LangChain Chinese Getting Started Guide
1.0.0
Untuk membaca dengan mudah, gitbook telah dihasilkan: https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
Alamat GitHub: https://github.com/liaokongvfx/langchain-chinese-getting-started-guide
"Dekripsi Teknologi Langchain: Panduan Panorama untuk Membangun Aplikasi Model Besar" telah diterbitkan sekarang: https://item.jd.com/14598210.html
Transfer API AI Domestik dan Luar Negeri dengan harga murah: https://api.91ai.me
Karena Perpustakaan Langchain telah diperbarui dengan cepat dan berulang, tetapi dokumen tersebut ditulis pada awal April, dan saya memiliki energi pribadi yang terbatas, sehingga kode di Colab mungkin agak ketinggalan zaman. Jika ada kegagalan dalam operasi, Anda dapat mencari terlebih dahulu apakah dokumen saat ini telah diperbarui
Saya menambahkan changelog dan memperbarui konten baru.
Jika Anda ingin memodifikasi rute root permintaan API OpenAI ke alamat proxy Anda sendiri, Anda dapat memodifikasinya dengan mengatur variabel lingkungan "OpenAI_API_BASE".
Kode referensi terkait: https://github.com/openai/openai-python/blob/d6fa3bfaae69d639b0dd2e9251b375d7070bbef1/openai/__init__.py#l48
Atau saat menginisialisasi objek model yang berhubungan dengan OpenAi, lulus dalam variabel "openai_api_base".
Kode referensi terkait: https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#l148
Seperti yang kita semua tahu, API Openai tidak dapat terhubung ke internet, jadi pasti tidak mungkin untuk menggunakan fungsinya sendiri untuk mencari dan memberikan jawaban, merangkum dokumen PDF, dan melakukan tanya jawab berdasarkan video YouTube. Jadi, mari kita perkenalkan perpustakaan open source pihak ketiga yang sangat kuat: LangChain .
Alamat dokumen: https://python.langchain.com/en/latest/
Perpustakaan ini saat ini sangat aktif dan berulang setiap hari.
Langchain adalah kerangka kerja untuk mengembangkan aplikasi yang ditenagai oleh model bahasa. Dia memiliki 2 kemampuan utama:
Model LLM: Model Bahasa Besar, Model Bahasa Besar
Panggilan llm
Manajemen yang cepat, mendukung berbagai templat khusus
Ini memiliki sejumlah besar loader dokumen, seperti email, markdown, pdf, youtube ...
Dukungan untuk indeks
Rantai
Saya percaya semua orang akan bingung setelah membaca pengantar di atas. Jangan khawatir, konsep di atas sebenarnya tidak terlalu penting ketika kita pertama kali mulai belajar.
Namun, berikut adalah beberapa konsep yang harus diketahui.
Seperti namanya, ini adalah memuat data dari sumber yang ditentukan. For example: folder DirectoryLoader , Azure Storage AzureBlobStorageContainerLoader , CSV file CSVLoader , Evernote EverNoteLoader , Google GoogleDriveLoader , any web page UnstructuredHTMLLoader , PDF PyPDFLoader , S3 S3DirectoryLoader / S3FileLoader ,
YouTube YoutubeLoader , dll. Saya baru saja mendaftarkan beberapa dari mereka.
https://python.langchain.com/docs/modules/data_connection/document_loaders.html
Setelah membaca sumber data menggunakan Loader Loader, sumber data perlu dikonversi menjadi objek dokumen sebelum dapat digunakan nanti.
Seperti namanya, segmentasi teks digunakan untuk membagi teks. Mengapa Anda perlu membagi teks? Karena setiap kali kami mengirim teks sebagai propt ke OpenAI API atau menggunakan fungsi embedding API OpenAI, ada batasan karakter.
Misalnya, jika kami mengirim PDF 300 halaman ke API Openai dan memintanya untuk meringkas, ia pasti akan melaporkan kesalahan yang melebihi token maksimum. Jadi di sini kita perlu menggunakan splitter teks untuk membagi dokumen yang dimasukkan oleh loader kami.
Karena pencarian korelasi data sebenarnya adalah operasi vektor. Oleh karena itu, apakah kami menggunakan fungsi embedding API OpenAI atau secara langsung diminta melalui database vektor, kami perlu memvektor Document data kami yang dimuat untuk melakukan pencarian operasi vektor. Konversi menjadi vektor juga sangat sederhana.
Pejabat ini juga menyediakan banyak database vektor untuk kami gunakan.
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
Kita bisa memahami rantai sebagai tugas. Rantai adalah tugas, dan tentu saja itu juga dapat menjalankan beberapa rantai satu per satu seperti rantai.
Kita dapat dengan mudah memahami bahwa itu secara dinamis dapat membantu kita memilih dan memanggil rantai atau alat yang ada.
Untuk proses eksekusi, silakan merujuk ke gambar berikut:
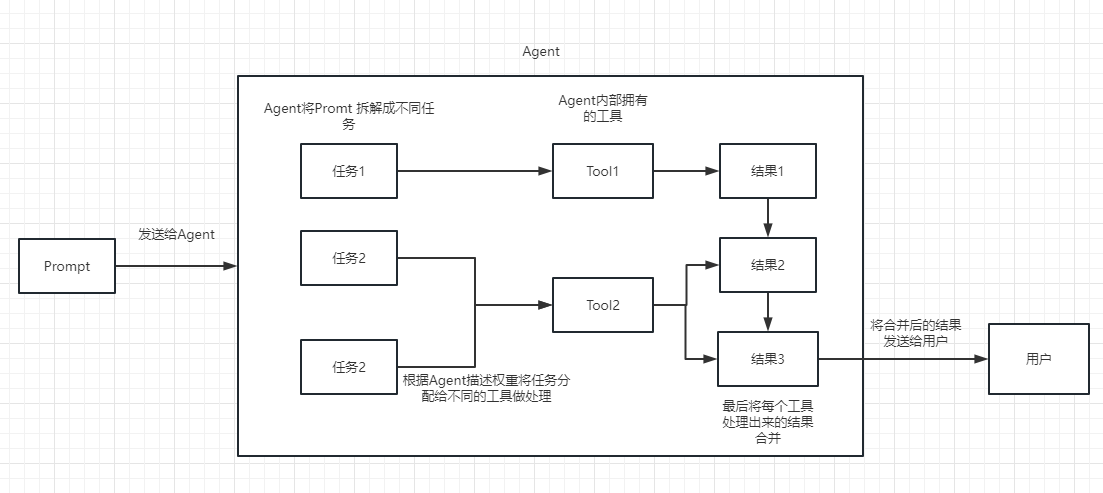
Digunakan untuk mengukur relevansi teks. Ini juga merupakan kunci kemampuan Openai API untuk membangun basis pengetahuannya sendiri.
