والثاني هو bbbbbbb ؛
ومع ذلك ، هذا ليس مطلقًا ، فهو يعتمد على الخوارزمية المحددة داخل نموذج تجزئة النص المستخدم.
يمكنك الرجوع إلى هذا المستند الخاص بتقسيم النص: https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
معلمة chain_type من السلسلة
تتحكم هذه المعلمة بشكل أساسي في الطريقة التي يتم بها نقل المستند إلى نموذج LLM ، وهناك 4 طرق في المجموع:
stuff : هذا أبسط وخام ، وسيقوم بتمرير جميع المستندات إلى نموذج LLM مرة واحدة لملخص. إذا كان هناك العديد من المستندات ، فسيتم الإبلاغ حتما عن خطأ يتجاوز الحد الأقصى للرمز المميز ، لذلك لا يتم تحديد ذلك عمومًا عند تلخيص النص.
map_reduce : ستؤدي هذه الطريقة أولاً إلى تلخيص كل مستند ، وأخيراً تلخيص النتائج التي تلخصها جميع المستندات.
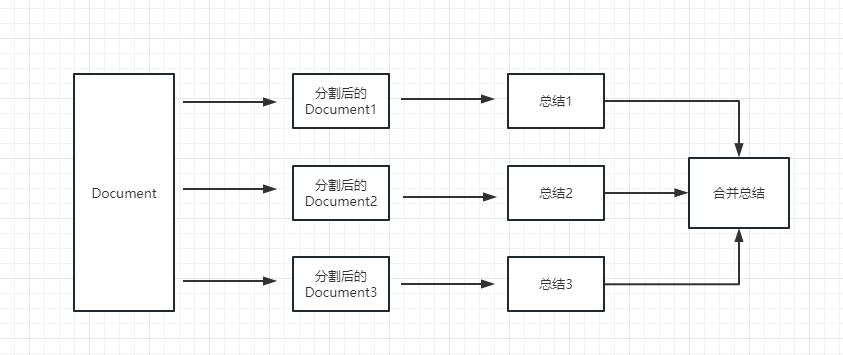
refine : ستلخص هذه الطريقة أولاً المستند الأول ، ثم إرسال المحتوى الذي تم تلخيصه بواسطة المستند الأول والوثيقة الثانية إلى نموذج LLM للحصول على ملخص ، وهكذا. ميزة هذه الطريقة هي أنه عند تلخيص المستند الأخير ، سيستغرق الأمر المستند السابق لتلخيصه ، وإضافة سياق إلى المستند الذي يجب تلخيصه ، وزيادة اتساق المحتوى الموجز.
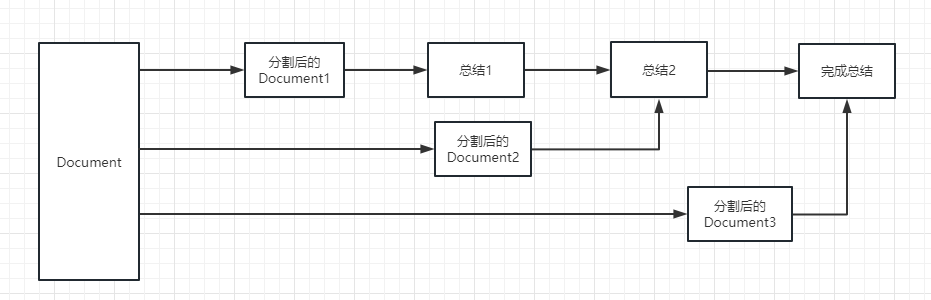
map_rerank : لا يتم استخدام هذا النوع من السلسلة بشكل عام ، ولكن في سلسلة الأسئلة وسلسلة الإجابة. أولاً ، تحتاج إلى تقديم سؤال.
في هذا المثال ، سنشرح كيفية إنشاء قاعدة للمعرفة من خلال قراءة مستندات متعددة منا محليًا واستخدام API Openai للبحث وإعطاء إجابات في قاعدة المعرفة.
هذا برنامج تعليمي مفيد للغاية ، مثل الروبوت الذي يمكنه بسهولة تقديم أعمال الشركة أو روبوت يقدم منتجًا.