Keuntungan terbesarnya atas penyempurnaan adalah bahwa ia tidak perlu berlatih dan dapat menambahkan konten baru secara real time, alih-alih menambahkan konten baru sekali, dan biaya dalam semua aspek jauh lebih rendah daripada fine-tuning.
Untuk perbandingan dan pilihan tertentu, silakan merujuk ke video ini: https://www.youtube.com/watch?v=9QQ6HTR7OCW
Melalui konsep -konsep penting di atas, Anda harus memiliki pemahaman tertentu tentang Langchain, tetapi Anda mungkin masih sedikit bingung.
Ini semua adalah pertanyaan kecil.
Karena API OpenAi kami sudah maju, LLM yang digunakan dalam contoh kami berikutnya semuanya didasarkan pada Open AI sebagai contoh.
Tentu saja, di akhir artikel ini, semua kode akan disimpan sebagai file Colab Ipynb dan disediakan untuk dipelajari semua orang.
Dianjurkan agar Anda melihat setiap contoh secara berurutan, karena contoh berikutnya akan menggunakan titik pengetahuan dalam contoh sebelumnya.
Tentu saja, jika Anda tidak mengerti sesuatu, jangan khawatir.
Dalam kasus pertama, kami akan menggunakan Langchain untuk memuat model openai dan menyelesaikan tanya jawab.
Sebelum memulai, kita perlu mengatur kunci OpenAI kami terlebih dahulu.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'Lalu kami mengimpor dan mengeksekusi
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1024 )
llm ( "怎么评价人工智能" )
Pada saat ini, kita bisa melihat hasil yang dia berikan kepada kita.
Selanjutnya, mari kita lakukan sesuatu yang menarik. Mari kita minta API OpenAI kami untuk mencari online dan mengembalikan jawaban kepada kami.
Di sini kita perlu menggunakan SERPAPI untuk mengimplementasikannya, yang menyediakan antarmuka API untuk pencarian Google.
Pertama, kita perlu mendaftarkan pengguna di situs web resmi SERPAPI, https://serpapi.com/ dan menyalinnya untuk menghasilkan kunci API untuk kami.
Maka kita perlu mengaturnya ke variabel lingkungan seperti kunci API OpenAI di atas.
import os
os . environ [ "OPENAI_API_KEY" ] = '你的api key'
os . environ [ "SERPAPI_API_KEY" ] = '你的api key'Kemudian, mulailah menulis kode saya
from langchain . agents import load_tools
from langchain . agents import initialize_agent
from langchain . llms import OpenAI
from langchain . agents import AgentType
# 加载 OpenAI 模型
llm = OpenAI ( temperature = 0 , max_tokens = 2048 )
# 加载 serpapi 工具
tools = load_tools ([ "serpapi" ])
# 如果搜索完想再计算一下可以这么写
# tools = load_tools(['serpapi', 'llm-math'], llm=llm)
# 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
# tools=load_tools(["serpapi","python_repl"])
# 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 运行 agent
agent . run ( "What's the date today? What great events have taken place today in history?" )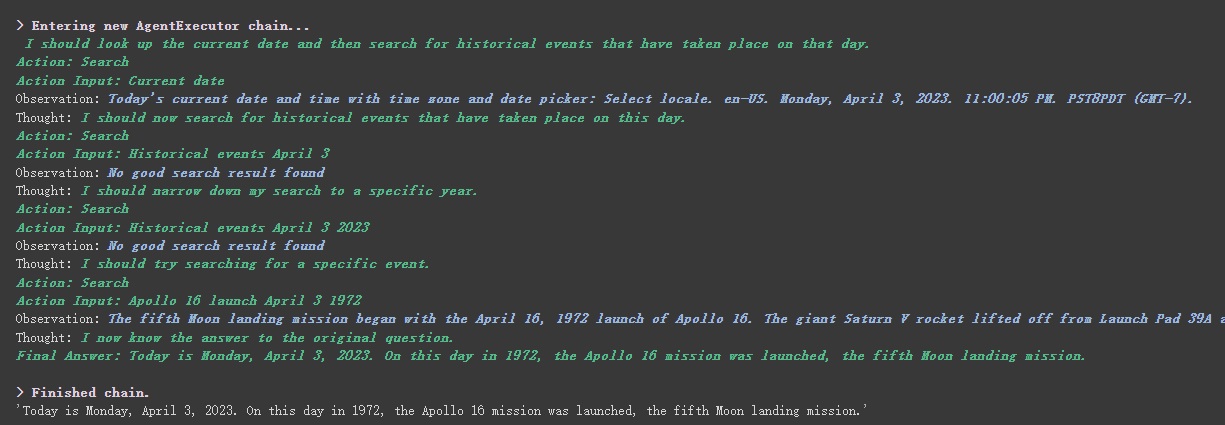
Kita dapat melihat bahwa dia dengan benar mengembalikan tanggal (kadang -kadang perbedaan) dan kembali ke hari ini dalam sejarah.
Ada parameter verbose pada objek rantai dan agen.
Seperti yang dapat Anda lihat dari hasil yang dikembalikan di atas, ia membagi pertanyaan kami menjadi beberapa langkah dan kemudian mendapatkan jawaban akhir langkah demi langkah.
Mengenai arti beberapa opsi untuk jenis agen (jika Anda tidak dapat memahaminya, itu tidak akan mempengaruhi pembelajaran berikut. Jika Anda menggunakannya terlalu banyak, Anda secara alami akan memahaminya):
Search dan Lookup , yang pertama digunakan untuk mencari, dan yang terakhir digunakan untuk menemukan istilah, misalnya: alat WipipediaGoogle search APIAnda dapat melihat ini untuk pengenalan reaksi: https://arxiv.org/pdf/2210.03629.pdf
Python Implementasi pola reaksi LLM: https://til.simonwillison.net/llms/python-react-pattern
Penjelasan Resmi Jenis Agen:
https://python.langchain.com/en/latest/modules/agents/agents/agent_types.html?highlight=zero-shot-react-description
Satu hal yang perlu dicatat adalah bahwa
serpapiini tampaknya tidak terlalu ramah kepada orang Cina, jadi prompt yang diminta disarankan untuk menggunakan bahasa Inggris.