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )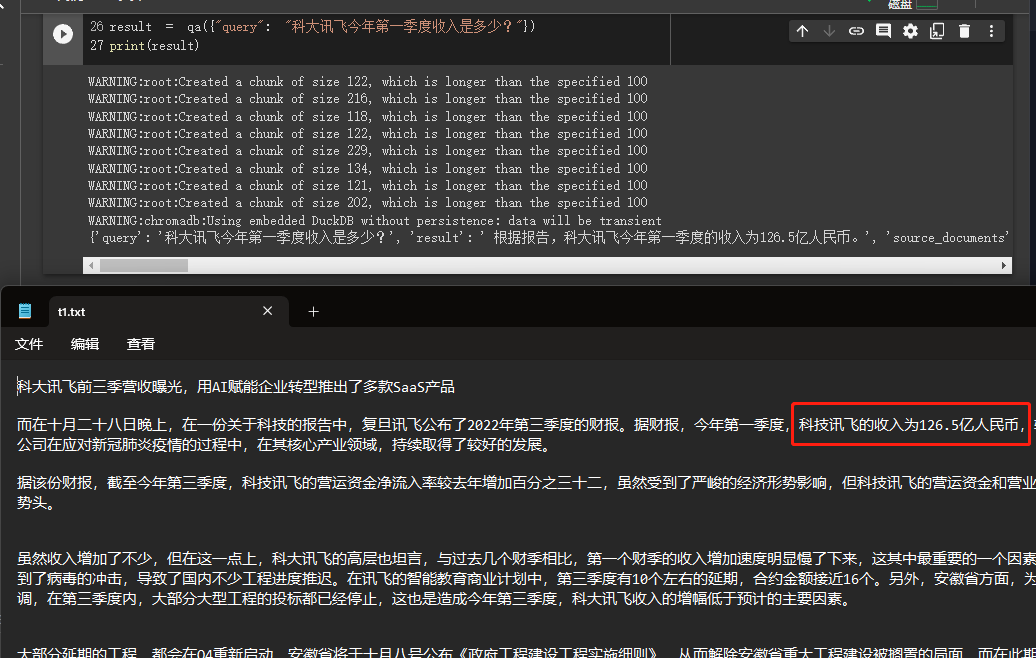
يمكننا أن نرى من خلال النتائج التي حصل عليها بنجاح الإجابة الصحيحة من البيانات التي قدمناها.
للحصول على تفاصيل حول Openai Opdedings ، يرجى الرجوع إلى هذا الرابط: https://platform.openai.com/docs/guides/embeddings
كانت خطوة واحدة في حالتنا السابقة هي تحويل معلومات المستند إلى معلومات المتجه وتضمين المعلومات وتخزينها مؤقتًا في قاعدة بيانات Chroma.
نظرًا لأنه يتم تخزينه مؤقتًا ، عند تنفيذ الكود أعلاه ، سيتم فقدان البيانات بعد التقييم أعلاه. إذا كنت ترغب في استخدامه في المرة القادمة ، فأنت بحاجة إلى حساب التضمين مرة أخرى ، وهذا بالتأكيد ليس ما نريد.
لذلك ، في هذه الحالة ، سوف نتحدث عن كيفية استمرار بيانات المتجهات من خلال قواعدتين من Chroma و Pinecone.
نظرًا لأن Langchain يدعم العديد من قواعد البيانات ، فهناك اثنان يستخدمان بشكل متكرر لمزيد من المعلومات.
Chroma
Chroma هي قاعدة بيانات متجه محلي ، والتي توفر persist_directory لتعيين الدليل المستمر للمثابرة. عند القراءة ، تحتاج فقط إلى الاتصال بالطريقة from_document لتحميلها.
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )كوز الصنوبر
Pinecone هي قاعدة بيانات متجه عبر الإنترنت. لذلك ، فإن الخطوة الأولى لا يزال بإمكاني التسجيل والحصول على مفتاح API المقابل. https://app.pinecone.io/
سيتم مسح الإصدار المجاني تلقائيًا إذا لم يتم استخدام الفهرس لمدة 14 يومًا.