Tentu saja, pejabat telah menulis agen ChatGPT Plugins .
Namun, saat ini, hanya plug-in yang tidak memerlukan otorisasi yang dapat digunakan.
Mereka yang tertarik dapat membaca dokumen ini: https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
Chatgpt hanya bisa menghasilkan uang untuk pejabat, dan Openai API dapat menghasilkan uang untuk saya
Jika kami ingin menggunakan API OpenAI untuk merangkum paragraf teks, cara kami yang biasa adalah mengirimkannya langsung ke API agar dapat diringkas. Namun, jika teks melebihi batas token maksimum API, kesalahan akan dilaporkan.
Pada saat ini, kami umumnya segmen artikel, seperti menghitung dan membaginya melalui Tiktoken, kemudian mengirim setiap paragraf ke API untuk ringkasan, dan akhirnya merangkum ringkasan setiap paragraf.
Jika Anda menggunakan Langchain, ia membantu kami menangani proses ini dengan sangat baik, sehingga sangat mudah bagi kami untuk menulis kode.
Tanpa basa -basi lagi, cukup unggah kode.
from langchain . document_loaders import UnstructuredFileLoader
from langchain . chains . summarize import load_summarize_chain
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader ( "/content/sample_data/data/lg_test.txt" )
# 将文本转成 Document 对象
document = loader . load ()
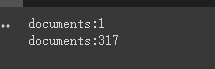
print ( f'documents: { len ( document ) } ' )
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 500 ,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter . split_documents ( document )
print ( f'documents: { len ( split_documents ) } ' )
# 加载 llm 模型
llm = OpenAI ( model_name = "text-davinci-003" , max_tokens = 1500 )
# 创建总结链
chain = load_summarize_chain ( llm , chain_type = "refine" , verbose = True )
# 执行总结链,(为了快速演示,只总结前5段)
chain . run ( split_documents [: 5 ])Pertama, kami mencetak jumlah dokumen sebelum dan sesudah pemotongan.
Akhirnya, ringkasan dari 5 dokumen pertama adalah output.

Berikut adalah beberapa parameter yang perlu diperhatikan:
Parameter chunk_overlap dari splitter teks
Ini mengacu pada konten yang diakhiri dengan beberapa dokumen sebelumnya di setiap dokumen setelah pemotongan. Misalnya, ketika chunk_overlap=0 chunk_overlap=2 dokumen pertama adalah AAAAAAA, yang kedua adalah BBBBBB;
Namun, ini tidak absolut, itu tergantung pada algoritma spesifik di dalam model segmentasi teks yang digunakan.
Anda dapat merujuk ke dokumen ini untuk pemecah teks: https://python.langchain.com/en/latest/modules/indexes/text_splitters.html
Parameter rantai chain_type
Parameter ini terutama mengontrol cara dokumen diteruskan ke model LLM, dan ada 4 cara secara total:
stuff : Ini paling sederhana dan kasar, dan akan meneruskan semua dokumen ke model LLM sekaligus untuk ringkasan. Jika ada banyak dokumen, itu pasti akan melaporkan kesalahan yang melebihi batas token maksimum, jadi ini umumnya tidak dipilih saat merangkum teks.
map_reduce : Metode ini pertama -tama akan merangkum setiap dokumen, dan akhirnya merangkum hasil yang dirangkum oleh semua dokumen.
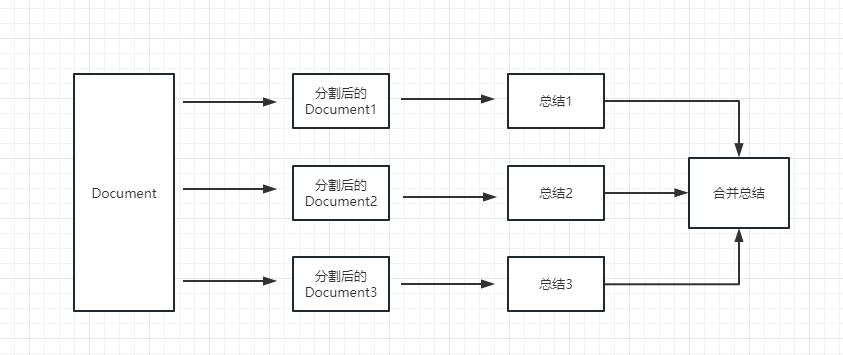
refine : Metode ini pertama -tama akan merangkum dokumen pertama, dan kemudian mengirim konten yang dirangkum oleh dokumen pertama dan dokumen kedua ke model LLM untuk ringkasan, dan sebagainya. Keuntungan dari metode ini adalah bahwa ketika merangkum dokumen yang terakhir, akan membutuhkan dokumen sebelumnya untuk merangkum, menambahkan konteks ke dokumen yang perlu dirangkum, dan meningkatkan konsistensi konten ringkasan.
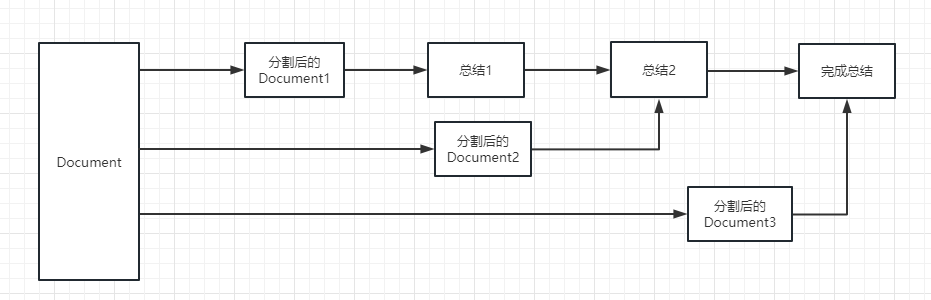
map_rerank : Jenis rantai ini umumnya tidak digunakan dalam ringkasan, tetapi rantai pertanyaan dan jawaban. Pertama, Anda perlu memberikan pertanyaan.
Dalam contoh ini, kami akan menjelaskan cara membangun basis pengetahuan dengan membaca banyak dokumen dari kami secara lokal dan menggunakan API OpenAI untuk mencari dan memberikan jawaban di basis pengetahuan.
Ini adalah tutorial yang sangat berguna, seperti robot yang dapat dengan mudah memperkenalkan bisnis perusahaan atau robot yang memperkenalkan produk.
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import CharacterTextSplitter
from langchain import OpenAI
from langchain . document_loaders import DirectoryLoader
from langchain . chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 100 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings ()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma . from_documents ( split_docs , embeddings )
# 创建问答对象
qa = RetrievalQA . from_chain_type ( llm = OpenAI (), chain_type = "stuff" , retriever = docsearch . as_retriever (), return_source_documents = True )
# 进行问答
result = qa ({ "query" : "科大讯飞今年第一季度收入是多少?" })
print ( result )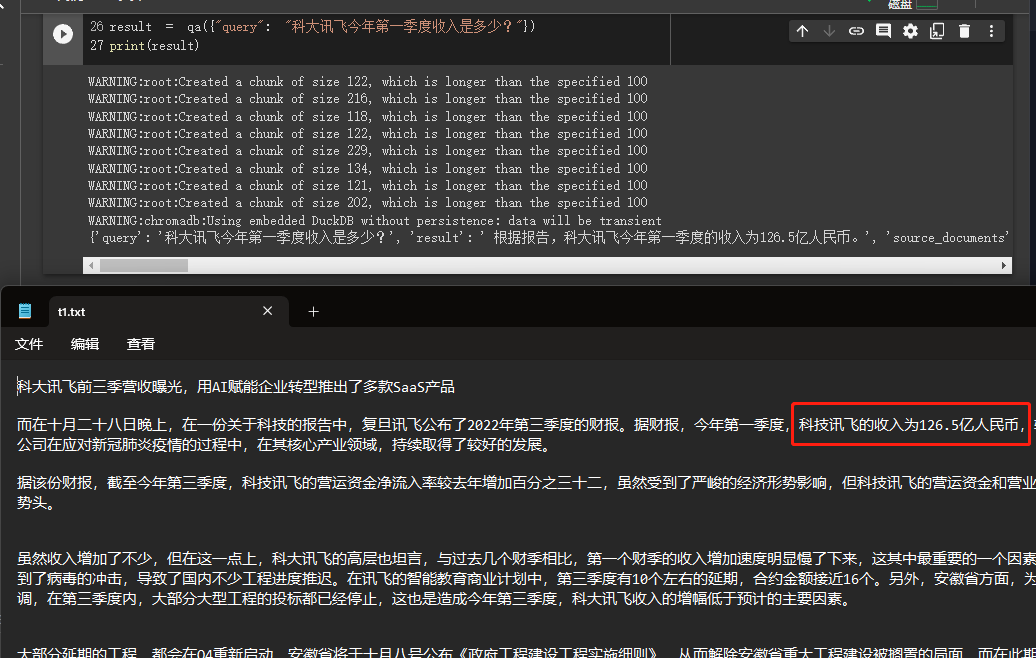
Kita dapat melihat melalui hasil bahwa dia berhasil mendapatkan jawaban yang benar dari data yang kita berikan.
Untuk detail tentang Openai Embeddings, silakan merujuk ke tautan ini: https://platform.openai.com/docs/guides/EMBEDDINGS
Salah satu langkah dalam kasus kami sebelumnya adalah untuk mengubah informasi dokumen menjadi informasi vektor dan menanamkan informasi dan untuk sementara menyimpannya ke dalam database Chroma.
Karena disimpan sementara, ketika kode di atas dieksekusi, data setelah vektorisasi di atas akan hilang. Jika Anda ingin menggunakannya lain kali, Anda perlu menghitung embeddings lagi, yang jelas bukan yang kami inginkan.
Jadi, dalam hal ini, kita akan berbicara tentang cara bertahan data vektor melalui dua database chroma dan pinecone.
Karena Langchain mendukung banyak database, berikut adalah dua yang digunakan lebih sering.
Chroma
Chroma adalah database vektor lokal, yang menyediakan persist_directory untuk mengatur direktori persisten untuk kegigihan. Saat membaca, Anda hanya perlu memanggil metode from_document untuk memuat.
from langchain . vectorstores import Chroma
# 持久化数据
docsearch = Chroma . from_documents ( documents , embeddings , persist_directory = "D:/vector_store" )
docsearch . persist ()
# 加载数据
docsearch = Chroma ( persist_directory = "D:/vector_store" , embedding_function = embeddings )Pinecone
Pinecone adalah database vektor online. Jadi, langkah pertama saya masih bisa mendaftar dan mendapatkan kunci API yang sesuai. https://app.pinecone.io/
Versi gratis akan secara otomatis dihapus jika indeks tidak digunakan selama 14 hari.