ثم قم بإنشاء قاعدة البيانات الخاصة بنا:
اسم الفهرس: هذا غير رسمي
الأبعاد: طراز Openai-embedding-ada-002 هو أبعاد الإخراج هو 1536 ، لذلك نحن نملأ 1536 هنا
المقياس: يمكن أن تتخلف عن جيب التمام
حدد خطة بداية
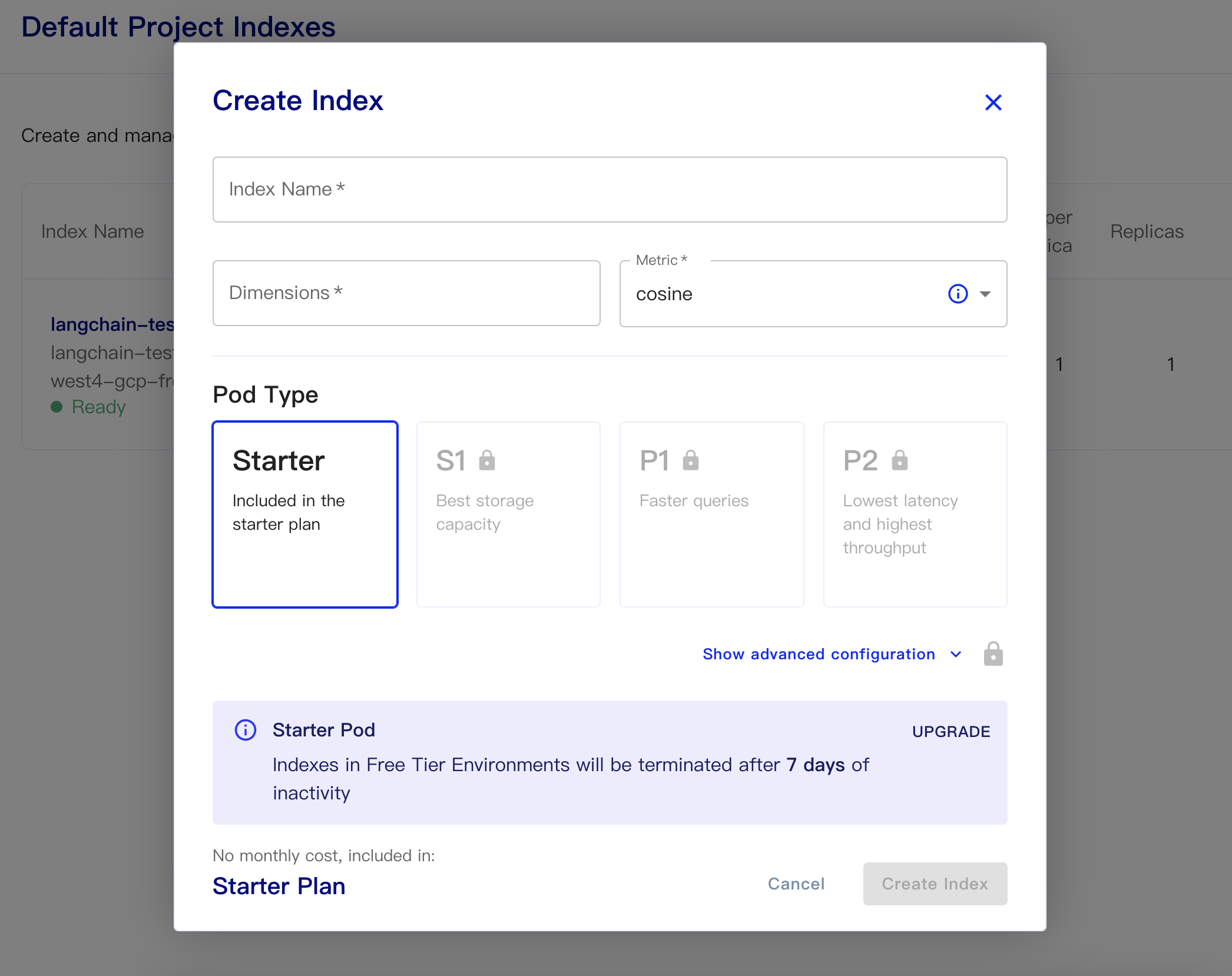
البيانات المستمرة ورموز البيانات هي كما يلي
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )رمز بسيط للحصول على التضمينات من قاعدة البيانات والإجابة عليه كما يلي
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
بعد إصدار طراز API ChatGPT (أي GPT-3.5-TURBO) ، كان محبوبًا من قبل الجميع لأنه كان أقل من المال ، لذلك أضاف Langchain أيضًا سلاسل ونماذج حصرية.
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])يمكننا أن نرى أنه يمكنه الإجابة بدقة على الأسئلة والإجابات حول فيديو أنابيب الزيت هذا

الإجابات المتدفقة هي أيضا مريحة للغاية
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ()) نحن نستخدم zapier بشكل أساسي لتوصيل الآلاف من الأدوات.