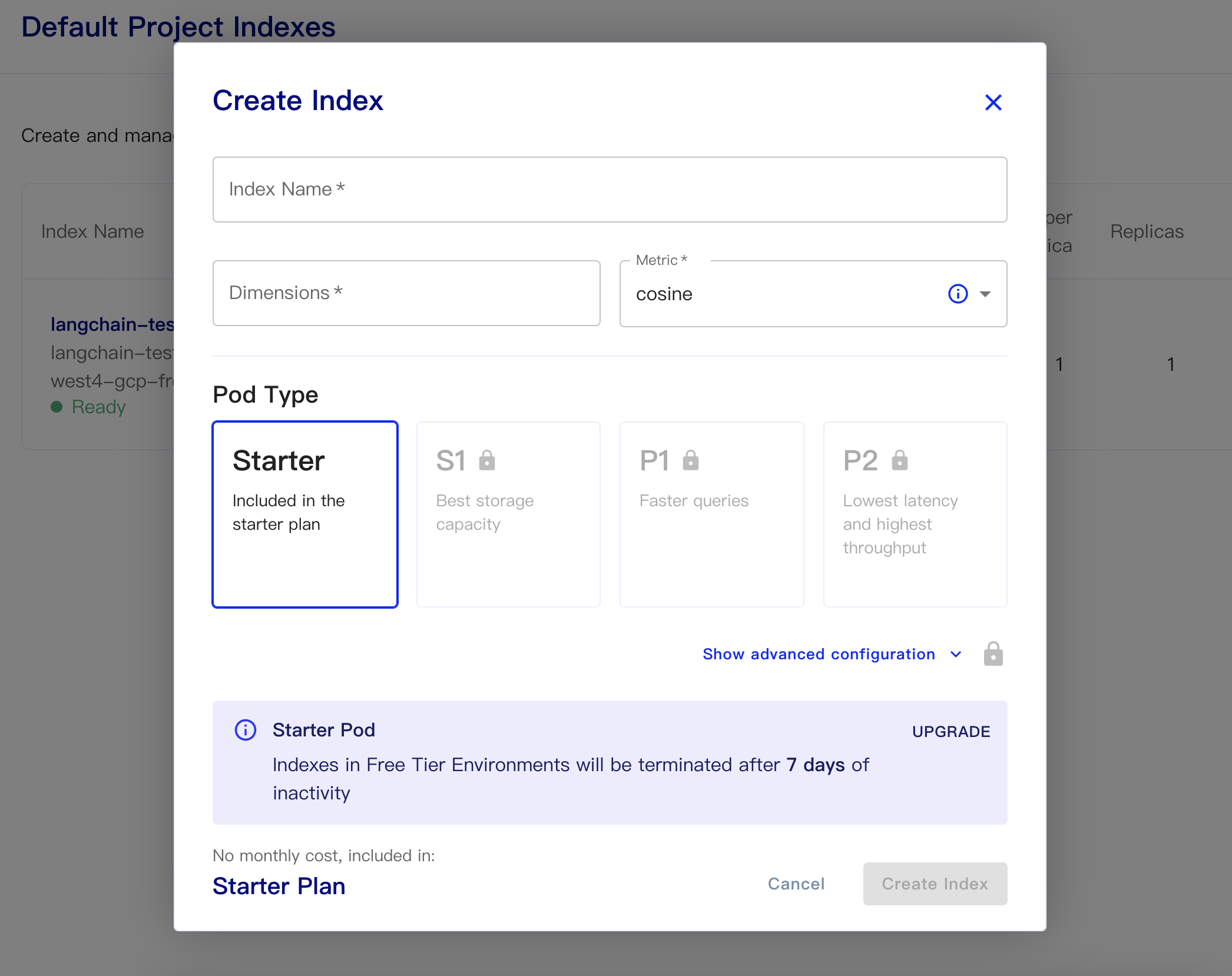
Kemudian buat database kami:
Nama Indeks: Ini Santai
Dimensi: Model Text-Embedding-DABE-002 Openai adalah dimensi keluaran adalah 1536, jadi kami mengisi 1536 di sini
Metrik: dapat default ke cosinus
Pilih Paket Starter
Data persisten dan memuat kode data adalah sebagai berikut
# 持久化数据
docsearch = Pinecone . from_texts ([ t . page_content for t in split_docs ], embeddings , index_name = index_name )
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )Kode sederhana untuk mendapatkan embeddings dari database dan menjawabnya adalah sebagai berikut
from langchain . text_splitter import CharacterTextSplitter
from langchain . document_loaders import DirectoryLoader
from langchain . vectorstores import Chroma , Pinecone
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . llms import OpenAI
from langchain . chains . question_answering import load_qa_chain
import pinecone
# 初始化 pinecone
pinecone . init (
api_key = "你的api key" ,
environment = "你的Environment"
)
loader = DirectoryLoader ( '/content/sample_data/data/' , glob = '**/*.txt' )
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader . load ()
# 初始化加载器
text_splitter = CharacterTextSplitter ( chunk_size = 500 , chunk_overlap = 0 )
# 切割加载的 document
split_docs = text_splitter . split_documents ( documents )
index_name = "liaokong-test"
# 持久化数据
# docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone . from_existing_index ( index_name , embeddings )
query = "科大讯飞今年第一季度收入是多少?"
docs = docsearch . similarity_search ( query , include_metadata = True )
llm = OpenAI ( temperature = 0 )
chain = load_qa_chain ( llm , chain_type = "stuff" , verbose = True )
chain . run ( input_documents = docs , question = query )
Setelah model chatgpt (yaitu, GPT-3.5-turbo) dirilis, itu dicintai oleh semua orang karena itu lebih sedikit uang, jadi Langchain juga menambahkan rantai dan model eksklusif.
import os
from langchain . document_loaders import YoutubeLoader
from langchain . embeddings . openai import OpenAIEmbeddings
from langchain . vectorstores import Chroma
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain . chains import ChatVectorDBChain , ConversationalRetrievalChain
from langchain . chat_models import ChatOpenAI
from langchain . prompts . chat import (
ChatPromptTemplate ,
SystemMessagePromptTemplate ,
HumanMessagePromptTemplate
)
# 加载 youtube 频道
loader = YoutubeLoader . from_youtube_url ( 'https://www.youtube.com/watch?v=Dj60HHy-Kqk' )
# 将数据转成 document
documents = loader . load ()
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1000 ,
chunk_overlap = 20
)
# 分割 youtube documents
documents = text_splitter . split_documents ( documents )
# 初始化 openai embeddings
embeddings = OpenAIEmbeddings ()
# 将数据存入向量存储
vector_store = Chroma . from_documents ( documents , embeddings )
# 通过向量存储初始化检索器
retriever = vector_store . as_retriever ()
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
# 构建初始 messages 列表,这里可以理解为是 openai 传入的 messages 参数
messages = [
SystemMessagePromptTemplate . from_template ( system_template ),
HumanMessagePromptTemplate . from_template ( '{question}' )
]
# 初始化 prompt 对象
prompt = ChatPromptTemplate . from_messages ( messages )
# 初始化问答链
qa = ConversationalRetrievalChain . from_llm ( ChatOpenAI ( temperature = 0.1 , max_tokens = 2048 ), retriever , condense_question_prompt = prompt )
chat_history = []
while True :
question = input ( '问题:' )
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa ({ 'question' : question , 'chat_history' : chat_history })
chat_history . append (( question , result [ 'answer' ]))
print ( result [ 'answer' ])Kita dapat melihat bahwa dia dapat secara akurat menjawab pertanyaan dan jawaban di sekitar video pipa oli ini

Jawaban streaming juga sangat nyaman
from langchain . callbacks . base import CallbackManager
from langchain . callbacks . streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI ( streaming = True , callback_manager = CallbackManager ([ StreamingStdOutCallbackHandler ()]), verbose = True , temperature = 0 )
resp = chat ( chat_prompt_with_values . to_messages ()) Kami terutama menggunakan zapier untuk menghubungkan ribuan alat.
Jadi langkah pertama kami adalah melamar akun dan kunci API bahasa alami. https://zapier.com/l/natural-language-actions
Kunci API -nya perlu mengisi aplikasi informasi. Namun, setelah pada dasarnya mengisi informasi, pada dasarnya Anda dapat melihat email yang disetujui di alamat email dalam hitungan detik.
Kemudian, kami membuka halaman konfigurasi API kami dengan mengklik kanan koneksi. Kami mengklik Manage Actions di sebelah kanan untuk mengonfigurasi aplikasi mana yang ingin kami gunakan.
Saya telah mengkonfigurasi tindakan Gmail untuk membaca dan mengirim email di sini, dan semua bidang dipilih dengan tebakan AI.
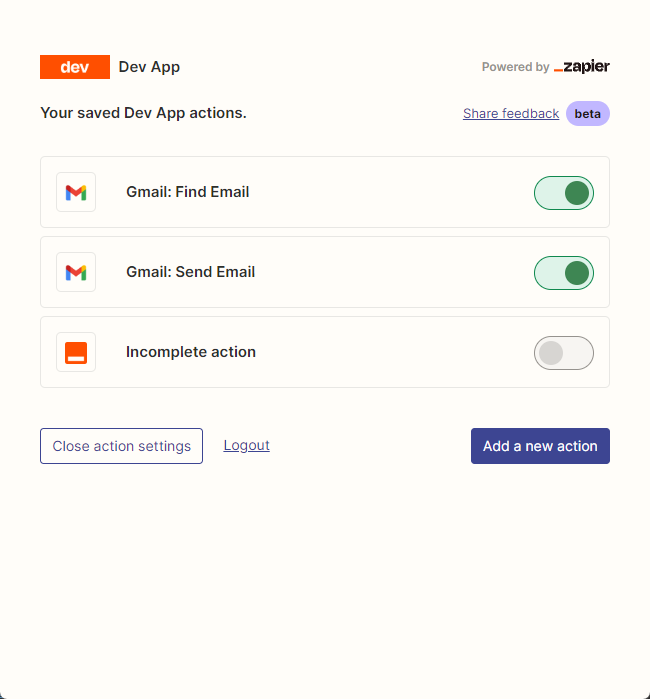
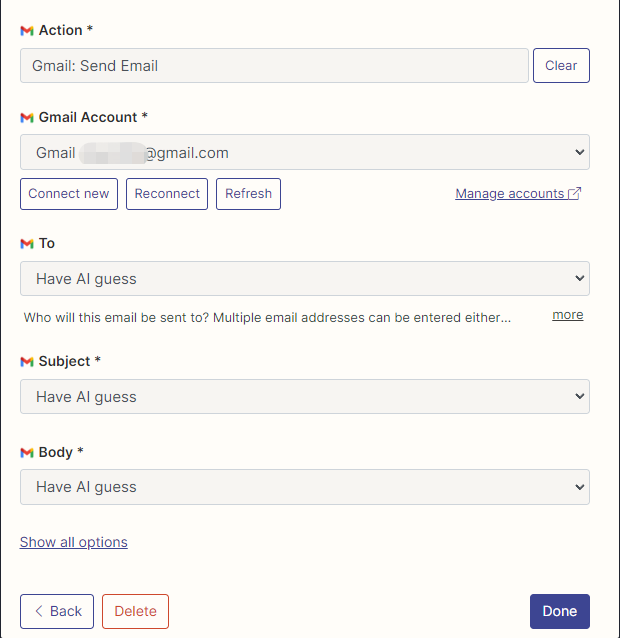
Setelah konfigurasi selesai, kami mulai menulis kode
import os
os . environ [ "ZAPIER_NLA_API_KEY" ] = '' from langchain . llms import OpenAI
from langchain . agents import initialize_agent
from langchain . agents . agent_toolkits import ZapierToolkit
from langchain . utilities . zapier import ZapierNLAWrapper
llm = OpenAI ( temperature = .3 )
zapier = ZapierNLAWrapper ()
toolkit = ZapierToolkit . from_zapier_nla_wrapper ( zapier )
agent = initialize_agent ( toolkit . get_tools (), llm , agent = "zero-shot-react-description" , verbose = True )
# 我们可以通过打印的方式看到我们都在 Zapier 里面配置了哪些可以用的工具
for tool in toolkit . get_tools ():
print ( tool . name )
print ( tool . description )
print ( " n n " )
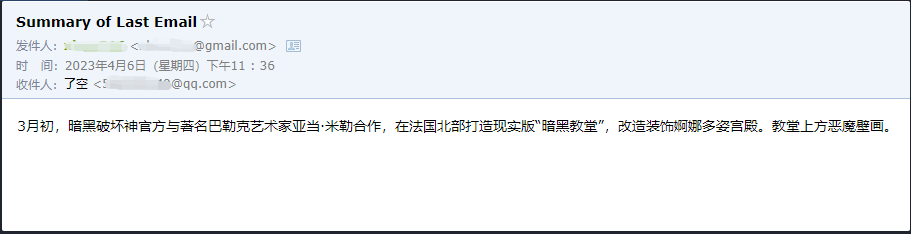
agent . run ( '请用中文总结最后一封"******@qq.com"发给我的邮件。并将总结发送给"******@qq.com"' )
Kita dapat melihat bahwa dia berhasil membaca email terakhir yang dikirim kepadanya oleh ******@qq.com dan mengirim konten ringkasan ke ******@qq.com lagi.
Ini adalah email yang saya kirim ke Gmail.

Ini adalah email yang dia kirim ke email QQ -nya.
Ini hanya contoh kecil, karena zapier memiliki ribuan aplikasi, sehingga kami dapat dengan mudah membangun alur kerja kami sendiri dengan API OpenAI.
Beberapa titik pengetahuan yang lebih besar telah dijelaskan, dan konten berikut adalah tentang beberapa contoh kecil yang menarik, sebagai ekstensi.
Karena dirantai, ia juga dapat menjalankan beberapa rantai secara berurutan.
from langchain . llms import OpenAI
from langchain . chains import LLMChain
from langchain . prompts import PromptTemplate
from langchain . chains import SimpleSequentialChain
# location 链
llm = OpenAI ( temperature = 1 )
template = """Your job is to come up with a classic dish from the area that the users suggests.
% USER LOCATION
{user_location}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_location" ], template = template )
location_chain = LLMChain ( llm = llm , prompt = prompt_template )
# meal 链
template = """Given a meal, give a short and simple recipe on how to make that dish at home.