لذا فإن خطوتنا الأولى هي التقدم بطلب للحصول على حساب ومفتاح واجهة برمجة تطبيقات اللغة الطبيعية. https://zapier.com/l/natural-language-actions
يحتاج مفتاح API الخاص به إلى ملء تطبيق المعلومات. ومع ذلك ، بعد ملء المعلومات بشكل أساسي ، يمكنك رؤية البريد الإلكتروني المعتمد في عنوان البريد الإلكتروني في ثوانٍ.
بعد ذلك ، نفتح صفحة تكوين API الخاصة بنا عن طريق النقر بزر الماوس الأيمن على الاتصال. نضغط على Manage Actions على اليمين لتكوين التطبيقات التي نريد استخدامها.
لقد قمت بتكوين إجراءات Gmail لقراءة وإرسال رسائل بريد إلكتروني هنا ، ويتم اختيار جميع الحقول من خلال التخمين الذكاء الاصطناعي.
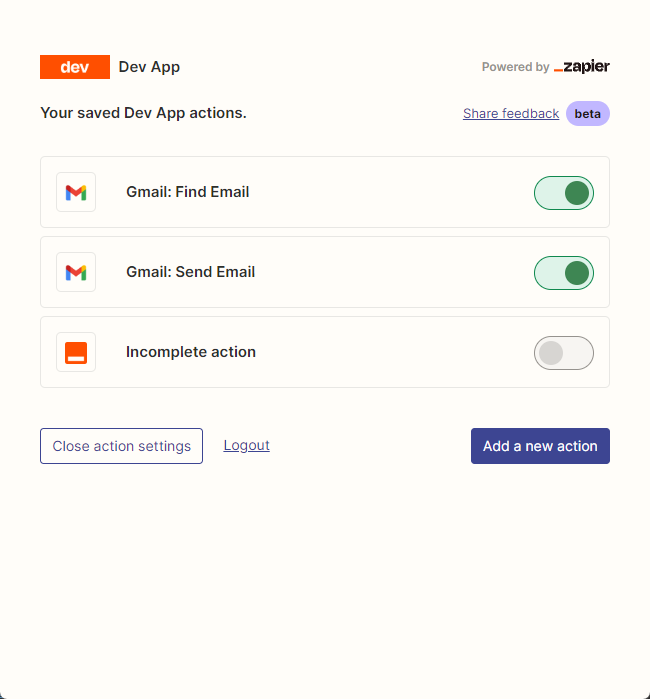
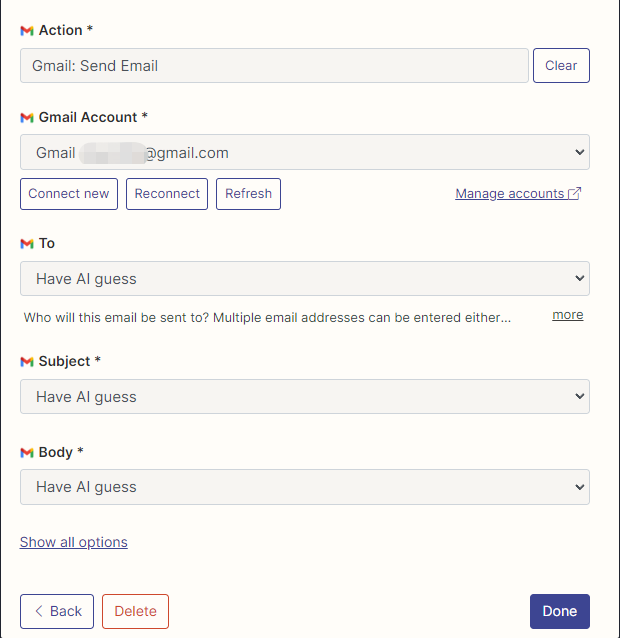
بعد اكتمال التكوين ، نبدأ في كتابة رمز
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
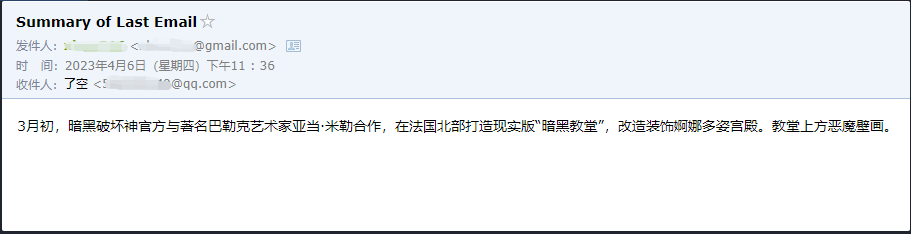
يمكننا أن نرى أنه بنجاح قراءة آخر بريد إلكتروني تم إرساله إليه بواسطة ******@qq.com وأرسل المحتوى الموجز إلى ******@qq.com مرة أخرى.