% MEAL
{user_meal}
YOUR RESPONSE:
"""
prompt_template = PromptTemplate ( input_variables = [ "user_meal" ], template = template )
meal_chain = LLMChain ( llm = llm , prompt = prompt_template )
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
overall_chain = SimpleSequentialChain ( chains = [ location_chain , meal_chain ], verbose = True )
review = overall_chain . run ( "Rome" )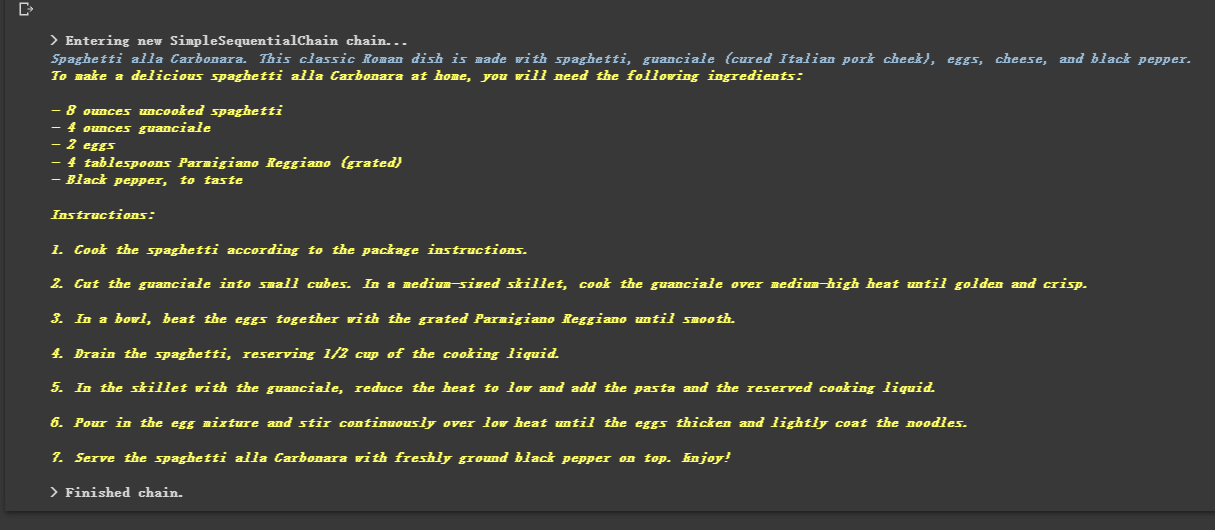
Terkadang kami ingin output bukan teks, tetapi data terstruktur seperti JSON.
from langchain . output_parsers import StructuredOutputParser , ResponseSchema
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
llm = OpenAI ( model_name = "text-davinci-003" )
# 告诉他我们生成的内容需要哪些字段,每个字段类型式啥
response_schemas = [
ResponseSchema ( name = "bad_string" , description = "This a poorly formatted user input string" ),
ResponseSchema ( name = "good_string" , description = "This is your response, a reformatted response" )
]
# 初始化解析器
output_parser = StructuredOutputParser . from_response_schemas ( response_schemas )
# 生成的格式提示符
# {
# "bad_string": string // This a poorly formatted user input string
# "good_string": string // This is your response, a reformatted response
#}
format_instructions = output_parser . get_format_instructions ()
template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""
# 将我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate (
input_variables = [ "user_input" ],
partial_variables = { "format_instructions" : format_instructions },
template = template
)
promptValue = prompt . format ( user_input = "welcom to califonya!" )
llm_output = llm ( promptValue )
# 使用解析器进行解析生成的内容
output_parser . parse ( llm_output )
Terkadang kita perlu merangkak beberapa Struktur yang lebih kuat dan informasi di halaman web perlu dikembalikan dalam mode JSON.
Kami dapat menggunakan kelas LLMRequestsChain untuk mengimplementasikannya.
Demi pemahaman yang mudah, saya secara langsung menggunakan metode prompt untuk memformat hasil output dalam contoh, tetapi tidak menggunakan
StructuredOutputParseryang digunakan dalam kasus sebelumnya untuk memformatnya, yang juga dapat dianggap sebagai memberikan ide pemformatan lain.
from langchain . prompts import PromptTemplate
from langchain . llms import OpenAI
from langchain . chains import LLMRequestsChain , LLMChain
llm = OpenAI ( model_name = "gpt-3.5-turbo" , temperature = 0 )
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是新浪财经A股上市公司的公司简介。
请抽取参数请求的信息。
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"company_name":"a",
"company_english_name":"b",
"issue_price":"c",
"date_of_establishment":"d",
"registered_capital":"e",
"office_address":"f",
"Company_profile":"g"
}}
Extracted:"""
prompt = PromptTemplate (
input_variables = [ "requests_result" ],
template = template
)
chain = LLMRequestsChain ( llm_chain = LLMChain ( llm = llm , prompt = prompt ))
inputs = {
"url" : "https://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/stockid/600519.phtml"
}
response = chain ( inputs )
print ( response [ 'output' ])Kita dapat melihat bahwa dia menghasilkan hasil yang diformat dengan sangat baik

from langchain . agents import initialize_agent , Tool
from langchain . agents import AgentType
from langchain . tools import BaseTool
from langchain . llms import OpenAI
from langchain import LLMMathChain , SerpAPIWrapper
llm = OpenAI ( temperature = 0 )
# 初始化搜索链和计算链
search = SerpAPIWrapper ()
llm_math_chain = LLMMathChain ( llm = llm , verbose = True )
# 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
tools = [
Tool (
name = "Search" ,
func = search . run ,
description = "useful for when you need to answer questions about current events"
),
Tool (
name = "Calculator" ,
func = llm_math_chain . run ,
description = "useful for when you need to answer questions about math"
)
]
# 初始化 agent
agent = initialize_agent ( tools , llm , agent = AgentType . ZERO_SHOT_REACT_DESCRIPTION , verbose = True )
# 执行 agent
agent . run ( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?" )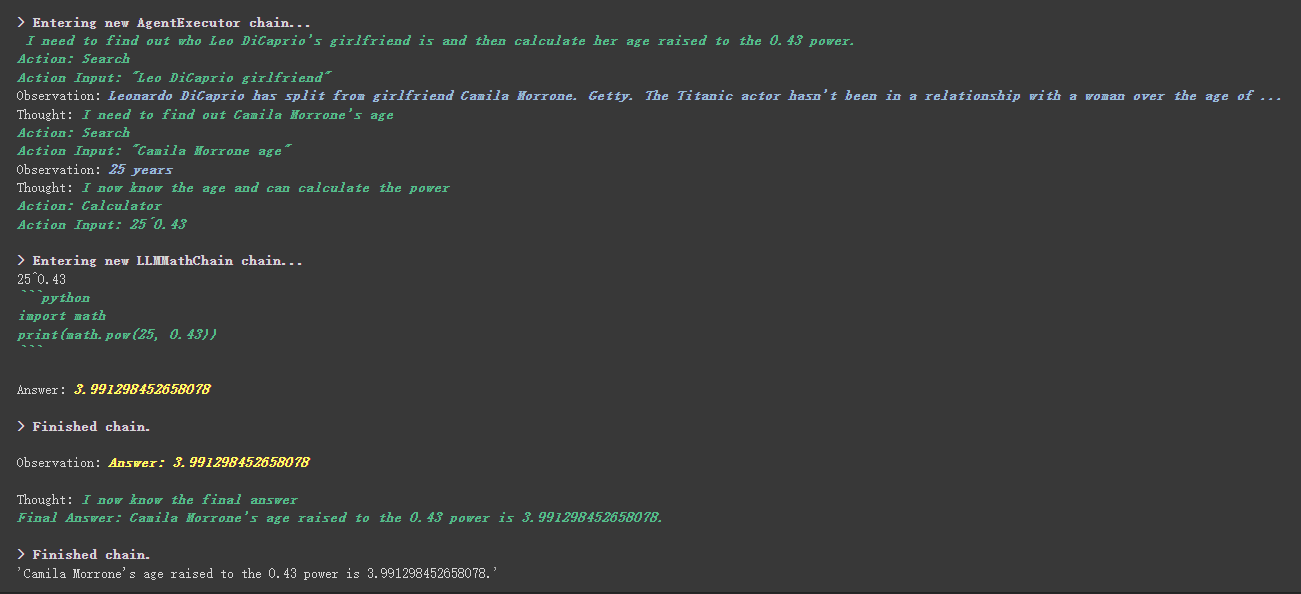