هذا هو البريد الإلكتروني الذي أرسلته إلى Gmail.

هذا هو البريد الإلكتروني الذي أرسله إلى بريده الإلكتروني QQ.
هذا مجرد مثال صغير ، لأن zapier لديه الآلاف من التطبيقات ، حتى نتمكن من بناء مهام سير العمل الخاصة بنا بسهولة باستخدام API Openai.
تم شرح بعض نقاط المعرفة الأكبر ، والمحتوى التالي يدور حول بعض الأمثلة الصغيرة المثيرة للاهتمام ، كملحقات.
لأنه مرتبط بالسلاسل ، يمكنه أيضًا تنفيذ سلاسل متعددة بالتسلسل.
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )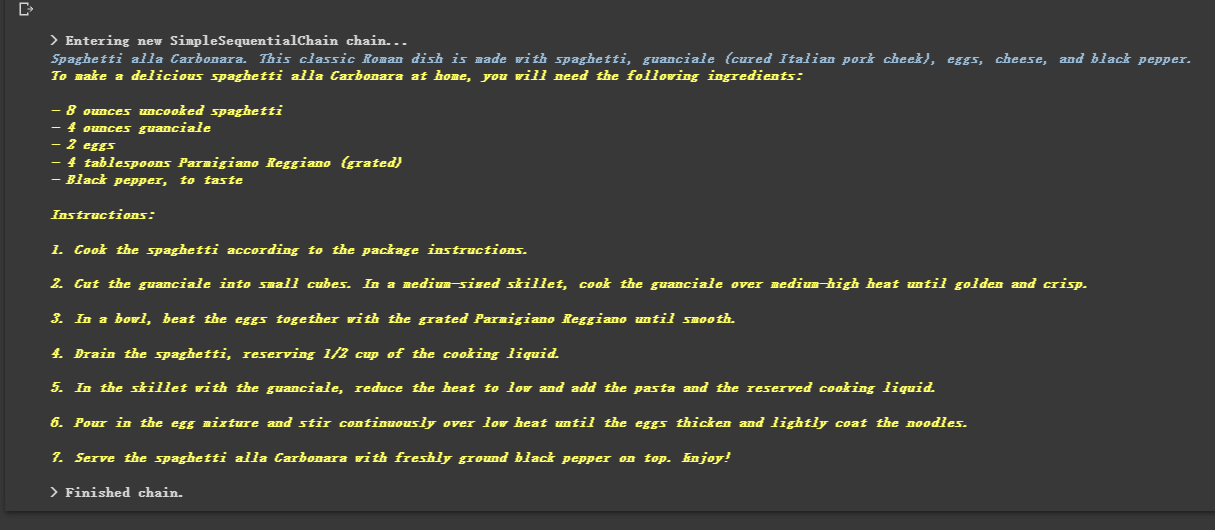
في بعض الأحيان نريد ألا يكون الإخراج نصًا ، ولكن البيانات المنظمة مثل JSON.
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
في بعض الأحيان نحتاج إلى زحف بعض هيكل أقوى ويجب إرجاع المعلومات الموجودة في صفحة الويب في وضع JSON.
يمكننا استخدام فئة LLMRequestsChain لتنفيذها.
من أجل الفهم السهل ، استخدمت طريقة المطالبة مباشرة لتنسيق نتائج الإخراج في المثال ، لكنني لم أستخدم
StructuredOutputParserالمستخدم في الحالة السابقة لتنسيقها ، والتي يمكن اعتبارها أيضًا توفير فكرة تنسيق أخرى.