Ada hal yang lebih工具中描述内容dalam alat kustom.
Misalnya, kalkulator menulis dalam deskripsi bahwa jika Anda mengajukan pertanyaan tentang matematika, gunakan alat ini. Kita dapat melihat dalam proses eksekusi di atas bahwa di bagian matematika dari propt yang kami minta, ia menggunakan alat kalkulator untuk perhitungan.
Dalam contoh sebelumnya, kami menggunakan cara kami menyimpan riwayat dengan menyesuaikan daftar untuk menyimpan percakapan.
Tentu saja, Anda juga dapat menggunakan objek memori yang disertakan untuk mencapai ini.
from langchain . memory import ChatMessageHistory
from langchain . chat_models import ChatOpenAI
chat = ChatOpenAI ( temperature = 0 )
# 初始化 MessageHistory 对象
history = ChatMessageHistory ()
# 给 MessageHistory 对象添加对话内容
history . add_ai_message ( "你好!" )
history . add_user_message ( "中国的首都是哪里?" )
# 执行对话
ai_response = chat ( history . messages )
print ( ai_response )Sebelum menggunakan model wajah pelukan, Anda perlu mengatur variabel lingkungan terlebih dahulu
import os
os . environ [ 'HUGGINGFACEHUB_API_TOKEN' ] = ''Menggunakan Model Wajah Memeluk Online
from langchain import PromptTemplate , HuggingFaceHub , LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm = HuggingFaceHub ( repo_id = "google/flan-t5-xl" , model_kwargs = { "temperature" : 0 , "max_length" : 64 })
llm_chain = LLMChain ( prompt = prompt , llm = llm )
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print ( llm_chain . run ( question ))Tarik model wajah pelukan langsung untuk digunakan secara lokal
from langchain import PromptTemplate , LLMChain
from langchain . llms import HuggingFacePipeline
from transformers import AutoTokenizer , AutoModelForCausalLM , pipeline , AutoModelForSeq2SeqLM
model_id = 'google/flan-t5-large'
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id )
pipe = pipeline (
"text2text-generation" ,
model = model ,
tokenizer = tokenizer ,
max_length = 100
)
local_llm = HuggingFacePipeline ( pipeline = pipe )
print ( local_llm ( 'What is the capital of France? ' ))
template = """Question: {question} Answer: Let's think step by step."""
prompt = PromptTemplate ( template = template , input_variables = [ "question" ])
llm_chain = LLMChain ( prompt = prompt , llm = local_llm )
question = "What is the capital of England?"
print ( llm_chain . run ( question ))Manfaat menarik model untuk digunakan secara lokal:
Kami dapat mengimplementasikan perintah SQL melalui SQLDatabaseToolkit atau SQLDatabaseChain
from langchain . agents import create_sql_agent
from langchain . agents . agent_toolkits import SQLDatabaseToolkit
from langchain . sql_database import SQLDatabase
from langchain . llms . openai import OpenAI
db = SQLDatabase . from_uri ( "sqlite:///../notebooks/Chinook.db" )
toolkit = SQLDatabaseToolkit ( db = db )
agent_executor = create_sql_agent (
llm = OpenAI ( temperature = 0 ),
toolkit = toolkit ,
verbose = True
)
agent_executor . run ( "Describe the playlisttrack table" ) from langchain import OpenAI , SQLDatabase , SQLDatabaseChain
db = SQLDatabase . from_uri ( "mysql+pymysql://root:[email protected]/chinook" )
llm = OpenAI ( temperature = 0 )
db_chain = SQLDatabaseChain ( llm = llm , database = db , verbose = True )
db_chain . run ( "How many employees are there?" )Di sini Anda dapat merujuk ke dua dokumen ini:
https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html
Semua kasus pada dasarnya telah berakhir. Artikel ini hanyalah penjelasan awal tentang Langchain.
Dan karena Langchain berulang dengan sangat cepat, itu pasti akan mengulangi fungsi yang lebih baik karena AI terus berkembang, jadi saya sangat optimis tentang perpustakaan open source ini.
Saya harap semua orang dapat menggabungkan Langchain untuk mengembangkan lebih banyak produk kreatif, daripada hanya membuat banyak produk yang membangun klien obrolan dengan satu klik.
Saya menambahkan 01 setelah judul ini.
Semua kode sampel dalam artikel ini ada di sini, saya berharap Anda belajar bahagia.
https://colab.research.google.com/drive/1arrvmis-ghulobhru6bes8ff57ueapq?usp=sharing