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])يمكننا أن نرى أنه يخرج النتائج المنسقة جيدًا

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )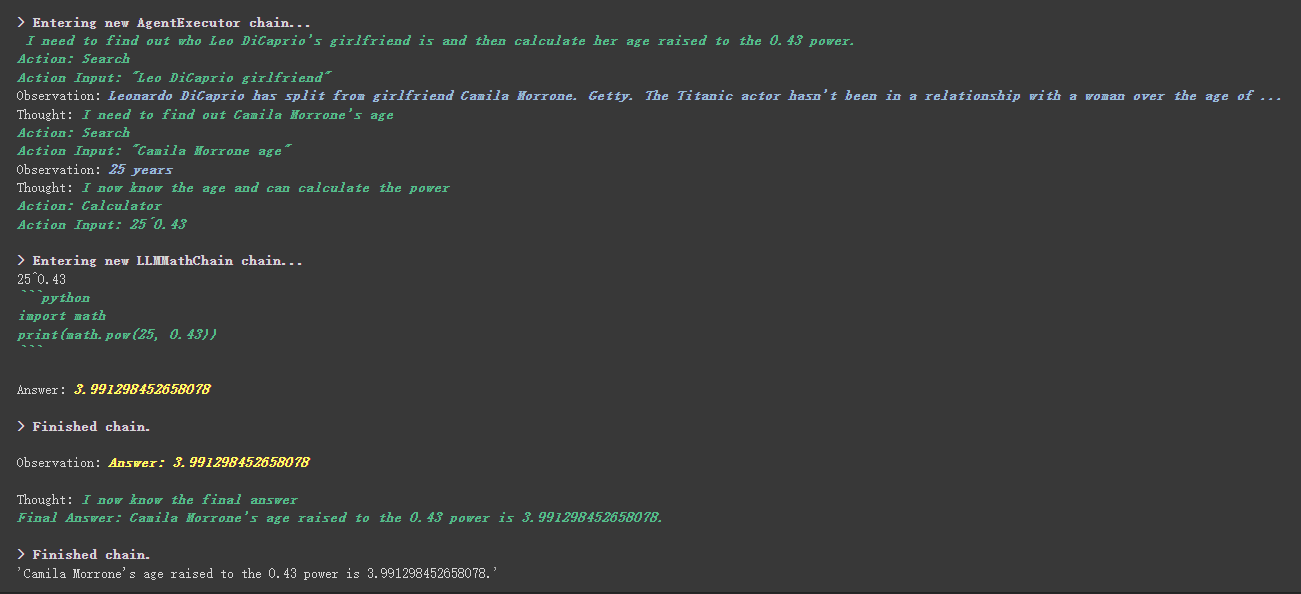
هناك شيء أكثر إثارة للاهتمام في الأداة المخصصة工具中描述内容
على سبيل المثال ، كتبت الآلة الحاسبة في الوصف أنه إذا طرحت أسئلة حول الرياضيات ، فاستخدم هذه الأداة. يمكننا أن نرى في عملية التنفيذ أعلاه أنه في جزء الرياضيات من ProPT المطلوبة ، استخدم أداة الآلة الحاسبة للحسابات.
في المثال السابق ، استخدمنا الطريقة التي أنقذنا بها التاريخ من خلال تخصيص قائمة لتخزين المحادثات.
بالطبع ، يمكنك أيضًا استخدام كائن الذاكرة المضمّن لتحقيق ذلك.
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )قبل استخدام نموذج الوجه المعانقة ، تحتاج إلى تعيين متغيرات البيئة أولاً
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''باستخدام نموذج الوجه المعانقة عبر الإنترنت
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))اسحب نموذج الوجه المعانقة مباشرة للاستخدام محليًا
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))فوائد سحب النموذج للاستخدام محليًا:
يمكننا تنفيذ أوامر SQL من خلال SQLDatabaseToolkit أو SQLDatabaseChain
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )هنا يمكنك الرجوع إلى هاتين الوثيقة:
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
انتهت جميع الحالات بشكل أساسي. هذا المقال هو مجرد شرح أولي لـ Langchain.
ولأن Langchain يتكرر بسرعة كبيرة ، فمن المؤكد أنها ستكرر وظائف أفضل مع استمرار تطوير الذكاء الاصطناعى ، لذلك أنا متفائل للغاية بشأن مكتبة المصدر المفتوح هذه.
آمل أن يتمكن الجميع من الجمع بين Langchain لتطوير المزيد من المنتجات الإبداعية ، بدلاً من مجرد إنشاء مجموعة من المنتجات التي تبني عملاء الدردشة بنقرة واحدة.
أضفت 01 بعد هذا العنوان.
جميع رموز العينة في هذه المقالة هنا ، أتمنى لك تعلم سعيد.
https://colab.research.google.com/drive/1arrvmis-ykhulobhru6bes8ff57ueapq؟usp=sharing


